一种场景文本检测方法及系统
文献发布时间:2023-06-19 09:44:49
技术领域
本发明涉及机器视觉技术领域,尤其涉及一种场景文本检测方法及系统。
背景技术
自然场景文本检测技术作为场景文本识别任务中的关键一环,其在计算机视觉应用场景中得到广泛的应用,如自动驾驶技术、无人超市和交通标志识别等。场景文本检测方法在各种文本系统中也发挥着重要的作用。然而,与一般目标检测相比,自然场景文本的检测更加复杂:(1)存在着字体、颜色、形状、方向和比例等各种文本变化的内部情况,使得算法无法进行精确的文本定位检测;(2)在自然场景中还存在光线照明程度不一和场景文本遮挡等外部实际情况,同样会使得自然场景文本检测具有很大的挑战性。
发明内容
本发明要解决的技术问题目的在于提供一种场景文本检测的模型训练方法及检测方法,用以解决原有网络结构检测不全面不精确的问题。
为了实现上述目的,本发明采用的技术方案为:
一种场景文本检测方法,包括步骤:
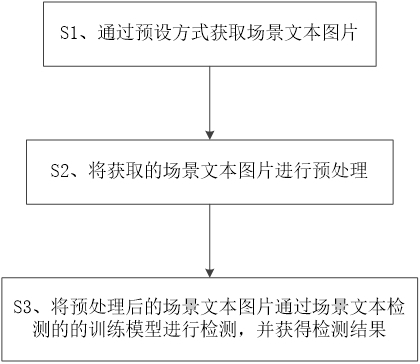
S1、通过预设方式获取场景文本图片;
S2、将获取的场景文本图片进行预处理;
S3、将预处理后的场景文本图片通过场景文本检测的训练模型进行检测,并获得检测结果。
进一步的,步骤S3中获得训练模型的具体步骤为:
S31、通过预设方式获取场景文本图片,并建立数据集;
S32、将数据集中的场景文本图片进行处理;
S33、将预处理后的场景文本图片通过富特征结构网络Res2NeXt和混合池化进行训练,并得到训练模型。
进一步的,步骤S33的具体步骤为:
S331、从场景文本图片中获取多个单一层次的特征图;
S332、将多个单一层次的特征图分别通过混合池化获取特征图中不同类型的上下文信息以及不同位置之间的距离依赖关系;
S333、将混合池化后的特征图进行预设方式的融合得到不同层次的特征图;
S334、将不同层次的特征图合并得到融合特征图;
S335、将融合特征图通过渐进式尺度扩展算法得到预测场景文本图片;
S336、对得到的预测场景文本图片进行训练并得到训练模型。
进一步的,步骤S331具体过程为:
将场景文本图片按顺序通过第一卷积层和第二卷积层进行卷积后再进行相加,然后将其相加后的结果再通过第三卷积层卷积,将通过第三卷积层输出的结果与输入的图像进行相加得到第一层次特征图,将第一层次特征图重复经过上述过程,得到多个单一层次的特征图;
进一步的,步骤S332包括步骤:
S3321、将不同层次的特征图输入到混合池化模块中;
S3322、将输入的特征图分别进行带状池化和金字塔池化;
S3323、将分别经过带状池化和金字塔池化的特征图融合得到包含有不同类型的上下文信息以及不同位置之间的距离依赖关系的特征图。
一种场景文本检测系统,包括:
图片采集模块,通过预设方式获取场景文本图片;
图片预处理模块,将获取的场景文本图片进行预处理;
图片检测模块,将预处理后的场景文本图片通过场景文本检测的训练模型进行检测,并获得检测结果。
进一步的,图片检测模块包括:
图片获取与存储单元,通过预设方式获取场景文本图片,并建立数据集;
图片处理单元,将数据集中的场景文本图片进行处理;
训练单元,通过处理后的场景文本图片对富特征结构网络Res2NeXt和混合池化进行训练,并得到训练模型。
进一步的,图片训练单元包括:
特征图获取单元,用于从场景文本图片中获取多个单一层次的特征图;
混合池化单元,用于将多个单一层次的特征图分别通过混合池化单元获取特征图中不同类型的上下文信息以及不同位置之间的距离依赖关系;
融合单元,用于将混合池化后的特征图进行预设方式的融合得到不同层次的特征图;
特征图合并单元,将不同层次的特征图合并得到融合特征图;
图片文本预测单元,用于将融合特征图通过渐进式尺度扩展算法得到预测场景文本图片;
特征训练单元,用于通过得到的预测场景文本图片进行训练并得到训练模型;
进一步的,混合池化单元包括:
特征图输入子单元,用于将不同层次的特征图输入到混合池化单元中;
池化子单元,用于将输入的特征图分别进行带状池化和金字塔池化;
池化融合子单元,用于将分别经过带状池化和金字塔池化的特征图融合得到包含有不同类型的上下文信息以及不同位置之间的距离依赖关系的特征图。
本发明与现有技术相比,至少包含以下有益效果:
(1)采用富特征结构网络Res2NeXt代替原PSENet主干网络ResNet以提高网络特征提取能力,从而提高网络的文本检测精度;
(2)在主干网路中合适位置添加混合池化,利用其不同内核形状的池化操作来收集有用的上下文信息,同时捕获不同位置之间的长短距离之间的依赖关系从而进一步提高网络文本检测精度。
附图说明
图1是本发明实施例一的总体流程图;
图2是本发明实施例一中步骤S3的流程图富;
图3是本发明实施例一中特征结构网络的架构示意图;
图4是本发明实施例一中步骤S331的示意图;
图5是本发明实施例一中步骤S332的流程图;
图6是本发明实施例一混合池化模块组成结构示意图;
图7是本发明实施例一混合池化模块的实验结果示意图;
图8 是本发明实施例二的总体流程图;
图9是本发明实施例二的实验结果示意图。
具体实施方式
以下是本发明的具体实施例,并结合附图对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
实施例一
如图1所示,本发明一种场景文本检测方法,包括步骤:
一种场景文本检测方法,其特征在于,包括步骤:
S1、通过预设方式获取场景文本图片;
S2、将获取的场景文本图片进行预处理;
S3、将预处理后的场景文本图片通过场景文本检测的的训练模型进行检测,并获得检测结果。
其中,如图2所示,步骤S3中获得训练模型的具体步骤为:
S31、通过预设方式获取场景文本图片,并建立数据集;
S32、将数据集中的场景文本图片进行处理;
S33、将预处理后的场景文本图片通过富特征结构网络Res2NeXt和混合池化进行训练,并得到训练模型。
进一步的,如图3所示,步骤S33的具体步骤为:
S331、从场景文本图片中获取多个单一层次的特征图;
S332、将多个单一层次的特征图分别通过混合池化模块获取特征图中不同类型的上下文信息以及不同位置之间的距离依赖关系;
S333、将混合池化后的特征图进行预设方式的融合得到不同层次的特征图;
S334、将不同层次的特征图合并得到融合特征图;
S335、将融合特征图通过渐进式尺度扩展算法得到预测场景文本图片;
S336、对得到的预测场景文本图片进行训练并得到训练模型。
如图4所示,步骤S331具体过程为将场景文本图片按顺序通过第一卷积层和第二卷积层进行卷积后再进行相加,然后将其相加后的结果再通过第三卷积层卷积,将通过第三卷积层输出的结果与输入的图像进行相加得到第一层次特征图,将第一层次特征图重复经过上述过程,得到多个单一层次的特征图;
ResNeXt是ResNet和Inception的结合体,它的本质是分组卷积,通过变量基数c来控制组的数量,即每个分支产生的特征图的通道数为n(我们令输入通道数为m,变量基数表示为c,则有m=n×c,n>1)。
在ResNeXt网络中的每一个残差模块中添加一个小的残差块,具体为采用更小的滤波器组替换ResNeXt网络中m个信道的滤波器,每个滤波器组都有n个信道(在不考虑损失通用性的情况下,我们令m=n×s)。同时将不同的滤波器组以残差的分层方式进行连接以获得更多的不同尺度特征信息,有效提高模型性能。
具体为经过卷积后,我们将特征映射平均分为s个特征映射子集,表示为
在Res2Net module中,可以看到其进行了多尺度处理并将不同尺度信息通过卷积进行了融合,有效处理了特征信息,将Res2Net module运用在ResNeXt网络上,有利于全局和局部信息的提取,有效提高了网络的特征提取能力,从而提高了模型的文本检测精度。
进一步的,如图5所示,步骤S332包括步骤:
S3321、将不同层次的特征图输入到混合池化中;
S3322、将输入的特征图分别进行带状池化和金字塔池化;
S3323、将分别经过带状池化和金字塔池化的特征图融合得到包含有不同类型的上下文信息以及不同位置之间的距离依赖关系的特征图。
其中,如图6所示,带状池化的具体过程为输入一个大小C×H×W的特征图,然后将输入的特征图经过水平和竖直的带状池化后变为C×H×1和C×1×W的特征图,随后经过卷积核大小为3的1×1卷积并进行扩展后再进行对应相同位置求和,经过ReLu函数和卷积核大小为3的3×3卷积得到C×H×W的特征图。
金字塔池化的具体过程为输入一个大小C×H×W的特征图,经过金字塔池化后变为C×H×W、C×20×20以及C×12×12的特征图,随后经过卷积核大小为3的3×3卷积并进行扩展后再进行对应相同位置求和,经过ReLu函数和卷积核大小为3的3×3卷积得到C×H×W的特征图。
将通过带状池化得到的C×H×W的特征图和通过金字塔池化得到的C×H×W的特征图进行融合,并将融合后的特征图通过卷积核大小为1的1×1卷积后和输入的特征图通过ReLu函数融合后的到经过混合池化模块后包含有不同类型的上下文信息以及不同位置之间的距离依赖关系的特征图。
混合池化模块在带状池化的基础上组合了金字塔池化,其中图5下半部分为带状池化,它不同于全局平均池化,不需要考虑整个特征图范围,只需考虑长而窄的范围,避免了除远距离位置之间的其它连接。
因此,带状池化主要负责长距离依赖关系,而在图5的上半部分为金字塔池化,金字塔池化负责短依赖关系。
最终,混合池化通过使用不同的池化操作得到不同类型的上下文信息,同时捕捉不同位置之间的短距离和长距离依赖关系,使特征表示更具区分性,增强场景分析能力,进一步提高了网络的检测精度。
步骤S33中将混合池化后的特征图融合得到不同层次的特征图的具体过程为:如图2所示,首先对特征图P5进行上采样,使其能够与混合池化后的特征图Stage3进行融合,就能够得到特征图P4,然后按上述相同操作依次能够得到特征图P3和P2,因为特征图P2~P5之间的通道数不同,特征图P2~P5就是所需的不同层次的特征图。
将特征图P2~P5扩展到相同尺度进行合并就能得到融合后的特征图。
图7为混合池化和带状池化分别在主干网络上的性能比较,其中“SP”表示在Res2NeXt网络上添加带状池化,“MPM”表示在Res2NeXt网路上添加混合池化,从图中可以看出在主干网络中添加混合池化后各项网络性能指标都有所改进,表明了在主干网络中添加混合池化能够进一步提高网络的模型性能。
本发明采用富特征结构网络Res2NeXt代替原PSENet主干网络ResNet以提高网络特征提取能力,从而提高网络的文本检测精度。
并且在主干网路中合适位置添加混合池化,利用其不同内核形状的池化操作来收集有用的上下文信息,同时捕获不同位置之间的长短距离之间的依赖关系从而进一步提高网络文本检测精度。
实施例二
如图8所示,本发明一种场景文本检测系统,包括:
图片采集模块,通过预设方式获取场景文本图片;
图片预处理模块,将获取的场景文本图片进行预处理;
图片检测模块,将预处理后的场景文本图片通过场景文本检测的训练模型进行检测,并获得检测结果。
进一步的,图片检测模块包括:
图片获取与存储单元,通过预设方式获取场景文本图片,并建立数据集;
图片处理单元,将数据集中的场景文本图片进行处理;
训练单元,通过处理后的场景文本图片对富特征结构网络Res2NeXt和混合池化进行训练,并得到训练模型。
进一步的,图片训练单元包括:
特征图获取单元,用于从场景文本图片中获取多个单一层次的特征图;
混合池化单元,用于将多个单一层次的特征图分别通过混合池化单元获取特征图中不同类型的上下文信息以及不同位置之间的距离依赖关系;
融合单元,用于将混合池化后的特征图进行预设方式的融合得到不同层次的特征图;
特征图合并单元,将不同层次的特征图合并得到融合特征图;
图片文本预测单元,用于将融合特征图通过渐进式尺度扩展算法得到预测场景文本图片;
特征训练单元,用于通过得到的预测场景文本图片进行训练并得到训练模型;
进一步的,混合池化单元包括:
特征图输入子单元,用于将不同层次的特征图输入到混合池化单元中;
池化子单元,用于将输入的特征图分别进行带状池化和金字塔池化;
池化融合子单元,用于将分别经过带状池化和金字塔池化的特征图融合得到包含有不同类型的上下文信息以及不同位置之间的距离依赖关系的特征图。
如图9所示,其中左侧一列展示的是图像原图,中间一列为原PSENet网络进行检测的结果,最右侧一列为本发明的检测结果;从图中可以看到,本发明相比于现有的PSENet网络的检测结果,在文本检测的精确度上更高。
本发明采用富特征结构网络Res2NeXt代替原PSENet主干网络ResNet以提高网络特征提取能力,从而提高网络的文本检测精度。
本发明在主干网路中合适位置添加混合池化,利用其不同内核形状的池化操作来收集有用的上下文信息,同时捕获不同位置之间的长短距离之间的依赖关系从而进一步提高网络文本检测精度。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 一种基于文本中心区域扩增的藏汉双语场景文本检测方法
- 一种基于非局部网络的自然场景文本检测方法和系统