一种基于多层次视觉特征增强网络的视觉问答方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于计算机视觉技术领域,尤其涉及一种基于多层次视觉特征增强网络的视觉问答方法及系统。
背景技术
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
视觉问答(visual Question Answering,VQA)是将给定的图片和对应的自然语言问题交互得到最终答案的一项多模态任务。
目前大多数视觉问答模型(VQA)大致可以分为四个模块:问题编码模块,图像编码模块,跨模态融合模块和问题预测模块。问题编码模块通常使用RNN,LSTM等模型将问题嵌入到向量中;图像编码模块首先使用FasterR-CNN模型提取图像特征,然后将问题编码与图像特征相加或者连接进行联合编码和关系建模学习文本和图像之间的关系,得到联合特征。跨模态融合模块将问题编码和联合特征进行融合,最后输入到问题预测模块进行答案预测。
然而传统的视觉问答模型通常采用基于区域的自上而下的图像特征表示,使区域特征与全局特征失去上下文联系,导致视觉特征的全局语义特征无法得到充分的利用,进而影响视觉问答结果的准确率。
发明内容
为了解决上述背景技术中存在的至少一项技术问题,本发明提供一种基于多层次视觉特征增强网络的视觉问答方法及系统,通过增强图像的区域特征之间以及区域特征与全局特征之间的联系,获得更准确的视觉特征表示,更好的与问题文本进行关联,提高了视觉问答结果的准确率。
为了实现上述目的,本发明采用如下技术方案:
本发明的第一个方面提供一种基于多层次视觉特征增强网络的视觉问答方法。
一种基于多层次视觉特征增强网络的视觉问答方法,包括:
获取待回答问题和视觉图像;
对待回答问题进行特征表示,得到文本特征表示向量;对视觉图像进行特征表示,得到视觉特征表示向量;
对文本特征表示向量和视觉特征表示向量进行更新;
将更新后的文本特征表示向量和视觉特征表示向量进行融合,得到融合特征向量;
对融合特征向量先进行线性变换,然后使用Sigmoid函数得到答案预测结果;
其中,采用多层次视觉特征增强网络对视觉图像进行特征表示。
进一步地,视觉特征包含两级图像特征:像素级视觉特征和对象级视觉特征;像素级视觉特征即全局视觉特征,对象级视觉特征即区域视觉特征。
进一步地,所述多层次视觉特征增强网络由基于图注意的分离视觉特征表示网络和基于图注意的联合视觉特征表示网络组成。
进一步地,所述分离视觉特征表示网络用于分别学习全局视觉特征和各区域视觉特征;所述联合视觉特征表示网络用于捕获全局视觉特征和区域视觉特征之间的语义关系,并将浅层的细节特征与深层的语义特征相结合,生成完整的视觉特征表示向量。
进一步地,所述分离视觉特征表示网络,针对两级图像特征,设计了两个独立的语义关系增强网络:注意像素关系增强网络和注意对象关系增强网络,用于学习增强的全局视觉特征和增强的区域视觉特征。
进一步地,所述联合视觉特征表示网络包括:联合特征表示网络和联合特征融合网络。
进一步地,所述联合特征表示网络将联合特征表示放入图注意网络中学习对象级和像素级对象之间的所有的语义关系;所述联合特征融合网络采用门控融合机制进行信息的整合,得到最终的视觉特征的表示。
本发明的第二个方面提供一种基于多层次视觉特征增强网络的视觉问答系统。
一种基于多层次视觉特征增强网络的视觉问答系统,包括:
问答获取模块,获取待回答问题和视觉图像;
特征表示模块,对待回答问题进行特征表示,得到文本特征表示向量;对视觉图像进行特征表示,得到视觉特征表示向量;
更新模块,对文本特征表示向量和视觉特征表示向量进行更新;
融合模块,将更新后的文本特征表示向量和视觉特征表示向量进行融合,得到融合特征向量;
预测模块,对融合特征向量先进行线性变换,然后使用Sigmoid函数得到答案预测结果;
其中,采用多层次视觉特征增强网络对视觉图像进行特征表示。
本发明的第三个方面提供一种计算机可读存储介质。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的基于多层次视觉特征增强网络的视觉问答方法中的步骤。
本发明的第四个方面提供一种计算机设备。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述所述的基于多层次视觉特征增强网络的视觉问答方法中的步骤。
与现有技术相比,本发明的有益效果是:
本发明提出了一种多层次视觉特征增强方法,能够增强局部对象与局部对象之间以及区域对象与全局概念之间的关系,从而共同学习多个空间上下文的视觉语义关系。基于图注意网络的分离视觉特征模块用以捕获像素级视觉特征和对象级区域特征;基于图注意网络的联合视觉特征表示将像素级特征与对象级特征联合表示,同时学习了不同层次之间的语义关系,更好的与问题文本进行关联,从而提供了更丰富的视觉特征表示。解决了传统视觉特征表示使区域特征与全局特征失去上下文之间的联系,使得全局语义无法得到充分的利用,导致视觉特征丢失的问题。
本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
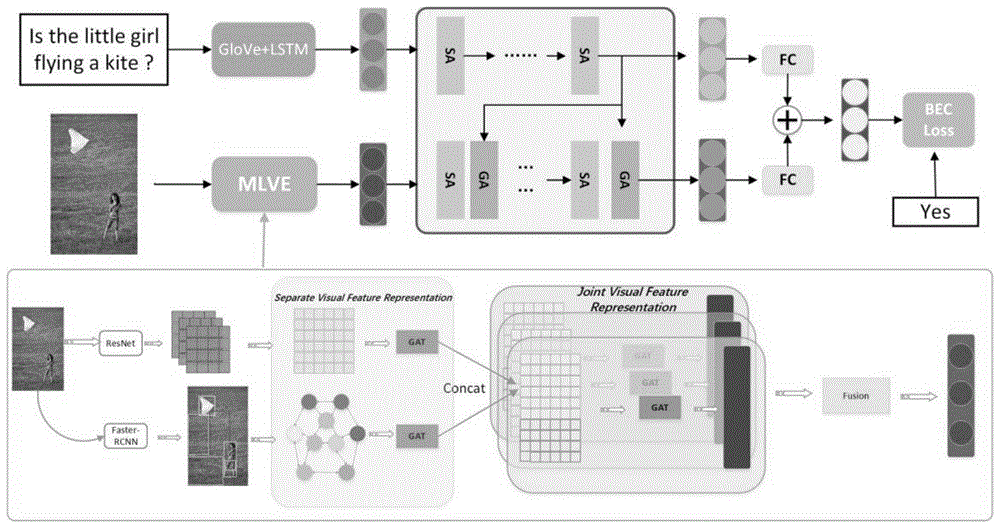
图1是本发明实施例方法的整体框架图。
图2是本发明实施例的协同注意力网络结构。
图3是本发明实施例的VQA2.0数据集在模型上的消融实验示意图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
实施例一
参照图1,本实施例一种基于多层次视觉特征增强网络的视觉问答方法,其具体包括如下步骤:
S1.获取待回答问题和视觉图像;
S2.对待回答问题进行特征表示,得到文本特征表示向量;对视觉图像进行特征表示,得到视觉特征表示向量;
S3.对文本特征表示向量和视觉特征表示向量进行更新;
S4.将更新后的文本特征表示向量和视觉特征表示向量进行融合,得到融合特征向量;
S5.对融合特征向量先进行线性变换,然后使用Sigmoid函数得到答案预测结果;
其中,步骤S2中采用多层次视觉特征增强网络对视觉图像进行特征表示。
所述的多层次视觉特征增强网络由分离视觉特征表示网络和联合视觉特征表示网络组成,分离视觉特征表示网络用于分别学习全局视觉特征和各区域视觉特征;联合视觉特征表示网络用于捕获全局视觉特征和区域视觉特征之间的语义关系,并将浅层的细节特征与深层的语义特征相结合,生成完整的视觉特征表示向量,浅层的细节特征指捕获的局部视觉特征,深层的语义特征指部视觉特征与全局特征之间的联系。
S2.1:对于问题的文本特征表示,本发明使用Glove模型和GRU模型进行特征表示。
首先是问题文本预处理,根据空格和标点符号将问题分割成单词形式;其次将问题包含的单词数填充或截断到相同长度N;再使用Glove模型进行词嵌入;最后将词嵌入输入到GRU网络获得语言特征表示。
S2.2:对于视觉特征表示,本发明使用多层次视觉特征增强网络进行特征表示,将原始图像表示为两级图像特征:像素级视觉特征和对象级视觉特征,像素级视觉特征即全局视觉特征,对象级视觉特征即区域视觉特征。
其中视觉信息处理主要包含两个模块:基于图注意网络的分离视觉特征表示模块,旨在学习对象级语义关系;基于图注意网络的联合视觉特征表示模块,旨在捕获对象与全局之间的关系。
(1)两级图像特征表示
设置原始图像I,分别提取全局特征G和基于区域的局部级特征R。
全局特征:从ImageNet【37】上预训练的ResNet152【38】的最后一个全连接层中提取全局特征
局部特征:从ImageNet【37】数据集上预训练的Faster R-CNN,主骨架网络为ResNet-101,检测图像中的目标特征提取局部特征表示为:
在他们之后加入一个全连接层,使其嵌入到共享的潜在空间。
V
其中W
最后得到两次图像特征表示:全局视觉特征:
(2)基于图注意网络的分离视觉表示模块
针对两级图像特征,设计了两个独立的语义关系增强模型,用于学习增强的全局图像特征,即像素关系和增强的局部图像特征,即对象关系。具体来说,分为注意像素关系增强网络、注意对象关系增强网络。
(2-1)注意像素关系增强网络
对于像素关系增强,本发明采用图注意力网络来捕获逐像素之间的关系。
首先,用全局视觉特征V
其中,
其次,使用图注意网络模块表示全局视觉语义关系增强特征
其中,GAT表示图注意网络模块;G
本模块主要决定了每个像素受到其他像素影响的程度,其表现形式为对应像素在图像中具有更高的注意力值,从而促进了逐像素之间的学习。
(2-2)注意对象关系增强网络
对于对象关系的增强,本发明采用图注意网络来捕获区域对象之间的关系。
首先,构架一个全连接图G
/>
其中,
其次使用图注意力网络处理对象图,图中包含对象特征及其关系,最终输出对象语义关系增强的区域表示特征,结果如下所示:
本模块主要决定了对象与对象之间的相互影响程度,其表现形式为对应对象在图像中具有更高的注意力值,从而促进对象之间的学习。
(3)基于图注意网络的联合视觉特征表示模块
本模块主要展示联合视觉特征的表示,采用多头图注意力机制来进行对象和像素之间的信息整合,其中的融合过程有助于融合多头输入特征,过滤无用的信息,如图2中所示。具体来说分为两部分:联合特征表示模块和联合特征融合模块。
(3-1)联合特征表示模块
对于联合特征表示,采用将联合特征表示放入图注意网络中学习对象级和像素级对象之间的所有的语义关系。
首先,将特征增强的像素级和对象级特征
其中,
然后,联合图注意力表示,图注意模型的输入是上述的联合特征,因此这个结构可以帮助对象或像素学习基于所有对象和像素的注意力值。
为了稳定自注意力的学习过程,本发明使用多头注意力机制,如图1所示,将G
其中,GAT
本模块通过联合注意力表示,学习了无论全局还是区域对象之间的所有独立元素之间的语义关系。
(3-2)联合特征融合
对于联合特征融合,本发明采用门控融合机制进行信息的整合,得到最终的视觉特征的表示。
将上述得到的多头注意力特征表示V
其中,W和U表示全连接层参数,σ表示Sigmiod函数;W
由于K值的不同,我们设置了不同的融合机制。
k=1,不需要特征融合,最后的图像特征表示为:
k=2两个GAT图的融合特征
k=4
其中F
步骤S3中,将上述提取的文本向量和视觉向量传入协同注意力网络中,通过协同共注意力网络使得文本向量和视觉向量进行自我注意建模以及使用两个基本注意力单元的模块化组合对视觉进行引导注意力,最终得到带有注意力的新的视觉和文本的特征向量。
其中协同注意网络的基本的组件为模块化协同注意力(MCA)层,它由两个基本注意力单元的模块化组成,即自注意力单元(SA)和导向注意力单元(GA)。SA单元由一个多头注意力层和一个测点前馈层组成,用于学习同一个模态内的各个样本之间的关系。GA单元结构与SA单元相似,用一种模态来指导另一种模态,用于表示不同模态之间的特征关系。
步骤S4中,将更新后的文本和视觉特征经过哈达玛积方式进行融合,得到融合特征向量。
步骤S5中,将融合特征经过线性变换后,将融合特征经过线性变换得到变换后的维度为d的特征向量,然后将维度d的特征向量转换为维度为N的候选答案。通过Sigmoid函数得到答案预测结果,Sigmoid函数常被用作神经网络的阈值函数,将变量映射到0,1之间。阈值越高与答案的匹配程度越高。使用二元交叉熵(BCE)作为损失函数训练分类问题,用于评判二分模型预测结果的好坏程度,损失函数如公式:
其中N为多分类中类型的数目,a′
实验结果评估
本实施例在VQA2.0数据集上对模型进行了评估。
(1)数据集
VQA2.0数据集是VQA任务中常用的基准数据集,它是由MSCOCO中的自然图像组成,并添加了相应的人工注释的问题和答案。每幅图片对应3个问题,每个问题对应10个答案。数据集的划分为:训练集包含80K图像和444K问题答案对;验证集包含40K图像和214问题答案对;测试集包含80K图像和448K问题。其中,测试集包含2个测试子集test-dev和test-standard用于在线评估模型性能。
(2)实验结果评估
表1显示了在test-dev和test-std上的在线评估实验结果。从表1中可以看出,对于早期的BUTD、MFH等模型的方法在VQA2.0数据集总体(overall)准确率提高了5.9%;对于最近的DSACA、MEDAN、MCAN等模型,本文的方法在数据集上的各项指标分别有0.47%~1.6%,0.11%~1.81%,0.07%~9.32%,0.12%~1.14%的提升。这是因为本方法在建模过程中从多个层次考虑视觉特征的表示。通过对全局特征和局部特征的相互补充学习,加强了视觉表示中区域对象和全局对象之间的关系,同时也学习了各个对象本身之间的相互关系。本方法通过多层次视觉特征增强的方法保障了信息提取的完整性、准确性。其中由于BAN+Counter方法中有专门的对象计数模块,即数字类型,因此他的计数类的准确率表现得更好。
Table 1本方法在VQA2.0数据集上与当前主要视觉问答模型的准确率比较
(3)消融实验
为了分析模型中的每个部分的贡献和作用,对提出的模型在VQA2.0数据集上进行了广泛的消融实验,从而证明了每个模块的有效性。对于视觉特征表示部分,有两条路径,一条是全局视觉特征表示,另一条是局部视觉特征表示。因此对于消融实验的研究分为以下几类:1)仅使用全局特征表示路径2)、仅使用局部视觉特征表示、3)、同时使用两条路经进行视觉特征表示。结果如table2所示,其中,“Regional”:表示全局视觉特征表示;”Global”:表示局部视觉特征表示;‘SRR’:表示分离视觉特征表示;“JRR”:表示联合视觉特征表示。
如表2第1-4行表示,仅使用单一路径进行图像特征表示,即仅仅使用局部或者全局视觉特征表示。实验结果显示,分离视觉特征表示(SRR)的使用显著提高了性能,从而证明SSR的有效性,旨在学习像素级全局关系或对象级区域关系。第2-7行表示使用两条路径进行图像特征表示。通过分离视觉特表示模块和联合视觉特征表示的两级视觉特征表示,对视觉问答模型的性能有显著的促进作用,这验证了通过这两个模块可以学习多层次的图像语义信息,从而提取更完整的视觉特征表示,最终提高视觉问答的整体性能。
Table 2模型消融实验
替代方案:可使用其他合理方法,如基于其他深度学习的特征融合算法,基于交叉模态相似性的特征融合算法等来进行特征融合过程。
实施例二
本实施例提供了一种基于多层次视觉特征增强网络的视觉问答系统,包括:
问答获取模块,获取待回答问题和视觉图像;
特征表示模块,对待回答问题进行特征表示,得到文本特征表示向量;对视觉图像进行特征表示,得到视觉特征表示向量;
更新模块,对文本特征表示向量和视觉特征表示向量进行更新;
融合模块,将更新后的文本特征表示向量和视觉特征表示向量进行融合,得到融合特征向量;
预测模块,对融合特征向量先进行线性变换,然后使用Sigmoid函数得到答案预测结果;
其中,采用多层次视觉特征增强网络对视觉图像进行特征表示。
实施例三
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述实施例一所述的基于多层次视觉特征增强网络的视觉问答方法中的步骤。
实施例四
本实施例提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例一所述的基于多层次视觉特征增强网络的视觉问答方法中的步骤。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于复杂网络分析方法的视觉问答问题解决方法
- 一种基于视觉反馈的TDI-CCD相机双目视觉系统视场对齐方法
- 一种基于视觉特征的网页关键内容检测系统及方法
- 一种基于跨模态预训练特征增强的视觉问答方法
- 一种多层次视觉特征描述方法和视觉检索系统