智能外呼系统、方法、计算机系统及存储介质
文献发布时间:2023-06-19 09:29:07
技术领域
本申请实施例涉及客服外呼技术领域,尤其涉及智能外呼系统、方法、计算机系统及存储介质。
背景技术
外呼是客户服务中心系统呼出服务主动发起对客户的呼叫。外呼服务已被广泛应用在各种领域,常见的例如金融行业,外呼常应用于电话催收、还款提醒、银行业务等业务中;在教育培训行业,可以通过外呼对潜在学员进行沟通回访,或者对成功预约的学员通知上课时间、地点等信息;在各种销售行业,售后回访都可能会用到外呼。
虽然目前已有自动化的外呼系统,即通过机器自动外呼并与用户会话应答;现有的自动外呼系统所应用的场景有些是通用化的或者是专用化的,通用化的自动外呼系统在会话精准度上不够,而专用化的自动外呼系统在能应对的业务类型上的灵活度不够,无法兼顾灵活应用不同场景且会话精准。
发明内容
有鉴于此,本申请实施例中提供智能外呼系统、方法、计算机系统及存储介质,解决现有技术中的技术问题。
本申请实施例提供了一种智能外呼系统,包括:
拨号服务单元,用于执行业务相关的拨号任务,以形成智能外呼系统同所拨打的用户电话间的会话;其中,所述拨号服务单元配置有与所述拨号任务相关的场景信息;
语音服务单元,用于将所述会话中的用户语音转换为用户文本,或将播报文本转换为对用户的播报语音;
会话服务单元,用于接受所述拨号服务单元的调用,根据所述场景信息启用相应场景模板,并能调用意图引擎的服务来分析该用户文本以获取对应的用户意图,以令所述场景模板中的多个流程节点在用户意图驱动下形成流程,并在所述流程到达的至少部分流程节点确定播报话术,并由所述语音服务单元转换所述播报话术对应的播报文本为对用户的播报语音。
可选的,所述多个流程节点的类型包括以下任意一种或多种组合:
意图节点,用于在流程到来时,通过所述意图引擎的服务以获得用户意图,并根据所述用户意图选择通往下一流程节点的路径;
答复节点,用于在流程到来时,输出预设播报话术;
词槽节点,用于在流程到来时,通过所述意图引擎的服务提取用户意图中的关键信息;
调用节点,用于通过预设应用接口使用外部资源。
可选的,所述意图节点和/或词槽节点,还用于在询问用户无应答的情况下,输出对应的播报话术。
可选的,所述询问用户无应答的情况包括以下任意一种:超时未答复;拒绝答复。
可选的,意图节点与词槽节点间连接形成的组合包括以下至少一种:
1)单个词槽节点,连接在一意图节点之后,以用于从意图节点所获得的用户意图中提取一种或多种关键信息;
2)多个词槽节点,串行连接在一意图节点之后,以用于从所述意图节点所获得的用户意图中分别提取一种或多种关键信息。
可选的,所述关键信息包括:命名实体信息。
可选的,所述意图引擎所提供服务的类型包括以下中的一种或多种:
语义搜索预测服务,用于输出基于模板匹配的语义搜索得到的预测结果;
机器学习预测服务,用于输出基于机器学习模型的语义预测结果;
命名实体识别预测服务,用于输出基于回归或机器学习语义模型对命名实体识别的预测结果;
知识图谱预测服务,用于输出基于知识图谱的语义搜索的预测结果;
阅读理解预测服务,用于输出基于对文本的阅读理解的语义搜索的预测结果。
可选的,所述多个流程节点中的意图节点和词槽节点具有意图服务属性信息,用于定义其所使用的意图引擎的服务类型。
可选的,所述拨号服务单元还配置有与所述拨号任务相关的用户信息;所述播报文本中的用户相关内容通过链接所述用户信息以得到填充。
可选的,所述的智能外呼系统包括:系统语音交换服务单元,连接所述拨号服务单元、语音服务单元及会话服务单元,并通过连接至电话业务网络能拨打用户电话。
可选的,所述系统语音交换服务单元与外部语音交换装置桥接,以通过所述外部语音交换装置连接于所述电话业务网络。
可选的,所述语音服务单元包括:语音转文字子单元以及文字转语音子单元。
可选的,所述语音服务单元还包括:
媒体资源控制子单元,分别供所述语音转文字子单元及文字转语音子单元可插拔地连接。
可选的,所述可插拔连接包括:远程过程调用连接。
本申请实施例还提供了一种智能外呼方法,应用于智能外呼系统;所述智能外呼方法包括:
执行拨号任务,以形成智能外呼系统同所拨打的用户电话间的会话;
将所述会话中的用户语音转换为用户文本;
根据与所述拨号任务相关的场景信息启用相应场景模板,并调用意图引擎的服务来分析该用户文本以获取对应的用户意图,以令所述场景模板中的多个流程节点在用户意图驱动下形成流程,并在所述流程到达的至少部分流程节点确定播报话术;
将所述播报话术对应的播报文本转换对用户的播报语音。
可选的,所述多个流程节点的类型包括以下任意一种或多种组合:
意图节点,用于在流程到来时,通过所述意图引擎的服务以获得用户意图,并根据所述用户意图选择通往下一流程节点的路径;
答复节点,用于在流程到来时,输出预设播报话术;
词槽节点,用于在流程到来时,通过所述意图引擎的服务提取用户意图中的关键信息;
调用节点,用于通过预设应用接口使用外部资源。
可选的,所述意图节点和/或词槽节点,还用于在询问用户无应答的情况下,输出对应的播报话术。
可选的,所述询问用户无应答的情况包括以下任意一种:超时未答复;拒绝答复。
可选的,意图节点与词槽节点间连接形成的组合包括以下至少一种:
1)单个词槽节点,连接在一意图节点之后,以用于从意图节点所获得的用户意图中提取一种或多种关键信息;
2)多个词槽节点,串行连接在一意图节点之后,以用于从所述意图节点所获得的用户意图中分别提取一种或多种关键信息。
可选的,所述关键信息包括:命名实体信息。
可选的,所述意图引擎所提供服务的类型包括以下中的一种或多种:
语义搜索预测服务,用于输出基于模板匹配的语义搜索得到的预测结果;
机器学习预测服务,用于输出基于机器学习模型的语义预测结果;
命名实体识别预测服务,用于输出基于回归或机器学习语义模型对命名实体识别的预测结果;
知识图谱预测服务,用于输出基于知识图谱的语义搜索的预测结果;
阅读理解预测服务,用于输出基于对文本的阅读理解的语义搜索的预测结果。
可选的,所述多个流程节点中的意图节点和词槽节点具有意图服务属性信息,用于定义其所使用的意图引擎的服务类型。
可选的,所述播报文本中的用户相关内容通过链接预先配置的用户信息以得到填充。
本申请实施例还提供了一种用于智能外呼系统的计算机系统,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行任一项所述智能外呼方法的步骤。
本申请实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序运行时执行任一项所述的智能外呼方法的步骤。
与现有技术相比,本申请实施例的技术方案具有以下有益效果:
一方面,本申请实施例中智能外呼系统通过预设场景模板,以根据不同业务需求加以选择启用,并通过在会话中分析用户意图在所述场景模板对应的多个流程节点中形成流程,确定相应播报话术,既达到了灵活根据业务需求进行适配的外呼应用业务场景的选择,同时通过精细化的流程节点和意图分析,达到精准的会话效果,良好解决现有技术中的问题。
另一方面,本申请的智能外呼系统中可以使用一种或各种类型的传统模型、深度学习模型等进行用户意图的分析,具有更好的场景通用性并兼顾会话精准性。
再一方面,本申请的智能外呼系统中,可在系统架构上可对语音/文本相互转换的模块的形式进行了独立模块划分,并使用可插拔连接方式,使得划分后的不同功能模块能承接不同的服务需求,达到更高的使用效率。
附图说明
图1是本申请实施例中智能外呼系统的应用场景示意图。
图2是本申请实施例中智能外呼系统的功能模块示意图。
图3是本申请实施例中语音服务单元的功能模块示意图。
图4是本申请实施例中场景管理的图形界面示意图。
图5是本申请实施例中场景流程结构的示意图。
图6是本申请实施例中流程节点应用的示意图。
图7a是本申请实施例中配置意图节点的图形界面示意图。
图7b是本申请实施例中配置答复节点的图形界面示意图。
图7c是本申请实施例中配置词槽节点的图形界面示意图。
图7d是本申请实施例中配置调用节点的图形界面示意图。
图8是本申请实施例中一种意图节点和词槽节点组合应用的示意图。
图9是本申请实施例中又一种意图节点和词槽节点组合应用的示意图。
图10是本申请又一实施例中智能外呼系统的功能模块示意图。
图11是本申请实施例中智能外呼系统的硬件架构示意图。
图12是本申请实施例中智能外呼方法的流程示意图。
图13是本申请实施例中计算机系统的结构示意图。
具体实施方式
智能外呼系统,是用于基于业务目的进行自动化地对客户进行电话拨打及会话。
在一些示例中,对外呼有需求的行业例如之前提到的证券金融、教育培训等,都会存在电销、回访的业务需求,而例如银行等也会因为贷款业务而产生催收需求。在以往这些外呼工作都是由客服来完成,电销业务在初筛时需要客服拨打大量陌生号码,但接通率极低且意向客户比例也极少,其中存在大量重复工作;在催收业务场景中,客服的工作是进行告知、通知接听方一些他们需要知晓的信息,接听方的反馈分类也比较简单:知晓并同意或拒绝,故在例如催收等通知场景下,通常所需要的话术轮数较短,引导和目的明确,通话内容也存在了大量重复。
可见,通过智能外呼系统来替代人工客服外呼来完成这些存在大量重复的,可以大大提升工作效率,且有效降低因为人工作业出现的失误、负面情绪等问题。
如图1所示,展示本申请实施例中智能外呼系统11应用的通信系统示意图。
智能外呼系统11要实现外呼功能,需要连接到电话网络以能与拨打用户的电话装置14通话。在此实施例中,通过外部的用户级交换机(Private Branch eXchange,PBX)12连接到公共交换电话网络(Public Switched Telephone Network,PSTN)13,通过公共交换电话网络13能访问到用户的电话装置14。其中,所述电话装置14可以为座机、手机或其它能接入公共交换电话网络13的通话设备,此类通话设备例如插设用户识别(SubscriberIdentity Module,SIM)卡的平板电脑、智能手表、智能手环、智能眼镜等。
在一些示例中,所述智能外呼系统11可以根据实际需求而由一台计算机设备实现,或由多台计算机设备相互连接成处理系统而协作实现。其中,所述计算机设备可例如为服务器,而多台计算机设备可构成协作的服务器组。
所述智能外呼系统11要实现的功能包括:自动外呼和自动会话。举一个简单的例子说明其工作过程,获得用户名单,例如一组用户电话,然后开始逐一拨打,当打通时,根据任务开始使用预定话术,例如电销中常见的“您好,了解到您是我x的优质客户,因此向您推荐xxxxx”等;进而,如果用户应答,则可对其应答进行语义分析,以获得用户意图,再继续应答,直至流程完结而挂断。
现有技术中的自动外呼系统,虽然也基本上是通过此原理在运作,通过机器自动外呼并与用户会话应答,但是它们的应用场景有些是通用化的或者是专用化的,通用化的自动外呼系统在会话精准度上不够,而专用化的自动外呼系统在能应对的业务类型上的灵活度不够;为解决这一问题,本申请实施例中提供了相应的解决方案。
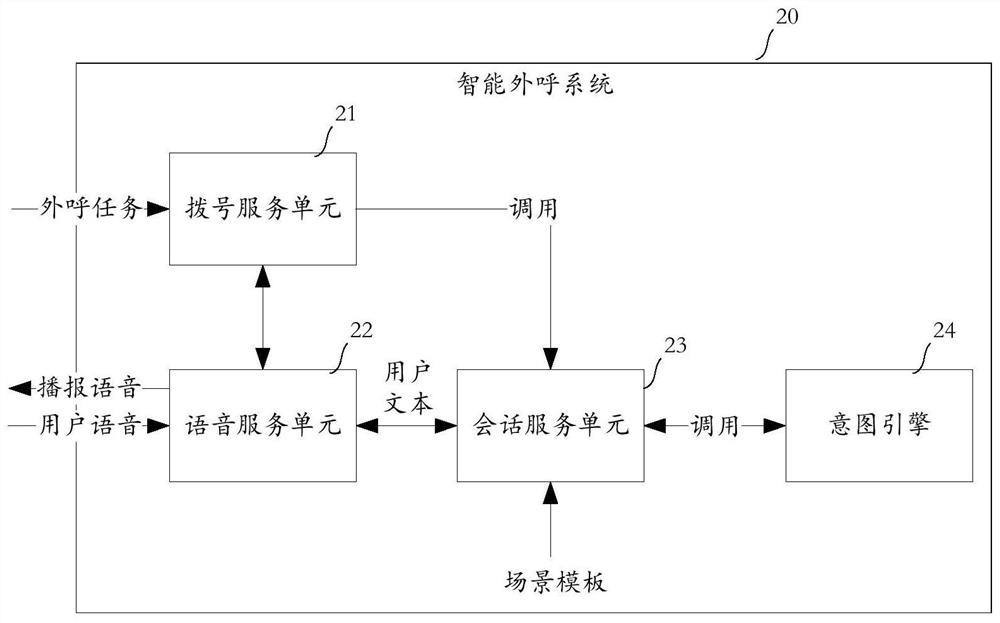
如图2所示,展示本申请实施例中的智能外呼系统的功能模块示意图。该智能外呼系统20可应用在图1实施例中。所述智能外呼系统20具体包括:拨号服务单元21、语音服务单元22及会话服务单元23。
所述拨号服务单元21,用于执行业务相关的拨号任务,以形成智能外呼系统20同所拨打的用户的电话装置间的会话。
在一些示例中,所述拨号服务单元21可配置有与所述拨号任务相关的场景信息,以用于指示相应的场景。例如,催收场景等。
在一些示例中,所述拨号服务单元21还可以配置有用户信息(例如包含用户的姓名、电话、职业等信息),而能实现用户名单服务,即确定需要拨打的用户名单,以根据该用户名单进行其中电话的拨打。
在一些示例中,所述拨号服务单元21还可以配置有策略服务,其中策略服务可以确定对用户拨打的时间计划(如避开休息日)、与用户个人信息相关的播报话术等等。
在一些示例中,所述拨号服务单元21还可以配置有外显号码信息,以能对所拨打的电话装置显示对应的外显号码,例如100XX,955XX等。
在会话中,由于用户输入的是语音,智能外呼系统对用户输出的也需是语音,而在智能外呼系统内又需要对用户输入语音转化为文本信息以进行语义分析,故需要通过该语音服务单元22进行处理。
所述语音服务单元22,用于将所述会话中的用户语音转换为用户文本,或将播报文本转换为对用户的播报语音。
在一些示例中,将用户语音转换为用户文本可以通过语音识别(AutomaticSpeech Recognition,ASR)算法实现,ASR算法一般包括语音特征提取(即编码),以及对提取到的特征向量解析以得到文字(即解码)的过程。其中,语音特征提取的算法如线性预测分析(Linear Prediction Coefficients,LPC)、感知线性预测系数(Perceptual LinearPredictive,PLP)、基于滤波器组的特征提取(Filterbank,Fbank)、线性预测倒谱系数(Linear Predictive Cepstral Coefficient,LPCC)或梅尔频率倒谱系数(Mel FrequencyCepstrum Coefficient,MFCC)等,解码的算法可以采用经训练的神经网络模型实现,例如循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-TermMemory,LSTM)、前馈序列记忆神经网络(Feedforward Sequential Memory NeuralNetworks,FSMN)等。
在一些示例中,将播报文本转换为对用户的播报语音可以通过语音合成(Text ToSpeech,TTS)的相关算法来实现,例如基于原始音频生成模型的WaveNet、基于端到端的语音合成模型的Tacotron、基于神经文本语音转换的DeepVoice、基于语音循环进行语音拟合与合成的VoiceLoop等。
由于在现有技术中,会把ASR和TTS模块集成为一整个模块,则一旦存在需要ASR或TTS的服务,整个模块都会被调用,但可能只需要使用其中的ASR和TTS中的一种进行工作,而另外一种却也被当前服务所占用,如此就会导后续服务需要等待,致使运行效率低下。
为此,如图3所示,示例性地展示本申请实施例中的所述语音服务单元的功能模块示意图。
在此示例中,所述语音服务单元30包括:独立的语音转文字子单元31和文字转语音子单元32。其中,所述语音转文字子单元31可以是前述ASR模块实现,所述文字转语音子单元32可以是前述TTS模块实现。两者间相互独立,则可以并行工作,例如语音转文字子单元31接受服务需求1而提供ASR服务,文字转语音子单元32并行地接受服务需求2而提供TTS服务,从而能有效提升整个智能外呼系统的运行效率,降低延迟。
可选的,所述语音服务单元30还可包括:媒体资源控制子单元33,供所述语音转文字子单元31及文字转语音子单元32分别可插拔地连接,用于与外部交互以根据服务需求选择调用所述语音转文字子单元31及文字转语音子单元32。其中,媒体资源控制子单元33可以通过媒体资源控制协议(Media Resource Control Protocol,MRCP)对外通信,媒体资源控制协议是一种计算机网络应用层的通讯协议,用于语音服务器向客户端提供各种语音服务。
在一些示例中,所述可插拔连接包括:远程过程调用(Remote Procedure Call)连接。在进一步的示例中,所述可插拔连接可以是gRPC,即Google RPC,是Google发布的基于HTTP 2.0传输层协议承载的高性能开源软件框架,由于可以进行二次开发,使用gRPC可以更加专注于业务层面的内容,减少了对由gRPC实现的底层通信的关注。
所述会话服务单元23,用于接受所述拨号服务单元21的调用,根据所述场景信息启用相应场景模板,并能调用意图引擎24的服务来分析该用户文本以获取对应的用户意图,以令所述场景模板中的多个流程节点在用户意图驱动下形成流程,并在所述流程到达的至少部分流程节点确定播报话术,并由所述语音服务单元22转换所述播报话术对应的播报文本为对用户的播报语音。
在以上示例中,本申请创新性地引入场景模板,以对应不同业务场景选择相应的场景模板,而场景模板并非只是简单的配置参数,在其中可以预先设定各种流程节点的组合,并在这些流程节点的运行过程中调用所述意图引擎的服务,来获得用户意图,以驱动自动地形成流程,既实现对应不同业务场景需求的场景模板的灵活选择,也通过流程节点和相应意图引擎的配合提升会话精准效果。
如图4所示,展示本申请实施例中场景管理的图形界面示意图。
在该图形界面中,示例性地展示了预先配置的多个场景模板,包括:反欺诈、催收、激活邀约等,可选的,其中还提供了“+”的区域供用户操作(如点击等),以新建场景模板;另外可选的,还可以提供删除场景模板的接口。
在一些示例中,所述拨号服务单元21所配置的场景信息可例如为场景模板的标识信息,例如ID编号等。所述场景信息可以在与拨号服务单元相关的其它图形交互界面中配置,与根据业务需求产生的需执行的外呼任务相关。例如,业务需求要进行催收,则产生了催收的外呼任务,在催收的外呼任务中对应于催收场景,若催收场景的ID号为ab003,则对应配置所述场景信息为ab003。
对每个场景模板中的流程节点进行介绍。如图5所示,展示本申请实施例中场景流程结构的示意图。
在图5中,展示了各个流程节点51,这些流程节点51按预设要求进行了关联,通过流程节点51间的连接线来表示;图中从左向右表示流程行进的方向,当然这只是例举而非以此方向为限,也可以是从上至下、从下至上或从右至左等。
换言之,某个流程节点51向左通过连接线相连的是其之前的流程节点51,而向右通过连接线相连的是其之后的流程节点51。若某个流程节点51向后有多个分支的连接,则在该流程节点51可能通过用户意图来进行选择。
在所述多个流程节点51中,可分别具有不同的类型,以各自实现所分配的逻辑来形成流程。在一些示例中,所述多个流程节点51的类型包括以下任意一种或多种组合:
1)意图节点,用于在流程到来时,通过所述意图引擎的服务以获得用户意图,并根据所述用户意图选择通往下一流程节点的路径。
例如图6所示,在催收场景中,若流程到达“核查身份”的意图节点“核身”时,若已向用户问询“您好,请问是xx先生么”而得到相应回复例如“我不是”的情况下,相应的意图节点“核身”根据“我不是”的用户文本通过意图引擎的服务可以判断“我不是”与预设意图分类“不是本人”较为匹配,则判断“不是本人”,而通过相应的连接线通向下一流程节点。
又或者,意图节点“核身”根据用户文本“我现在很忙”,判断与预设意图分类“在忙”较为匹配,则判断“在忙”,通过相应连接线通向下一流程节点。
在一些示例中,所述意图节点还可用于在询问用户无应答的情况下,输出对应的播报话术。可选的,所述询问用户无应答的情况包括以下任意一种:超时未答复;拒绝答复。
举例来说,对应超时未回复可以设置“超时话术”,判断超时所依据的时间阈值可以根据实际需求加以设定,例如5秒等;比如当先询问用户:“您好,请问是张先生么?”之后5秒未得到回应,则“超时话术”可以是重复询问“您好,请问是张先生么?”,或者“您现在可能不方便打电话,我呆会再打给您吧,谢谢”。
对应拒绝答复可以设置“拒说话术”,比如用户不回复,则可以对应采用例如重复询问“您是张先生么?”,或者“您现在可能不方便打电话,我呆会再打给您吧,谢谢”等。
虽然上述示例中列举的超时话术和拒说话术存在内容重复,但可以理解的是,在实际应用中,皆可根据不同的需求而加以变化,并不限定两种话术的内容。
在一些示例中,所述意图节点中可以识别的意图分类、超时话术、拒识话术等中的一或多种,皆可通过图形用户界面展示给用户,以由用户设定。
例如图7a的图形用户界面中,用户可以自行编辑设置相关内容,例如节点名称、意图分类、超时话术、拒识话术、询问话术、及它们的内容和条目增加/删除(图中“+”表示增加,垃圾桶的符号表示删除)等。其中,节点名称可以自行定义,例如与本节点功能相关的如“核对身份”;意图分类项中可填写一或多项用户意图,例如“打错了”、“在忙”、“确定”;所述询问话术例如为“尊敬的客户,我是银行信贷业务部的,请问是张X先生本人么”;超时话术例如包括:“没听清楚,能否再说一遍?”,“您好,您能听见我说话么?”;拒识话术可与超时话术一致。
需说明的是,当意图节点存在新增意图分类时,若所述意图引擎的服务是通过训练的机器学习模型来预测用户意图的话,则该新增意图分类可以被作为新分类标签而送入意图引擎以对所述机器学习模型进行训练,例如对预先正确标记该新分类标签的用户文本(可以是从相同场景下的用户语音中提取的,也可以是有经验的人员对应相同场景进行人工输入的,也可以是从其它相同场景中用户侧的现有应答数据中导入的)作为训练数据输入机器学习模型,并根据预测结果与所述分类标签间的差异即损失,所述机器学习模型参数以降低该损失为目的自行调整,直至达到收敛,从而令机器学习模型能学习到新分类标签和相应用户文本的关系。
2)答复节点,用于在流程到来时,输出预设播报话术。
例如,在图6中,意图节点“核身”的上一节点即可为答复节点“核身”其中可以预设需要答复的预先设定的答复话术“您好,请问是xx先生么?”。
答复节点可以不需要进行用户意图的识别,可以仅在流程到来时即被相应连接线选择时输出预先设定的答复话术即可。
图7b展示的是配置答复节点中参数的图形用户界面。在图7b的图形用户界面中,用户可以通过操作来设置答复节点的名称、及预设的答复话术,例如节点名称为“核身”,答复话术为“您好,请问是xx先生么?”
3)词槽节点,用于在流程到来时,通过所述意图引擎的服务提取用户意图中的关键信息。
在一些示例中,所述关键信息可以包括命名实体信息。所谓的命名实体(namedentity)就是人名、机构名、地名以及其他所有以名称为标识的实体。更广泛的实体还包括数字、日期、货币、地点等等。
在一些示例中,词槽节点中也可以预设设置有相应的询问话术,用于引导用户输出带有所需要的关键信息的应答内容,比如在之前已获取到用户意图为“买火车票”的情况下,而需要获得相应的目的地,则可以输出预先设定的询问话术:“您要买去哪里的火车票”;进一步的,如果用户应答是“我要买去北京的火车票”,那么可以明确用户意图是买火车票,而通过词槽节点可以通过调用意图引擎的服务从中提取“北京”这一关键信息,从而能得到更精确的用户意图是需要购买去北京的火车票。
可见,当已获得用户意图的时候,可以通过进一步从中抽取命名实体,以提供更加精细的流程,使得在会话精准效果上能得到较大提升,更贴合于用户的实际需求,在实际应用中也能达到更好的用户体验,比如用户满意度高;应用在电话销售场景中也有利于提升精准营销的精度而达成较高的销售成功率等。
图7c展示的是配置词槽节点中参数的图形用户界面。在图7c的图形用户界面中,用户可以通过操作来设置例如节点名称(比如“收集地点”)、词槽(表示要提取的关键信息类别等)、询问话术等。
在词槽节点中,也可以设置超时时间、超时话术、拒说话术等,以应对接收不到用户答复的情形。
在上述配置界面中,存在对用户信息的调用需求,例如“张先生”,又例如常见外呼中的“您的账户是xxx”,“您的尾号是yyy”,都会涉及用户信息。故在一些示例中,所述拨号服务单元还配置有与所述拨号任务相关的用户信息,而上述节点所使用播报话术对应的所述播报文本中的用户相关内容通过链接所述用户信息以得到填充,例如“张先生”通过例如“{user.name}”用户姓名函数调用得到。
4)调用节点,用于通过预设应用接口使用外部资源。
在一些示例中,应用接口(Application Programming Interface,API)是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。可选的,所述预设应用接口可以是表现层状态转移(REpresentational State Transfer,REST)应用接口,RESTful API可作为对Web,iOS和Android等提供服务的一套统一接口。对于广大平台来说,如微博开放平台,微信公共平台等,不需要有显式的前端,只需要一套提供服务的接口,RESTful API就更适合于此。
如图7d所示,展示本申请实施例中配置调用节点的图形用户界面示意图。所述调用节点可配置的项目有节点名称、调用地址、请求方式、输入参数设置(入参的值是被调函数需要)、输出参数设置(出参的值是主调函数需要的)等等。
另外需说明的是,为表示流程启动和结束,流程节点的类型中还可以包括开始节点和结束节点,以分别位于流程的首、尾位置。
从上述举例可以发现,不同类型的节点之间可以相互组合,以实现不同的逻辑。其中,意图节点和词槽节点皆以用户意图所驱动而选择流程流向,通过它们的逻辑组合可以达成与用户的会话过程中的多步交流。
意图节点与词槽节点间连接形成的组合包括以下至少一种:
1)单个词槽节点,连接在一意图节点之后,以用于从意图节点所获得的用户意图中提取一种或多种关键信息。
例如图8所示,假设意图节点A之后连接有一词槽节点B,若意图节点A判断出用户需要上门服务的意图,而进入词槽节点B,词槽节点B可以是从该意图中获取相关时间,获得按xx时间上门服务的意图。
例如,词槽节点B输出询问话术“请问您要哪天送货上门”,如果用户回答“2020年8月20日”,则明确用户需要2020年8月20日送货上门;或者,所述词槽节点B既可以获得时间信息,也可以一并获得地点信息,例如询问“请问您要哪天送货上门,地址是否是xxxx”。
2)多个词槽节点,串行连接在一意图节点之后,以用于从所述意图节点所获得的用户意图中分别提取一种或多种关键信息。
例如图9所示,展示一个意图节点C之后串接词槽节点D和词槽节点E;在实际例子中,用户意图中会包含多种关键信息,地点、时间等等,可以通过先后的多个词槽节点逐步获取,例如已获取到用户意图为“买火车票”的情况下,而需要获得相应的目的地,则可以输出预先设定的询问话术:“您要买从哪里去哪里的火车票”;进一步的,如果用户应答是“我要买从上海去北京的火车票”,那么可以明确用户意图是买火车票,且通过词槽节点D可以通过调用意图引擎的服务从中提取出发和目的地点这一关键信息,从而能得到更精确的用户意图是需要购买从上海去北京的火车票;通过词槽节点E询问用户“你要买哪天的火车票”,若从用户应答中提取“明天”的关键信息,则表明用户要买明天从上海去北京的火车票。在之后的流程节点中,还可以通过词槽节点继续询问更细致的内容,例如几点;也可以通过调用节点调用外部数据,例如列车管理数据,取得明天上海去北京的列车班次,之后汇报给用户等。
可以理解的是,意图节点和词槽节点在实际运行中可能会遇到无法命中意图的情形。例如,在询问“请问您要哪天送货上门”,获得的回答是“星期八”,则可以再次对用户重新询问直至获得可识别的应答;或者,可以视情形引入人工服务,并可选地对应增加意图分类或词槽。
在具体实施中,所述答复节点可能连接在意图节点之前,例如“核身”先要对用户发起预设播报话术,“您好,请问是xx先生么”;所述答复节点也可能连接在意图节点之后,例如判断用户意图是“不需要”之后,输出答复的预设播报话术“好的,再见!”等。
在一些示例中,具体说明所述意图引擎的原理。在具体实施中,所述意图引擎可以由一种或多种意图预测模型实现,所述意图引擎所提供服务的类型包括以下中的一种或多种:
1)语义搜索预测服务,用于输出基于模板匹配的语义搜索得到的预测结果。
在一些示例中,所述基于模板匹配的语义搜索可以是在可用于其它机器学习模型的用户语料较少的情况下使用,比如预先设定有哪些意图分类之后,对应每种意图分类设置一词库,词库中可以设置与所属意图分类相关的关键词,从而可以与用户文本进行语义匹配,可以根据例如词频等统计结果,或还可结合所匹配关键词的权重,以预测得到用户意图。
2)机器学习预测服务,用于输出基于机器学习模型的语义预测结果。
在一些示例中,所述机器学习语义模型可以是基于自然语言处理(NaturalLanguage Processing,NLP)的语义模型。例如,传统机器学习模型(如贝叶斯、朴素贝叶斯、支持向量机等);深度学习模型,例如循环神经网络(Recurrent Neural Networks,RNN)、长短记忆模型(Long Short-Term Memory,LSTM)、双向长短记忆模型(Bi-directional LongShort-Term Memory,BiLSTM)、卷积神经网络(Convolutional Neural Networks,CNN);可选的,在NLP的语义识别中,还可以使用词表示模型等来预先将文本处理成特征向量再作语义识别,例如上下文相关的词向量,更有利于处理效率并降低数据维度;最简单的独热(one-hot)的词向量表示方式,存在维度灾难和语义鸿沟问题,而后续预训练模型,例如静态词向量表示模型如Word2vec、FastText可以大大提升效率,例如的ELMo、GPT、BERT等动态词向量表示模型,又能进一步解决有效一词多义的问题;此外,可选的,还可以结合注意力(Attention)算法,例如自注意力(Self-Attention)算法,以给文本中关键信息的特征给予更高的权重,通过注意力算法可对得到的词特征向量进行进一步的编码,以得到能反映更加准确的上、下文语义的向量,以令语义预测结果更加精准。
在训练所述机器学习模型时,可通过带有真实标签的用户文本语料,输入到模型中,将输出的预测结果与真实标签对比计算损失,根据损失调节机器学习模型的参数,以在输出机器学习模型稳定时完成训练,得到训练完成的语义预测模型。
3)命名实体识别预测服务,用于输出基于回归或机器学习语义模型对命名实体识别的预测结果。
命名体识别(Named Entity Recognition,NER)是NLP技术中的一种基础任务。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)。
NER模型包括例如隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场模型(Conditional Random Field,CRF)或它们的变形模型或与其它模型的组合,例如LSTM和CRF模型组合等。
由于命名体识别任务是序列标注任务,则训练数据可以通过对语料进行词性标记得到,所述词性标记包括例如BIO的标注方式,将语料中每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。进而,将得到的训练数据输入NER模型进行训练,得到训练完成的NER模型。
4)知识图谱预测服务,用于输出基于知识图谱的语义搜索的预测结果。
在一些示例中,知识图谱是知识表达的方式,知识图谱常基于三元组进行知识表达,知识图谱的三元组指的是<主体(subject),谓词(predicate),客体(object)>,主体的取值通常是实体、事实或者概念中的任何一个;谓词的取值通常是关系或者属性;客体的取值既可以是实体、事件、概念,也可以是普通的值。
根据数据生成知识图谱,再根据知识图谱进行语义搜索的预测,相比于直接处理数据提取特征再进行预测计算的方式,在效率上要有极大提升。知识图谱未必是在本智能外呼系统生成,可以是外部现有的而导入本系统中,尤其是与相关业务的客服/外呼任务较为相关的现有知识图谱,更能有利于提升智能外呼系统的运行效率。
在知识图谱预测服务中,同样可以采用与之前机器学习预测服务相似的基于NLP技术的语义识别模型,如深度学习模型LSTM、Bi-LSTM等,通过取自知识图谱中的语料及对应真实分类标签作为训练数据,输入相应模型以对其训练,以得到训练完成的基于知识图谱的语义预测模型。
5)阅读理解预测服务,用于输出基于对文本的阅读理解的语义搜索的预测结果。
在一些实施例中,与知识图谱预测相似的,可以通过已有的文档,比如与客服外呼相关的工作资料,标准作业程序(Standard Operating Procedure,SOP)相关资料文档,话术应对的相关资料文档等等。在实际实现中,阅读理解模型可以采用前述实施例中的机器学习模型,或者更加适合于阅读理解的机器学习模型如深度LSTM(DeepLSTM)、专注阅读者(Attentive Reader)模型等,通过取自文档中的语料及真实分类标签作为训练数据,输入相应模型以对其训练,以得到训练完成的基于阅读理解的语义预测模型。
需说明的是,在上述1)~5)的意图预测服务中,2)~5)采用的是机器学习模型。在可能的实现方式中,意图节点进行用户意图获取可能会使用1)、2)、4)、5)的服务,而词槽节点进行关键信息提取可能会用到3)命名实体识别预测服务。并且,当意图节点存在新增的意图分类标签之后,可以将意图分类标签传输给意图引擎,以用于2)、4)、5)相关的机器学习模型的训练;可选的,词槽节点若有新增词槽,也可以传输给意图引擎,用于3)相关的模型的训练。
可选的,所述多个流程节点中的意图节点和词槽节点具有意图服务属性信息,用于定义其所使用的意图引擎的服务类型。例如,意图节点具有意图服务属性信息A,定义了其使用上述1)、2)、4)、5)中任意一项或多项的服务;词槽节点具有意图服务属性信息B,定义了其使用上述3)的服务。
所述会话服务单元,可以监控各个流程节点间的流程进展,并可根据流程到达的意图节点或词槽节点的意图服务属性信息,调用所述意图引擎的对应语义预测服务来获得用户意图或用户意图中的关键信息。
在一些示例中,所述意图引擎或词槽节点的意图服务属性信息中可能定义了可以使用多项服务,例如1)、2)、4)、5),故优选的,可以根据实际业务场景的特点对这些服务赋予不同的优先权重,例如兼顾预测精准度和效率,优先级从上至下为4)>5)>2)>1);又或者,在训练语料匮乏或机器学习模型尚未训练完成的情况下,可以令1)最优先。
再如图10所示,展示本申请又一实施例中智能外呼系统的功能模块示意图。
现有的自动外呼系统,与外部语音交换装置(PBX)直接相连,因此如果应用不同,则需要开发不同的PBX。
为此,在本申请的示例中,所述的智能外呼系统100还包括:系统语音交换服务单元101,连接所述拨号服务单元102、语音服务单元103及会话服务单元104,并通过连接至电话业务网络能拨打用户电话。
需说明的是,所述系统语音交换服务单元101可以作为系统内部的PBX,而可以配置成能灵活切换以适配不同应用的功能单元,从而避免了了对外部PBX 106多次外发的问题。
所述拨号服务单元102接受外呼任务,执行外呼任务时向系统语音交互服务单元发出相应指令,以通过与外部PBX 106而访问PSTN 107,对目标用户进行电话拨打以形成会话;拨号服务单元102通过系统语音交换服务单元101调用所述会话服务单元104,提供任务相关的场景信息,还可以提供用户信息,会话服务单元104根据场景信息启用相应的场景模板,开始执行流程,比如在开始节点之后的一个答复节点输出引导用户的话术“您好,请问是xx先生么”等;系统语音交换服务单元101与语音服务单元103的媒体资源控制子单元1031数据交互(可以通过例如MRCP协议交互),将从用户电话输入的语音经语音服务单元103的语音转文字子单元1032转换成用户文本,并通过系统语音交换服务单元101传输给会话服务单元104,会话服务单元104调用意图引擎105来分析用户文本以得到用户意图,以继续流程;当场景模板中流程到达的流程节点需要向用户播报语音时,将对应播报话术的播报文本通过系统语音交换服务单元101传递给媒体资源控制子单元1031,调用文字转语音子单元1033以转换成播报语音,通过所述系统语音交换服务单元101向外部PBX 106输出,而通过PSTN 107达到用户的电话装置108以向用户播放。
可选的,所述系统语音交互服务单元同拨号服务单元102、会话服务单元104之间可以基于互联网通信协议(例如超文本传输协议HTTP)交互数据。
所述系统语音交换服务单元101与外部语音交换装置桥接,以通过所述外部语音交换装置连接于所述电话业务网络。
如图11所示,展示本申请实施例中智能外呼系统的硬件架构示意图。
所述智能外呼系统的硬件架构包括:应用服务器组111、后台服务器组112和数据服务器组113。
在一些示例中,应用服务器组111中的应用服务器用于整个智能外呼系统的部署,以及供管理员或普通用户的用户管理终端110访问、管控所述智能外呼系统;可选的,为安全隔离智能外呼系统,所述用户管理终端110和应用服务器组111之间还可设有防火墙。应用服务器组111所具有的多个应用服务器,相互之间可以通过负载均衡规则调整相互各自相互任务负担的比例。
在一些示例中,所述后台服务器组112可以用于实现例如图10中智能外呼系统部分的软件系统中的各个功能单元,如拨号服务单元、语音服务单元及会话服务单元。所述后台服务器组112中的各后台服务器可以形成集群,进行同一种外呼任务的协作,也可以分别执行不同的外呼任务。
后台服务器组112通过外部的PBX 114接入PSTN 115,并呼叫用户的电话装置116。在实际应用中,PBX 114和PSTN 115之间还可以设置防火墙。
在一些示例中,所述数据服务器组113中主要运行数据库,例如关系型数据库(如PostgreSQL)和分布式数据(如MongoDB)等,以进行外呼相关数据的存取。所述数据服务器组113可以可以包括至少两个数据服务器,形成双机热备,即其中一个作为主机,另一个作为从机,相互网络连接;正常情况下主机处于工作状态,从机处于监视状态,一旦从机发现主机异常,从机将会在很短的时间之内代替主机,完全实现主机的功能,有利于保障数据安全,也有利于整个智能外呼系统的稳定运行。
需特别说明的是,图11中的硬件架构只是一种实现的举例,其架构完全可以根据实际需求加以变化,如果智能外呼系统的数据量较小,上述各服务器组也可以分别由单台服务器替代,甚至整个智能外呼系统可以实现在一台服务器上。
如图12所示,展示本申请实施例中的智能外呼方法,应用于前述实施例中的智能外呼系统,即可由智能外呼系统作为执行主体。本实施例中的智能外呼方法,其具体实施细节可以参考上述智能外呼系统的实施例,此处省略对技术细节的重复赘述。
所述智能外呼方法,具体包括:
步骤S121:执行拨号任务,以形成智能外呼系统同所拨打的用户电话间的会话;
步骤S122:将所述会话中的用户语音转换为用户文本;
步骤S123:根据与所述拨号任务相关的场景信息启用相应场景模板,并调用意图引擎的服务来分析该用户文本以获取对应的用户意图,以令所述场景模板中的多个流程节点在用户意图驱动下形成流程,并在所述流程到达的至少部分流程节点确定播报话术;
步骤S124:将所述播报话术对应的播报文本转换对用户的播报语音。
可选的,所述多个流程节点的类型包括以下任意一种或多种组合:
意图节点,用于在流程到来时,通过所述意图引擎的服务以获得用户意图,并根据所述用户意图选择通往下一流程节点的路径;
答复节点,用于在流程到来时,输出预设播报话术;
词槽节点,用于在流程到来时,通过所述意图引擎的服务提取用户意图中的关键信息。
可选的,所述意图节点和/或词槽节点,还用于在询问用户无应答的情况下,输出对应的播报话术。
可选的,所述询问用户无应答的情况包括以下任意一种:超时未答复;拒绝答复。
可选的,意图节点与词槽节点间连接形成的组合包括以下至少一种:
1)单个词槽节点,连接在一意图节点之后,以用于从意图节点所获得的用户意图中提取一种或多种关键信息;
2)多个词槽节点,串行连接在一意图节点之后,以用于从所述意图节点所获得的用户意图中分别提取一种或多种关键信息。
可选的,所述关键信息包括:命名实体信息。
可选的,所述意图引擎所提供服务的类型包括以下中的一种或多种:
语义搜索预测服务,用于输出基于模板匹配的语义搜索得到的预测结果;
机器学习预测服务,用于输出基于机器学习模型的语义预测结果;
命名实体识别预测服务,用于输出基于回归或机器学习语义模型对命名实体识别的预测结果;
知识图谱预测服务,用于输出基于知识图谱的语义搜索的预测结果;
阅读理解预测服务,用于输出基于对文本的阅读理解的语义搜索的预测结果。
可选的,所述多个流程节点中的意图节点和词槽节点具有意图服务属性信息,用于定义其所使用的意图引擎的服务类型。
可选的,所述播报文本中的用户相关内容通过链接预先配置的用户信息以得到填充。
如图13所示,展示本申请实施例中的计算机系统的结构示意图。
所述计算机系统可以由服务器/服务器组实现,在对硬件需求不高的情况下,还可以由处理能力更小的例如台式机、笔记本电脑、手机、平板电脑等实现,或这些处理设备通信连接而形成的处理系统。
所述计算机系统可以搭载有例如图2、图10中的智能外呼系统;所述计算机系统也可以实现为图12中的后台服务器或后台服务器组实现。
所述计算机系统130包括存储器131和处理器132,所述存储器131上存储有可在所述处理器132上运行的计算机程序,所述处理器132运行所述计算机程序时执行例如图12实施例中的智能外呼方法的步骤。
在一些示例中,所述处理器132可以是实现计算功能的组合,例如包含一个或多个微处理器组合,数字信号处理(Digital Signal Processing,DSP)、ASIC等;所述存储器131可能包含高速RAM存储器,也可能还包括非易失性存储器(Non-volatile Memory),例如至少一个磁盘存储器。
在计算机系统130需要与外部通信时,其还可包括通信器133,所述通信器133可以包括例如有线网卡、无线网卡、及2G/3G/4G/5G模块等中的一种或多种,而能与外部进行信息交互,如互联网交互。
本申请实施例还可以提供计算机可读存储介质,其上存储有计算机程序,所述计算机程序运行时执行例如图12实施例中的智能外呼方法的步骤。
即,上述本发明实施例中的图形编程作品检查方法被实现为可存储在记录介质(诸如CD ROM、RAM、软盘、硬盘或磁光盘)中的软件或计算机代码,或者被实现通过网络下载的原始存储在远程记录介质或非暂时机器可读介质中并将被存储在本地记录介质中的计算机代码,从而在此描述的方法可被存储在使用通用计算机、专用处理器或者可编程或专用硬件(诸如ASIC或FPGA)的记录介质上的这样的软件处理。可以理解,计算机、处理器、微处理器控制器或可编程硬件包括可存储或接收软件或计算机代码的存储组件(例如,RAM、ROM、闪存等),当所述软件或计算机代码被计算机、处理器或硬件访问且执行时,实现在此描述的图形编程作品检查方法。此外,当通用计算机访问用于实现在此示出的图形编程作品检查方法的代码时,代码的执行将通用计算机转换为用于执行前述实施例中方法的专用计算机。
与现有技术相比,本申请实施例的技术方案具有以下有益效果:
一方面,本申请实施例中智能外呼系统通过预设场景模板,以根据不同业务需求加以选择启用,并通过在会话中分析用户意图在所述场景模板对应的多个流程节点中形成流程,确定相应播报话术,既达到了灵活根据业务需求进行适配的外呼应用业务场景的选择,同时通过精细化的流程节点和意图分析,达到精准的会话效果,良好解决现有技术中的问题。
另一方面,本申请实施例的智能外呼系统中可以使用一种或各种类型的传统模型、深度学习模型等进行用户意图的分析,具有更好的场景通用性并兼顾会话精准性。
再一方面,本申请实施例的智能外呼系统中,可在系统架构上可对语音/文本相互转换的模块的形式进行了独立模块划分,并使用可插拔连接方式,使得划分后的不同功能模块能承接不同的服务需求,达到更高的使用效率。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。计算机程序产品包括一个或多个计算机程序。在计算机上加载和执行计算机程序指令时,全部或部分地产生按照本申请的流程或功能。计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。计算机程序可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输。
例如,图2、3、10实施例等中的各个功能单元可以是软件实现;或者也可以是软硬件配合实现,例如通过计算机系统实施例中的处理器运行存储器的计算机程序实现;或者,也可以是通过硬件电路实现。
此外,在本申请各个实施例中的各功能单元可以集成在一个处理部件中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个部件中。上述集成的部件既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。上述集成的部件如果以软件功能单元的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读存储介质中。该存储介质可以是只读存储器,磁盘或光盘等。
例如,图2、3、10实施例中各个功能单元可以是独立、单一的程序实现,也可以是一程序中的不同程序段分别实现,在某些实施场景模板中,这些功能单元可以位于一个物理设备,也可以位于不同的物理设备但相互通信耦合。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包括于本申请的至少一个实施例或示例中。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或隐含地包括至少一个该特征。在本申请的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的单元、片段或部分。并且本申请的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能。
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。
例如,图12实施例中的智能外呼方法等,其中的各个步骤的顺序可以在具体场景模板中加以变化,并非以上述描述为限。
虽然本说明书实施例披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本说明书实施例的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 智能外呼系统、方法、计算机系统及存储介质
- 基于人工智能的外呼方法、外呼装置、计算机设备及存储介质