一种杂音抑制方法及信号处理装置
文献发布时间:2023-06-19 18:35:48
技术领域
本申请涉及音频信号处理技术领域,尤其涉及一种杂音抑制方法及信号处理装置。
背景技术
目前在手机终端市场中,小型扬声器大规模地应用,然而,小型扬声器在其振膜的速度或者振动量比较大时,即使其振膜的振幅未超过最大设计振幅,仍能听到明显的杂音;而且,小型扬声器通常采用小腔体的设计,在低频、大振幅的音源的冲击下容易产生大量失真,导致声音不纯;另外,小型扬声器腔体内的气流还可能摩擦出声孔进而导致气流杂音。上述杂音现象特别是在播放钢琴音时更加明显,这是由于钢琴音具有突变起振的音色,且起振音色的音高与小型扬声器的固有频率可能会重合,因此上述杂音也被称为“钢琴杂音”。
在用户对声音音质和听感要求越来越高的当今社会,小型扬声器的杂音问题越来越难以满足用户需求,因此,如何对音频信号中的杂音信号进行有效抑制是本行业亟待解决的技术问题。
发明内容
为解决上述技术问题,本申请实施例提供了一种杂音抑制方法及信号处理装置,以实现对音频信号中杂音信号的有效抑制,提高声音播放质量,满足用户对声音音质和听感的需求。
为解决上述问题,本申请实施例提供了如下技术方案:
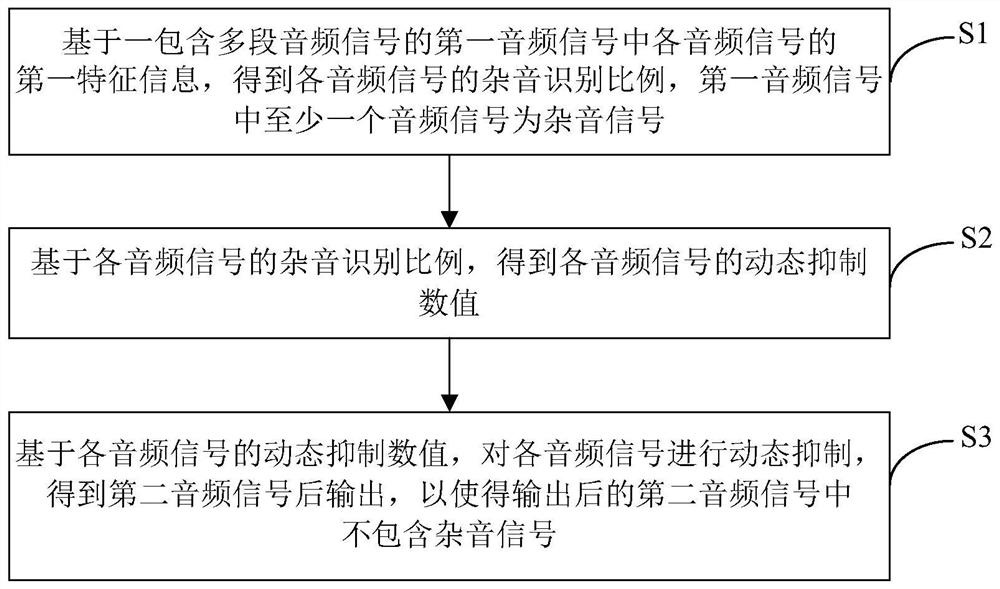
一种杂音抑制方法,包括:
基于一包含多段音频信号的第一音频信号中各音频信号的第一特征信息,得到各所述音频信号的杂音识别比例,所述第一音频信号中至少一个音频信号为杂音信号,所述杂音识别比例表征所述音频信号被识别为杂音信号的概率,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征;
基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值;
基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号。
可选的,基于各所述音频信号的第一特征信息,得到各所述音频信号的杂音识别比例包括:
基于各所述音频信号的第一特征信息,利用杂音识别模型计算得到各所述音频信号的第一预测函数值,所述第一预测函数值表征所述音频信号被识别为杂音信号的概率;
基于各所述音频信号的第一预测函数值,得到各所述音频信号的杂音识别比例;
其中,所述杂音识别模型以包括多段杂音信号和多段非杂音信号的第一样本音频信号作为训练样本,以所述第一样本音频信号中各音频信号是否为杂音信号的标注结果作为样本标签训练得到。
可选的,基于各所述音频信号的第一预测函数值,得到各所述音频信号的杂音识别比例包括:
基于各所述音频信号的第一预测函数值,对各所述音频信号的第一预测函数值进行归一化,得到各所述音频信号的杂音识别比例。
可选的,该方法在基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值之前还包括:
获取所述第一音频信号中各音频信号的幅值;
基于各所述音频信号的幅值,对各所述音频信号的幅值进行归一化,得到各所述音频信号的幅值比例;
基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值包括:
基于各所述音频信号的杂音识别比例,得到各所述音频信号的第一动态抑制数值,所述音频信号的杂音识别比例越大,所述音频信号的第一动态抑制数值越大;
基于各所述音频信号的幅值比例,得到各所述音频信号的第二动态抑制数值,所述音频信号的幅值比例越大,所述音频信号的第二动态抑制数值越大;
基于各所述音频信号的第一动态抑制数值和第二动态抑制数值,得到各所述音频信号的动态抑制数值。
可选的,该方法在基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值之前还包括:
基于所述第一音频信号中各音频信号的第二特征信息,得到各所述音频信号的非杂音识别比例,所述音频信号的非杂音识别比例表征所述音频信号被识别为非杂音信号的概率,各所述音频信号的第二特征信息为各所述音频信号的时域和/或频域中的至少一个特征;
基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值还包括:
基于各所述音频信号的非杂音识别比例,得到各所述音频信号的第三动态抑制数值,所述音频信号的非杂音识别比例越大,所述音频信号的第三动态抑制数值越小;
基于各所述音频信号的第一动态抑制数值和第二动态抑制数值,得到各所述音频信号的动态抑制数值包括:
基于各所述音频信号的第一动态抑制数值、第二动态抑制数值和第三动态抑制数值,得到各所述音频信号的动态抑制数值。
可选的,基于各所述音频信号的第二特征信息,得到各所述音频信号的非杂音识别比例包括:
基于各所述音频信号的第二特征信息,利用非杂音识别模型计算得到各所述音频信号的第二预测函数值,所述第二预测函数值表征所述音频信号被识别为非杂音信号的概率;
基于各所述音频信号的第二预测函数值,得到各所述音频信号的非杂音识别比例;
其中,所述非杂音识别模型以包括多段非杂音信号和多段杂音信号的第二样本音频信号作为训练样本,以所述第二样本音频信号中各音频信号是否为非杂音信号的标注结果作为样本标签训练得到。
可选的,基于各所述音频信号的第二预测函数值,得到各所述音频信号的非杂音识别比例包括:
基于各所述音频信号的第二预测函数值,对各所述音频信号的第二预测函数值进行归一化,得到各所述音频信号的非杂音识别比例。
可选的,基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号包括:
基于各所述音频信号的动态抑制数值,对各所述音频信号的幅值进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号。
可选的,该方法还包括:
获取一包含多段音频信号的待识别音频信号;
提取该待识别音频信号中各音频信号的第一特征信息,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征;
基于该待识别音频信号中各音频信号的第一特征信息,利用杂音识别模型得到各所述音频信号的第一识别结果,所述第一识别结果表征所述音频信号是否为杂音信号;
如果该待识别音频信号中至少一个音频信号被识别为杂音信号,则该待识别音频信号为所述第一音频信号。
可选的,该方法还包括:
提取该待识别音频信号中各音频信号的第二特征信息,各所述音频信号的第二特征信息为各所述音频信号的时域和/或频域中的至少一个特征;
基于该待识别音频信号中各音频信号的第二特征信息,利用非杂音识别模型得到各所述音频信号的第二识别结果,所述第二识别结果表征所述音频信号是否为非杂音信号;
如果所述第一识别结果和所述第二识别结果均表征所述音频信号为杂音信号,则确定该音频信号为杂音信号;
如果所述第一识别结果和所述第二识别结果均表征所述音频信号为非杂音信号,则确定该音频信号为非杂音信号;
如果所述第一识别结果表征所述音频信号为杂音信号,且所述第二识别结果表征所述音频信号为非杂音信号,或所述第一识别结果表征所述音频信号为非杂音信号,且所述第二识别结果表征所述音频信号为杂音信号,则该方法还包括:
基于该待识别音频信号中各音频信号的第一特征信息,得到各所述音频信号的预设特征值;
基于各所述音频信号的预设特征值与预设门限值,得到各所述音频信号的第三识别结果,所述第三识别结果表征所述音频信号是否为杂音信号;
如果所述第三识别结果表征所述音频信号为杂音信号,则确定该音频信号为杂音信号,否则为非杂音信号。
可选的,所述音频信号的第一特征信息包括所述音频信号的短时能量、梅尔倒谱系数、一阶差分梅尔倒谱系数、响度和声门激励脉冲中的至少一个。
一种信号处理装置,包括:处理器和扬声器,其中,
所述处理器用于对输入的第一音频信号执行上述任一项所述的杂音抑制方法的各个步骤,并将输出的第二音频信号传输给所述扬声器。
与现有技术相比,上述技术方案具有以下优点:
本申请实施例所提供的杂音抑制方法,包括:基于一包含多段音频信号的第一音频信号中各音频信号的第一特征信息,得到各所述音频信号的杂音识别比例,所述第一音频信号中至少一个音频信号为杂音信号,所述杂音识别比例表征所述音频信号被识别为杂音信号的概率,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征;基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值;基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号,从而实现对所述第一音频信号中杂音信号的有效抑制,提高声音播放质量,满足用户对声音音质和听感的需求。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请一个实施例所提供的杂音抑制方法的流程示意图;
图2为本申请另一个实施例所提供的杂音抑制方法的流程示意图;
图3为杂音识别模型将杂音信号(正样本点,用+表示)和非杂音信号(负样本点,用-表示)划分为两类的示意图;
图4为本申请又一个实施例所提供的杂音抑制方法的流程示意图;
图5为本申请再一个实施例所提供的杂音抑制方法的流程示意图;
图6为第一音频信号和第二音频信号的幅值对比展示图;
图7为本申请又一个实施例所提供的杂音抑制方法中,对一待识别音频信号中各音频信号是否为杂音信号进行识别的流程示意图;
图8为利用杂音识别模型对一待识别音频信号中各音频信号是否为杂音信号进行识别得到的第一识别结果展示图;
图9为本申请再一个实施例所提供的杂音抑制方法中,对一待识别音频信号中各音频信号是否为杂音信号进行识别的流程示意图;
图10为利用非杂音识别模型对一待识别音频信号中各音频信号是否为非杂音信号进行识别得到的第二识别结果展示图;
图11为一待识别音频信号中各音频信号的响度特征展示图;
图12为一待识别音频信号中各音频信号的声门激励脉冲频谱展示图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
在下面的描述中阐述了很多具体细节以便于充分理解本申请,但是本申请还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本申请内涵的情况下做类似推广,因此本申请不受下面公开的具体实施例的限制。
其次,本申请结合示意图进行详细描述,在详述本申请实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本申请保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
正如背景技术部分所述,在用户对声音音质和听感要求越来越高的当今社会,小型扬声器的杂音问题越来越难以满足用户需求,因此,如何对音频信号中的杂音信号进行有效抑制是本行业亟待解决的技术问题。
有鉴于此,本申请实施例提供了一种杂音抑制方法,如图1所示,该方法包括:
S1:基于一包含多段音频信号的第一音频信号中各音频信号的第一特征信息,得到各所述音频信号的杂音识别比例,所述第一音频信号中至少一个音频信号为杂音信号,所述杂音识别比例表征所述音频信号被识别为杂音信号的概率,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征。
可选的,在本申请的一个实施例中,所述音频信号的第一特征信息包括所述音频信号的短时能量、梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,简称MFCC)、一阶差分梅尔倒谱系数(一阶差分MFCC)、响度和声门激励脉冲中的至少一个,但本申请对此并不做限定,在本申请的其他实施例中,所述音频信号的第一特征信息还可以包括所述音频信号的时域和/或频域中的其他特征,具体视情况而定。
具体的,在本申请的一个实施例中,如图2所示,基于各所述音频信号的第一特征信息,得到各所述音频信号的杂音识别比例包括:
S11:基于各所述音频信号的第一特征信息,利用杂音识别模型计算得到各所述音频信号的第一预测函数值,所述第一预测函数值表征所述音频信号被识别为杂音信号的概率;
其中,所述杂音识别模型以包括多段杂音信号和多段非杂音信号的第一样本音频信号作为训练样本,以所述第一样本音频信号中各音频信号是否为杂音信号的标注结果作为样本标签训练得到。
可选的,在本申请的一个实施例中,所述杂音识别模型为支持向量机模型(Support Vector Machine,SVM),所述支持向量机模型的第一预测函数的计算公式为:
f(x)=w
其中,w
由公式(1)可以看出,将各所述音频信号的第一特征信息构成的特征向量输入所述支持向量机模型中,即可利用所述支持向量机模型计算得到各所述音频信号的第一预测函数值f(x)=w
可选的,在本申请的另一个实施例中,所述杂音识别模型为K-近邻模型,本申请对此并不做限定,具体视情况而定。
下面以所述杂音识别模型为支持向量机模型为例,对所述杂音识别模型的训练过程进行描述,以对经过训练后的所述杂音识别模型基于所述音频信号的第一特征信息计算得到的该音频信号的第一预测函数值如何表征该音频信号被识别为杂音信号的概率进行说明。
可选的,在本申请的一个实施例中,以二维空间的样本点x=(x1,x2)为例对所述支持向量机模型的训练过程进行描述。具体的,如图3所示,将所述第一样本音频信号中各音频信号的第一特征信息构成的特征向量输入所述支持向量机模型中,对所述支持向量机模型进行训练,以使得所述支持向量机模型找到最大间隔超平面f(x)=w
由此可见,通过对所述支持向量机模型进行训练,使得当所述音频信号的第一预测函数值f(x)大于0时,该音频信号位于超平面f(x)=w
S12:基于各所述音频信号的第一预测函数值,得到各所述音频信号的杂音识别比例。
可选的,在本申请的一个实施例中,基于各所述音频信号的第一预测函数值,得到各所述音频信号的杂音识别比例包括:
基于各所述音频信号的第一预测函数值,对各所述音频信号的第一预测函数值进行归一化,得到各所述音频信号的杂音识别比例。
需要说明的是,在上述实施例中,对各所述音频信号的第一预测函数值进行归一化,得到各所述音频信号的杂音识别比例,即将各所述音频信号的第一预测函数值映射到[0,1]区间进行比较,所述音频信号中包含杂音信号的权重越大,该音频信号被识别为杂音信号的概率越大,即该音频信号的第一预测函数值越大,因此,该音频信号的杂音识别比例也越大,越接近于1,后续基于该音频信号的杂音识别比例,对该音频信号的抑制也越多,反之,所述音频信号中包含的杂音信号的权重越小,该音频信号被识别为杂音信号的概率越小,即该音频信号的第一预测函数值越小,因此,该音频信号的杂音识别比例也越小,越接近于0,后续基于该音频信号的杂音识别比例,对该音频信号的抑制也越少。
还需要说明的是,在上述实施例中,如果所述音频信号被识别为杂音信号的概率大于一定的概率值,即该音频信号的第一预测函数值大于一定的阈值,则该音频信号的杂音识别比例可以直接设定为1,以便于后续对杂音识别比例为1的各所述音频信号进行相同程度地抑制;反之,如果所述音频信号被识别为杂音信号的概率小于一定的概率值,即该音频信号的第一预测函数值小于一定的阈值,则该音频信号的杂音识别比例可以直接设定为0,以便于后续对杂音识别比例为0的各所述音频信号进行零抑制或不进行抑制。
具体的,在本申请的一个实施例中,基于各所述音频信号的第一预测函数值,对各所述音频信号的第一预测函数值进行归一化,得到各所述音频信号的杂音识别比例包括:
基于各所述音频信号的第一预测函数值,以及预先设定的第一阈值和第二阈值,对各所述音频信号的第一预测函数值进行归一化,得到各所述音频信号的杂音识别比例,其中,所述第一阈值大于所述第二阈值,且所述第一阈值不大于各所述音频信号的第一预测函数值中的最大值,所述第二阈值不小于各所述音频信号的第一预测函数值中的最小值,对各所述音频信号的第一预测函数值进行归一化的公式为:
其中,x为各所述音频信号的第一特征信息构成的特征向量,f(x)为各所述音频信号的第一预测函数值,A为预先设定的第一阈值,B为预先设定的第二阈值,ratio(f(x))为各所述音频信号的杂音识别比例。
在上述实施例的基础上,可选的,在本申请的一个实施例中,所述第一阈值为各所述音频信号的第一预测函数值中的最大值,所述第二阈值为各所述音频信号的第一预测函数值中的最小值;在本申请的另一个实施例中,所述第一阈值小于各所述音频信号的第一预测函数值中的最大值,所述第二阈值大于各所述音频信号的第一预测函数值中的最小值,本申请对所述第一阈值和所述第二阈值并不做限定,具体视情况而定。
S2:基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值。
S3:基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号。
可选的,在本申请的一个实施例中,对于所述第一音频信号中的杂音信号,基于该音频信号的杂音识别比例,得到该音频信号的动态抑制数值,进而基于该音频信号的动态抑制数值,对该音频信号进行动态抑制,对于所述第一音频信号中的非杂音信号,则不对该音频信号进行抑制。
可选的,在本申请的另一个实施例中,对于所述第一音频信号中的任一音频信号,基于该音频信号的杂音识别比例,得到该音频信号的动态抑制数值,其中,如果该音频信号为杂音信号,则该音频信号的动态抑制数值不小于0,如果该音频信号为非杂音信号,则该音频信号的动态抑制数值等于0,进一步基于该音频信号的动态抑制数值,对该音频信号进行动态抑制。
在上述实施例的基础上,在本申请的一个实施例中,基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号包括:
基于各所述音频信号的动态抑制数值,对各所述音频信号的幅值进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包含杂音信号。
由此可见,本申请实施例所提供的杂音抑制方法,根据各所述音频信号的杂音识别比例对各所述音频信号进行动态抑制,即根据各所述音频信号被识别为杂音信号的概率对各所述音频信号进行动态抑制,由于所述音频信号中包含杂音信号的权重越大,则该音频信号被识别为杂音信号的概率越大,该音频信号的杂音识别比例也越大,需要对该音频信号的抑制也越多,因此,当所述音频信号为杂音信号时,该方法对其进行抑制,且该音频信号的杂音识别比例越大,对其抑制也越多,而当所述音频信号为非杂音信号时,该方法对其不进行抑制或进行零抑制,从而实现对所述第一音频信号中杂音信号的有效抑制,提高声音播放质量,满足用户对声音音质和听感的需求。
需要说明的是,在实际应用中,当所述音频信号为杂音信号时,对该音频信号进行抑制多少,还需要考虑该音频信号的幅值大小,如果该音频信号的幅值较大,则可以对该音频信号抑制多一些,以消除该音频信号中的杂音信号,而不会影响该音频信号的音质和听感,如果该音频信号的幅值较小,则需要对该音频信号抑制少一些,以防止对小信号音频信号抑制过多,造成其音质或听感上的损失。
因此,在上述实施例的基础上,在本申请的一个实施例中,如图4所示,该方法在基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值之前还包括:
S13:获取所述第一音频信号中各音频信号的幅值。
具体的,在本申请的一个实施例中,利用Peak检测方法获取所述第一音频信号中各音频信号的幅值。但本申请对幅值检测方法并不做限定,具体视情况而定。
S14:基于各所述音频信号的幅值,对各所述音频信号的幅值进行归一化,得到各所述音频信号的幅值比例。
需要说明的是,在上述实施例中,对各所述音频信号的幅值进行归一化,得到各所述音频信号的幅值比例,即将各所述音频信号的幅值映射到[0,1]区间进行比较,当所述音频信号为杂音信号时,如果该音频信号的幅值越大,则该音频信号的幅值比例也越大,越接近于1,从而可以对该音频信号抑制多一些,以消除该音频信号中的杂音信号,而不会影响该音频信号的音质和听感,反之,如果该音频信号的幅值越小,则该音频信号的幅值比例也越小,越接近于0,从而需要对该音频信号抑制少一些,以防止对小信号音频信号抑制过多,造成其音质或听感上的损失。
还需要说明的是,在上述实施例中,当所述音频信号为杂音信号时,如果所述音频信号的幅值大于一定阈值,则该音频信号的幅值比例可以直接设定为1,以便于后续对幅值比例为1的各所述音频信号进行相同程度地抑制;反之,如果所述音频信号的幅值小于一定阈值,则该音频信号的幅值比例可以直接设定为0,以便于后续对幅值比例为0的各所述音频信号进行零抑制或不进行抑制。
具体的,在本申请的一个实施例中,基于各所述音频信号的幅值,对各所述音频信号的幅值进行归一化,得到各所述音频信号的幅值比例包括:
基于各所述音频信号的幅值,以及预先设定的第三阈值和第四阈值,对各所述音频信号的幅值进行归一化,得到各所述音频信号的幅值比例,其中,所述第三阈值大于所述第四阈值,且所述第三阈值不大于各所述音频信号的幅值中的最大值,所述第四阈值不小于各所述音频信号的幅值中的最小值,对各所述音频信号的幅值进行归一化的公式为:
其中,k为各所述音频信号的幅值,M为预先设定的第三阈值,N为预先设定的第四阈值,ratio(k)为各所述音频信号的幅值比例。
在上述实施例的基础上,可选的,在本申请的一个实施例中,所述第三阈值为各所述音频信号的幅值中的最大值,所述第四阈值为各所述音频信号的幅值中的最小值;在本申请的另一个实施例中,所述第三阈值小于各所述音频信号的幅值中的最大值,所述第四阈值大于各所述音频信号的幅值中的最小值,本申请对所述第三阈值和所述第四阈值并不做限定,具体视情况而定。
继续如图4所示,基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值包括:
S21:基于各所述音频信号的杂音识别比例,得到各所述音频信号的第一动态抑制数值,所述音频信号的杂音识别比例越大,所述音频信号的第一动态抑制数值越大;
S22:基于各所述音频信号的幅值比例,得到各所述音频信号的第二动态抑制数值,所述音频信号的幅值比例越大,所述音频信号的第二动态抑制数值越大;
S23:基于各所述音频信号的第一动态抑制数值和第二动态抑制数值,得到各所述音频信号的动态抑制数值。
由此可见,本申请实施例所提供的杂音抑制方法,不仅可以根据各所述音频信号的杂音识别比例对各所述音频信号进行动态抑制,还可以根据各所述音频信号的幅值比例对各所述音频信号进行动态抑制,从而在对杂音信号进行有效抑制时,防止对小信号音频信号抑制过多,造成其音质或听感上的损失,使得各所述音频信号在听感上柔和过渡,没有突然的忽大忽小。
需要说明的是,在实际应用中,当所述音频信号为杂音信号时,对该音频信号进行抑制多少,还需要考虑该音频信号中包含非杂音信号(如人声信号等)的权重,如果该音频信号中包含非杂音信号的权重较大,则需要对该音频信号的抑制少一些,以防止对该音频信号中的非杂音信号进行抑制,造成该音频信号在音质或听感上的损失,如果该音频信号中包含非杂音信号的权重较小,则可以对该音频信号的抑制多一些,以消除该音频信号中的杂音信号,从而实现在保证各所述音频信号的音质和听感不受损失的情况下对杂音信号进行合理有效地抑制。
因此,在上述实施例的基础上,在本申请的一个实施例中,如图5所示,该方法在基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值之前还包括:
S15:基于所述第一音频信号中各音频信号的第二特征信息,得到各所述音频信号的非杂音识别比例,所述音频信号的非杂音识别比例表征所述音频信号被识别为非杂音信号的概率,各所述音频信号的第二特征信息为各所述音频信号的时域和/或频域中的至少一个特征。
可选的,在本申请的一个实施例中,所述音频信号的第二特征信息包括所述音频信号的短时能量、梅尔倒谱系数、一阶差分梅尔倒谱系数、响度和声门激励脉冲中的至少一个,但本申请对此并不做限定,在本申请的其他实施例中,所述音频信号的第二特征信息还可以包括所述音频信号的时域和/或频域中的其他特征,具体视情况而定。
在上述实施例的基础上,可选的,在本申请的一个实施例中,所述音频信号的第二特征信息与其第一特征信息完全相同;在本申请的另一个实施例中,所述音频信号的第二特征信息与其第一特征信息完全不同;在本申请的又一个实施例中,所述音频信号的第二特征信息与其第一特征信息部分相同,部分不同,即所述音频信号的第二特征信息中包括的特征与所述音频信号的第一特征信息中包括的特征部分相同,部分不同。
具体的,在本申请的一个实施例中,继续如图5所示,基于各所述音频信号的第二特征信息,得到各所述音频信号的非杂音识别比例包括:
S151:基于各所述音频信号的第二特征信息,利用非杂音识别模型计算得到各所述音频信号的第二预测函数值,所述第二预测函数值表征所述音频信号被识别为非杂音信号的概率;
其中,所述非杂音识别模型以包括多段非杂音信号和多段杂音信号的第二样本音频信号作为训练样本,以所述第二样本音频信号中各音频信号是否为非杂音信号的标注结果作为样本标签训练得到。
可选的,在本申请的一个实施例中,所述非杂音识别模型为支持向量机模型(Support Vector Machine,SVM),所述支持向量机模型的第二预测函数的计算公式为:
f(z)=w
其中,w
由公式(4)可以看出,将各所述音频信号的第二特征信息构成的特征向量输入所述支持向量机模型中,即可利用所述支持向量机模型计算得到各所述音频信号的第二预测函数值f(z)=w
可选的,在本申请的另一个实施例中,所述杂音识别模型为K-近邻模型,本申请对此并不做限定,具体视情况而定。
需要说明的是,所述非杂音识别模型与所述杂音识别模型的训练过程类似,将所述第二样本音频信号中各音频信号的第二特征信息构成的特征向量输入所述非杂音识别模型中,对所述非杂音识别模型进行训练,以使得所述非杂音识别模型基于所述音频信号的第二特征信息计算得到的该音频信号的第二预测函数值可以表征该音频信号被识别为非杂音信号的概率,当所述音频信号的第二预测函数值f(z)大于0时,表征该音频信号为非杂音信号,且所述音频信号的第二预测函数值f(z)越大,该音频信号被识别为非杂音信号的概率越大。
还需要说明的是,所述第二样本音频信号和所述第一样本音频信号可以相同,也可以不同,本申请对此并不做限定,具体视情况而定。
S152:基于各所述音频信号的第二预测函数值,得到各所述音频信号的非杂音识别比例。
可选的,在本申请的一个实施例中,基于各所述音频信号的第二预测函数值,得到各所述音频信号的非杂音识别比例包括:
基于各所述音频信号的第二预测函数值,对各所述音频信号的第二预测函数值进行归一化,得到各所述音频信号的非杂音识别比例。
需要说明的是,在上述实施例中,对各所述音频信号的第二预测函数值进行归一化,得到各所述音频信号的非杂音识别比例,即将各所述音频信号的第二预测函数值映射到[0,1]区间进行比较,所述音频信号中包含非杂音信号的权重越大,该音频信号被识别为非杂音信号的概率越大,即该音频信号的第二预测函数值越大,因此,该音频信号的非杂音识别比例也越大,越接近于1,后续基于该音频信号的非杂音识别比例,对该音频信号的抑制越少,反之,所述音频信号中包含的非杂音信号的权重越小,该音频信号被识别为非杂音信号的概率越小,即该音频信号的第二预测函数值越小,因此,该音频信号的非杂音识别比例也越小,越接近于0,后续基于该音频信号的非杂音识别比例,对该音频信号的抑制也越多。
还需要说明的是,在上述实施例中,如果所述音频信号被识别为非杂音信号的概率大于一定的概率值,即该音频信号的第二预测函数值大于一定的阈值,则该音频信号的非杂音识别比例可以直接设定为1,以便于后续对非杂音识别比例为1的各所述音频信号进行零抑制或不进行抑制;反之,如果所述音频信号被识别为非杂音信号的概率小于一定的概率值,即该音频信号的第二预测函数值小于一定的阈值,则该音频信号的非杂音识别比例可以直接设定为0,以便于后续对非杂音识别比例为0的各所述音频信号进行相同程度地抑制。
具体的,在本申请的一个实施例中,基于各所述音频信号的第二预测函数值,对各所述音频信号的第二预测函数值进行归一化,得到各所述音频信号的非杂音识别比例包括:
基于各所述音频信号的第二预测函数值,以及预先设定的第五阈值和第六阈值,对各所述音频信号的第二预测函数值进行归一化,得到各所述音频信号的非杂音识别比例,其中,所述第五阈值大于所述第六阈值,且所述第五阈值不大于各所述音频信号的第二预测函数值中的最大值,所述第六阈值不小于各所述音频信号的第二预测函数值中的最小值,对各所述音频信号的第二预测函数值进行归一化的公式为:
其中,z为各所述音频信号的第二特征信息构成的特征向量,f(z)为各所述音频信号的第二预测函数值,X为预先设定的第五阈值,Y为预先设定的第六阈值,ratio(f(z))为各所述音频信号的非杂音识别比例。
在上述实施例的基础上,可选的,在本申请的一个实施例中,所述第五阈值为各所述音频信号的第二预测函数值中的最大值,所述第六阈值为各所述音频信号的第二预测函数值中的最小值;在本申请的另一个实施例中,所述第五阈值小于各所述音频信号的第二预测函数值中的最大值,所述第六阈值大于各所述音频信号的第二预测函数值中的最小值,本申请对所述第五阈值和所述第六阈值并不做限定,具体视情况而定。
继续如图5所示,基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值还包括:
S24:基于各所述音频信号的非杂音识别比例,得到各所述音频信号的第三动态抑制数值,所述音频信号的非杂音识别比例越大,所述音频信号的第三动态抑制数值越小;
基于各所述音频信号的第一动态抑制数值和第二动态抑制数值,得到各所述音频信号的动态抑制数值包括:
基于各所述音频信号的第一动态抑制数值、第二动态抑制数值和第三动态抑制数值,得到各所述音频信号的动态抑制数值。
具体的,在本申请的一个实施例中,各所述音频信号的动态抑制数值为:
ratio(s)=a·ratio(f(x))+b·ratio(k)-c·ratio(f(z)) (6)
其中,a、b和c分别为各所述音频信号的杂音识别比例ratio(f(x))、幅值比例ratio(k)和非杂音识别比例ratio(f(z))的权重系数。
由公式(6)可以看出,对于某一杂音信号,在该杂音信号的幅值比例ratio(k)和非杂音识别比例ratio(f(z))不变时,该杂音信号的杂音识别比例ratio(f(x))越大,则该杂音信号的动态抑制数值越大,对该杂音信号的抑制越多;在该杂音信号的杂音识别比例ratio(f(x))和非杂音识别比例ratio(f(z))不变时,该杂音信号的幅值比例ratio(k)越大,则该杂音信号的动态抑制数值越大,对该杂音信号的抑制越多;在该杂音信号的杂音识别比例ratio(f(x))和幅值比例ratio(k)不变时,该杂音信号的非杂音识别比例ratio(f(z))越大,则该杂音信号的动态抑制数值越小,对该杂音信号的抑制越少。
具体的,图6给出了利用本申请实施例所提供的杂音抑制方法对某一第一音频信号进行动态抑制后输出的第二音频信号与该第一音频信号的幅值对比展示图,从图6可以看出,本申请实施例所提供的杂音抑制方法对该第一音频信号进行了有效地动态抑制。
由此可见,本申请实施例所提供的杂音抑制方法,根据各所述音频信号的杂音识别比例、非杂音识别比例和幅值比例,对各所述音频信号进行动态抑制,即根据各所述音频信号被识别杂音信号的概率、被识别为非杂音信号的概率以及幅值大小对各所述音频信号进行动态抑制,从而在对杂音信号进行合理有效地抑制时,既防止对非杂音信号进行抑制,又防止对小信号音频信号抑制过多,保证各所述音频信号的音质不受损失,使得各所述音频信号在听感上过渡更加柔和,进一步提高声音播放质量,满足用户对声音音质和听感的需求。
需要说明的是,上述各实施例均是在所述第一音频信号中的杂音信号已被识别出的基础上进行的,即对被识别出的杂音信号进行的动态抑制,在上述任一实施例的基础上,在本申请的一个实施例中,如图7所示,该方法还包括对所述第一音频信号中的杂音信号进行识别的过程,具体为:
S01:获取一包含多段音频信号的待识别音频信号;
S02:提取该待识别音频信号中各音频信号的第一特征信息,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征;
可选的,在本申请的一个实施例中,所述音频信号的第一特征信息包括所述音频信号的短时能量、梅尔倒谱系数、一阶差分梅尔倒谱系数、响度和声门激励脉冲中的至少一个,但本申请对此并不做限定,在本申请的其他实施例中,所述音频信号的第一特征信息还可以包括所述音频信号的时域和/或频域中的其他特征,具体视情况而定。
S03:基于该待识别音频信号中各音频信号的第一特征信息,利用杂音识别模型得到各所述音频信号的第一识别结果,所述第一识别结果表征所述音频信号是否为杂音信号。
具体的,在本申请的一个实施例中,基于该待识别音频信号中各音频信号的第一特征信息,利用杂音识别模型得到各所述音频信号的第一识别结果包括:
S031:基于该待识别音频信号中各音频信号的第一特征信息,利用杂音识别模型计算得到各所述音频信号的第一预测函数值,所述第一预测函数值表征所述音频信号被识别为杂音信号的概率。
在上述实施例的基础上,在本申请的一个实施例中,S031和S11分别单独进行,在本申请的另一个实施例中,S031和S11合并为一步,即采用S031或S11中的任意一步得到各所述音频信号的第一预测函数值。但本申请对S031和S11单独进行,还是合并成一步进行并不做限定,具体视情况而定。
需要说明的是,所述杂音识别模型以包括多段杂音信号和多段非杂音信号的第一样本音频信号作为训练样本,以所述第一样本音频信号中各音频信号是否为杂音信号的标注结果作为样本标签训练得到,由于该训练过程已在S11步骤中进行了详细地介绍,此处不再赘述。
还需要说明的是,在上述对所述杂音识别模型进行训练的过程中,还包括对所述音频信号的第一特征信息中各特征的选择,具体的,提取所述第一样本音频信号中各音频信号在时域和频域中的各个特征;将所述第一样本音频信号中各音频信号在时域和频域中的各个特征输入所述杂音识别模型中,对所述杂音识别模型进行训练,以挑选出各所述音频信号在时域和/或频域中共同的有效特征,使得所述杂音识别模型基于所述第一样本音频信号中各音频信号在时域和/或频域中的有效特征,确定各所述音频信号是否为杂音信号的第一识别结果与该音频信号的标签一致的概率大于预设值;各所述音频信号在时域和/或频域中的有效特征组成各所述音频信号的第一特征信息。可选的,在本申请的一个实施例中,所述预设值为98%,但本申请对所述预设值并不做限定,具体视情况而定。
S032:基于各所述音频信号的第一预测函数值,得到各所述音频信号的第一识别结果。
具体的,在本申请的一个实施例中,基于各所述音频信号的第一预测函数值,得到各所述音频信号的第一识别结果包括:
如果所述音频信号的第一预测函数值大于第一预设值,则标记该音频信号为第一标记,如果所述音频信号的第一预测函数值小于第一预设值,则标记该音频信号为第二标记;
其中,所述第一标记表示该音频信号为杂音信号,所述第二标记表示该音频信号为非杂音信号,从而利用所述第一标记和所述第二标记直观地表示所述音频信号是否为杂音信号。
需要说明的是,在S11的基础上,所述第一预设值为0,如果所述音频信号的第一预测函数值大于0,则该音频信号为杂音信号,如果所述音频信号的第一预测函数值小于0,则该音频信号为非杂音信号。
在上述实施例的基础上,在本申请的一个实施例中,对各所述音频信号的第一预测函数值进行符号化处理,以快速实现对各所述音频信号是否为杂音信号的标记,其中,符号化公式如下:
sign(f(x))=sign(w
其中,sign为数学符号函数。
从公式(7)可以看出,当所述音频信号的第一预测函数值大于第一预设值时,该音频信号的第一预测函数值对应的sign(f(x))(如sign(f(x))=1)为第一标记,当所述音频信号的第一预测函数值小于第一预设值时,该第一预测函数值对应的sign(f(x))(如sign(f(x))=-1)为第二标记。
在上述实施例的基础上,在本申请的一个实施例中,所述第一预设值为0,所述第一标记为0,所述第二标记为1,即如果所述音频信号的第一预测函数值大于0,将该音频信号标记为0,表示该音频信号为杂音信号,如果所述音频信号的第一预测函数值小于0,将该音频信号标记为1,表示该音频信号为非杂音信号,具体的,如图8所示,图8为利用所述杂音识别模型对一待识别音频信号中各音频信号是否为杂音信号进行识别得到的第一识别结果展示图。
需要说明的是,本申请对所述第一标记和所述第二标记的具体值并不做限定,具体视情况而定。
S04:如果该待识别音频信号中至少一个音频信号被识别为杂音信号,则该待识别音频信号为所述第一音频信号。
需要说明的是,如果该待识别音频信号中的任一音频信号均没有被识别为杂音信号,即该待识别音频信号中不包含杂音信号,则无需对该待识别音频信号进行杂音抑制。
为进一步提高对杂音信号的识别精度,在上述实施例的基础上,在本申请的一个实施例中,如图9所示,该方法还包括:
S05:提取该待识别音频信号中各音频信号的第二特征信息,各所述音频信号的第二特征信息为各所述音频信号的时域和/或频域中的至少一个特征。
可选的,在本申请的一个实施例中,所述音频信号的第二特征信息包括所述音频信号的短时能量、梅尔倒谱系数、一阶差分梅尔倒谱系数、响度和声门激励脉冲中的至少一个,但本申请对此并不做限定,在本申请的其他实施例中,所述音频信号的第一特征信息还可以包括所述音频信号的时域和/或频域中的其他特征,具体视情况而定。
在上述实施例的基础上,可选的,在本申请的一个实施例中,所述音频信号的第二特征信息与其第一特征信息完全相同;在本申请的另一个实施例中,所述音频信号的第二特征信息与其第一特征信息完全不同;在本申请的又一个实施例中,所述音频信号的第二特征信息与其第一特征信息部分相同,部分不同,即所述音频信号的第二特征信息中包括的特征与所述音频信号的第一特征信息中包括的特征部分相同,部分不同。
S06:基于该待识别音频信号中各音频信号的第二特征信息,利用非杂音识别模型得到各所述音频信号的第二识别结果,所述第二识别结果表征所述音频信号是否为非杂音信号。
具体的,在本申请的一个实施例中,基于该待识别音频信号中各音频信号的第二特征信息,利用非杂音识别模型得到各所述音频信号的第二识别结果包括:
S061:基于该待识别音频信号中各音频信号的第二特征信息,利用非杂音识别模型计算得到各所述音频信号的第二预测函数值,所述第二预测函数值表征所述音频信号被识别为杂音信号的概率。
在上述实施例的基础上,在本申请的一个实施例中,S061和S151分别单独进行,在本申请的另一个实施例中,S061和S151合并为一步,即采用S061或S151中的任意一步得到各所述音频信号的第二预测函数值。但本申请对S061和S151单独进行,还是合并成一步进行并不做限定,具体视情况而定。
需要说明的是,所述非杂音识别模型以包括多段非杂音信号和多段杂音信号的第二样本音频信号作为训练样本,以所述第二样本音频信号中各音频信号是否为非杂音信号的标注结果作为样本标签训练得到,由于该训练过程与所述杂音识别模型的训练过程类似,此处不再赘述。
还需要说明的是,在上述对所述非杂音识别模型进行训练的过程中,还包括对所述音频信号的第二特征信息中各特征的选择,由于该选择过程与所述音频信号的第一特征信息中各特征的选择过程类似,此处不再赘述。
S062:基于各所述音频信号的第二预测函数值,得到各所述音频信号的第二识别结果。
具体的,在本申请的一个实施例中,基于各所述音频信号的第二预测函数值,得到各所述音频信号的第二识别结果包括:
如果所述音频信号的第二预测函数值大于第二预设值,则标记该音频信号为第三标记,如果所述音频信号的第一预测函数值小于第二预设值,则标记该音频信号为第四标记;
其中,所述第三标记表示该音频信号为非杂音信号,所述第四标记表示该音频信号为杂音信号,从而利用所述第三标记和所述第四标记直观地表示所述音频信号是否为非杂音信号。
需要说明的是,在S151的基础上,所述第二预设值为0,如果所述音频信号的第二预测函数值大于0,则该音频信号为非杂音信号,如果所述音频信号的第二预测函数值小于0,则该音频信号为杂音信号。
还需要说明的是,也可以利用数学符号函数sign对各所述音频信号的第二预测函数值进行符号化处理,以快速实现对各所述音频信号是否为非杂音信号的标记,该过程与对各所述音频信号的第一预测函数值进行符号化处理的过程类似,此处不再赘述。
在上述实施例的基础上,在本申请的一个实施例中,所述第二预设值为0,所述第三标记为1,所述第四标记为0,即如果所述音频信号的第二预测函数值大于0,将该音频信号标记为1,表示该音频信号为非杂音信号,如果所述音频信号的第一预测函数值小于0,将该音频信号标记为0,表示该音频信号为杂音信号,具体的,如图10所示,图10为利用所述非杂音识别模型对一待识别音频信号中各音频信号是否为非杂音信号进行识别得到的第二识别结果展示图。
S07:如果所述第一识别结果和所述第二识别结果均表征所述音频信号为杂音信号,则确定该音频信号为杂音信号;
如果所述第一识别结果和所述第二识别结果均表征所述音频信号为非杂音信号,则确定该音频信号为非杂音信号;
如果所述第一识别结果表征所述音频信号为杂音信号,且所述第二识别结果表征所述音频信号为非杂音信号,或所述第一识别结果表征所述音频信号为非杂音信号,且所述第二识别结果表征所述音频信号为杂音信号,则该方法还包括:
S08:基于该待识别音频信号中各音频信号的第一特征信息,得到各所述音频信号的预设特征值;
S09:基于各所述音频信号的预设特征值与预设门限值,得到各所述音频信号的第三识别结果,所述第三识别结果表征所述音频信号是否为杂音信号。
可选的,在本申请的一个实施例中,所述预设特征值为响度值,所述预设门限值为响度门限值,基于各所述音频信号的预设特征值与预设门限值,得到各所述音频信号的第三识别结果,所述第三识别结果表征所述音频信号是否为杂音信号包括:
如果所述音频信号的响度值小于响度门限值,则该音频信号为杂音信号,否则为非杂音信号。
具体的,在待识别音频信号中,最先出现的响度值小于响度门限值的音频信号为杂音信号的端点,随后出现的响度值大于响度门限值的音频信号为杂音信号的结束点,介于该端点和该结束点之间的音频信号均为杂音信号,其余音频信号为非杂音信号。如图11所示,图11给出了一待识别音频信号中各音频信号的响度特征展示图,其中,响度门限值M如图11虚线所示,低于该虚线的音频信号为杂音信号,高于该虚线的音频信号为非杂音信号。
可选的,在本申请的另一个实施例中,所述预设特征值为声门激励脉冲值,所述预设门限值为声门激励脉冲门限值,基于各所述音频信号的预设特征值与预设门限值,得到各所述音频信号的第三识别结果,所述第三识别结果表征所述音频信号是否为杂音信号包括:
如果所述音频信号的声门激励脉冲值小于声门激励脉冲门限值,则该音频信号为杂音信号,否则为非杂音信号。
具体的,在待识别音频信号中,最先出现的声门激励脉冲值小于声门激励脉冲门限值的音频信号为杂音信号的端点,随后出现的声门激励脉冲值大于声门激励脉冲门限值的音频信号为杂音信号的结束点,介于该端点和该结束点之间的音频信号均为杂音信号,其余音频信号为非杂音信号。如图12所示,图12给出了一待识别音频信号中各音频信号的声门激励脉冲频谱展示图,其中,声门激励脉冲值门限值N如图12虚线所示,低于该虚线的音频信号为杂音信号,高于该虚线的音频信号为非杂音信号。
需要说明的是,由于所述音频信号的预设特征值不同,对应的预设门限值也不同,因此,本申请对预设特征值大于预设门限值的音频信号为杂音信号,还是预设特征值小于预设门限值的音频信号为杂音信号并不做限定,具体可根据所述音频信号的预设特征的应用特性来确定。
还需要说明的是,本申请对预设门限值的具体数值并不做限定,具体可根据所述音频信号的预设特征的应用特性来确定。
S10:如果所述第三识别结果表征所述音频信号为杂音信号,则确定该音频信号为杂音信号,否则为非杂音信号。
此外,本申请实施例还提供了一种信号处理装置,该装置包括:处理器和扬声器,其中,
所述处理器用于对输入的第一音频信号执行上述任一实施例所提供的杂音抑制方法的各个步骤,并将输出的第二音频信号传输给所述扬声器。
由于所述杂音抑制方法的各个步骤已在上述各实施例中进行了详细地阐述,此处不再赘述。
综上,本申请实施例所提供的杂音抑制方法及信号处理装置,包括:基于一包含多段音频信号的第一音频信号中各音频信号的第一特征信息,得到各所述音频信号的杂音识别比例,所述第一音频信号中至少一个音频信号为杂音信号,所述杂音识别比例表征所述音频信号被识别为杂音信号的概率,各所述音频信号的第一特征信息为各所述音频信号的时域和/或频域中的至少一个特征;基于各所述音频信号的杂音识别比例,得到各所述音频信号的动态抑制数值;基于各所述音频信号的动态抑制数值,对各所述音频信号进行动态抑制,得到第二音频信号后输出,以使得输出后的所述第二音频信号中不包括杂音信号,从而实现对所述第一音频信号中杂音信号的有效抑制,提高声音播放质量,满足用户对声音音质和听感的需求。
进一步地,该方法还根据各所述音频信号的幅值比例和非杂音识别比例,对各所述音频信号进行动态抑制,从而在对杂音信号进行合理有效地抑制时,既防止对非杂音信号进行抑制,又防止对小信号音频信号抑制过多,保证各所述音频信号的音质不受损失,使得各所述音频信号在听感上柔和过渡,没有突然的忽大忽小。
本说明书中各个部分采用并列和递进相结合的方式描述,每个部分重点说明的都是与其他部分的不同之处,各个部分之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,本说明书中各实施例中记载的特征可以相互替换或组合,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种声音采集设备及其信号处理方法、装置、设备
- 一种触控装置、移动终端及信号处理方法
- 一种信号处理方法、装置、设备及计算机可读存储介质
- 一种抑制扬声器杂音的方法和装置
- 一种抑制扬声器杂音的方法和装置