批量矩阵奇异值分解的并行协同体系设计方法及装置
文献发布时间:2023-06-19 18:35:48
技术领域
本发明涉及并行协同体系技术领域,具体为批量矩阵奇异值分解的并行协同体系设计方法及装置。
背景技术
在海洋数据同化的核心算法中,需要批量对不同大小的矩阵进行奇异值分解,在以往的计算过程中,通过多CPU并行方法开启多进程进行处理,最多可以同时处理两千个矩阵。为了提高并发性,可以通过计算装置对矩阵进行处理,计算装置通常包括DCU(DeepComputing Unit)或GPU(Graphic Procrssing Unit),本文中提到的计算装置代指DCU或GPU。通常情况下,使用计算装置自带的Nvidia和AMD数学库(cusolver、rocsolver)中的矩阵SVD批处理函数对矩阵进行批量处理。
在计算装置数学库中使用的SVD算法为QR迭代算法,该算法在计算过程中存大量的逻辑判断,对于计算装置来说,这种逻辑判断会极大的影响矩阵的运算效率;目前对矩阵进行SVD分解的算法是QR迭代算法,此算法在计算过程中存在着大量的逻辑判断,这种逻辑判断在异构平台上,会严重的影响运行效率。例如,32个线程在同时运行程序,其中一个进程在逻辑判断中判断出来“否”,剩余31个线程在逻辑判断中判断出来“是”,那么GPU-DCU会先运行逻辑判断为“否”的线程下的程序,其余31个线程在等待这一个线程运行完,再运行它们的程序,这就影响了设备的运行效率。
为此,我们提出批量矩阵奇异值分解的并行协同体系设计方法及装置。
发明内容
本发明的目的在于提供批量矩阵奇异值分解的并行协同体系设计方法及装置,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:批量矩阵奇异值分解的并行协同体系设计方法及装置,包括以下步骤:
S1:将批量矩阵拷贝到计算装置;
S2:进行Householder分解,将所有矩阵二对角化,得到双对角矩阵,并保留每步的Householder矩阵;
S3:将矩阵二对角化后得到的双对角矩阵和每步的Householder矩阵拷贝从设备的显存拷贝到计算机内存中;
S4:通过CPU进行逻辑判断判断现有的上双对角型矩阵进行遍历,每次对双对角矩阵进行逻辑判断,判断它要用Upward算法迭代,还是Backward算法迭代。
S5:将双对角矩阵进行QR迭代,最终得到对角矩阵,对角线上的值为奇异值,保存迭代结果。
S6:将QR迭代结果和Householder分解的迭代结果拷贝到计算装置,在计算装置上进行累乘,得到的结果矩阵为奇异矩阵。
S7:最终将奇异矩阵拷贝到内存中,计算结束。
进一步的,所述计算装置指DCU或GPU其中的一种。
进一步的,所述计算装置自带的Nvidia和AMD数学库中的矩阵SVD批量处理函数对矩阵进行批量处理。
进一步的,所述矩阵SVD批量处理函数的算法为QR迭代算法。
进一步的,奇异值分解算法中逻辑判断部分交给CPU处理。
进一步的,所述计算装置只做数值计算部分。
进一步的,所述DCU对矩阵进行SVD分解。
与现有技术相比,本发明的有益效果是:提供批量矩阵奇异值分解的并行协同体系设计方法及装置,将SVD算法的逻辑判断部分移植到CPU上处理,发挥CPU处理算法的优势,计算装置只进行它擅长的计算部分,从而发挥每个设备的优势,进而提高整体计算效率;
利用DCU,同时对8192个矩阵进行SVD分解,官方数学库的运算时间为38s左右,而我们优化后的函数运行时间仅为4s左右,通过这种方式大幅提高了算法的整体计算效率。
附图说明
图1为现有的传统单个矩阵SVD分解简易流程图;
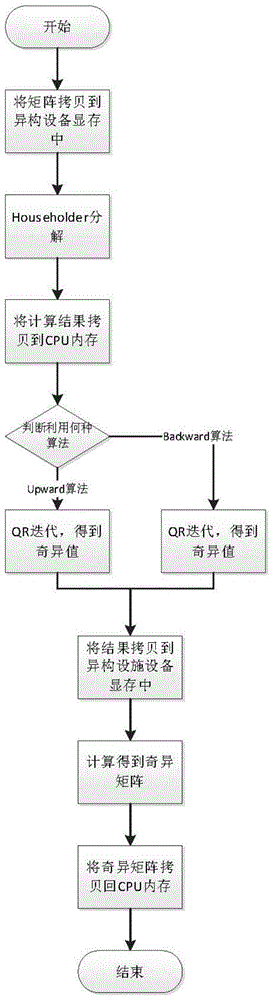
图2为本发明计算装置版矩阵SVD分解简易流程图。
具体实施方式
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明。
如图2所示,该提供批量矩阵奇异值分解的并行协同体系设计方法及装置,包括以下步骤:将批量矩阵拷贝到计算装置,推荐使用锁页内存,计算装置指DCU或GPU其中的一种,所述计算装置自带的Nvidia和AMD数学库中的矩阵SVD批量处理函数对矩阵进行批量处理,所述矩阵SVD批量处理函数的算法为QR迭代算法,所述计算装置只做数值计算部分,将算法达到用CPU-DCU协同处理的目的,充分利用CPU和计算装置各自在计算中的优势部分,最终提高奇异值分解的计算效率,所述DCU对矩阵进行SVD分解;进行Householder分解,将所有矩阵二对角化,得到双对角矩阵,并保留每步的Householder矩阵;将矩阵二对角化后得到的双对角矩阵和每步的Householder矩阵拷贝从设备的显存拷贝到计算机内存中;通过CPU进行逻辑判断判断现有的上双对角型矩阵进行遍历,每次对双对角矩阵进行逻辑判断,判断它要用Upward算法迭代,还是Backward算法迭代,奇异值分解算法中逻辑判断部分交给CPU处理;将双对角矩阵进行QR迭代,最终得到对角矩阵,对角线上的值为奇异值,保存迭代结果;将QR迭代结果和Householder分解的迭代结果拷贝到计算装置,在计算装置上进行累乘,得到的结果矩阵为奇异矩阵;最终将奇异矩阵拷贝到内存中,计算结束;利用DCU,同时对8192个矩阵进行SVD分解,官方数学库(rocsolver)的运算时间为38s左右,而我们优化后的函数运行时间仅为4s左右,通过这种方式大幅提高了算法的整体计算效率。
工作原理:在使用该批量矩阵奇异值分解的并行协同体系设计方法及装置时,使用时,将矩阵拷贝到异构设备储存中,进行Householder分解,将所有矩阵二对角化,得到双对角矩阵,并保留每步的Householder矩阵,将矩阵二对角化后得到的双对角矩阵和每步的Householder矩阵拷贝从设备的显存拷贝到计算机内存中,通过CPU进行逻辑判断判断现有的上双对角型矩阵进行遍历,每次对双对角矩阵进行逻辑判断,判断它要用Upward算法迭代,还是Backward算法迭代,将双对角矩阵进行QR迭代,最终得到对角矩阵,对角线上的值为奇异值,保存迭代结果,将QR迭代结果和Householder分解的迭代结果拷贝到计算装置,在计算装置上进行累乘,得到的结果矩阵为奇异矩阵,最终将奇异矩阵拷贝到内存中,计算结束。
以上的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。