一种基于社会文化传播的智能体形态演化方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于智能优化技术领域,涉及一种基于社会文化传播的智能体形态演化方法。
背景技术
经过亿万年的发展,生物种群演化出了多种多样的形态,可以帮助生物体完成各种任务、学会在复杂的环境中生存。例如,鱼群已经进化出理想的流线型体型,可以最大限度地减少在水中受到的摩擦和形状阻力的综合影响。因此,研究形态学的演化对于在环境中寻找最佳身体结构以实现给定目标具有重要意义。
目前人工智能领域的一个研究热点是强化学习,目标是实现智能体完全自主地活动,使其能够与所处的环境进行交互。智能体可以根据从环境反馈中获得的累计预期奖励学习最佳行为,并通过反复实验不断改进控制器,以获得完成目标的最优策略。然而,目前主流的工作通常侧重通过预先设计好形态的智能体在单个控制任务上高效完成控制器的学习。智能体的形态设计可能没有达到该任务的最佳设计状态,或者有时甚至故意设计成使策略搜索具有挑战性的形态。同时考虑智能体控制器策略的学习和智能体形态的演化是一种自然的方式,因为智能体的形态是学习智能行为的基础。通过设计智能算法使得智能体可以通过调整自身的形态参数,从而更好地完成对其设定的任务。自从1994年思维机器公司的Karl Sims克服了人工设计对特定任务的限制,使用演化策略训练一个基于神经网络的控制器,并在每一代对智能体的结构图进行变异演化智能体形态,形态演化得到了广泛的研究。创建具有良好自适应形态的智能体,在不同的复杂环境中学习控制任务是具有挑战性的,因为主要有以下两个困难:
(1)智能体形态的搜索空间非常大。
(2)对大多数任务来说,为了评估智能体的适应度,需要通过强化学习训练种群中每一个形态的智能体的控制器,所需的计算资源是昂贵的。
因此,目前的方法对于智能体形态搜索空间比较受限,并且评估适应度的困难迫使之前的工作:
(1)避免直接从原始传感器中学习自适应控制器。
(2)学习人工设计的控制器。
(3)预测形态的适应度而不是在真实环境中进行评估。
这些工作需要从头开始独立地求解各个智能体的适应度,忽视了智能体之间存在的相似关系和从其它智能体获取知识的可能性,存在计算成本高、效率低、收敛速度慢等问题。
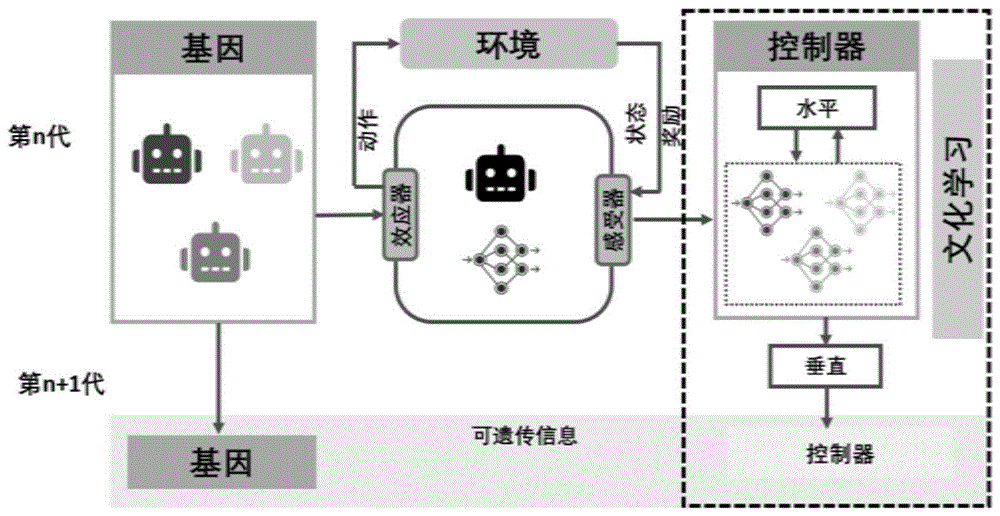
在自然界中有两种学习知识的方法,一种是通过使用试错策略与环境交互(即个体学习),另一种是通过观察其他个体与环境之间的交互(即文化学习)。根据文化学习理论,每个人都可以通过非基因遗传方式从其他人那里学习信息,例如通过模仿、教学或语言。文化学习使信息能够垂直(即从上一代成员)和水平(即在同一代成员之间)传播。根据累积文化进化论,文化特征在连续几代人中进行传播和个人独自学习相比更有助于个人获得知识。因此,社会文化传播对提高学习效率具有重要意义。
发明内容
针对当前算法在智能体形态演化方面的不足,本发明提出了一种基于社会文化传播的智能体形态演化方法,目的在于构建一种高效的智能体演化框架,使其能够更好完成指定任务。
为了达到上述目的,本发明采用的技术方案如下:
一种基于社会文化传播的智能体形态演化方法,具体步骤如下:
步骤1、设定问题模型,确定适应度函数与设计目标;
在优化过程中,每一代g中有K个智能体需要同时优化,记为
其中π
[ξ,θ]
步骤2、学习控制器策略;
(1)初始化控制器时,采用拉马克遗传实现垂直文化传播,利用智能体已有知识节省计算资源;因为第一代智能体没有父代,在第二代智能体之后使用垂直文化传播。垂直文化传播使每个智能体能够继承上一代智能体的知识,下一代的个体根据智能体之间的距离,从当前种群的个体继承控制器参数;
使用欧氏距离来度量智能体之间的距离,其计算方法如下:
其中,g
将上一代个体中的知识迁移到当前个体使得当前个体在初始化时具有更高的适应度,从而使个体比需要从头开始学习的达尔文进化的个体有更高的生存机会;拉马克学习通过将上一代的控制器重新放入种群中竞争繁殖机会,迫使基因型反映控制器改进的结果;
(2)在训练开始时,只更新控制器策略参数,而保持智能体形态设计参数不变;
基于OpenAI ES实现训练强化学习智能体的方法;在OpenAI ES中,控制器策略参数θ通过适应度函数的随机梯度上升进行优化:
其中,∈从高斯分布N(0,I)中采样得到,I为高斯分布的方差;σ为噪声标准差;
扩展OpenAI ES方法,在学习控制器策略中应用水平文化传播,使知识能够在同一代种群中进行迁移;具体如下:
智能体在一代种群的演化过程中可以与其他智能体进行交互,并根据这些交互中观察到或收集到的信息优化自己的行为;根据智能体之间距离的定义,智能体i有一个邻居集合B
为了在智能体训练的早期阶段加快学习速率,并且在训练完成时保证训练收敛,在整个学习过程中动态调整迁移系数来控制智能体从其他智能体学习的权重;在早期阶段,设置较高的迁移系数鼓励当前智能体从其他智能体学习,而在后期,设置较小的迁移系数使算法专注于当前智能体以找到最优控制器;迁移系数的指数衰减公式为:
其中,N
需要防止没有学习到足够知识的智能体将知识转移给学习良好的智能体,具体做法为在智能体学习过程中,只有比当前智能体适应度高的邻居智能体可以迁移知识给当前智能体;因此,通过控制系数来c
控制系数c
综上,智能体i在t+1时刻的参数
其中,α为学习率;n为采样数量;智能体与环境交互获得的奖励表示为适应度F
步骤3、优化形态;
使用遗传算法演化智能体的形态;具体如下:
初始化时,为了编码智能体的形态属性,使用D维向量来表示相应的形态属性;向量中的每个维度表示肢体的一个参数,被线性缩放到范围[0,1]内;这意味着参数为0.5的变量表示智能体肢体的参数和原始设计保持相同,而变量0和1分别表示达到了肢体的参数达到了最低和最高的大小;在演化初始阶段,同时随机生成并初始化K个不同形态的智能体,对它们进行评估选择后进行重组和变异以产生新一代;
在个体的选择阶段,需要从父代个体中选择表现较好的个体产生后代,以确定将在未来几代中生存的候选个体,并用于创建新的智能体;使用两阶段轮盘赌选择高质量的父代个体。在选择候选个体后,采用模拟二进制交叉和高斯变异算子产生一个新的有前途的个体,该个体具有引导优化过程向新的搜索区域前进的潜力;在演化过程中采用精英策略,在种群演化过程中出现的最佳个体被直接复制到下一代;不断重复上述过程,直到最后生成表现最好的个体;
在个体选择时,使用新颖性搜索鼓励探索新奇的形态,具体如下:
首先定义智能体形态的稀疏度,度量方法是到该智能体的k个邻居的平均距离,其中k是通过实验确定的固定参数;如果到给定智能体邻居的平均距离很大,那么它处于稀疏区域;如果平均距离较小,则为密集区域;智能体i的稀疏度ρ(i)由下式给出:
其中j是i相对于距离度量dist的第i个邻居;来自该形态学搜索空间的更稀疏区域的候选解,可以获得更高的稀疏度;
然而,适应度奖励信号对于智能体形态演化仍然非常有用,完全丢弃它们可能会导致智能体无法正常工作;奖励纯粹的形态学稀疏度不能解决智能体的功能性问题,因此,需要对新颖性搜索进行扩展,鼓励功能性;
为了控制形态多样性的同时保证个体功能性,引入了两阶段轮盘赌选择,两阶段轮盘赌选择方法优先选择与其他个体相比环境适应度更高且更多样化的个体,具体如下:
第一个阶段:根据个体的适应度进行选择;目标函数F用来评价智能体的适应度,在计算智能体i的适应度分数F
第二个阶段:从第一阶段比赛的获胜者中,根据稀疏性选择出新颖的个体;个体i被选择的概率S
本发明的有益效果:
本发明在智能体形态演化过程中采取了一个新的高度可并行化的框架,用于同时对多个智能体进行控制器的学习和形态演化,从而允许利用计算的可扩展性。在演化下一代个体时,采用了一种遗传传递策略来传递智能体的形态属性,引入了新颖性搜索,对于形态多样性进行控制,增加个体之间的平均距离,使得种群分布范围更广。因此,进化过程陷入局部最优的概率较低,可以并行探索更多不同的搜索方向。根据智能体之间的相似度进行水平文化传播和垂直文化传播,并且自动调整智能体之间的信息迁移系数,以增加正向知识迁移,提高了智能体学习的效率。
附图说明
图1为本发明的整体框架流程图。
图2为智能体默认形态示意图。
图3为经过优化后的智能体形态示意图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
本发明的方法可用于指导智能体在指定任务中演化形态完成任务,本发明的方法流程如图1所示。
在本发明中,针对强化学习中智能体的形态演化和控制器优化问题提出了一种基于社会文化传播的智能体形态演化方法用于演化智能体的形态和控制策略。根据智能体之间的相似性,利用水平文化传播和垂直文化传播在智能体之间迁移它们学习到的知识,避免了从头重新开始学习。并且提出使用两阶段轮盘赌方法,结合智能体的适应度和新颖性演化下一代种群。最终增加了智能体种群的多样性,提高了智能体的学习效率以及性能。
以下对本发明的实施方式进行详细说明,具体包括以下步骤:
(1)产生初代种群:
(1.1)初始化种群:首先生成初代种群,包含随机生成的不同形态的智能体,被编码为取值范围在[0,1]内的一个D维向量。
(2)主循环过程:
(2.1)收集智能体与环境交互信息:智能体将观察到的环境信息进行编码,输入到神经网络控制器中,产生动作。
(2.2)学习种群中智能体的控制器参数:计算种群中智能体之间的相似度,通过个体与环境交互获得的信息和水平文化传播获取到的其它智能体的信息学习当前智能体控制器策略参数。
(2.2)评估种群中智能体的适应度:完成智能体控制器的学习后,通过在环境中收集智能体控制器获得的累积回报奖励评估智能体的适应度。
(2.3)根据智能体的适应度通过轮盘赌算法选择出第一轮获胜的个体。
(2.4)从第一轮获胜的个体中根据智能体的新颖性通过轮盘赌算法选择个体。
(2.5)产生下一代智能体:通过二进制交叉和高斯变异算子产生种群子代,计算父代中的个体和子代中的个体的相似度,根据智能体之间的相似度进行垂直文化传播。
当不满足循环条件时,即循环达到预先设定次数,可得到在当前任务上表现良好的智能体形态。
本实施例基于MuJoCo模拟器,考虑演化OpenAI Gym中Hopper和Ant机器人智能体形态。其中,Hopper为二维机器人,只可以前后移动,而Ant为三维机器人,它们的默认形态分别如图2(a)和图2(b)所示。基于OpenAI Gym中默认形态参数进行演化,允许其中每个可演化的部分在50%到150%的合理范围内变化。保持构建智能体材料的密度,以及运动关节的参数与原始环境相同,并允许其肢体的长度和半径参数被学习。保持了智能体的框架与原始框架相同,以保证其原始设计意图没有被破坏。演化的目标是通过在连接身体部位的关节上施加扭矩,使智能体尽可能快地向前移动。
通过评估控制策略在环境中的表现,对候选的演化智能体进行评估。奖励函数为算法提供了一个量化智能体在执行任务时表现的数值。这个奖励函数在通过梯度反向传播训练强化学习神经网络模型的损失函数中起着核心作用,智能体在与环境交互的过程中获得高奖励值与成功完成任务直接相关。使用默认的奖励函数,为智能体向前移动,保持健康的奖励和采取过大行动的惩罚的加权总和。
Hopper由四个身体部分组成,分别是上部的躯干、中部的大腿、下部的腿和一只脚。Hopper有八个与智能体肢体的长度和半径相关的参数可以学习,其中长度和半径分别有四个维度,表示四个肢体的长度和半径的缩放因子。Ant是一个由四条腿支撑的三维智能体,每条腿由三个部分组成,由两个铰链关节控制。Ant具有三十六维形态空间,其中有二十四维表示十二个肢体的长度,由其关节连接的二维坐标控制,有十二维表示十二个肢体的半径。
所有智能体通过一个产生动作分布的随机策略选择其动作。观测值由一个2层的全连接网络编码,每个隐藏层有256个单元,使用tanh激活函数。将智能体在环境中的观察值连接并进一步编码为256维的向量,最后将其传递到线性层以生成策略网络的高斯动作策略参数。策略网络输出层的大小取决于驱动关节的数量。最后经过优化的Hopper和Ant机器人形态分别如图3(a)和图3(b)所示,其在完成指定任务时可获得相比默认形态的机器人更高的分数。
- 基于多智能体的信息传播与舆情演化仿真方法
- 基于多智能体的信息传播与舆情演化仿真方法