一种基于知识图谱的中文易混词生成方法
文献发布时间:2023-06-19 19:04:00
技术领域
本发明涉及文本纠错领域,具体涉及一种基于知识图谱的中文易混词生成方法。
背景技术
在文本纠错领域,常用的方法包括基于语言模型的文本纠错方法和基于深度学习模型的文本纠错方法两类,而无论在哪类方法中,易混词集都起到了重要的作用。
基于语言模型的文本纠错方法的主要思路是对待纠错文本进行预处理,按一定方法定位语法错误的位置,并按字粒度或词粒度,在易混词集中搜索文本中每个字/词的候选字/词,从而生成待纠错文本的候选文本集,从而通过对各候选文本进行评价,并与待纠错文本进行比较,而实现特定类型错误文本的纠正。
基于深度学习模型的文本纠错方法根据用于训练的数据量和模型结构的不同,可分为基于无监督学习、有监督学习和弱监督学习模型等类型。这些方法对易混词集的应用主要有两种形式。其一,由于获取准确标注的数据存在一定的困难,一种常用的数据增强方法是在语法正确的文本数据基础上,利用易混词集,生成包含错误的合成数据,并将生成的数据用于模型参数的学习过程,从而提升模型预测文本错误的准确率。其二,为提升基于深度学习模型的文本纠错方法的性能,一种可行的方法是利用输入文本生成相应的易混词集,并作为模型的额外特征接入到模型中,从而改善文本纠错模型的准确率。
目前,在文本纠错领域中,针对易混词的研究主要面向英文文本,而对中文易混词的生成的研究较少。英文易混词集的生成过程主要考虑的因素包括发音、单词编辑距离、领域、主题等。相较于英文而言,中文由于是语素文字,在书写过程中易将汉字写错位具有相似字形的错别字,因此,目前在中文易混词生成过程中,通常考虑的因素包括字音、字形、领域等。此外,随着表示学习模型的发展,基于词向量的字/词相似性也成为易混词生成的一种考虑因素。然而,中文易混词的生成过程缺少统一的标准,通常针对不同的领域构造单独的易混词集,而这样得到的易混词集因缺少泛化性,而无法或较难应用于其他领域。
综上,中文易混词对中文文本纠错具有重要的意义。然而,在生成中文易混词的过程中仍存在较多问题。一方面,中文易混词集的生成过程强烈依赖于所应用的领域,当领域发生变化时,现有的中文易混词集难以直接泛化到新的领域。另一方面,生成中文易混词集的过程强烈依赖于专家经验对所需考虑的因素的权衡,而缺少统一的标准。因此,研究影响中文易混词的生成过程中的关键因素,建立具有较好泛化性的生成方法,对提升中文文本纠错算法性能具有重要的意义,是目前该领域研究的关键问题之一。
发明内容
本发明的目的在于针对现有中文文本纠错方法中,难以有效利用场景、领域和上下文等信息,灵活而准确地生成中文易混词的问题,提供一种基于知识图谱的中文易混词生成方法。
本发明的目的是通过以下技术方案实现的:
一种基于知识图谱的中文易混词生成方法,包括以下步骤:
步骤一:定义面向中文易混词生成的中文词知识本体,包含实体类型和/或实体属性,以及实体间关系类型和/或关系属性;
步骤二:对中文文本数据进行清洗和特征提取,得到处理后的中文字和词以及对应的特征,生成中文词集;
步骤三:根据生成的中文词集,计算词-词之间在发音、词形、语义的相似度和编辑距离;
步骤四:根据步骤一所构建的知识本体、步骤二中数据预处理得到的中文词集以及步骤三得到的发音、词形、语义的相似度和编辑距离,完成知识图谱实例化;
步骤五:根据步骤二得到的中文词集,利用步骤四得到的知识图谱,得到中文词集中的每条数据对应的知识图谱的子图;
步骤六:根据步骤三得到的发音、词形、语义的相似度和编辑距离,得到中文词集中的每个中文词的易混词集合;
步骤七:构建基于深度学习的多输入多输出的中文易混词生成模型,利用步骤二得到的中文词集,以及步骤五得到的每条数据对应的知识图谱的子图作为输入,以步骤六得到的每个中文词的易混词集合作为标签,训练所述中文易混词生成模型;
步骤八:接收用户输入,并进行和步骤二相同的清洗和特征提取预处理操作;
步骤九:根据步骤八得到的结果,以及步骤四生成的知识图谱,生成所述知识图谱的子图;
步骤十:将步骤八得到的结果和步骤九生成的知识图谱的子图输入训练后的中文易混词生成模型,得到用户输入中各中文词所对应的中文易混词集合。
进一步地,所述步骤一中定义的面向中文易混词生成的中文词知识本体的实体类型包括四类:
(1)以不同粒度描述的中文文本的实体类型,包括中文的字、词、命名实体、常用词、短语、句子、段落和文章类型实体,其中字、词、命名实体、常用词、短语类型的实体具有的属性包括词性、发音、语义,句子实体具有的属性包括标识、文本、语法错误标识、错误列表、修正和时态,段落和文章类型的实体具有标识属性;
(2)与中文文本语义相关的实体类型,包括领域和主题;
(3)能够描述用于易混词生成的语料库实体,其具有的属性包括来源、名称、类型和描述;
(4)对字、词、命名实体、常用词、短语、句子、段落和文章类型实体进行抽象而定义的篇章类型实体,以及对篇章、语料库、领域和主题类型实体进行抽象而定义的物体类型实体。
进一步地,所述实体间关系类型包括:
(1)描述各类实体间相似性的相似关系,其具有的属性包括发音相似性、字形相似性、语义相似性和编辑距离;
(2)描述篇章、句子、段落、文章、短语、字、词、命名实体、常用词类型的实体之间的子类关系;
(3)描述物体、篇章、语料库、领域和主题类型的实体之间的子类关系;
(4)描述命名实体缩略词与全称的缩写关系;
(5)描述一篇文章中的词、句子、段落之间先后顺序的接续关系,其具有的属性包括所在的句子标识和标点;
(6)描述语料库实体、文章、段落、句子、词之间的包含关系;
(7)描述语料库实体与领域实体的属于关系;
(8)描述段落实体与主题实体的具有关系。
进一步地,所述步骤二对中文文本数据进行的清洗和特征提取包括:对多种来源的文本依次进行Unicode正规化、去除无意义字符、替换不需纠错的文本内容、分段、繁简转换、命名实体识别、分词、词性标注、依存关系识别、拼音识别、按文章/段落/句子识别其所对应的主题和所属领域、停用词过滤、识别命名实体的全称与缩写的对应关系;最后将处理后的中文字、词以及对应的特征进行汇总,生成中文词集。
进一步地,所述步骤三对中文词集中的中文简体汉字/词对,执行如下操作:
根据拼音计算发音相似性;
根据偏旁部首计算词形相似性;
根据字典中各字/词的释义计算语义相似度;
根据两词等价变换所需编辑操作计算其编辑距离。
进一步地,所述步骤四的知识图谱实例化过程通过以下子步骤实现:
(1)对步骤二预处理后得到的中文词集,按数据来源分成不同的语料库,对各份处理后的语料中的中文文章、文章中段落、段落中句子、句子中短语、命名实体、常用词和字,按步骤一中定义的知识本体,生成相应的实体节点以及实体之间的子类、包含、接续和相似关系;按实体类型和处理后的数据,生成对应的实体属性和关系属性;
(2)由步骤二中得到的段落所对应的主题和语料库所对应的领域,生成主题实体和领域实体,并建立段落实体与主题实体之间的具有关系、语料库实体与领域实体之间的属于关系。
进一步地,所述步骤五的知识图谱子图生成过程通过以下子步骤来实现:
(5.1)知识图谱实体匹配和筛选:根据步骤二得到的中文词集,与所述知识图谱中的实体进行匹配,并过滤掉关联性低于给定阈值的实体;
(5.2)连通子图生成:根据经过筛选的实体集,在所述知识图谱中搜索能够覆盖这一实体集的最小连通子图,并将其与位于所述最小连通子图之外且与所述最小连通子图直接相连的实体和边,构成与所述中文词集中的每条数据相对应的知识图谱子图。
进一步地,所述步骤六中中文词的易混词集合生成过程通过以下子步骤实现:
(1)对步骤二中得到的中文词集中任意两词,利用步骤三中得到的发音相似度、词形相似度、语义相似度和编辑距离,计算其加权平均值,作为这两词的平均相似度;
(2)针对步骤二中得到的中文词集中的每个词,按平均相似度进行排序,截取其中平均相似度大于预设阈值的词集合,作为该词的易混词集合。
进一步地,所述步骤七的中文易混词生成模型具有如下特征:
所述基于深度学习的多输入多输出的中文易混词生成模型为包括序列编码器和图编码器、一个信息融合模块和一个解码器的深度学习模型,其中,所述序列编码器将步骤二得到的中文词集映射到隐状态空间A,所述图编码器将知识图谱的子图映射到隐状态空间B;所述信息融合模块将隐状态空间A和B进行拼接、空间变换、卷积和池化操作,得到融合后的信息向量;所述解码器将信息融合模块输出的信息向量,经过全连接神经网络和softmax操作后,得到输入中文词序列中每个词所对应的易混词集合。
进一步地,所述步骤七中的中文易混词生成模型参数训练过程中,为扩充训练数据,针对每组输入和输出,在输出中的易混词集合中进行随机采样,生成其子集,并将原输入与该子集,作为新的训练样本,加到训练数据中。
本发明的有益效果如下:
1.本发明定义了面向中文文本纠错的中文词知识本体,在对多种来源的中文文本数据的表征的同时,能够有层次地描述包含文章、段落、句子、词、字等不同粒度的中文文本之间在发音、字形和语义等方面的相似性,具备对新数据的泛化性。
2.本发明在中文易混词生成过程中,不仅利用了知识图谱中对中文字/词间在发音、字形、语义等方面的相似性,还利用了中文字/词在所对应的主题、领域以及上下文信息,使该模型具备跨领域应用的能力。
3.本发明的中文易混词生成模型能够有效融合具有序列结构、图结构等不同模态的多源异构数据,通过对各模态数据的有效表征、融合和处理,有效预测用户输入文本中各词所对应的易混词列表。
附图说明
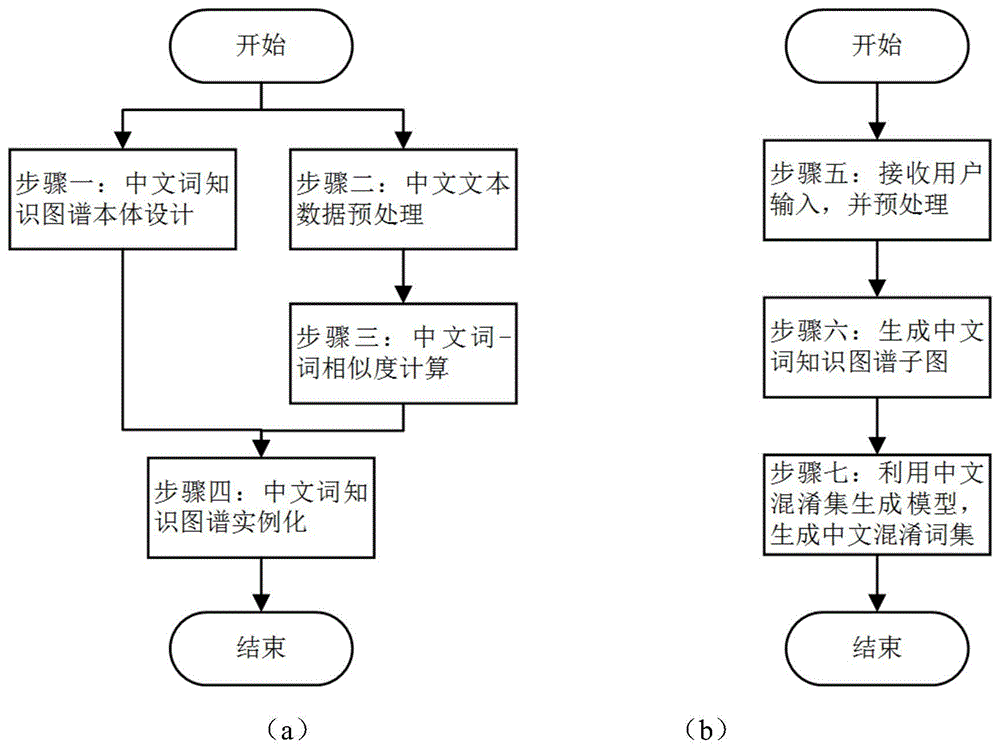
图1是本发明所述方法的主要流程图;其中图(a)为中文词知识图谱的离线生成过程;图(b)为中文易混词在线生成过程。
图2是本发明所述方法中的中文词知识本体设计图。
图3是本发明所述方法步骤五流程图。
图4是本发明所述方法中易混词生成模型流程图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。在本发明使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本发明。在本发明和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
如图1所示,本发明提出的基于知识图谱的中文易混词生成方法,具体描述如下:
步骤一:定义面向中文易混词生成的中文词知识本体,具有如图2所示的形式。本体包含了实体类型、实体间关系以及实体/关系属性,其说明如下:
不同类型的实体具有层次结构,根实体类型为抽象类型实体——物体,其子实体类型包括抽象类型实体——篇章、语料库、领域和主题。其中篇章实体用于描述具有不同粒度的中文文本,包括文章、段落、句子、短语、词、常用词、命名实体和字类型实体,语料库实体用以描述在一组正确或错误的中文文本,即一组篇章的集合,领域实体用以描述某一中文文本所涉及的领域,主题实体用以描述某一中文文本所讨论的主题。从不同粒度对篇章进行描述,可以将其分为文章、段落、句子、基本符号,按组成汉字的数目不同,进一步将基本符号细分为中文字、词,按是否具有特定意义,将词细分为常用词和命名实体,其中命名实体包括全称和缩写。
实体间关系描述了任意两类实体节点之间存在的关联关系。本发明所提出的本体主要包含,但不限于如下关系:子类、相似、缩写、接续、包含、具有和属于关系。子类关系用于描述实体类型间的层次关系,如篇章实体是物体实体的子类;相似关系用于描述基本符号之间的相似性;缩写关系用于描述命名实体A是命名实体B的缩写;接续关系用于描述在某一句子中,基本符号之间的序列先后关系;包含关系用于描述语料库实体包含了一个或多个文章实体或不同粒度的篇章子类实体间的包含关系,如文本段落A包含了文本句1、文本句2……;具有关系用于描述一个段落所描述事实的主题;属于关系用于描述某一文章归属的领域,如报纸上的一篇军事评论文章归属于军事领域。
实体/关系属性是对实体或关系的特征的进一步说明,且子类实体继承了父类实体的属性。本发明为短语、词、常用词、命名实体和字类型实体增加了语义、词性标注和发音属性,为句子实体增加了标识、文本、语法错误标识、错误列表、修正和时态属性,为段落实体、文章实体增加了标识属性,为语料库实体增加了来源、名称、类型和描述属性。此外,实体间关系也需增加额外的特征描述,包括但不限于:为基本符号实体间的相似关系增加了语义相似度属性,为中文字实体间相似关系增加了发音相似性和字形相似性属性,为词实体间相似关系增加了编辑距离属性,为基本符号实体间的接续关系增加了句子标识和标点属性。
步骤二:对中文文本数据进行清洗和特征提取,得到处理后的中文字和词以及对应的特征,并生成中文词集。例如,现有文本如下:
“煙臺市牟平區有座雷神廟。這座建於1634年的廟宇,占地約有兩三個籃球場那麽大。”
由于中文文本具有多种编码格式,在读取数据时,需将其转化为统一的格式,即Unicode正规化。由于不需对数字/年份等进行纠正,因此需识别句中的这类实体,并进行替换。替换后的文本如下:
“煙臺市牟平區有座雷神廟。這座建於[NUM]年的廟宇,占地約有[NUM]個籃球場那麽大。”
其中“[NUM]”表示数字。
按自然段,对文章中的数据进行分段。在本例中,文章仅有1个段落,且该段落中仅有两个句子。
利用Python的OpenCC工具包将繁体中文转化为简体中文。转换后的结果如下:
“烟台市牟平区有座雷神庙。这座建于[NUM]年的庙宇,占地约有[NUM]个篮球场那么大。”
利用HanLP工具识别文本中的命名实体,识别结果包括“烟台市”、“牟平区”、“雷神庙”。
利用HanLP工具对文本进行分词和词性标注,结果为“烟台市(ns)/牟平区(ns)/有(v)/座(q)/雷神庙(ns)/。(w)/这(r)/座(q)/建(v)/于(p)/[NUM](m)/年(t)/的(u)/庙宇(n)/,(w)/占地(v)/约(d)/有(v)/[NUM](m)/个(q)/篮球场(n)/那么(r)/大(a)/。(w)”,其中词性标识采用北大词性标注规范,如表1所示。
表1词性标注说明
利用HanLP工具对文本进行依存关系识别,识别结果如表2所示,采用斯坦福依存关系标注,部分标注说明如表3所示。
表2示例文本依存关系分析结果
表3斯坦福依存关系标注说明(部分)
利用Python中xpinyin包对文本中中文字进行拼音识别,结果为“烟/(yan1)台/(tai2)市(shi4)/牟/(mu4)平/(ping2)区(qu1)/有(you3)/座(zuo4)/雷/(lei2)神/(shen2)庙(miao4)/。/这(zhe4)/座(zuo4)/建(jian4)/于(yu2)/[NUM]/年(nian2)/的(de5)/庙/(miao4)宇(yu3)/,/占/(zhan4)地(di4)/约(yue1)/有(you3)/[NUM]/个(ge4)/篮/(lan2)球/(qiu2)场(chang3)/那/(na4)么(me5)/大(da4)/。”。
利用Python中gensim包识别该文本的主题,并利用该文本的向量表示,计算与预先指定领域向量进行余弦相似性度量,从而预测其所属领域。
利用规则,识别文本中存在的命名实体间的缩写关系。在本例中无缩写。
最终,将上述处理后的中文字和词以及对应的特征进行汇总,并生成中文词集。
步骤三:根据生成的中文词集,计算词-词之间在发音、词形和语义方面的相似度和编辑距离。具体过程如下:
(1)发音相似性
从语言学和口腔发音规律等角度,对比任意两个中文字在声母、韵母和音调方面的相似性,并利用一下公式计算发音相似性:
其中
(2)字形相似性
从语言学和中文简体字偏旁部首的角度,对比任意两个中文字的相似性。由于汉字中的偏旁部首具有空间位置特征,因此,采用无向图来描述这种特征,并利用图嵌入方法对两个具有无向图描述的中文字进行对比,其公式如下:
其中
(3)语义相似性
区别于发音和字形相似性仅适用于中文字,语义相似性还适用于中文词,并从语言学和字的词典释义等角度,对比任意两个中文字/词的相似性,其公式如下:
其中
(4)编辑距离
适用于中文词-词间的相似性计算,其公式如下:
其中
步骤四:根据步骤一所构建的知识本体、步骤二中数据预处理得到的中文词集以及步骤三得到的发音、词形、语义的相似度和编辑距离,完成知识图谱实例化。
(1)对步骤二预处理后得到的中文词集,按数据来源分成不同的语料库,对各份处理后的语料中的中文文章、文章中段落、段落中句子、句子中短语、命名实体、常用词和字,按步骤一中定义的知识本体,生成相应的实体节点以及实体之间的子类、包含、接续和相似关系;按实体类型和处理后的数据,生成对应的实体属性和关系属性;
(2)由步骤二中得到的段落所对应的主题和语料库所对应的领域,生成主题实体和领域实体,并建立段落实体与主题实体之间的具有关系、语料库实体与领域实体之间的属于关系。
步骤五:根据步骤二得到的中文词集,利用步骤四得到的知识图谱,得到中文词集中的每条数据对应的知识图谱的子图。这一步骤又分为知识图谱实体匹配与筛选、连通子图生成等步骤,如图3所示。
首先,进行知识图谱实体匹配与筛选,根据步骤二得到的中文词集,与所述知识图谱中的实体进行匹配,并过滤掉关联性低于给定阈值的实体。例如,对步骤二中样例,可得到分别如下表4和表5所示的实体和实体关系。
表4匹配到的实体
表5匹配到的关系类型
其次,进行连通子图生成。根据经过筛选的实体集,利用最短路算法,在完整的知识图谱中搜索能够连接其中任意两个实体节点的路径,并将该路径上的所有实体节点和相应的边加入到子图中,从而得到能够覆盖这一实体集的最小连通子图,并将位于该最小连通子图之外且与该最小连通子图直接相连的实体和边,构成与所述中文词集中的每条数据相对应的知识图谱子图。例如,对步骤二中样例,在得到如由表中实体和表中实体关系构成的最小联通子图后,向其中加入如表6和表7所示的扩展实体和关系,共同构成与所述中文词集中的每条数据相对应的知识图谱子图。
表6扩展实体
表7扩展关系
步骤六:根据步骤三得到的发音、词形、语义的相似度和编辑距离,得到中文词集中的每个中文词的易混词集合。其过程如下:
(1)步骤二中得到的中文词集中任意两词,利用步骤三中得到的发音相似度、词形相似度、语义相似度和编辑距离,计算其加权平均值,作为这两词的平均相似度;
(2)针对步骤二中得到的中文词集中的每个词,按平均相似度进行排序,截取其中平均相似度大于预设阈值的词集合,作为该词的易混词集合;
步骤七:构建基于深度学习的多输入多输出的中文易混词生成模型,利用步骤二得到的中文词集,以及步骤五得到的每条数据对应的知识图谱的子图作为输入,以步骤六得到的每个中文词的易混词集合作为标签,训练基于深度学习的多输入多输出的中文易混词生成模型,如图4所示。该模型具有如下特征:
(1)该模型以步骤二得到的序列形式的中文词集和步骤五得到的具有图结构的知识图谱子集作为输入,以步骤六得到的每个中文词的易混词集合作为输出标签;
(2)该模型是一种包括两个编码器、一个信息融合模块和一个解码器的深度学习模型;
(3)该模型中两个编码器包括序列编码器和图编码器,其中序列编码器将步骤二得到的中文词集映射到隐状态空间A,图编码器将知识图谱子集映射到隐状态空间B;
(4)该模型中的信息融合模块,将隐状态空间A和B进行拼接、空间变换、卷积和池化操作,得到融合后的信息向量;
(5)该模型中的解码器将信息融合模块输出的信息向量,经过全连接神经网络和softmax操作后,得到输入中文词序列中每个词所对应的易混词集合。
中文易混词生成模型参数训练过程包括如下步骤:
针对每组输入数据,其中包括步骤二得到的序列形式的中文词集和步骤五得到的具有图结构的知识图谱子集,对步骤七中模型的输出和步骤六中得到的期望数据进行对比,计算交叉熵,并对输入数据集中所有数据对应的交叉熵求平均值,并通过更新模型参数,最小化该平均交叉熵。
为扩充训练数据,针对每组输入和输出,在输出中的易混词集合中进行随机采样,生成其子集,并将原输入与该子集,作为新的训练样本,加到训练数据中。
步骤八:接收用户输入,并进行和步骤二相同的清洗和特征提取预处理操作;
步骤九:根据步骤八得到的结果,以及步骤四生成的知识图谱,生成所述知识图谱的子图;
步骤十:将步骤八得到的结果和步骤九生成的知识图谱的子图输入训练后的中文易混词生成模型,得到用户输入中各中文词所对应的中文易混词集合。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 一种基于知识图谱的中文课程教案生成方法
- 一种基于知识图谱和疑问词驱动的问题生成系统