基于相似度度量的类案判别方法及系统
文献发布时间:2024-04-18 19:58:26
技术领域
本文件涉及智慧检务领域,尤其涉及一种基于相似度度量的类案判别方法及系统。
背景技术
由于过往案件数量庞大、种类繁多,在查找相似案例时耗时耗力,缺乏智能化手段以协助当事人提高获取相似案例效率。
因此,基于人工智能的案件相似度计算方法研究具有重要的意义。
发明内容
本说明书提供了一种基于相似度度量的类案判别方法,用以解决过往案件数量庞大、种类繁多,在查找相似案例时耗时耗力,缺乏智能化手段以协助当事人提高获取相似案例效率的问题。
本发明的第一方面,提出了一种基于相似度度量的类案判别方法,所述类案判别方法包括:
步骤S10,基于已判定案件文书的案由、案件情节、判决依据、法院综述、法条,抽取案件判别的要素标签;
步骤S20,通过SpanBERT方法对待判别案件文本进行人称指代消解,并基于所述要素标签进行不同类别的要素文本抽取;
步骤S30,基于抽取的要素文本进行待处理案件文本的单篇章构图,并通过图神经网络计算所述单篇章构图与已判定案件构图的相似度;
步骤S40,以相似度值大于设定阈值的已判定案件的类别,作为待判别案件的类别。
在一些优选的实施例中,步骤S30中基于抽取的要素文本进行待处理案件文本的单篇章构图,其方法为:
将抽取的要素文本转换为one-hot向量,分别通过预训的连续词袋模型获取给定词汇表中每个词作为目标词的概率;所述连续词袋模型包括输入层、隐藏层和输出层;
以概率最大的目标词为节点进行构图,获得待处理案件文本的单篇章构图。
在一些优选的实施例中,所述连续词袋模型,其预训练方法为:
将待输入上下文词转换为one-hot向量;
将所有待输入上下文词对应的one-hot向量分别与所述连续词袋模型的输入层共享权重矩阵相乘,获得输入向量;
以各输入向量的加权平均值作为所述连续词袋模型的隐藏层向量;
将所述隐藏层向量与所述连续词袋模型的输出层共享权重矩阵相乘,获得输出向量;
通过Softmax函数进行所述输出向量的分类,并通过预设的损失函数计算分类获取的预测标签与真实标签之间的损失值;
基于所述预设的损失函数进行所述连续词袋模型的梯度优化训练,获得预训练的连续词袋模型。
在一些优选的实施例中,所述连续词袋模型,所述输入层共享权重矩阵和所述输出层共享权重矩阵为通过随机初始化生成的嵌入矩阵。
在一些优选的实施例中,步骤S30中通过图神经网络计算所述单篇章构图与已判定案件构图的相似度,其方法为:
通过图神经网络分别计算所述单篇章构图中任一节点与所述已判定案件构图中多个节点间的相似性;
将各相似性转换为交叉图匹配向量,并基于所述交叉图匹配向量的值获取所述单篇章构图与已判定案件构图的相似度。
在一些优选的实施例中,所述节点间的相似性,其表示为:
其中,f
在一些优选的实施例中,所述相似性度量的跨图信息传递函数,其表示为:
其中,s
在一些优选的实施例中,所述交叉图匹配向量,其表示为:
在一些优选的实施例中,所述单篇章构图与已判定案件构图的相似度,其判别方法为:
判断所述交叉图匹配向量,若其趋向为0向量,则所述单篇章构图与已判定案件构图的相似度趋向于完全相同。
本发明的另一方面,提出了一种基于相似度度量的类案判别系统,所述类案判别系统包括:
要素标签抽取模块,配置为基于已判定案件文书的案由、案件情节、判决依据、法院综述、法条,抽取案件判别的要素标签;
要素文本抽取模块,配置为通过SpanBERT方法对待判别案件文本进行人称指代消解,并基于所述要素标签进行不同类别的要素文本抽取;
相似度计算模块,配置为基于抽取的要素文本进行待处理案件文本的单篇章构图,并通过图神经网络计算所述单篇章构图与已判定案件构图的相似度;
案件类别判定模块,配置为以相似度值大于设定阈值的已判定案件的类别,作为待判别案件的类别。
本说明书实施例采用的上述至少一个技术方案能够达到以下有益效果:
(1)本发明基于相似度度量的类案判别方法,通过分析裁判文书案例,确定特征要素。采用语义依存分析技术,分析句子各个语言单位之间的语义关联,将语义关联以依存结构呈现,实现要素信息抽取,本发明方法跨越句子表层句法结构的束缚,获取深层的语义信息,有效提升后续类案判别的准确性和精度。
(2)本发明基于相似度度量的类案判别方法,基于要素施事者的裁判文书进行案例图构建,采用人称指代消歧方法,统一案件中的原告、被告人信息,将抽取的要素文本按照施事者区分,构造三级异构文本图,最后通过图神经网络计算各案件文本图事件相似度,得到案件相似度打分,实现案件类别判定。
(3)本发明基于相似度度量的类案判别方法,提高了长文本相似度计算的准确性,以更好地求解司法案例之间的相似度,为实现适用司法案例推荐提供算法基础,为当事人正在面临的案件寻找适合的司法案例提供参考。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
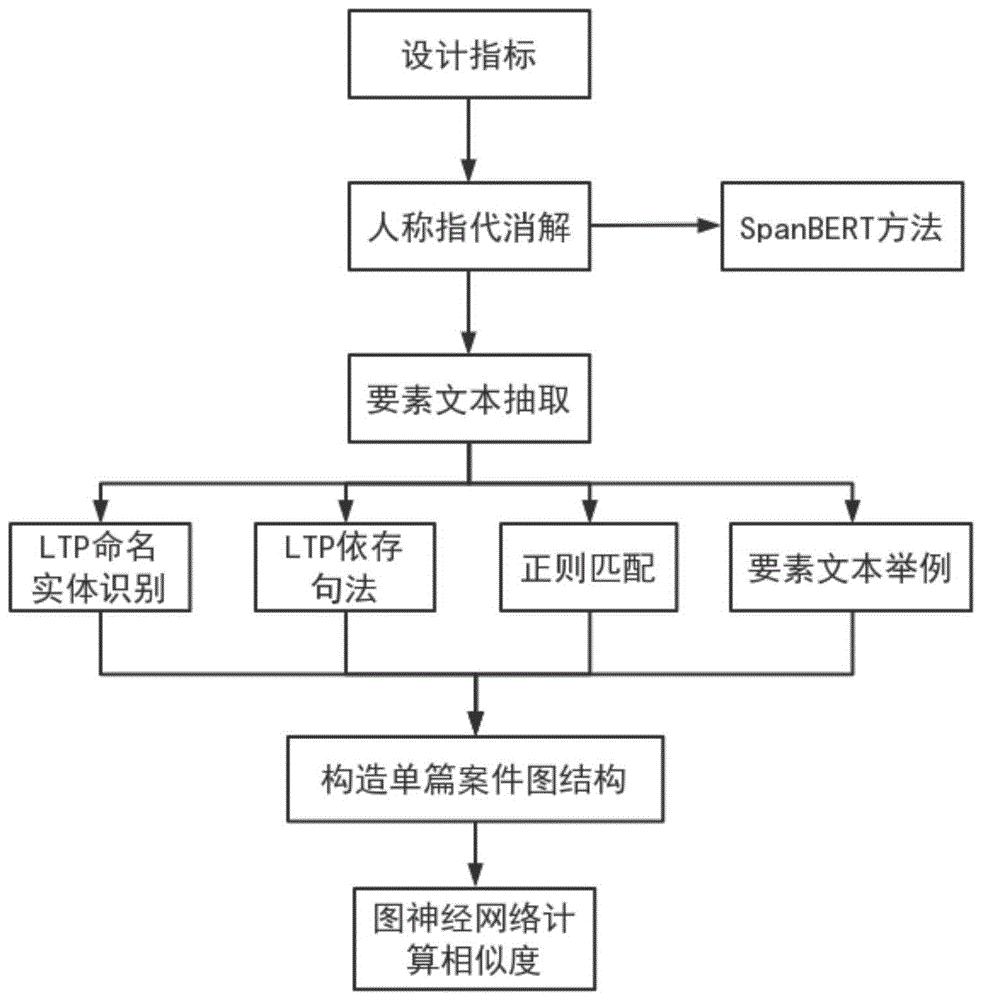
图1为本说明书一实施例提供的一种基于相似度度量的类案判别方法的流程示意图;
图2为本说明书一实施例提供的SpanBERT框架示意图;
图3为本说明书一实施例提供的单篇章构图示意;
图4为本说明书一实施例提供的CBOW模型的结构示意图;
图5为本说明书一实施例提供的CBOW模型的训练权重示意图;
图6为本说明书一实施例提供的图相似度计算示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本发明基于相似度度量的类案判别方法,更好地满足向当事人推荐相似案例的需求,解决传统方法中当事人不知道该选用哪些案例作为参考的问题,为实现类案推荐提供算法基础。类案推荐的目的为当事人面临的案件寻找适用的相似案例,为当事人处理当事案件提供过往案件以作参考。
语义依存分析(Semantic Dependency Parsing,SDP),是分析句子各个语言单位之间的语义关联,并将语义关联以依存结构呈现。使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇,而论元的数目相对词汇来说数量总是少了很多的。语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。同时,语义依存分析不受句法结构的影响,将具有直接语义关联的语言单元直接连接依存弧并标记上相应的语义关系。
BERT(Bidirectional Encoder Representations from Transformers)已被证明是一种非常强大的方法,可以显著提高各种自然语言处理任务的性能,尤其是在自然语言理解任务中具有非常显著的优势,而文本分类本质上也是一种自然语言理解任务。本发明一个实施例中,采用BERT的变种SpanBERT进行文本分类。
SpanBERT是一个pre-training method,它被用于更好地表示和预测spans oftext。它是对BERT的一种拓展,这个拓展主要分为两个方面:
首先,与BERT中对random tokens进行mask不同,SpanBERT所提出的模型是对contiguous random spans进行mask。
其次,对span boundary representations进行训练,从而让它(在不依赖于masked tokens的representations的时候)可以对masked span中的所有内容进行预测。
以下结合附图,详细说明本申请各实施例提供的技术方案。
图1为本说明书一实施例提供的一种基于相似度度量的类案判别方法的流程示意图,所述方法具体可以包括如下步骤:
首先是指标设计及数值化。根据已判案件文书中案由、案件情节、判决依据、法院综述、依据法条等,设计需要抽取的要素标签。
其次是对法律事实叙述文本预处理,如通过人称指代消解算法,统一文本中的“原告”和“被告”指代。
然后是根据之前定义的要素标签,对不同类别要素文本进行抽取。本发明一个实施例中,采用哈工大LTP自然语言处理工具进行命名实体识别句法分析,以及采用正则匹配等方法抽取要素文本。
再次是对待判别案件进行单篇章构图。
最后是将单篇章构图输入图神经网络,计算单篇章构图与已判定案件构图的相似度,以相似度值大于设定阈值的已判定案件的类别,作为待判别案件的类别。
本发明第一实施例的一种基于相似度度量的类案判别方法,参见图1,包括:
步骤S10,基于已判定案件文书的案由、案件情节、判决依据、法院综述、法条,抽取案件判别的要素标签。
本发明设计了一套指标体系来描述案件,作为案件的特征用于相似度计算。指标的选取准则为:能够尽可能地表示该案由,同时能够区分其他的案由。
以房租租赁纠纷为例,由《中华人民共和国民法典》第七百零三条对租赁合同的定义:租赁合同是出租人将租赁物交付收益,承租人支付租金的合同。关于房屋租赁合同涉及的相关法律法规有:《中华人民共和国民法典》自2021年1月1日起施行;《中华人民共和国城市房地产管理法》自1995年1月1日起施行,2019年8月26日修改;部门规章住房和城乡建设部《商品房屋租赁管理办法》2011年2月1日起施行司法解释;《最高人民法院关于审理城镇房屋租赁合同纠纷案件具体应用法律若干问题的解释》法释〔2009〕11号,2020年12月23日修改,于2021年1月1日施行法释〔2020〕17号。
房屋租赁合同的形式由《民法典》第七百零七条规定:租赁期限六个月以上的,应当采用书面形式。当事人未采用书面形式,无法确定租赁期限的,视为不定期租赁。租赁合同的核心内容为:《民法典》第七百零四条称租赁合同的内容一般包括租赁物的名称、数量、用途、租赁期限、租金及其支付期限和方式、租赁物维修等条款。
步骤S20,通过SpanBERT方法对待判别案件文本进行人称指代消解,并基于所述要素标签进行不同类别的要素文本抽取。
人称代词的消解是自然语言处理中十分重要的问题。人称代词消解,就是确定人称代词与先行语之间的相互关系,从而明确人称代词究竟指代什么对象。现有的许多应用系统,如文本摘要、信息抽取等采取了从文本中直接抽取句子的做法,而结果可能会含有某些无先行语的人称代词,使理解变得非常困难。人称代词消解无疑可以解决类似的问题。本发明主要结合句类基本知识,根据人称代词所在语义块中的语义角色和人称代词对应的先行语判断可能的语义角色,给出了消解人称代词的基本规则;同时,本发明也从句法的角度,结合局部焦点法给出了优选性规则。
图2为本说明书一实施例提供的SpanBERT框架示意图,参照图2,本发明通过SpanBERT方法进行人称指代消解,包括:
(1)对random contiguous spans(而不是randomindividual tokens)进行mask。
(2)提出了一个span-boundary objective(SBO),从而使得模型可以通过span两端boundaries处的observed tokens而去让模型对整个masked span进行学习。
(3)针对每一个training example,SpanBERT将从中采样出一个contiguoussegment of text(而BERT则是采样出两个),其中本模型去掉了BERT中所含有的nextsentence prediction objective。
要素文本抽取是法律智能化辅助应用的重要基础,其目的是判别裁判文书涉及的关键案情要素。以往要素文本抽取通常采用多标签分类方法进行建模,模型主要依赖于裁判文书文本特征,忽略了要素标签的语义信息。同时,由于裁判文书数据集存在样本分布不均衡的情况,分类方法会因负例过多而导致模型性能不佳。
本发明一个实施例中,通过LTP方法进行要素文本抽取,包括:
1.LTP命名实体识别
命名实体识别(Named Entity Recognition,NER)是在句子的词序列中定位并识别人名、地名、机构名等实体的任务。
2.LTP依存句法
依存语法(Dependency Parsing,DP)通过分析语言单位内成分之间的依存关系揭示其句法结构。直观来讲,依存句法分析识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
3.正则表达式
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a到z之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
4.要素文本举例
本发明利用LTP对输入文本进行词性标注、句法结构分析,通过这两类分析推知它的要素类别,例如要素类别为“证据”的文本“被告出具一份借条”,根据LTP的词性标注,“被告”为名词,“出具”为动词,“一份”为数量词,“借条”为名词,再根据依存句法树,出具与借条之间为VOB结构,也就是动宾结构。
又比如文本“原告通过银行转账、微信和现金方式共向被告转款30万元”,同理通过LTP,可知该文本中各个词的词性:“原告”为名词,“转款”为动词,“30万”为数量词,“元”为名词,再通过依存句法树,转款与30万元构成VOB结构,也就是动宾结构,根据句法结构,可知它的要素类别为付款方式。
(1)举例一
要素类别:“证据”
要素文本:“被告出具一份借条”
语法结构:动宾结构
词性分析:“被告”为名词,“出具”为动词,“一份”为数量词,“借条”为名词。
(2)举例二
要素类别:“付款方式”
要素文本:“原告通过银行转账、微信和现金方式共向被告转款30万元”
语法结构:动宾结构
词性分析:“原告”为名词,“转款”为动词,“30万”为数量词,“元”为名词。
步骤S30,基于抽取的要素文本进行待处理案件文本的单篇章构图,并通过图神经网络计算所述单篇章构图与已判定案件构图的相似度。
图3为本说明书一实施例提供的单篇章构图示意,参照图3,本文将要素文本作为节点,构造单篇案件的图结构。各个节点采用word2vec嵌入。通过word2vec得到的训练结果——词向量(word embedding),可以很好地度量节点之间的相似性。
本发明使用word2vec的连续词袋模型(Continuous Bag-of-Words Model,以下简称CBOW),通过给定上下文词来预测中间目标词。输入为上下文词,原始的单词是无法作为输入的,这里的输入是每个词汇的one-hot向量,输出为给定词汇表中每个词作为目标词的概率,图4为本说明书一实施例提供的CBOW模型的结构示意图。图5为本说明书一实施例提供的CBOW模型的训练权重示意图,图5中标出了CBOW模型要训练的参数,本发明要训练得到输入层到隐藏层的权重以及隐藏层到输出层的权重。
连续词袋模型,其预训练方法为:
将待输入上下文词转换为one-hot向量;
将所有待输入上下文词对应的one-hot向量分别与所述连续词袋模型的输入层共享权重矩阵相乘,获得输入向量;
以各输入向量的加权平均值作为所述连续词袋模型的隐藏层向量;
将所述隐藏层向量与所述连续词袋模型的输出层共享权重矩阵相乘,获得输出向量;
通过Softmax函数进行所述输出向量的分类,并通过预设的损失函数计算分类获取的预测标签与真实标签之间的损失值;
基于所述预设的损失函数进行所述连续词袋模型的梯度优化训练,获得预训练的连续词袋模型。
连续词袋模型,所述输入层共享权重矩阵和所述输出层共享权重矩阵为通过随机初始化生成的嵌入矩阵。
本发明一个实例中,假设语料为“原告的付款方式为银行转账30万元”,以原告、银行转账30万元作为上下文词,以付款方式作为目标词。将上下文词和目标词都进行one-hot表征作为输入,然后将one-hot表征分别乘以输入层权重矩阵,这个矩阵也叫嵌入矩阵,可以随机初始化生成。然后将得到的向量结果相加求平均作为隐藏层向量。将隐藏层向量乘以输出层权重矩阵,这个矩阵也是嵌入矩阵,可以初始化得到,得到输出向量。最后对输出向量做Softmax激活处理得到实际输出,并将其与真实标签做比较,然后基于损失函数做梯度优化训练。
步骤S30中通过图神经网络计算所述单篇章构图与已判定案件构图的相似度,其方法为:
通过图神经网络分别计算所述单篇章构图中任一节点与所述已判定案件构图中多个节点间的相似性。
图形相似性搜索在数据库和数据挖掘领域得到了广泛的研究。相似性通常由精确匹配(全图或子图同构)定义或某种结构相似性度量,例如根据图形egit-distance定义。在这方面提出的大多数方法都不是以学习为基础的,而是注重效率。
图核是图上的核,用于捕获图的相似性,可用于图分类等核心方法。流行的图核包括测量图上面的“行走”或“路径”之间相似性的那些方法、基于有限大小子结构的核和基于子树结构的核。图核通常用于可能已经学习过组件的模型中,但核本身是由图论手工设计和驱动的。它们通常可以表示为首先计算每个图的特征向量(核嵌入),然后取这些向量之间的内积来计算核值。与这些方法相比,本发明的基于图神经网络的相似性学习框架能够端到端地学习相似性度量。
学习数据点之间的距离度量是度量学习领域的重点。关于度量学习的早期工作大多假设数据已经存在于向量空间中,并且只有线性度量矩阵才能正确地测量该空间中的距离,以便将相似的示例分组在一起,而将不同的示例相距很远。最近,距离度量学习和表示学习的思想被结合到诸如人脸验证等应用中,在这些应用中,学习深度卷积神经网络将相似的图像映射到相似的表示向量。本发明主要研究了图的表示和相似度量学习,通过对跨图匹配的建模,图匹配模型比典型的表示学习方法有了很大的改进。
Siamese网络是视觉相似性学习的神经网络模型中的一个家族。这些模型通常由两个网络组成,共享参数分别应用于两个输入图像来计算表示,然后使用一个小网络来融合这些表示并计算相似度得分。它们可以被认为同时学习了表示和相似性度量。Siamese网络在许多视觉识别和验证任务中取得了巨大成功。本发明使用Siamese网路来处理图,但图匹配网路更强大,因为它们会进行交叉图计算,因此会在计算过程的早期融合两个图的信息。
给定两个图G1=(V1,E1)和G2=(V2,E2),需要一个模型来生成它们之间的相似性得分s(G1,G2)。每个图G=(V,E)表示为节点V和边E的集合,每个节点i具有特征向量x
1、图嵌入模型(图内传播)
图嵌入模型将每个图嵌入到一个向量中,然后在向量空间中使用相似度度量来度量图之间的相似度。
具体来看,模型由三个部分组成:编码器,传播层,聚合器。
(1)编码器:编码器通过单独的MLP将节点和边缘特征映射到初始节点和边缘向量空间。
(2)传播层:将节点特征进行更新。
(3)聚合器:经过一定数量的T轮传播,聚合器把节点集合的特征表示作为输入,计算一个graph-level的特征表示。
它使用带gating向量的加权和,跨节点聚合点的特征。加权和可以帮助过滤出不相关的信息,它比简单的和更强大,而且在实验结果上也明显更好。
在对(G1,G2)计算图表示hG1和hG2之后,使用向量空间中的相似度量来计算它们之间的相似性,例如欧几里德相似性、余弦相似性或Hamming相似性。
2、图匹配模型(跨图传播)
图匹配模型以一对图为输入,计算它们之间的相似度。与嵌入模型相比,这些匹配模型联合计算两个图的相似度,而不是首先将每个图独立映射到一个向量。因此,这些模型可能比嵌入模型更强,但会牺牲一些额外的计算效率。
本发明创新性地提出了如下的图匹配网络,它改变了每个传播层中的节点更新模块,不仅考虑了每个图的边上的聚合消息,而且还考虑了一个跨图匹配向量,该向量测量一个图中的节点与另一个图中的一个或多个节点的匹配程度:
编码层(与图嵌入模型相同),采用多层感知机分别编码节点特征和边特征:
其中,x
传播层,利用前一层的节点表征和传播函数获取新的节点表征:
其中,f
聚合层利用T轮传播的节点表征集合和聚合函数获得图级别的表征向量:
其中,
相似性度量的跨图信息传递函数,其表示为:
其中,s
交叉图匹配向量,其表示为:
sh也是一个向量空间相似性度量,就像欧几里德或余弦相似性差不多,a
这意味着交叉图通信将减少为零向量,并且这两个图将在下一轮传播中继续计算相同的表示。另一方面,图之间的差异将被捕获在交叉图匹配向量
最终,两个长文本之间相似度计算公式为:
与图嵌入模型相比,匹配模型能够根据与之比较的其他图改变图的表示。模型将调整图形表示,使它们在不匹配时变得更加不同。
将各相似性转换为交叉图匹配向量,并基于所述交叉图匹配向量的值获取所述单篇章构图与已判定案件构图的相似度。
步骤S40,以相似度值大于设定阈值的已判定案件的类别,作为待判别案件的类别。
本发明第二实施例的基于相似度度量的类案判别系统,所述类案判别系统包括:
要素标签抽取模块,配置为基于已判定案件文书的案由、案件情节、判决依据、法院综述、法条,抽取案件判别的要素标签;
要素文本抽取模块,配置为通过SpanBERT方法对待判别案件文本进行人称指代消解,并基于所述要素标签进行不同类别的要素文本抽取;
相似度计算模块,配置为基于抽取的要素文本进行待处理案件文本的单篇章构图,并通过图神经网络计算所述单篇章构图与已判定案件构图的相似度;
案件类别判定模块,配置为以相似度值大于设定阈值的已判定案件的类别,作为待判别案件的类别。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 一种法律类案相似度判别及推送方法
- 一种法律类案相似度判别及推送方法