一种源域可迁移性自适应学习的言语想象脑电解码方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明属于脑电信号处理技术领域,具体涉及一种源域可迁移性自适应学习的言语想象脑电解码方法。
背景技术
语言对话是一种高级认知行为,是人们进行沟通的主要表达方式。而言语想象指的是在思维中构建语言表达的过程,即通过内在的心理活动模拟、构想、或者回忆语言的使用,而非实际产生声音或文字。这种思维活动通常包括对语言元素的形成、组织和演绎。在大脑中,语言的处理涉及多个区域,包括布洛卡区(Broca's area)和颞上回(Temporalgyrus),这些区域在言语的产生和理解中起着重要作用。当个体进行言语想象时,大脑皮层会发生电活动,人类大脑皮层电活动产生的生理信号——脑电图(electroencephalography,EEG)为我们提供了言语想象脑电解码数据源。言语想象脑电解码是一个多学科融合研究领域,涉及计算机科学、心理学、神经学和脑认知科学等多个学科,旨在研究和开发能够识别、解释、处理和模拟人类言语想象的理论、方法和系统。言语想象脑电解码是言语想象脑电解码领域的一个新兴分支,其研究对象是人的脑电信号。不同于常见的输入信号包括视频、图片(肢体动作、面部表情等)、语音、文本等,人的脑电信号属于生理信号,不易伪装,因而基于脑电信号的言语想象脑电解码更能反应个体的真实言语想象任务类型。
如何在脑电图中获取关于个体内在言语想象的任务类型信息,是言语想象脑电解码研究的重要目标。在跨被试言语想象脑电解码领域中,个体差异性是不可避免的,一个人在不同状态、不同时间下的脑电信号以及人与人之间的脑电信号均存在分布差异,这就导致以独立同分布为假设的机器学习方法难以泛化。因此,迁移学习的概念被提出,其核心思想是降低源域和目标域之间的域差异,但常见的迁移学习方法如最大均值差异法、深度神经网络迁移等,无法直观的量化表示样本的可迁移性,对迁移学习中间过程的可解释性较为欠缺。
在迁移学习领域中,最大均值差异法是一个较为常见的方法,其将源域和目标域数据映射至共享子空间中以缩减两域差异,达到一个基本近似分布的状态。在图学习领域中,基于图的半监督学习方法一般通过样本间的相似性来构建图关联矩阵,其中样本相似性可以通过高斯核、欧几里德距离等方法度量。基于图的半监督标签传播可以理解为有限个带标签样本传播到大量无标签样本的过程。构造结构化二部图时需要将经过数据预处理和特征提取的脑电信号作为输入,二部图一侧为源域样本(有标签),另一侧为目标域样本(无标签),层内无连接,层间全连接。
发明内容
本发明的目的在于针对现有言语想象脑电解码方法技术普适性的不足,提供一种源域可迁移性自适应学习的言语想象脑电解码方法,本发明通过对双映射矩阵P=[P
一种源域可迁移性自适应学习的言语想象脑电解码方法,包括以下步骤:
步骤1、在不同言语想象任务下,采集一个或多名被试者的带标签的脑电数据,以及解码对象的无标签的脑电数据。
步骤2、对步骤1采集得到的脑电数据进行预处理和特征提取,得到源域样本矩阵X
步骤3、构建描述各源域样本可迁移性的样本权重系数矩阵Θ并将其引入双映射主动域适应模型;将双映射主动域适应模型和半监督标签传播模型联合至一个统一框架,得到言语想象脑电解码模型。
步骤4、根据步骤3中建立的目标函数,对言语想象脑电解码模型中的参数进行联合迭代优化,并得到优化后的目标域标签矩阵F
步骤5、根据步骤4得到的目标域标签矩阵F
作为优选,步骤3中所述的言语想象脑电解码模型的目标函数如下:
其中,X=[X
步骤4中对双映射矩阵P=[P
作为优选,步骤3中构建言语想象脑电解码模型的具体过程为:
步骤3.1、采用最大均值差异策略作为子空间中源域和目标域之间分布差异的度量准则,建立双映射主动域适应模型:
步骤3.2、建立基于结构化二部图的半监督标签传播模型:
步骤3.3、联合步骤3.1和步骤3.2构建的两个模型,得到言语想象脑电解码模型的目标函数。
作为优选,步骤4中联合迭代优化的具体过程为:
步骤4.1、使用欧几里得距离计算样本间相似性,初始化结构化二部图关联矩阵B;初始化目标域标签矩阵F
步骤4.2、更新双映射矩阵P=[P
求解式(3),得到更新后的映射矩阵P=[P
步骤4.3、更新样本权重系数矩阵Θ,固定双映射矩阵P=[P
求解式(4),得到更新后的样本权重系数矩阵Θ;
步骤4.4、更新结构化二部图关联矩阵S,固定双映射矩阵P=[P
求解式(5),得到更新后的结构化二部图关联矩阵S;
步骤4.5、更新目标域标签矩阵F
步骤4.6、更新重复交替进行步骤4.2、步骤4.3、步骤4.4及步骤4.5直至目标函数收敛,完成双映射矩阵P=[P
作为优选,在步骤4.2和步骤4.5中,通过拉格朗日函数求解源域映射矩阵P
作为优选,在步骤4.3中,先通过拉格朗日函数简化目标函数后通过按行求解的策略求解得到样本权重系数矩阵Θ。
作为优选,在步骤4.4中,通过按行求解的策略求解得到结构化二部图关联矩阵S。
作为优选,步骤2中预处理和特征提取的过程为:对以1024Hz记录的脑电数据进行采样,采样率为256Hz,然后通过1Hz~70Hz的五阶巴特沃斯带通滤波器滤除噪声以及与EMG活动相关的伪影,提取脑电信号在不同频段下的状态特征,计算脑电信号的微分熵作为样本矩阵。
第二方面,本发明提供一种计算机设备,其包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述存储器存储计算机程序;所述处理器执行前述的源域可迁移性自适应学习的言语想象脑电解码方法。
第三方面,本发明提供一种可读存储介质,其存储有计算机程序;所述计算机程序被处理器执行时用于实现前述的源域可迁移性自适应学习的言语想象脑电解码方法。
本发明具有以下有益效果:
1、本发明提出的基于源域可迁移性自适应学习的言语想象脑电解码方法不同于现有言语想象脑电解码方法只关注提高言语想象脑电解码的性能,本发明重视挖掘被试者脑电数据的可迁移性。本发明将描述各源域样本可迁移性的样本权重系数矩阵Θ引入双映射主动域适应模型,从而清晰地量化表示了源域样本的可迁移性,促使源域高可迁移性样本在模型学习过程中发挥更大的作用。
2、本发明提出的基于源域可迁移性自适应学习的言语想象脑电解码方法提供了一种具有高准确性和高可靠性的有效工具,通过建立数学模型不断迭代优化目标域样本的标签,能够根据脑电图数据准确地识别出解码对象的言语想象任务类型。
3、本发明针对脑电研究领域中较难的跨被试脑电解码问题,构造的双映射矩阵极大程度上减小了域间差异,促使在目标域的状态识别中应用到更丰富的源域知识。
附图说明
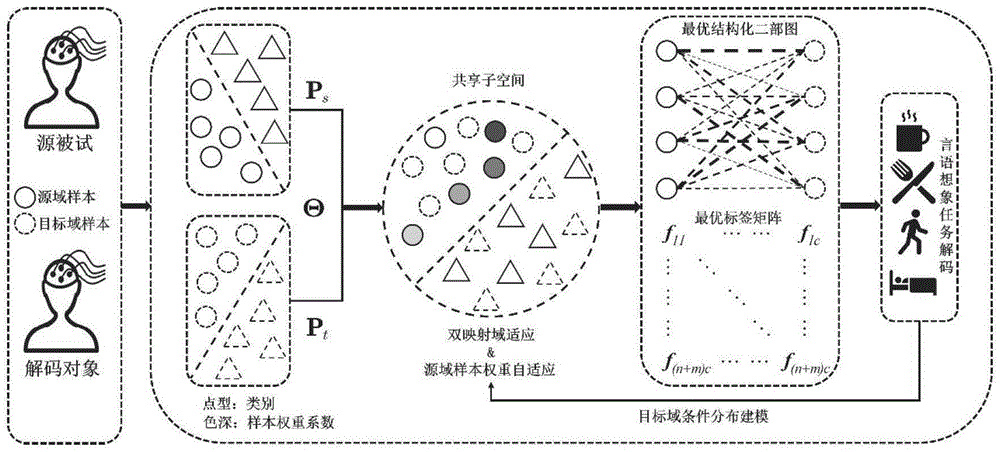
图1为一种源域可迁移性自适应学习的言语想象脑电解码方法的框架图。
图2为一种源域可迁移性自适应学习的言语想象脑电解码方法的流程图。
具体实施方式
以下结合附图对本发明进行进一步说明。
一种源域可迁移性自适应学习的言语想象脑电解码方法,用于对未知脑电言语想象任务标签的脑电样本进行解码,以便于对语言障碍者(如脑梗患者)的语言意图进行识别。本实施例中,被识别的言语想象类型包括需要喝水、需要进食、需要运动、需要休息。此外,被识别的言语想象类型也可以为不同发音的字母;由想象不同发音的字母从而映射至具体任务,任务内容包括且不限于喝水、进食、运动、休息。
在跨被试的言语想象脑电解码中,往往会因为被试间差异过大而导致识别不准确的问题,因此本实施例期望通过构造映射矩阵将源域和目标域映射至子空间来减小域间差异。同时,本实施例在减小域间差异的过程中引入样本权重系数矩阵,量化表示了源域样本的可迁移性,促使源域高可迁移性样本在模型学习过程中发挥更多的作用,解决了跨被试言语想象脑电解码领域中因个体差异性造成的言语想象脑电解码不准确的问题。
如图1和图2所示,一种源域可迁移性自适应学习的言语想象脑电解码方法,具体包括以下步骤:
步骤1、采集多名被试者在不同言语想象任务下的带标签的脑电数据;并采集解码对象在不同言语想象任务下的无标签的脑电数据。
步骤2、对步骤1采集得到的脑电数据进行预处理和特征提取。对以1024Hz记录的脑电数据进行采样,采样率为256Hz,然后通过1Hz~70Hz的五阶巴特沃斯带通滤波器滤除噪声以及与EMG活动相关的伪影。利用信号处理技术,提取脑电信号在不同频段下的状态特征,具体使用微分熵(differentail entroy,DE)作为特征,计算脑电信号的微分熵作为样本矩阵
步骤3、构建基于源域可迁移性自适应学习的言语想象脑电解码方法模型。构建描述各源域样本可迁移性的样本权重系数矩阵,并将其引入双映射主动域适应模型;将双映射主动域适应模型和半监督标签传播模型联合至一个统一框架,得到言语想象脑电解码模型。迭代更新求解目标函数,得到样本权重系数矩阵和目标域标签矩阵;样本权重系数矩阵量化表示源域样本的可迁移性,目标域标签矩阵得到目标域的标签完成言语想象脑电解码。
步骤3.1、采用最大均值差异策略作为子空间中源域和目标域之间分布差异的度量准则并在其中融入主动学习的思想,建立双映射主动域适应模型:
式(1)中,
步骤3.2、建立基于结构化二部图的半监督标签传播模型:
式(2)中,S是描述源域样本与目标域样本关联程度的最优结构化二部图关联矩阵,s
步骤3.3、联合步骤3.1和步骤3.2构建的两个模型,将双映射主动域适应模型和基于结构化二部图的半监督标签传播模型整合至统一的框架中联合优化,得到的目标函数如下:
步骤4、根据步骤3中建立的目标函数,对双映射矩阵P=[P
步骤4.1、使用欧几里得距离计算样本间相似性,初始化结构化二部图关联矩阵B;初始化目标域标签矩阵F
步骤4.2、更新双映射矩阵P=[P
在求解式(4)时为简化计算,令P=[P
利用拉格朗日乘子法对式(5)进行求解,可得到关于P的目标函数如下式:
在式(6)中Φ为拉格朗日乘子,对P求偏导并将结果赋值为零,化简可得下式:
式(7)是典型的特征值分解问题,特征值分解后可得到更新后的映射矩阵P=[P
步骤4.3、更新样本权重系数矩阵Θ,固定双映射矩阵P=[P
可将式(8)转换为如下形式:
应用拉格朗日乘子法求解式(9)可得到更新后的样本权重系数矩阵Θ。
步骤4.4、更新结构化二部图关联矩阵S,固定双映射矩阵P=[P
可将式(10)转换为以下形式:
定义
通过按行求解的方式求解式(12),得到更新后的结构化二部图关联矩阵S。
步骤4.5、更新目标域标签矩阵F
可将式(13)转换为如下形式:
应用拉格朗日乘子法和按行求解方法求解式(14),得到更新后的目标域标签矩阵F
步骤4.6、更新重复交替进行步骤4.2、步骤4.3、步骤4.4及步骤4.5直至目标函数收敛,完成双映射矩阵P=[P
步骤5、分析步骤4得到的目标域标签矩阵F
步骤6、通过分析步骤4得到的样本权重系数矩阵Θ,可以看出,样本权重系数矩阵Θ量化表示了源域样本的可迁移性,在目标函数迭代过程中,促使源域高可迁移性样本在模型学习过程中发挥更大的作用。
- 一种基于大数据处理的景点离线图像识别方法及其装置
- 一种基于大数据的疑似窃电用户识别装置及识别方法
- 一种基于激光的动态物体检测方法、装置及终端设备
- 一种基于动态检测数据的接触网潜在风险识别方法及装置
- 基于开放数据的知识图谱动态风险识别方法及装置