用于检测生理事件的装置和方法
文献发布时间:2023-06-19 10:58:46
相关申请
本申请要求于2018年6月14日提交的美国临时申请号62/684,871的优先权,其全部内容通过引用整体并入本文。
技术领域
本文公开的装置和方法涉及生理事件的检测。特别地,描述了一种用于获取声音和运动数据以检测生理事件的方法和装置。
背景技术
咳嗽用于清除来自呼吸道的分泌物,并且是维持生命的重要生理保护反射。在患有诸如中风、脊髓损伤和神经肌肉疾病的脑损伤的患者中,咳嗽受损会显著增加危及生命的肺炎的风险。同样,最近从机械通气中解放出来的危重患者有减少咳嗽的风险。
咳嗽还传达有关呼吸道病理生理学的信息,并且与不同疾病相关联的咳嗽可能具有不同类型的特性。例如,与百日咳相关联的咳嗽具有特性品质。通常,咳嗽可能被称为干咳或湿咳,当在其他数据的背景下进行评估时,它们可能会提供关于患者疾病的附加信息。
另外,呼吸系统产生各种呼吸声音,包括呼吸音和附加音。这些呼吸声可能在例如肺部、气管和口腔中生成。虽然某些呼吸声是常见的,并且不会引起警报,但其他声音(诸如噼啪声、喘息声、喘鸣声和干罗音)可能指示呼吸问题。这些异常呼吸声的识别和表征在为患者提供护理方面可能很重要。
诸如在咳嗽和异常呼吸声期间由体内器官生成的声音信号被发送到皮肤,从而引起皮肤振动。听诊器被设计为通过检测皮肤振动来捕获身体声音。当前,由医疗专业人员采用听诊器来通过听取身体声音并识别与特定疾病相关联的模式来帮助诊断疾病。然而,听诊器的这种使用受到数据采集的偶发性质以及人类声音灵敏度和模式识别的限制。电子听诊器被开发成对声音信号进行数字放大并有助于模式识别,但是数据采集仍然受其偶发性质的限制。由于听诊器的重量和缺乏适当的、可穿戴的设计,因此电子听诊器不适合连续监视活跃用户。
计算机处理的进步导致对身体声音的计算机化分析以识别疾病状态的研究。这些研究典型地在可控的环境中进行,在那里传感器用于捕获身体声音以进行计算机化分析。
另外,已知使用诸如加速度计的可穿戴运动传感器来监视各种运动,诸如行走。
发明内容
在一个方面,一种方法包括从用户穿戴的可穿戴设备的至少一个传感器接收运动数据。该方法还包括从可穿戴设备的至少一个传感器接收音频数据,该音频数据表示从用户的呼吸系统发出的声音。该方法还包括将运动数据与运动数据标准进行比较。该方法还包括将音频数据与音频数据标准进行比较。该方法还包括基于运动数据与运动数据标准的比较以及音频数据与音频数据标准的比较,确定用户是否咳嗽。
在另一方面,一种方法包括从用户穿戴的可穿戴设备的至少一个传感器接收运动数据。该方法还包括从可穿戴设备的至少一个传感器接收音频数据,该音频数据表示从用户的呼吸系统发出的声音。该方法还包括将音频数据与音频数据标准进行比较。该方法还包括基于音频数据与音频数据标准的比较来识别异常呼吸声音。该方法还包括确定异常呼吸声音的发生率。该方法还包括基于运动数据评估用户的活动水平。该方法还包括确定用户所遭受的状况是改善还是恶化。
在另一方面,一种方法包括从用户穿戴的可穿戴设备的至少一个传感器接收运动数据。该方法还包括从可穿戴设备的至少一个传感器接收音频数据,该音频数据表示从用户的呼吸系统发出的声音。该方法还包括将音频数据与音频数据标准进行比较。该方法还包括基于音频数据与音频数据标准的比较来识别异常呼吸声音。该方法还包括基于运动数据确定异常呼吸声音是在呼吸循环的吸气部分期间还是在呼吸循环的呼气部分期间发生。
在另一方面,一种方法包括从用户穿戴的可穿戴设备的至少一个传感器接收运动数据。该方法还包括从可穿戴设备的至少一个传感器接收音频数据,该音频数据表示从用户的呼吸系统发出的声音。该方法还包括基于运动数据来计算用户的胸壁运动。该方法还包括基于音频数据确定用户肺部中的气流。该方法还包括基于胸壁运动和气流来计算用户呼吸循环的潮气量。
在另一方面,可穿戴设备包括:至少一个传感器,其被配置为响应于用户的运动而生成运动数据;至少一个传感器,其被配置为响应于从用户的呼吸系统发出的声音而生成音频数据;以及处理器。该处理器可操作以将运动数据与运动数据标准进行比较,并将音频数据与音频数据标准进行比较。处理器还可操作以基于运动数据与运动数据标准的比较以及音频数据与音频数据标准的比较来确定用户是否咳嗽。
在另一方面,可穿戴设备包括:至少一个传感器,其被配置为响应于用户的运动而生成运动数据;至少一个传感器,其被配置为响应于从用户的呼吸系统发出的声音而生成音频数据;以及处理器。该处理器可操作以将运动数据与运动数据标准进行比较,并将音频数据与音频数据标准进行比较。处理器还可操作以基于音频数据与音频数据标准的比较来识别异常呼吸声音。处理器还可操作以确定异常呼吸声音的发生率。处理器还被配置为基于运动数据来评估用户的活动水平。处理器还被配置为确定用户所遭受的状况是改善还是恶化。
在另一方面,可穿戴设备包括:至少一个传感器,其被配置为响应于用户的运动而生成运动数据;至少一个传感器,其被配置为响应于从用户的呼吸系统发出的声音而生成音频数据;以及处理器。处理器可操作以将音频数据与音频数据标准进行比较。处理器还可操作以基于音频数据与音频数据标准的比较来识别异常呼吸声音。处理器还可操作以基于运动数据确定异常呼吸声音是在呼吸循环的吸气部分期间还是在呼吸循环的呼气部分期间发生。
在另一方面,可穿戴设备包括:至少一个传感器,其被配置为响应于用户的运动而生成运动数据;至少一个传感器,其被配置为响应于从用户的呼吸系统发出的声音而生成音频数据;以及处理器。处理器可操作以基于运动数据来计算用户的胸壁运动。处理器还可操作以基于音频数据来确定用户肺部中的气流。处理器还可操作以基于胸壁运动和气流来计算用户呼吸循环的潮气量。
附图说明
图1A是根据第一示例性实施例的可穿戴设备的分解图。
图1B是根据第一示例性实施例的隔膜、隔膜密封件和底部壳体/胸件配件的分解图。
图2A-图2H是在图1A中示出的可穿戴设备的各个组件的透视图。
图3是根据示例性实施例的图2C中示出的电子组件的侧视图。
图4是根据示例性实施例的身体声音采集电路的框图。
图5是根据示例性实施例的传感器的框图。
图6是根据示例性实施例的数据处理单元的框图。
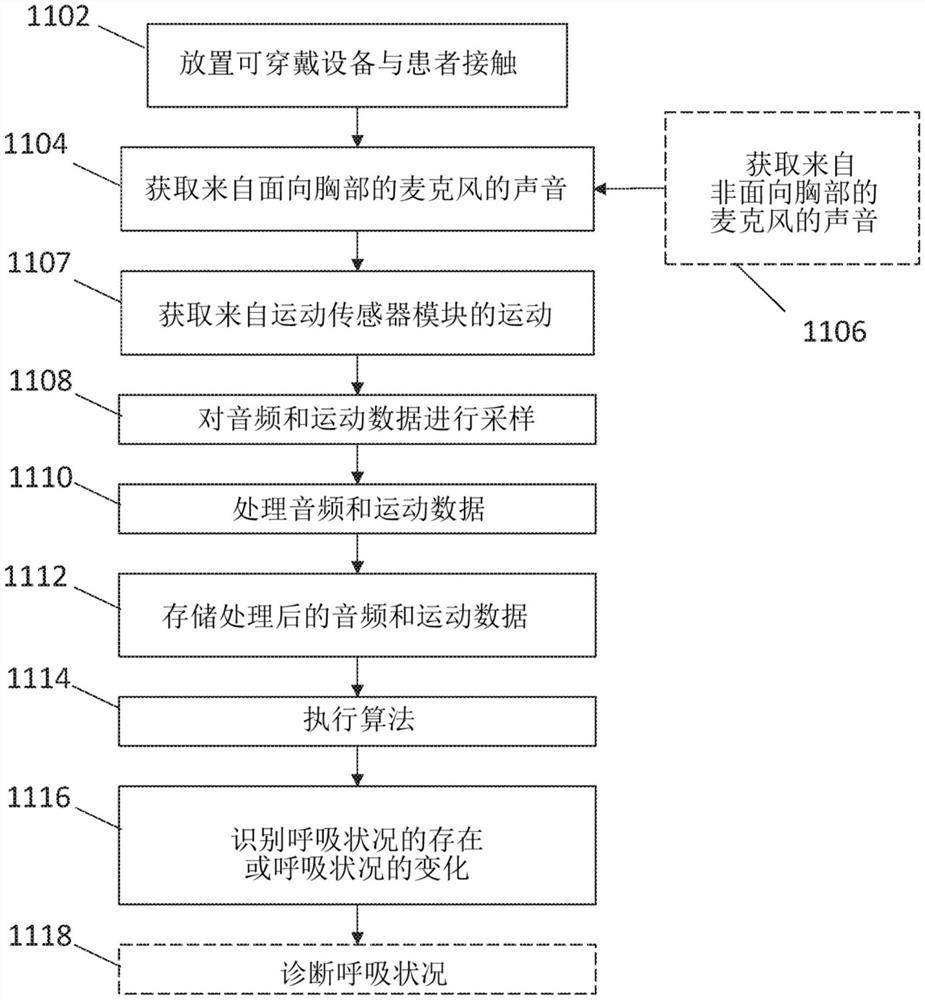
图7是示出了根据示例性实施例可以执行的步骤的流程图。
图8是示出了确定何时已捕获到异常呼吸声音的数据处理的流程图。
图9示出了两个麦克风通道重叠的示例性样本。
图10示出了从第一信号减去第二信号之后来自图9的数据。
图11以直方图格式示出了来自图10的数据。
图12示出了在将数据平方之后来自图10的数据。
图13示出了运动传感器模块的示例性样本。
图14示出了单次呼吸期间胸壁运动的示例性图。
图15示出了由可穿戴设备的第一麦克风和第二麦克风获取的示例性频谱图。
图16是示出了根据示例性实施例可以执行的步骤的流程图。
图17是根据示例性实施例的电子组件的视图。
图18和图19示出了确定与咳嗽相关联的误吸风险(aspiration risk)的方法。
图20示出了确定与咳嗽相关联的风险的方法。
图21示出了确定咳嗽特性的方法。
图22示出了识别与咳嗽相关联的风险水平的另一种方法。
图23示出了一种用于评估与异常呼吸声音相关联的风险的方法。
图24示出了表征异常呼吸声音的另一种方法。
具体实施方式
旨在结合附图阅读示例性实施例的该描述,这些附图被认为是整个书面描述的一部分。为了清楚和简洁起见,附图不一定按比例绘制,并且某些特征可以按比例放大或以些许示意性形式示出。在描述中,相对术语诸如“水平”、“垂直”、“上”、“下”、“顶部”和“底部”及其派生词(例如,“水平地”、“向下”、“向上”等)应解释为是指如当时描述的或如所讨论的附图中示出的取向。这些相对术语是为了便于描述,并且通常不旨在要求特定的取向。包括“向内”与“向外”、“纵向”与“横向”和诸如此类的术语将被解释为相对于彼此或相对于延伸轴或旋转轴或旋转中心,视情况而定。关于附接、耦接和诸如此类的术语诸如“连接的”和“互连的”是指其中结构通过中间结构直接或间接地彼此固定或附接的关系,以及可移动的或刚性的附接或关系,除非另有明确描述。术语“可操作地连接”是这样的附接、耦接或连接,其允许相关结构借由该关系按预期操作。
本文描述的设备和方法被设计用于连续采集身体声音和运动数据以进行计算机化分析。相比之下,用于身体声音采集的现有设备被设计为用于人类听觉的身体声音的偶发采集。这种差异导致构造材料、重量和身体声音采集的机构的设计差异。具体而言,现有设计典型地需要操作员手动将听诊器按压在皮肤上,以进行足够的声音信号采集。这种数据采集是偶发的,这是因为它受操作员可以手动将听诊器按压在皮肤上的持续时间限制。使用诸如粘合剂或夹在患者所穿的一件衣服上的夹子之类的机构将本文描述的设备按压在皮肤上。像这样,数据采集可以连续发生并且不依赖于操作员的努力。
身体声音采集的现有机构包括接触麦克风、电磁隔膜和金属制成的空气耦合器胸件。
理想地经由设备与皮肤之间的紧密接触来实现使用电子接触式麦克风和电磁隔膜进行身体声音采集。设备和皮肤之间的最小移动会显著扭曲信号。因此,在这些情况下,可以排除使用粘合剂和夹子作为附接机构,这是因为对于这些类型的身体声音采集机构,这些附接机构不提供足够的皮肤接触。
此外,在连续监视的情况下,使用电磁隔膜需要更多的电池功率,这使得该设计在可穿戴设备中不太理想。
使用空气耦合器胸件的身体声音采集更为宽容,皮肤设备接触较松且不需要移动。高密度材料(诸如金属)被用于其构造中,以用于针对人类听觉的更好的声音质量。但是,金属胸件对于可穿戴应用而言太重了。例如,Littmann 3200电子听诊器胸件重98克,而本文描述的可穿戴设备的示例性实施例重25克,这是因为使用了轻质、密度低的聚合材料,诸如丙烯腈丁二烯苯乙烯(ABS)。胸件中常用的金属包括低成本听诊器中的铝合金和优质听诊器中的钢。铝合金的密度约为2.7克/cm^3,而钢的密度约为7.8克/cm^3。相比之下,ABS的密度约为1克/cm^3。使用轻质量、低密度的空气耦合器胸件会使人类听觉的音质相对较差,但对于计算机化分析来说是足够的。
尽管对设备和方法的该描述涉及其中使用特定组件和技术来例如收集音频和运动数据的实施例,但是应当理解,可以使用其他组件和技术。例如,在一个实施例中,一种设备包括用于捕获音频和运动数据两者的接触加速度计。例如,该设备可以包括如Gupta等人于2018年6月3日至7日的Precision High-Bandwidth Out-of-Plane Accelerometer asContact Microphone for Body-Worn Auscultation Devices,Solid-State Sensors,Actuators and Microsystems Workshop中描述所配置的接触加速度计,其全部内容通过引用并入本文,并且根据其中描述的技术来使用。
另外,本文描述的可穿戴设备的一些实施例结合了运动传感器,该运动传感器获取用于优化计算机化的身体声音分析的附加生理数据。生理数据包括但不限于呼吸的阶段,即,如本文描述的吸气和呼气、心律和胸壁扩张的程度。
本文描述的方法和装置使能评估患者的呼吸。根据示例性实施例,对患者的评估可以例如导致与患者的呼吸相关联的医学问题的检测。评估还可能导致检测到患者肺功能恶化。示例性患者包括哮喘患者和患有慢性阻塞性肺疾病(COPD)的患者。在另一个示例性应用中,肺音监视用于检测由于心力衰竭而导致肺部中的液体积聚。在另一示例性应用中,在针对心力衰竭的利尿剂治疗期间对肺音的连续监视被用于监视治疗效果。
根据一个实施例,可穿戴设备被放置成与患者的身体接触,以便接收和处理从患者的身体内部发出的声音并收集运动数据。图1A中示出了示例性可穿戴设备100的分解图。隔膜107被配置为放置成与患者的皮肤接触。隔膜密封件106将隔膜107固定在适当的位置。胸件和底部壳体105放置在隔膜107上方。电子组件103放置在胸件105上方。顶部壳体101放置在电子组件103上方。软外壳108放置在胸件和底部壳体105下方。在图1B中还示出了这些组件中的几个。将依次讨论可穿戴设备100的每个组件。
图2A示出了示例性的顶部壳体101。尽管可以使用其他材料,但是顶部壳体101理想地由刚性、轻质的聚合材料构成。顶部壳体101的示例性尺寸是长56mm、宽34mm和高7mm。
图2B示出了示例性电池102。电池102包括直径为24.5mm和高度为3.3mm的示例性尺寸。
图2C示出了示例性电子组件103,其包括长度为51mm、宽度为28mm和高度为2mm的示例性尺寸。电子组件130接收来自患者的可听声音并生成可用于诊断呼吸问题的数据。下面详细描述电子组件103的示例性结构和操作方法。
图2D示出了示例性的充电线圈104,其包括直径为11mm和高度为1.4mm的示例性尺寸。充电线圈104使能无线充电。
图2E示出了示例性的底部壳体和胸件105,其包括长度为56mm、宽度为34mm和高度为4.5mm的示例性尺寸。底部壳体和胸件105理想地由刚性的、轻质的聚合材料构成,尽管也可以使用其他材料。底部壳体和胸件105理想地由一种类型的材料构成,尽管它也可以由几种类型的材料融合成一件。
图2F示出了示例性的隔膜密封件106,其包括直径为29mm和高度为2.75mm的示例性尺寸。隔膜密封件106将隔膜107固定到底部壳体和胸件105。
图2G示出了示例性的隔膜107,其包括直径为24mm和高度为0.25mm的示例性尺寸。隔膜107理想地由刚性的、轻质量的聚合物材料构成,尽管可以使用其他材料。
图2H示出了示例性的软外壳108。软外壳108理想地由软硅树脂构成,并且包括被设计成将其保持在适当位置的底部边缘。示例性尺寸包括长度为72mm、宽度为50mm和高度为12mm。可以将软外壳108设计成使用粘合剂贴附在患者的皮肤上,尽管也可以使用其他安装机构(例如,带子或夹子)。
图3提供了有关电子组件103的进一步的细节。电子组件103包括面向胸部的麦克风305。可以将可选的背景麦克风310安装在电子组件103的任一侧。面向胸部的麦克风305的麦克风端口孔面向底部壳体和胸件105。可选的背景麦克风310的麦克风端口孔面向顶部壳体101。电子组件103所包括的其他部件可以取决于空间可用性而安装在电子组件103的任一侧。为了给电子组件103供电,包括了电池102。例如,电池102可以是盘形电池,以便为电子组件103提供期望的外部厚度。处理器170能够执行如下面描述的各种操作。多传感器模块315包括可选的传感器,包括但不限于运动传感器、温度计和压力传感器。电力管理设备320可选地控制电子组件103内的电力水平以便节省电力。RF放大器325和天线330可选地使能电子组件103与外部计算设备(例如,智能电话、平板电脑、手提电脑、基于云的计算系统等)无线通信。可选的USB和编程连接器316使能与电子组件103进行有线通信。
在一个实施例中,多传感器模块315包括运动传感器模块317,该运动传感器模块317包括一个或多个加速度计、陀螺仪和磁力计。在一个实施例中,如图17中示出的,在第一芯片321上提供了第一加速度计和陀螺仪。此外,在第二芯片322上提供了第二加速度计和磁力计。通过在第一芯片321上同时提供加速计和陀螺仪,避免了传感器的轴的未对准。类似地,通过在第二芯片322上一起提供第二加速度计和磁力计,避免了那些传感器的轴的未对准。尽管在单个芯片上包括多个传感器提供了提到的优点,但在其他实施例中,传感器分开贴附在电子板上。在一个实施例中,运动传感器模块317的元件可以被设置为以2kHz的频率收集数据。在其他实施例中,运动传感器模块317的元件以任何适当的频率(诸如1kHz、2kHz、3kHz、4kHz或5kHz)收集数据。
在一个实施例中,运动传感器模块317包括四个传感器。所述传感器中的三个定位为使得它们以九个自由度提供运动数据。包括第四个传感器以对同时发生的运动进行去噪。在一些实施例中,将加速度计和陀螺仪(例如在第一芯片321上)定位为感测胸壁的线性运动和角运动,该数据可以用于进一步表征异常呼吸声音。此外,磁力计可用于基于运动的线性向量和角向量来收集数据,该数据可用于表征非胸壁运动,诸如步行、跳跃或利用助行器走路。在一些实施例中,附加的加速度计可用于基于胸壁的同时运动来收集用于检测心率的数据。多轴运动感测的其他应用包括但不限于在物理治疗期间检测姿势和特定运动。通过沿着与用于胸壁运动测量的运动传感器不同的轴而放置附加运动传感器,可以计算每种类型的运动对每个向量的相对贡献,使得可以对多个运动进行分类。
由运动传感器模块317捕获的数据可以用于例如确定每次呼吸的幅度、每次呼吸的吸气和呼气的持续时间以及呼吸之间的间隔的持续时间以及这些参数的可变性。此外,在穿戴多于一个可穿戴设备100的用户中,呼吸模式还可以进一步表征为躯干的不同部分的运动,包括腹部区域和胸壁。如本文将进一步描述的。该信息可以与由麦克风305、310捕获的音频数据结合使用,以表征异常呼吸声音并评估与之相关联的风险。
由于经历呼吸失代偿的患者将表现出不同类型的姿势和活动水平,因此检测同时运动的能力在围手术期(peri-surgical)呼吸监视和手术后物理治疗中很重要。姿势、胸壁运动和动态模式的变化(包括但不限于步态、活动水平和移动时间)可以在围手术期环境中以多种方式使用。这些包括但不限于以下各项:(1)呼吸失代偿的检测;(2)药物的调整,诸如可以减少呼吸驱动的止痛药物;以及(3)物理治疗和肺部康复的动态反馈。
图4是示出数据采集电路150的框图。数据采集电路150包括传感器160和数据处理单元170。接收到的声音由传感器160接收,其在图5中更清楚地示出。传感器160可以包括一个或多个麦克风,诸如例如面向胸部的麦克风305和可选的背景麦克风310,其被配置为将声能转换为电能。在一些实施例中,面向胸部的麦克风305和背景麦克风310中的一个或两个是基于电容器的麦克风。在其他实施例中,如上面描述的,可穿戴设备100包括接触加速度计以捕获音频数据。传感器160还接收可选的运动数据、压力数据和温度数据,其在图5中更清楚地示出。传感器160可以包括多传感器模块315,其被配置为将模拟运动、温度和压力数据转换成电能。多传感器模块315可以包括运动传感器模块317、气压计318和温度计319。来自每个麦克风305、310和多传感器模块315的信号可以被发送到A-D转换器340和电气总线接口350。来自传感器的数据可以通过板载处理器由外部计算机360的处理器(例如,智能电话、平板电脑、基于云的处理器等)处理。
还可以包括一个或多个可选的物理滤波器306。示例性滤波器包括线性连续时间滤波器及其它。示例性滤波器类型包括低通、高通及其它。示例性技术包括电子、数字、机械及其它。一个或多个可选的滤波器306可以在数字化之前、数字化之后或两者接收声音。
电气总线接口350的输出可以被发送到数据处理单元170,其在图6中更清楚地示出。数据处理单元170包括数字信号处理器171、存储器172和无线模块173(其包括如图3中示出的RF放大器以及天线)。数字信号处理器171可以在制造后可编程。示例性处理器包括赛普拉斯可编程片上系统、具有集成功能的现场可编程门阵列、以及与现场可编程门阵列耦接的无线使能的微控制器。无线模块173可以使用低功耗蓝牙作为无线传输标准。无线模块173可以包括集成的平衡-不平衡变换器和完全认证的蓝牙堆栈。处理器171、存储器172和无线模块173被理想地集成。
在一个示例性实施例中,数据从存储器172传送到外部计算机360。这将在下面进一步描述。
图7示出了示例性实施例的操作。在步骤1102处,可穿戴设备100被放置为与患者(优选地患者的皮肤)接触。可穿戴设备100可以包括粘合剂以保持其与患者接触,尽管可以使用其他形式的粘附。可穿戴设备100被放置为使得面向胸部的麦克风305面向患者并且可选的背景麦克风310不面向患者。
在步骤1104处,获取来自面向胸部的麦克风305的声音。在可选步骤1106处,获取来自背景麦克风310的声音。声音在被麦克风305转换为电能之前可选地通过滤波器306。此外,在步骤1107处,运动传感器模块317获取运动数据。在转换为电能之后,音频和/或运动数据在被数字信号处理器171接收之前通过A-D转换器340和电气总线接口350。处理器171可以例如以20kHz对音频和/或运动数据进行采样。采样可以发生例如二十秒钟。步骤1108可选地包括使用在步骤1106处经由麦克风310接收到的音频信号以便执行噪声消除的步骤。可以使用噪声消除领域中的普通技术人员众所周知的算法来执行噪声消除。
在步骤1110处处理采样后的音频和/或运动数据。处理音频数据以便检测与呼吸相关联的(和/或与呼吸困难相关联的)某些声音。步骤1110处的处理可以包括例如快速傅立叶变换。处理还可以包括例如数字低通和/或高通巴特沃斯和/或切比雪夫滤波器。可以如本文进一步描述的那样处理运动数据。
在可选步骤1112处,将数据存储在存储器172中。图7示出了在步骤1110之后执行的步骤1112,但是可以理解,在某些情况下,步骤1112与步骤1110同时执行或在步骤1110之前执行。可能存在存储在存储器172中的两种类型的数据。第一种数据类型可以是“原始”数据,即已由麦克风305采样的声音的记录(并且如果噪声消除是可用的并且是需要的,则其已经经受了噪声消除)。在一个示例性实施例中,最近的20分钟的“原始”音频数据被存储在存储器中。数据以先进先出的配置存储,即,最旧的数据被连续删除以在存储器中为新的和连续获取的数据腾出空间。存储在存储器中的第二种类型的数据是处理后的数据,即已经经受了由处理器171进行的某种形式的处理(诸如时频分析)的数据。这种类型的处理后数据的示例包括上面阐述的示例,诸如快速傅立叶变换、数字低通和/或高通巴特沃斯和/或切比雪夫滤波器等。在示例性实施例中,将20秒的处理后的音频数据存储在存储器172中。此数据也以先进先出的配置进行存储。
在步骤1114处,处理器171评估处理后的数据,以确定麦克风305是否捕获了“异常”呼吸声音。“异常”呼吸声音的示例包括喘息声、咳嗽、干罗音、呼吸困难或指示呼吸问题的一些其他类型的呼吸声音。评价发生如下。在一个示例性实施例中,处理后的数据(即来自诸如傅立叶变换或小波变换的变换)产生频谱图。频谱图可以例如对应于已经存储在存储器172中的处理后的数据的20秒值。然后使用“预定义的数学特征”的集合来评估频谱图。
“预定义的数学特征”是从多个“预定义的频谱图”生成的。每个“预定义的频谱图”都是通过处理已知对应于不规则呼吸声音(诸如喘息声)的数据生成的。生成这种预定义的频谱图的方法由图8的流程图示出,并且可以如下执行:a)医师使用诸如听诊器的设备来听取来自人的呼吸声音;b)来自人的呼吸声音被记录并经受诸如上面识别出的处理之类的处理;c)基于上面阐述的处理生成频谱图;d)医师记录他/她听到医师认为是喘息声的声音的确切时间;e)识别出对应于医师听到喘息声的确切时间的频谱图的部分;并且f)识别出的频谱图的部分被用作“预定义的频谱图”。
预定义的频谱图可以是患者特定的。例如,可以针对将穿戴可穿戴设备100的特定患者执行以上步骤a至f。预定义的频谱图也可以基于群体。换句话说,预定义的频谱图可以基于对将穿戴可穿戴设备100的患者之外的某人执行步骤a至f。在一些实施例中,预定义的频谱图基于患者特定的频谱图和基于群体的频谱图。
一旦原始数据已经从受试者获取(步骤1202),并且经受了音频处理(步骤1204),则可以发生频谱图特征提取(步骤1206)(图8中示出的)。
可以从每个预定义的频谱图中提取数学特征的集合。数学特征提取是本领域普通技术人员已知的,并且在各种出版物中描述,包括:1)Bahoura,M.,&Pelletier,C.(2004年9月).Respiratory sounds classification using cepstral analysis and Gaussianmixture models.In Engineering in Medicine and Biology Society,2004.IEMBS'04.26th Annual International Conference of the IEEE(第1卷,第9-12页).IEEE;2)Bahoura,M.(2009).Pattern recognition methods applied to respiratory soundsclassification into normal and wheeze classes.Computers in biology andmedicine,39(9),824-843;3)Palaniappan,R.,&Sundaraj,K.(2013年12月).Respiratorysound classification using cepstral features and support vector machine.InIntelligent Computational Systems(RAICS),2013IEEE Recent Advances in(第132-136页).IEEE;4)Mayorga,P.,Druzgalski,C.,Morelos,R.L.,Gonzalez,O.H.,&Vidales,J.(2010年8月).Acoustics based assessment of respiratory diseases using GMMclassification.In Engineering in Medicine and Biology Society(EMBC),2010Annual International Conference of the IEEE(第6312-6316页).IEEE;以及5)Chien,J.C.,Wu,H.D.,Chong,F.C.,&Li,C.I.(2007年8月).Wheeze detection usingcepstral analysis in gaussian mixture models.In Engineering in Medicine andBiology Society。以上所有参考文献均通过引用整体并入本文。
使用包括但不限于以下的数学方法而从数据簇的预定义的频谱图的固有功率和/或频率中得出数学特征的集合:数据变换(傅里叶、小波、离散余弦)和对数分析。从每个预定义的频谱图中提取的数学特征的集合可以因利用其提取集合中每个特征的方法而变化。这些特征可以包括但不限于数据波形的频率、功率、音高、音调和形状。参见Lartillot,O.和Toiviainen,P.(2007年9月).AMatlab toolbox for musical feature extractionfrom audio.In International Conference on Digital Audio Effects(第237-244页)。该参考文献通过引用整体并入本文。
例如,在一个实施例中,使用统计平均值和模式从预定义的频谱图中提取两个数学特征的第一集合。使用统计平均值和熵从相同预定义的频谱图中提取两个数学特征的第二集合。数学特征的集合还可以因数学特征的每个集合中特征的数量而变化。例如,在一个实施例中,从预定义的频谱图中提取二十个数学特征的集合。在另一个示例中,从相同预定义的频谱图中提取五十个数学特征的集合。另外,数学特征可能因利用其提取数学特征的预定义的频谱图的分段长度而变化。例如,使用统计方法从预定义的频谱图的一秒分段中提取的数学特征与使用相同统计方法从预定义的频谱图的五秒分段中提取的数学特征不同。
用于提取“预定数学特征”的数学方法的集合是“预先指定的特征提取”。在一个示例性实施例中,“预先指定的特征提取”是使用梅尔频率倒谱系数开发的,并使用包括但不限于以下的机器学习方法进行优化:支持向量机、决策树、高斯混合模型、递归神经网络、半监督自动编码器、受限玻耳兹曼机、卷积神经网络和隐马尔可夫链(参见上面的参考文献)。每种机器学习方法可以单独使用,或者可以与其他机器学习方法结合使用。
“预定义的数学特征”以下列方式从多个预定义的频谱图导出。如上面定义的特征提取方法用于从每个预定义的频谱图中提取与一种类型的呼吸声音相对应的数学特征的集合。以这种方式评估多个特征。然后,从多个呼吸声音类型一起绘制特征(步骤1208),以便在第n维执行聚类分析(n是所提取的特征数)。例如,如果从每个数据文件中提取了三个特征进行分析,则每个数据文件将对应于三维空间中的一个点,每个轴表示特定特征的值。此后,算法生成的一个示例尝试在此三维空间中找到超平面,该超平面最大程度地分离了表示特定声音类型的点簇。例如,如果来自喘息声文件的数据点聚集在此三维空间的一个角落中,而来自咳嗽文件的数据点聚集在另一个角落中,则将这两个簇分开的平面将对应于以下算法,该算法可以区分这两个簇并能够将这些声音类型分类分为两个群组。该分析可以根据需要外推出尽可能多的特征n,从而将分析移动到第n维空间。这样允许对每种声音类型基于其独特特征集合的区分。如上面描述的,将生成彼此最相似的输出(数学特征的集合)的算法选择为“预先指定的算法”。例如,使用不同的算法从对应于喘息的十个预定义的频谱图中提取二十个统计特征的十个集合。提取彼此最相似的特征的十个集合的算法被选择为“预先指定的算法”(步骤1210)。在分类的示例性图形表示中,线表示根据示例性实施例的在多维数据分类中的“预定义算法”。接下来,利用“预先指定的算法”提取的数学特征的集合的“平均值”被选择为“预定义的数学特征”。在此,“平均”由“预定义的数学特征”与“预定义的数学特征”所源自的数学特征的每个集合之间的数学相似性定义。
具有预定义的频谱图的频谱图的评估可以基于几个基础。频谱图通过“预先指定的特征提取”方法进行处理,以生成数学特征的集合。然后将数学特征的集合与“预定义的数学特征”的集合进行比较,其中每个集合对应于一种特定类型的声音。如果从频谱图提取的数学特征的集合与一种类型的呼吸声音的预定义的数学特征之间的相似性经过某些阈值,则确定出已经发出了对应类型的呼吸声音。通过说“经过”,其可能意味着超过某个值。可替选地其可能意味着低于某个值。因此,通过频谱图的部分高于或低于与可能的异常呼吸声相关联的预定频谱图的部分,确定出可能已经发生异常呼吸声音。
多种因素可用于从可用的预定义的频谱图中识别出应该将特定患者的数据与之进行比较的那些,并以其他方式对呼吸声音进行分类。例如,当在手术后使用可穿戴设备时,可以使用从具有类似手术解剖结构的受试者收集到的预定义的频谱图。以这种方式选择适当的比较频谱图可能会提供更准确的结果,这是因为一般群体数据可能不适合手术后时段。在一些实施例中,还将运动数据与从具有相似解剖结构和/或患有相似状况的患者收集到的数据进行比较。
另外,可以基于患者经历的肺部疾病来选择适当的预定义的频谱图。例如,可以将预定义的频谱图滤波为从患有COPD的患者中捕获的那些。患有严重COPD的患者的呼吸声音通常会减弱。COPD还影响肺力学。患有COPD的患者的胸壁在基线处扩张,其被称为“桶状胸(barrel chest)”。这会影响角位移和线性位移、以及潮气量和气流速率的后续计算。COPD的严重程度可以根据过去的医疗记录来确定,并且对于没有足够的事先医学评估的患者可以根据吸烟史来确定。通过匹配COPD历史或吸烟史选择预定义的频谱图可以帮助确保考虑最相关的因素。
示例性应用涉及食道手术的患者,这使患者由于手术部位泄漏而处于化学性肺炎的高风险中。随着外科手术泄漏的发展,这种示例性患者的肺音生成了特定的签名。同时,患者可能呼吸频率增加,并且潮气量减少。但是,由于严重的COPD,患者可能具有桶状胸。因此,减少的潮气量不会导致胸壁运动的减少,而这正是无COPD患者所期望的。如上面描述的,预定义的频谱图可以从多个群体导出,使得可以收集患有COPD的患者和无COPD的患者的边界条件的差异并将其应用于示例性情况。
另外,由麦克风305、310和/或运动传感器模块317收集到的信息可用于将水肿性胸壁或肺部与没有水肿的胸壁和肺部进行区分。此信息可用于精细化或滤波将与患者的呼吸声音进行比较的频谱图。由于水肿性胸壁发送声音与无水肿性胸壁不同,因此,与从具有类似状况的受试者收集到的数据进行比较可以进一步提高确定异常呼吸声音的准确性。
另外,可以基于患者的心力衰竭历史来滤波预定义的频谱图。这些患者可能由于支气管痉挛或失代偿性心力衰竭而经历喘息,这通常还会导致体重增加。仅基于声音,很难将由于支气管痉挛引起的喘息声与心脏性喘息声区分开。在这些患者中,呼吸性喘息声vs心脏性喘息声的分类可能会考虑患者病历中其他地方可用的信息。一个主要的区别是患者的病史。心脏衰竭恶化的标志是体重增加。此信息可用于调整分类阈值。例如,在没有心力衰竭史的患者中,无论体重增加量,均可将喘息声归类为由于支气管痉挛引起的喘息声。然而,在患有心力衰竭的患者中,显着的体重增加(即,两个界限或更多)将导致喘息声分类为心脏性喘息声。与没有心力衰竭史的患者相比,在处于失代偿性心力衰竭风险的患者中,体重的较小变化将导致心脏性喘息声而不是非心脏性喘息声的分类。
喘息声和其他呼吸声音可进一步基于喘息声发生在呼吸循环中的哪一点处(例如,在吸气或呼气阶段期间)而进行分类。在各种实施例中,可以基于来自可穿戴设备100的运动传感器模块317的数据来确定呼吸声音在循环的哪个部分中发生,如本文中进一步描述的。
在一些实施例中,在手术之前获取患者特定的预定义的频谱图,以提供用于手术后监视的术前基准(benchmark)。除了获取术前频谱图之外,还可以收集其他术前信息。例如,患者的胸壁运动数据、心率、呼吸频率和动态模式,包括但不限于姿势和步态。除了用作基准外,该数据还可用于为患者选择合适的边界条件或基准频谱图。可替选地或附加地,可以将音频和/或运动数据与手术后但在较早时间处从同一患者捕获的数据进行比较。
用于选择基准频谱图或边界条件的其他示例性输入包括视频成像输入。输入可能来自患者家中个人移动设备的摄像头或“智能”电视。视频输入用于确定可穿戴设备100在患者胸壁上的放置。视频还可以用于将声音和运动传感器数据与患者的运动相关联,其包括但不限于呼吸、姿势和步态。与视频输入的相关性可以合并到校准过程中,但不是必需的。来自个体的视频输入可与基于群体的数据库进行比较,并可有助于选择适当的边界条件。
一旦使用“预定义的数学特征”识别出不规则的呼吸声音(诸如喘息声),则已经存储在存储器172中的前20分钟(举例而言)的累积的原始数据可以接收“进一步处理”。在一个示例性实施例中,将20分钟的原始数据从存储器172传送到外部计算机360以进行更鲁棒的处理。在另一个示例性实施例中,原始数据在处理器171中经受进一步处理,而不被传送到外部计算机。可以取决于相应的处理能力、无线通信能力等,在处理器171、外部计算机360或两者中执行上面描述的进一步处理。
通过实施“进一步处理”步骤,将第一算法用于可能地识别不规则的呼吸声音,并且将第二算法(更鲁棒,即,比第一算法需要更重要的处理)应用于原始数据以尝试更准确地确定是否确实出现了不规则的呼吸声音(诸如喘息声)。在一个示例性实施例中,第一算法生成二十个数学特征。第二算法生成五十个数学特征,并且更鲁棒。在另一个示例性实施例中,用于提取第二算法中的每个数学特征的数学方法比用于第一算法中的数学方法需要更多的处理能力。像这样,第二算法可以更鲁棒。
因此,该进一步处理可以包括确定处理后的数据是否已经通过(即,高于或低于)边界条件。边界条件可以包括以上识别出的任何输入和/或特性中的一个或多个,诸如从预定义的频谱图中提取出的数学特征。在一个实施例中,这是通过预先指定的算法来实现的,该算法是先前使用利用深度学习框架的机器学习方法开发的。这涉及多层分类方案。外部计算机中的预先指定的算法中使用的变量包括但不限于上面描述的示例性变量。
除了将频谱图与第二算法一起使用之外,在分析中还可以使用其他因素。示例性因素包括:1)用户输入,包括主观感觉、急救吸入器的使用、药物使用的类型和频率以及当前的哮喘状态;2)来自与患者当前生理状态有关的传感器(例如,加速度计、磁力计和陀螺仪)的输入,这将在下面进行详细说明;3)从传感器可获得的环境输入,其包括但不限于温度传感器和气压计;以及4)从诸如互联网之类的信息源可获得的环境输入。换句话说,代替形成了初始处理后的数据(例如,上面讨论的例如20秒的数据)的分析基础的变量或除了其之外,可以将其他变量集成到分析中。这些因素还可以包括患者的人口统计学、心率、手术类型、活动水平、姿势、步态、药物使用以及医学成像结果。
在一个实施例中,医学成像可以用于导出身体组织组成和解剖结构。然后,可以使用此信息来定义与患者的呼吸声音进行比较的边界条件。
在另一个实施例中,患者对药物的使用被用来进一步定义与患者的呼吸声音进行比较的边界条件和频谱图。许多常见的止痛药(包括但不限于阿片类药物和氯胺酮)会引起呼吸抑制和神经抑制。呼吸抑制可能表现为潮气量和呼吸流速降低。经由运动传感器模块317,可穿戴设备100可以测量身体运动,并且所得数据可以用于检测这些变化。将数据与正在使用类似药物的用户的频谱图进行比较可以允许更准确地表征。神经抑制可能表现为潮气量和呼吸流速降低。这种状况还可以表现为误吸和上呼吸道阻塞,除了胸壁运动外,它还对肺音产生影响。神经抑制还会导致总体患者运动减少。可穿戴设备100可以测量身体运动和肺音,并且运动和音频数据可以用于检测这种变化。此外,在这样的实施例中,患者的药物使用数据可以与传感器数据相关,以提供关于止痛药物使用安全性的反馈。
由可穿戴设备100收集到的(例如,来自运动传感器模块317)和/或由患者或护理人员提供的信息(例如,患者身高、患者体重、患者人口统计学、药物、手术信息)也可以是用于完善和调整边界条件。例如,可以基于从运动传感器模块317导出的数据来向上或向下调整从预定义的频谱图提取出的比较数学特征。
当确定出数据已经越过边界条件之上或之下时,可以提供警报或警告。可以将警报或警告发布给患者和/或医师或护理人员。例如,可穿戴设备100可以发出可听、视觉或触觉反馈,诸如通过蜂鸣、照亮一个或多个灯或振动。可替选地,可穿戴设备100可以经由无线模块173连接到计算设备,诸如智能电话。结果,可以在计算设备上发出警报。在一些实施例中,发出警报的计算设备是外部计算机360。警报也可以被发送给医师或其他护理人员,使得护理人员可以联系患者或通知紧急响应者。
警报阈值(即,与发出警报所需的边界条件的偏差量)可能因患者而异。例如,如果患者在手术后使用可穿戴设备100,则警报阈值可以较低(即,更灵敏),这是因为患者相比普通群体可能处于更高的风险。该阈值可基于手术类型和潜在并发症而进一步变化。例如,处于发生化学性肺炎风险的患者可能需要较低的阈值。
可以被存储在例如存储器172中的“原始”数据提供多种功能。例如,它为呼吸声音分类提供了延长的时间段。可以将数据处理成频谱图,并且然后可以使用第二算法结合上面提及的其他变量来分析频谱图。作为进一步地示例,原始数据可以用于改进算法。例如,如果识别出异常的肺音,则可以将其用作控件,并且可以将原始数据用作数据集,以进一步细化(或“训练”)预先指定的算法。
图15中示出了基于根据示例性实施例捕获的音频数据的示例性频谱图。顶部部分是从面向患者的麦克风获得的。底部部分是从背向患者的麦克风获得的。
可以根据分析的目标来实施附加算法。例如,在一个实施例中,获得多个声音样本并将其分类为不同的肺音。接下来,将样本(频谱图)输入到预先指定的分类算法中,以生成数学特征的集合。该分类算法的输出与预定义的数学特征之间的差异用于细化算法。目的是确保分类算法具有在特征提取期间滤除不想要的噪声所需的变量。
接下来,可以将分类算法应用于包含音频频谱图和上面被定义为“边界条件”的附加用户数据两者的附加样本。在这种情况下,机器学习方法不必专注于特征提取。而是,这种机器学习方法采用了预测性统计分析。基本概念保持不变:分类算法和预定义答案之间的差异用于创建和调整变量的权重。
根据示例性实施例的算法可以基于用于训练算法的特定方法以及算法本身。
为了进一步阐明,在一个示例性实施例中,通过识别在一个时间段期间某种类型的呼吸声音发生了多少次(“频率”)来检测呼吸状况。如果在一个时间段内识别出声音的次数经过阈值,则将生成一个信号,指示已检测到不利的呼吸状况(或不利的呼吸状况变得更好或更糟)。通过说“经过阈值”,所包括的是满足阈值、超过阈值或低于阈值,这取决于期望检测到什么样的不利的呼吸状况。在进一步的示例性实施例中,将某种类型的呼吸声音在第一时间段中发生的次数与某种类型的呼吸声在第二时间段中发生的次数进行比较(第一时间段和第二时间段可能重叠或可能不重叠,则第一时间段和第二时间段可能相等也可能不相等)。例如,可以将第一时间段中的呼吸声音的数量与大于第一时间段的第二时间段中的呼吸声音的数量进行比较。比较可以是关于频率、功率、被评估的时间帧中的位置和/或其他标准。在一个示例性实施例中,第一时间段可以是三个小时,并且第二时间段可以是18小时。这些时间段仅是示例性的。
在另一个示例性实施例中,基于音频信号的频率(喘息声频率~300-400Hz)和事件发生的次数(事件本身的频率)来识别呼吸问题。
可替选地或附加地,可穿戴设备100可以检测和监视其他生理事件。例如,可穿戴设备100可以用于检测穿戴者的心率和心率变异性。如上面描述的,可穿戴设备100包括记录两个数据通道的两个麦克风。第一麦克风305面向穿戴者的胸壁,并且第二麦克风310背对胸壁并被配置为主要捕获外部声音。图9示出了覆盖的两个通道的示例性样本。为了消除外部噪声,从第一信号中减去第二信号。接下来,将高通滤波器应用于数据,结果如图10中示出的。图11以直方图的形式示出了相同的数据。在直方图中,可以清楚地看到高体积峰值。最后,数据被平方以进一步突出显示由第一麦克风305检测到的心搏,如图12中示出的。
在对数据进行滤波之后,可以对峰值进行计数以确定心率。峰值检测算法可用于以预定义的间隔对峰值的数量进行计数,并将此值存储在向量中。预定间隔可以是任何适当的间隔,诸如0.5秒。然后,每个间隔的搏动向量可以用于使用连续差分法的均方根来识别心率的变异性。该向量还可用于计算平均每分钟搏动。
在进一步的实施例中,可穿戴设备100可以被配置为检测其他心音,诸如心脏杂音以及心脏杂音的特性或速率随时间的变化。对心音的检测(例如,使用来自第一麦克风305的音频数据)以及从由运动传感器模块317捕获的运动数据得出的活动和姿势信息可有助于疾病的评估,包括但不限于心脏瓣膜疾病、心力衰竭、心律失常和心源性晕厥。这对于在家中监视患者以及评估患者对在家治疗的反应特别有用。
在一些实施例中,还可以通过比较来自第一麦克风305和第二麦克风310的音频数据来检测口呼吸的存在。当由第一麦克风305和第二麦克风310捕获的肺音之间的差异显著减小时,口呼吸可能被怀疑。这是因为当患者的口张开时,异常的肺音可以被发送到周围环境,并且随后可以由外部麦克风(例如,第二麦克风310)捕获声音。口呼吸在临床上很重要,这是因为它可能表明患者的呼吸状态恶化。此外,在静止用户中也经历不定呼吸音的患者中发生口呼吸(如基于来自运动传感器模块317的数据确定出的那样)可能指示用户处于危险中。在这样的情况下,警报或其他通知可以被提供给用户或护理人员。
此外,进行低强度步行(如由运动传感器模块317的数据确定出的那样)的患者出现口呼吸(而前几天其不存在)指示出疾病可能恶化并且可以用作进一步处理音频数据的触发器,或提供另一个输入进行处理(与包括肺音、胸壁运动和吸入器使用的其他输入结合)。
在另一个实施例中,运动传感器模块317用于监视附加生理参数。例如,运动传感器模块317可以用于监视例如胸壁扩张、平均潮气量、呼吸频率、气流速率、分钟通气量和心率。这些附加参数对于评估患者的健康可能很重要。例如,在某些疾病中,潮气量是比呼吸频率更可靠的肺失代偿的标志。
在一个实施例中,可穿戴设备100定位在最大脉冲点(PMI)处(即,由于心搏引起的胸部振荡运动最突出的位置)。可替选地,当设备未放置在PMI附近时,运动传感器模块317可用于经由心冲击描记术检测心率。如上面提及的,运动传感器模块317可以包括一个或多个加速度计、磁力计和陀螺仪。来自这些传感器中的每个的信号可以被转换成标准单位(例如,m/s
可以通过分析由运动传感器模块317捕获的数据来确定呼吸信息。可以使用双重积分方法将加速度计数据转换为位置数据。在对来自设备的原始加速度和时间数据进行滤波和处理以显示正确的单位后,使用梯形积分法对其进行积分一次以确定速度,然后第二次得到位置向量。然后评估该位置向量以找到个体呼吸波形。
该位置数据可用于确定潮气量和胸壁扩张。例如,可以对数据进行绘图。图的峰值和谷值分别对应于肺部的最大体积和最小体积。峰值定位器功能可用于定位峰值。在识别出峰值和谷值后,该算法可以将数据拆分为单独的呼吸。然后可以计算出每次呼吸期间行进的总距离。图14示出了单次呼吸的示例图。
通过将运动传感器模块317捕获的运动数据与从麦克风305、310接收到的音频数据结合使用,可以进一步改善潮气量的计算。例如,胸壁运动的幅度可以用于计算潮气量,如本文描述的。在一些实施例中,可以基于例如麦克风305、310捕获的呼吸声音来评估该确定的可靠性。胸壁运动与潮气量的相关性可以基于患者的气道开放(patent)的假设。结果,如果患者的呼吸道不开放,则基于胸壁运动的潮气量计算可能不准确。呼吸道开放可以通过呼吸声音评估。例如,当呼吸声音正常时(如由麦克风305、310捕获的音频数据确定出的),与550cc的潮气量相关的胸壁运动可以被分类为准确的。当与喘息声相关联时,相同的胸壁运动(如由麦克风305、310捕获的音频数据确定出的)可被分类为较不准确。类似地,当与没有呼吸音相关联时(如由麦克风305、310捕获的音频数据确定出的),相同的胸壁运动可以被分类为不准确的。
另外,在一个实施例中,呼吸声音的响度可以与呼吸系统中的空气流量相关。根据流量和呼吸声音的持续时间,可以估计潮气量。在这样的实施例中,可以将基于音频数据的确定与基于胸壁运动的确定进行比较,以验证和/或调整潮气量的计算。
另外,在一些实施例中,用户穿戴多于一个可穿戴设备100,从而允许更准确地计算潮气量。例如,在一些实施例中,用户在用户的躯干的每一侧都穿戴至少一个设备。在一些实施例中,一个可穿戴设备100定位于前/上胸壁上,并且第二可穿戴设备100定位于用户的剑突上。前/上胸壁上的可穿戴设备100可以被最佳定位以捕获胸壁运动。定位在剑突上的可穿戴设备100最好定位为捕获不同类型的呼吸方式,诸如浅呼吸和腹式呼吸。
在一些实施例中,还基于潮气量和呼吸频率来计算潮气量(即,患者在一分钟内移动的空气量)。这可以使用音频和运动数据来完成。分钟通气量的快速增加或减少可能指示出患者的状况正在恶化,并且需要护理人员的注意。在这样的情况下,可穿戴设备100可以发布或发送警报。
基于信号的频率和胸壁运动的大小,可以将心搏与呼吸进行区分。这些差异用于对信号进行滤波以区分心率和呼吸。通过使运动传感器模块317中的三个不同传感器当中的向量大小相关联,可以隔离心搏波形。可以比较独立传感器的波形比较,以识别心搏。
除了测量和/或计算胸壁的线性位移之外,还可以测量和/或计算角位移。角位移可被用作线性位移的补充或替代。可以基于运动传感器模块317的陀螺仪来确定角位移。
胸壁的线速度和/或角速度也可以用于确定气流速率。
因为可穿戴设备100检测生理声音以及胸壁的运动,所以可以提高呼吸异常和/或模式的识别的准确性。例如,运动传感器和麦克风的组合可用于识别呼吸音减弱的个体,诸如患有严重支气管痉挛的个体。如上面描述的,运动传感器模块317可以用于识别呼吸循环中的阶段。比较各个阶段期间麦克风收集到的数据允许更准确地识别呼吸音异常。
另外,结合使用来自运动传感器模块317的数据和来自一个或多个麦克风305、310的数据可以允许区分喘息声和喘鸣声。这两种情况导致类似的呼吸声音。但是,这些声音出现在呼吸循环的不同阶段。因此,可能难以单独使用声音来区分这些状况。然而,通过将呼吸声音的定时与由运动传感器模块317收集到的胸壁运动数据进行比较,可以识别这些状况。
在一个实施例中,可穿戴设备100收集到的数据用于在物理治疗期间提供有关患者的信息。在这样的实施例中,经由软件平台将肺音、胸壁运动以及包括心率、姿势、活动水平和步态的其他运动数据提供给物理治疗师或其他护理人员。基于收集到的数据,实时反馈和决策支持将提供给物理治疗师进行个性化治疗。趋势数据也可以用于随时间推移的趋势进展。物理治疗师可以使用此信息来评估患者的健康以及体育训练计划的功效。如有必要,物理治疗师然后可以对训练计划进行修改。例如,如果患者的呼吸困难和/或异常,则物理治疗师可以降低计划的强度。可替选地,如果患者的呼吸在所期范围内,并且不指示异常,则可以增加计划的强度。通过提供对患者的呼吸、心率和其他度量的连续监视,可穿戴设备100还可以在不存在物理治疗师的情况下允许患者安全地执行训练例程。物理治疗师或医师可以在锻炼期间或以后审查此信息,以确保患者没有危险。
可穿戴设备100还可以用于监视对规定或推荐活动的依从性。例如,经常规定激励肺活量测定,以防止术后患者肺不张。在一个实施例中,可穿戴设备100包括用户界面,该用户界面基于传感器数据提供关于规定的康复活动的实时反馈和指令。同时,可以将传感器数据发送给家庭成员和临床提供者,以监控依从性和进度。
麦克风305、310还可用于检测其他生理事件。在一个实施例中,可穿戴设备100被放置在大血管上或附近。可穿戴设备100可以检测与通过血管的血流相关联的声音。通过血管的血流的声音可用于监视血管变窄或血管“狭窄”、手术支架状态的变化以及血流的变化。可穿戴设备100还可以检测血管周围的皮肤的振动的变化,该变化与血管壁的生理状态、心率和血压以及血管周围的组织相关。身体声音和运动然后通过将声音与从基准音频和运动数据得到的预定义的数学特征所得到的边界条件进行比较来进行处理,如上面描述的。该信息可用于诊断或监视血管疾病,其包括但不限于外周动脉疾病、颈动脉狭窄、腹主动脉瘤和血管内手术的进入部位。
在另一实施例中,可穿戴设备100被放置在患者的关节(例如,肩膀、肘、臀部、膝盖、脚踝)上或附近。关节在运动期间生成的声音用于监视骨科疾病。在一个实施例中,可穿戴设备100被放置在一个以上的关节上。例如,一个可穿戴设备可以放置在左髋上,而一个可穿戴设备可以放置在右髋上。在这样的实施例中,从两个设备收集到的数据的比较允许识别例如步态模式中的异常。如上面描述的,可以通过将收集到的数据与从基准音频和运动数据所得出的数学特征进行比较来执行识别。
在另一个实施例中,该设备被放置在腹部上以检测腹部声音和腹部运动。如上面描述的,对腹部声音和腹部运动的变化进行声学分析,以检测导致腹部积液、腹壁僵硬、肠梗阻、假性肠梗阻和便秘的情况。
在进一步的示例性实施例中,外部计算机(例如,智能电话、平板电脑、手提电脑、基于云的计算系统)调制传感器160捕获数据的频率。
可以以多种方式显示和/或布置步骤1118(参见图7)的结果。例如,可以利用由用户输入设置的边界来执行音频数据的分类。还可以基于智能电话中包括的传感器数据(即,陀螺仪)来执行分类。
在一个示例性实施例中,患者能够提供反馈,即诊断的自我评估,以便提高诊断的准确性。无论如何,可以在一段时间(几天、几个月、几年)内累积历史数据,以进一步完善用于识别呼吸问题的边界条件和模型。
在一个示例性实施例中,可以使用除智能手机以外的计算设备。示例性计算设备包括计算机、平板电脑等。
在一个示例性实施例中,将呼吸疾病的识别的结果和/或呼吸状况的改变提供给患者提供者。可以使用各种不同的用户界面来显示识别和/或改变。
在本发明的一个示例性实施例中,可穿戴设备100提供了剩余电池寿命的指示。
在一个示例性实施例中,使能近场通信(NFC)的标签用于跟踪药物和吸入器的使用。使能NFC的标签附接在吸入器或药物容器上。在每次使用吸入器或每剂药物之后,用户将使能NFC的计算设备轻击到使能NFC的标签上。然后,使能NFC的计算设备记录发生轻击的时间,该时间对应于使用吸入器或给药的时间。使能NFC的计算设备可以包括但不限于以下内容:移动电话、平板电脑或作为电子组件130的一部分。用药跟踪的输出是上面描述的“边界条件”。
在一个示例性实施例中,识别和/或改变的结果被推送给患者或患者提供者。在另一个示例性实施例中,识别和/或改变的结果被拉到患者或患者提供者(即,按需提供)。
在一个示例性实施例中,识别和/或改变的结果以电子邮件和/或文本消息的形式和/或电子通信的其他形式提供给患者和/或患者提供者。在一个示例性实施例中,结果显示在智能手机或其他计算设备上运行的软件应用程序(“app”)中。
以上阐述的采样频率和采样持续时间仅是示例性的。在本发明的一种示例性形式中,可以改变采样频率和/或持续时间。
在一个示例性实施例中,本发明与诸如GPS之类的定位技术结合使用,以便定位患者的位置。
在图16中示出的一个实施例中,提供了一种识别生理事件的方法。该方法包括将可穿戴设备固定到用户(步骤1302)。可穿戴设备包括至少一个麦克风、运动传感器模块和处理器。该方法还包括获取来自至少一个麦克风的记录的音频数据和来自运动传感器模块的记录的运动数据(步骤1304)。该方法还包括基于记录的运动数据对预定义的音频样本的集合进行滤波,以得到基准音频样本的集合(步骤1306)。该方法还包括从基准音频样本的集合中提取数学特征的第一集合(步骤1308)。该方法还包括从记录的音频数据中提取数学特征的第二集合(步骤1310)。该方法还包括将数学特征的第二集合与数学特征的第一集合进行比较以确定是否已经发生生理事件(步骤1312)。
在一个实施例中,从多个受试者记录预定义的音频样本的集合。
在一个实施例中,该方法还包括:当比较步骤确定出发生了生理事件时,基于从记录的音频数据中提取的附加数学特征与从基准音频样本中提取的附加数学特征的比较来执行确定的验证。
在一个实施例中,至少一个麦克风包括第一麦克风和第二麦克风,第一麦克风朝向用户,并且第二麦克风朝向远离用户。在这样的实施例中,该方法还包括:在提取数学特征的第二集合之前,从由第一麦克风生成的信号中减去来自第二麦克风的信号。
在一个实施例中,滤波步骤还包括基于用户数据滤波预定义的频谱图。在这样的实施例中,用户数据选自由手术史、疾病状况、药物使用、人口统计学、用户体重和用户身高组成的群组。
在一个实施例中,可穿戴设备被贴附在最大脉冲点处。
在一个实施例中,可穿戴设备被贴附在用户的关节附近。
在一个实施例中,可穿戴设备被贴附到患者的腹部。
在一个实施例中,该方法还包括将记录的音频数据和记录的运动数据导出到计算设备,并使用该计算设备分析记录的音频数据和记录的运动数据,以验证是否已发生了生理事件的确定。在一个这样的实施例中,分析步骤包括至少部分地基于在比较步骤中未使用的参数来分析记录的音频数据和记录的运动数据。
在另一方面,提供了一种用于提供关于生理事件的反馈的系统。该系统包括可穿戴设备和计算设备。可穿戴设备被配置为由患者穿戴并且包括至少一个麦克风,该至少一个麦克风被配置为捕获记录的音频数据。可穿戴设备还包括运动传感器模块,其被配置为捕获记录的运动数据。可穿戴设备还包括处理器,其被配置为基于记录的音频数据和记录的运动数据来确定是否发生了生理事件,并且在发生了生理事件时生成信号。该计算设备包括显示器并且与可穿戴设备通信。该计算设备被配置为:(i)接收来自可穿戴设备的记录的音频数据;(ii)接收来自可穿戴设备的记录的运动数据;(iii)接收来自处理器的信号;并且(iv)在显示器上提供图形用户界面,以指示发生了生理事件。
在一个实施例中,计算设备是智能电话。
在另一个实施例中,计算设备还包括处理器,该处理器被配置为至少部分地基于可穿戴设备的处理器未使用的参数来分析记录的音频数据和记录的运动数据。
在另一方面,提供了一种非暂时性计算机可读介质,其包含用于执行识别生理事件的方法的计算机可执行编程指令。该方法包括从至少一个麦克风获取记录的音频数据和从运动传感器模块获取记录的运动数据,该至少一个麦克风和运动传感器模块被容纳在贴附于用户的可穿戴设备中。该方法还包括基于记录的运动数据来滤波预定义的音频样本的集合,以得到基准音频样本的集合。该方法还包括从基准音频样本的集合中提取数学特征的第一集合。该方法还包括从记录的音频数据中提取数学特征的第二集合。该方法还包括将数学特征的第二集合与数学特征的第一集合进行比较以确定是否发生了生理事件。该方法还包括使图形用户界面响应地显示已经发生了生理事件的指示。
在另一方面,提供了一种用于分析呼吸运动的方法。该方法包括将可穿戴设备贴附到用户。可穿戴设备包括运动传感器模块。该方法还包括从运动传感器模块获取记录的运动数据。该方法还包括计算胸壁的运动以确定呼吸循环的潮气量。
在另一实施例中,可穿戴设备包括至少一个麦克风,并且该方法还包括利用至少一个麦克风获取记录的音频数据,该记录的音频数据包括呼吸声音。该方法还包括基于记录的运动数据来确定在其期间出现呼吸声音的呼吸循环的阶段。
在另一方面,提供了一种识别生理事件的方法。该方法包括将可穿戴设备贴附到用户。可穿戴设备包括至少一个麦克风和处理器。该方法还包括从至少一个麦克风获取记录的音频数据。该方法还包括基于用户数据滤波预定义的音频样本的集合,以得到基准音频样本的集合。该方法还包括从基准音频样本的集合中提取数学特征的第一集合。该方法还包括从记录的音频数据中提取数学特征的第二集合。该方法还包括将数学特征的第二集合与数学特征的第一集合进行比较以确定是否发生了生理事件。
在一个实施例中,用户数据选自由手术史、疾病状况、药物使用、人口统计学、用户体重和用户身高组成的群组。
在另一方面,提供了一种识别生理事件的方法。该方法包括将可穿戴设备贴附到用户。可穿戴设备包括至少一个麦克风和处理器。该方法还包括从至少一个麦克风获取记录的音频数据。该方法还包括从基准音频样本的集合中提取数学特征的第一集合。该方法还包括对数学特征的第一集合施加调整以确定调整后的数学特征。该方法还包括从记录的音频数据中提取数学特征的第二集合。该方法还包括将数学特征的第二集合与调整后的数学特征进行比较,以确定是否发生了生理事件。
在一个实施例中,可穿戴设备包括运动传感器模块,并且该方法包括从运动传感器模块获取记录的运动数据。该方法还包括使用记录的运动数据来计算调整后的数学特征。
在一个实施例中,使用用户数据来计算调整后的数学特征。用户数据选自由手术史、疾病状况、药物使用、人口统计学、用户体重和用户身高组成的群组。
图18和图19示出了确定与使用由可穿戴设备100收集到的数据检测到的咳嗽相关联的误吸风险的方法。在图18中,在步骤1402处,首先基于音频使用麦克风305和/或麦克风310检测咳嗽。咳嗽可使用本文描述的任何过程进行识别。在识别出咳嗽之后,在步骤1404处,评估用户的胸壁运动。该评估可以基于从运动传感器模块317接收到的数据。如果用户的胸壁运动未反映出用户咳嗽,则可以确定出用户实际上没有咳嗽。例如,该区域中的其他人可能咳嗽了,或者其他环境噪音可能创建了指示咳嗽的音频数据。另一方面,如果运动数据指示出胸壁确实经历了指示咳嗽的运动,则评估胸壁运动的幅度和/或加速度。这可以允许确定咳嗽是强咳嗽还是弱咳嗽。例如,胸壁的高幅度和/或运动加速可能指示出它是强咳嗽,具有对应地较低的误吸风险。另一方面,胸壁运动的低幅度和/或加速可能指示出弱咳嗽,具有对应地更高的误吸风险。在步骤1408处,可以基于运动数据来评估用户的呼吸模式,以确定在呼吸循环中何时发生咳嗽。这可以进一步允许确定误吸风险。
转到图19,在步骤1502处,可以使用从运动传感器模块317接收到的运动数据基于胸壁运动来检测咳嗽。例如,可以通过分析胸壁运动、速度、加速度及其派生来识别咳嗽。在检测到咳嗽之后,在步骤1504处,可以评估胸壁运动数据以确定该咳嗽是强咳嗽还是弱咳嗽。在步骤1506处,可以分析从麦克风305和/或麦克风310接收到的音频数据。例如,如果对胸壁运动的分析指示出已经发生了强咳嗽,并且对音频数据的分析证实了这一点,则可以确定发生了具有低误吸风险的强咳嗽。另一方面,如果对胸壁运动的分析指示出强咳嗽,但是对音频数据的分析却没有证实强咳嗽,则这可能指示用户的上呼吸道受阻。在这种情况下,可穿戴设备100可以向用户或护理人员发出通知以检查上呼吸道阻塞。
如果对胸壁运动的分析指示出弱咳嗽并且音频数据指示出强咳嗽,则这可能指示错误。例如,可穿戴设备100可能会错误地定位在用户的胸壁上。相反,如果对胸壁运动的分析指示出弱咳嗽,并且对音频数据的分析证实了该评估,则可以确定出现了弱咳嗽。如上面描述的,可选地,可以基于运动数据来评估用户的呼吸模式,以确定在呼吸循环中何时发生咳嗽。这可以进一步允许确定误吸风险。
图20中示出了一种确定与咳嗽相关联的风险的方法。在步骤1602处,检测咳嗽。咳嗽可通过本文描述的任何过程来检测。例如,可以通过分析从麦克风305、310接收到的音频数据或从运动传感器模块317接收到的运动数据来检测咳嗽。在步骤1604处,确定出在给定间隔内发生的咳嗽的数量以识别咳嗽的簇。例如,当在30秒内识别出三个或更多个的咳嗽时,可以识别出簇。在其他实施例中,可以使用不同数量的咳嗽或不同持续时间(例如10秒、5分钟等)来对咳嗽簇进行分类。在某些实施例中,运动数据可用于识别咳嗽簇,其中基于音频的方法仅识别单个咳嗽(即,当患者在咳嗽期间声门关闭时,或者大声的环境声掩盖附加咳嗽时)。在步骤1606处,基于咳嗽的频率,确定与咳嗽相关联的风险水平。在步骤1608处,基于该风险水平,可以调整用于激活进一步的评估算法的阈值。以这种方式评估风险具有许多优势。例如,通过仅在识别出高风险的咳嗽簇时才实施进一步的评估,可以节省电池和计算能力。
图21示出了确定咳嗽特性的方法。在步骤1702处,检测咳嗽。咳嗽可通过本文描述的任何过程来检测。例如,可以通过分析从麦克风305、310接收到的音频数据或从运动传感器模块317接收到的运动数据来检测咳嗽。在步骤1704处,确定咳嗽的性质(例如,咳嗽是干咳还是湿咳)。例如,这可以基于从麦克风305、310接收到的音频数据来完成。在一些实施例中,从运动传感器模块317接收到的运动数据用于确定咳嗽是“强”咳嗽还是“弱”咳嗽。基于咳嗽的性质和特性,可以确定误吸风险水平。例如,干咳具有相对较低的感染和/或误吸的风险,而湿咳具有相对较高的感染和/或误吸的风险。基于风险水平的确定,在步骤1710处,可以发起进一步的评估算法。通过仅在检测到高风险咳嗽时才发起进一步的评估算法,可以节省计算和电池资源。
图22示出了识别与咳嗽相关联的风险水平的另一种方法。在步骤1802处,检测咳嗽。咳嗽可通过本文描述的任何过程来检测。例如,可以通过分析从麦克风305、310接收到的音频数据或从运动传感器模块317接收到的运动数据来检测咳嗽。在步骤1804处,确定咳嗽率是增加还是减少。例如,可以将在前24小时内识别出的咳嗽次数与在前72小时内接收到的咳嗽次数进行比较。另外,在步骤1806处,可以基于从运动传感器模块317接收到的运动数据来评估用户的活动水平。如果咳嗽率增加了并且用户的活动水平也增加了,则增加的咳嗽速度可能是由于锻炼引起的支气管痉挛。在这种情况下,可能不需要进一步的行动。此外,如果咳嗽率降低了并且活动水平增加了,则这可能指示出症状有所改善。咳嗽率的降低和活动水平的同时降低可能指示出用户的症状没有明显改变。
在一些实施例中,在步骤1808处,可以使用从运动传感器模块317接收到的运动数据来评估用户姿势的变化。这可以进一步帮助评估用户的状况。例如,如果用户的咳嗽率增加了、用户的活动水平基本保持不变或降低了、并且用户的姿势指示出用户正躺下,则这可能指示出用户正在经历夜间症状。在某些情况下,这也可能指示出用户正在经历心脏衰竭的恶化。在用户的咳嗽率增加、用户的活动水平保持不变或下降、并且运动数据指示出用户没有躺下的情况下,这可能指示出用户的症状正在恶化。在某些情况下,这也可能指示出用户正在经历心脏衰竭的恶化。
另一方面,在用户的咳嗽率降低、用户的活动水平基本保持不变、并且用户的姿势未改变的情况下,这可能指示出用户的症状正在改善。在用户的咳嗽率降低、用户的活动水平基本保持不变且用户的姿势没有改变的情况下,这可能指示出咳嗽率的变化与姿势有关。
图23示出了一种用于评估与异常呼吸声音相关联的风险的方法。该方法包括许多与以上关于图22描述的过程和评估相同的过程和评估。在步骤1902处,可以检测异常呼吸声音。例如,可以基于从麦克风305、310接收到的音频数据来检测异常呼吸声音。异常呼吸声音可以包括但不限于喘息声或干罗音。在步骤1904处,可以确定发生异常呼吸声音的速率是增加还是减小。例如,可以将在前24小时内识别出的异常呼吸声音的数量与在前72小时内识别出的异常呼吸声音的数量进行比较。在步骤1906处,可以基于从运动传感器模块317接收到的运动数据来评估用户的活动水平。可选地,在步骤1908处,可以基于从运动传感器模块317接收到的运动数据来评估用户姿势的变化。基于关于异常呼吸声的速率、用户的活动水平以及用户姿势的变化的该信息,可以如上面参考图22描述的来确定风险水平。例如,在异常呼吸声音速率增加和用户活动水平的增加的情况下,这可能指示出增加的异常呼吸声音速率与锻炼引起的支气管痉挛有关。
图24示出了表征异常呼吸声音(诸如不定呼吸音)的另一种方法。例如,这可能包括喘息声、干罗音和啰音。在步骤2002处,可以使用从麦克风305、310接收到的音频数据来检测异常呼吸声音。在步骤2004处,可以使用从运动传感器模块317接收到的运动数据来确定出现异常呼吸声音的呼吸循环的阶段。在步骤2008处,在呼吸循环的呼气阶段期间或者呼气和吸气阶段期间出现异常呼吸声音的情况下,风险水平可能相对较低,并且可生成临床医生要审查的信息。
另一方面,如果在吸气阶段期间出现异常呼吸声音的情况下用户穿戴多个设备(例如,第一设备和第二设备),则可以在步骤2006处确定上下肺野之间是否存在梯度。如果不存在这样的梯度,或者梯度很低,则风险水平可能相对较低,并且在步骤2008处,可以生成信息以供临床医生审查。另一方面,如果上下肺野之间存在明显的梯度,这可能指示出用户经历了喘鸣声。在这种情况下,可以生成警报以使用户或护理人员意识到风险。该警报可以是例如可听警报或触觉警报(例如,振动)。可替选地或附加地,可以生成文本消息、电子邮件或其他基于文本的警报,并将其发送给用户、护理人员或临床医生。
在某些情况下,使用音频数据识别出的异常呼吸声音是不定呼吸音(例如,喘息声、干罗音、哨声等)。在其他情况下,异常呼吸声音指示出用户正在使用吸入器。在这种情况下,音频数据可用于确定所使用的吸入器的类型。这可以使用从面向胸部的麦克风305以及背景麦克风310接收到的音频数据来完成。不同类型的吸入器导致可以在音频数据中识别出不同类型的声音。此外,可以分析音频数据以识别在吸入器使用期间出现的肺音。此外,可以分析运动数据以确定在呼吸循环的哪个阶段中使用吸入器(例如,基于胸壁运动)。
对用户使用吸入器的分析可用于识别错误的吸入器使用。许多患者在使用其吸入器时采用了错误的技术,导致次优的剂量。与正常吸入器声音和胸壁运动的偏差可用于识别吸入器误用。具体而言,与胸壁运动相比的吸入器“喀哒”声的定时和/或指示吸入器使用的呼吸声音的定时可用于识别吸入器误用。
以上描述并且在图18-图24中示出的方法每个提供了通过监视和分析从麦克风305、310接收到的音频数据以及从运动传感器模块317接收到的运动数据而提供的优点的示例。使用在呼吸系统中生成的声音以及例如胸壁运动、用户活动水平和用户姿势来分析咳嗽和其他异常呼吸声音的能力允许了仅使用音频不可能的风险水平的分析。运动数据和音频数据两者的使用可以提高对特定类型的呼吸声音进行分类的准确性,并且允许对特定类型的呼吸声音进行进一步表征。这提供了明显的临床优势。通过在同一可穿戴设备中同时包括音频传感器(诸如麦克风)以及一个或多个运动传感器,可以捕获和分析可靠的数据。
尽管前面的描述和附图表示本发明的优选或示例性实施例,但是将理解的是,在不脱离所附权利要求的精神和范围以及等同范围的情况下,可以在其中进行各种添加、修改和替换。特别地,对于本领域技术人员将清楚的是,在不脱离其精神或基本特性的情况下,本发明可以以其他形式、结构、布置、比例、尺寸以及其他元件、材料和组件来实施。本领域技术人员将进一步认识到,本发明可以在结构、布置、比例、尺寸、材料和组件的许多修改下使用,并且可以在本发明的实践中使用,其在不背离本发明原理的情况下特别适合于特定的环境和操作要求。因此,当前公开的实施例在所有方面都应被认为是说明性的而不是限制性的,本发明的范围由所附权利要求及其等同物限定,并且不限于前述描述或实施例。相反,所附权利要求应被宽泛地解释为包括本发明的其他变型和实施例,其可以由本领域技术人员在不脱离本发明的范围和等同范围的情况下做出。本文识别出的所有专利和公开的专利申请均通过引用整体并入本文。
- 用于检测生理事件的装置和方法
- 用于人体汗液生理指标检测及脱水事件提醒的微流芯片及其制备方法与应用