一种边界感知的目标跟踪模型及目标跟踪方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于信息技术领域,具体涉及一种可形变Transformer的边界感知的目标跟踪模型及基于该模型的目标跟踪方法。
背景技术
目标跟踪在计算机视觉领域发挥着重要的作用。目标追踪技术能被广泛的应用于视频监控、智能交通、人机交互、无人机等领域。将目标跟踪技术应用到视频监控中,能够更好的检测并跟踪异常事件,有效地降低或避免异常行为的发生。这样能够让视频监控更加智能且具有更高的实效性,对社会安防和工业生产均具有深远的意义。将目标跟踪应用到无人机中,可以让无人机具有脱离人工操作从而实现自动跟踪、定位处理事件的能力。机器人要与人进行交互,首先要知道人在哪里并且能够跟踪人出现的位置,从而实现更高的智能应用。这些智能技术对于公共安全、国防、航空航天等领域都有深远的意义。通过众多科研工作者多年不懈的研究,目前已经有许多优秀的目标跟踪算法相继被提出。近年来,随着视频获取设备的发展和视频网络传输的日益成熟,视频中目标跟踪技术越来越受到人们的关注。不论是全球各大高校实验室和研究院所,还是各大公司,视频目标跟踪被均被列为一个重点的研究方向。
现有目标跟踪方法主要是基于滑动窗口的跟踪器,其主要是通过预先在生成的特征图生成候选点,然后通过在特征图上不断地滑动窗口来找到合适的跟踪目标框。这一方法在跟踪领域展现了优越的性能和计算效率,因此引起了广泛的关注。但是基于滑动窗口的跟踪器包含以下问题:
首先,由于卷积网络的局部感受野,采用候选点对应的特征来判断目标的候选位置较为局限。基于滑动窗口的跟踪器忽略了跟踪目标的边界内容的有效探索,这样预测出的目标候选框并不精准。滑动窗口跟踪器首先利用孪生网络提取模板和搜索图像的主干特征,然后采用相关操作得到跟踪目标的特征响应图。基于上述方法预测的特征响应图的每一像素位置,滑动窗口跟踪器产生大量的候选点,然后选用分类和回归网络来预测出目标的跟踪框。最近比较常见的跟踪器像SiamRPN++和SiamFC++首先利用分类网络预测出目标的候选位置,然后选用回归网络来精调目标的预测框。但是这些方法在计算过程中,是以相关响应图的每一网格点特征作为输入,而这些特征中通常包含一部分背景信息,这样将会影响模型的性能。同时这些方法忽略了跟踪目标的边界信息的有效探索。
其次,滑动窗口跟踪器由于忽略了在线更新网络权重的机制,使得其性能略低于基于在线学习的跟踪器。这些跟踪器在大规模图片对上端对端的离线训练。而在目标跟踪中,由于视角改变,光照变化,快速运动等挑战因素的存在,目标的形状在视频序列中的每一帧都会发生改变。传统基于滑动窗口的跟踪器由于缺乏在线学习机制很容易漂移到干扰物位置。
发明内容
针对现有基于滑动窗口的跟踪器忽略了目标的边界特征提取,本发明提供一种边界感知网络,该网络可以更加关注目标的边界特征,这样基于滑动窗口的跟踪器可以更精准地预测出目标的边界框。此外本发明提供了一种可形变Transformer模型,该模型用来增强现有滑动窗口跟踪器的模板特征和测试图像特征。为了提升整个跟踪器的鲁棒性,一种在线学习机制被引入分类分支中用来增强滑动窗口跟踪器分类得分。
本发明提出了一种边界感知的目标跟踪模型,包括主干特征提取网络、基于可形变Transformer的判别式模型和跟踪头网络;其中,主干特征提取网络有两个,第一主干特征提取网络以模板集为输入,提取所述模板集的主干特征后,一路输出到所述判别式模型,另一路输出到所述跟踪头网络的PrRoI Pooling组件;第二主干特征提取网络以搜索集为输入,提取所述搜索集的主干特征后,一路输入到所述跟踪头网络,另一路输入到所述判别式模型;所述模板集和搜索集是对目标进行跟踪的图像集合;所述判别式模型采用在线学习方式进行训练,包括编码器、解码器及判别式滤波器,所述编码器用于增强所述模板集的主干特征和跟踪目标的特征响应,所述解码器以所述编码器的输出和所述搜索集的主干特征为输入,以增强后的特征为输出,传输目标的位置信息,所述解码器的输出分成两路,一路输入到所述判别式滤波器,以在线学习方式训练以确定所述判别式滤波器的权重,将所述权重作为卷积核,与所述解码器的另一路输出进行卷积,得到跟踪目标的响应图,响应图高的位置代表潜在的跟踪目标位置;所述跟踪头网络采用离线学习方式进行训练,包括分类分支和回归分支,所述分类分支用来计算边界感知的分类预测,所述回归分支用来预测边界感知的回归预测;所述在线学习和离线学习的框架都制定在统一的多任务学习框架下进行。
进一步的,所述主干特征提取网络采用深度残差网络ResNet-50实现,将所述第一深度残差网络ResNet-50的Conv-3和Conv-4的输出作为所述模板集的主干特征,将所述第二深度残差网络ResNet-50的Conv-3和Conv-4的输出作为所述搜索集的主干特征。
进一步的,在所述基于可形变Transformer的判别式模型中,所述模板集的主干特征经过卷积网络生成查询特征以及卷积特征;然后,所述查询特征经过线性映射层生成目标的相对偏移量和,所述卷积特征经过线性映射与和相结合生成目标的可形变输出。
进一步的,在所述跟踪头网络中引入了特定任务的交互式头网络,以增强分类任务和回归任务的交互。
进一步的,在所述分类分支和回归分支引入了一个BorderAlign组件,用来自适应地从搜索图像中区分出目标的边界信息。
另一方面,本发明提出了一种边界感知的目标跟踪方法,基于上述边界感知的目标跟踪模型,实现目标候选框的精确预测,包括:构建训练数据集;基于所述数据集,训练所述基于可形变Transformer的判别式模型,得到目标的在线学习得分;基于所述数据集,训练所述目标跟踪模型的分类分支,得到目标的分类得分;基于所述数据集,训练所述目标跟踪模型的回归分支,得到目标的回归得分;将所述判别式模型计算的在线学习得分和所述分类得分进行融合,得到最终的分类得分;将所述回归得分用来预测目标的回归偏移,得到最终的跟踪框。
进一步的,所述训练所述基于可形变Transformer的判别式模型,得到目标的在线学习得分,包括:采用零填充操作使得在线学习得分图与分类得分图有着相同的维度大小,将学习的在线学习得分与跟踪头网络的分类得分相融合。
进一步的,所述训练所述基于可形变Transformer的判别式模型,得到目标的在线学习得分,包括:将构建好的训练数据输入给主干特征提取网络得到输入图像的主干特征;所述主干特征提取网络采用ResNet-50,所述主干特征是所述ResNet-50的Conv_3和Conv_4的输出;将所述主干特征输入给卷积网络得到卷积特征;对所述卷积特征进行数据增强,包括翻转,旋转、裁剪、缩放,得到增强后的卷积特征;将数据增强后的卷积特征输入给可形变Transformer模型,再输入给判别式滤波器,以训练判别式滤波器的权重;通过选用判别性学习损失,并利用迭代优化求解的方式,获得目标位置;将训练好的滤波器的权重作为卷积核与搜索特征进行卷积得到特定跟踪目标的得分响应图;将得分响应图采用零填充操作得到目标的在线学习得分。
进一步的,所述训练所述目标跟踪模型的分类分支,得到目标的分类得分,包括:将构建好的训练数据输入给主干特征提取网络得到输入图像的主干特征;所述主干特征提取网络采用ResNet-50,所述主干特征是所述ResNet-50的Conv_3和Conv_4的输出;将提取的主干特征输入给PrRoI Pooling提取目标的池化特征;将提取的主干特征输入给卷积网络得到卷积特征;通过将目标的池化特征与卷积特征进行element-wise相乘得到相关特征;将提取的相关特征输入给边界感知网络得到目标的分类得分。
进一步的,所述训练所述目标跟踪模型的回归分支,得到目标的回归得分,包括:将构建好的训练数据输入给主干特征提取网络得到输入图像的主干特征;所述主干特征提取网络采用ResNet-50,所述主干特征是所述ResNet-50的Conv_3和Conv_4的输出;将提取的主干特征输入给PrRoI Pooling提取目标的池化特征;将提取的主干特征输入给卷积网络得到卷积特征;通过将目标的池化特征与卷积特征进行element-wise相乘得到相关特征;将提取的相关特征输入给边界感知网络得到目标的边界感知回归得分;所述回归分支融入了BorderAlign,以精调预测的目标位置,从而得到精确的目标框。
本发明针对滑动窗口跟踪器,提出了一种改进的跟踪方法,提出的方法可以实时地对输入视频的特定目标进行跟踪,从而获得精确的候选框。该模型无需依靠数据增广等技术即可实现对类别不平衡数据的充分训练并取得较为准确的目标跟踪效果。本发明可嵌入到摄像头中实现,或将模型加载到GPU服务器通过网络请求使用。
附图说明
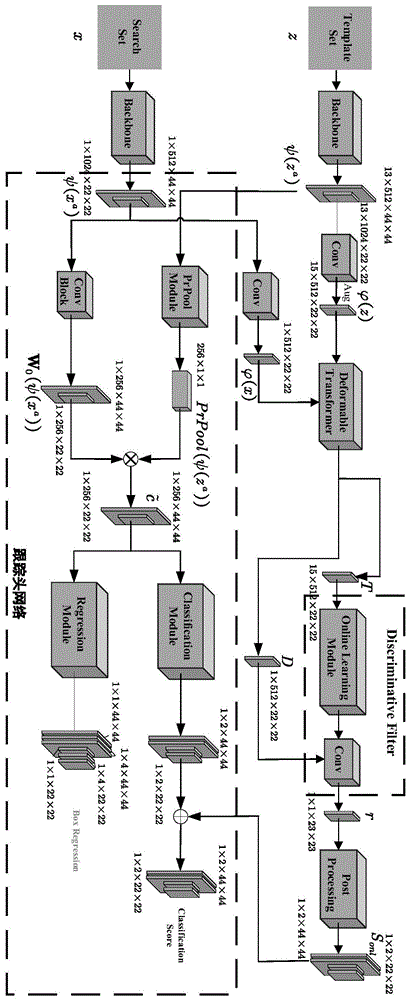
图1是本发明边界感知的目标跟踪模型框图。
图2是本发明可形变Transformer编码器模型框图。
图3是本发明训练判别式模型的流程图。
图4是本发明训练跟踪器的分类分支的流程图。
图5是本发明训练跟踪器回归分支的流程图。
具体实施方式
附图1所示是本发明边界感知的目标跟踪模型框图,在提出的跟踪框架中,其主要包括两个部分:(1)基于Transformer的判别式模型框架,采用在线学习方式进行训练。(2)由分类分支和回归分支组成的跟踪头网络,采用离线学习方式进行训练。特别地,跟踪头网络引入了特定任务的交互式模块来增强分类任务和回归任务的交互。同时,在分类分支和回归分支引入了一个BorderAlign组件,用来探索目标的边界特征。同时,提出的在线学习和离线学习框架都制定在统一多任务学习框架下进行。
如图1所示,模板集和搜索集输入给主干特征提取网络,这里采用ResNet-50作为特征提取器。本发明使用的主干特征提取网络结构及参数如表1所示。
表1本发明使用的主干特征提取网络结构及参数
深度残差网络由许多残差模块组成,解决了深度模型退化问题。输入图像的分辨率较高,本发明采用resize操作将其裁剪为352*352大小。使用深度残差网络作为主干特征提取网络对裁剪后的图像抽取特征,抽取后的特征维度为22*22和44*44。这里将ResNet-50的Conv-3和Conv-4的输出作为主干特征。整个主干特征提取网络采用目标检测、跟踪数据集作为训练数据,在测试过程中,学习得到的主干特征提取网络权重保持固定。提取的输入图像主干特征分别输入到判别式模型和跟踪头网络中。
在判别式模型中,提取的主干特征首先输入给卷积网络,用来将主干特征的通道数由1024减少到512。减少通道的卷积特征然后输入给可形变Transformer来探索目标的丰富时序信息。该操作具体包括:首先将模板集的卷积特征输入给Transformer编码器用来增强跟踪目标的特征响应,而Transformer编码器的输出和搜索集图像的主干特征输入给Transformer解码器,以此来传输目标的位置信息,从而简化了目标的搜索过程。然后Transformer解码器的输出特征输入给判别式滤波器,用来学习判别式滤波器的权重。学习得到的判别式滤波器权重被选作卷积核,将其与解码器的输出特征进行卷积得到跟踪目标的响应图,而响应图高的位置代表潜在的跟踪目标位置。为了将学习的在线学习得分与跟踪头网络的分类得分相融合,采用了零填充操作使得在线学习得分图与分类得分图有着相同的维度大小。
在跟踪头网络中,提取的主干特征首先输入到PrRoI Pooling组件中,用来生成包含特定目标内容的调制向量,另一分支的搜索集图像的主干特征输入给卷积网络得到卷积特征。随后将卷积特征和池化特征进行卷积得到目标的调制向量。这一调制向量即为目标的相关特征,包含了特定目标的跟踪内容。计算的相关特征然后输入给分类分支和回归分支:其中,分类分支用来计算边界感知的分类预测,回归分支用来计算边界感知的回归预测。一种边界对齐网络被引入在分类和回归预测中。该引入的边界对齐网络包含BorderAlign操作,其用来提取目标的边界特征,以此自适应地从搜索图像中区分出目标的边界信息。在边界感知的分类预测中,分类分支中不包含边界感知模块的部分用来预测粗略分类得分,分类分支中包含边界感知模块的部分用来预测边界感知的分类得分。然后将判别式模型计算的在线学习得分和分类得分进行融合得到最终的预测得分。在边界感知的回归预测中,回归分支中不包含边界感知网络模块用来预测粗略的回归偏移,回归分支中包含边界感知网络模块用来预测边界感知的回归偏移。最后,将粗略的回归预测和边界感知的回归预测相结合来得到最终的跟踪框。
为了优化提出的跟踪模型,本发明采用多任务损失在大规模训练数据集上进行训练。通过将上述计算的分类和回归预测采用下式进行优化:
其中,
其中为超参数,(1)式中的
其中,为超参数,(1)式中的而
其中a为超参数,(1)式中的
其中
/>
(1)式中的
请参阅图2,为本发明可形变Transformer编码器模型框图:
模板集的主干特征
其中k为关键采样点位;K为总采样点数;W
T=Reshape(Lay.Norm(Linear(d)+z
其中T表示Transformer编码器输出;Lay.Norm表示layer normalization;Linear表示线性映射;值得注意的是,在整个Transformer编码器中,整个输出特征T与原始的输入特征
图3为本发明训练判别式模型的实施例流程图,包括:
1):构建训练数据集。
2):将构建好的训练数据输入给主干特征提取网络得到输入图像的主干特征。本发明采用ResNet-50作为主干特征提取网络,并将其Conv_3和Conv_4的输出作为输入图像特征。
3):将提取的输入图像特征输入给卷积网络得到卷积特征。
4):对卷积特征进行数据增强。具体包括翻转,旋转、裁剪、缩放、以此得到10组数据增强后的卷积特征。
5):将数据增强后的卷积特征输入给可形变Transformer模型,该Transformer模型中的编码器通过注意力模型增强模板特征,这有利于高质量跟踪模型的学习,同时解码器将跟踪信息从先前的模板传播到当前帧,从而简化了目标搜索过程。
6):将经过Transformer增强后的特征输入给判别式滤波器,以此来训练判别式滤波器的权重。判别式滤波器是一种端到端的跟踪结构,可以充分利用目标和背景信息进行目标预测,通过选用判别性学习损失,并利用迭代优化求解的方式,可以获得目标位置。将训练好的滤波器的权重作为卷积核与搜索特征进行卷积得到特定跟踪目标的得分响应图。
7):将得分响应图采用零填充操作得到目标的在线学习得分。
图4为本发明训练目标跟踪模型的分类分支的流程图,包括:
1):构建训练数据集。
2):将构建好的训练数据输入给主干特征提取网络得到输入图像的主干特征。本发明采用ResNet-50作为主干特征提取网络,并将其Conv_3和Conv_4的输出作为主干特征。
3):将提取的主干特征输入给PrRoI Pooling提取目标的池化特征。PrRoIPooling不涉及任何量化取整操作,解决了RoI Align中插值像素点数目N的问题。另一方面,将提取的主干特征输入给卷积网络得到卷积特征。最后通过将目标的池化特征与卷积特征进行element-wise相乘得到相关特征。
4):将提取的相关特征输入给边界感知网络得到目标的分类得分。该边界感知网络引入BorderAlign操作,显式地提取目标边界极限点的特征,高效且不会引入很多冗余的背景信息。
图5为本发明训练跟踪器回归分支的流程图,包括:
1):构建训练数据集。
2):将构建好的训练数据输入给主干特征提取网络得到输入图像特征。本发明采用ResNet-50作为主干特征提取网络,并将其Conv_3和Conv_4的输出作为主干特征。
3):将提取的主干特征输入给PrRoI Pooling提取目标的池化特征。PrRoIPooling不涉及任何量化取整操作,解决了RoI Align中插值像素点数目N的问题。另一方面,将提取的主干特征输入给卷积网络得到卷积特征。最后通过将池化特征与卷积特征进行element-wise相乘得到相关特征。
4)将提取的相关特征输入给边界感知网络得到目标的边界感知回归得分。该回归分支融入了BorderAlign,以此精调预测的目标位置,从而得到精确的目标框。
- 基于边界框回归模型的目标跟踪方法
- 基于边界框回归模型的目标跟踪方法