基于人体智能定位的远场语音增强系统及方法
文献发布时间:2023-06-19 19:33:46
技术领域
本发明涉及智能设备远场语音处理领域,具体涉及一种基于人体智能定位的远场语音增强系统及方法。
背景技术
随着互联网技术的普及和发展,各种智能设备和终端层出不穷。智能电视、智能音响以及其它相关智能家居,基于网络的互联互通已成为目前市场应用的主流。如何简单操控上述设备也成为目前各大厂商技术突破的主攻方向,如简单方便的语音控制系统,用户只需要说出自己的需求,智能设备就会立即响应操作,并基于后台网络的云平台和云计算,呈现出用户的各种需求。现在市场主流的语音控制系统有基于蓝牙遥控器的近场语音控制系统和完全抛开遥控器的远场语音控制系统,这时用户只需要在一定范围内对着设备喊话,设备就会立即响应相关操作,极大的方便了用户操作,做到了随时随地,随心所控。
针对智能电视和智能音响的远场语音控制技术目前已经相对比较成熟了,针对不同智能家居的语音控制也逐渐普遍开来。其驱动电路都是通过模拟或数字麦克风方式进行语音采集处理并通过智能终端进行运算控制,在现有的远场语音采集系统中,麦克风的安装位置固定以后,声场的空间也就基本确定,用户在不同位置上由于声音传播路径的不同,体验效果也会明显差异。特别是用户使用环境比较复杂时,如周围有其它设备的声音干扰下,会造成麦克风语音识别明显下降,影响用户的体验感。因为,此时麦克风采集的是周围环境所有的声音,包含各种干扰声音,这会严重影响电路识别灵敏度和信噪比,近而直接影响远场语音识别的正确率。
发明内容
本发明的目的是提供一种基于人体智能定位的远场语音增强系统及方法,极大地提高了远场语音识别的准确率。
本发明采取如下技术方案实现上述目的,基于人体智能定位的远场语音增强系统,用于对智能设备的远场语音进行增强,所述智能设备包括数字音频处理模块以及多个麦克风,麦克风设置在智能设备面向用户的一面,数字音频处理模块与麦克风连接,所述远场语音增强系统包括定位模块;
所述定位模块用于对用户进行定位,确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块;
所述数字音频处理模块用于根据用户位置信号选择对应角度的多个麦克风,并将该多个麦克风设置成阵列,形成对用户语音的定向响应波束信号。
进一步的是,所述定位模块包括红外传感器阵列、AD模数转换模块,以及控制模块,红外传感器阵列设置在智能设备面向用户的一面,AD模数转换模块分别与红外传感器阵列以及控制模块连接;
所述红外传感器阵列用于探测是否存在用户;
所述AD模数转换模块用于将红外传感器阵列探测的模拟信号转化为数字信号;
所述控制模块用于根据所述数字信号确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块。通过该方式能够提高对用户定位的准确性。
进一步的是,所述数字音频处理模块还用于,对所述定向响应波束信号进行降噪处理以及自然语音处理,得到IIS或PCM数字信号,并将IIS或PCM数字信号输出至智能设备。通过该方式能够提高定向响应波束信号的准确性。
基于人体智能定位的远场语音增强方法,应用于上述所述的基于人体智能定位的远场语音增强系统,所述方法包括:
定位模块对用户进行定位,确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块;
所述数字音频处理模块根据用户位置信号选择对应角度的多个麦克风,并将该多个麦克风设置成阵列,形成对用户语音的定向响应波束。
进一步的是,所述定位模块包括红外传感器阵列、AD模数转换模块,以及控制模块,红外传感器阵列设置在智能设备面向用户的一面,AD模数转换模块分别与红外传感器阵列以及控制模块连接;
所述红外传感器阵列探测是否存在用户,所述AD模数转换模块将红外传感器阵列探测的模拟信号转化为数字信号;
所述控制模块根据所述数字信号确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块。
进一步的是,该方法还包括:
对所述定向响应波束信号进行降噪处理以及自然语音处理,得到IIS或PCM数字信号,并将IIS或PCM数字信号输出至智能设备。
本发明的有益效果为:
本发明通过对人体的精确定位,确定用户位置的声场,选择对应角度的多个麦克风,并将该多个麦克风设置成阵列,形成对用户语音的定向响应波束,而角度之外的声场信号则会衰减,通过该方式能够衰减非人体发出的干扰声源,极大地提高了远场语音识别的准确率。
附图说明
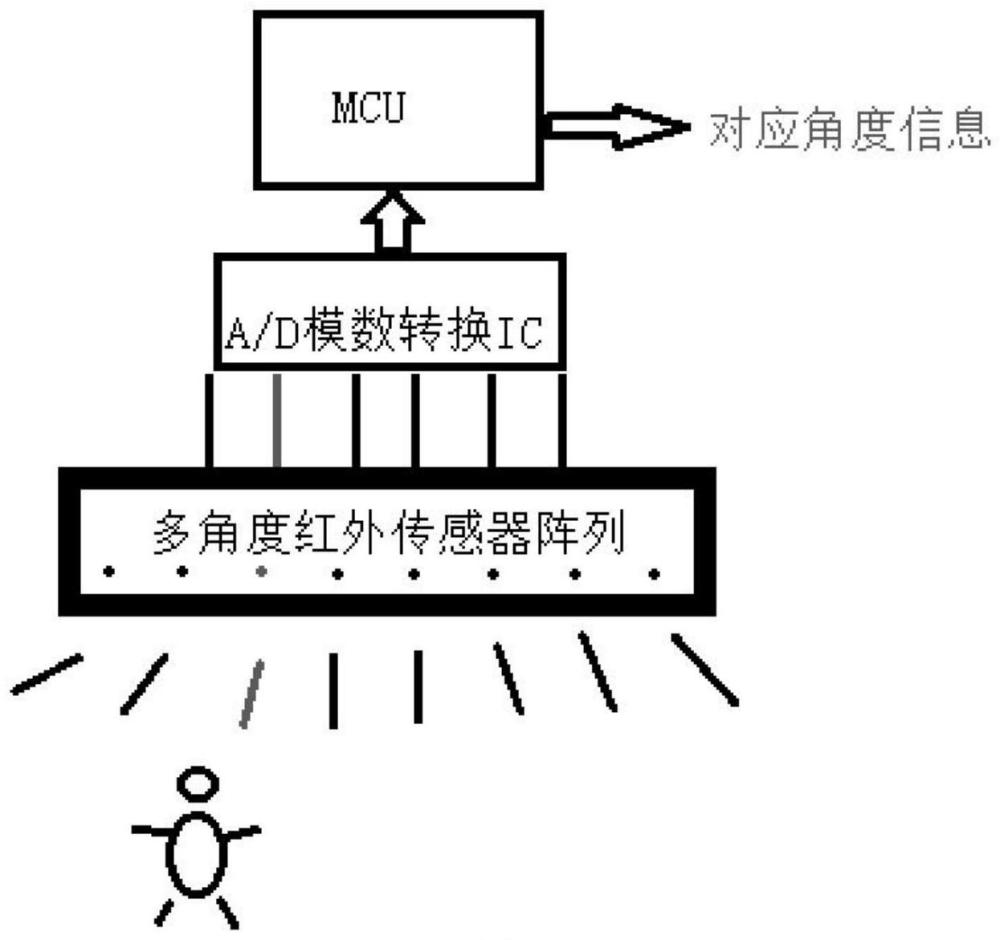
图1为本发明实施例提供的定位模块的结构框图。
图2为本发明实施例提供的远场语音增强系统的部分结构框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种基于人体智能定位的远场语音增强系统,用于对智能设备的远场语音进行增强,所述智能设备包括数字音频处理模块以及多个麦克风,麦克风设置在智能设备面向用户的一面,数字音频处理模块与麦克风连接,所述远场语音增强系统包括定位模块;
定位模块用于对用户进行定位,确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块;
数字音频处理模块用于根据用户位置信号选择对应角度的多个麦克风,并将该多个麦克风设置成阵列,形成对用户语音的定向响应波束信号。
在本发明的一种实施例中,定位模块包括红外传感器阵列、AD模数转换模块,以及控制模块,红外传感器阵列设置在智能设备面向用户的一面,AD模数转换模块分别与红外传感器阵列以及控制模块连接;
红外传感器阵列用于探测是否存在用户;
AD模数转换模块用于将红外传感器阵列探测的模拟信号转化为数字信号;
控制模块用于根据所述数字信号确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块。通过该方式能够提高对用户定位的准确性。
具体的,如图1所示,定位模块包括多角度红外传感器阵列及驱动电路,A/D模数转换IC芯片,MCU(MicrocontrollerUnit,微控制单元)。由于人体正常体温为36.5℃左右,发出的红外波长大约为10um,采用人体红外传感器可探测周围环境存在的人体,人体在不同位置,对应角度的传感器感应电平升高,通过A/D模数转换芯片,可将不同角度的感应值数字化,经过MCU数据算法分析,将数值高于阈值的角度定义为人体位置,并将位置发送给数字音频处理器。
在本发明的一种实施例中,所述数字音频处理模块还用于,对所述定向响应波束信号进行降噪处理以及自然语音处理,得到IIS或PCM数字信号,并将IIS或PCM数字信号输出至智能设备。通过该方式能够提高定向响应波束信号的准确性。
具体的,如图2所示,智能设备包括数字音频处理器以及麦克风,远场语音增强系统根据红外人体识别处理得到的角度信息通过数字音频处理器选择对应相同角度数字麦克风,多语音识别可以对来自一个或多个特定方向的声音更敏感,形成特定角度上接受灵敏度最大的声场信号,而角度之外的声场信号则可以迅速衰减。它包括多个数字硅麦负责采集各个方向的声场信号,通过数字麦克风接口电路,如IIS或PCM接口电路进入数字音频处理器,数字音频处理可以保留对特定方向声音的识别灵敏度。
声音定向处理后智能设备进行波束成形处理,即智能设备通过数字音频处理器将人体声源方向多个麦克风配置成阵列,形成定向响应的波束场型,形成特定角度上接受灵敏度最大的声场信号,可以对一个或多个特定方向的声音更敏感,而角度之外的声场信号迅速衰减,实现麦克风对人体声音方向的自动定位。
对波束成形的信号再进行降噪处理和自然语音处理,通过内部算法处理可以消除一些静态固定环境噪声等影响,最后处理为IIS或PCM数字信号输出。输出的IIS或PCM数字信号进入后端相关智能设备,如智能电视及智能音响,近而在通过互联网云端处理识别后,响应用户的操作和功能。
本发明还提供了一种基于人体智能定位的远场语音增强方法,所述方法包括:
定位模块对用户进行定位,确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块;
所述数字音频处理模块根据用户位置信号选择对应角度的多个麦克风,并将该多个麦克风设置成阵列,形成对用户语音的定向响应波束。
在本发明的一种实施例中,所述定位模块包括红外传感器阵列、AD模数转换模块,以及控制模块,红外传感器阵列设置在智能设备面向用户的一面,AD模数转换模块分别与红外传感器阵列以及控制模块连接;
红外传感器阵列探测是否存在用户,所述AD模数转换模块将红外传感器阵列探测的模拟信号转化为数字信号;
控制模块根据所述数字信号确定用户的位置信息,并将用户位置信息发送至所述数字音频处理模块。
在本发明的一种实施例中,该方法还包括:
对所述定向响应波束信号进行降噪处理以及自然语音处理,得到IIS或PCM数字信号,并将IIS或PCM数字信号输出至智能设备。
综上所述,本发明通过采用红外人体方向辩识和波束成形增强技术,以实时精准定位人体位置方向的声场,衰减削弱非人体周围的干扰声场影响,从而达到提升语音数据采集的信噪比和灵敏度,提升快速精准识别的远场语音系统。适合高端智能电视、智能投影机、智能音响等家居的远场语音控制电路,提升用户精准控制效果。
- 一种基于语音增强技术的耳机远场交互系统
- 一种远场语音增强的视频通话方法与系统