一种基于文本描述的行人图像检索方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及跨媒体信息检索领域,具体涉及一种基于文本描述的行人图像检索方法。
背景技术
给定一段以自然语言形式对行人外观进行描述的查询文本,基于文本描述的行人图像检索旨在从行人图像数据库中检索出最相关的行人图像。随着视频监控的逐步推广和普及,本任务在预防犯罪、天眼寻人、形迹追踪等领域有着重要的应用价值。该任务的主要难点在于文本特征和图像特征属于不同模态的特征,两者之间存在着异构语义鸿沟。在应用场景中,我们需要计算文本特征和图库中行人图像特征之间的相似度。然而,直接计算图像和文本的特征相似度是没有意义的。因为它们来自两个完全不同的语义空间,这意味着特征相似度可能与它们的匹配程度无关。为了解决这个问题,许多已提出的算法致力于在共享特征空间中为每个行人学习具有模态不变的和具有区分度的特征。
这些算法大多采用了多分类交叉熵损失函数来学习更具有区分度的图像与文本联合嵌入特征。交叉熵损失函数能够促进模型将同一行人的图像特征和文本特征分类为同一类别,从而间接提高匹配的图像文本对的相似度。直观来看,在共享语义特征空间中同时最大化相同类内部的紧凑性和不同类间的差异将有助于模型学习到更具有区分度的特征。在基于文本描述的行人图像检索研究的相关算法中,softmax损失函数被广泛应用。Softmax损失函数由一个全连接层,一个softmax函数和一个交叉熵损失函数组成。从softmax损失函数的数学表达式可以看出,它并且没有直接增加类内部的紧致度和类间的差异。由softmax损失函数训练出来的特征会存在一些问题,例如:类内特征的相似度反而小于类间特征相似度。Softmax损失函数中的完全连接层实际上起着线性分类器的作用,特征所属类的概率分布取决于该特征与完全连接层中每个类权重向量的内积。值得注意的是,内积的值可以被分解为向量的模和角度余弦的大小。因此,我们可以考虑增大特征与线性分类其中类权重向量的角度间隔来获得更具有区分度的特征。与人脸识别相比,如何将角度余量纳入softmax损失函数中并同时考虑视觉和文本特征的联合嵌入学习是挑战所在。
在行人相关任务领域,深度度量学习已得到广泛应用。在人脸识别和行人再识别等领域中,对比损失(ContrastiveLoss)和三元组损失(Triplet Loss)已显示出其令人印象深刻的改进模型性能的能力。但是,三元组损失对基于文本描述的行人图像检索却收效甚微。通过审视基于对的度量损失(如对比损失和三元组损失)的数学表达式,我们发现正对或负对的系数相等,这似乎是不合理的。例如,可能存在一些异常的图像文本对,它们匹配但余弦相似度分数低,或者不匹配但余弦相似度分数高。这些异常对总是提供更多信息和价值。显然,异常对应该比那些正常对受到更多的关注。基于这些分析,我们考虑在基于文本描述的行人图像检索研究中为异常图像文本对赋予更大的权重,以此提高模型的学习效率。
已有的算法大都采用全连接层形成的一个线性分类器对特征进行类别分类进而通过多分类交叉熵损失函数来促进模型学习更准确的行人特征。然而,这种直接采用线性分类器计算特征所属类别概率分布的方法却存在着明显的不足。它不能增大类内特征的相似度与此同时增大类间特征的差异,这就导致一个后果:尽管模型能够做好图像和文本特征所属行人类别的分类,但在推理过程中计算文本和数据库中图像相似度时却无法建立匹配度与相似度的正确关系。此外,在基于文本描述的行人图像检索任务中,模型主要处理的对象是图像文本对。这些图像文本对会存在一些不匹配然而相似度却较高,或者匹配然而相似度却较低的情况。这就要求我们对不同的图像文本对应该赋予不同的关注,对于一些匹配却相似度较低的图文对以及不匹配却具有较高相似度的图文对,模型应该赋予更多的关注从而提高模型学习的效率。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于文本描述的行人图像检索方法解决了现有技术中基于文本描述的行人图像检索任务中行人特征类内差异过大而类内差异过小的问题。
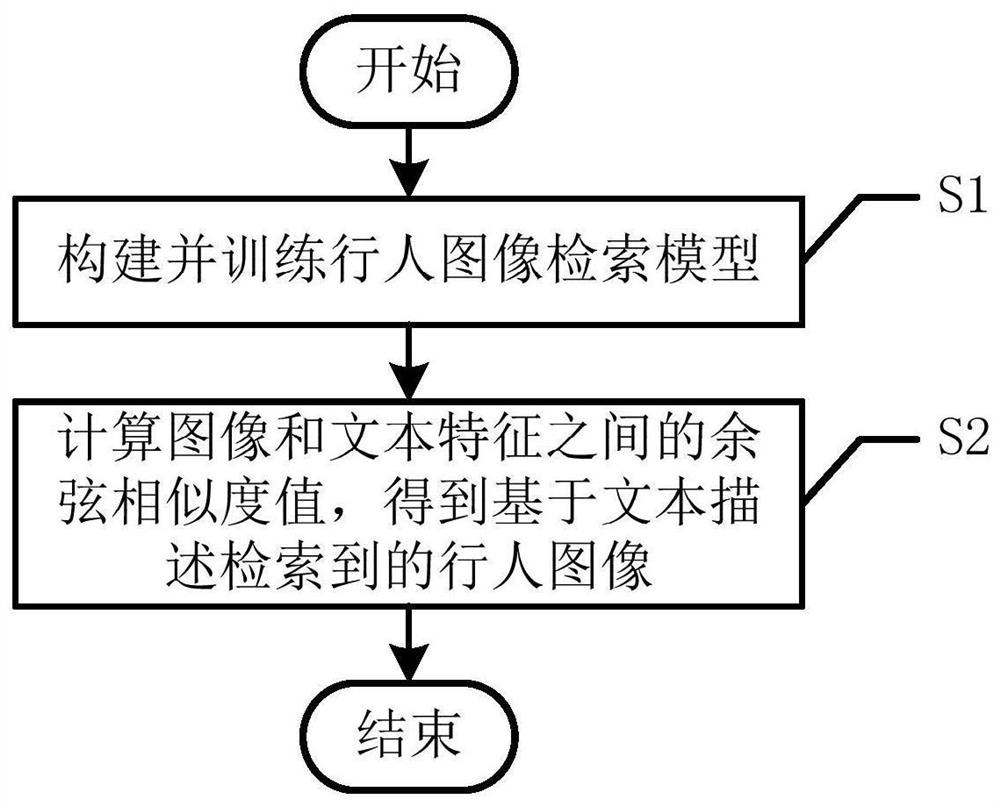
为了达到上述发明目的,本发明采用的技术方案为:一种基于文本描述的行人图像检索方法,包括以下步骤:
S1、构建行人图像检索模型,对行人图像检索模型进行训练,得到训练完成的行人图像检索模型;
S2、采用训练完成的行人图像检索模型计算图像特征和文本特征之间的余弦相似度值,根据余弦相似度值,得到基于文本描述检索到的行人图像。
进一步地,所述步骤S1中行人图像检索模型包括:图像特征提取器、文本特征提取器和联合嵌入学习器;
所述图像特征提取器为去除最后全连接层的MobileNet模型;
所述文本特征提取器包括:词嵌入层和双向长短期记忆网络;
所述联合嵌入学习器包括:共享参数全连接层。
进一步地,所述步骤S1包括以下分步骤:
S11、采用文本特征提取器对输入文本进行特征提取,得到初始文本特征;
S12、采用图像特征提取器对输入的行人图像进行特征提取,得到初始图像特征;
S13、将初始文本特征和初始图像特征输入联合嵌入学习器,构建损失函数模型,并基于损失函数模型对联合嵌入学习器进行训练,得到训练完成的行人图像检索模型。
进一步地,所述步骤S13中联合嵌入学习器的共享参数全连接层的损失函数模型为:
L=L
其中,L为总体损失函数,L
进一步地,所述乘性角度余量损失函数为:
L
其中,L
上述进一步方案的有益效果为:本发明提出的乘性角度余量损失函数,通过将其中一个模态特征投影到另一个模态的标准化特征来融合文本和图像特征,并从文本和图像特征中获得了一个新的特征向量,这个向量的模来自其中一个特征向量,它的方向却与另外一个方向相同。通过这种方式,实现增强了匹配文本图像对的文本和图像特征的关联。
进一步地,所述成对相似度加权损失函数为:
其中,L
上述进一步方案的有益效果为:本发明设计的成对相似度加权损失函数具有:负对的权重与其相似度值成正比,从而确保为异常图文对分配更高的权重。
进一步地,所述跨模态投影匹配(CMPM)损失函数为:
其中,L
上述进一步方案的有益效果为:本发明设计的跨模态投影匹配(CMPM)损失函数本质上是一个相对熵的应用,这样设计能够促使x
综上,本发明的有益效果为:本发明的方法可以直接提高属于同一行人的图文特征相似度,同时也能直接增大属于不同行人的图文特征之间的差异。这有助于模型在推理过程中,计算特征相似度时获得优异的性能。另外,本方法在模型学习的过程中,为不同图文对赋予不同权重。这有助于模型在学习参数的过程中更具有针对性,从而能从一些异常图文对中学习到更多的信息。本发明仅凭借对损失函数的设计与改进,就使得模型在基于文本描述的行人图像检索任务上获得了令人满意的性能。与现有技术相比,本发明的方法操作简单,对计算资源要求不高,性能稳定且优异。
附图说明
图1为一种基于文本描述的行人图像检索方法的流程图;
图2为行人图像检索模型的结构示意图;
图3为不匹配图文对的余弦相似度与成对相似度加权损失函数之间关系的图;
图4为消融实验结果图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于文本描述的行人图像检索方法,包括以下步骤:
S1、构建行人图像检索模型,对行人图像检索模型进行训练,得到训练完成的行人图像检索模型;
如图2所示,步骤S1中行人图像检索模型包括:图像特征提取器、文本特征提取器和联合嵌入学习器;
所述图像特征提取器为去除最后全连接层的MobileNet模型;
所述文本特征提取器包括:词嵌入层和双向长短期记忆网络;
所述联合嵌入学习器包括:共享参数全连接层。
所述步骤S1包括以下分步骤:
S11、采用文本特征提取器对输入文本进行特征提取,得到初始文本特征;
S12、采用图像特征提取器对输入的行人图像进行特征提取,得到初始图像特征;
S13、将初始文本特征和初始图像特征输入联合嵌入学习器,构建损失函数模型,并基于损失函数模型对联合嵌入学习器进行训练,得到训练完成的行人图像检索模型。
联合嵌入学习器的共享参数全连接层的损失函数模型为:
L=L
其中,L为享参数全连接层的损失函数,L
所述乘性角度余量损失函数(MultiplicativeAngularMargin,简称MAM)为:
L
其中,L
乘性角度余量损失函数的论证过程为:
一个小批量中有N个人图像和相应的描述。图像文本对被表示为
首先介绍现有技术中基于文本描述的行人图像检索任务中常用的softmax损失函数。一个图像特征x
其中W
本发明提出的乘性角度余量损失函数,与仅涉及图像特征的人脸识别算法不同,基于文本描述的行人图像检索不仅关注图像特征,还涉及文本特征。本发明通过将其中一个模态特征投影到另一个模态的标准化特征来融合文本和图像特征。因此,可从文本和图像特征中获得了一个新的特征向量,这个向量的模来自其中一个特征向量,它的方向却与另外一个方向相同。通过这种方式,增强了匹配文本图像对的文本和图像特征的关联。更重要的是,在
所述成对相似度加权损失函数(Pairwise Similarity Weighting,简称PSW)为:
其中,L
成对相似度加权损失函数的论证过程为:
在基于文本描述的行人图像检索任务中,每个行人匹配的图像文本对的数量要比不匹配的图像文本对少得多。同时,存在着一些图像文本对,他们的匹配程度与相似度有着不合常理的数值关系。但是,在现有的算法(例如三元组损失)中,所有匹配对和未匹配对都分配有相同的权重,这就使得模型不能关注于异常图像文本对,从而导致收敛速度慢和性能不佳。为了更好地利用信息对,许多深度度量学习文献中都提出了难负例样本挖掘策略和对加权方法。特别是在本发明技术方案中,有必要设计一种对加权机制,为信息丰富的图像文本对分配更高的权重。在图像文本样本对相似度与权重的关系上,正对的权重应与其相似度值成反比,而负对的权重与其相似度值成正比。本发明提出的成对相似度加权损失函数中,将图像文本对的权重定义为成对相似度加权损失函数相对于其余弦相似度的导数。为了方便和简单起见,并基于二次函数专门设计了成对相似度加权损失函数。
为了进一步解释本发明提出的成对相似度加权损失函数的工作原理,绘制了一幅有关不匹配图文对的余弦相似度与成对相似度加权损失函数之间关系的图,如图3所示。
根据图3可知,随着负对的相似度增加,其相关的成对相似度加权损失函数和对权重都增加。
首先,把一个不匹配的图像文本特征对的权重定义为
所述跨模态投影匹配(英文全称:Cross-Modal Projecting Matching,简称CMPM)损失函数为:
其中,L
S2、采用训练完成的行人图像检索模型计算图像特征和文本特征之间的余弦相似度值,根据余弦相似度值,得到基于文本描述检索到的行人图像。
采用数据集CUHK-PEDES对我们训练好的模型进行测试,测试方法为:采用文本特征提取器提取文本特征,采用图像特征提取器提取图像特征,将文本特征和图像特征输入联合嵌入学习器中,计算文本特征和图像特征之间的余弦相似度值,并对采用评测标准召回率Recall@K作为性能评价指标。Recall@K表示符号在前K个结果中,至少存在一个真实匹配行人图像的测试数据所占百分比。
表一实验性能结果
此外,并进行了一系列消融实验,以验证本发明提出的损失函数的有效性。通过比较有无特定组件的模型性能,可以判断每个组件对模型性能的贡献。在实验中,主要评估乘性角度余量(MAM)损失函数和成对相似度加权(PSW)损失函数的影响,结果如图4所示。实验结果证明了本发明提出的乘性角度余量(MAM)损失函数以及成对相似度加权(PSW)损失函数的有效性。
- 一种基于文本描述的行人图像检索方法
- 一种基于不完整文本描述的特定行人检索方法