基于时空注意力机制的车辆轨迹预测方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于车辆轨迹预测技术领域,具体涉及一种基于时空注意力机制的车辆轨迹预测方法及系统。
背景技术
在交通管理、无人驾驶、安防监控等领域中,车辆轨迹预测具有广泛应用,是实现智能交通的关键技术之一。在目标追踪场景中,车辆轨迹预测可以结合目标检测和跟踪技术,对目标车辆的位置、速度、加速度等信息进行实时预测,从而实现目标车辆的自动追踪。
在目标追踪过程中,由于遮挡、光照变化、运动模式的突然变化等多种原因,目标可能会脱离监控范围。由于仅仅基于摄像头和雷达等传感器进行追踪,监控范围受限,不能完全掌握目标车辆的移动情况。本发明基于GPS定位技术对目标车辆进行监控,记录大量时空轨迹数据,以此动态预测车辆的未来路径。本发明聚焦于道路网络上的车辆轨迹预测,通过实时监控道路上的目标车辆轨迹,根据历史轨迹预测其未来轨迹,及时找回脱离监控视野的目标车辆,实现运动目标的持续追踪。
车辆轨迹预测方法通常基于传统机器学习方法和深度学习方法。传统机器学习方法包括支持向量机、决策树、随机森林等。这些方法通常使用历史轨迹和环境信息等特征作为输入,预测目标车辆的未来运动轨迹。虽然它们通常具有较高的预测精度,但需要手工设计特征,且不易扩展到复杂的场景。随着深度学习技术的发展,基于深度学习的车辆轨迹预测方法逐渐成为主流。这些方法使用卷积神经网络、长短时记忆网络、自注意力网络等模型对历史轨迹进行建模,并预测目标车辆的未来运动轨迹。与传统方法相比,基于深度学习的方法无需手工设计特征,可以自动学习特征表示,且预测精度更高。
目前,现有的方法主要集中于下一个位置的预测,这样的模型不适于长期序列预测。并且,由于没有考虑不同路段之间的连接关系,基于现有的方法进行预测得到的路段序列准确率较低。因此,城市道路网络中的车辆轨迹预测仍然是一个具有挑战性的问题。
发明内容
基于现有技术中存在的上述缺点和不足,本发明的目的是提供一种基于时空注意力机制的车辆轨迹预测方法及系统。首先,将道路网络中的路段表示为有向图,将车辆轨迹映射成道路网络中的路段序列,并对序列进行划分,输入到模型中。然后,嵌入层将道路路段映射成空间向量,输入路段和邻接路段构成局部道路网络图,通过图注意力网络获取道路网络中的空间特征。Transformer对输入序列分配不同的权重,提取其中的时间特征。最后,结合局部道路网络结构图,对输出序列进行过滤,获得连续的轨迹序列,以实现车辆的轨迹预测。
为了达到上述发明目的,本发明采用以下技术方案:
一种基于时空注意力机制的车辆轨迹预测方法,包括以下步骤:
S1、采集车辆轨迹数据集并对车辆轨迹数据集的车辆轨迹数据进行预处理;
S2、将预处理之后的车辆轨迹数据通过地图匹配算法进行地图映射得到路段序列,并对路段序列进行分割得到数个子路段序列;
其中,每个子路段序列的长度为L,子路段序列的前K部分作为输入序列,子路段序列的后L-K部分作为输出序列;所有子路段序列随机打乱,划分为训练集、验证集和测试集;
S3、利用训练集和验证集对轨迹预测模型进行训练,得到目标轨迹预测模型;
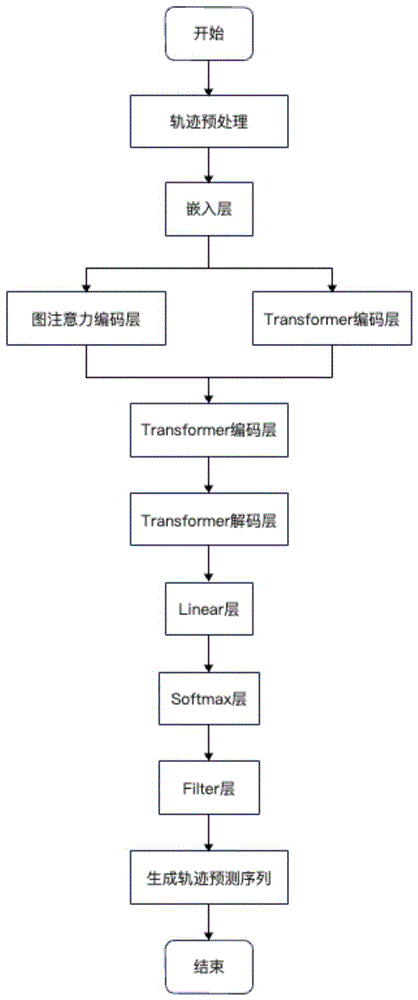
其中,轨迹预测模型包括嵌入层、图注意力编码层、第一Transformer编码层、第二Transformer编码层、Transformer解码层、Linear层、Softmax层和Filter层,输入序列输入嵌入层转换为特征向量,特征向量分别输入图注意力编码层、第一Transformer编码层以提取得到空间特征和时间特征,将空间特征和时间特征聚合后输入第二Transformer编码层以进一步得到输入序列的特征,然后输入Transformer解码层生成轨迹预测序列,预测序列依次经过Linear层、Softmax层和Filter层,得到输出序列;
S4、利用测试集将待预测车辆的车辆轨迹数据通过地图匹配算法进行地图映射得到目标路段序列,之后输入目标轨迹预测模型进行轨迹预测。
作为优选方案,所述步骤S1中,预处理包括数据清洗、过滤和压缩。
作为优选方案,所述步骤S2中,地图匹配算法采用Fast Map Matching算法;
将车辆轨迹数据集和道路网络作为输入,预先计算出道路网络中特定长度内的所有最短路径对,并存储在UBODT表中;UBODT表中的每一行存储从起始节点n
当第i条路径的起始节点n
当第i条路径的起始节点n
由此得到道路网络中每一路段的邻居路段信息,构建道路网络的有向图,即路段序列。
作为优选方案,所述步骤S2中,K>L-K。
作为优选方案,所述图注意力编码层采用注意力机制,为不同的邻居节点分配不同的权重,计算每个图节点的特征;
图注意力编码层的输入为h={h
其中,LeakyReLU为非线性激活函数,a∈R
在对注意力系数归一化之后,图注意力层节点i的输出为
作为优选方案,所述第一Transformer编码层包括多头注意力机制和前馈神经网络两个子层,多头注意力机制层用于对输入序列中的每个位置进行编码,并捕捉序列中不同位置之间的依赖关系;
在多头注意力机制层中,输入序列首先经过多个注意力头的独立变换,然后将所有注意力头的输出拼接起来,通过线性变换生成该位置的上下文表示;
多头注意力机制层的输出作为前馈神经网络层的输入,通过包含两个全连接层的前馈神经网络层进行处理,得到前馈神经网络层的最终输出。
作为优选方案,所述Transformer解码层通过内部的注意力机制逐步输出每个目标路段,每个路段的位置信息在解码层中通过添加位置编码确定;在确定位置编码之后,Transformer解码层逐个输出解码结果。
作为优选方案,所述Linear层对Transformer解码层的输出向量进行线性变换,并映射至道路网络中路段数量的维度;将Linear层的输出结果输入Softmax层,进行归一化处理;Filter层根据交通网络的有向图G
邻接向量W
当路段i与路段j有连接时,i和j之间的权重为1,否则为0;邻接向量W
作为优选方案,所述车辆轨迹数据通过GPS传感器采集。
本发明还提供一种基于时空注意力机制的车辆轨迹预测系统,应用如上任一项方案所述的车辆轨迹预测方法,所述车辆轨迹预测系统包括:
采集模块,用于采集车辆轨迹数据集以及待预测车辆的车辆轨迹数据;
预处理模块,用于对车辆轨迹数据进行预处理;
地图匹配模块,用于将预处理之后的车辆轨迹数据通过地图匹配算法进行地图映射得到路段序列;
分割模块,用于对路段序列进行分割得到数个子路段序列;
划分模块,用于划分输入序列、输出序列、训练集、验证集和测试集;
训练模块,用于利用训练集和验证集对轨迹预测模型进行训练,得到目标轨迹预测模型;
预测模块,用于利用将目标路段序列输入目标轨迹预测模型进行轨迹预测。
本发明与现有技术相比,有益效果是:
本发明的基于时空注意力机制的车辆轨迹预测方法及系统,预测的车辆轨迹精度高。
附图说明
图1为方法执行流程图;
图2为路段邻居信息提取过程的示意图;
图3为部分道路结构图;
图4为Transformer编码层结构图;
图5为经过Filter层的结果表示图;
图6为北京道路网络图;
图7为成都道路网络图。
具体实施方式
为了更清楚地说明本发明实施例,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
本发明实施例的基于时空注意力机制的车辆轨迹预测方法的执行流程图请参阅图1,包括以下步骤:
S1、采集车辆轨迹数据集并对车辆轨迹数据集的车辆轨迹数据进行预处理;
S2、将预处理之后的车辆轨迹数据通过地图匹配算法进行地图映射得到路段序列,并对路段序列进行分割得到数个子路段序列;
其中,每个子路段序列的长度为L,子路段序列的前K部分作为输入序列,子路段序列的后L-K部分作为输出序列;所有子路段序列随机打乱,划分为训练集、验证集和测试集;
S3、利用训练集、验证集和测试集对轨迹预测模型进行训练,得到目标轨迹预测模型;
其中,轨迹预测模型包括嵌入层、图注意力编码层、第一Transformer编码层、第二Transformer编码层、Transformer解码层、Linear层、Softmax层和Filter层,输入序列输入嵌入层转换为特征向量,特征向量分别输入图注意力编码层、第一Transformer编码层以提取得到空间特征和时间特征,将空间特征和时间特征聚合后输入第二Transformer编码层以进一步得到输入序列的特征,输入序列的特征输入Transformer解码层生成轨迹预测序列,预测序列依次经过Linear层、Softmax层和Filter层,得到输出序列;
S4、将待预测车辆的车辆轨迹数据通过地图匹配算法进行地图映射得到目标路段序列,之后输入目标轨迹预测模型进行轨迹预测。
具体地,本发明实施例的基于时空注意力机制的车辆轨迹预测方法的执行流程如下:
步骤(1):轨迹预处理,在原始数据集中,车辆轨迹数据是通过GPS传感器获得,原始数据是包含有噪声的GPS记录。这些记录中,有的前后点之间距离过大,有的车辆轨迹记录太短,有的出现位置停滞。大多数车辆都在前往目的地的过程中,在数据处理过程中,要剔除掉偏差过大的异常数据、轨迹时间长度太短的数据以及由于出租车中途休息导致位置停滞的数据等不满足实验要求的数据。
为了获得一系列路段的序列,需要将GPS记录映射到道路网络上。地图匹配算法能够从有噪声的GPS轨迹推断得到道路网络上的路径。为此,本发明使用了一个开源的地图匹配框架,快速地图匹配(Fast Map Matching,FMM)。该算法是一种结合隐马尔可夫模型和预计算的快速地图匹配算法。它将GPS轨迹集和道路网络作为输入,预先计算出道路网络中特定长度内的所有最短路径对,并存储在UBODT(Upper Bounded Origin DestinationTable)表中。UBODT表中的每一行存储了从起始节点n
如图2所示,当第i条路径的起始节点n
在GPS记录经过地图匹配算法转换得到路段序列之后,将路段序列进行分割,划分为多个子路段序列。每个子路段序列长度为12,前8个为输入序列,后4个为输出序列。这些子路段序列被随机打乱,划分成训练集、验证集和测试集。
步骤(2):时空特征提取,通过地图映射得到的道路路段序列不能直接输入到神经网络中,神经网络无法对其进行直接处理。在对原始轨迹预处理之后,嵌入层将输入的道路序列映射到稠密的连续型特征空间中,以便于捕获序列中的特征信息。路段序列中的每一个路段v
图注意编码层通过为不同节点分配不同的重要性来聚合邻居的信息,不依赖于完整的图结构,能处理动态图。如图3所示,不同的道路有不同的邻接路段。图注意力网络处理图数据结构,采用注意力机制,为不同的邻居节点分配不同的权重,计算每个图节点的特征。图注意力层的输入为h={h
其中,LeakyReLU为非线性激活函数,a∈R
在对注意力系数归一化之后,图注意力层节点i的输出为
Transformer编码层如图4所示,其包括多头注意力机制Multi-Head Attention和前馈神经网络Feed Forward两个子层。多头注意力机制是基于自注意力机制实现的,能够对输入序列中的每个位置进行编码,并捕捉序列中不同位置之间的依赖关系。在多头注意力机制中,输入序列首先经过多个注意力头的独立变换,然后将所有注意力头的输出拼接起来,通过线性变换生成该位置的上下文表示。自注意力机制能够对所有位置进行并行计算,有效地处理序列特征。多头自注意力机制层的输出将作为前馈神经网络层的输入,通过一个包含两个全连接层的前馈神经网络进行处理,得到前馈神经网络层的最终输出。
步骤(3):未来轨迹预测,最后一层Transformer编码层的输出序列被传递到Transformer解码层中进行解码。解码层通过内部的注意力机制逐步输出每个目标路段,每个路段的位置信息可以在解码层中通过添加位置编码确定。在确定位置编码之后,解码层会逐个输出解码结果。虽然编码层和解码层都使用了自注意力机制,但他们的操作方式略有不同。为了能够逐个输出目标序列,解码层的自注意力对后续位置进行了隐藏。解码层将学习到的特征表示输入到与编码层相同的前馈神经网络,以获得更大维度的加权特征向量。
解码层输出的结果经由Linear层、Softmax层和Filter层处理后,输出预测序列。Linear层对编码器的输出向量进行线性变换,并映射至道路网络中路段数量的维度。将输出结果输入Softmax层,进行归一化处理。经过步骤(1)提及的数据预处理之后,我们得到了表示交通网络的有向图G
当路段i与路段j有连接时,i和j之间的权重为1,否则为0。邻接向量W
基于上述车辆轨迹预测方法,本发明实施例还提供基于时空注意力机制的车辆轨迹预测系统包括以下功能模块:
采集模块,用于采集车辆轨迹数据集以及待预测车辆的车辆轨迹数据;
预处理模块,用于对车辆轨迹数据进行预处理;
地图匹配模块,用于将预处理之后的车辆轨迹数据通过地图匹配算法进行地图映射得到路段序列;
分割模块,用于对路段序列进行分割得到数个子路段序列;
划分模块,用于划分输入序列、输出序列、训练集、验证集和测试集;
训练模块,用于利用训练集和验证集对轨迹预测模型进行训练,得到目标轨迹预测模型;
预测模块,用于利用测试集将目标路段序列输入目标轨迹预测模型进行轨迹预测。
上述功能模块的具体过程可参考上述车辆轨迹预测方法中的具体描述,在此不赘述。
为了验证本发明提出的模型性能,在两个真实的车辆轨迹数据集上进行了大量实验,分别是北京出租车轨迹数据集和成都出租车轨迹数据集,数据集结构如下表1和表2所示。
表1北京数据集
表2成都数据集
北京出租车轨迹数据集:该项目包含北京市2008年2月2日至2008年02月8日期间10357辆出租车的一周轨迹。每个数据记录包括车辆ID、时间、经度和纬度的信息。本文从OpenStreetMap获得了边界范围为[39.74,40.10,116.14,116.80]的道路网络结构,由46859个路口节点和109314个路段组成,如图6所示。
成都出租车轨迹数据集:该数据集包含成都市2014年8月3日至2014年8月13日13605名出租车司机通过智能手机收集得到的11天数据。每个GPS数据记录描述了特定时间和地点的出租车承载情况,包括时间、车辆ID、占用状态、经度和纬度等信息。实验中,本文以[30.29,31.04,103.26,104.61]为边界范围获取了OpenStreetMap上的道路网络结构,由83483个路口节点和203578个路段组成,如图7所示。
在实验中,本发明以距离误差(Distance Error,DE)和平均匹配率(AverageMatch Ratio,AMR)作为评价指标评估车辆轨迹预测模型的预测性能。
距离误差(DE):预测轨迹和实际轨迹之间的平均编辑距离。编辑距离常用于通过计算将一个序列转换为另一个序列所需的最小操作数来量化两个序列之间的相似性。DE的公式定义为:
其中,N
平均匹配率(AMR):正确预测的路段数量与预测轨迹长度的平均比率。AMR公式定义为:
其中,v′
本发明使用的深度学习框架是Pytorch,模型的输入轨迹序列长度为8,输出序列长度为4。实验过程中,本文使用Adam优化器优化训练过程,初始学习率设置为0.5,采用线性学习率衰减,权重衰减值设置为0.01,batch大小为100,丢弃率为0.1,迭代的epoch大小为40。
本模型的主要实验结果如下表3所示。
表3不同模型的对比实验结果
本发明以LSTM Encoder-Decoder和Transformer为基线模型,通过与基线模型进行比较来评估本文提出的方法的性能。在北京数据集上,TPred(为本方法简称,下同)的AMR值达到了73.07%,比LSTM Encoder-Decoder和Transformer分别提高了37.45%和6.38%。而在成都数据集上,TPred的AMR值则达到了78.93%,相较于LSTM Encoder-Decoder和Transformer分别提高了36.06%和10.55%。可以观察到,对于两个数据集,本文所提出的方法都比基线模型具有更好的性能。
以上所述仅是对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。
- 一种基于LSTM和时空注意力机制的车辆轨迹预测方法
- 一种基于LSTM和时空注意力机制的车辆轨迹预测方法