一种基于加权得分标签分配的小目标检测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及计算机视觉技术领域,尤其是涉及一种基于加权得分标签分配的小目标检测方法。
背景技术
近年来,随着计算机性能的提升和大数据的发展,视觉信息数据迅猛增多,包括静态图像、动态图像、视频文件、音频文件等多媒体数据都以很快的速度在各种社交媒体上传播。目标检测作为计算机视觉领域最基本的问题之一,被广泛应用于目标跟踪、行为理解、人机交互、人脸识别等诸多领域,在21世纪初就吸引众多学者的广泛关注和研究。人类主要是通过视觉接收外界信息,所以基于视觉信息的应用技术将是人工智能的一个前瞻性研究点。其中,人脸识别、视频监控、目标检测、互联网图像内容审查、生物特征识别等技术都成为当今的研究热点。这些技术也被广泛应用于医疗、养老、交通、城市运行、安防等领域,例如:医学图像诊断、姿态估计、车站安检、自动驾驶、车速检测、视频监控行为分析等。
小目标检测是计算机视觉和机器学习中极其重要的一个研究领域,融合图像处理、模式识别、人工智能、自动控制等多个领域的前沿知识。图像中的小目标通常只占据少量的像素,小目标检测任务要求算法尽可能准确快速地对这些微小的目标进行定位和分类。随着智能设备和智慧城市的发展,人们能够使用更多的硬件设施如无人车、无人机等对周围环境进行感知,小目标检测也开始广泛应用于上述领域,如在自动驾驶中对交通标识的检测、在遥感图像中进行车辆或重要设施的检测、在灾难救援中对受困人员检测帮助发现潜在的求救者等。
当下目标检测技术越来越趋近于成熟,通用的目标检测器也被广泛应用于日常生活、城市管理、工业制造等各个现实场景中。然而,大部分检测器在针对微小目标的检测任务上依然无法达到令人满意的效果。在真实的应用场景下,通用的检测器想要拥有对各个尺度目标尤其是对小目标的检测能力,依然是一个具有挑战性的问题。因此,小目标检测任务最近引起越来越多的关注。
现有的基于深度学习的小目标检测方法性能远远优于早期基于特征提取的方法,通过卷积神经网络(CNN)对图像进行特征提取,并送入检测头中进行分类和回归,可以更精准地检测出其中的小目标。尽管基于深度学习的方法在检测性能上取得了巨大的突破,但由于小目标特征上的局限性,依然存在三个主要的具有挑战性的问题。首先,特征提取往往需要经过一系列的下采样过程,图像的空间分辨率在这一过程中不断下降,从而不可避免地丢失一部分图像的信息。这种信息丢失对于尺寸微小的目标来说是致命的,因为这意味着小目标仅有的一小部分特征很可能在下采样过程中丢失了,之后检测头便无法检测到这些小目标。其次,小目标的分辨率通常较低,当图像质量较差的时候,物体非常模糊,很容易受到背景或噪声的干扰,这进一步加剧小目标特征提取的难度。最后,目标检测回归物体的通用范式基于检测框与目标之间的IoU,对于尺寸很小的目标来说,与他们匹配的检测框的轻微扰动会造成IoU值的巨大变化,这在很大程度上限制了网络对小目标的学习。
为了解决上述问题,有许多针对小目标检测的方法被提出。根据不同方法的策略,可以分为基于数据增强的方法、基于尺度感知的方法、基于特征融合的方法、基于超分辨率的方法、基于上下文信息建模的方法以及其他方法。尽管这些方法从不同的角度提升了小目标检测的性能,但它们通常都需要大量复杂的操作,造成额外的计算成本,并且有的方法很难以端到端的方式进行设计,难以满足现实场景的需要,甚至有的方法过于关注小目标,反而阻碍了对较大物体的检测能力。
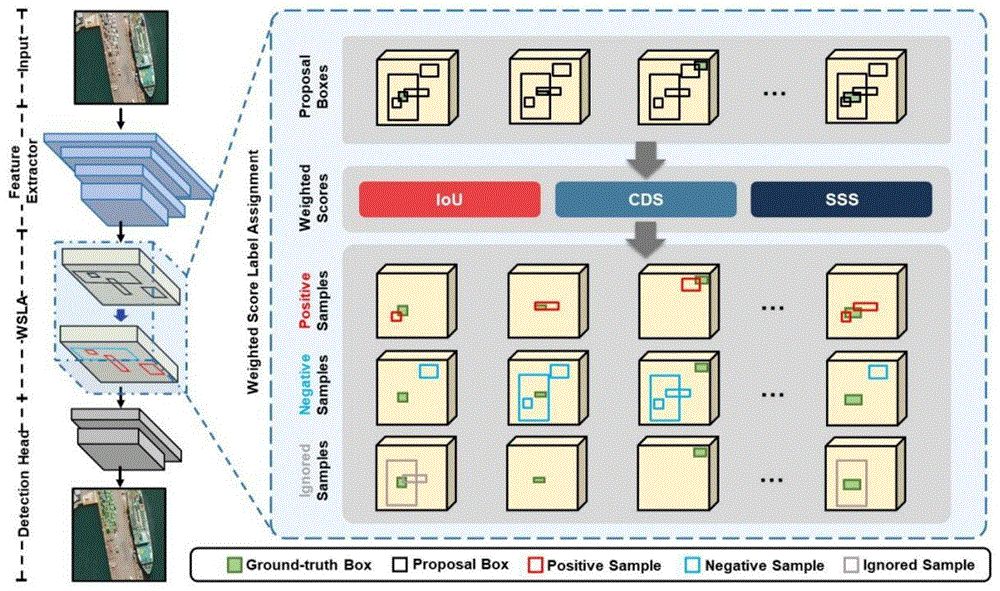
最近有许多工作注意到标签分配对检测器性能的影响,一些针对小目标的标签分配方案被提出。Ming等人(Qi Ming,Zhiqiang Zhou,Lingjuan Miao,Hongwei Zhang,andLinhao Li.2021.Dynamic anchor learrningforarbitrary-oriented objectdetection.In Proceedingsof the AAAI Conference on Artificial Intelligence,Vol.35.2355-2363.)采用一种动态学习的方式,使用样本框回归的后验信息帮助进行标签分配,有效提升了检测器的精度。Xu等人(Chang Xu,Jinwang Wang,Wen Yang,Huai Yu,LeiYu,and Gui-Song Xia.2022.RFLA:Gaussian receptive field based label assignmentfor tiny object detection.In Proceedings of the European Conference onComputer Vision.Springer,526-543.)提出一种基于高斯感受野的标签分配策略,对小目标检测任务具有启发意义。由于标签分配是目标检测算法的一部分,更改分配策略是一种对所有检测范式通用的改进方案,并且几乎不会引入额外的计算量。标签分配对粗糙的先验进行评分,这个分数作为他们是否能成为正样本的依据与设定的阈值进行比较,评分高于正样本阈值的先验被分为正样本,低于负样本阈值的则被分为负样本。正负样本的选择对于模型的训练至关重要,为模型提供足够的小目标样本有利于提高小目标检测性能。然而,如图1所示,发现原有的标签分配几乎都是基于IoU得分的策略,而IoU得分在很多情况下偏向于大目标。当目标具有一定大小的尺寸时,与他们匹配的样本框的IoU通常较大,而小目标则很难拥有一个相对较大的IoU,这导致标签分配过程中正样本几乎都对应中等或大尺寸的目标,图1中使用IoU方式进行标签分配的正样本也全部集中在较大尺寸的目标上,使用这些样本进行训练的模型相应地缺乏对小目标的检测能力,导致小目标检测性能的下降。
发明内容
本发明的目的在于提供一种基于加权得分标签分配的小目标检测方法,加权得分有效缓解IoU得分对小目标不公平的问题,一方面提高训练样本的尺度多样性,另一方面兼顾训练样本的质量,提升模型的检测性能。
本发明提供一种基于加权得分标签分配的小目标检测方法,包括如下步骤:
步骤1,对待检测的图片进行预处理,将预处理后待检测的图片及其对应的图片级别的标签送入神经网络;
步骤2,神经网络对图片进行特征提取和特征融合,根据特征筛选样本框;
步骤3,采用基于加权得分的标签分配方式WSLA为样本框分配正标签和负标签;
步骤4,模型根据WSLA分配的正负样本进行训练,在训练过程中输出待检测图片对应每一个类别的概率数值,在测试过程中输出待检测图片预测的框的坐标、类别、得分。
在步骤1中,所述预处理,可先对图片进行标准化处理,再把图片缩放为256×256大小,最后随机裁剪为224×224大小。
在步骤2中,所述特征提取使用主干特征提取网络(ResNet50、ResNet101)完成,所述特征融合使用特征金字塔网络(FPN)完成;
在步骤3中,所述基于加权得分的标签分配方式WSLA包括如下步骤:
步骤a1,对每一个样本框,根据下面的公式计算它与所有真实框的IoU得分(Intersection overUnion):
其中,A表示样本框所占的区域,B是一个维度与真实框数目相等的向量,向量中的每个元素代表对应的真实框所占的区域;
步骤a2,对每一个样本框,根据下面的公式计算它与所有真实框的中心距离得分(Center Distance Score,CDS):
d=||(x
其中,(x
步骤a3,对每一个样本框,根据下面的公式计算它与所有真实框的形状尺寸得分(Shape Size Score,SSS):
其中,(w
步骤a4,对每一个样本框得到的IoU得分(S
w=1+α+β
其中,α和β都是超参数,S={S
步骤a5,根据预先设定好的正负样本阈值,与加权得分S进行比较。若S
在步骤4中,所述训练方法与选用的检测器一致,但用于训练的样本是经过步骤3的WSLA分配后的样本。
与现有技术相比,本发明具有以下突出优点:
1、本发明发现通用的IoU得分会倾向于为大尺寸目标分配正样本,并针对这一问题提出了一种简单有效的基于加权得分的标签分配方式(WSLA),有效提升训练样本的尺寸多样性,并提高样本的质量。
2、本发明设计中心距离得分(CDS)和形状尺寸得分(SSS),这两个得分从不同角度评价了样本框的好坏,并且对各种尺度的目标都是公平的。
3、在DOTA和HRSC2016数据集上进行的广泛实验表明,与其他竞争性方法相比,本发明提出的WSLA实现了显著和一致的性能改进。
附图说明
图1是本发明神经网络的网络结构示意图。
图2是本发明的流程示意图。
具体实施方式
以下实施例将结合附图,对本发明的技术方案及有益效果进行详细说明。
一种基于加权得分标签分配的小目标检测方法,合理地提高训练样本中小目标正样本的数目从而提高对小目标的检测性能。包括模型训练阶段和模型测试阶段:
模型训练阶段:步骤1,首先对待检测的图片进行预处理,然后将预处理后待检测的图片及其对应的类别送入神经网络;步骤2,神经网络对图片进行特征提取和特征融合,根据特征筛选样本框,并将样本框送入加权得分标签分配模块中;步骤3,加权得分标签分配为样本框根据加权得分分配正标签和负标签;步骤4,模型根据标签分配的正负样本进行训练,在训练过程中输出待图片中检测目标对应每一个类别的概率数值。
模型测试阶段:在测试过程中输出待检测图片预测的框的坐标、类别、得分。标签分配过程发生在模型训练之前,算法根据样本框的得分为训练样本分配正负标签。加权得分在原有的IoU分数的基础上引入了两个完全解耦的得分:中心距离得分用于衡量样本框与真实框在位置上的相近程度,形状尺寸得分用于衡量样本框与真实框在形状上和尺寸上的相似程度。通过对这三个得分的加权,可以有效缓解IoU得分对大物体的倾斜问题,使模型更好地检测到小目标,同时也保证样本框的质量。在DOTA和HRSC2016数据集上实验,本发明实现显著和一致的性能改进。
本发明设计的加权得分在原有的IoU分数的基础上引入两个完全解耦的得分:IoU得分即一般标签分配中通用的得分,通过计算样本框与真实框重叠部分的面积占总面积的比例,对两个框的相近程度进行定量评价;CDS得分以两个框之间的中心距离作为评价指标,明确地为目标与检测框的远近程度进行打分,并且这个分数与物体大小无关,是一个对不同尺度都公平的指标;SSS得分从框的宽高进行评价,是一个与CDS完全解耦的得分,它一方面考虑了形状是否相近的问题,另一方面也对正样本的尺寸进行了约束。WSLA对这三个得分赋予不同的权重,从而缓解IoU得分在尺寸上的不公平问题,提高与小目标匹配的正样本数量,同时保证这些框的质量。
如图2所示,本发明主要包含四个部分:输入、特征提取、WSLA标签分配、检测头。
本发明实施例具体包括如下步骤:
步骤1,在输入部分,将预处理后待检测的图片及其对应的候选框送入神经网络;在图片的预处理中,先对图片进行标准化处理,再把图片缩放为256×256大小,最后随机裁剪为224×224大小。
步骤2,在特征提取部分,图片被送入主干特征提取网络(ResNet50、ResNet101)进行特征提取,再经过特征金字塔网络(FPN)进行特征融合,根据特征筛选样本框,并将样本框送入WSLA中;
步骤3,在WSLA标签分配部分,所述WSLA包括如下步骤:
步骤a1,对每一个样本框,根据下面的公式计算它与所有真实框的IoU得分(Intersection overUnion):
其中,A表示样本框所占的区域,B是一个维度与真实框数目相等的向量,向量中的每个元素代表对应的真实框所占的区域;
步骤a2,对每一个样本框,根据下面的公式计算它与所有真实框的中心距离得分(CenterDistance Score,CDS):
d=||(x
其中,(x
步骤a3,对每一个样本框,根据下面的公式计算它与所有真实框的形状尺寸得分(Shape Size Score,SSS):
其中,(w
步骤a4,对每一个样本框得到的IoU得分(S
w=1+α+β
其中,α和β都是超参数,S={S
步骤a5,根据预先设定好的正负样本阈值,与加权得分S进行比较。若S
步骤4,在检测头部分,模型根据正负样本进行训练,在训练过程中输出待检测图片对应每一个类别的概率数值,在测试过程中输出待检测图片预测的框的坐标、类别、得分;
本发明的效果通过以下仿真实验作进一步的说明。
1)仿真条件:本发明在Ubuntu平台上进行开发,开发的深度学习框架基于Pytorch。本发明中主要用的语言为Python。
2)仿真内容:
取遥感图像领域常用的两个小目标数据集,DOTA以及HRSC2016,根据以上的步骤训练网络并且使用测试集进行测试。表1和表2分别为本发明和其他方法在两个数据集的检测结果,可以发现本发明一致地提升基线算法的性能,并且相比于其他的方法,本发明取得最优的结果。其中Oriented R-CNNw/WSLA是本发明的结果,PL、BD、BR等表示算法对飞机、棒球场、桥梁等DOTA数据集中15种不同检测目标的检测性能,评价指标mAP
表1在DOTA数据集上与最新的技术方法进行比较
表2在HRSC2016数据集上与最新的技术方法进行比较
在DOTA和HRSC2016数据集上进行的广泛实验表明,与其他竞争性方法相比,提出的WSLA不仅使得基线方法实现了显著和一致的性能改进,并且取得了最好的检测结果。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
参考文献:
[1]Zhiming Chen,Kean Chen,WeiyaoLin,John See,HuiYu,YanKe,andCongYang.2020.Piouloss:Towardsaccurateoriented object detection incomplexenvironments.In Proceedings of the European Conference on ComputerVision.Springer,195-211.
[2]Jian Ding,Nan Xue,Yang Long,Gui-Song Xia,and QikaiLu.2019.Learning roitransformer for oriented object detection in aerialimages.In Proceedings of theIEEE/CVF Conference on Computer Vision andPattern Recognition.2849-2858.
[3]Zonghao Guo,Chang Liu,Xiaosong Zhang,Jianbin Jiao,Xiangyang Ji,andQixiang Ye.2021.Beyond bounding-box:Convex-hull feature adaptationfororiented and densely packed object detection.In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.8792-8801.
[4]Jiaming Han,Jian Ding,Jie Li,and Gui-Song Xia.2021.Align deepfeatures fororiented object detection.IEEE Transactions on Geoscience andRemote Sensing 60(2021),1-11.
[5]Jiaming Han,Jian Ding,Nan Xue,and Gui-Song Xia.2021.Redet:Arotation-equivariant detector for aerial object detection.In Proceedings ofthe IEEE/CVFConference on Computer Vision and Pattern Recognition.2786-2795.
[6]Yingying Jiang,Xiangyu Zhu,Xiaobing Wang,Shuli Yang,Wei Li,HuaWang,Pei Fu,and Zhenbo Luo.2017.R2CNN:Rotatioual region CNN fororientationrobust scene text detection.arXiv preprint arXiv:1706.09579(2017).
[7]Chengzheng Li,Chunyan Xu,Zhen Cui,Dan Wang,Tong Zhang,and JianYang.2019.Feature-attentioned obj ect detection in remote sensing imagery.In2019IEEE internatioual conference on image processing(ICIP).IEEE,3886-3890.
[8]Wentong Li,Yijie Chen,Kaixuan Hu,and Jianke Zhu.2022.Orientedreppointsfor aerial object detection.In Proceedings of the IEEE/CVFConference on ComputerVision and Pattern Recognition.1829-1838.
[9]Minghui Liao,Zhen Zhu,Baoguang Shi,Gui-song Xia,and XiangBai.2018.Rotation-sensitive regression for oriented scene text detection.InProceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition.5909-5918.
[10]Tsung-Yi Lin,Priya Goyal,Ross Girshick,Kaiming He,and Piotr Dollár.2017.Focal loss for dense object detection.In Proceedings of the IEEE/CVFInternatioualConference on Computer Vision.2980-2988.
[11]Qi Ming,Zhiqiang Zhou,Lingjuan Miao,Hongwei Zhang,and LinhaoLi.2021.Dynamic anchor leaming for arbitrary-oriented object detection.InProceedingsof the AAAI Conference on Artificial Intelligence,Vol.35.2355-2363.
[12]Xingjia Pan,Yuqiang Ren,Kekai Sheng,Weiming Dong,Haolei Yuan,XiaoweiGuo,Chongyang Ma,and Changsheng Xu.2020.Dynamic refinement networkfororiented and densely packed object detection.In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.11207-11216.
[13]Wen Qian,Xue Yang,Silong Peng,Junchi Yan,and YueGuo.2021.Learningmodulated loss for rotated object detection.In Proceedingsof the AAAI conferenceon artificial intelligence,Vol.35.2458-2466.
[14]Shaoqing Ren,Kaiming He,Ross Girshick,and Jian Sun.2015.Faster r-cnn:Towards real-time object detection with region proposal networks.Advancesinneuralinformation processing systems 28(2015).
[15]Jinwang Wang,Jian Ding,Haowen Guo,Wensheng Cheng,Ting Pan,andWenYang.201 9.Mask OBB:A semantic attention-based mask oriented boundingboxrepresentation for multi-category object detection in aerialimages.RemoteSensing 11,24(2019),2930.
[16]Haoran Wei,Yue Zhang,Zhonghan Chang,Hao Li,Hongqi Wang,and XianSun.2020.Oriented objects as pairs of middle lines.ISPRS Journal ofPhotogrammetryand Remote Sensing 169(2020),268-279.
[17]XingxingXie,Gong Cheng,Jiabao Wang,Xiwen Yao,and JunweiHan.2021.Oriented R-CNN for object detection.In Proceedings of the IEEE/CVFInternatioualConference on Computer Vision.3520-3529.
[18]Yongchao Xu,Mingtao Fu,Qimeng Wang,Yukang Wang,Kai Chen,Gui-SongXia,and Xiang Bai.2020.Gliding vertex on the horizontal bounding boxformulti-oriented object detection.IEEE transactioUs on pattern analysis andmachineintelligence 43,4(2020),1452-1459.
[19]Feng Yang,Wentong Li,Haiwei Hu,Wanyi Li,and Peng Wang.2020.Multi-scalefeature integrated attention-based rotation network for object detectionin VHRaerialimages.Sensors 20,6(2020),1686.
[20]Xue Yang,Liping Hou,Yue Zhou,Wentao Wang,and JunchiYan.2021.Denselabel encoding for boundary discontiuuity free rotationdetection.In Proceedingsof the IEEE/CVF Conference on Computer Vision andPattern Recognition.15819-15829.
[21]Xue Yang and Junchi Yan.2020.Arbitrary-oriented object detectionwith circularsmooth label.In Proceedings of the Europeau Conference onComputer Vision.Springer,677-694.
[22]Xue Yang,JunchiYan,ZimingFeng,andTaoHe.2021.R3det:Refined single-stagedetector with feature refinement for rotating object.In Proceedings ofthe AAAIconference on artificial intelligence,Vol.35.3163-3171.
[23]Xue Yang,Jirui Yang,Junchi Yan,Yue Zhang,Tengfei Zhang,Zhi Guo,Xian Sun,and Kun Fu.2019.Scrdet:Towards more robust detection for small,clutteredand rotated objects.InProceedings of the IEEE/CVF InternatioualConference onComputer Vision.8232-8241.
[24]Gongjie Zhang,Shijian Lu,and Wei Zhang.2019.CAD-Net:A context-awaredetection network for objects in remote sensing imagery.IEEETransactions onGeosciennce and Remote Sensing 57,12(2019),10015-10024.
[25]Xingyi Zhou,Dequan Wang,and Philipp
[26]Chang Xu,Jinwang Wang,Wen Yang,Huai Yu,Lei Yu,and Gui-SongXia.2022.RFLA:Gaussian receptive field based label assignment for tiny object detection。
- 一种基于加权截断核范数的红外弱小目标检测方法
- 一种基于加权块对比度的红外小目标检测方法
- 一种基于加权扩展特征金字塔的遥感图像小目标检测方法