一种基于CUDA C的短波辐射模式加速方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明涉及高性能计算技术领域,具体涉及一种基于CUDA C的短波辐射模式加速方法。
背景技术
地球上的天气与气候情况是由太阳辐射量及其分布所决定的。辐射过程作为重要的大气物理过程之一,需要保证其模拟的气候变化准确率高,因此对辐射计算模型的精确性有很高的要求。RRTMG(rapid radiative transfer model for general circulationmodels)是一种计算长短波大气辐射通量和加热速率的辐射模式,该模式使用相关k方法来满足目前对辐射计算精确度的要求。复杂的气候数值模拟系统需要模拟多种物理过程,其辐射传输模块的计算量占比较大,无法满足地球系统模式大规模高效计算的需要。
通过分析RRTMG短波辐射模式RRTMG_SW的串行计算,可以发现RRTMG_SW的驱动子程序rrtmg_sw计算耗时最多,所以主要对rrtmg_sw进行基于GPU的加速计算。在rrtmg_sw中,各个子程序的计算时间不一,其中spcvmc_sw子程序耗时最长,占rrtmg_sw总计算时间的71.4%。
表1 RRTMG_SW各子程序计算时间(s)
为了提高RRTMG_SW的计算效率,可以在GPU上对其进行加速计算。具体,通过改写串行Fortran程序,基于CUDA C实现RRTMG_SW的加速计算。
发明内容
本发明的目的在于提供一种基于CUDA C的短波辐射模式加速方法,用以提高短波辐射模式RRTMG_SW的计算效率。
为实现上述目的,本发明的技术方案为:
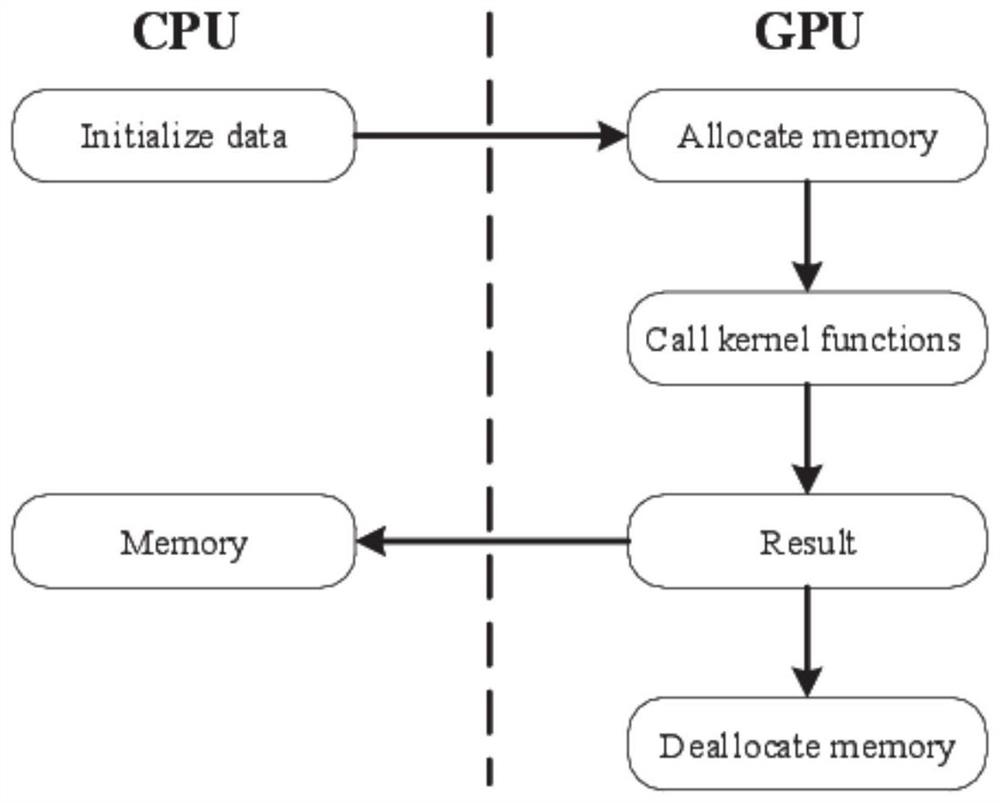
步骤1.数据初始化。首先对四个子程序inatm_sw、cldprmc_sw、setcoef_sw和spcvmc_sw所需要的数据进行定义和初始化。由于水平维度上ncol值的不确定性,在定义CPU端数组时,采用定长数组来解决ncol值不确定的问题,例如,double play[nlay*ncol],其中nlay=51,ncol=1024*n(n为整数)。在GPU端,采用指针数组,例如,double*play_d,并通过cudaMalloc()对GPU端的数组进行内存分配,例如,cudaMalloc((void**)&play_d,nlay*ncol*sizeof(double));
步骤2.数据传输。将CPU端数组通过cudaMemcpy()赋值给GPU端对应的数组,要求数组的大小和类型相同。例如,cudaMemcpy(play_d,play,nlay*ncol*sizeof(double),cudaMemcpyHostToDevice),其中,play_d为GPU端定义的数组,play为CPU端定义的数组。
步骤3.核函数的编写。在串行代码中,四个子程序格式为subroutine xxx(parameters)。将它们改写为GPU端核函数,格式为__global__void xxx(parameters)。例如,第一个子程序subroutine inatm_sw(parameters)改写为__global__void inatm_sw(parameters)。原串行代码通过对四个子程序进行外部循环来计算水平柱数,而并行加速代码则是将原代码的相关计算数组增加一个维度,表现在代码上就是增加了ncol这个维度,然后使用if语句对CUDA中全局线程索引号进行标识来计算水平柱数。由于中间数据的特性,对维度的改变并不会影响计算过程中输入输出的数据值,进而不会影响原算法计算结果。
步骤4.启动核函数计算。在CPU端启动GPU端的核函数进行计算。例如,启动inatm_sw核函数,inatm_sw<<
步骤5.数据传回及内存释放。计算完毕后,将CPU端需要的数组从GPU端传回CPU端,以便CPU端进行后续的计算。例如,cudaMemcpy(zbbfd,pbbfd,ncol*53*sizeof(double),cudaMemcpyDeviceToHost),其中,zbbfd为CPU端数组,pbbfd为GPU端数组。数据传输完毕后使用cudaFree()释放GPU端内存,例如,cudaFree(play_d),cudaFree(pbbcd)。
本发明具有如下优点:
本发明将GPU技术和CUDA并行计算架构应用到了短波辐射模式中,在不考虑I/O传输下,在一个Titan GPU上实现了38.88倍的加速,提高了短波辐射模式的计算效率。
附图说明
图1本发明的加速计算流程示意图
图2RRTMG短波辐射程序结构
图3当线程块大小不同时,RRTMG_SW的CUDA C版本在一个K20 GPU上的运行时间
具体实施方式
下面将结合本发明实施例中的附图和表格,对本发明实施例中的技术方案进行清楚、完整地描述。
RRTMG_SW基于CUDA C加速方法如下:
以下算法2~5分别为核函数inatm_sw_d、cldprmc_sw_d、setcoef_sw_d和spcvmc_sw_d的具体实施伪代码。
RRTMG_SW在K20,P100和Titan GPU上的运行时间和相应的加速效果如表2所示。表中的CPU时间是指串行计算所需的时间,GPU时间是指并行计算所需的时间。实验结果表明在一个Titan GPU上RRTMG_SW的加速比能够达到13.73。
表2不同GPU上的计算时间(s)及加速比(规模2048×384,block size=128)
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 一种基于CUDA Fortran的短波辐射模式加速方法
- 一种基于GPU的短波辐射传输模式三维加速方法