提高kubernetes的节点资源利用率平衡负载的方法及系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及资源分配技术领域,具体地,涉及提高kubernetes的节点资源利用率平衡负载的方法及系统。
背景技术
在当前的kubernetes集群中,官方的调度方案是寻找当前时间点下最匹配的节点来部署pod,但pod一旦调度绑定到节点上,便不会重新调。即使集群在一段时间后节点出现负载不均衡,亲和性不匹配等问题。
本发明通过对可重建pod的驱逐来实现pod的再调度,解决了kubernetes集群中pod一旦被绑定,节点不会触发重新调度,随着集群的动态变化,一段时间后集群节点可能出现负载不均衡,亲和性不匹配等问题。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种提高kubernetes的节点资源利用率平衡负载的方法及系统。
根据本发明提供的一种提高kubernetes的节点资源利用率平衡负载的方法,包括:
步骤S1:通过配置创建连接到集群的client获取集群支持的kube-apiserver版本,判断集群是否支持驱逐,如果不支持驱逐,则直接退出;
步骤S2:经过校验的集群client,创建sharedInformerFactory,注册nodes,pods,namespaces资源的informer到sharedInformerFactory中,获取集群的的相关信息;
步骤S3:使用pod选择器组件筛选出进行动态分布调整的pods;
步骤S4:基于筛选出的能够动态分布调整的pods,根据获取的集群相关信息,获取pod-node的映射关系;
步骤S5:根据获取的pod-node的映射关系,根据配置文件依次执行策略,从而得到驱逐重建结果;
步骤S6:重建pod,集群调度器kube-scheduler将重建的pod重新部署到预设节点上;按照配置参数中的interval间隔进行循环监测,重复触发步骤S3至步骤S6,对集群中的pod分布进行动态调整,从而均衡集群负载,调节均衡性;
所述集群的相关信息包括集群各个节点信息以及每个节点上的pods信息。
优选地,所述步骤S3采用:
步骤S3.1:获取配置中的namespace参数,并判断namespace参数是否为空;当namespace参数为空时,则从sharedInformerFactory的缓存中获取namespace参数下除kubernetes系统命名空间以外的所有命名空间中的pod;当namespace参数不为空时,则从sharedInformerFactory的缓存中获取namespace参数下所有命名空间中的pod;
步骤S3.2:获取配置中的priorityThreshold参数,并判断priorityThreshold参数是否为空;当priorityThreshold参数为空时,则获取的所有命名空间中的pod都进行动态分布调整;当priorityThreshold参数不为空时,则遍历获取的所有命名空间中的pod,剔除优先级大于priorityThreshold的pod,将获取的剔除后剩余的pod进行动态分布调整。
优选地,所述执行策略包括:LoadBalancing策略组件、Affinity策略组件以及ReCreate策略组件中的一种或多种。
优选地,所述执行LoadBalancing策略组件采用:
步骤S5.1:将获取到的pod状态是success和fail的pod剔除,得到剩下的pod;
步骤S5.2:从sharedInformerFactory的缓存中获取剩下的pod所在节点的相关信息;
步骤S5.3:计算各个节点的cpurequest占比NodeCpuRequestPercent和memoryrequest占比NodeMemoryRequestPercent;
步骤S5.4:计算所有节点的cpurequest比例均值AvgNodesCpuRequest和所有节点的memoryrequest比例均值AvgNodesMemoryRequest;
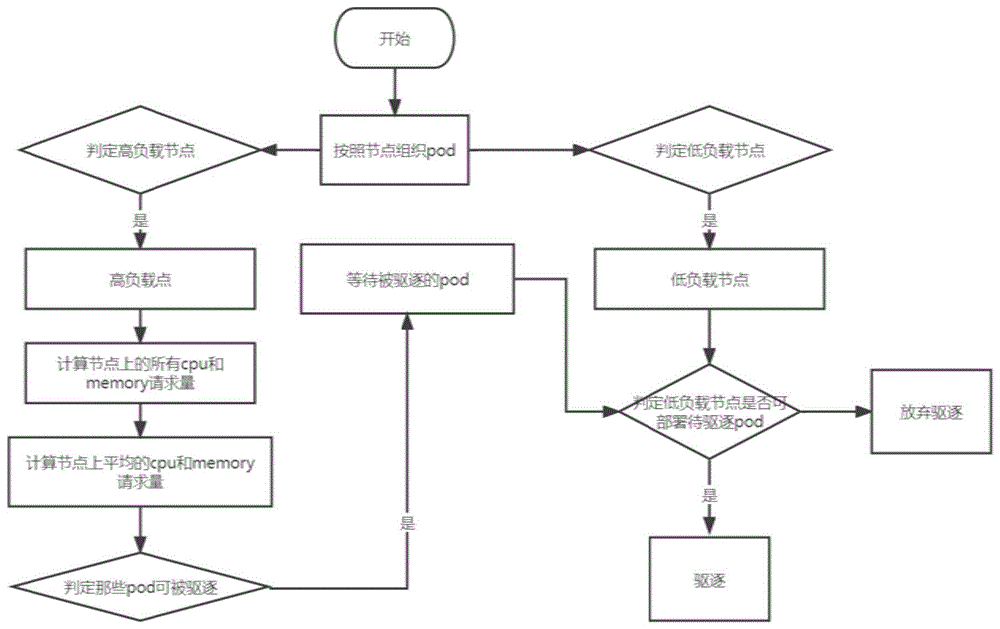
步骤S5.5:使用策略配置参数cputhresholds,memorythresholds判断低负载节点:NodeCpuRequestPercent 步骤S5.6:使用策略配置参数cpuTargetThresholds,memoryTargetThresholds判断高负载节点:NodeCpuRequestPercent>AvgNodesCpuRequest+cpuTargetThresholds或者NodeMemoryRequestPercent>AvgNodesMemoryRequest+memoryTargetThresholds; 步骤S5.7:计算节点中所有高负载节点pod的cpurequest均值AvgPodCpu和memoryrequest均值AvgPodMemory; 步骤S5.8:根据所有高负载节点pod的cpurequest均值和memoryrequest均值判断对应节点的各个pod是否待驱逐,待驱逐pod的cpurequest>AvgPodCpu和/或pod的memoryrequest>AvgPodMemory; 步骤S5.9:使用node选择器组件筛选低负载节点,基于pod亲和性、node亲和性以及污点判断是否满足将pod部署在低负载节点上,且不会变成高负载节点;当找到部署节点部署待驱逐pod,则将当前pod驱逐,否则不驱逐。 优选地,所述Affinity策略组件采用:分别判断获取的所有命名空间中的pod是否满足pod亲和性、node亲和性以及污点,当pod不满足pod亲和性和/或node亲和性,则使用node选择器组件在集群中筛选满足pod亲和性和node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod时,则将当前pod驱逐;否则不驱逐。 优选地,所述ReCreate策略组件采用:判断获取的所有命名空间中的pod的存在时间是否超过策略配置中的maxPodLifeTimeSeconds,有超时的pod则保留,没有超过的pod则剔除;对于保留的pod,使用node选择器组件在集群中筛选满足pod亲和性、node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod,则当前pod驱逐,否则不驱逐。 根据本发明提供的一种提高kubernetes的节点资源利用率平衡负载的系统,包括: 模块M1:通过配置创建连接到集群的client获取集群支持的kube-apiserver版本,判断集群是否支持驱逐,如果不支持驱逐,则直接退出; 模块M2:经过校验的集群client,创建sharedInformerFactory,注册nodes,pods,namespaces资源的informer到sharedInformerFactory中,获取集群的的相关信息; 模块M3:使用pod选择器组件筛选出进行动态分布调整的pods; 模块M4:基于筛选出的能够动态分布调整的pods,根据获取的集群相关信息,获取pod-node的映射关系; 模块M5:根据获取的pod-node的映射关系,根据配置文件依次执行策略,从而得到驱逐重建结果; 模块M6:重建pod,集群调度器kube-scheduler将重建的pod重新部署到预设节点上;按照配置参数中的interval间隔进行循环监测,重复触发模块M3至模块M6,对集群中的pod分布进行动态调整,从而均衡集群负载,调节均衡性; 所述集群的相关信息包括集群各个节点信息以及每个节点上的pods信息。 优选地,所述模块M3采用: 模块M3.1:获取配置中的namespace参数,并判断namespace参数是否为空;当namespace参数为空时,则从sharedInformerFactory的缓存中获取namespace参数下除kubernetes系统命名空间以外的所有命名空间中的pod;当namespace参数不为空时,则从sharedInformerFactory的缓存中获取namespace参数下所有命名空间中的pod; 模块M3.2:获取配置中的priorityThreshold参数,并判断priorityThreshold参数是否为空;当priorityThreshold参数为空时,则获取的所有命名空间中的pod都进行动态分布调整;当priorityThreshold参数不为空时,则遍历获取的所有命名空间中的pod,剔除优先级大于priorityThreshold的pod,将获取的剔除后剩余的pod进行动态分布调整。 优选地,所述执行策略包括:LoadBalancing策略组件、Affinity策略组件以及ReCreate策略组件中的一种或多种。 优选地,所述执行LoadBalancing策略组件采用: 模块M5.1:将获取到的pod状态是success和fail的pod剔除,得到剩下的pod; 模块M5.2:从sharedInformerFactory的缓存中获取剩下的pod所在节点的相关信息; 模块M5.3:计算各个节点的cpurequest占比NodeCpuRequestPercent和memoryrequest占比NodeMemoryRequestPercent; 模块M5.4:计算所有节点的cpurequest比例均值AvgNodesCpuRequest和所有节点的memoryrequest比例均值AvgNodesMemoryRequest; 模块M5.5:使用策略配置参数cputhresholds,memorythresholds判断低负载节点:NodeCpuRequestPercent 模块M5.6:使用策略配置参数cpuTargetThresholds,memoryTargetThresholds判断高负载节点:NodeCpuRequestPercent>AvgNodesCpuRequest+cpuTargetThresholds或者NodeMemoryRequestPercent>AvgNodesMemoryRequest+memoryTargetThresholds; 模块M5.7:计算节点中所有高负载节点pod的cpurequest均值AvgPodCpu和memoryrequest均值AvgPodMemory; 模块M5.8:根据所有高负载节点pod的cpurequest均值和memoryrequest均值判断对应节点的各个pod是否待驱逐,待驱逐pod的cpurequest>AvgPodCpu和/或pod的memoryrequest>AvgPodMemory; 模块M5.9:使用node选择器组件筛选低负载节点,基于pod亲和性、node亲和性以及污点判断是否满足将pod部署在低负载节点上,且不会变成高负载节点;当找到部署节点部署待驱逐pod,则将当前pod驱逐,否则不驱逐; 所述Affinity策略组件采用:分别判断获取的所有命名空间中的pod是否满足pod亲和性、node亲和性以及污点,当pod不满足pod亲和性和/或node亲和性,则使用node选择器组件在集群中筛选满足pod亲和性和node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod时,则将当前pod驱逐;否则不驱逐; 所述ReCreate策略组件采用:判断获取的所有命名空间中的pod的存在时间是否超过策略配置中的maxPodLifeTimeSeconds,有超时的pod则保留,没有超过的pod则剔除;对于保留的pod,使用node选择器组件在集群中筛选满足pod亲和性、node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod,则当前pod驱逐,否则不驱逐。 与现有技术相比,本发明具有如下的有益效果: 1、本发明可以动态调整kubernetes集群中pods的分布; 2、多策略支持,可得到不同pod分布调整结果; 3、LoadBalancing策略下的均值偏离算法判定低负载节点和高负载节点; 4、LoadBalancing策略下高负载节点上,待驱逐pod的判定算法。 5、本发明通过将可重建pod进行驱逐,实现动态调整kubernetes集群中pods的分布,保证在集群中pod的分布长期处于合理状态; 6、本发明通过驱逐高负载节点的高负载pod并在其它节点重建,实现负载均衡的效果; 7、本发明通过驱逐反亲合性的pod并在符合亲和性关系的节点重建,实现保证集群中亲和性的效果。 附图说明 通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显: 图1为提高kubernetes的节点资源利用率平衡负载的方法流程图。 图2为LoadBalancing策略流程图。 图3为工作示例图 具体实施方式 下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。 实施例1 根据本发明提供的一种提高kubernetes的节点资源利用率平衡负载的方法,如图1至3所示,包括: 步骤S1:通过配置创建连接到集群的client获取集群支持的kube-apiserver版本,判断集群是否支持驱逐,如果不支持驱逐,则直接退出; 步骤S2:经过校验的集群client,创建sharedInformerFactory,注册nodes,pods,namespaces资源的informer到sharedInformerFactory中,获取集群的的相关信息,包括集群各个节点信息,每个节点上的pods信息,用于后续的资源计算; 步骤S3:使用pod选择器组件筛选出进行动态分布调整的pods; 所述Pod选择器组件根据命名空间,优先级等配置从集群中筛选出可能进行动态分布调整的pods。 具体地,所述步骤S3采用: 步骤S3.1:获取配置中的namespace参数,并判断namespace参数是否为空;当namespace参数为空时,则从sharedInformerFactory的缓存中获取namespace参数下除kubernetes系统命名空间(kube-system)以外的所有命名空间中的pod;当namespace参数不为空时,则从sharedInformerFactory的缓存中获取namespace参数下所有命名空间中的pod; 步骤S3.2:获取配置中的priorityThreshold参数,并判断priorityThreshold参数是否为空;当priorityThreshold参数为空时,则获取的所有命名空间中的pod都进行动态分布调整;当priorityThreshold参数不为空时,则遍历获取的所有命名空间中的pod,剔除优先级大于priorityThreshold的pod,将获取的剔除后剩余的pod进行动态分布调整。 步骤S4:将获取的pods按照map[nodeName][]podInfo的映射关系进行组织,方便后续的过程对相关node,pod的筛选; 步骤S5:根据获取的pod-node的映射关系,根据配置文件依次执行策略,(不同策略对pod的驱逐判定大不相同,顺序决定了策略的权重,顺序越靠前权重越高),不同策略组合最终得到不同的驱逐重建结果; 具体地,所述执行策略包括:LoadBalancing策略组件、Affinity策略组件以及ReCreate策略组件中的一种或多种; 所述LoadBalancing策略通过策略配置参数和均值偏离算法判定低负载节点和高负载节点。在高负载节点中,使用待驱逐pod的判定算法。再将这些pod驱逐,重建到负载低的节点上面,来实现节点间的负载均衡。 所述Affinity策略组件通过遍历节点上的pod,判断pod间反亲和性,节点和node的反亲和性关系。这种情况一般是pod部署后添加了节点affinity,taints和labels等,使得原来调度的pod与node不匹配导致的。如果发现反亲和性的pod存在,则进行驱逐,重新部署到满足亲和性约束条件的节点上。 所述ReCreate策略通过策略参数maxPodLifeTimeSeconds来筛选运行时间超长的pod进行驱逐,重新创建调度。 具体地,所述执行LoadBalancing策略组件采用: 步骤S5.1:将获取到的pod状态是success和fail的pod剔除,得到剩下的pod; 步骤S5.2:从sharedInformerFactory的缓存中获取剩下的pod所在节点的相关信息; 步骤S5.3:计算各个节点的cpurequest占比NodeCpuRequestPercent和memoryrequest占比NodeMemoryRequestPercent; 节点的cpurequest占比:NodeCpuRequestPercent 节点的memoryrequest占比:NodeMemoryRequestPercent 步骤S5.4:计算所有节点的cpurequest比例均值AvgNodesCpuRequest和所有节点的memoryrequest比例均值AvgNodesMemoryRequest; 所有节点的cpurequest比例均值:AvgNodesCpuRequest 所有节点的memoryrequest比例均值:AvgNodesMemoryRequest 步骤S5.5:使用策略配置参数cputhresholds,memorythresholds判断低负载节点:NodeCpuRequestPercent 步骤S5.6:使用策略配置参数cpuTargetThresholds,memoryTargetThresholds判断高负载节点:NodeCpuRequestPercent>AvgNodesCpuRequest+cpuTargetThresholds或者NodeMemoryRequestPercent>AvgNodesMemoryRequest+memoryTargetThresholds; 步骤S5.7:计算节点中所有高负载节点pod的cpurequest均值AvgPodCpu和memoryrequest均值AvgPodMemory; 节点的cpurequest均值:AvgPodCpu 节点的memoryrequest均值:AvgPodMemory /> 步骤S5.8:根据所有高负载节点pod的cpurequest均值和memoryrequest均值判断对应节点的各个pod是否待驱逐,待驱逐pod的cpurequest>AvgPodCpu和/或pod的memoryrequest>AvgPodMemory; 步骤S5.9:使用node选择器组件筛选低负载节点,基于pod亲和性、node亲和性以及污点判断是否满足将pod部署在低负载节点上,且不会变成高负载节点;当找到部署节点部署待驱逐pod,则将当前pod驱逐,否则不驱逐。 所述node选择器根据上面不同的策略去寻找可以重新部署待驱逐pod的节点。节点选择主要从node亲和性,pod亲和性,污点等方面考量,如果是LoadBalancing策略,所选择的节点必须要是低负载节点。如果没有其它节点可以部署待驱逐的pod,那么该最终pod将不会被驱逐。 具体地,所述Affinity策略组件采用:分别判断获取的所有命名空间中的pod是否满足pod亲和性、node亲和性以及污点,当pod不满足pod亲和性和/或node亲和性,则使用node选择器组件在集群中筛选满足pod亲和性和node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod时,则将当前pod驱逐;否则不驱逐。 具体地,所述ReCreate策略组件采用:判断获取的所有命名空间中的pod的存在时间是否超过策略配置中的maxPodLifeTimeSeconds,有超时的pod则保留,没有超过的pod则剔除;对于保留的pod,使用node选择器组件在集群中筛选满足pod亲和性、node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod,则当前pod驱逐,否则不驱逐。 步骤S6:重建pod,集群调度器kube-scheduler将重建的pod重新部署到预设节点上;按照配置参数中的interval间隔进行循环监测,重复触发步骤S3至步骤S6,对集群中的pod分布进行动态调整,从而均衡集群负载,调节均衡性。 根据本发明提供的一种提高kubernetes的节点资源利用率平衡负载的系统,包括: 模块M1:通过配置创建连接到集群的client获取集群支持的kube-apiserver版本,判断集群是否支持驱逐,如果不支持驱逐,则直接退出; 模块M2:经过校验的集群client,创建sharedInformerFactory,注册nodes,pods,namespaces资源的informer到sharedInformerFactory中,获取集群的的相关信息,包括集群各个节点信息,每个节点上的pods信息,用于后续的资源计算; 模块M3:使用pod选择器组件筛选出进行动态分布调整的pods; 所述Pod选择器组件根据命名空间,优先级等配置从集群中筛选出可能进行动态分布调整的pods。 具体地,所述模块M3采用: 模块M3.1:获取配置中的namespace参数,并判断namespace参数是否为空;当namespace参数为空时,则从sharedInformerFactory的缓存中获取namespace参数下除kubernetes系统命名空间(kube-system)以外的所有命名空间中的pod;当namespace参数不为空时,则从sharedInformerFactory的缓存中获取namespace参数下所有命名空间中的pod; 模块M3.2:获取配置中的priorityThreshold参数,并判断priorityThreshold参数是否为空;当priorityThreshold参数为空时,则获取的所有命名空间中的pod都进行动态分布调整;当priorityThreshold参数不为空时,则遍历获取的所有命名空间中的pod,剔除优先级大于priorityThreshold的pod,将获取的剔除后剩余的pod进行动态分布调整。 模块M4:将获取的pods按照map[nodeName][]podInfo的映射关系进行组织,方便后续的过程对相关node,pod的筛选; 模块M5:根据获取的pod-node的映射关系,根据配置文件依次执行策略,(不同策略对pod的驱逐判定大不相同,顺序决定了策略的权重,顺序越靠前权重越高),不同策略组合最终得到不同的驱逐重建结果; 具体地,所述执行策略包括:LoadBalancing策略组件、Affinity策略组件以及ReCreate策略组件中的一种或多种; 所述LoadBalancing策略通过策略配置参数和均值偏离算法判定低负载节点和高负载节点。在高负载节点中,使用待驱逐pod的判定算法。再将这些pod驱逐,重建到负载低的节点上面,来实现节点间的负载均衡。 所述Affinity策略组件通过遍历节点上的pod,判断pod间反亲和性,节点和node的反亲和性关系。这种情况一般是pod部署后添加了节点affinity,taints和labels等,使得原来调度的pod与node不匹配导致的。如果发现反亲和性的pod存在,则进行驱逐,重新部署到满足亲和性约束条件的节点上。 所述ReCreate策略通过策略参数maxPodLifeTimeSeconds来筛选运行时间超长的pod进行驱逐,重新创建调度。 具体地,所述执行LoadBalancing策略组件采用: 模块M5.1:将获取到的pod状态是success和fail的pod剔除,得到剩下的pod; 模块M5.2:从sharedInformerFactory的缓存中获取剩下的pod所在节点的相关信息; 模块M5.3:计算各个节点的cpurequest占比NodeCpuRequestPercent和memoryrequest占比NodeMemoryRequestPercent; 节点的cpurequest占比:NodeCpuRequestPercent 节点的memoryrequest占比:NodeMemoryRequestPercent 模块M5.4:计算所有节点的cpurequest比例均值AvgNodesCpuRequest和所有节点的memoryrequest比例均值AvgNodesMemoryRequest; 所有节点的cpurequest比例均值:AvgNodesCpuRequest /> 所有节点的memoryrequest比例均值:AvgNodesMemoryRequest 模块M5.5:使用策略配置参数cputhresholds,memorythresholds判断低负载节点:NodeCpuRequestPercent 模块M5.6:使用策略配置参数cpuTargetThresholds,memoryTargetThresholds判断高负载节点:NodeCpuRequestPercent>AvgNodesCpuRequest+cpuTargetThresholds或者NodeMemoryRequestPercent>AvgNodesMemoryRequest+memoryTargetThresholds; 模块M5.7:计算节点中所有高负载节点pod的cpurequest均值AvgPodCpu和memoryrequest均值AvgPodMemory; 节点的cpurequest均值:AvgPodCpu 节点的memoryrequest均值:AvgPodMemory 模块M5.8:根据所有高负载节点pod的cpurequest均值和memoryrequest均值判断对应节点的各个pod是否待驱逐,待驱逐pod的cpurequest>AvgPodCpu和/或pod的memoryrequest>AvgPodMemory; 模块M5.9:使用node选择器组件筛选低负载节点,基于pod亲和性、node亲和性以及污点判断是否满足将pod部署在低负载节点上,且不会变成高负载节点;当找到部署节点部署待驱逐pod,则将当前pod驱逐,否则不驱逐。 所述node选择器根据上面不同的策略去寻找可以重新部署待驱逐pod的节点。节点选择主要从node亲和性,pod亲和性,污点等方面考量,如果是LoadBalancing策略,所选择的节点必须要是低负载节点。如果没有其它节点可以部署待驱逐的pod,那么该最终pod将不会被驱逐。 具体地,所述Affinity策略组件采用:分别判断获取的所有命名空间中的pod是否满足pod亲和性、node亲和性以及污点,当pod不满足pod亲和性和/或node亲和性,则使用node选择器组件在集群中筛选满足pod亲和性和node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod时,则将当前pod驱逐;否则不驱逐。 具体地,所述ReCreate策略组件采用:判断获取的所有命名空间中的pod的存在时间是否超过策略配置中的maxPodLifeTimeSeconds,有超时的pod则保留,没有超过的pod则剔除;对于保留的pod,使用node选择器组件在集群中筛选满足pod亲和性、node亲和性的节点部署当前pod;当找到部署节点部署待驱逐pod,则当前pod驱逐,否则不驱逐。 模块M6:重建pod,集群调度器kube-scheduler将重建的pod重新部署到预设节点上;按照配置参数中的interval间隔进行循环监测,重复触发模块M3至模块M6,对集群中的pod分布进行动态调整,从而均衡集群负载,调节均衡性。 本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。 以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 一种提高可再生能源利用率的资源调度方法及系统
- 用于在负载平衡的无线电通信系统中的改善的资源利用的方法和网络节点
- 用于在负载平衡的无线电通信系统中的改善的资源利用的方法和网络节点