用于通过核酸甲基化分析检测癌症的方法和系统
文献发布时间:2024-04-18 20:01:30
交叉引用
本申请要求于2021年3月26日提交的美国临时专利申请号63/166,641的权益,所述专利申请的内容通过引用并入本文。
援引并入
本说明书中提及的所有出版物、专利和专利申请均通过引用并入本文,就好像每个单独的出版物、专利或专利申请被明确地并单独地指示通过引用并入一样。就通过引用并入的出版物和专利或专利申请与本说明书中包含的公开内容相矛盾而言,本说明书旨在取代和/或优先于任何这种矛盾的材料。
背景技术
本公开总体上涉及癌症检测和疾病监测。更具体地,该领域涉及癌症相关的DNA甲基化检测和早期癌症的疾病监测。在过去几十年里,癌症筛查和监测可以有助于改善结局,因为癌症可以在有机会扩散之前就被消除,所以早期检测产生更好的结局。
任何筛查工具的主要问题可能是假阳性与假阴性结果(或特异性与敏感性)之间的折中,在前一种情况下导致不必要的调查,而在后一种情况下导致无效。理想的测试可以是具有高阳性预测值(PPV)的,最大限度地减少不必要的调查,但能检测到绝大多数癌症。另一个关键因素是“检测敏感性”。与测试敏感性不同,检测敏感性是关于肿瘤大小的检测下限。遗憾的是,等待肿瘤生长到足够大以释放检测所必需水平的循环肿瘤标志物可能与在治疗最有效的早期治疗肿瘤的目标相矛盾。因此,需要基于循环分析物对早期癌症进行有效的基于血液的筛查。
发明内容
本公开提供了涉及与细胞增殖性病症和癌症检测和疾病进展相关联的基因的甲基化谱分析的方法和系统。还提供了涉及与肺、结肠、肝、卵巢、胰腺、前列腺、直肠和乳腺细胞增殖性病症检测和疾病进展相关联的基因的甲基化谱分析的方法和系统。
一方面,本公开提供了一种为至少两种细胞增殖性病症所特有的甲基化特征小组(methylation signature panel),其包含:选自表1的六个或更多个甲基化基因组区域,其中所述一个或多个区域在患有细胞增殖性病症或细胞增殖性病症亚型的对象的生物样品中的甲基化程度更高,而在未患有细胞增殖性病症的对象的正常组织和正常血细胞中的甲基化程度则较低。
在一些实施方案中,生物样品包括核酸、DNA、RNA或无细胞核酸(cfDNA或cfRNA)。
在一些实施方案中,所述基因组区域是非编码区、编码区或非转录区或调控区。
在一些实施方案中,所述特征小组包含在6个或更多个、或12个或更多个表1中的基因组区域中增加的甲基化。
在一些实施方案中,所述特征小组包含在六个或更多个表1中与一种类型的癌症相关联的甲基化基因组区域中增加的甲基化。
在一些实施方案中,从对象获得的生物样品选自体液、粪便、结肠排出物、尿液、血浆、血清、全血、分离的血细胞、从血液分离的细胞及其组合。
在一些实施方案中,所述细胞增殖性病症选自结直肠细胞增殖、前列腺细胞增殖、肺细胞增殖、乳腺细胞增殖、胰腺细胞增殖、卵巢细胞增殖、子宫细胞增殖、肝细胞增殖、食管细胞增殖、胃细胞增殖或甲状腺细胞增殖。
在一些实施方案中,所述细胞增殖性病症选自结肠腺癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢浆液性囊腺癌、胰腺腺癌、前列腺腺癌和直肠腺癌。
在一些实施方案中,所述细胞增殖性病症选自1期癌症、2期癌症、3期癌症或4期癌症。
在一些实施方案中,所述特征小组包含表1中的三个或更多个甲基化基因组区域、表1中的四个或更多个甲基化基因组区域、表1中的五个或更多个甲基化基因组区域、表1中的六个或更多个甲基化基因组区域、表1中的七个或更多个甲基化基因组区域、表1中的八个或更多个甲基化基因组区域、表1中的九个或更多个甲基化基因组区域、表1中的十个或更多个甲基化基因组区域、表1中的十一个或更多个甲基化基因组区域、表1中的十二个或更多个甲基化基因组区域、或表1中的十三个或更多个甲基化基因组区域。
一方面,本公开提供了一种为至少两种细胞增殖性病症的组织来源所特有的甲基化特征小组,其包含:选自表2至17中的甲基化基因组区域的两个或更多个甲基化基因组区域特征小组,其中所述基因组区域在患有细胞增殖性病症或细胞增殖性病症亚型的对象的生物样品中的甲基化程度更高,而在未患有细胞增殖性病症的对象的正常组织和正常血细胞中的甲基化程度则较低。
在一些实施方案中,生物样品是核酸、DNA、RNA或无细胞核酸(cfDNA或cfRNA)。
在一些实施方案中,所述基因组区域是非编码区、编码区或非转录区或调控区。
在一些实施方案中,所述特征小组包含在6个或更多个、12个或更多个表2至17中的基因组区域中增加的甲基化。
在一些实施方案中,所述特征小组包含在六个或更多个表2至17中与癌症类型和肿瘤组织来源相关联的甲基化基因组区域中增加的甲基化。
在一些实施方案中,从对象获得的生物样品选自体液、粪便、结肠排出物、尿液、血浆、血清、全血、分离的血细胞、从血液分离的细胞及其组合。
在一些实施方案中,所述细胞增殖性病症选自结直肠细胞增殖、前列腺细胞增殖、肺细胞增殖、乳腺细胞增殖、胰腺细胞增殖、卵巢细胞增殖、子宫细胞增殖、肝细胞增殖、食管细胞增殖、胃细胞增殖或甲状腺细胞增殖。在一些实施方案中,所述细胞增殖性病症选自结肠腺癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢浆液性囊腺癌、胰腺腺癌、前列腺腺癌和直肠腺癌。
在一些实施方案中,所述细胞增殖性病症选自1期癌症、2期癌症、3期癌症或4期癌症。
在一些实施方案中,所述特征小组包含表2至17中的三个或更多个甲基化基因组区域、表2至17中的四个或更多个甲基化基因组区域、表2至17中的五个或更多个甲基化基因组区域、表2至17中的六个或更多个甲基化基因组区域、表2至17中的七个或更多个甲基化基因组区域、表2至17中的八个或更多个甲基化基因组区域、表2至17中的九个或更多个甲基化基因组区域、表2至17中的十个或更多个甲基化基因组区域、表2至17中的十一个或更多个甲基化基因组区域、表2至17中的十二个或更多个甲基化基因组区域、或表2至17中十三个或更多个的甲基化基因组区域。
在一个实施方案中,所述至少两种细胞增殖性病症包括选自以下的组合:结直肠癌和前列腺癌;结直肠癌和肺癌;结直肠癌和乳腺癌;结直肠癌和肝癌;结直肠癌和卵巢癌;结直肠癌和胰腺癌;前列腺癌和肺癌;前列腺癌和乳腺癌;前列腺癌和肝癌;前列腺癌和卵巢癌;前列腺癌和胰腺癌;肺癌和乳腺癌;肺癌和肝癌;肺癌和卵巢癌;肺癌和胰腺癌;乳腺癌和肝癌;乳腺癌和卵巢癌;乳腺癌和胰腺癌;肝癌和卵巢癌;肝癌和胰腺癌;卵巢癌和胰腺癌;结直肠癌、前列腺癌和肺癌;结直肠癌、前列腺癌和乳腺癌;结直肠癌、前列腺癌和肝癌;结直肠癌、前列腺癌和卵巢癌;结直肠癌、前列腺癌和胰腺癌;结直肠癌、肺癌和乳腺癌;结直肠癌、肺癌和肝癌;结直肠癌、肺癌和卵巢癌;结直肠癌、肺癌和胰腺癌;结直肠癌、乳腺癌和肝癌;结直肠癌、乳腺癌和卵巢癌;结直肠癌、乳腺癌和胰腺癌;前列腺癌、肝癌和卵巢癌;前列腺癌、肝癌和胰腺癌;前列腺癌、卵巢癌和胰腺癌;以及结直肠癌、前列腺癌、肺癌和乳腺癌。
在各种实施方案中,与结直肠癌组织来源相关联的预定甲基化基因组区域小组选自表2、3或4。
在各种实施方案中,与肝癌组织来源相关联的预定甲基化基因组区域小组选自表5、6或7。
在各种实施方案中,与肺癌组织来源相关联的预定甲基化基因组区域小组选自表8或9。
在各种实施方案中,与卵巢癌组织来源相关联的预定甲基化基因组区域小组选自表10、11或12。
在各种实施方案中,与胰腺癌组织来源相关联的预定甲基化基因组区域小组选自表13或14
在各种实施方案中,与前列腺癌组织来源相关联的预定甲基化基因组区域小组选自表15、16或17。
一方面,本公开提供了一种在与2种或更多种癌症类型相关联的预定甲基化基因组区域小组上训练的机器学习分类器,其中所述甲基化基因组区域选自a)表1和/或b)表2-17及其组合。
另一方面,本公开提供了一种能够区分健康对象群体与患有细胞增殖性病症的对象的机器学习分类器,其包括:
a)代表表1-17的与2种或更多种细胞增殖性病症相关联的差异甲基化基因组区域的测量值集,其中所述测量值获自来自健康对象和患有细胞增殖性病症的对象的甲基化测序数据,
b)其中所述测量值用于生成与所述差异甲基化基因组区域的特性相对应的特征集,并且其中使用机器学习或统计模型分析所述特征,
c)其中所述模型提供可用作分类器的特征向量,所述分类器能够区分健康对象群体与患有细胞增殖性病症的对象。
在一个实施方案中,所述测量值集描述了选自以下的甲基化区域的特点:CpG、CHG、CHH的逐个碱基甲基化百分比、转化效率(CHH的100-平均甲基化百分比)、低甲基化段、甲基化水平(CPG、CHH、CHG的全局平均甲基化、片段长度、片段中点,以及在诸如chrM、LINE1或ALU的一个或多个基因组区域中的甲基化水平)、每个片段的甲基化CpG的数量、每个片段的CpG甲基化占总CpG的分率、每个区域的CpG甲基化占总CpG的分率、小组中CpG甲基化占总CpG的分率、二核苷酸覆盖度(归一化的二核苷酸覆盖度)、覆盖度的均匀度(在lx和10x平均基因组覆盖下的独特CpG位点(对于S4运行))、全局平均CpG覆盖度(深度),以及在CpG岛(CGI)、CGI架、CGI岸处的平均覆盖度。
在一些实施方案中,所述小组包括经训练的机器学习分类器的将对象分类为患有癌症和/或定位所述对象的肿瘤的组织来源的部分。
在一些实施方案中,包括所述分类器的机器学习模型被加载到计算机系统的存储器中,所述机器学习模型使用从以下项获得的训练向量来训练:训练生物样品、被鉴定为患有细胞增殖性病症的所述训练生物样品的第一子集和被鉴定为未患有细胞增殖性病症的所述训练生物样品的第二子集。
一方面,本公开提供了一种机器学习分类器,其在与2种或更多种类型的细胞增殖性病症相关联的预定甲基化基因组区域小组上训练,并且对于待使用所述小组检测的不同类型的细胞增殖性病症具有预选的敏感性和特异性。
在各种实施方案中,所述不同类型的细胞增殖性病症选自结直肠癌、乳腺癌、卵巢癌、前列腺癌、肺癌、胰腺癌、子宫癌、肝癌、食管癌、胃癌、甲状腺癌或膀胱癌。
在一个实施方案中,所述机器学习分类器被定制为根据两种或更多种癌症的癌症诊断和确认性诊断的需要对于待检测的不同类型的细胞增殖性病症提供预选的敏感性和特异性,所述两种或更多种癌症选自结直肠癌、乳腺癌、卵巢癌、前列腺癌、肺癌、胰腺癌、子宫癌、肝癌、食管癌、胃癌、甲状腺癌或膀胱癌或其组合,其中对于结直肠癌相关分类小组的预选的敏感性是至少70%敏感性;对于乳腺癌相关分类小组的预选的特异性是至少70%特异性;对于卵巢癌相关分类小组的预选的特异性是至少90%特异性;对于前列腺癌相关分类小组的预选的特异性是至少70%特异性;对于肺癌相关分类小组的预选的特异性是至少70%特异性;对于胰腺癌相关分类小组的预选的特异性是至少90%特异性;对于子宫癌相关分类小组的预选的特异性是至少90%特异性;对于肝癌相关分类小组的预选的敏感性是至少70%敏感性;对于食管癌相关分类小组的预选的敏感性是至少70%敏感性;对于胃癌相关分类小组的预选的敏感性是至少70%敏感性;对于甲状腺癌相关分类小组的预选的特异性是至少70%特异性;并且对于膀胱癌相关分类小组的预选的敏感性是至少70%敏感性,基于通过所述分类模型检测到的癌症类型进行选择。
一方面,本公开提供了一种用于确定cfDNA样品的甲基化谱的方法,其通过以下进行:获得具有与2种或更多种癌症类型的存在相关联的基因组区域的预选小组的样品中的cfDNA,将其转化、测序,以及计算与所述基因组区域的预选小组相对应的cfDNA的甲基化谱。
一方面,本公开提供了一种用于确定来自对象的无细胞脱氧核糖核酸(cfDNA)样品的甲基化谱的方法,其包括:
a)提供能够在所述cfDNA样品的核酸分子中将非甲基化胞嘧啶转化为尿嘧啶以产生多个转化核酸的条件;
b)使所述多个转化核酸与核酸探针接触,所述核酸探针与选自表1-17中的差异甲基化区域的至少两个差异甲基化区域的预鉴定甲基化特征小组互补,以富集与所述特征小组相对应的序列;
c)确定所述多个转化核酸分子的核酸序列;以及
d)将所述多个转化核酸分子的所述核酸序列与参考核酸序列比对,从而确定所述对象的所述甲基化谱。
另一方面,本公开提供了一种用于确定来自对象的cfDNA样品的甲基化谱的方法,其包括:
a)提供能够在cfDNA样品的核酸分子中将非甲基化胞嘧啶转化为尿嘧啶以产生多个转化核酸的条件;
b)通过聚合酶链式反应来扩增转化核酸;
c)用核酸探针探测所述转化核酸,所述核酸探针与选自表1-17的至少两个差异甲基化区域的预鉴定甲基化特征小组互补,以富集与所述特征小组相对应的序列;
d)在大于5000x的深度下确定所述转化核酸分子的核酸序列,以及
e)将所述转化核酸分子的所述核酸序列与CpG基因座的预鉴定小组的参考核酸序列比对,以确定所述对象的所述甲基化谱。
在一些实施方案中,在所述扩增之前制备核酸测序文库。
在一些实施方案中,所述甲基化谱与细胞增殖性病症相关联,并提供对象关于患有细胞增殖性病症的分类。
在一些实施方案中,在a)之前将包含独特分子标识符的核酸衔接子连接到cfDNA样品中未转化的核酸上。
在一些实施方案中,使用化学方法、酶促方法或其组合使核酸分子处于胞嘧啶向尿嘧啶的转化条件下。
在一些实施方案中,用试剂处理生物样品中的cfDNA,所述试剂选自重亚硫酸盐(bisulfite)、亚硫酸氢盐(hydrogen sulfite)、焦亚硫酸盐(disulfite)及其组合。
在一些实施方案中,从对象获得的生物样品选自体液、粪便、结肠排出物、尿液、血浆、血清、全血、分离的血细胞、从血液分离的细胞及其组合。
在一些实施方案中,所述方法包括将从对象测量的甲基化特征小组与从正常对象测量的甲基化特征小组的数据库进行对比,其中所述数据库存储在计算机系统中;通过测量到相对于正常对象的甲基化状况在甲基化特征小组的甲基化状况中有至少15%的变化来确定所述对象患细胞增殖性病症的风险增加。
在一些实施方案中,所述细胞增殖性病症选自1期癌症、2期癌症、3期癌症和4期癌症。
另一方面,本公开提供了一种用于检测生物对象中的细胞增殖性病症的方法,其包括:
a)从来自所述对象的核酸样品获得与2种或更多种不同的细胞增殖性病症组织类型的存在相关联的基因组区域的预选小组的甲基化测序信息,
b)将来自所述对象的所述序列信息应用于在与2种或更多种不同的细胞增殖性病症类型的存在相关联的基因组区域的预选小组上训练的分类模型,以鉴定细胞增殖性病症的存在,以及如果检测到细胞增殖性病症,并且
c)将来自所述对象的序列信息应用于在与不同组织类型中细胞增殖性病症的存在相关联的基因组区域的预选小组上训练的分类模型,以确定所述对象中所述细胞增殖性病症的组织来源。
一方面,本公开提供了一种用于检测对象中的细胞增殖性病症的方法,其包括:
a)从来自所述对象的核酸样品获得与两种或更多种不同的细胞增殖性病症相关联的基因组区域的预选小组的甲基化测序信息病症,
b)计算所述样品中与两种或更多种类型的细胞增殖性病症相关联的预定甲基化基因组区域的所述预选小组相对应的cfDNA的甲基化谱,以及
c)应用机器学习分类器,所述机器学习分类器在与两种或更多种类型的细胞增殖性病症相关联的预定甲基化基因组区域小组上训练,并且对于待使用所述小组检测的所述不同类型的细胞增殖性病症具有预选的敏感性和特异性。
在各种实施方案中,所述不同类型的细胞增殖性病症选自结直肠癌、乳腺癌、卵巢癌、前列腺癌、肺癌、胰腺癌、子宫癌、肝癌、食管癌、胃癌、甲状腺癌或膀胱癌。
在一个实施方案中,所述机器学习分类器被定制为根据两种或更多种癌症的癌症诊断和确认性诊断的需要对于待检测的不同类型的细胞增殖性病症提供预选的敏感性和特异性,所述两种或更多种癌症选自结直肠癌、乳腺癌、卵巢癌、前列腺癌、肺癌、胰腺癌、子宫癌、肝癌、食管癌、胃癌、甲状腺癌或膀胱癌或其组合。
在一个实施方案中,对于结直肠癌相关分类小组的预选的敏感性是至少70%敏感性;对于乳腺癌相关分类小组的预选的特异性是至少70%特异性;对于卵巢癌相关分类小组的预选的特异性是至少90%特异性;对于前列腺癌相关分类小组的预选的特异性是至少70%特异性;对于肺癌相关分类小组的预选的特异性是至少70%特异性;对于胰腺癌相关分类小组的预选的特异性是至少90%特异性;对于子宫癌相关分类小组的预选的特异性是至少90%特异性;对于肝癌相关分类小组的预选的敏感性是至少70%敏感性;对于食管癌相关分类小组的预选的敏感性是至少70%敏感性;对于胃癌相关分类小组的预选的敏感性是至少70%敏感性;对于甲状腺癌相关分类小组的预选的特异性是至少70%特异性;或者对于膀胱癌相关分类小组的预选的敏感性是至少70%敏感性,基于通过所述分类模型检测到的癌症类型进行选择。
一方面,本公开提供了一种用于检测对象中细胞增殖性病症的存在或不存在的方法,其包括:
a)提供能够在获自或衍生自所述对象的生物样品的核酸分子中将非甲基化胞嘧啶转化为尿嘧啶以产生多个转化核酸的条件;
b)使所述多个转化核酸与核酸探针接触,所述核酸探针与选自表1-17中的差异甲基化区域的至少两个差异甲基化区域的预鉴定甲基化特征小组互补,以富集与所述特征小组相对应的序列;
c)确定所述转化核酸分子的核酸序列;
d)将所述多个转化核酸分子的所述核酸序列与参考核酸序列比对,从而确定所述对象的甲基化谱;以及
e)将经训练的机器学习分类器应用于所述甲基化谱,其中所述经训练的机器学习分类器被训练为能够区分健康对象与患有细胞增殖性病症的对象,以提供与存在细胞增殖性病症相关联的输出值,从而检测所述对象中所述细胞增殖性病症的存在或不存在。
另一方面,本公开提供了一种用于检测对象中的细胞增殖性病症的方法,其包括:
a)提供能够在cfDNA样品的核酸分子中将非甲基化胞嘧啶转化为尿嘧啶以产生多个转化核酸的条件;
b)通过聚合酶链式反应来扩增转化核酸;
c)用核酸探针探测所述转化核酸,所述核酸探针与选自表1-17的至少两个差异甲基化区域的预鉴定甲基化特征小组互补,以富集与所述特征小组相对应的序列;
d)在大于5000x的深度下确定所述转化核酸分子的核酸序列,以及
e)将所述转化核酸分子的所述核酸序列与CpG基因座的预鉴定小组的参考核酸序列比对,以确定所述对象的甲基化谱,以及
f)使用机器学习模型分析所述甲基化谱,所述机器学习模型被训练为能够区分健康对象与患有细胞增殖性病症的对象,以提供与存在细胞增殖性病症相关联的输出值,从而指示所述对象中细胞增殖性病症的存在。
在一些实施方案中,从对象获得的生物样品选自体液、粪便、结肠排出物、尿液、血浆、血清、全血、分离的血细胞、从血液分离的细胞及其组合。
在一些实施方案中,所述方法包括将从对象测量的甲基化特征小组与从正常对象测量的甲基化特征小组的数据库进行对比,其中所述数据库存储在计算机系统中;通过测量到相对于正常对象的甲基化状况在所述甲基化特征小组的甲基化状况中有至少15%的变化来确定所述对象患细胞增殖性病症的风险增加。
在一些实施方案中,所述细胞增殖性病症选自1期癌症、2期癌症、3期癌症和4期癌症。
在一些实施方案中,所述方法检测胰腺癌并且与检测所述生物样品中CA19-9蛋白的存在或量组合进行。
在一些实施方案中,所述方法检测前列腺癌并且与检测所述生物样品中PSA蛋白的存在或量组合进行。
一方面,本公开提供了一种用于检测细胞增殖性病症的包括机器学习模型分类器的系统,其包括:
a)包括分类器的计算机可读介质,所述分类器可操作以基于表1-17的甲基化特征小组或其组合将对象分类为患有所述细胞增殖性病症或未患有所述细胞增殖性病症;和
b)一个或多个处理器,用于执行存储在所述计算机可读介质上的指令。
在一个实施方案中,所述系统包括被加载到计算机系统的存储器中的分类器,所述机器学习模型使用从以下项获得的训练向量来训练:训练生物样品、被鉴定为患有细胞增殖性病症的所述训练生物样品的第一子集和被鉴定为未患有细胞增殖性病症的所述训练生物样品的第二子集。
在一些实施方案中,所述分类器提供在用于检测细胞增殖性病症的系统中,所述系统包括:
a)包括分类器的计算机可读介质,所述分类器可操作以基于本文所述的甲基化特征小组来对所述对象进行分类;和
b)一个或多个处理器,用于执行存储在所述计算机可读介质上的指令。
在一些实施方案中,所述系统包括分类回路,其被配置为选自以下的机器学习分类器:深度学习分类器、神经网络分类器、线性判别分析(LDA)分类器、二次判别分析(QDA)分类器、支持向量机(SVM)分类器、随机森林(RF)分类器、线性核支持向量机分类器、一阶或二阶多项式核支持向量机分类器、岭回归分类器、弹性网算法分类器、序列最小优化算法分类器、朴素贝叶斯算法分类器和主成分分析分类器。
在一些实施方案中,计算机可读介质是包括机器可执行代码的非临时计算机可读介质,所述机器可执行代码在由一个或多个计算机处理器执行时,实现上述或本文其他地方的任何方法。
在一些实施方案中,所述系统包括一个或多个计算机处理器和与之耦合的计算机存储器。计算机存储器包括机器可执行代码,所述机器可执行代码在由一个或多个计算机处理器执行时,实现本文所述的任何方法。
另一方面,本公开提供了一种用于监测先前因疾病而接受治疗的对象中的微小残留疾病的方法,其包括:确定如本文所述的甲基化谱作为基线甲基化状态,并重复分析以确定在一个或多个预定时间点的甲基化谱,其中与基线相比的变化指示所述对象在基线时微小残留疾病状况的变化。
在一些实施方案中,微小残留疾病选自对治疗的应答、肿瘤负荷、术后残留肿瘤、复发、二次筛查、初次筛查和癌症进展。
另一方面,提供了一种用于确定对治疗的应答的方法。
另一方面,提供了一种用于监测肿瘤负荷的方法。
另一方面,提供了一种用于检测术后残留肿瘤的方法。
另一方面,提供了一种用于检测复发的方法。
另一方面,提供了一种用作二次筛查的方法。
另一方面,提供了一种用作初次筛查的方法。
另一方面,提供了一种用于监测癌症进展的方法。
在一些实施方案中,数据集以至少约80%的敏感性指示所述癌症的存在或易感性。在一些实施方案中,数据集以在至少约90%的敏感性指示所述癌症的存在或易感性。在一些实施方案中,数据集以在至少约95%的敏感性指示所述癌症的存在或易感性。在一些实施方案中,数据集以至少约70%的阳性预测值(PPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集以至少约80%的阳性预测值(PPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集以至少约90%的阳性预测值(PPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集指示在至少约95%的阳性预测值(PPV)下所述癌症的存在或易感性。在一些实施方案中,数据集以至少约99%的阳性预测值(PPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集以至少约80%的阴性预测值(NPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集以至少约90%的阴性预测值(NPV)指示所述癌症的存在或易感性。在一些实施方案中,数据集指示在至少约95%的阴性预测值(NPV)下所述癌症的存在或易感性。在一些实施方案中,数据集指示在至少约99%的阴性预测值(NPV)下所述癌症的存在或易感性。在一些实施方案中,经训练的算法以至少约0.90的曲线下面积(AUC)确定对象中所述癌症的存在或易感性。在一些实施方案中,经训练的算法以至少约0.95的曲线下面积(AUC)确定对象中所述癌症的存在或易感性。在一些实施方案中,经训练的算法以至少约0.99的曲线下面积(AUC)确定对象中所述癌症的存在或易感性。
在一些实施方案中,所述方法还包括在用户的电子装置的图形用户界面上显示报告。在一些实施方案中,用户是对象、个体或患者。
在一些实施方案中,所述方法还包括确定所述对象、个体或患者中癌症的存在或易感性的可能性。
在一些实施方案中,经训练的算法(例如,机器学习模型或分类器)包括有监督的机器学习算法。在一些实施方案中,有监督的机器学习算法包括深度学习算法、支持向量机(SVM)、神经网络或随机森林(Random Forest)。
在一些实施方案中,所述方法还包括为所述对象提供至少部分基于甲基化谱或分析的治疗干预,诸如治疗癌症患者的治疗干预(例如,化疗、放疗、免疫疗法或手术)。
在一些实施方案中,所述方法还包括监测癌症的存在或易感性,其中所述监测包括在多个时间点评估所述对象的癌症的存在或易感性,其中所述评估至少是基于在多个时间点的每一个下所确定的癌症的存在或易感性。
在一些实施方案中,在多个时间点之间评估对象的癌症的存在或易感性的差异指示一个或多个选自以下的临床指征:(i)对象的癌症的存在或易感性的诊断;(ii)对象的癌症的存在或易感性的预后;以及(iii)治疗对象的癌症的存在或易感性的治疗过程有效或无效。
在一些实施方案中,所述方法还包括通过使用经训练的算法对对象的癌症进行分层,以从多个不同的癌症亚型或分期中确定对象的癌症的亚型。
本公开的另一方面提供了一种包括机器可执行代码的非临时计算机可读介质,所述机器可执行代码在由一个或多个计算机处理器执行时,实现上述或本文其他地方的任何方法。
本公开的另一方面提供了一种系统,其包括一个或多个计算机处理器和与之耦合的计算机存储器。计算机存储器包括机器可执行代码,所述机器可执行代码在由一个或多个计算机处理器执行时,实现上述或本文其他地方的任何方法。
根据以下具体实施方式,本公开的另外的方面和优点对于本领域技术人员将容易地变得清楚,在以下具体实施方式中仅示出和描述了本公开的说明性实施方案。如将会理解的,本公开能够具有其他的和不同的实施方案,并且其若干细节能够在各个明显的方面进行修改,所有这些都不背离本公开。因此,附图和说明书将在本质上被视为是说明性的而非限制性的。
附图说明
现将参考附图仅以举例的方式来描述本公开的实施例。本发明的新颖特征在随附权利要求中具体阐述。将通过参考阐述了利用本发明原理的说明性实施方案的以下具体实施方式和附图(在本文中也称为“图”)获得对本发明的特征和优点的更好的理解,在所述附图中:
图1提供了以编程或以其他方式配置有机器学习模型和分类器以实现本文提供的方法的计算机系统的示意图。
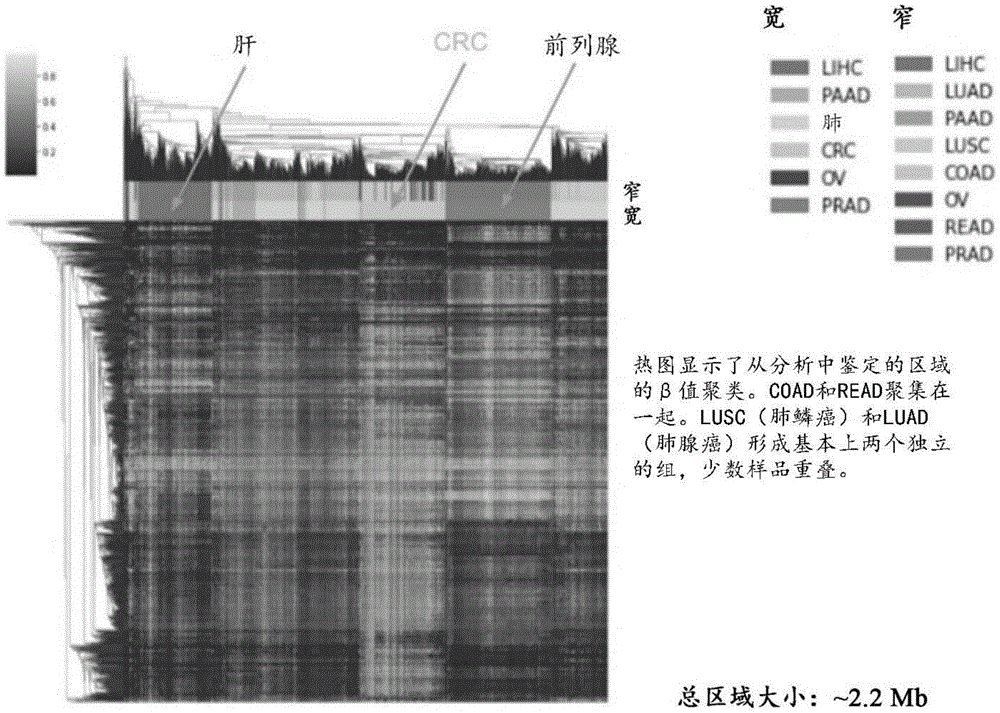
图2提供了这些1681个区域的β值的热图,其指示这些区域也可以含有可用于确定肿瘤来源的信号。不同的肿瘤类型聚类成基本上不同的分组。
图3提供了包括在多癌症小组中的区域的热图。热图显示即使是这个较小的子集,不同癌症类型之间也有适当区分。
具体实施方式
尽管本文已经示出和描述了本发明的各种实施方案,但对于本领域技术人员明显的是,此类实施方案仅以举例的方式提供。在不背离本发明的情况下,本领域技术人员可以想到多种变型、改变和替代。应当理解,可以采用针对本文所描述的本发明实施方案的各种替代方案。
本公开总体上涉及癌症检测和疾病监测。更具体地,所述领域涉及癌症相关的DNA甲基化检测和早期癌症的疾病监测。癌症筛查和监测可以有助于改善结局,因为癌症可以在有机会扩散之前就被消除,所以早期检测产生更好的结局。例如,在结直肠癌的情况下,使用结肠镜检查可以在改善早期诊断方面发挥作用。遗憾的是,结肠镜检查带来了挑战,特别是由于患者对定期筛查的依从性较低。
任何筛查工具的主要问题可能是假阳性与假阴性结果(或特异性和敏感性)之间的折中,在前一种情况下导致了不必要的调查,而在后一种情况下导致无效。理想的测试可以是具有高阳性预测值(PPV)的,最大限度地减少不必要的调查,但能检测到绝大多数癌症。另一个关键因素是“检测敏感性”。与测试敏感性不同,检测敏感性是关于肿瘤大小的检测下限。遗憾的是,等待肿瘤生长到足够大以释放检测所必需水平的循环肿瘤标志物可能与在治疗最有效的早期治疗肿瘤的目标相矛盾。因此,需要基于循环分析物对早期癌症进行有效的基于血液的筛查。
循环肿瘤DNA可以是一种可行的“液体活检”,用于以非侵入性的方式对肿瘤进行检测和信息调查。循环肿瘤DNA中肿瘤特异性突变的鉴定可以应用于结肠癌、乳腺癌和前列腺癌的诊断。然而,由于循环中存在高背景的正常(例如,非肿瘤来源的)DNA,所以这些技术的敏感性可能受到限制。
对血液中肿瘤特异性甲基化的检测可以提供比突变检测明显的优势。可以在癌症中评估许多单一或多种甲基化生物标志物,所述癌症包括结直肠癌、前列腺癌、肺癌、乳腺癌、胰腺癌、卵巢癌、子宫癌、肝癌、食管癌、胃癌或甲状腺癌。这些生物标志物可能会有低敏感性,因为所述生物标志物在肿瘤中可能不够普遍。仍需要更敏感且更具特异性的筛查工具来检测复发中的早期或低肿瘤负荷的癌症肿瘤信号,并在高危群体中进行初次筛查。
本公开提供了涉及与癌症检测和疾病进展相关联的基因甲基化谱分析的方法和系统。
一方面,本公开提供了使用可用于分析区域或基因内的甲基化的甲基化区域小组的方法。其他方面提供了区域、基因和基因产物的新颖用途,以及涉及检测、区别和区分细胞增殖性病症的方法、测定和试剂盒。本文提供的方法和核酸可以用于分析细胞增殖性病症,诸如腺癌、腺瘤、息肉、鳞状细胞癌、类癌瘤、肉瘤和淋巴瘤。
在一些实施方案中,所述方法包括使用甲基化区域的一个或多个基因作为用于细胞增殖性病症的区别、检测和区分的标志物。在一些实施方案中,所述方法包括分析选自本文所述的甲基化区域的一个或多个基因及其启动子或调控元件的甲基化状况。
本公开的方法和系统可以包括根据在此所述的甲基化区域和与之互补的序列对一个或多个基因组序列中的CpG二核苷酸的甲基化状态进行分析。
I.定义
除非上下文另有明确指示,否则如说明书和权利要求中所用,单数形式“一个/种(a/an)”以及“所述(the)”包括复数个指示物。例如,术语“核酸”包括多个核酸,包括其混合物。
如本文所用,术语“对象”一般是指具有可测试或可检测的遗传信息的实体或媒介。对象可以是个人、个体或患者。对象可以是脊椎动物,例如像哺乳动物。哺乳动物的非限制性实例包括人、猿猴、农场动物、竞技动物、啮齿动物和宠物。对象可以是患有癌症或疑似患有癌症的人。对象可以表现出指示对象健康或生理状态或状况的症状,诸如对象的癌症或其他疾病、病症或病状。作为替代,对象可以在这种健康或生理状态或状况方面无症状。
如本文所用,术语“样品”一般是指获自或衍生自一个或多个对象的生物样品。生物样品可以是无细胞生物样品或大体上无细胞的生物样品,或者可以被加工或分级分离以产生无细胞生物样品。例如,无细胞生物样品可包括无细胞核糖核酸(cfRNA)、无细胞脱氧核糖核酸(cfDNA)、无细胞胎儿DNA(cffDNA)、血浆、血清、尿液、唾液、羊水及其衍生物。可以使用乙二胺四乙酸(EDTA)收集管、无细胞RNA收集管(例如,
如本文所用,术语“核酸”一般是指任意长度的核苷酸的聚合形式,无论是脱氧核糖核苷酸(dNTP)或核糖核苷酸(rNTP),或其类似物。核酸可以具有任何三维结构,并且可以执行任何已知或未知的功能。核酸的非限制性实例包括脱氧核糖核酸(DNA)、核糖核酸(RNA)、基因或基因片段的编码或非编码区、从连锁分析中定义的基因座(locus)、外显子、内含子、信使RNA(mRNA)、转移RNA、核糖体RNA、短干扰RNA(siRNA)、短发夹RNA(shRNA)、微RNA(miRNA)、核酶、cDNA、重组核酸、支链核酸、质粒、载体、任意序列的分离DNA、任意序列的分离RNA、核酸探针和引物。核酸可以包含一个或多个修饰的核苷酸,诸如甲基化的核苷酸和核苷酸类似物。如果存在修饰,则可以在核酸组装之前或之后赋予对核苷酸结构的修饰。核酸的核苷酸序列可以被非核苷酸组分中断。核酸可以在聚合之后进一步被修饰,诸如通过与报告因子缀合或结合
如本文所用,术语“靶核酸”一般是指核酸分子起始群体中的核酸分子,所述核酸分子的核苷酸序列的存在、量和/或序列或其中一个或多个的变化都需要被确定。靶核酸可以是任何类型的核酸,包括DNA、RNA及其类似物。如本文所用,“靶核糖核酸(RNA)”一般是指作为RNA的靶核酸。如本文所用,“靶脱氧核糖核酸(DNA)”一般是指作为DNA的靶核酸。
如本文所用,术语“扩增(amplifying)”和“扩增(amplification)”一般是指增加核酸分子的大小或数量。核酸分子可以是单链的或双链的。扩增可以包括生成核酸分子的一个或多个拷贝或“扩增产物”。扩增可以例如通过延伸(例如引物延伸)或连接进行。扩增可以包括进行引物延伸反应以生成与单链核酸分子互补的链,并在一些情况下生成所述链和/或单链核酸分子的一个或多个拷贝。术语“DNA扩增”一般是指生成DNA分子的一个或多个拷贝或“扩增的DNA产物”。术语“逆转录扩增”一般是指通过逆转录酶的作用,从核糖核酸(RNA)模板生成脱氧核糖核酸(DNA)
如本文所用,术语“无细胞核酸(cfNA)”一般是指生物样品中不包含在细胞中的核酸(诸如无细胞RNA(“cfRNA”)或无细胞DNA(“cfDNA”))。cfDNA可以在体液中,诸如在血流中自由循环。
如本文所用,术语“无细胞样品”一般是指大体上缺乏完整细胞的生物样品。这可衍生自本身大体上缺乏细胞的生物样品,或可以衍生自细胞已被去除的样品。无细胞样品的实例包括衍生自血液(诸如血清或血浆)的那些;尿;或衍生自其他来源的样品,诸如精液、痰、粪便、导管渗出液、淋巴或回收的灌洗液。
如本文所用,术语“循环肿瘤DNA”一般是指源自肿瘤的cfDNA。
如本文所用,术语“基因组区域”一般是指核酸的鉴定区域,所述区域是根据它们在染色体中的位置来鉴定的。在一些实例中,基因组区域由一个基因名称来指代,并且涵盖与核酸物理区域相关的编码区和非编码区。如本文所用,基因包含编码区(外显子)、非编码区(内含子)、转录控制区或其他调控区以及启动子。在另一个实例中,基因组区域可以包含命名基因内的内含子或外显子或内含子/外显子边界。
如本文所用,术语“CpG岛”或“CGI”一般是指基因组DNA满足以下标准的连续区域:(1)与“观测/预期比率”相对应的CpG二核苷酸的频率大于约0.6;和(2)“GC含量”大于约0.5。CpG岛的长度可以介于约0.2至约3千碱基(kb)之间,有高频率的CpG位点。CpG岛可以见于约40%哺乳动物基因的启动子处或附近。CpG岛也可以见于哺乳动物基因之外。在一些实例中,CpG岛见于外显子、内含子、启动子、增强子、抑制子和转录调控元件中。CpG岛可以倾向于出现在所谓的“管家基因”的上游。CpG岛的CpG二核苷酸含量可以是统计预期的至少约60%。CpG岛在基因5'末端处或上游的出现可以反映在转录调控中的作用。基因启动子内CpG位点的甲基化可能导致沉默。反之,甲基化所造成的肿瘤抑制子的沉默可以是许多人癌症的标志。
如本文所用,术语“CpG岸”或“CGI岸”一般是指从CpG岛向外延伸的短距离区域,其中也可能发生甲基化。CpG岸可以见于CpG岛的上游和下游约0至2kb的区域内。
如本文所用,术语“CpG架”或“CGI架”一般是指从CpG岸延伸的短距离区域,其中也可能发生甲基化。CpG架一般可以见于CpG岛的上游和下游约2kb与4kb之间的区域(例如,从CpG岸向外再延伸2kb)。
如本文所用,术语“细胞增殖性病症”一般是指包括细胞的紊乱或异常增殖的病症或疾病。在一些非限制性实例中,所述疾病是结直肠细胞增殖、前列腺细胞增殖、肺细胞增殖、乳腺细胞增殖、胰腺细胞增殖、卵巢细胞增殖、子宫细胞增殖、肝细胞增殖、食管细胞增殖、胃细胞增殖或甲状腺细胞增殖。在一些实施方案中,所述细胞增殖性病症是结肠腺癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢浆液性囊腺癌、胰腺腺癌、前列腺腺癌或直肠腺癌。
如本文所用,术语“正常”或“健康”一般是指不具有细胞增殖性病症的细胞、组织、血浆、血液、生物样品或对象。
如本文所用,术语“表观遗传参数”一般是指胞嘧啶甲基化。另外的表观遗传参数可以包括例如组蛋白的乙酰化,其可能与DNA甲基化相关。
如本文所用,术语“遗传参数”一般是指基因的突变和多态性以及基因调控进一步所需的序列。突变的实例包括插入、缺失、点突变、倒位和多态性,诸如SNP(单核苷酸多态性)。
如本文所用,术语“半-甲基化”或“半甲基化”一般是指回文CpG甲基化位点的甲基化状态,其中只有回文CpG甲基化位点的两个CpG二核苷酸序列之一者中一个胞嘧啶被甲基化(例如,5'-CC
如本文所用,术语“高甲基化”一般是指相对于正常对照DNA样品中相应的CpG二核苷酸处所见的5-mC的量,与测试DNA样品的DNA序列中一个或多个CpG二核苷酸处5-mC存在的增加相对应的平均甲基化状态。在一些实施方案中,测试DNA样品来自患有细胞增殖性病症的个体。
如本文所用,术语“低甲基化”一般是指相对于正常对照DNA样品中相应的CpG二核苷酸处所见的5-mC的量,与测试DNA样品的DNA序列中一个或多个CpG二核苷酸处5-mC存在的减少相对应的平均甲基化状态。在一些实施方案中,测试DNA样品来自患有细胞增殖性病症的个体。
如本文所用,术语“甲基化状态”或“甲基化状况”一般是指DNA序列中一个或多个CpG二核苷酸处5-甲基胞嘧啶(“5-mC”)的存在或不存在。DNA序列中一个或多个特定的回文CpG甲基化位点(每个位点有两个CpG二核苷酸序列)的甲基化状态包括“非甲基化”、“完全甲基化”和“半甲基化”。
如本文所用,术语“甲基化胞嘧啶”一般是指在5'位置上含有甲基或羟甲基官能团的核酸碱基胞嘧啶的任何甲基化形式。甲基化胞嘧啶可以是基因组DNA中基因转录的调控因子。此术语可以包括5-甲基胞嘧啶和5-羟甲基胞嘧啶。
术语“甲基化测定”是指用于确定DNA序列内的一个或多个CpG二核苷酸序列的甲基化状态的任何测定。
术语“微小残留疾病”或“MRD”是指癌症治疗后是体内的少量癌细胞。可以进行MRD测试,以确定癌症治疗是否有效,并指导进一步的治疗计划。
如本文所用,术语“MSP”(甲基化特异性PCR)一般是指甲基化测定,诸如由Herman等人Proc.Natl.Acad.Sci.USA 93:9821-9826,1996和美国专利号5,786,146(其各自的内容通过引用全文并入本文)所描述的。
如本文所用,术语“甲基化转化的”或“转化的”核酸一般是指核酸,例如像DNA,其已经历了用于甲基化测序的DNA转化过程。转化过程的实例包括基于试剂(诸如重亚硫酸盐)的转化、酶促转化或组合转化(诸如TAPS转化),其中非甲基化胞嘧啶在PCR扩增或测序之前转化为尿嘧啶。转化过程可以用于甲基测序方法,以区分甲基化与非甲基化胞嘧啶碱基。
如本文所用,术语“癌症中甲基化的区域”一般是指基因组中含有甲基化位点(CpG二核苷酸)的区段,其甲基化与恶性细胞状态相关联。区域的甲基化可以与多于一种不同类型的癌症相关联,或者与一种类型癌症特异性相关联。在这种情况下,区域的甲基化可以与多于一种癌症亚型相关联,或者与一种癌症亚型特异性相关联。
术语癌症“类型”和“亚型”在本文中一般是相对使用的,使得一种“类型”的癌症,诸如乳腺癌,可以是基于例如分期、形态学、组织学、基因表达、受体谱、突变谱、侵袭性、预后、恶性特点等的“亚型”。同样,“类型”和“亚型”可以应用在更细的层次上,例如,将一个组织学“类型”区别为“亚型”,例如,根据突变谱或基因表达来定义。癌症“分期”也可以用来指代基于与疾病进展相关的组织学和病理学特点的癌症类型分类。
II.分析样品
无细胞生物样品可以从人对象中获得或衍生。无细胞生物样品在加工前可以储存在不同的储存条件下,诸如不同的温度(例如在室温、冷藏或冷冻条件下、在25℃、在4℃、在-18℃、-20℃或在-80℃)或不同的悬液(例如,EDTA收集管、无细胞RNA收集管或无细胞DNA收集管)。
无细胞生物样品可以从患有癌症的对象、疑似患有癌症的对象、或未患或未疑似患有癌症的对象中获得。
无细胞生物样品可以在癌症对象的治疗之前和/或之后获取。在治疗或治疗方案期间,可以从对象中获得无细胞生物样品。可以从对象中获得多个无细胞生物样品,以监测随时间推移的治疗效果。无细胞生物样品可以取自已知或疑似患有癌症的对象,而所述对象无法通过临床测试得到明确的阳性或阴性诊断。样品可以取自疑似患有癌症的对象。无细胞生物样品可以取自出现以下无法解释的症状的对象,诸如疲劳、恶心、体重减轻、疼痛、虚弱或出血。无细胞生物样品可以取自有解释的症状的对象。无细胞生物样品可以取自因诸如家族史、年龄、高血压或高血压前期、糖尿病或糖尿病前期、超重或肥胖、环境暴露、生活方式风险因素(例如吸烟、饮酒或吸毒)或存在其他风险因素的因素而有发生癌症的风险的对象。
无细胞生物样品可以含有一种或多种可以被分析的分析物,诸如适用于分析以生成转录组数据的无细胞核糖核酸(cfRNA)分子,适用于分析以生成基因组数据的无细胞脱氧核糖核酸(cfDNA)分子,或其混合物或组合。一种或多种这样的分析物(例如,cfRNA分子和/或cfDNA分子)可以从对象的一个或多个无细胞生物样品中分离或提取,以便使用一种或多种合适的测定进行下游分析。
从对象获得无细胞生物样品之后,可以对所述无细胞生物样品进行加工,以生成指示对象癌症的数据集。例如,在癌症相关基因组的基因座小组上对无细胞生物样品的核酸分子进行存在、不存在或定量评估(例如,在癌症相关基因组基因座上对RNA转录物或DNA的定量量度)。对从对象获得的无细胞生物样品进行加工可以包括:(i)将无细胞生物样品置于足以分离、富集或提取多个核酸分子的条件下;以及(ii)分析多个核酸分子以生成数据集。
在一些实施方案中,从无细胞生物样品中提取多个核酸分子,并对其进行测序以生成多个测序读取。核酸分子可以包括核糖核酸(RNA)或脱氧核糖核酸(DNA)。核酸分子(例如,RNA或DNA)可以通过以下多种方法从无细胞生物样品中提取,诸如来自MP Biomedicals的FastDNA
测序可以通过任何合适的测序方法进行,诸如大规模并行测序(MPS)、配对末端测序、高通量测序、下一代测序(NGS)、鸟枪法测序、单分子测序、纳米孔测序、半导体测序、焦磷酸测序、合成测序(SBS)、连接法测序、杂交测序和RNA-Seq(Illumina)。
测序可以包括核酸扩增(例如,RNA或DNA分子)。在一些实施方案中,核酸扩增是聚合酶链式反应(PCR)。可以进行适当轮数的PCR(例如PCR、qPCR、逆转录酶PCR、数字PCR等),以将初始量的核酸(例如RNA或DNA)充分扩增到所需的输入量,以便后续测序。在一些情况下,PCR可以用于靶核酸的全局扩增。这可包括使用衔接子序列,所述衔接子序列可首先连接到不同的分子,然后使用通用引物进行PCR扩增。PCR可以使用许多商用试剂盒中的任一种来进行,例如由Life Technologies、Affymetrix、Promega、Qiagen等提供的试剂盒。在其他情况下,核酸群内仅有某些靶核酸可以被扩增。特异性引物(可能与衔接子连接相结合)可以用于选择性扩增某些靶标以用于下游测序。PCR可以包括一个或多个基因组基因座的靶向扩增,诸如与癌症相关的基因组基因座。测序可以包括使用同步逆转录(RT)和聚合酶链式反应(PCR),诸如由Qiagen、NEB、Thermo Fisher Scientific或Bio-Rad提供的OneStepRT-PCR试剂盒方案。
从无细胞生物样品中分离或提取的RNA或DNA分子可以例如使用可鉴定的标签来标记,以允许多个样品的多重化。任何数量的RNA或DNA样品都可以进行多重化。例如,多重化的反应可以含有来自至少约2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、25个、30个、35个、40个、45个、50个、55个、60个、65个、70个、75个、80个、85个、90个、95个、100个或多于100个初始无细胞生物样品的RNA或DNA。例如,可以用样品条形码标记多个无细胞生物样品,这样每个DNA分子都可以追溯到DNA分子起源的样品(和对象)。这种标签可以通过连接或引物PCR扩增连接到RNA或DNA分子上。
对核酸分子进行测序之后,可以对序列读取进行合适的生物信息学处理,以生成指示癌症存在、不存在或相对评估的数据。例如,序列读取可以与一个或多个参考基因组(例如,一个或多个物种的基因组,诸如人基因组)比对。比对的序列读取可以在一个或多个基因组基因座上定量,以生成指示癌症的数据集。例如,对与癌症相关的多个基因组基因座相对应的序列进行定量,可以生成指示癌症的数据集。
无细胞生物样品不需要任何核酸提取即可加工。例如,可以通过使用配置为选择性富集与多个癌症相关基因组基因座相对应的核酸(例如RNA或DNA)分子的探针来鉴定或监测对象中的癌症。探针可以是核酸引物。探针可与来自多个癌症相关基因组基因座或基因组区域中的一个或多个的核酸序列具有序列互补性。多个癌症相关基因组基因座或基因组区域可以包含至少2个、至少3个、至少4个、至少5个、至少6个、至少7个、至少8个、至少9个、至少10个、至少11个、至少12个、至少13个、至少14个、至少15个、至少16个、至少17个、至少18个、至少19个、至少20个、至少约25个、至少约30个、至少约35个、至少约40个、至少约45个、至少约50个、至少约55个、至少约60个、至少约65个、至少约70个、至少约75个、至少约80个、至少约85个、至少约90个、至少约95个、至少约100个或更多个不同的癌症相关基因组基因座或基因组区域。多个癌症相关基因组基因座或基因组区域可以包含一个或多个选自表1-11中列出的组的成员(例如,1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、约25个、约30个、约35个、约40个、约45个、约50个、约55个、约60个、约65个、约70个、约75个、约80个或更多个)。癌症相关基因组基因座或基因组区域可与不同的癌症(例如,结直肠癌)分期或亚型相关。
探针可以是与一个或多个基因组基因座(例如,癌症相关基因组基因座)的核酸序列(例如,RNA或DNA)具有序列互补的核酸分子(例如,RNA或DNA)。这些核酸分子可以是引物或富集序列。使用对一个或多个基因组基因座(例如癌症相关基因组基因座)有选择性的探针对无细胞生物样品进行的分析可以包括使用阵列杂交(例如基于微阵列的)、聚合酶链式反应(PCR)或核酸测序(例如RNA测序或DNA测序)。在一些实施方案中,DNA或RNA可以通过以下项的一种或多种来分析:DNA/RNA等温扩增方法(例如环介导的等温扩增(LAMP)、解旋酶依赖性扩增(HDA)、滚圈扩增(RCA)、重组酶聚合酶扩增(RPA))、免疫测定、电化学测定、表面增强拉曼光谱(SERS)、基于量子点(QD)的测定、分子反转探针、液滴数字PCR(ddPCR)、基于CRISPR/Cas的检测(例如CRISPR分型PCR(ctPCR)、特异性高灵敏度酶报告解锁(SHERLOCK)、DNA核酸内切酶靶向的CRISPR反式报告基因(DETECTR)、和CRISPR介导的模拟多事件记录装置(CAMERA))和激光透射光谱(LTS)。
测定读出可以在一个或多个基因组基因座(例如,癌症相关基因组基因座)上定量,以生成指示癌症的数据。例如,与多个基因组基因座(例如,癌症相关基因组基因座)相对应的阵列杂交或聚合酶链式反应(PCR)的定量可生成指示癌症的数据。测定读出可以包括定量PCR(qPCR)值、数字PCR(dPCR)值、数字液滴PCR(ddPCR)值、荧光值等,或其归一化值。测定可以是被配置来在家庭环境中进行的家庭用户测试。
在一些实施方案中,多重测定可以用于同时处理对象的无细胞生物样品。例如,第一测定可以用于处理从对象获得或衍生的第一无细胞生物样品,以生成指示癌症的第一数据集;并且与第一测定不同的第二测定可以用于处理从对象获得或衍生的第二无细胞生物样品,以生成指示癌症的第二数据集。然后可以分析第一数据集和第二数据集的任一或所有数据集,以评估对象的癌症。例如,可以基于第一数据集与第二数据集的组合生成单个诊断指标或诊断评分。另一个实例是,可以根据第一数据集和第二数据集生成单独的诊断指标或诊断评分。
无细胞生物样品可以使用甲基化特异性测定来处理。例如,甲基化特异性测定可以用于鉴定对象的无细胞生物样品中多个癌症相关基因组基因座中每个的甲基化定量量度(例如,指示存在、不存在或相对数量)。甲基化特异性测定可以被配置来处理无细胞生物样品,诸如对象的血液样品或尿液样品(或其衍生物)。无细胞生物样品中癌症相关基因组基因座甲基化的定量量度(例如,指示存在、不存在或相对数量)可以指示一种或多种癌症。甲基化特异性测定可以用于生成数据集,以指示对象的无细胞生物样品中多个癌症相关基因组基因座中每个的甲基化的定量量度(例如,指示存在、不存在或相对数量)。
例如,甲基化特异性测定可以包括以下一种或多种:甲基化感知测序(例如,使用重亚硫酸盐处理)、焦磷酸测序、甲基化敏感性单链构象分析(MS-SSCA)、高分辨率熔融分析(HRM)、甲基化敏感性单核苷酸引物延伸(MS-SnuPE)、碱基特异性裂解/MALDI-TOF、基于微阵列的甲基化测定、甲基化特异性PCR、靶向重亚硫酸盐测序、氧化重亚硫酸盐测序、基于质谱的重亚硫酸盐测序或简化代表性重亚硫酸盐测序(RRBS)。
III.特征小组
本公开提供了分析生物样品的方法和系统,以从样品中与细胞增殖性病症发展相关联的DNA中高甲基化区域的组合中获得可测量的特征,从而鉴定区域的特征小组。来自特征小组的特征可以使用经训练的算法(例如,机器学习模型)来处理,以创建分类器,所述分类器被配置来对细胞增殖性病症的个体群体进行分层。所述方法的特征是使用一个或多个具有在特征小组中描述的甲基化区域的核酸,这些核酸在测序之前与一种或一系列能够区分已鉴定的区域内的甲基化与非甲基化CpG二核苷酸的试剂接触。
本文所述的特征小组一般是指在无细胞核酸样品中鉴定的并在与细胞增殖性病症相关联的样品中呈现出胞嘧啶碱基甲基化增加的基因组DNA靶向区域的集合。特征小组的形成可以允许对与细胞增殖性病症相关联的特定甲基化区域进行快速和特异性分析。如本文方法中描述和采用的特征小组可以用于改善细胞增殖性病症的诊断、预后、治疗选择和监测(例如,治疗监测)。
与目前的方法相比,所述特征小组和方法可以提供显著的改进,以从诸如全血、血浆或血清的体液样品中检测早期细胞增殖性病症。
在一些实施方案中,癌症中甲基化的区域包括CpG岛。在一些实施方案中,癌症中甲基化的区域包括CpG岸。在一些实施方案中,癌症中甲基化的区域包括CpG架。在一些实施方案中,癌症中甲基化的区域包括CpG岛和CpG岸。在一些实施方案中,癌症中甲基化的区域包括CpG岛、CpG岸和CpG架。
在一些实施方案中,癌症中甲基化的区域包括CpG岛以及CpG岛上游和下游约0至4kb的序列。癌症中甲基化的区域还可以包括CpG岛以及以下序列:CpG岛上游和下游约0至3kb、上游和下游约0至2kb、上游和下游约0至1kb、上游和下游约0至500个碱基对(bp)、上游和下游约0至400bp、上游和下游约0至300bp、上游和下游约0至200bp、或上游和下游约0至100bp。
根据一些实例,在选择癌症中的高甲基化区域时可以考虑许多设计参数。在某些实例中,甲基化区域的长度为约200bp、约300bp、约400bp或约500bp。这个选择过程的数据可以获自多种来源,例如像癌症基因组图谱(TCGA),通过使用例如用于广泛多种癌症的Illumina Infinium HumanMethylation450 BeadChip衍生而来,或获自基于例如重亚硫酸盐全基因组测序或其他方法的其他来源。在一些实施方案中,可以使用“甲基化值”(可以从TCGA 3级甲基化数据衍生而来,而TCGA 3级甲基化数据又从约-0.5至0.5的β值衍生而来)来选择区域。在一些实施方案中,用引物集进行扩增,所述引物集被设计来扩增至少一个甲基化位点,所述位点的甲基化值在正常组织中低于约-0.3。甲基化值可以在多个正常组织样品中建立,诸如约4。甲基化值可以等于或低于约-0.1、约-0.2、约-0.3、约-0.4、约-0.5、约-0.6、约-0.7、约-0.8、约-0.9或约-1.0。
在一些实施方案中,引物集被设计来扩增至少一个甲基化位点,所述位点在癌症组织与正常组织中的平均甲基化值之间的差异大于预定义的阈值,诸如约0.3。在一些实施方案中,所述差异可以大于约0.1、约0.2、约0.3、约0.4、约0.5、约0.6、约0.7、约0.8、约0.9、或约1.0。在一些实例中,满足此要求的其他甲基化位点的邻近性也可在选择区域中发挥作用。在一些实施方案中,引物集包括扩增至少一个甲基化位点的引物对,所述引物对在约200bp内有至少一个甲基化位点,在正常组织中甲基化值也低于约-0.3,并且在癌症组织与正常组织中的平均甲基化值之间的差异大于约0.3。
在一些实例中,如果一个区域的甲基化大于从一个或多个健康个体(例如,没有癌症的个体)获得或衍生的样品中同一区域的甲基化,则选择靶区域。这种选择可以手动或以计算方式执行。在某些实例中,如果一个区域与来自健康个体的样品相比有多出至少约5%、约10%、约15%、约20%、约30%、约40%、约50%、约55%、约60%、约65%、约70%、约75%、约80%、约85%、约90%、约95%、约100%或多于约100%的甲基化,则选择所述区域。在另一个实例中,如果疾病样品中以预定义阈值甲基化CpG计数映射到一个区域的读取数超过健康个体样品中同一区域的相同预定义阈值甲基化CpG计数,则可以选择所述区域。对于给定区域,在健康样品中用作基线阈值的甲基化CpG计数可以发生变化,但映射到所述区域的读取数超过健康样品中所述区域的甲基化CpG计数的基线阈值则可以指示一个重要区域,而不管阈值CpG计数如何波动。
在一些实例中,可以基于验证集中在所述位点处有甲基化的样品的数量来选择靶区域进行扩增。例如,如果与来自健康个体的样品相比,来自疾病个体的测试样品的至少约5%、约10%、约15%、约20%、约25%、约30%、约35%、约40%、约45%、约50%、约55%、约60%、约65%、约70%、约75%、约80%、约85%、约90%、约95%、约96%、约97%、约98%或约99%的甲基化程度更高,则可以选择所述区域。例如,如果区域在至少约75%的测试肿瘤(包括在特定亚型内)中甲基化,则可以选择所述区域。对于一些验证,肿瘤衍生的细胞系可以用于测试。
本公开还提供了一种用于进行测定的方法,以确定一个或多个选自本文所述的特征小组的基因以及所述一个或多个基因的启动子和调控元件的遗传和/或表观遗传参数。在一些实施方案中,使用根据以下方法进行的测定来检测一个或多个选自本文所述的特征小组的基因内的甲基化,其中所述甲基化核酸存在于还包含过量的背景DNA的溶液中,其中背景DNA以待检测的DNA浓度约100至1,000倍、约100至10,000倍、约100至100,000倍、约1,000至10,000倍、约1,000至100,000倍、或约10,000至100,000倍存在。在一些实施方案中,待检测的DNA浓度大于背景DNA浓度的约100,000倍。在一些实施方案中,所述方法包括使从对象获得的核酸样品与至少一种试剂或一系列试剂(例如,区分靶核酸内甲基化与非甲基化CpG二核苷酸的试剂)接触。
如本文所述,肿瘤或结肠细胞增殖性病症可以选自结直肠、前列腺、肺、乳腺、胰腺、卵巢、子宫、肝、食管、胃或甲状腺细胞增殖。在一些实施方案中,所述细胞增殖性病症选自结肠腺癌、肝细胞癌、肺腺癌、肺鳞状细胞癌、卵巢浆液性囊腺癌、胰腺腺癌、前列腺腺癌和直肠腺癌。
A.多组织类型癌症标志物检测小组
可以根据预期测定的目的选择包含信息甲基化区域的特征小组。对于靶向方法,引物对可以基于预期的靶区域集来设计。表1示出了指示癌症的基因组甲基化区域。本文所述的甲基化区域被注释到人参考基因组中,例如,来自基因组参考序列联盟人构建体38(GRCh38)(癌症基因组图谱(TCGA))。在一些实施方案中,所述区域集包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个、至少十个、至少十一个、至少十二个、至少十三个、至少十四个、至少十五个、至少十六个、至少十七个、至少十八个、至少十九个、至少二十个、至少二十五个、至少三十个、至少三十五个、至少四十个、至少四十五个、至少五十个、至少五十五个或更多表1中列出的区域。在一些实施方案中,所述区域集包含表1中列出的所有区域。
在一些实施方案中,与不同癌症类型的检测相关联的甲基区域集选自表1。
在一些实施方案中,所述癌症小组包含选自以下的区域:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个、至少十个、至少十一个、至少十二个、至少十三个、至少十四个、至少十五个、至少十六个、至少十七个、至少十八个、至少十九个、至少二十个、至少二十五个、至少三十个、至少三十五个、至少四十个、至少四十五个、至少五十个、至少五十五个或更多表1中列出的区域。在一些实施方案中,癌症小组包含表1中列出的所有区域。
表1
/>
/>
在一些实施方案中,所述方法还包括定量甲基化信号,其中超过预定阈值的数值指示细胞增殖性病症,诸如癌症。在一些实施方案中,对细胞增殖性病症中每个甲基化位点的定量和比较是独立进行的。因此,可以为每个位点建立肿瘤阳性信号的计数。在一些实施方案中,所述方法还包括确定含有肿瘤信号的测序读取的比例,其中超过阈值的比例指示细胞增殖性病症。在一些实施方案中,对细胞增殖性病症中的每个甲基化位点的确定是独立进行的。
如本文所用,术语“阈值”一般是指选出以鉴别、分离或区分两个对象群体的值。在一些实施方案中,阈值将甲基化状况鉴别为疾病(例如恶性)状态与非疾病(例如健康)状态。在一些实施方案中,阈值鉴别疾病的不同分期(例如1期、2期、3期或4期)。阈值可根据有关疾病设定,并可根据早期的分析,例如对训练集的分析,或根据一组具有已知特点的输入(例如健康、疾病或疾病分期)计算确定。根据特定位点的甲基化预测值,也可以为基因区域设置阈值。每个甲基化位点的阈值可不同,并且在最终分析中可以组合多个位点的数据。
B.组织来源癌症标志物检测小组
在前述方法的一些实施方案中,所述癌症小组包含与一种类型的癌症的组织来源(TOO)相关联的甲基化基因组区域。以下小组可以并入到机器学习分类器、方法和系统中,以确定生物样品中肿瘤相关甲基化信号的组织来源。
i.结直肠癌
表2示出了结直肠组织来源TCGA分析甲基化区域。在一些实施方案中,癌症小组包含一个或多个表2中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表2中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表2中列出的基因组区域。
表2
表3示出了结直肠组织来源组织甲基化测序甲基化区域。在一些实施方案中,癌症小组包含一个或多个表3中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表3中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表3中列出的基因组区域。
表3
表4示出了组织数据和TCGA分析中重叠的结直肠甲基化区域。在一些实施方案中,癌症小组包含一个或多个表4中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表4中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表4中列出的基因组区域。这些区域与癌症的存在相关联并且与结直肠组织相关联,并且在与表2和/或表3中的区域组合时,支持结直肠癌检测。
表4
ii.肝癌
表5示出了肝组织来源TCGA分析甲基化区域。在一些实施方案中,癌症小组包含一个或多个表5中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表5中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表5中列出的基因组区域。
表5
/>
表6示出了肝组织来源组织甲基化测序甲基化区域。在一些实施方案中,癌症小组包含一个或多个表6中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表6中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表6中列出的基因组区域。
表6
表7示出了组织数据和TCGA分析中重叠的肝甲基化区域。在一些实施方案中,癌症小组包含一个或多个表7中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表7中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表7中列出的基因组区域。这些区域与癌症的存在相关联并且与肝组织相关联,并且在与表5和/或表6中的区域组合时,支持肝癌检测。
表7
iii.肺癌
表8示出了肺组织来源TCGA分析甲基化区域。在一些实施方案中,癌症小组包含一个或多个表8中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表8中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表8中列出的基因组区域。
表8
表9示出了组织数据和TCGA分析中重叠的肺甲基化区域。在一些实施方案中,癌症小组包含一个或多个表9中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表9中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表9中列出的基因组区域。这些区域可以与癌症的存在相关联并且与肺组织相关联,并且在与表8中的区域组合时,可以支持肺癌检测。
表9
iv.卵巢癌
表10示出了卵巢组织来源TCGA分析甲基化区域。在一些实施方案中,癌症小组包含一个或多个表10中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个或全部表10中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个或全部表10中列出的基因组区域。
表10
表11示出了卵巢组织来源组织甲基化测序甲基化区域。在一些实施方案中,癌症小组包含一个或多个表11中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表11中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表11中列出的基因组区域。
表11
/>
表12示出了组织数据和TCGA分析中重叠的卵巢甲基化区域。在一些实施方案中,癌症小组包含一个或多个表12中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表12中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表12中列出的基因组区域。这些区域可以与癌症的存在相关联并且可以与卵巢组织相关联,并且在与表10和/或表11中的区域组合时,可以支持卵巢癌检测。
表12
v.胰腺癌
表13示出了胰腺组织来源组织甲基化测序甲基化区域。在一些实施方案中,癌症小组包含一个或多个表13中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表13中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表13中列出的基因组区域。
表13
表14示出了组织数据和TCGA分析中重叠的胰腺甲基化区域。在一些实施方案中,癌症小组包含一个或多个表14中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表14中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表14中列出的基因组区域。这些区域与癌症的存在相关联并且与胰腺组织相关联,并且在与表13中的区域组合时,可以支持胰腺癌检测。
表14
vi.前列腺癌
表15列出了前列腺组织来源TCGA分析甲基化区域。在一些实施方案中,癌症小组包含一个或多个表15中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表15中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表15中列出的基因组区域。
表15
表16列出了前列腺组织来源组织甲基化测序甲基化区域。在一些实施方案中,癌症小组包含一个或多个表16中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表16中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表16中列出的基因组区域。
表16
表17列出了组织数据和TCGA分析中重叠的前列腺甲基化区域。在一些实施方案中,癌症小组包含一个或多个表17中列出的区域。例如,癌症小组包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表17中列出的基因组区域。在一些实施方案中,将一组探针定向至选自以下的序列:至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或全部表17中列出的基因组区域。这些区域与癌症的存在相关联并且与前列腺组织相关联,并且在与表15和/或表16中的区域组合时,支持前列腺癌检测。
表17
/>
一方面,本公开提供了一种用于鉴定指示生物学特点的甲基化特征的方法,所述方法包括:为群体获得包含多个与细胞增殖性病症状况相关联的基因组甲基化数据集的数据,其中所述基因组甲基化数据集中的每个都与相应样品的生物信息相关联;将甲基化数据集分离为与具有所述生物学特点的一种组织或细胞类型相对应的第一分组和与不具有所述生物学特点的多种组织或细胞类型相对应的第二分组;将第一分组的甲基化数据与第二分组的甲基化数据在基因组中逐个位点进行匹配;在基因组中逐个位点鉴定CpG位点集,所述位点满足用于在第一分组与第二分组之间建立差异甲基化的预定阈值;使用CpG位点集鉴定靶基因组区域,所述区域在约30至300bp内包含至少一个、至少两个、至少三个或多于三个满足所述预定标准的差异甲基化CpG,以鉴定差异甲基化基因组区域,从而提供指示与细胞增殖性病症存在相关联的生物学特点的甲基化特征。
在一些实例中,靶基因组区域在具有以下长度的区域内包含至少一个、至少两个、至少三个或多于三个差异甲基化CpG位点:约30至150bp、约40至150bp、约50至150bp、约75至150bp、约100至150bp、约150至300bp、约150至250bp、约150至200bp、约200至300bp、或约250至300bp。
在一些实例中,靶基因组区域包含至少四个差异甲基化CpG位点、至少五个差异甲基化CpG位点、至少六个差异甲基化CpG位点、至少七个差异甲基化CpG位点、至少八个差异甲基化CpG位点、至少九个差异甲基化CpG位点、至少十个差异甲基化CpG位点、至少12个差异甲基化CpG位点、或至少15个差异甲基化CpG位点。
在一些实施方案中,所述方法还包括通过使用来自至少一个具有所述生物学性状的独立样品的DNA和来自至少一个不具有所述生物样品的独立样品的DNA在延伸的靶基因组区域内测试差异甲基化来验证延伸的靶基因组区域。
在一些实施方案中,所述鉴定还包括将CpG位点集限制为与来自对照样品的外周血单核细胞相比进一步表现出差异甲基化的CpG位点。
在一些实施方案中,所述预定阈值在第一分组中为至少约50%的甲基化。
在一些实施方案中,所述预定阈值是至少约0.3的第一分组与第二分组之间的平均甲基化差异。
在一些实施方案中,所述生物学性状包括恶性度。
在一些实施方案中,所述生物学性状包括癌症类型。
在一些实施方案中,所述生物学性状包括癌症分期。
在一些实施方案中,所述生物学性状包括癌症分类。
在一些实施方案中,所述癌症分类包括癌症分级。
在一些实施方案中,所述癌症分类包括组织学分类。
在一些实施方案中,所述生物学性状包括代谢谱。
在一些实施方案中,所述生物学性状包括突变。
在一些实施方案中,所述突变是疾病相关突变。
在一些实施方案中,所述生物学性状包括临床结局。
在一些实施方案中,所述生物学性状包括药物应答。
在一些实施方案中,所述方法还包括设计多个PCR引物对,以扩增延伸的靶基因组区域的部分,每个部分包含至少一个差异甲基化CpG位点。
在一些实施方案中,多个引物对的设计包括将非甲基化胞嘧啶转化为尿嘧啶以模拟胞嘧啶向尿嘧啶的转化,以及使用转化的序列设计引物对。
在一些实施方案中,引物对被设计成具有甲基化倾向。
在一些实施方案中,引物对是甲基化特异性的。
在一些实施方案中,引物对内无CpG残基,对甲基化状况无偏好。
一方面,本公开提供了一种用于合成对甲基化特征有特异性的引物对的方法,所述方法包括:进行本公开的方法及合成所设计的引物对。
IV.核酸转化和甲基化测序
A.核酸处理
甲基化测序可以利用多种方法,包括核酸碱基的化学基和酶基转化,以区分核酸序列中的甲基化胞嘧啶与非甲基化胞嘧啶。这些测定允许确定DNA序列内一个或多个CpG二核苷酸(例如,CpG岛)的甲基化状态。此类测定尤其可以包括重亚硫酸盐处理DNA的DNA测序或酶处理DNA的DNA测序、聚合酶链式反应(PCR)(用于序列特异性扩增)、定量PCR(qPCR)、或数字液滴PCR(ddPCR)、DNA印迹分析。在各个实例中,以这样的方式处理生物样品中的DNA,使得在5'-位置处未甲基化的胞嘧啶碱基转化为尿嘧啶、胸腺嘧啶或在杂交行为方面与胞嘧啶不同的另一种碱基。这个过程可以称为“转化”。
在一些实施方案中,试剂将在5'-位置处未甲基化的胞嘧啶碱基转化为尿嘧啶、胸腺嘧啶或在杂交行为方面与胞嘧啶不同的另一种碱基。
DNA的重亚硫酸盐修饰一般是指用于评估CpG甲基化状况的工具。用于分析DNA中5-甲基胞嘧啶存在的方法可以是基于重亚硫酸盐与胞嘧啶的反应,在随后的碱性脱硫作用下,胞嘧啶转化为尿嘧啶,其与胸腺嘧啶在碱基配对行为方面相对应。例如,通过使用重亚硫酸盐处理,基因组测序可以适于DNA甲基化模式和5-甲基胞嘧啶分布的分析(例如,如由Frommer等人,Proc.Natl.Acad.Sci.USA 89:1827-1831,1992所述,其内容通过引用并入本文)。然而,值得注意地,5-甲基胞嘧啶在这些条件下可以保持未被修饰。因此,原始DNA可以这样一种方式转化,即最初无法通过杂交行为与胞嘧啶区分的甲基胞嘧啶现在可以通过各种分子生物学技术,例如通过扩增和杂交或通过测序,作为唯一剩下的胞嘧啶被检测出来。在各个实例中,其他试剂可实现与适用于甲基化测序的重亚硫酸盐修饰相同的结果。
直接测序方法可以采用经PCR扩增的重亚硫酸盐处理的DNA,其可用于全基因组重亚硫酸盐测序(WGBS)或靶向重亚硫酸盐测序。
靶向重亚硫酸盐测序是可商购获得的NGS方法,用于评价位点特异性DNA甲基化变化。探针可以被设计成链特异性和重亚硫酸盐特异性的。甲基化和非甲基化序列都可以被扩增。所述过程可以类似于焦磷酸测序,但总体上可以提供更高的通量。在一些实施方案中,下一代测序平台用于递送大量有用的DNA甲基化信息(例如,EPIGENTEK,Farmingdale,NY和ZYMO RESEARCH,Irvine,CA)。通过对DNA进行重亚硫酸盐处理,然后对靶区域进行PCR扩增,构建文库,并对扩增子区域进行测序,可以促进DNA中单个胞嘧啶的单碱基分辨率的甲基化分析。可以为目标区域设计特定引物,并且可以评价此区域内胞嘧啶甲基化的变化。每个目标DNA甲基化位点可以在高测序覆盖度深度下评估,以获得准确、定量和单碱基分辨率的数据输出。
酶促甲基测序(EM-seq)可以依赖于核酸的酶促转化来进行甲基组分析。生成EM-seq文库的过程可以不会像重亚硫酸盐测序那样破坏DNA。EM-seq文库虽然对所有DNA输入量使用更少的PCR循环,但可获得更高的PCR产率,这表明与全基因组重亚硫酸盐测序(WGBS)相比,在酶促处理和文库制备过程中丢失的DNA更少。反之,减少的PCR周期可以在测序过程中转化为更复杂的文库和更少的PCR复制品。EM-seq文库的平均插入尺寸也可以比WGBS更大,这进一步支持了DNA保持完整的事实。在EM-seq流程中,TET2氧化5-mC和5-hmC,在下一个操作中防止APOBEC脱氨基。相反,未修饰的胞嘧啶可以被脱氨基为尿嘧啶。在一些实施方案中,靶向方法包括核酸的酶促转化(TEM-seq)。在一些实施方案中,甲基化测序方法可以是用
在另一个实例中,5-hmC也可以使用TET辅助的重亚硫酸盐测序(TAB-seq)(例如,如由Yu,M.等人(2012).Nat.Protoc.7,2159-2170所述,其内容通过引用并入本文)(WiseGene;
氧化重亚硫酸盐测序(oxBS)提供了另一种区分5-mC与5-hmC的方法(例如,如由byBooth,M.J.,等人,2012Science 336:934-937所述,其内容通过引用并入本文)。氧化试剂过钌酸钾将5-hmC转化为5-甲酰胞嘧啶(5-fC),并且后续的重亚硫酸钠处理使5-fC脱氨基以生成尿嘧啶。5-mC保持不变,因此可以使用这种方法鉴定。
APOBEC-偶联表观遗传测序(ACE-seq)完全排除重亚硫酸盐转化,并依靠酶促转化以检测5-hmC(例如,如由Schutsky,E.K.,等人,Nat.Biotechnol.,2018年10月8日所述,其内容通过引用并入本文)。通过这种方法,T4-BGT使5-hmC糖基化为5-ghmC,这保护5-hmC免受载脂蛋白B mRNA编辑酶亚基3A(APOBEC3A)的脱氨基作用。胞嘧啶。5-mC通过APOBEC3A被脱氨基并测序为胸腺嘧啶。
在另一个实例中,无重亚硫酸盐的和碱基层面分辨率的测序方法,即TET辅助吡啶硼烷测序(TAPS),可以用于5-mC和5-hmC的检测。TAPS将5-mC和5-hmC向5-羧基胞嘧啶(5-caC)的10-11易位(TET)氧化与5-caC向二氢尿嘧啶(DHU)的吡啶硼烷还原结合在一起。后续的PCR将DHU转化为胸腺嘧啶,实现了5-mC和5-hmC的C向T的转换。TAPS以高敏感性和特异性直接检测修饰,而不会影响未修饰的胞嘧啶(例如,如由Liu,Y.等人Nat Biotechnol.2019年4月;37(4):424-429所述,其内容通过引用并入本文)。
TET辅助的5-甲基胞嘧啶测序(TAmC-seq)富集了5-mC基因座,并利用两个连续酶促反应,然后进行亲和力下拉(Zhang,L.2013,Nat Commun 4:1517)。用T4-BGT处理片段化的DNA,从而通过糖基化保护5-hmC。然后使用mTET1酶将5-mC氧化为5-hmC,并使用修饰的葡萄糖部分(6-N3-葡萄糖),用T4-BGT标记新形成的5-hmC。点击化学可以用于引入生物素标签,实现了含有5-mC的DNA片段的富集,以供检测和全基因组谱分析。
B.下一代测序
在一些实施方案中,通过下一代测序(NGS)进行测序读取的生成。NGS可以允许为给定区域实现高读取深度。此类高通量方法包括例如Illumina(Solexa)测序、DNB-测序仪T7或G400(MGI Tech Co.,Ltd)、GenapSys测序(GenapSys,Inc.)、Roche 454测序(RocheSequencing Solutions,Inc.)、Ion Torrent测序(Thermo Fisher Scientific)和SOLiD测序(Thermo Fisher Scientific)。测序读取的数量可以根据DNA输入量和分析所需数据的深度进行调整。
在一些实施方案中,对从多个患者中获得的样品同时进行测序读取的生成,其中对每个患者的无细胞核酸片段标注条形码。测序读取的同时生成允许在一次测序运行中对多个患者进行并行分析。
另一方面,本公开提供了一种用于检测肿瘤的试剂盒,其包括用于进行上述方法的试剂和用于检测肿瘤信号的说明书。试剂可以包括例如引物集、PCR反应组分和/或测序试剂。
C.靶向测序
在靶向甲基化测序方法中,为了确定靶基因序列的甲基化状态,可以对生物样品(诸如cfDNA)中的靶向区域进行分析。在一些实施方案中,靶区域包括目标靶区域(诸如目标靶区域的至少约16个相邻核苷酸)的相邻核苷酸,或在严格条件下与之杂交。在不同的实例中,可以使用杂交捕获和扩增子测序方法来实现靶向测序。
D.杂交捕获
本文提供的杂交方法可以用于各种形式的核酸杂交,诸如溶液内杂交和诸如固体支撑体上的杂交(例如,膜、微阵列和细胞/组织载玻片上的RNA、DNA和原位杂交)。具体来说,所述方法适用于溶液内杂交捕获,以供下一代靶向测序中使用的某些类型的基因组DNA序列(例如外显子)的靶标富集。对于杂交捕获方法,无细胞核酸样品可以经历文库制备。如本文所用,“文库制备”包括末端修复、加A尾、衔接子连接或对无细胞DNA进行的任何其他制备,以允许后续的DNA测序。在某些实例中,所制备的无细胞核酸文库序列含有连接到无细胞核酸样品分子上的衔接子、序列标签或索引条形码。各种商购获得的试剂盒可以用于帮助文库制备以供下一代测序方法。下一代测序文库的构建可以包括使用一系列协调的酶促反应来制备核酸靶标,以产生特定大小的随机DNA片段集合,用于高通量测序。各种文库制备技术的进步和发展扩大了下一代测序在诸如转录组学和表观遗传学的领域中的应用。
测序技术的改进带来了文库制备的变化和改进。由诸如Agilent、BiooScientific、Kapa Biosystems、New England Biolabs、Illumina、Life Technologies、Pacific Biosciences和Roche的公司开发的下一代测序文库制备试剂盒为各种分子生物学反应提供了一致性和可重复性,确保与最新的NGS仪器技术兼容。
在靶向捕获基因小组的各个实例中,各种文库制备试剂盒可以选自Nextera Flex(Illumina)、IonAmpliseq(Thermo Fisher Scientific)、Genexus(Thermo FisherScientific)、Agilent ClearSeq(Illumina)、Agilent SureSelect Capture(Illumina)、Archer FusionPlex(Illumina)、BiooScientific NEXTflex(Illumina)、IDT xGen(Illumina)、Illumina TruSight(Illumina)、Nimblegene SeqCap(Illumina)和QiagenGeneRead(Illumina)。
在一些实施方案中,使用特异性探针对所制备的文库序列进行杂交捕获方法。在一些实施方案中,如本文所用的术语“特异性探针”一般是指对已知甲基化位点有特异性的探针。在一些实施方案中,特异性探针的设计是基于使用人基因组作为参考序列,并使用已知具有甲基化位点的特定基因组区域作为靶序列。具体地,已知有甲基化位点的基因组区域可以包括以下区域中的至少一个:启动子区、CpG岛区、CGI岸区和印迹基因区。因此,当使用一些实施方案的特异性探针进行杂交捕获时,可以有效地捕获与靶序列互补的样品基因组中的序列,例如,样品基因组中已知具有甲基化位点的区域(在本文中也称为“特定的基因组区域”)。
在一些实施方案中,本文所述的甲基化区域被用于设计特异性探针。在一些实施方案中,使用商购获得的方法(例如像eArray系统)设计特异性探针。探针的长度可以足以与目标甲基化区域以足够的特异性进行杂交。在各个实例中,探针是10聚体、11聚体、12聚体、13聚体、14聚体、15聚体、16聚体、17聚体、18聚体、19聚体或20聚体。
表1-17中列出的区域可以使用数据库资源(诸如基因本体论)来筛选。根据互补碱基配对的原理,单链捕获探针可以与单链靶序列互补组合,从而成功捕获靶区域。在一些实施方案中,所设计的探针可以被设计为固体捕获芯片(其中探针固定在固体支撑体上)或被设计为液体捕获芯片(其中探针在液体中是自由的),但受到以下各种因素的限制,诸如探针长度、探针密度和高成本等。固体捕获芯片很少使用,而液体捕获芯片使用较多。
在一些实施方案中,与正常序列(其中A、T、C、G碱基平均含量分别为25%)相比,核酸中富含GC的序列(其中GC碱基含量高于60%)可能会因C和G碱基的分子结构而导致捕获效率降低。对于重点研究区域,例如CGI区域(CpG岛),可以建议设计更多量的探针,以获得足够和准确的CGI数据。
E.基于扩增子的测序
转化的DNA片段可以被扩增。在一些实施方案中,用引物进行扩增,所述引物被设计成对其中具有至少一个甲基化位点的甲基化转化靶序列进行退火。甲基化测序转化导致非甲基化胞嘧啶转化为尿嘧啶,而5-甲基胞嘧啶不受影响。因此,“转化的靶序列”可以被理解为以下序列:其中已知为甲基化位点的胞嘧啶被固定为“C”(胞嘧啶),而已知非甲基化的胞嘧啶可以被固定为“U”(尿嘧啶;在引物设计时,可以将其视为“T”(胸腺嘧啶))。
在各个实例中,DNA的来源可以是来自全血、血浆、血清的无细胞DNA或从细胞或组织中提取的基因组DNA。在一些实施方案中,扩增的片段长度介于约100与200个碱基对之间。在一些实施方案中,DNA来源从细胞来源(例如,组织、活检或细胞系)中提取,并且扩增的片段长度介于约100与350个碱基对之间。在一些实施方案中,扩增片段包含至少一个20个碱基对序列,所述序列包含至少一个、至少两个、至少三个或多于三个CpG二核苷酸。扩增可以使用根据本公开的引物寡核苷酸集进行,并且可以使用热稳定聚合酶。若干DNA区段的扩增可以在同一个反应容器中同时进行。在所述方法的一些实施方案中,两个或更多个片段同时被扩增。例如,可以使用聚合酶链式反应(PCR)进行扩增。
被设计来靶向这些序列的引物可以对已转化的甲基化序列表现出一定程度的偏爱。在一些实施方案中,PCR引物可以被设计为甲基化特异性的,以供靶向甲基化测序应用,其在一些应用中可以实现更大的敏感性。例如,引物可以被设计以包含可鉴别核苷酸(在重亚硫酸盐转化后对甲基化序列有特异性),其被定位以(例如,在PCR应用中)实现最佳鉴别。鉴别体可以位于3'末端或倒数第二的位置处。
引物可以被设计为基于循环DNA的一般大小范围来扩增DNA片段。根据本实例,优化引物设计以考虑靶尺寸可以提高方法的敏感性。在一些实施方案中,引物被设计来扩增长度为75至350bp的DNA片段。引物可以被设计来扩增长度约50至200、约75至150或约100或125bp的区域。
在所述方法的一些实施方案中,可以使用甲基化特异性引物寡核苷酸,通过基于扩增子的方法检测核酸序列中预选CpG位置的甲基化状况。使用甲基化状况特异性引物扩增重亚硫酸盐处理的DNA可以允许区别甲基化与未甲基化核酸。MSP引物对可以含有至少一个与转化的CpG二核苷酸杂交的引物。因此,所述引物的序列可以包含至少一个CpG、TpG或CpA二核苷酸。对非甲基化DNA有特异性的MSP引物可以在CpG中C位置的3'位置处含有“T”。因此,所述引物的碱基序列可能需要包含长度为至少18个核苷酸的序列,所述序列与预处理的核酸序列及其互补序列杂交,其中所述寡聚物的碱基序列包含至少一个CpG、TpG或CpA二核苷酸。在所述方法的一些实施方案中,MSP引物包含2至5个CpG、TpG或CpA二核苷酸。在一些实施方案中,二核苷酸位于引物的3'半内,例如,其中引物的长度为18个碱基,指定的二核苷酸位于分子3'末端起的前9个碱基内。除了CpG、TpG或CpA二核苷酸外,引物还可以包含几个甲基转化碱基(例如,胞嘧啶转化为胸腺嘧啶,或在杂交链上,鸟嘌呤转化为腺苷)。在一些实施方案中,引物被设计成包含不多于2个胞嘧啶或鸟嘌呤碱基。
在一些实施方案中,每个区域使用多个引物对分区段进行扩增。在一些实施方案中,这些区段不重叠。这些区段可以直接相邻或间隔(例如,间隔可达10、20、30、40或50bp)。由于靶区域(包括CpG岛、CpG岸和/或CpG架)通常长于75至150bp,所以本实例可以允许评估跨越一个给定靶区域的更多(或全部)位点的甲基化状况。
可以使用合适的工具,诸如Primer3、Primer3Plus、Primer-BLAST等为靶区域设计引物。如所讨论的,重亚硫酸盐转化导致胞嘧啶转化为尿嘧啶,并且5'-甲基-胞嘧啶转化为胸腺嘧啶。因此,引物定位或靶向可以利用重亚硫酸盐转化的甲基化序列,这取决于所需的甲基化特异性程度。
扩增的靶区域可以被设计为具有至少10个CpG二核苷酸甲基化位点。然而,在一些实例中,扩增具有多于10个CpG甲基化位点的区域可以是有利的。例如,300bp长的序列读取可以具有约10、20、30、40或50个CpG甲基化位点,所述位点在与细胞增殖性病症相关联的核酸样品中被甲基化。在各个实例中,表1-17中鉴定的甲基化区域可以具有25、50、100、200、300、400或500个CpG甲基化位点,所述位点在与细胞增殖性病症相关联的核酸样品中被甲基化。在一些实施方案中,引物被设计来扩增在靶向区域中包含3至20个CpG甲基化位点的DNA片段。总的来说,这种方法可以允许在单次测序读取中查询更多的甲基化位点,并且可以提供额外的确定性(排除假阳性),因为在单次测序读取中可能检测到多个一致的甲基化。在一些实施方案中,肿瘤信号包含选自表1-17的多于两个甲基化区域。在本实例中,检测多重肿瘤信号可以提高肿瘤检测的置信度。这类信号可以在同一位点或在不同位点。在一些实施方案中,在同一区域处多于一个肿瘤信号的检测指示肿瘤。
在一些实施方案中,可以在两个具有不同细胞增殖性病症特点的群体之间对已鉴定的甲基化区域中的CpG位点数量建模,以鉴定甲基化阈值,其中一个区域中的CpG位点数量超过阈值指示细胞增殖性病症。
在各个实例中,在已鉴定的甲基化区域中指示癌症的CpG位点数量为4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个或18个,其中甲基化CpG的存在如果超过此鉴定的数量,则指示癌症,并可以用作机器学习模型的输入特征,所述模型用作将群体分层为健康个体和癌症个体的分类器。
在本实例中,对指示基因组中同一位点处的甲基化的多重肿瘤信号的检测可以提高肿瘤检测的置信度。检测基因组中相邻位点的甲基化也可以提高肿瘤检测的置信度,即使信号衍生自不同的测序读取也是如此。检测基因组中相邻位点的甲基化反映了另一种类型的信号一致性。在一些实施方案中,在至少两个不同的测序读取中相邻或重叠的肿瘤信号的检测指示肿瘤。在一些实施方案中,相邻或重叠的肿瘤信号在同一CpG岛内。在一些实施方案中,在无细胞DNA片段中3至34个近端甲基化位点的检测指示肿瘤。在一些实施方案中,在片段中3至34个甲基化CpG位点的检测被用于鉴定阈值,以区分具有某种特点(例如,健康、疾病或疾病分期)的个体群体。在一些实施方案中,读取片段中约4至10个、约4至15个、约10至20个、约15至20个、约15至25个、约20至25个、约20至34个、约25至34个、或约30至34个甲基化近端CpG位点的检测被用于确定阈值,以区分具有某种特点(例如健康、疾病或疾病分期)的个体群体。如本文所用,术语“近端CpG位点”是指无细胞核酸样品中同一核酸片段上的CpG位点相邻或在2至10个CpG位点之间的CpG位点。
在一些实施方案中,使用多于100个引物对进行扩增。扩增可以使用约10个、约20个、约30个、约40个、约50个、约60个、约70个、约80个、约90个、约100个、约110个、约120个、约130个、约140个、约150个或更多个引物对进行。在一些实施方案中,扩增是复合扩增。复合扩增允许从基因组的许多靶区域并行地收集大量甲基化信息,即使是从DNA通常不丰富的cfDNA样品中也可以。复合可以扩展到一个平台,诸如ION AmpliSeq,其中可以同时查询多达约24,000个扩增子。在一些实施方案中,扩增是巢式扩增。巢式扩增可提高敏感性和特异性。
此外,另一种用于并行检查多个甲基化序列的快速和稳健的方案被称为同步靶向甲基化测序(sTM-Seq)。此项技术的主要特点包括消除了对大量高分子量DNA的需求,以及5-甲基胞嘧啶(5-mC)与5-羟甲基胞嘧啶(5-hmC)的核苷酸特异性区分。此外,sTM-Seq可以是可扩展的并且可以用于在一次测序运行中调查几十个样品中的多个基因座。免费可用的基于web的软件和用于多用途条形码、文库制备和定制测序的通用引物使sTM-Seq经济实惠、高效且广泛适用。(如由Asmus,N.等人,Curr Protoc Hum Genet.2019年4月;101(1)所述,其内容通过引用并入本文)。
一般来说,本文提供的方法和系统对于制备下游应用测序反应的无细胞多核苷酸序列可以是有用的。在一些实施方案中,测序方法是经典桑格测序。测序方法可以包括但不限于:高通量测序、焦磷酸测序、合成测序、单分子测序、纳米孔测序、半导体测序、连接法测序、杂交测序、RNA-Seq(Illumina)、Digital Gene Expression(Helicos)、下一代测序、单分子合成测序(SMSS)(Helicos)、大规模平行测序、Clonal Single Molecule Array(Solexa)、鸟枪法测序、Maxim-Gilbert测序、引物步移和任何其他测序方法。
焦磷酸测序是一种基于核苷酸掺入后焦磷酸释放的光度检测的实时测序技术,适用于同时分析和定量若干个CpG位置的甲基化程度。在基因组DNA转化之后,可以用聚合酶链式反应(PCR)扩增目标区域,其中两个引物中的一个被生物素化。PCR生成的模板可以呈现为单链,并且焦磷酸测序引物被退火以定量分析CpG位置。在重亚硫酸盐处理和PCR之后,序列中每个CpG位置上的每个甲基化程度可以是由T与C信号的比率决定的,反映了原始序列中每个CpG位点上未甲基化与甲基化胞嘧啶的比例。
V.分类器、机器学习模型和系统
在各个实例中,甲基化测序特征可以被用作经训练的算法(例如,机器学习模型或分类器)的输入数据集,以鉴定序列组成与患者分组之间的相关性。此类患者分组的实例包括疾病或病状的存在、分期、亚型、应答者与无应答者、以及进展者与无进展者。在各个实例中,可以生成特征矩阵以比较从具有已知条件或特点的个体中获得的样品。在一些实施方案中,样品可以从健康个体或不具有任何已知适应症的个体中获得并且样品从已知患有癌症的患者中获得。
如本文所用,关于机器学习和模式识别,术语“特征”一般是指被观察现象的单个可测量的特性或特点。“特征”的概念可以与统计技术中使用的解释变量的概念有关,例如像但不限于线性回归和逻辑回归。特征可以是数字的,但在语法模式识别中可以使用结构特征,诸如字符串和图。
如本文所用,术语“输入特征”(或“特征”)一般是指被经训练的算法(例如,模型或分类器)用来预测样品的输出分类(标签)的变量,例如条件、序列内容(例如,突变)、建议的数据收集操作或建议的处理。变量的值可以确定为一个样品,并用于确定分类。
在各个实例中,遗传数据的输入特征可以包括:比对变量,其与序列数据(例如,序列读取)同基因组的比对相关,和非比对变量,例如与序列读取的序列内容、蛋白质或自身抗体的测量或基因组区域的平均甲基化水平相关。输入特征可以是遗传特征,诸如染色质可及性(例如,转录因子结合特征)、核小体定位特征(例如,转录起始位点上的V图测量和cfDNA测量)或细胞类型去卷积(例如,FREE-C去卷积)。甲基化分析中可以使用的指标包括但不限于:CpG、CHG、CHH的逐个碱基甲基化百分比,转化效率(CHH的100-平均甲基化百分比),低甲基化段,甲基化水平(CPG、CHH、CHG的整体平均甲基化,片段长度,片段中点),每个片段的甲基化CpG的数量,每个片段的CpG甲基化占总CpG的分率,每个区域的CpG甲基化占总CpG的分率,小组中CpG甲基化占总CpG的分率,二核苷酸覆盖度(归一化的二核苷酸覆盖度),覆盖度的均匀度(在lx和10x平均基因组覆盖下的独特CpG位点(对于S4运行)),整体平均CpG覆盖度(深度),以及在CpG岛、CGI架或CGI岸处的平均覆盖度。这些指标可以用作机器学习方法和模型的特征输入。
对于多个测定,系统可以鉴定特征集以使用经训练的算法(例如,机器学习模型或分类器)进行分析。系统可以对每一个分子类别进行测定,并从测量值形成特征向量。系统可以使用机器学习模型分析特征向量,并获得生物样品是否具有指定特性的输出分类。
在一些实施方案中,机器学习模型输出一个分类器,所述分类器能够区分个体的两个或更多个分组或类别或个体群体中的特征或群体的特征。在一些实施方案中,分类器是经训练的机器学习分类器。
在一些实施方案中,对癌症组织中生物标志物的信息基因座或特征进行测定,以形成图谱。受试者工作特征(ROC)曲线可通过绘制特定特征(例如,本文所述的任何生物标志物和/或任何额外生物医学信息项)在区分两个群体(例如,对治疗剂有应答的个体和无应答的个体)时的表现来生成。在一些实施方案中,跨整个群体(例如,病例和对照)的特征数据是基于单个特征值按升序排序的。
在各个实例中,指定的特性选自健康与癌症、疾病亚型、疾病分期、进展者与非进展者、以及应答者与非应答者。
A.数据分析
在一些实例中,本公开提供了一种系统、方法或试剂盒,其中数据分析可以在软件应用、计算硬件或这两者中实现。在各个实例中,分析应用或系统包括至少一个数据接收模块、一个数据预处理模块、一个数据分析模块(其可以对一种或多种类型的基因组数据进行操作)、一个数据解释模块或一个数据可视化模块。在一些实施方案中,数据接收模块可以包括将实验室硬件或仪器与处理实验室数据的计算机系统连接起来的计算机系统。在一些实施方案中,数据预处理模块包括硬件系统或计算机软件,其对数据进行操作,以备分析。可以应用于预处理模块中的数据的操作的实例包括仿射转换、去噪操作、数据清理、重新格式化或子采样。数据分析模块可以专门用于分析来自一个或多个基因组材料的基因组数据,例如,可以对组装的基因组序列进行概率和统计分析,以鉴定与疾病、病理、状态、风险、条件或表型相关的异常模式。数据解释模块可以使用分析方法,例如,从统计学、数学或生物学中提取的分析方法,以支持理解已鉴定的异常模式与健康状况、功能状态、预后或风险之间的关系。数据可视化模块可以使用数学建模、计算机图形学或渲染的方法来创建数据的可视化展现,所述可视化展现可以促进对结果的理解或解释。
在各个实例中,可以应用机器学习方法来区分样品群体中的样品。在一些实施方案中,应用机器学习方法来区分健康与晚期疾病(例如腺瘤)样品。
在一些实施方案中,用于训练预测引擎的一个或多个机器学习操作选自以下:广义线性模型、广义加性模型、非参数回归运算、随机森林分类器、空间回归运算、贝叶斯回归模型、时间序列分析、贝叶斯网络、高斯网络、决策树学习操作、人工神经网络、循环神经网络、卷积神经网络、强化学习操作、线性或非线性回归操作、支持向量机、聚类操作和遗传算法操作。
在各个实例中,计算机处理方法选自逻辑回归、多元线性回归(MLR)、降维、偏最小二乘(PLS)回归、主成分回归、自编码器、变分自编码器、奇异值分解、傅立叶基、小波、判别分析、支持向量机、决策树、分类和回归树(CART)、基于树的方法、随机森林、梯度推进树、逻辑回归、矩阵分解、多维标度(MDS)、降维方法、t-分布随机邻域嵌入(t-SNE)、多层感知器(MLP)、网络聚类、神经模糊和人工神经网络。
在一些实例中,本文公开的方法可以包括对来自个体或多个个体的样品的核酸测序数据的计算分析。
B.分类器生成
一方面,所公开的系统和方法提供了一种分类器,它是基于从cfDNA生物样品甲基化序列分析衍生的特征信息生成的。分类器可以形成预测引擎的一部分,用于基于生物样品(诸如cfDNA)中鉴定的序列特征在群体中区分各组。
在一些实施方案中,通过以下步骤来创建分类器:通过将序列信息的相似部分格式化为统一的格式和统一的规模来对序列信息进行归一化;将归一化的序列信息存储在柱状数据库中;通过对存储的归一化序列信息应用一个或多个机器学习操作,预测引擎针对特定群体映射一个或多个特征的组合,来训练预测引擎;将预测引擎应用于所访问的字段信息,以鉴定与分组相关联的个体;以及将个体划分到分组中。
在一些实施方案中,通过以下步骤来创建层次结构:通过将序列信息的相似部分格式化为统一的格式和统一的规模来对序列信息进行归一化;将归一化的序列信息存储在柱状数据库中;通过对存储的归一化序列信息应用一个或多个机器学习操作,预测引擎针对特定群体映射一个或多个特征的组合,来训练预测引擎;将预测引擎应用于所访问的字段信息,以鉴定与分组相关联的个体;以及将个体划分到分组中。
如本文所用,特异性一般是指“在没有患病的个体中,测试结果为阴性的概率”。特异性可以用测试结果为阴性的无病人数除以无病个体的总数来计算。
在各个实例中,模型、分类器或预测测试具有以下特异性:至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少99%。
如本文所用,敏感性一般是指“在患病的个体中,测试结果为阳性的概率”。敏感性可以用测试结果为阳性的患病个体数量除以患病个体的总数来计算。
在各个实例中,模型、分类器或预测测试具有以下敏感性:至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%或至少99%。
C.数字处理装置
在一些实例中,本文所述的主题可以包括数字处理装置或其用途。在一些实例中,数字处理装置可以包括一个或多个执行装置功能的硬件中央处理单元(CPU)、图形处理单元(GPU)或张量处理单元(TPU)。在一些实例中,数字处理装置可以包括被配置来执行可执行指令的操作系统。
在一些实例中,数字处理装置可以任选地连接计算机网络。在一些实例中,数字处理装置可以任选地连接到互联网。在一些实例中,数字处理装置可以任选地连接到云计算设施。在一些实例中,数字处理装置可以任选地连接到内联网。在一些实例中,数字处理装置可以任选地连接到数据存储装置。
合适的数字处理装置的非限制性实例包括服务器计算机、台式计算机、笔记本计算机、笔记本计算机、子笔记本计算机、上网本计算机、上网板计算机、机顶盒计算机、手持计算机、互联网电器、移动智能手机和平板计算机。合适的平板计算机可以包括例如具有小册子、笔记板和可转换配置的那些。
在一些实例中,数字处理装置可以包括被配置来执行可执行指令的操作系统。例如,操作系统可以包括软件,包括程序和数据,用于管理装置的硬件并为应用的执行提供服务。操作系统的非限制性实例包括Ubuntu、FreeBSD、OpenBSD、
在一些实例中,装置可以包括存储和/或存储器装置。存储和/或存储器装置可以是用于临时或永久地存储数据或程序的一个或多个物理设备。在一些实例中,装置可以是易失性存储器,并且需要电力来维持存储的信息。在一些实例中,装置是非易失性存储器,并且在数字处理装置不通电时保留所存储的信息。在一些实例中,非易失性存储器可以包括闪速存储器。在一些实例中,非易失性存储器可以包括动态随机存取存储器(DRAM)。在一些实例中,非易失性存储器可以包括铁电随机存取存储器(FRAM)。在一些实例中,非易失性存储器可以包括相变随机存取存储器(PRAM)。
在一些实例中,装置可以是存储装置,包括例如CD-ROM、DVD、闪速存储器装置、磁盘驱动器、磁带驱动器、光盘驱动器和基于云计算的存储。在一些实例中,存储和/或存储器装置可以是诸如本文公开的那些装置的组合。在一些实例中,数字处理装置可以包括向用户发送视觉信息的显示器。在一些实例中,显示器可以是阴极射线管(CRT)。在一些实例中,显示器可以是液晶显示器(LCD)。在一些实例中,显示器可以是薄膜晶体管液晶显示器(TFT-LCD)。在一些实例中,显示器可以是有机发光二极管(OLED)显示器。在一些实例中,OLED显示器可以是无源矩阵OLED(PMOLED)或有源矩阵OLED(AMOLED)显示器。在一些实例中,显示器可以是等离子体显示器。在一些实例中,显示器可以是视频投影仪。在一些实例中,显示器可以是诸如本文公开的那些装置的组合。
在一些实例中,数字处理装置可以包括从用户接收信息的输入装置。在一些实例中,输入装置可以是键盘。在一些实例中,输入装置可以是定点装置,包括例如鼠标、轨迹球、轨迹板、操纵杆、游戏控制器或触控笔。在一些实例中,输入装置可以是触摸屏或多点触摸屏。在一些实例中,输入装置可以是麦克风,用于捕获语音或其他声音输入。在一些实例中,输入装置可以是摄像机,用于捕捉运动或视觉输入。在一些实例中,输入装置可以是诸如本文公开的那些的装置的组合。
D.非临时计算机可读存储介质
在一些实例中,本文公开的主题可以包括一种或多种非临时计算机可读存储介质,所述存储介质用包含可由任选的网络数字处理装置的操作系统可执行的指令的程序编码。在一些实例中,计算机可读存储介质可以是数字处理装置的有形组件。在一些实例中,计算机可读存储介质可以任选地是可从数字处理装置移除的。在一些实例中,计算机可读存储介质可以包括例如CD-ROM、DVD、闪速存储器装置、固态存储器、磁盘驱动器、磁带驱动器、光盘驱动器、云计算系统和服务等。在一些实例中,程序和指令可以永久地、大体上永久地、半永久地或非临时性地编码在介质上。
E.计算机系统
本公开提供了被编程以实现本文所述的方法的计算机系统。图1示出了计算机系统101,它可以被编程或以其他方式配置以存储、处理、鉴定或解释患者数据、生物数据、生物序列和参考序列。计算机系统101可以处理本公开的患者数据、生物数据、生物序列或参考序列的各个方面(图1)。计算机系统101可以是用户的电子装置或位于电子装置远端的计算机系统。电子装置可以是移动电子装置。
计算机系统101可以包括中央处理单元(CPU,本文也称为“处理器”和“计算机处理器”)105,其可以是单核或多核处理器,或者用于并行处理的多个处理器。计算机系统101还可以包括存储器或存储位置110(例如,随机存取存储器、只读存储器、闪速存储器)、电子存储单元115(例如,硬盘)、用于与一个或多个其他系统通信的通信接口120(例如,网络适配器)以及外围装置125,诸如高速缓存、其他存储器、数据存储和/或电子显示适配器。存储器110、存储单元115、接口120和外围装置125可以通过通信总线(实线)(诸如主板)与CPU 105通信。存储单元115可以是用于存储数据的数据存储单元(或数据储存库)。借助于通信接口120,计算机系统101可以可操作地耦合到计算机网络(“网络”)130。网络130可以是因特网、互联网和/或外联网,或者与因特网通信的内联网和/或外联网。在一些实例中,网络130可以是电信和/或数据网络。网络130可以包括一个或多个计算机服务器,其可以实现分布式计算,诸如云计算。在一些实例中,借助于计算机系统101,网络130可以实现点对点网络,这可以使耦合到计算机系统101的装置表现为客户端或服务器。
CPU 105可以执行一系列机器可读的指令,所述指令可以体现在程序或软件中。指令可以存储在存储器位置(诸如存储器110)中。指令可以被引导到CPU 105,其可以随后编程或以其他方式配置CPU 105以实施本公开的方法。由CPU 105进行的操作的实例可以包括提取、解码、执行和写回。
CPU 105可以是电路(诸如集成电路)的一部分。系统101的一个或多个其他组件可以包括在电路中。在一些实例中,电路可以是专用集成电路(ASIC)。
存储单元115可以存储文件,诸如驱动程序、库和保存的程序。存储单元115可以存储用户数据,例如,用户偏好和用户程序。在一些实例中,计算机系统101可以包括可以在计算机系统101外部的一个或多个额外数据存储单元,诸如位于通过内联网或互联网与计算机系统101通信的远程服务器上。
计算机系统101可以通过网络130与一个或多个远程计算机系统通信。例如,计算机系统101可以与用户的远程计算机系统通信。远程计算机系统的实例包括个人计算机(例如,便携式PC)、平板(slate/tablet)PC(例如,
如本文所述的方法可以通过存储在计算机系统101的电子存储位置上(例如像,存储在存储器110或电子存储单元115上)的机器(例如,计算机处理器)可执行代码来实现。可以用软件的形式提供机器可执行或机器可读代码。在使用期间,代码可以由处理器105执行。在一些实例中,代码可以从存储单元115中取回并存储在存储器110上以供处理器105访问。在一些实例中,可以排除电子存储单元115,而将机器可执行指令存储在存储器110上。
代码可以被预编译和配置成与具有适于执行代码的处理器的机器一起使用,或者可以在运行时解释或编译。可以用编程语言提供代码,可以选择所述编程语言以使代码能够以预编译、解释或所编译的方式执行。
本文提供的系统和方法的方面,诸如计算机系统101,可以在编程中体现。所述技术的各个方面可以被认为是“产品”或“制品”,例如是机器(或处理器)可执行代码和/或相关数据的形式,其被承载或包含在一种类型的机器可读介质中。机器可执行代码可以存储在电子存储单元诸如存储器(例如,只读存储器、随机存取存储器、闪速存储器)或硬盘上。“存储”类型的介质可以包括计算机、处理器等的任何或所有有形存储器或其相关模块,诸如各种半导体存储器、磁带驱动器、磁盘驱动器等,它们可以在任何时候为软件编程提供非临时性存储。软件的全部或部分有时可以通过互联网或各种其他电信网络进行通信。例如,此类通信可以使得能够将软件从一台计算机或处理器加载到另一台计算机或处理器中,例如,从管理服务器或主计算机加载到应用服务器的计算机平台中。因此,可以承载软件元素的另一种类型的介质包括光、电和电磁波,诸如通过有线和光学陆线网络以及各种空中链路在本地装置之间的物理接口上使用的。携带此类波的物理元件,诸如有线或无线链路、光链路等,也可以被认为是承载软件的介质。如本文所用,除非限于非临时性的、有形的“存储”介质,否则诸如计算机或机器“可读介质”的术语可以是指参与向处理器提供指令以供执行的任何介质。
因此,机器可读介质(诸如计算机可执行代码)可以采取许多形式,包括但不限于有形存储介质、载波介质或物理传输介质。非易失性存储介质包括例如,光盘或磁盘,如任何一个或多个计算机等中的任何存储装置,诸如可以用于实现附图中所示的数据库等。易失性存储介质包括动态存储器,诸如这种计算机平台的主存储器。有形传输介质可以包括同轴电缆;铜线和光纤,包括构成计算机系统内总线的电线。载波传输介质可以采取电信号或电磁信号的形式,或者声波或光波的形式,如在射频(RF)和红外(IR)数据通信期间产生的那些声波或光波。因此,计算机可读介质的常见形式包括例如:软盘、软磁盘、硬盘、磁带、任何其他磁介质、CD-ROM、DVD或DVD-ROM、任何其他光学介质、穿孔卡片纸带、具有孔图案的任何其他物理存储介质、RAM、ROM、PROM和EPROM、FLASH-EPROM、任何其他存储芯片或盒式磁带、传输数据或指令的载波、传输这种载波的电缆或链路,或者计算机可以从中读取编程代码和/或数据的任何其他介质。这些形式的计算机可读介质中的许多可以涉及将一个或多个指令的一个或多个序列传送到处理器以供执行。
计算机系统101可以包括电子显示器135或与电子显示器135通信,所述电子显示器包括用户界面(UI)140,以用于提供例如核酸序列、浓缩核酸样品、甲基化谱、表达谱、以及甲基化或表达谱的分析。UI的实例可以包括但不限于图形用户界面(GUI)和基于网络的用户界面。
本公开的方法和系统可以通过一种或多种算法来实现。算法可以在由中央处理单元105执行时通过软件来实现。例如,算法可以存储、处理、鉴定或解释患者数据、生物数据、生物序列和参考序列。
虽然本文已经示出和描述了方法和系统的某些实例,但技术人员会意识到这些仅以举例的方式提供,并且不打算在说明书中加以限制。在不背离本文所述的范围的情况下,本领域技术人员现将会想到许多变型、改变和替代。此外,应理解所述方法和系统的所有方面不限于本文所列举的具体描述、配置或相对比例,这些描述取决于多种条件和变量,并且描述旨在包括此类替代方案、修改、变型或等价物。
在一些实例中,本文公开的主题可以包括至少一个计算机程序或其用途。计算机程序可以是在数字处理装置的CPU、GPU或TPU中执行、被编写以执行指定任务的指令序列。计算机可读指令可被实现为执行特定任务或实现特定抽象数据类型的程序模块,诸如函数、对象、应用编程接口(API)、数据结构等。鉴于本文提供的公开内容,计算机程序能够以各种版本的各种语言编写。
在各种环境中,可以根据需要对计算机可读指令的功能进行组合或分配。在一些实例中,计算机程序可以包括一个指令序列。在一些实例中,计算机程序可以包括多个指令序列。在一些实例中,计算机程序可以由一个位置提供。在一些实例中,计算机程序可以由多个位置提供。在一些实例中,计算机程序可以包括一个或多个软件模块。在一些实例中,计算机程序可以部分或整体地包括一个或多个网络应用、一个或多个移动应用、一个或多个独立应用、一个或多个网络浏览器插件、扩展项、加载项或附加项、或其组合。
在一些实例中,计算机处理可以是统计学、数学、生物学或其任何组合的方法。在一些实例中,计算机处理方法包括降维方法,例如,包括逻辑回归、降维、主成分分析、自编码器、奇异值分解、傅立叶基、奇异值分解、小波、判别分析、支持向量机、基于树的方法、随机森林、梯度推进树、逻辑回归、矩阵分解、网络聚类和神经网络,诸如卷积神经网络。
在一些实例中,计算机处理方法可以是有监督的机器学习方法,包括例如回归、支持向量机、基于树的方法和网络。
在一些实例中,计算机处理方法可以是无监督的机器学习方法,包括例如聚类、网络、主成分分析和矩阵分解。
F.数据库
在一些实例中,本文公开的主题可以包括一个或多个数据库,或使用所述数据库存储患者数据、生物数据、生物序列或参考序列的用途。参考序列可以从数据库中衍生。鉴于本文提供的公开内容,许多数据库可适用于存储和检索序列信息。在一些实例中,合适的数据库可以包括例如关系数据库、非关系数据库、面向对象的数据库、对象数据库、实体-关系模型数据库、关联数据库以及XML数据库。在一些实例中,数据库可以是基于互联网的。在一些实例中,数据库可以是基于网络的。在一些实例中,数据库可以是基于云计算的。在一些实例中,数据库可以是基于一个或多个本地计算机存储装置的。
一方面,本公开提供了一种非临时的计算机可读介质,其包括指示处理器执行本文所述的方法的指令。
一方面,本公开提供了一种包括计算机可读介质的计算装置。
另一方面,本公开提供了一种用于对生物样品进行分类的系统,其包括:
a)接收多个训练样品的接收器,所述多个训练样品中的每个具有多个类别的分子,其中所述多个训练样品中的每个包含一个或多个已知标记;
b)特征模块,用于鉴定与测定相对应的可操作的特征集,以便对于所述多个训练样品中的每个使用机器学习模型进行分析,其中所述特征集与所述多个训练样品中的分子特性相对应,其中对于所述多个训练样品中的每个,所述系统可操作以使所述训练样品中的多个类别的分子进行多个不同的测定,以获得测量值集,其中每个测量值集都来自于对所述训练样品中的一类分子进行的一次测定,其中为所述多个训练样品获得多个测量值集;
c)分析模块,用于对所述测量值集进行分析,以获得所述训练样品的训练向量,其中所述训练向量包括相应测定的N个特征集的特征值,每个特征值与一个特征相对应并包括一个或多个测量值,其中所述训练向量使用来自与所述多个不同测定的第一子集相对应的所述N个特征集中的至少两个的至少一个特征而形成;
d)标记模块,用于使用所述机器学习模型的参数通知所述系统关于所述训练向量的信息,以便为所述多个训练样品获得输出标记;
e)比较器模块,用于将所述输出标记与所述训练样品的已知标记相比较;
f)训练模块,用于基于将所述输出标记与所述训练样品的已知标记进行比较迭代搜索所述参数的最优值作为训练所述机器学习模型的一部分;以及
g)输出模块,用于提供所述机器学习模型的参数和所述机器学习模型的特征集。
VI.对群体中的对象进行分类的方法
所公开的方法旨在通过对象中的cfDNA分析,确定与细胞增殖性病症相关联的基因组DNA的遗传和/或表观遗传参数。所述方法可以用于改善细胞增殖性病症的诊断、治疗和监测,更具体地说,是通过改善所述病症的分期或亚类与所述病症的遗传易感性之间的鉴定和区分。
在一些实施方案中,所述方法包括分析CpG岛、CpG岸或CpG架的甲基化状况。
在一些实施方案中,所述方法包括分析生物样品中无细胞核酸的甲基化状态、半甲基化状况、高甲基化状态或低甲基化状态。
一般来说,本公开提供了一种用于检测细胞增殖性病症的方法,其可以应用于无细胞样品,例如,以检测无细胞循环的细胞增殖性病症DNA。所述方法可以利用在单次测序读取中甲基化信号的检测作为基本的“阳性”细胞增殖性病症信号。
一方面,本公开提供了一种用于检测细胞增殖性病症的方法,其包括:从获自对象的无细胞样品中提取DNA,转化至少一部分所述DNA以供甲基测序,扩增癌症中由所述转化的DNA产生的甲基化区域,从所述扩增的区域生成测序读取,以及检测细胞增殖性病症信号,其包含至少一个、至少两个、至少三个或多于三个在癌症小组内的甲基化区域,以获得输入特征,所述输入特征可以使用机器学习模型进行分析,以获得能够鉴别两组对象(例如,健康与癌症、疾病分期、晚期腺瘤与癌症)的分类器。
本文所述的经训练的机器学习方法、模型和鉴别分类器可以应用于各种医疗应用,包括癌症检测、诊断和治疗应答性。由于模型可以用个体元数据和分析物衍生特征来训练,所以应用可以进行定制,以对群体中的个体进行分层,并相应地指导治疗决策。
诊断
本文提供的方法和系统可以使用基于人工智能的方法进行预测分析,以分析从对象(患者)获得的数据,从而生成对患癌对象的诊断输出。例如,所述应用可以对所获取的数据应用预测算法,以生成对患癌对象的诊断。预测算法可以包括基于人工智能的预测器,诸如基于机器学习的预测器,其被配置来处理所获取的数据,以生成对患癌对象的诊断。
机器学习预测器可以使用数据集来训练,例如,使用本文所述的特征小组对来自一个或多个患癌患者队列集的个体生物样品进行甲基化测定而生成的数据集作为输入,和对象的已知诊断(例如,分期和/或肿瘤分数)结局作为机器学习预测器的输出。
训练数据集(例如,使用本文所述的特征小组对个体生物样品进行甲基化测定而生成的数据集)可以从例如具有共同特点(特征)和结局(标记)的一个或多个对象集生成。训练数据集可以包括与诊断相关的特征相对应的特征和标记集。特征可以包括一些特点,例如像cfDNA测定测量的某些范围或类别,诸如从健康和疾病样品中获得的生物样品中重叠或落在参考基因组的箱(基因组窗口)集合中的cfDNA片段的计数。例如,在给定的时间点从给定的对象收集的特征集可以共同充当诊断特征,这可指示在给定的时间点对象患有已鉴定的癌症。特点还可以包括指示对象诊断结局(诸如一种或多种癌症)的标记。
标记可以包括结局,例如对象的已知诊断(例如,分期和/或肿瘤分数)结局。结局可以包括与对象的癌症相关联的特点。例如,特点可以指示对象患有一种或多种癌症。
训练集(例如,训练数据集)可以通过对与一个或多个对象集(例如,患有或未患有一种或多种癌症的回顾性和/或前瞻性患者队列)相对应的一个数据集的随机抽样来选择。可替代地,训练集(例如,训练数据集)可以通过对与一个或多个对象集(例如,患有或未患有一种或多种癌症的回顾性和/或前瞻性患者队列)相对应的一个数据集的比例抽样来选择。训练集可以在与一个或多个对象集(例如,来自不同临床地点或试验的患者)相对应的数据集之间进行平衡。可以对机器学习预测器进行训练,直到满足某些预定的准确性或性能条件,诸如具有与诊断准确性量度相对应的最小期望值。例如,诊断准确性量度可以与对对象的一种或多种癌症的诊断、分期或肿瘤分数的预测相对应。
诊断准确性量度的实例可以包括敏感性、特异性、阳性预测值(PPV)、阴性预测值(NPV)、准确性以及与检测或预测癌症的诊断准确性相对应的受试者工作特征(ROC)曲线的曲线下面积(AUC)。
一方面,本公开提供了一种使用能够区分个体群体的分类器的方法,其包括:
a)测定生物样品中多个类别的分子,其中所述测定提供代表所述多个类别的分子的多个测量值集;
b)鉴定与所述多个类别的分子中每个的特性相对应的特征集,以使用机器学习或统计模型进行分析;
c)从所述多个测量值集中的每个制备特征值的特征向量,每个特征值与所述特征集的一个特征相对应并包括一个或多个测量值,其中所述特征向量包括使用所述多个测量值集中的每个集获得的至少一个特征值;
d)将包括所述分类器的所述机器学习模型加载到计算机系统的存储器中,所述机器学习模型使用从以下项获得的训练向量来训练:训练生物样品、被鉴定为具有指定特性的所述训练生物样品的第一子集和被鉴定为不具有指定特性的所述训练生物样品的第二子集;以及
e)使用所述机器学习模型分析所述特征向量,以获得所述生物样品是否具有所述指定特性的输出分类,从而区分具有所述指定特性的个体群体。
一方面,本公开提供了一种使用能够区分个体群体的层次结构的方法,其包括:
a)测定生物样品中多个类别的分子,其中所述测定提供代表所述多个类别的分子的多个测量值集;
b)鉴定与所述多个类别的分子中每个的特性相对应的特征集,以使用机器学习或统计模型进行分析;
c)从所述多个测量值集中的每个制备特征值的特征向量,每个特征值与所述特征集的一个特征相对应并包括一个或多个测量值,其中所述特征向量包括使用所述多个测量值集中的每个集获得的至少一个特征值;
d)将包括所述分类器的经训练的机器学习模型加载到计算机系统的存储器中,所述经训练的机器学习模型使用从以下项获得的训练向量来训练:训练生物样品、被鉴定为具有指定特性的所述训练生物样品的第一子集和被鉴定为不具有指定特性的所述训练生物样品的第二子集;以及
e)将所述经训练的机器学习模型应用于所述特征向量,以获得所述生物样品是否具有所述指定特性的输出分类,从而区分具有所述指定特性的个体群体。
一方面,本公开提供了一种使用能够区分个体群体的层次结构的方法,其包括:
a)检测一个或多个第一患者样品中预选基因组区域的单个测序读取内的甲基化信号;
b)所述甲基化信号影响数据输出的层次结构,从而影响机器学习模型;以及
c)对第二患者样品使用所述受影响的层次结构来检测甲基化信号。
在一些实施方案中,所述特征小组包含三个或更多个表2-17中的甲基化基因组区域、四个或更多个表2-17中的甲基化基因组区域、五个或更多个表2-17中的甲基化基因组区域、六个或更多个表2-17中的甲基化基因组区域、七个或更多个表2-17中的甲基化基因组区域、八个或更多个表2-17中的甲基化基因组区域、九个或更多个表2-17中的甲基化基因组区域、十个或更多个表2-17中的甲基化基因组区域、十一个或更多个表2-17中的甲基化基因组区域、十二个或更多个表2-17中的甲基化基因组区域、或十三个或更多个表2-17中的甲基化基因组区域。
另一方面,本公开提供了一种用于鉴定对象的两种或更多种癌症的方法,其包括:
(a)提供包含来自所述对象的无细胞核酸(cfNA)分子的生物样品;
(b)对来自所述对象的所述cfNA分子进行甲基转化和测序,以生成多个cfNA测序读取;
(c)将所述多个cfNA测序读取与参考基因组比对;
(d)在所述参考基因组的第一多个基因组区域中的每个上生成所述多个cfNA测序读取的定量量度,从而生成第一cfNA特征集,其中所述参考基因组的所述第一多个基因组区域包含至少约10个不同的区域,所述至少约10个不同的区域中的每个包含选自本文所述的特征小组中的甲基化区域的基因的至少一部分;以及
(e)将经训练的算法应用于所述第一cfNA特征集,以生成所述对象患有所述癌症的可能性。
在一些实例中,所述至少约10个不同的区域包含至少约20个不同的区域,所述至少约20个不同的区域中的每个包含表1-17中鉴定的甲基化区域的至少一部分。在一些实例中,所述至少约10个不同的区域包含至少约30个不同的区域,所述至少约30个不同的区域中的每个包含表1-17中鉴定的甲基化区域的至少一部分。
作为另一个实例,这种预定的条件可以是包括以下值的预测结肠细胞增殖性病症的特异性:例如,至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%。
作为另一个实例,这种预定的条件可以是包括以下值的预测结肠细胞增殖性病症的阳性预测值(PPV):例如,至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%。
作为另一个实例,这种预定的条件可以是包括以下值的预测结肠细胞增殖性病症的阴性预测值(NPV):例如,至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%。
作为另一个实例,这种预定的条件可以是包括以下值的预测结肠细胞增殖性病症的受试者工作特征(ROC)曲线的曲线下面积(AUC):至少约0.50、至少约0.55、至少约0.60、至少约0.65、至少约0.70、至少约0.75、至少约0.80、至少约0.85、至少约0.90、至少约0.95、至少约0.96、至少约0.97、至少约0.98、或至少约0.99。
治疗应答性
本文所述的预测分类器、系统和方法可以用于对个体群体进行分类,以用于多种临床应用(例如,基于使用本文所述的特征小组对个体生物样品进行甲基化测定)。这类临床应用的实例包括:检测早期癌症、诊断癌症、将癌症分类为特定的疾病分期、以及确定对治疗癌症的治疗剂的应答性或耐药性。
本文所述的方法和系统可以应用于结肠细胞增殖性病症的特点,诸如分级和分期。因此,在本系统和方法中可以使用分析物与测定的组合来预测不同组织中不同癌症类型的癌症治疗剂的应答性,并基于治疗应答性对个体进行分类。在一些实施方案中,本文所述的分类器能够将一组个体分层为治疗应答者与非应答者。
本公开还提供了一种用于确定目标病状或疾病的药物靶标(例如,与特定类别相关或重要的基因)的方法,其包括:评估从个体获得的样品中至少一种基因的基因表达水平;以及使用邻域分析程序,确定与样品分类相关的基因,由此确定一个或多个与分类相关的药物靶标。
本公开还提供了一种用于确定被设计来治疗疾病类别的药物的功效的方法,其包括:从患有所述疾病类别的个体中获得样品;使所述样品经受所述药物的作用;评估经药物暴露的样品中至少一种基因的基因表达水平;以及使用加权投票方案建立的计算机模型,根据样品相对于模型的相对基因表达水平的函数,将经药物暴露的样品分类为一类疾病。
本公开还提供了一种用于确定被设计来治疗疾病类别的药物的功效的方法,其中个体已经受所述药物的作用,所述方法包括从经受所述药物的作用的个体中获得样品;评估样品中至少一种基因的基因表达水平;以及使用加权投票方案建立的模型,将所述样品分类为一类疾病,包括与模型的基因表达水平相比评价所述样品的基因表达水平。
本公开还提供了一种确定个体是否属于表型类别(例如,智力、对治疗的应答、寿命长短、病毒性感染或肥胖的可能性)的方法,其包括:从所述个体中获得样品;评估样品中至少一种基因的基因表达水平;以及使用加权投票方案建立的模型,将样品分类为一类疾病,包括与模型的基因表达水平相比评价样品的基因表达水平。
一方面,本文所述的与基于治疗应答性对群体分类相关的系统和方法是指使用DNA损伤剂、DNA修复靶向疗法、DNA损伤信号传导抑制剂、DNA损伤诱导细胞周期阻滞抑制剂和间接导致DNA损伤的过程抑制等类别但不限于这些类别的化疗剂治疗的癌症。这些化疗剂中的每一种都可以被认为是“DNA损伤治疗剂”,如本文使用的术语一样。
基于患者的分析物数据,可以将患者分类到高风险和低风险患者分组中,诸如临床复发风险高或低的患者,并且结果可以用于确定治疗过程。例如,被确定为高危患者的患者可以在手术后接受辅助化疗。对于被视为低危患者的患者,手术之后可以停止辅助化疗。因此,本公开在某些方面提供了一种制备指示复发风险的结肠癌肿瘤基因表达谱的方法。
在各个实例中,本文所述的分类器能够在对治疗有应答者与无应答者之间对个体群体进行分层。
另一方面,本文公开的方法可以应用于涉及癌症检测或监测的临床应用。
在一些实施方案中,本文公开的方法可以应用于确定和/或预测对治疗的应答。
在一些实施方案中,本文公开的方法可以应用于监测和/或预测肿瘤负荷。
在一些实施方案中,本文公开的方法可以应用于检测和/或预测术后残留肿瘤。
在一些实施方案中,本文公开的方法可以应用于检测和/或预测治疗后的微小残留疾病。
在一些实施方案中,本文公开的方法可以应用于检测和/或预测复发。
一方面,本文公开的方法可以用作二次筛查。
一方面,本文公开的方法可以用作初次筛查。
一方面,本文公开的方法可以应用于监测癌症发展。
一方面,本文公开的方法可以应用于监测和/或预测癌症风险。
VII.鉴定或监测癌症
在使用经训练的算法处理数据集之后,可以在对象中鉴定或监测至少两种癌症类型。所述鉴定可以至少部分基于癌症相关基因组基因座小组的数据集序列读取的定量量度(例如,癌症相关基因组基因座的RNA转录物或DNA的定量量度)。
在一个实施方案中,在对象中鉴定或监测2种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测3种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测4种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测5种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测6种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测7种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测8种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测9种或更多种癌症类型,在另一个实施方案中,在对象中鉴定或监测10种或更多种癌症类型。
可以以如下准确性在对象中鉴定癌症:至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或更大。由经训练的算法鉴定癌症的准确性可以计算为独立测试样品(例如,已知患有癌症的对象或癌症临床测试结果为阴性的对象)被正确鉴定或分类为患有或未患有癌症的百分比。
可以以如下阳性预测值(PPV)在对象中鉴定癌症:至少约5%、至少约10%、至少约15%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或更大。使用经训练的算法鉴定癌症的PPV可以计算为被鉴定或分类为具有癌症的无细胞生物样品与真正患有癌症的对象相对应的百分比。
可以以如下阴性预测值(NPV)在对象中鉴定癌症:至少约5%、至少约10%、至少约15%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或更大。使用经训练的算法鉴定癌症的NPV可以计算为被鉴定或分类为不具有癌症的无细胞生物样品与真正患有癌症的对象相对应的百分比。
可以以如下临床敏感性在对象中鉴定癌症:至少约5%、至少约10%、至少约15%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%、至少约99.1%、至少约99.2%、至少约99.3%、至少约99.4%、至少约99.5%、至少约99.6%、至少约99.7%、至少约99.8%、至少约99.9%、至少约99.99%、至少约99.999%或更大。使用经训练的算法鉴定癌症的临床敏感性可以计算为与存在癌症相关联的独立测试样品(例如,已知患有癌症的对象)被正确鉴定或分类为具有癌症的百分比。
可以以如下临床特异性在对象中鉴定癌症:至少约5%、至少约10%、至少约15%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%、至少约99.1%、至少约99.2%、至少约99.3%、至少约99.4%、至少约99.5%、至少约99.6%、至少约99.7%、至少约99.8%、至少约99.9%、至少约99.99%、至少约99.999%或更大。使用经训练的算法鉴定癌症的临床特异性可以计算为与不存在癌症相关联的独立测试样品(例如,癌症临床测试结果为阴性的对象)被正确鉴定或分类为不具有癌症的百分比。
在一些实施方案中,经训练的算法可以确定对象患癌症的风险为至少约5%、至少约10%、至少约15%、至少约20%、至少约25%、至少约30%、至少约35%、至少约40%、至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或更大。
经训练的算法可以确定对象有患癌症的风险,准确性为至少约50%、至少约55%、至少约60%、至少约65%、至少约70%、至少约75%、至少约80%、至少约81%、至少约82%、至少约83%、至少约84%、至少约85%、至少约86%、至少约87%、至少约88%、至少约89%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%、至少约99.1%、至少约99.2%、至少约99.3%、至少约99.4%、至少约99.5%、至少约99.6%、至少约99.7%、至少约99.8%、至少约99.9%、至少约99.99%、至少约99.999%或更大。
A.定制多癌症特征小组
在一些实施方案中,多癌症检测测定生物标志物小组包括针对在特征小组中和后续分析中测定的不同癌症类型选择的测试特点。在某些实施方案中,测试特点可以通过筛查目标和特征小组标志物选择来确定。例如,对于一线筛查测试,由于后续诊断性检查的益处和风险,一些癌症在临床上可接受的特异性下可能需要更高的敏感性,而其他癌症在临床上可接受的敏感性下可能需要非常高的特异性。此外,性能特点取决于所述测试是在公认的筛查方法之前、补充所述筛查方法还是遵循所述筛查方法,或者是否代表对无症状、平均风险或有症状的高风险个体中进行其他未筛查的癌症的新前线筛查。例如,导致“不必要的”结肠镜检查的结直肠癌(CRC)的假阳性筛查对患者的影响与导致“不必要的”腹部大手术以确认诊断的胰腺癌或卵巢癌的假阳性筛查明显不同。当与特征小组标志物选择相结合时,多癌症检测生物标志物小组可以提供针对可用的筛查目标、确认性测试和后续治疗定制的方法和系统。
表18总结了多癌症检测测试的筛查测试特点。一方面,提供了一种方法,其中多癌症小组被定制为基于表18所示的两种或多种癌症类型或其组合的癌症诊断和确认性诊断的需要,为待检测的癌症类型提供测试特点敏感性和特异性。
表18
/>
在一个实施方案中,多中心测试包括用于检测胰腺癌、子宫癌或卵巢癌的标志物,并且具有至少80%、至少85%、至少90%、至少95%、至少99%的特异性。
在一个实施方案中,多中心测试包括用于检测结直肠癌、肝癌、食管癌或膀胱癌的标志物,并且具有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%的敏感性。
在一个实施方案中,多中心测试包括用于检测乳腺癌、前列腺癌、肺癌或甲状腺癌的标志物,并且具有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%的特异性。
在将对象鉴定为患有癌症类型后,可以任选地为对象提供治疗性干预(例如,为对象开具治疗癌症的适当治疗过程)。治疗性干预可以包括开具有效剂量的药物、对癌症的进一步检查或评价、对癌症的进一步监测或其组合。如果对象目前正在以一个治疗过程接受癌症的治疗,则治疗性干预可以包括后续的不同治疗过程(例如,由于当前治疗过程无效而增加治疗功效)。
治疗性干预可以包括建议对象进行二次临床测试,以确认癌症的诊断。此二次临床测试可以包括影像学测试、血液测试、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
可以在一段时间上评估癌症相关基因组基因座小组上数据集序列读取的定量量度(例如,在结直肠癌相关基因组基因座上的RNA转录物或DNA的定量量度),以监测患者(例如,患有癌症或正在接受癌症治疗的对象)。在这种情况下,患者数据集的定量量度可在治疗过程中发生变化。例如,对因有效治疗而降低癌症风险的患者数据集的定量量度可以转向健康对象(例如,未患有癌症的对象)的图谱或分布。相反,例如,由于治疗无效而导致癌症风险增加的患者数据集的定量量度可以转向癌症风险更高或更晚期癌症的对象的图谱或分布。
通过对治疗对象的癌症的治疗过程的监测,可以监测对象的癌症。所述监测可以包括在两个或更多个时间点评估对象的癌症。所述评估可以至少基于在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度),包括在两个或更多个时间点中的每个上确定的癌症相关基因组基因座小组的定量量度。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示一个或多个临床指征,诸如:(i)对象的癌症诊断;(ii)对象的癌症预后;(iii)对象患癌症的风险增加;(iv)对象患癌症的风险降低;(v)治疗对象的癌症的治疗过程有效;以及(vi)治疗对象的癌症的治疗过程无效。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示对象的癌症的诊断。例如,如果对象在较早的时间点没有检测到癌症,但在较晚的时间点检测到,则差异指示对象的癌症的诊断。临床行动或决定可以基于对象的癌症诊断的这个指征作出,例如,为对象开具新的治疗性干预。临床行动或决定可以包括建议对象进行二次临床测试,以确认癌症的诊断。此二次临床测试可以包括影像学测试、血液测试、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示对象的癌症的预后。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示对象患癌症的风险增加。例如,如果对象在较早的时间点和较晚的时间点都检测到结直肠癌,且如果差异是正性差异(例如,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)从较早的时间点到较晚的时间点是增加的),则差异可以指示对象患癌症的风险增加。临床行动或决定可以基于癌症风险增加的这个指征作出,例如,为对象开具新的治疗性干预或转换治疗性干预(例如,结束当前治疗,并开具新的治疗)。临床行动或决定可以包括建议对象进行二次临床测试,以确认患癌症的风险增加。此二次临床测试可以包括影像学检查、血液检查、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在结直肠癌相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示对象患癌症的风险降低。例如,如果对象在较早的时间点和较晚的时间点都检测到癌症,且如果差异是负性差异(例如,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在结直肠癌相关基因组基因座上的RNA转录物或DNA的定量量度),包括癌症相关基因组基因座小组的定量量度,从较早的时间点到较晚的时间点是减少的),则差异可以指示对象患结直肠癌的风险降低。临床行动或决定可以基于癌症风险降低的这个指征作出,为对象(例如,继续或结束当前的治疗性干预)。临床行动或决定可以包括建议对象进行二次临床测试,以确认患结直肠癌的风险降低。此二次临床测试可以包括影像学测试、血液测试、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示治疗对象的癌症的治疗过程有效。例如,如果对象在较早的时间点检测到癌症,但在较晚的时间点没有检测到,则差异可以指示治疗对象的癌症的治疗过程有效。临床行动或决定可以基于治疗对象的癌症的治疗过程有效的这个指征作出,例如,为对象继续或结束当前的治疗性干预。临床行动或决定可以包括建议对象进行二次临床测试,以确认治疗对象的癌症的治疗过程有效。此二次临床测试可以包括影像学测试、血液测试、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
在一些实施方案中,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度)的差异,包括在两个或更多个时间点之间确定的癌症相关基因组基因座小组的定量量度的差异,可以指示治疗对象的癌症的治疗过程无效。例如,如果对象在较早的时间点和较晚的时间点都检测到癌症,且如果差异是正性或零差异(例如,在癌症相关基因组基因座小组上数据集的序列读取的定量量度(例如,在癌症相关基因组基因座上的RNA转录物或DNA的定量量度),包括癌症相关基因组基因座小组的定量量度,从较早的时间点到较晚的时间点是增加的或保持在恒定水平),则差异可以指示治疗对象的癌症的治疗过程无效。临床行动或决定可以基于治疗对象的癌症的治疗过程无效的这个指征作出,例如,为对象结束当前的治疗性干预和/或转换(例如,开具)新的不同的治疗性干预。临床行动或决定可以包括建议对象进行二次临床测试,以确认治疗对象的癌症的治疗过程无效。此二次临床测试可以包括影像学测试、血液测试、计算机断层(CT)扫描、磁共振成像(MRI)扫描、超声扫描、胸部X光、正电子发射断层(PET)扫描、PET-CT扫描、无细胞生物细胞学检查、FIT测试、FOBT测试或其任何组合。
VIII.试剂盒
本公开提供了用于鉴定或监测对象的两种或更多种癌症类型的试剂盒。试剂盒可以包括探针,用于鉴定对象的无细胞生物样品中多个癌症相关基因组基因座中每个上的序列定量量度(例如,指示存在、不存在或相对数量)。无细胞生物样品中多个癌症相关基因组基因座中每个上的序列定量量度(例如,指示存在、不存在或相对数量)可指示一种或多种癌症。探针可对无细胞生物样品中多个癌症相关基因组基因座上的序列有选择性。试剂盒可以包括使用探针处理无细胞生物样品以生成数据集的说明书,所述数据集指示对象的无细胞生物样品中多个癌症相关基因组基因座的每个上的序列定量量度(例如,指示存在、不存在或相对数量)。
试剂盒中的探针可以对无细胞生物样品中多个癌症相关基因组基因座上的序列有选择性。试剂盒中的探针可以被配置为选择性富集与多个癌症相关基因组基因座相对应的核酸(例如,RNA或DNA)分子。试剂盒中的探针可以是核酸引物。试剂盒中的探针可以与来自多个癌症相关基因组基因座或基因组区域中的一个或多个的核酸序列具有序列互补性。多个癌症相关基因组基因座或基因组区域可以包含至少2个、至少3个、至少4个、至少5个、至少6个、至少7个、至少8个、至少9个、至少10个、至少11个、至少12个、至少13个、至少14个、至少15个、至少16个、至少17个、至少18个、至少19个、至少20个、至少25个、至少30个、至少35个、至少40个、至少45个、至少50个、至少55个或更多个不同的癌症相关基因组基因座或基因组区域。多个癌症相关基因组基因座或基因组区域可以包含选自表1-17中所列区域的一个或多个成员。
试剂盒中的说明书可以包括使用对无细胞生物样品中多个癌症相关基因组基因座上的序列有选择性的探针来测定所述无细胞生物样品的说明书。这些探针可以是核酸分子(例如RNA或DNA),与来自多个癌症相关基因组基因座中的一个或多个的核酸序列(例如RNA或DNA)具有序列互补性。这些核酸分子可以是引物或富集序列。测定无细胞生物样品的说明书可以包括执行阵列杂交、聚合酶链式反应(PCR)或核酸测序(例如,DNA测序或RNA测序)以处理无细胞生物样品由此生成数据集的说明书,所述数据集指示在无细胞生物样品中多个癌症相关基因组基因座的每个上的序列定量量度(例如,指示存在、不存在或相对数量)。无细胞生物样品中多个癌症相关基因组基因座中每个上的序列定量量度(例如,指示存在、不存在或相对数量)可指示一种或多种癌症。
试剂盒中的说明书可以包括测量和解释测定读出的说明书,所述测定读出可以在多个癌症相关基因组基因座中的一个或多个处定量,以生成数据集,所述数据集指示无细胞生物样品中多个癌症相关基因组基因座中的每个上的序列定量量度(例如,指示存在、不存在或相对数量)。例如,与多个癌症相关基因组基因座相对应的阵列杂交或聚合酶链式反应(PCR)的定量可以生成指示无细胞生物样品中多个癌症相关基因组基因座中的每个上的序列定量量度(例如,指示存在、不存在或相对数量)的数据集。测定读出可以包括定量PCR(qPCR)值、数字PCR(dPCR)值、数字液滴PCR(ddPCR)值、荧光值,或其归一化值。
实施例
实施例1:用于检测多种癌症类型的甲基化区域的选择
为了设计能够检测和区分多种类型癌症的特征小组,鉴定了在各种类型的癌症中甲基化并能够用于确定癌症类型(肿瘤或癌细胞)的组织来源的cfDNA区域。使用两个原则来设计DNA甲基化区域的多癌症特征小组:
(i)鉴定可用于筛查不同癌症类型的区域,包括可以被认为是“泛癌症”并在多于一种类型的癌症中甲基化的区域;和
(ii)鉴定可用于确定肿瘤组织来源(TOO)的区域,包括仅在一种目标癌症中甲基化或高甲基化并且在其他癌症类型或未患任何癌症的对象中并非如此的区域。
TCGA和EPIC阵列数据分析
使用TCGA 450K阵列数据进行分析。从TCGA网站下载33种癌症类型的450K甲基化阵列原始idat文件(包括癌症和正常组织数据)。使用R包SeSAMe来计算每个探针的β值。向CpG致密光小组(CpGdv2)中的每个区域分配与所述区域重叠的所有探针的平均β值。表19示出了获得的癌症和正常组织数量的数据。
表19
从GEO下载用于分析的公共血液EPIC阵列数据(血液,GSE110555,67个样品)。在EPIC阵列上生成公共血液数据,因此仅使用与TCGA 450K阵列数据重叠的探针。向CpG致密光小组中的每个区域分配β值,与以上对于TCGA数据所述的程序类似。
单变量分析
针对癌症与正常组织(对于具有正常组织数据的所有癌症)以及癌症与血液(对于所有癌症)计算CpG致密光小组中每个区域的单变量AUC。保留癌症与血液以及癌症与正常组织比较两者中单变量AUC≥0.9的区域用于下游分析。这产生了总计3840个区域,大小达到6349802bp。
Metilene分析
对来自TCGA的450K甲基化阵列组织数据(不包括来自非癌样品的数据)进行Metilene分析。使用探针β值,所述值使用OpenSesame R流程进行归一化。保留q值为0.05或更小的差异甲基化区域(DMR)。检查了这些区域与CpG致密小组的重叠。将每个CpG致密区域注释为在各组织类型中通过Metilene检测到或未检测到。此信息用于鉴定相对于多个组织在单个组织中检测到并且可以用于组织来源检测的区域。这产生了总计3498个区域,大小达到4276029bp。
单变量分析与metilene分析之间的重叠
在单变量分析与metilene分析之间重叠~2.2Mb(1681个区域)。这些区域进一步用于下游分析,并且基于与后面描述的组织TEM-seq数据HMFC分析的区域的重叠进行过滤。
图2提供了这些1681个区域的β值的热图,其指示这些区域也可以含有可用于确定肿瘤来源的信号。不同的肿瘤类型聚类成基本上不同的分组。热图显示了从分析中鉴定的区域的β值聚类。结肠腺癌(COAD)和直肠腺癌(READ)聚类在一起。肺鳞癌(LUSC)和肺腺癌(LUAD)形成基本上两个独立的分组,少数样品重叠。此分析中的总区域大小是~2.2Mb。
从TCGA分析鉴定组织来源区域
对于TCGA分析中与单变量分析和metilene分析重叠的1681个区域,定义了仅在一种癌症类型中具有DMR的TOO推定列表。通过对一种癌症类型相对于每种其他癌症类型进行单变量分析,并且保留在metilene分析与单变量分析之间组织类型一致的区域来验证这些区域。所述癌症的单变量AUC≥0.75的区域被认为是DMR,而每种其他癌症类型的AUC<0.65的区域被保留在TCGA分析的最终推定TOO列表中。此分析产生79个区域,总大小为103,554bp。
组织甲基-seq数据的分析
数据
获得FF(快速冷冻)组织回顾性样品。用甲基化序列方法对从中分离的DNA进行测序。表20示出了获得的每种组织样品的样品数量。
表20
自动区段化
使用自动区段化流程的修改版本来为每种癌症类型限定合理的区域边界。为每种癌症类型创建过滤和未过滤的bam文件。创建Pickle文件并将其输入到经修改的自动区段化流程中,以鉴定在癌症样品中具有甲基化但在健康血浆样品中几乎没有甲基化的区域。
用于特征选择的癌症与血浆模型中的高甲基化片段分析
使用高甲基化片段分析,并对每种癌症的区段化区域进行总结。为了鉴定主要特征,使用5折CV和5次重组对癌症与血浆模型进行高甲基化片段分析,保留在至少1折中经选择并且平均效应大小>第90百分位数的区域。这产生845个区域,总区域大小为643185bp。
用于推定TOO特征选择的癌症与每种其他癌症模型中的高甲基化片段分析
对于每种癌症类型,鉴定在目标癌症中高甲基化但在任何其他癌症中未甲基化的区域。为了达到这一目的,使用高甲基化片段分析,保留在所有25折中经选择并且平均效应大小为第100或第99百分位数值中的较小者的区域。这产生总计141个区域,总大小为86,129bp。
最终多癌症小组设计程序
将TCGA单变量分析中与metilene差异甲基化区域分析和甲基化片段组织甲基-seq分析两者重叠的区域与从TCGA或甲基-seq组织数据分析中鉴定的推定TOO区域组合,以获得多癌症特征小组。这产生总计417个甲基化区域,总大小为512,123bp。
图3示出了包括在多癌症小组中的区域的热图。热图显示即使是这个较小的子集,不同癌症类型之间也有明显区分。热图显示了从分析中鉴定的区域的β值聚类。结肠腺癌(COAD)和直肠腺癌(READ)聚类在一起。肺鳞癌(LUSC)和肺腺癌(LUAD)形成基本上两个独立的分组,少数样品重叠。
- 包括组织压缩闭锁件的外科缝合系统
- 被构造成能够提供组织的选择性切割的外科缝合系统
- 包括可切入组织支撑件的圆形缝合系统
- 一种组织缝合夹和组织的缝合方法
- 一种用于软组织缝合的医用缝合针