一种用于大规模超图的聚类方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明提出了一种在具有百万甚至千万节点的大规模超图上进行聚类的算法,具体涉及一种名为HyperLocal的半监督超图聚类算法,并在该方法上进行优化和衍生,而得到的新方法。
背景技术
在机器学习问题中,我们通常假设我们感兴趣的对象之间存在成对关系。具有成对关系的对象集可以自然地表示为一个图,其中顶点表示对象,具有某种关系的任意两个顶点通过一条边连接在一起。图可以是无向的或有向的。这取决于对象之间的成对关系是否对称。
然而,在普通图中,一条边只能连接两个点,因此在许多实际问题中,将一组复杂的关系对象表示为无向图或有向图是不完整的。由此,将一组顶点与一条超边相连而成所组成的超图,是普通图的推广。与两个节点通过一条边连接的普通图不同,每个超边可以和任意数量的节点相连接。超图中每条边的度可能比普通图中边的度要高很多,因为在普通图当中每条边的度只能为2.因此,超图在建模实际数据的相关性当中有着显著的优势,而实际数据的相关性可能比成对关系复杂得多。而超图正好能够反应数据之间的高阶关联。
在一些特定情况下,使用超图来进行聚类工作要比使用普通图的方法更加有效果,这是因为在某些实际情况下,超图中所能保留数据之间的高阶信息,这使得在进行聚类分类任务时,能够通过这些高阶信息,对数据进行更加精确有效的分类。然而,在针对大规模的数据集时,许多超图聚类方法在实际运行起来往往会遇到困难。因为在保存和使用大规模的超图数据时,传统的方法往往会占用大量的内存,并且消耗大量的时间。部分超图的聚类算法在针对小规模数据集是能够呈现很好的效果,但是一旦上升到大规模的数据及之后,其算法复杂度可能会非常高,很难得到成功运行。因此,一些适用于大规模超图的聚类算法应运而生。
发明内容
针对现有技术中存在的不足,本发明提供了一种用于大规模超图的聚类方法。
本发明构建了一个基于流的局部超图聚类框架,该框架基于最小化局部比率切割目标。由于是作用在大规模超图上的,我们的方法采用局部切割思想,不在全局的超图上进行处理,通过输入一组带聚类标签的节点,将这些输入节点向周围进行扩散,筛选出部分与我们聚类目标相关性较高的节点,形成一个由这些相关节点组成的局部超图,再将该局部超图在保留高阶信息的同时通过特定方法转化为普通图的形式。然后将转化之后的普通图进行s-t切割(即将包含源节点s和汇聚节点t的超图分割为两个子集,并且s、t节点分别位于两个子集中),通过最小化定义的损失函数来得到与输入集高度相关并且连接良好的节点集作为输出。其中“连接良好”通过比率切割样式目标形式化,该目标可以包含广泛的超图切割函数,包括全有或全无处罚或集团扩张处罚。
一种用于大规模超图的聚类方法,包括步骤如下:
步骤一:首先输入大规模超图中现有的带标签的节点,然后将这些节点看成一个节点集,称为种子集Rs。
步骤二:搜寻整个全局超图中所有与该种子集有连接的节点,称其为单跳节点,也就是已知种子集的邻居节点N(Rs)。
步骤三:对所获得的所有单跳节点进行筛选得到参考集R;
步骤四:将参考集R和其邻居节点N(R)视作局部超图,并将该局部超图转化成带源节点s和汇聚节点t的局部有向图;
步骤五:在加入s、t节点的有向图上解决最大流最小割问题,从而得到一个切割后的子集S即节点集S,定义一个优化聚类目标的损失函数HLC;
步骤六:比较HLC
步骤三具体方法如下;
(1)计算所有Rs的单跳节点与种子集连接的超边个数d1,以及所有单跳节点与种子集以外的所有点的超边个数d2;
(2)得到单跳节点中每个点的d1/d2之比,再将所有单跳节点根据这个比值进行排序;
(3)选取比值最大的节点v,并将其并入种子集Rs中,然后计算加入之后整个节点集的电导:
(4)若加入的节点使原来的节点集的电导值下降了,即cond(R
步骤四转化方法如下:
(1)将每条超边转换为由两个辅助节点连接的有向图。
(2)之后在该超边中的所有节点都生成一条指向其中一个辅助节点的有向边,其权重为1。
(3)再在由另一个辅助节点上生成指向该超边中每个节点的有向边,其权重为1。
(4)在两个辅助节点之间生成一条从大写字母指向小写字母的有向边,其权重为1。
(5)最后对于所有m∈R的节点m,生成一条由源节点s指向m权重为d(m)γ的有向边。对于所有
步骤五具体方法如下:
在加入s、t节点的有向图上解决最大流最小割问题,从而得到一个切割后的子集S即节点集S,定义一个优化聚类目标的损失函数HLC,公式(2)所示。
其中cut(S)为将节点集S切割出来的切割损失,其表达式为:
其中w为每条超边的权重,e便是被切割的超边。节点集S的体积表达式代表该节点集中所有点的度之和:vol(S)=∑
本发明有益效果如下:
本发明方法在几秒钟内从具有数百万个节点和超边以及较大平均超边大小的超图中找到具有数千个节点的簇。本发明方法也比基于细化种子集邻域的启发式方法或在派系扩展上使用现有的图方法更精确。本发明利用广义超图s-t切割问题的最新结果,以最小化具有一般超图边分裂函数的局部比率切割目标。
附图说明
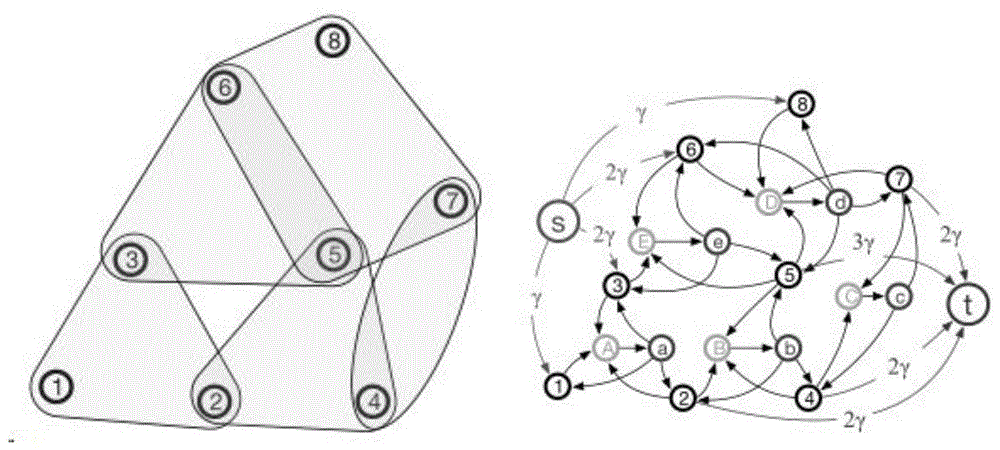
图1为将超图转化为图的示意图。
具体实施方式
以下结合附图与实施例对本发明技术方案进行进一步描述。
一种用于大规模超图的聚类方法,具体实现步骤如下所示:
步骤一:首先输入大规模超图中现有的带标签的节点,这些节点的标签信息都是已知的,然后将这些节点看成一个节点集,称为种子集Rs。
步骤二:搜寻整个全局超图中所有与该种子集有连接的节点,称其为单跳节点,也就是已知种子集的邻居节点N(Rs)。由于是大规模的超图,我们获得的单跳节点数量会比较多,因此需要对单跳节点进行筛选。
步骤三:对所获得的所有单跳节点进行筛选得到参考集R;
(1)计算所有Rs的单跳节点与种子集连接的超边个数d1,以及所有单跳节点与种子集以外的所有点的超边个数d2;
(2)得到单跳节点中每个点的d1/d2之比,再将所有单跳节点根据这个比值进行排序;
(3)选取比值最大的节点v,并将其并入种子集Rs中,然后计算加入之后整个节点集的电导:
(4)若加入的节点使原来的节点集的电导值下降了,即cond(R
步骤四:将参考集R和其邻居节点N(R)视作局部超图,并将该局部超图转化成带源节点s和汇聚节点t的局部有向图。转化方法如图1所示。转化方法如下:
(1)将每条超边转换为由两个辅助节点(例如图1中A、a,B、b等字母表示的节点)连接的有向图。
(2)之后在该超边中的所有节点都生成一条指向由大写字母表示的辅助节点的有向边,其权重为1。
(3)再在由小写字母表示的辅助节点上生成指向该超边中每个节点的有向边,其权重为1。
(4)最后在两个辅助节点之间生成一条从大写字母指向小写字母的有向边,其权重为1。
(5)最后对于所有m∈R的节点m,生成一条由源节点s指向m权重为d(m)γ的有向边。对于所有
步骤五:在加入s、t节点的有向图上解决最大流最小割问题,从而得到一个切割后的子集S,定义一个优化聚类目标的损失函数HLC(Hypergraph Local Conductance),公式(2)所示。
其中cut(S)为将S节点集切割出来的切割损失,其表达式为:
其中w为每条超边的权重,e便是被切割的超边。节点集S的体积表达式代表该节点集中所有点的度之和:vol(S)=∑
步骤六:比较HLC
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
本发明未详细说明部分属于本领域技术人员公知技术。
- 一种融合低秩核学习和自适应超图的图像聚类方法
- 一种基于半监督超图聚类的个体出行模式分析方法