信息获取方法、装置、设备、服务器及其集群、存储介质
文献发布时间:2024-04-18 19:52:40
技术领域
本发明涉及信息获取领域,特别是涉及一种信息获取方法,本发明还涉及一种信息获取装置、设备、服务器、服务器集群以及计算机可读存储介质。
背景技术
随着人工智能技术的发展,在多种领域(例如文旅领域)都可以设计提供信息获取服务,以便满足用户对于领域内知识的问答需求,在使用信息获取服务时,用户通常可以提供关键词,然后从数据库中检索确定出关键词所描述的领域内的某个实体,然而相关技术中缺少一种成熟的信息获取方法,导致检索确定出的实体与用户理想中实体的匹配度较差,降低了用户体验。
因此,如何提供一种解决上述技术问题的方案是本领域技术人员目前需要解决的问题。
发明内容
本发明的目的是提供一种信息获取方法,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验;本发明的另一目的是提供一种信息获取装置、设备、服务器、服务器集群以及计算机可读存储介质,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验。
为解决上述技术问题,本发明提供了一种信息获取方法,包括:
获取预先构建的包含目标领域内各个实体的表征数据的预设数据库;
通过人机交互接口获取描述同一实体的多种模态的查询数据;
基于各种模态的所述查询数据以及所述预设数据库内各个实体的表征数据,通过相似度检测算法确定出所述查询数据描述的实体,并将其作为目标实体;
将所述目标实体的标识信息推送至所述人机交互接口。
另一方面,所述获取预先构建的包含目标领域内各个实体的表征数据的预设数据库包括:
确定出属于目标领域内的多个实体,并将其作为待存储实体;
针对每个所述待存储实体,获取所述待存储实体多个指定模态的表征数据;
将各个所述待存储实体及其对应的所述表征数据,存储至预设数据库;
其中,所述指定模态包括文本模态、语音模态、图像模态、视频模态以及地理坐标模态中的至少两种。
另一方面,所述针对每个所述待存储实体,获取所述待存储实体多个指定模态的表征数据之后,该信息获取方法还包括:
通过文本-图像多模态模型,对各个所述待存储实体的所述表征数据进行编码,得到特征向量;
将各个所述待存储实体的各个所述表征数据,通过所述文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至所述预设数据库;
所述基于各种模态的所述查询数据以及所述预设数据库内各个实体的表征数据,通过相似度检测算法确定出所述查询数据描述的实体,并将其作为目标实体包括:
通过所述文本-图像多模态模型,将各种模态的所述查询数据编码为特征向量;
对于任一所述查询数据,确定出所述查询数据通过所述文本-图像多模态模型编码的特征向量与所述第一特征向量集合中的各个特征向量之间的相似度;
对于所述预设数据库中任一实体,将本次通过所述实体的所述表征数据对应的特征向量确定出的所有所述相似度的数值之和,作为所述实体的打分值;
将所述预设数据库中所述打分值最高的实体作为所述查询数据描述的实体,并将其作为目标实体;
其中,所述多种模态的查询数据包括文本模态、语音模态、图像模态、视频模态以及地理坐标模态中的至少两种。
另一方面,所述针对每个所述待存储实体,获取所述待存储实体多个指定模态的表征数据之后,该信息获取方法还包括:
通过文本数据专用编码器将各个所述待存储实体的文本模态的表征数据编码为特征向量;
将各个所述待存储实体通过所述文本数据专用编码器编码得到的特征向量作为第二特征向量集合,存储至所述预设数据库,将各个所述待存储实体的地理坐标模态的所述表征数据作为第三特征向量集合,存储至所述预设数据库;
所述对于所述预设数据库中任一实体,将本次通过所述实体的所述表征数据对应的特征向量确定出的所有所述相似度的数值之和,作为所述实体的打分值之前,该信息获取方法还包括:
通过所述文本数据专用编码器将文本模态的所述查询数据编码为特征向量;
对于任一文本模态的所述查询数据,确定出所述查询数据通过所述文本数据专用编码器编码的特征向量与所述第二特征向量集合中的各个特征向量之间的相似度;
对于任一地理坐标模态的所述查询数据,确定出所述查询数据与所述第三特征向量集合中的各个特征向量之间的相似度。
另一方面,所述获取预先构建的包含目标领域内各个实体的表征数据的预设数据库之后,所述通过人机交互接口获取描述同一实体的多种模态的查询数据之前,该信息获取方法还包括:
通过人机交互接口提示输入描述同一实体的图像模态以及文本模态的查询数据。
另一方面,所述基于各种模态的所述查询数据以及所述预设数据库内各个实体的表征数据,通过相似度检测算法确定出所述查询数据描述的实体,并将其作为目标实体之后,该信息获取方法还包括:
将所述预设数据库中与所述目标实体的关联关系的数值大于预设阈值的实体作为推荐实体;
将所述推荐实体的标识信息推送至所述人机交互接口;
其中,所述预设数据库中预先确定有各个实体之间的关联关系。
另一方面,所述将所述目标实体的标识信息推送至所述人机交互接口之后,该信息获取方法还包括:
通过所述人机交互接口获取对于所述目标实体的文本模态的提问内容;
基于预设数据库中各个实体之间的关联关系,通过预设的人工智能问答模型得到针对所述提问内容的解答内容;
将所述解答内容推送至所述人机交互接口。
另一方面,所述人工智能问答模型包括聊天生成对抗网络或第二代生成对抗网络。
另一方面,所述预设数据库中各个实体之间的关联关系包括:
依次将所述预设数据库中的各个实体作为待测实体,并基于互联网针对所述待测实体提供的文本内容,确定出与待测实体具有直接相关关系的实体;
基于所述预设数据库中的各个实体以及各个实体间的所述直接相关关系,构建知识图谱;
针对当前的所述知识图谱,采用社会网络中的三元闭包原理,挖掘出各个所述实体间的潜在关联关系。
另一方面,所述针对当前的所述知识图谱,采用社会网络中的三元闭包原理,挖掘出各个所述实体间的潜在关联关系之后,该信息获取方法还包括:
通过各个所述实体的地理坐标,确定出各个所述实体间的空间关联关系。
另一方面,所述文本-图像多模态模型包括基于对比文本-图像对的预训练模型。
另一方面,所述文本数据专用编码器包括自注意力语言模型。
另一方面,所述将各个所述待存储实体的各个所述表征数据,通过所述文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至所述预设数据库包括:
将各个所述待存储实体的各个所述表征数据,通过所述文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至所述预设数据库;其中,所述第一特征向量集合包括多个子集合,每个子集合中包括对应的一种预设标签的所有所述表征数据通过所述文本-图像多模态模型编码的特征向量;
所述通过所述文本-图像多模态模型,将各种模态的所述查询数据编码为特征向量之后,所述对于任一所述查询数据,确定出所述查询数据通过所述文本-图像多模态模型编码的特征向量与所述第一特征向量集合中的各个特征向量之间的相似度之前,该信息获取方法还包括:
判断是否启用聚类加速功能;
若未启用,执行所述对于任一所述查询数据,确定出所述查询数据通过所述文本-图像多模态模型编码的特征向量与所述第一特征向量集合中的各个特征向量之间的相似度的步骤;
若启用,对所述第一特征向量集合中的每个子集合进行聚类,并确定出各个聚类的聚类中心;
对于任一所述查询数据,将所述第一特征向量集合中各个聚类的聚类中心中,与所述查询数据通过所述文本-图像多模态模型编码的特征向量之间的相似度按照从大到小的顺序排名前预设数量位的聚类中心所在的子集合,作为目标子集合;
对于任一所述查询数据,确定出所述查询数据通过所述文本-图像多模态模型编码的特征向量与各个所述目标子集合中的各个特征向量之间的相似度;
执行所述对于所述预设数据库中任一实体,将本次通过所述实体的所述表征数据对应的特征向量确定出的所有所述相似度的数值之和,作为所述实体的打分值的步骤。
另一方面,所述对所述第一特征向量集合中的每个子集合进行聚类包括:
通过K均值聚类算法对所述第一特征向量集合中的每个子集合进行聚类。
另一方面,所述预设标签包括所述表征数据的数据模态。
另一方面,所述对所述第一特征向量集合中的每个子集合进行聚类之前,该信息获取方法还包括:
通过主成分分析法,对所述第一特征向量集合中的所有特征向量进行降维处理。
另一方面,所述确定出属于目标领域内的多个实体,并将其作为待存储实体包括:
通过爬虫技术从互联网中爬取属于目标领域内的多个实体,并将其作为待存储实体;
所述针对每个所述待存储实体,获取所述待存储实体多个指定模态的表征数据包括:
针对每个所述待存储实体,通过爬虫技术从互联网中爬取所述待存储实体多个指定模态的表征数据。
为解决上述技术问题,本发明还提供了一种信息获取装置,包括:
第一获取模块,用于获取预先构建的包含目标领域内各个实体的表征数据的预设数据库;
第二获取模块,用于通过人机交互接口获取描述同一实体的多种模态的查询数据;
确定模块,用于基于各种模态的所述查询数据以及所述预设数据库内各个实体的表征数据,通过相似度检测算法确定出所述查询数据描述的实体,并将其作为目标实体;
推送模块,用于将所述目标实体的标识信息推送至所述人机交互接口。
为解决上述技术问题,本发明还提供了一种信息获取设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现如上所述信息获取方法的步骤。
为解决上述技术问题,本发明还提供了一种服务器,包括如上所述的信息获取设备。
为解决上述技术问题,本发明还提供了一种服务器集群,包括至少一台如上所述的服务器。
为解决上述技术问题,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述信息获取方法的步骤。
有益效果:本发明提供了一种信息获取方法,考虑到不同模态的查询数据能够从不同维度对于目标实体进行描述,因此本发明中可以通过人机交互接口获取描述同一实体的多种模态的查询数据,并且在预先构建了包含目标领域内各个实体的表征数据的预设数据库的前提下,便可以基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其标识信息推送至人机交互接口,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验。
本发明还提供了一种信息获取装置、设备、服务器、服务器集群以及计算机可读存储介质,具有如上信息获取方法相同的有益效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对相关技术和实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
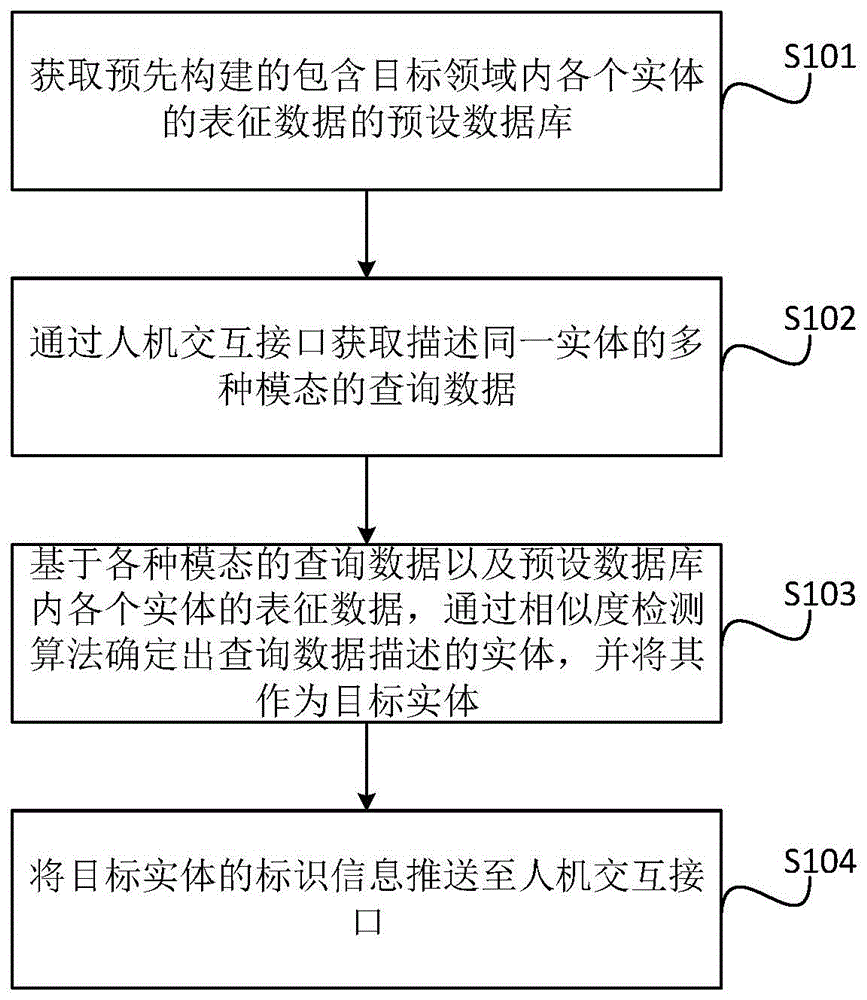
图1为本发明提供的一种信息获取方法的流程示意图;
图2为本发明提供的另一种信息获取方法的流程示意图;
图3为本发明提供的一种信息获取装置的结构示意图;
图4为本发明提供的一种信息获取设备的结构示意图;
图5为本发明提供的一种计算机可读存储介质的结构示意图。
具体实施方式
本发明的核心是提供一种信息获取方法,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验;本发明的另一核心是提供一种信息获取装置、设备、服务器、服务器集群以及计算机可读存储介质,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参考图1,图1为本发明提供的一种信息获取方法的流程示意图,该信息获取方法包括:
S101:获取预先构建的包含目标领域内各个实体的表征数据的预设数据库;
具体的,考虑到如上背景技术中的技术问题,又结合考虑到不同模态的查询数据能够从不同维度对于目标实体进行描述,而相关技术中通常采用单一模态的例如文本或者图像模态的查询数据进行实体匹配,导致实体匹配精度较差,因此本发明实施例中欲基于多模态的查询数据进行实体的匹配,而进行实体匹配时的基础是领域内各个实体的表征数据,因此本发明实施例的步骤中首先可以获取预先构建的包含目标领域内各个实体的表征数据的预设数据库,以便后续展开实体匹配工作。
其中,目标领域可以为多种类型,例如可以为文化旅游领域,或者家具产品领域等,本发明实施例在此不做限定。
具体的,实体可以为具体领域内的各种有形物体或者无形的事件等,例如在文化旅游行业中实体可以为景点、建筑物、人物、历史事件、美食等,本发明实施例在此不做限定。
其中,表征数据指的是表征实体的数据,其可以为各种模态,本发明实施例在此不做限定。
具体的,预设数据库的具体类型可以为知识图谱,知识图谱能够更好地组织异构(也即不同格式的)的数据。
S102:通过人机交互接口获取描述同一实体的多种模态的查询数据;
具体的,在有了预设数据库后,便可以基于用户提供的查询数据展开实体匹配工作,因此本发明实施例中可以通过人机交互接口获取描述同一实体的多种模态的查询数据,对于用户来说则可以通过人机交互接口输入多种模态的描述同一实体的查询数据,便于后续展开实体匹配。
S103:基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其作为目标实体;
具体的,在具备预设数据库以及查询数据后,便可以通过相似度检测算法确定出查询数据描述的实体,并将其作为目标实体,基于多种模态的查询数据通过相似度计算所进行的实体匹配的过程可以为多种,本发明实施例在此不做限定。
S104:将目标实体的标识信息推送至人机交互接口。
具体的,在确定出目标实体之后,为了便于用户获知想要了解的目标实体是什么,因此本发明实施例中可以将目标实体的标识信息推送至人机交互接口,该标识信息的具体内容可以为表征目标实体是什么的信息,例如可以为实体名称或者实体的图像等,本发明实施例在此不做限定。
本发明提供了一种信息获取方法,考虑到不同模态的查询数据能够从不同维度对于目标实体进行描述,因此本发明中可以通过人机交互接口获取描述同一实体的多种模态的查询数据,并且在预先构建了包含目标领域内各个实体的表征数据的预设数据库的前提下,便可以基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其标识信息推送至人机交互接口,多模态的查询数据能够多维度的对实体进行更加完善的表征,从而有利于提升实体匹配的精度,提升了用户体验。
在上述实施例的基础上:
作为一种优选的实施例,获取预先构建的包含目标领域内各个实体的表征数据的预设数据库包括:
确定出属于目标领域内的多个实体,并将其作为待存储实体;
针对每个待存储实体,获取待存储实体多个指定模态的表征数据;
将各个待存储实体及其对应的表征数据,存储至预设数据库;
其中,指定模态包括文本模态、语音模态、图像模态、视频模态以及地理坐标模态中的至少两种。
具体的,数据库的构建过程可以为首先确定实体列表,然后再获取每个实体对应的表征数据,考虑到不同模态的数据可以从不同维度表征实体,因此本发明为了进一步提升实体匹配的精度,可以获取实体的多种模态的数据,指定模态包括文本模态、语音模态、图像模态、视频模态以及地理坐标模态中的至少两种,当然可以尽量多几种模态。
其中,这一步是让知识图谱多模态信息丰富的重要过程,对于图片、视频数据,本发明采用网络爬虫抓取互联网上的图片、短视频网站信息,并且对齐到相应的知识图谱实体。对于音频数据主要是采用有声读物、广播、视频讲述等来源。对于空间数据则采用地图软件的API(Application Programming Interface,应用程序编程接口)获得每个景点的空间经纬度信息。
作为一种优选的实施例,针对每个待存储实体,获取待存储实体多个指定模态的表征数据之后,该信息获取方法还包括:
通过文本-图像多模态模型,对各个待存储实体的表征数据进行编码,得到特征向量;
将各个待存储实体的各个表征数据,通过文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至预设数据库;
基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其作为目标实体包括:
通过文本-图像多模态模型,将各种模态的查询数据编码为特征向量;
对于任一查询数据,确定出查询数据通过文本-图像多模态模型编码的特征向量与第一特征向量集合中的各个特征向量之间的相似度;
对于预设数据库中任一实体,将本次通过实体的表征数据对应的特征向量确定出的所有相似度的数值之和,作为实体的打分值;
将预设数据库中打分值最高的实体作为查询数据描述的实体,并将其作为目标实体;
其中,多种模态的查询数据包括文本模态、语音模态、图像模态、视频模态以及地理坐标模态中的至少两种。
具体的,考虑到相似度计算时需要基于各种模态数据编码的特征向量进行,而为了便于不同模态数据对应的特征向量之间的相似度计算,本发明实施例中无论对于预设数据库中的表征数据,还是查询数据,均可以通过文本-图像多模态模型进行编码,从而使得不同模态数据的特征向量位于同一语义空间,那么位于同一语义空间内的特征向量便可以直接展开运算,提升了运算效率,也即提升了实体匹配的效率。
具体的,在通过文本-图像多模态模型,对各个待存储实体的表征数据进行编码时,由于地理坐标模态的数据本身就可以与特征向量进行直接运算,因此可以通过文本-图像多模态模型,对各个待存储实体除地理坐标模态的其他模态的表征数据进行编码,而无需再对地理坐标模态的表征数据进行编码,而地理坐标模态的表征数据可以被直接加入第一特征向量集合。
其中,预设数据库中的每个实体都包含多个模态的表征数据,而表征数据都存在自身所属的实体,在进行相似度打分时,可以将某一实体相关(也即通过该实体的表征数据计算得到的相似度)的所有相似度之和作为该实体的打分值。
具体的,在一种实例中,采用文本-图像多模态模型进行编码,例如CLIP,该模型将文本和图像的表征进行对齐。对于视频数据也会提取一些视频帧作为图像进行编码,如公式(1)所示:
其中,
V
此外文本模态数据占据大量内容,基于文本模态数据的特殊属性,本发明也单独编码了文本描述的向量,如公式(3)所示。
v
其中Ftext()采用sentence-BERT(sentence-Bidirectional EncoderRepresentation from Transformers,基于Transformer的双向编码器表征)模型,将知识图谱中实体的文本描述编码为向量表示v
v
其中,D为所有文本模态的表征数据的特征向量v
对于音频数据首先采用科大讯飞的语音识别API将音频转化为文本,也采用上述的sentence-BERT模型进行编码。
作为一种优选的实施例,针对每个待存储实体,获取待存储实体多个指定模态的表征数据之后,该信息获取方法还包括:
通过文本数据专用编码器将各个待存储实体的文本模态的表征数据编码为特征向量;
将各个待存储实体通过文本数据专用编码器编码得到的特征向量作为第二特征向量集合,存储至预设数据库,将各个待存储实体的地理坐标模态的表征数据作为第三特征向量集合,存储至预设数据库;
对于预设数据库中任一实体,将本次通过实体的表征数据对应的特征向量确定出的所有相似度的数值之和,作为实体的打分值之前,该信息获取方法还包括:
通过文本数据专用编码器将文本模态的查询数据编码为特征向量;
对于任一文本模态的查询数据,确定出查询数据通过文本数据专用编码器编码的特征向量与第二特征向量集合中的各个特征向量之间的相似度;
对于任一地理坐标模态的查询数据,确定出查询数据与第三特征向量集合中的各个特征向量之间的相似度。
具体的,考虑到通过文本-图像多模态模型对文本模态的数据进行编码的精度不如文本数据专用编码器,因此本发明实施例中针对文本模态的表征数据以及查询数据,均可以通过文本数据专用编码器进行编码,那么在进行相似度计算的时候,对于任一文本模态的查询数据,还可以确定出查询数据通过文本数据专用编码器编码的特征向量与第二特征向量集合中的各个特征向量之间的相似度,同样的逻辑,对于对于任一地理坐标模态的查询数据,确定出查询数据与第三特征向量集合中的各个特征向量之间的相似度,由于额外进行了文本模态以及地理坐标模态数据的相似度计算,因此可以进一步提升实体的匹配精度。
具体的,对于本发明实施例中提及的多模态查询数据的实体匹配方法的具体实例可以为:
本发明提出文本描述增强的图像检索方法,不仅仅利用图像本身的信息,还会利用知识图谱中实体的描述向量,综合多种评价维度得出最终匹配得分。这是一种混合特征匹配方法(也即多模态查询数据的实体匹配方法),图片也采用CLIP模型进行编码,然后采用向量检索。
通过用户输入一段对图像特征描述的文字,例如颜色、外观、所处景点、附近的标志物等。采用CLIP模型将文本描述编码为向量,进行跨模态检索。
其中
其中photo代表用户拍摄的照片,公式(6)与公式(2)为相同的模型。
得到上述向量表征后,通过混合特征检索的形式,基于点积计算进行向量检索,如公式(7)所示。
其中,α、β、γ为三个加权系数,其数值为1或0,V
具体的,值得一提的是,考虑到对于文本数据已经通过CLIP编码器进行编码,因此上述实例中未通过文本图片多模态模型对预设数据库中的文本数据进行编码,那么在公式7的相似度计算过程中,文本模态的查询数据的特征向量则与预设数据库中通过文本数据专用编码器编码文本模态的表征数据得(也包括语音模态转换得到的文本模态的数据)到的向量集合D进行相似度计算。
作为一种优选的实施例,获取预先构建的包含目标领域内各个实体的表征数据的预设数据库之后,通过人机交互接口获取描述同一实体的多种模态的查询数据之前,该信息获取方法还包括:
通过人机交互接口提示输入描述同一实体的图像模态以及文本模态的查询数据。
具体的,考虑到查询数据的模态要求过多会降低用户体验,而图像以及文本是较为容易获得的查询数据,且其对于实体的表征也较为全面,因此本发明实施例中可以通过人机交互接口提示输入描述同一实体的图像模态以及文本模态的查询数据,以便基于用户输入的这两种模态的查询数据展开实体匹配工作。
当然,除了这两种模态的数据外,查询数据的模态组合还可以为其他多种类型,本发明实施例在此不做限定。
作为一种优选的实施例,基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其作为目标实体之后,该信息获取方法还包括:
将预设数据库中与目标实体的关联关系的数值大于预设阈值的实体作为推荐实体;
将推荐实体的标识信息推送至人机交互接口;
其中,预设数据库中预先确定有各个实体之间的关联关系。
具体的,考虑到用户在查询目标实体的过程中,会有兴趣或者有需求知道与目标实体相关联的其他实体,因此本发明实施例中可以在预设数据库中预先构建各个实体之间的关联关系,那么在确定出目标实体后,便可以将预设数据库中与目标实体的关联关系的数值大于预设阈值的实体作为推荐实体,并将推荐实体的标识信息推送至人机交互接口。
其中,预设阈值可以进行自主设定,本发明实施例在此不做限定。
作为一种优选的实施例,将目标实体的标识信息推送至人机交互接口之后,该信息获取方法还包括:
通过人机交互接口获取对于目标实体的文本模态的提问内容;
基于预设数据库中各个实体之间的关联关系,通过预设的人工智能问答模型得到针对提问内容的解答内容;
将解答内容推送至人机交互接口。
具体的,考虑到在确定出目标实体后,用户存在针对目标实体进行文本模态内容的提问需求,因此本发明实施例中可以在获取到提问内容后,基于预设数据库中各个实体之间的关联关系,通过预设的人工智能问答模型得到针对提问内容的解答内容,然后将解答内容推送至人机交互接口即可,进一步丰富了功能,提升了用户体验。
具体的,根据检索出的多模态数据向量,从而找出知识图谱中对应的实体。然后通过基于chatGPT的API或者其他小型的自回归语言模型GPT-2对景点的知识进行问答。采用提示学习的形式,对问题做出回答,如公式(8)所示。
answer=F
其中,F
作为一种优选的实施例,人工智能问答模型包括聊天生成对抗网络或第二代生成对抗网络。
具体的,聊天生成对抗网络也即chatGPT(Chat Generative Pre-trainedTransformer),第二代生成对抗网络也即小型的自回归语言模型GPT-2,两者均有智能程度高以及处理速度快等优点。
当然,除了这两种类型外,人工智能问答模型还可以为其他多种类型,本发明实施例在此不做限定。
作为一种优选的实施例,预设数据库中各个实体之间的关联关系包括:
依次将预设数据库中的各个实体作为待测实体,并基于互联网针对待测实体提供的文本内容,确定出与待测实体具有直接相关关系的实体;
基于预设数据库中的各个实体以及各个实体间的直接相关关系,构建知识图谱;
针对当前的知识图谱,采用社会网络中的三元闭包原理,挖掘出各个实体间的潜在关联关系。
具体的,考虑到互联网包含有对于各个实体的文本介绍内容,例如百科网站中对于单一实体的词条的介绍内容中,通常都会提到与该词条具有直接相关关系的其他实体的标识信息(例如名称),因此本发明实施例中可以依次将预设数据库中的各个实体作为待测实体,并基于百科网站针对待测实体提供的文本内容,确定出与待测实体具有直接相关关系的实体,从而可以完成知识图谱的构建,知识图谱也可以作为一种数据库类型,其可以更好地组织异构的数据;在此基础上,本发明实施例中还可以针对当前的知识图谱,采用社会网络中的三元闭包原理,挖掘出各个实体间的潜在关联关系,从而更加紧密的表达各个实体之间的关联关系。
其中,多模态知识图谱可以由三元组构成,例如在文旅领域可以包括(北京故宫,类型,宫殿)、(北京故宫,子景点,三大殿)、(北京故宫,图片,<具体图像>)、(北京故宫,视频,<具体视频>)等,本发明实施例在此不做限定。
具体的,知识图谱构建技术旨在通过本体建模、实例层建模的技术,将实体、概念通过不同类型的关系进行关联,从而构建为语义网络。知识图谱构建包含本体建模和实例层建模两部分。其中本体构建,先前的方法主要基于人工设计本体,本发明提出采用ChatGPT类的预训练语言模型进行本体生成。生成概念之间的层次结构以及概念的属性等。对于实例层建模,先前的多模态旅游知识图谱主要包含文本和图像两种模态,而且仅仅作为单独的数据进行存储,没有进行统一的融合表征。本发明提出的多模态文旅知识图谱将文本、图像、视频、音频、空间坐标等不同模态的数据进行融合,从而实现多模态的感知。
作为一种优选的实施例,针对当前的知识图谱,采用社会网络中的三元闭包原理,挖掘出各个实体间的潜在关联关系之后,该信息获取方法还包括:
通过各个实体的地理坐标,确定出各个实体间的空间关联关系。
具体的,考虑到实体的坐标对于用户来说也是较为重要的数据,例如在文化旅游领域中,用户在游览第一实体的同时,可以顺便游览附近的其他实体,因此本发明实施例中还可以通过各个实体的地理坐标,确定出各个实体间的空间关联关系,从而更加全面的表征实体间的关联关系。
其中,各实体的地理坐标可以通过多种方式获取,例如爬取或者通过地图软件获取等,本发明实施例在此不做限定。
作为一种优选的实施例,文本-图像多模态模型包括基于对比文本-图像对的预训练模型。
具体的,基于对比文本-图像对的预训练模型也即CLIP(Constrastive Language-Image Pre-training),具有处理速度快以及精度高等优点。
当然,除了CLIP外,文本-图像多模态模型还可以为其他多种类型,本发明实施例在此不做限定。
作为一种优选的实施例,文本数据专用编码器包括自注意力语言模型。
具体的,自注意力语言模型也即sentence-BERT,具备编码速度快以及精度高等优点。
当然,除了自注意力语言模型外,文本数据专用编码器还可以为其他多种类型,本发明实施例在此不做限定。
作为一种优选的实施例,将各个待存储实体的各个表征数据,通过文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至预设数据库包括:
将各个待存储实体的各个表征数据,通过文本-图像多模态模型编码的特征向量作为第一特征向量集合,存储至预设数据库;其中,第一特征向量集合包括多个子集合,每个子集合中包括对应的一种预设标签的所有表征数据通过文本-图像多模态模型编码的特征向量;
通过文本-图像多模态模型,将各种模态的查询数据编码为特征向量之后,对于任一查询数据,确定出查询数据通过文本-图像多模态模型编码的特征向量与第一特征向量集合中的各个特征向量之间的相似度之前,该信息获取方法还包括:
判断是否启用聚类加速功能;
若未启用,执行对于任一查询数据,确定出查询数据通过文本-图像多模态模型编码的特征向量与第一特征向量集合中的各个特征向量之间的相似度的步骤;
若启用,对第一特征向量集合中的每个子集合进行聚类,并确定出各个聚类的聚类中心;
对于任一查询数据,将第一特征向量集合中各个聚类的聚类中心中,与查询数据通过文本-图像多模态模型编码的特征向量之间的相似度按照从大到小的顺序排名前预设数量位的聚类中心所在的子集合,作为目标子集合;
对于任一查询数据,确定出查询数据通过文本-图像多模态模型编码的特征向量与各个目标子集合中的各个特征向量之间的相似度;
执行对于预设数据库中任一实体,将本次通过实体的表征数据对应的特征向量确定出的所有相似度的数值之和,作为实体的打分值的步骤。
为了更好地对本发明实施例进行说明,请参考图2,图2为本发明提供的另一种信息获取方法的流程示意图,其中,最左侧一列指的是五类模态的表征数据,基于文旅领域的多源异构的多模态数据,其中多模态数据主要包含文本、图像、视频、音频、地图等。①首先采用知识图谱构建的流程对文本和表格类数据进行知识图谱构建。②然后进行多模态知识扩展,将多模态的数据对齐到知识图谱实体上,实现知识集成。(也即图中的多模态知识扩展)③然后采用基于多模态预训练语言模型的方法对多模态知识进行向量化表示和跨模态对齐(也即通过文本-图像多模态模型对表征数据的编码,对应图2中的多模态知识融合)。④然后在应用阶段,用户输入拍照的图像数据或者文本数据都可以进行混合特征匹配(基于多模态的查询数据进行的实体匹配,对应图2中的混合特征匹配),基于本发明提出的文本增强的图像检索技术。⑤当模型在计算过程中,面临大数据的问题,采用基于K-means聚类(K均值聚类算法)的向量加速技术(也即本发明中的聚类加速功能,对应图2中的基于聚类的向量加速检索),从而将效率提升数百倍。从而返回知识图谱中的对应实体的标识信息。⑥基于返回的实体知识图谱,用户可以进行个性化提问,基于提示学习的技术对问题进行编码,基于预训练语言模型(也即人工智能问答模型)的理解能力多模态实体知识图谱中返回对应答案,整个计算过程可以在AI(人工智能)服务器中完成(对应图2中最右侧一列的包含提示学习以及预训练语言模型在内的多模态实体问答模块)。
具体的,在计算各个查询数据与第一特征向量集合中的各个特征向量的过程中,考虑到第一特征向量集合中特征向量数量较多,因此耗费时间较长,且很多特征向量的相似度较差,理论上无需计算,因此为了提升计算速度,本发明实施例中可以首先对第一特征向量集合中的特征向量进行聚类,以便筛选距离较近的聚类,而为了进一步提升计算速度,本发明实施例中可以通过各个特征向量的所属的表征数据的预设标签,对位于第一特征向量集合中的各个特征向量进行分类,也即分类为多个子集合,每个子集合中包括对应的一种预设标签的所有表征数据通过文本-图像多模态模型编码的特征向量,然后针对每个子集合中的特征向量首先进行聚类,然后确定出与查询数据距离较近的聚类中心,针对距离较近的聚类展开相似度计算即可,很大程度的降低了数据计算量,提升了信息获取效率。
其中,考虑到根据预设数据库中数据量的多少可以适应性的选择聚类加速功能的开启与否,因此本发明实施例中在通过文本-图像多模态模型,将各种模态的查询数据编码为特征向量之后,可以首先判断是否启用聚类加速功能,如果未启用,则可以执行对于任一查询数据,确定出查询数据通过文本-图像多模态模型编码的特征向量与第一特征向量集合中的各个特征向量之间的相似度的步骤,也即对于第一特征向量集合中的特征向量进行全面的相似度计算。
其中,预设数量可以进行自主设定,本发明实施例在此不做限定。
具体的,聚类加速功能的具体原理介绍如下:
对于响应速度提升的问题,本发明提出一种高效的向量数据搜索算法。先前的工作直接基于所有的向量进行相似度计算,然而在数据量比较大的情况下,直接暴力搜索效率太低。数据库中的每个向量都要参与计算,会导致计算资源的浪费。对于无法一次性载入GPU(Graphics Processing Unit,图形处理器)的情况,还需要将向量分批次载入GPU,造成巨大的计算开销。
本发明提出一种多模态特征加速聚类方法:
(1)首先本发明将不同标签类型(预设标签)的特征向量分别进行组织,例如根据知识图谱中的实体标签,将同类标签实体多模态特征向量(例如图片特征向量)放在一起处理,这样有利于精细化的聚类,使得聚类中心能够区分同类的目标差异。
(2)采用主成分分析(PCA)方法进行所有的特征降维,从而降低聚类方法的计算代价。
(3)基于降维后的特征进行聚类,针对每个标签类别分别执行K-means聚类算法,将每类实体的向量聚类为m
对所有智慧文旅多模态向量数据进行离线的K-means聚类,总共聚为m簇,然后以每一个簇的中心点代表该簇。在向量检索时,可以先找到top-k(距离最近的前k个)目标簇,然后进行簇内检索。大大节省了计算量。原始的计算复杂度为O(n),改进之后的计算复杂度为
例如,以100万个多模态向量为例,原始的对比方法需要对比100万次,与每个样本进行对比。经过聚类为200个簇,每个簇有5000个样本。通过距离对比选择top-2最接近的簇,仅需要计算200次,2个簇总共包含10000个样本,需要对比计算10000次,总共计算10200次即可实现检索过程,大约提升了100倍的计算速度,效率提升非常明显,通过调节簇的数量,效率还可以进一步提升。
作为一种优选的实施例,对第一特征向量集合中的每个子集合进行聚类包括:
通过K均值聚类算法对第一特征向量集合中的每个子集合进行聚类。
具体的,K均值聚类算法具有处理速度快以及精度高等优点。
当然,除了K均值聚类算法外,聚类算法还可以为其他多种类型,本发明实施例在此不做限定。
作为一种优选的实施例,预设标签包括表征数据的数据模态。
具体的,数据模态能够清晰的划分各个表征数据。
当然,除了数据模态外,预设标签还可以为其他类型,本发明实施例在此不做限定。
作为一种优选的实施例,对第一特征向量集合中的每个子集合进行聚类之前,该信息获取方法还包括:
通过主成分分析法,对第一特征向量集合中的所有特征向量进行降维处理。
具体的,为了进一步降低计算量并提升信息获取效率,本发明实施例中还可以在聚类前通过主成分分析法,对第一特征向量集合中的所有特征向量进行降维处理。
当然,除了主成分分析法外,降维处理还可以通过其他方法进行,本发明实施例在此不做限定。
作为一种优选的实施例,确定出属于目标领域内的多个实体,并将其作为待存储实体包括:
通过爬虫技术从互联网中爬取属于目标领域内的多个实体,并将其作为待存储实体;
针对每个待存储实体,获取待存储实体多个指定模态的表征数据包括:
针对每个待存储实体,通过爬虫技术从互联网中爬取待存储实体多个指定模态的表征数据。
具体的,为了提升预设数据库中实体以及对应的指定模态的表征数据的获取效率,本发明实施例中可以通过爬虫技术从互联网中爬取这些内容。
当然,除了该具体方式外,预设数据库中实体以及对应的指定模态的表征数据的获取方式还可以为其他多种类型,本发明实施例在此不做限定。
请参考图3,图3为本发明提供的一种信息获取装置的结构示意图,该信息获取装置包括:
第一获取模块31,用于获取预先构建的包含目标领域内各个实体的表征数据的预设数据库;
第二获取模块32,用于通过人机交互接口获取描述同一实体的多种模态的查询数据;
确定模块33,用于基于各种模态的查询数据以及预设数据库内各个实体的表征数据,通过相似度检测算法确定出查询数据描述的实体,并将其作为目标实体;
推送模块34,用于将目标实体的标识信息推送至人机交互接口。
对于本发明实施例提供的信息获取装置的介绍请参照前述的信息获取方法的实施例,本发明实施例在此不再赘述。
请参考图4,图4为本发明提供的一种信息获取设备的结构示意图,该信息获取设备包括:
存储器41,用于存储计算机程序;
处理器42,用于执行计算机程序51时实现如前述实施例中信息获取方法的步骤。
对于本发明实施例提供的信息获取设备的介绍请参照前述的信息获取方法的实施例,本发明实施例在此不再赘述。
本发明还提供了一种服务器,包括如前述实施例中的信息获取设备。
对于本发明实施例提供的服务器的介绍请参照前述的信息获取方法的实施例,本发明实施例在此不再赘述。
本发明还提供了一种服务器集群,包括至少一台如前述实施例中的服务器。
对于本发明实施例提供的服务器集群的介绍请参照前述的信息获取方法的实施例,本发明实施例在此不再赘述。
请参考图5,图5为本发明提供的一种计算机可读存储介质的结构示意图,该计算机可读存储介质50上存储有计算机程序51,计算机程序51被处理器42执行时实现如前述实施例中信息获取方法的步骤。
对于本发明实施例提供的计算机可读存储介质的介绍请参照前述的信息获取方法的实施例,本发明实施例在此不再赘述。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。还需要说明的是,在本说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 电子设备的显示控制方法、装置、电子设备和存储介质
- 电子设备控制方法及装置、电子设备及存储介质
- 数据分布存储方法、装置、存储介质及电子设备
- 存储清理方法、装置、电子设备及存储介质
- 多版本数据存储管理方法及装置、电子设备、存储介质
- 可变刷新率动态补偿方法、装置、电子设备及存储介质
- 屏幕刷新率的控制方法、装置、电子设备及可读存储介质