训练数据中心硬件实例网络
文献发布时间:2023-06-19 10:14:56
优先权声明
本申请要求于2018年6月22日提交的美国专利申请序列第16/016,362号的优先权的权益,该美国专利申请的全部内容通过引用并入本文中。
背景技术
任何规模的数据中心的构建、操作和维护都是复杂的。将各种类型的技术与技能、团队、工具、互操作性相结合在逻辑上具有挑战性。使数据中心全面运行可能需要随着时间逐步进行改进。到数据中心全面运行时,复杂性可能会使得很少有人了解所有方面,并且针对业务需求进行重新配置或引入新技术可能与原始构建相比在规模方面具有同等或更大的挑战。
例如,现代数据中心通常包括服务器网络,服务器网络可以通过Web协议、语言平台、可以为用户提供完整桌面的虚拟机或提供微服务的容器化应用中的多种中的任一种来提供对应用工作流的客户端访问。典型的数据中心硬件资源可以包括:服务器、网络组件和存储体。服务器管理应用工作流并对客户端请求进行响应。网络交换机与数据中心服务器耦接以管理工作流。网络路由器执行分组转发功能。网络网关可以用作数据中心网络与因特网之间的连接。存储体存储由服务器使用以提供应用工作流的信息。数据中心可以支持多种不同的应用工作流。
数据中心管理涉及:监测数据中心工作流需求并响应于客户端需求的变化来调整针对不同应用工作流的数据中心资源分配。数据中心可以包括:一个或更多个控制器,用于配置、监测以及划分硬件资源;协调器,管理如何在硬件资源之间部署或分配软件和服务;以及在数据中心内运行的应用软件本身。存在来自这些硬件资源、控制器、协调器和应用的许多数据,数据中心操作员监测这些数据以管理资源分配、故障查找、优化性能和计划增长。这些数据通常由专注于一个或另一个功能领域的工具收集,并由该特定功能领域的领域专家进行解析。汇总来自不同功能区域的所有数据并将其收集到大型(也许是巨大的)数据库中并不难,但是对如此庞大的数据集的解析可能成为指数级的挑战,不仅是由于数据的大小而且还是由于使用数据所需的复杂性以及跨领域知识。随着数据中心的大小和复杂性的增长,单独的人类在以有用的实时方式使用这些数据方面面临日益增长的挑战。
附图说明
图1是根据一些实施方式的数据中心硬件实例的说明性框图。
图2是根据一些实施方式的包括数据中心硬件实例的网络的示例数据中心网络(DCN)的说明性表示。
图3是表示在主操作系统上运行的示例容器的说明图。
图4是表示用于部署和管理容器的系统的说明性框图。
图5是根据一些实施方式的配置有容器的图2的示例DCN的说明性表示。
图6是表示根据一些实施方式的将探测逻辑实例配置成监测和存储网络流量数据和事件发生的方法的说明性第一流程图。
图7是表示根据一些实施方式的网络数据存储器实例和存储在其中的示例探测数据结构的说明图。
图8是表示根据一些实施方式的向量的示例时间序列的说明图。
图9是表示根据一些实施方式的将主设备配置成从数据中心硬件实例的集群收集探测向量以产生时间序列向量的方法的说明性第三流程图。
图10A是表示根据一些实施方式的将计算机系统配置成产生自标记的训练数据的方法的说明性第四流程图。
图10B是表示根据一些实施方式的将计算机系统配置成产生自标记的训练数据的方法的说明性第五图。
图11是表示根据一些实施方式的包括第一组自标记的带标记的探测向量快照训练数据的示例快照数据结构的说明图。
图12是表示根据一些实施方式的包括第二组自标记的带标记的探测向量快照训练数据的示例快照数据结构的说明图。
图13是表示根据一些实施方式的包括第三组自标记的快照训练数据1300的示例快照数据结构的说明图。
图14是表示根据一些实施方式的被配置成基于带标记的训练探测向量快照来训练推断引擎以预测网络状况的监督学习系统的说明图。
发明内容
数据中心包括可以被聚类以共享数据中心功能的多个物理计算实例例如物理设备。可以同时探测多个不同实例的组件以产生探测向量,所述探测向量包括以时间增量的序列指示不同实例的组件的状态的数据值序列。探测向量可以指示事件的发生。一个或更多个快照数据结构包括包含在可能发生一个或更多个事件之前的数据值序列的不同子序列的多个快照,并且表示在一个或更多个事件发生之前的一组时间间隔序列期间在数据中心网络内的一个或更多个集群内的多个节点的多个组件的同时物理状态。一个或更多个数据结构可以用作机器学习训练数据,以基于在实时数据中心操作期间收集的探测数据训练推断引擎以预测事件。
在一个方面,一种系统被配置成产生用于训练推断引擎以预测数据中心中的事件的训练数据集。该系统包括至少一个处理器和至少一个存储设备。该存储设备包括所存储的指令,所述指令可被至少一个处理器访问和执行。第一指令在被执行时产生与至少一个数据中心硬件(DCH)实例的多个相应组件对应的多个探测向量。探测向量包括数据元素的时间顺序的序列。数据元素具有指示在对应的时间增量序列期间与探测向量对应的相应组件的状态的值。探测向量指示在与一个或更多个探测向量对应的一个或更多个相应组件处的一个或更多个事件的发生,并且指示与一个或更多个事件对应的一个或更多个发生时间。第二指令产生一组训练快照。该组训练快照的多个相应训练快照包括来自一个或更多个探测向量的数据元素的相应子序列。数据元素的子序列包括与时间增量对应的相应最新数据元素,所述时间增量不迟于与一个或更多个事件中的至少一个事件对应的指示的发生时间而发生。
具体实施方式
A.介绍
在一些实施方式中,数据中心网络(DCN)200可以以功能相同的物理计算实例来递增地构建,所述物理计算实例可以被实现为数据中心硬件(DCH)实例200a至200f,每个数据中心硬件实例包括服务器102、网络电路104和存储体106。各个硬件实例200a至200f的网络电路可以被配置成分别管理其自身加入(onboarding)到DCN 200。可以部署、管理和扩展容器化应用,以定义由数据中心硬件实例的集群提供的服务器级服务和网络级服务两者,从而简化数据中心管理。DCH节点实例的网络电路104可以用作节点的群集,以部署和管理容器化网络级应用以共享网络相关的任务。每个网络电路将容器化应用实例托管在通用主操作系统上。因此,DCN 200去除了在一般数据中心中已成为标准的层抽象上的典型层,从而也简化了数据中心管理。
参与节点的集群以部署和管理容器化网络级应用的网络电路产生指示节点事件的探测数据702。探测信息可以用于生成指示DCN 200内的网络相关事件的探测向量800的集合。可以基于探测向量产生自标记的带标记的探测向量快照训练数据。推断引擎可以使用快照训练数据来预测关注的网络状况的发生。如本文所使用的,术语“快照”是指与由一个或更多个探测向量跨越的时间增量的子序列对应的一个或更多个探测向量的数据元素的子序列。
B.数据中心硬件实例
图1是根据一些实施方式的数据中心硬件(DCH)实例100的说明性框图。DCH实例100包括主机服务器(S)102、网络交换机/路由器电路(以下称为“网络电路”)(X)104、永久性存储体(V)106以及将它们互连的通信总线107。主机服务器102包括主处理器系统108,该主机处理器系统108可以包括耦接以通过总线107通信的一个或更多个主机CPU 110和主机服务器存储器112。主机存储器112可以包括例如用于配置主机CPU 110以提供应用工作流服务的可执行指令和数据。网络电路104包括网络控制器114,网络控制器114包括可配置交换逻辑114S,可配置交换逻辑114S用于确定在包括交换结构118的输入队列117I和输出队列117O的多个物理接口端口116之间的分组的交换,并且网络控制器114包括用于确定发送至网络上的分组的路由的可配置路由逻辑114R、用于监测分组流并探测网络事件的发生的可配置探测逻辑114P,并且网络控制器114包括用于管理在DCH实例的集群内部署的,并且在一些实施方式中还在与其耦接的通用机内部署的容器的容器部署和管理逻辑114D(‘容器逻辑114D’)。在一些实施方式中,网络控制器114可以包括存储设备122中的指令以将其配置成实现交换逻辑114S、路由逻辑114R、探测逻辑114P和容器逻辑114D的功能。探测逻辑114P可以将多个探测逻辑实例114Pi实例化以产生对应的探测向量。在一些实施方式中,网络控制器114可以包括一个或更多个硬件CPU(未示出)以执行与交换、路由、监测以及容器相关的功能中的一个或更多个。可替选地,网络控制器114可以包括驻留在可从主机服务器102获得的计算资源中的软件应用。网络电路104还包括网络数据存储器122,该网络数据存储器122被耦接以存储网络性能相关的信息。在一些实施方式中,网络电路104可以被实现为一个或更多个专用集成电路(ASIC)。例如,存储体106可以包括磁盘存储器124和/或闪存126。
DCH实例100可以单独地用作独立的数据中心。更具体地,DCH实例100包括用于提供应用服务的服务器(S)、用于提供被用于提供服务的信息的存储体(V)以及用于与客户端设备(未示出)传送信息分组的交换机/路由器(X)。因此,例如,典型数据中心的功能可以被封装在单个DCH实例100内。
C.数据中心硬件实例网络——物理组件
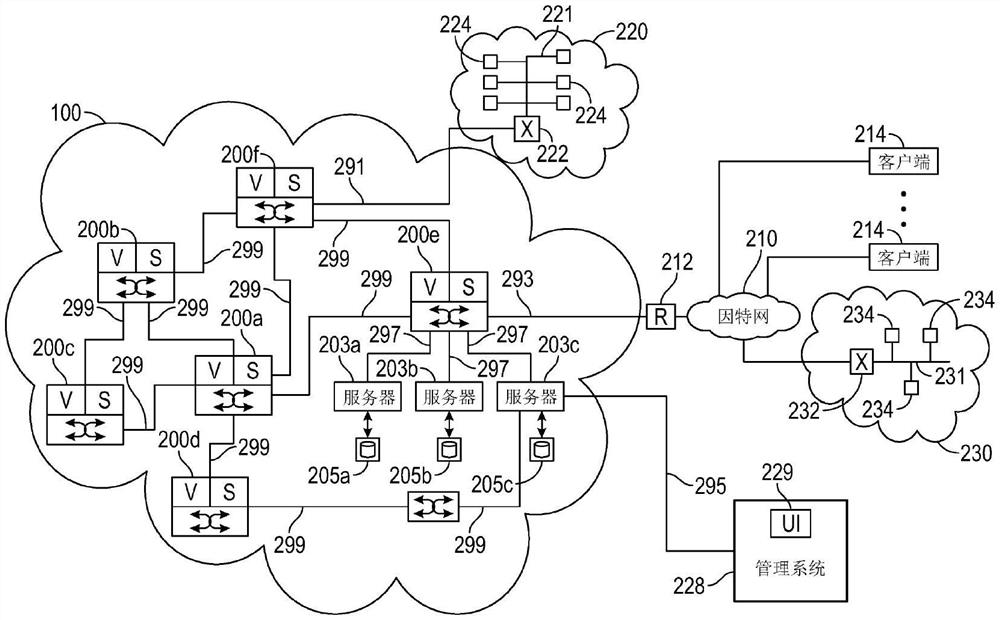
图2是根据一些实施方式的包括DCH实例的网络的示例数据中心网络(DCN)200的说明性表示。DCN 200包括经由分组交换或路由的网络中的网络连接299耦接的多个DCH实例200a至200f。如下面参照图5更全面地解释的,DCH实例200a至200f的网络电路104部分可以被配置成用作“节点”的“集群”,因此,DCH实例在本文中也可以被称为“节点”。每个DCH实例200a至200f可以如在图1中描述的那样被配置成包括服务器(S)、网络电路(X)和存储体(V)。交换机/路由器(X)可以被配置成实现以太网分组交换和/或IP路由网络协议。交换机/路由器(X)也可以被配置成支持MPLS协议或VXLAN协议。经由网络连接295耦接至服务器203a的管理员计算设备228包括管理用户接口(UI)229,以监测DCN活动并响应于例如应用工作流需求的变化来重新配置DCN 200的组件。如下面更全面地解释的,在一些实施方式中,服务器(S)和交换机/路由器(X)的重新配置可以通过容器化服务的分配和管理来实现。不同的DCH实例可以被配置成具有不同级别的计算、存储和交换机/路由器功能。
示例DCN 200还包括通用(例如,常规的)交换机/路由器201和通用服务器203a、203b、203c,通用服务器203a、203b、203c经由网络连接297耦接至如图2所示耦接的相应通用存储体205a、205b、205c,上述在本文可以被称为“通用”组件。DCH实例200a至200f和通用组件201、203a至203c、205a至205c之间的共同点是它们运行共同的操作系统,在一些实施方式中,该共同的操作系统包括本地Linux操作系统。在示例DCN 200中,通用服务器203a至203c及其存储体2005a至2005c耦接至DCH 200e,DCH 200e可以操作以将通用服务器及其存储体配置成用作集群内的节点,如下面更全面地解释的,其中通用服务器及其存储体与它们耦接至的DCH 200e共享其计算和存储能力。
DCN 200可以被配置成通过因特网210发送和接收信息分组。经由网络连接293耦接至DCH 200e的路由设备212例如可以被配置成通过因特网210在DCN 200与一个或更多个第一客户端设备214(例如膝上型计算机或移动计算设备)之间发送和接收分组。DCN 200还可被配置成在包括第一本地网络221(例如LAN)的第一专用网络220之间发送和接收分组,以与耦接至第一本地网络的第二客户端设备224传送分组。经由网络连接291耦接至DCH200f的交换机/路由器222(可以用作防火墙)例如可以耦接DCN 200与一个或更多个第二客户端设备224之间的分组。DCN 200还可以被配置成在包括第二本地网络231(例如第二LAN)的第二专用网络230之间发送和接收分组,以与耦接至第二本地网络231的第三客户端设备234传送分组。可以用作例如防火墙的交换机/路由器232可以耦接因特网210与一个或更多个第三客户端设备234之间的分组。于2017年3月31日提交的标题为“HeterogeneousNetwork in a Modular Chassis”的共同拥有的美国专利申请序列第15/476,664号、于2017年3月31日提交的标题为“Priority Based Power-Off During Partial Shutdown”的共同拥有的美国专利申请序列第15/476,673号以及于2017年3月31日提交的标题为“Modular Chassis with Fabric Integrated into the Line Card”的共同拥有的美国专利申请序列第15/476,678号(上述所有美国专利申请的全部内容通过该引用明确地并入本文)公开了根据一些实施方式的分布数据中心网络200的实现方式。
多个DCH实例200a至200f被配置成与DCN 200协同工作。更具体地,多个DCH实例200a至200f的各个服务器(S)、各个存储体(V)和各个网络电路(X)共同起作用,以与客户端设备214、224和234传送信息分组。DCN 200的总体容量可以通过渐进地耦接更多数量的DCH实例以增加服务容量并通过渐进地耦接更少数量的DCH实例以减少服务容量来动态地缩放。
每个DCH实例200a至200f包括容器逻辑114D,该容器逻辑114D包括用于流线化(streamline)向DCN 200添加实例的嵌入式系统软件。在一些实施方式中,容器逻辑114D可以将网络控制器114配置成管理将实例加入到DCN 200。从新添加的DCH实例的第一次加电开始,嵌入式容器逻辑114D管理操作系统软件(例如,本地Linux)以及嵌入式系统、逻辑114D本身的网络发现、下载和配置。容器114D可以将DCH配置成参与在容器化应用的管理中进行协作的机器集群。容器逻辑114D还可以将耦接至DCH(诸如DCH 200e)的通用服务器(诸如通用服务器203a至203c)配置成参与在容器化应用的管理中进行协作的机器集群。交换/路由/容器功能作为操作系统资源(例如作为Linux资源)向操作系统(例如Linux)公开,该操作系统任何标准应用都已经可以利用而无需知道它正在DCH实例上运行。因此,交换/路由/容器逻辑可以在这样的DCH或通用机器上运行,而无需修改DCH的或机器的基础操作系统。通过在其网络控制器114内运行的嵌入式操作系统,例如,DCH实例100的网络电路(X)104组件可以自行安装并自行配置,以加入DCN实例的集群,该集群耦接在DCN 200中并被配置成协同提供例如与容器化网络相关的应用。
D.容器化
图3是表示在主机操作系统304上运行的示例容器302的说明图。容器302包括多个应用服务实例306以及二进制文件和库308,以访问在主机操作系统304上运行应用服务所需的计算机资源(例如CPU和RAM)。更具体地,示例容器302包括在操作系统304的内核内实例化的应用服务302的虚拟化实例。容器302将应用服务306与操作系统304和用于连接至网络的物理基础结构(未示出)分开。在容器304内运行的应用实例306只能看到分配给它们的操作系统资源。根据一些实施方式,与仅能访问虚拟资源相反,所分配的操作系统资源可以允许容器访问物理网络资源。
通常,可以通过共享操作系统资源来使用容器以较低的开销运行分布式应用。可以在操作系统内核内实例化几个容器,并将计算机资源的子集分配给每个这样的容器。应用可以被封装为一个或更多个容器的集合。可以将应用作为高级系统即服务(SaaS)提供给用户。将应用及其服务扩展在许多容器上提供了更好的冗余性、更好的可移植性,并为应用提供了服务于更多用户的能力。在单个容器中,可以存在多个构建块应用,例如软件封装/库、工具等,来帮助形成更高级别的应用。可以响应于对应用服务的请求的增加而按照高效工作流管理的需求在数据中心网络的服务器之间创建和分配容器,并且可以响应于对应用服务的请求的减少来终止容器。
E.容器部署和管理
图4是表示用于部署和管理容器的系统的说明性框图。虽然以下描述作为示例使用通常用于描述用于使容器操作自动化的“kubernetes”平台的术语,然而可以按照本文公开的原理使用其他类型的容器自动化平台来部署和管理容器。Kubernetes是开源系统,其用于跨多个主机管理容器化应用,提供用于应用的部署、维护和扩展的基本机制。(参见,https://kubernetes.io/docs/home)Kubernetes平台将机器(称为“节点”)的集群协调作为单个整体工作。容器化应用可以被部署到集群中,而不必专门将它们绑定到各个节点。可以将应用封装为容器,以将它们与各个主机去耦接。Kubernetes将在节点的集群上的对应用容器的分配、调度和扩展自动化。
主设备例如通用服务器203a(或DCH实例200a至200f之一或其他通用服务器203b至203c之一)可以被配置成提供容器部署和在主机操作系统404的实例上运行的主模块402。在替选实施方式中,主“设备”可以被实现为跨多于一个服务器和/或DCH的分布式服务。一个或更多个工作节点406各自包括一个或更多个pod 408,每个pod包括在主机操作系统404的实例上运行的一个或更多个容器410。如本文所使用的,“节点”是指工作机器,其可以是物理实例例如DCH实例200a至200f之一,或者可以是虚拟机(未示出),所述虚拟机可以在它们的一个或更多个上被实例化。如本文所使用的,“pod”是指部署到单个节点的一个或更多个容器的组。pod内的容器410共享工作节点资源,例如诸如CPU和RAM。诸如管理员计算机228的管理员机器可以向主设备/计算机203a提供指示期望的部署定义状态的命令,以在包括物理机或虚拟机的节点上调度和运行容器。主设备/计算机203a协调节点406的集群。它根据管理员计算机228提供的部署定义来控制一个节点406或节点406的集群内的一个或更多个pod 408内的容器的组的实际部署调度和运行。在一个或更多个节点变得不可用的情况下,它还控制部署的复制。
pod 408可以在容器410与操作系统404之间提供接口层412。接口层412可以用于调度容器工作负荷并用于在容器410之间分配共享的CPU、交换机/路由器和存储资源。接口412也可以使得更容易地在节点之间迁移容器。每个pod 408包括代理414,以向主设备/计算机203a报告关于pod 408内的容器410的状态信息,该主设备/计算机203a可以将状态提供给管理员计算机228。
节点通常包括外部IP地址(IP
主机/计算机203a监测已部署的pod 408和容器410的状态。例如,它可以通过进行校正来响应实际部署状态与期望部署定义状态之间的差异,校正诸如自动添加节点以替换已经离线的节点以及自动创建新的pod和容器以自动替换已经消失的节点的pod和节点。例如,主机/计算机203a可以提供负载平衡服务以在容器410之间分配工作流。
F.数据中心硬件节点集群-容器化应用
图5是根据一些实施方式的被配置为具有容器化应用的节点的集群的图2的示例DCN 200的说明性表示。DCH实例200a至200f的服务器配置有容器,以向示例客户端214、224、234中的一个或更多个提供应用服务。容器A、B和C可以直接地或在虚拟机(未示出)上在一个或更多个DCH实例的物理服务器(S)102的CPU 108上运行。容器N可以在DCH实例的交换/路由电路(X)104的网络控制器114上运行。
管理员计算机228可以被配置成向服务器203a提供指示用于相应容器A、B、C和N的部署定义A至C和N的命令,服务器203a可以被配置成用作主设备。更具体地,主设备/服务器203可以配置有主模块240,主模块240使用部署定义A至C和N来管理容器A、B、C和N的部署调度以及运行和缩放。根据一些实施方式,200内的DCH设备或通用服务器中的任何一个可以被配置成用作主模块。此外,主模块可以是跨多个服务器和/或DCH的分布式服务。因此,主模块不必是固定的、专用的、特定的机器。如果用作主模块的机器发生故障,则DCH或通用服务器中的任何一个都可以接管主功能。
在示例DCN 200中,主模块240使用定义A来管理包括200a、200b、200c、200e和200f的DCH实例的第一集群的配置,以托管具有应用服务“A”的容器(容器A)的实例。通用服务器203还被配置成运行容器A。主模块240使用定义B来管理包括200a、200c和200d的DCH实例的服务器的第二集群的配置,以托管具有应用服务“B”的容器(容器B)的实例。主模块240使用定义C来管理包括200a和200d的DCH实例的服务器的第三集群的配置,以托管具有应用服务“C”的容器(容器C)的实例。例如,主模块240使用定义N来管理包括200a至200f和通用机203b、203c的DCH实例的交换机/路由器的第四集群的配置,以托管具有应用服务“N”的容器(容器N)的实例。
例如,容器A、B和C可以提供基于服务器级容器的业务、个人或娱乐服务。容器N提供基于网络级容器的服务。定义N可以用于部署和管理以与例如参照图4所描述的部署和管理其它应用级服务和微服务的方式相同的方式提供网络服务的容器。
G.监测和探测网络性能
DCN 200的DCH实例200a至200f的网络电路(X)104位于数据中心流量的联网路径中。此外,耦接至DCH 200e的通用服务器203a至203c位于数据中心流量的联网路径中。各个DCH实例的探测逻辑114P监测并记录用于关注的事件的发生的网络流量。例如,可以在网络电路104内创建多个探测逻辑实例114Pi,以探测多个不同的组件,例如在给定的DCH上运行的不同的硬件元件或不同的应用程序(包括微服务)。容器化应用N可以由主设备203a根据定义N来分布,以将各个网络电路104配置成实现探测逻辑114P。如下面更全面地解释的,网络定义N可以将DCH配置成包括探测逻辑114P,以不仅访问集群数据,而且解析、整理、聚集和存储数据。例如,各个探测逻辑实例114Pi可以对分组进行采样以从分组报头收集统计数据,即确定正在通过DCH实例200a至200f流动的内容。用于探测关注事件的探测逻辑可以由管理员配置。在一些实施方式中,每个DCN的网络电路每秒可以访问大约15000个数据点。
图6是表示根据一些实施方式的将探测逻辑实例114Pi配置成监测和存储网络流量数据度量和事件的发生的方法的第一流程图600。网络控制器114可以根据程序指令被配置成根据图6的过程来监测和存储网络流量数据度量和事件的发生。数据流量度量可以指示在每个时间增量的顺序序列期间的DCH组件的状态。将理解的是,探测逻辑实例114Pi可以被配置成提供第一流600的多种不同的实现,每个实现都针对产生用于不同的DCH组件的度量和事件。DCH实例200a至200f的网络电路104的各个网络控制器114可以根据第一流程图F00来进行配置。第一探测块602接收由DCN的网络控制器114在时间增量内在DCN 200上接收的网络数据。在一些实施方式中,例如,接收数据可以包括根据网络协议接收网络分组。在一些实施方式中,时间增量可以是每秒,并且该增量可以例如根据事件的类型以及精度与资源(计算/存储)利用率之间的折衷来增加或减少。第二探测块604产生针对时间增量的网络数据流度量。第二探测块604可以解析、整理和/或汇总所接收的数据以产生网络数据流度量。例如,探测逻辑实例114Pi可以根据第二块604的实现来配置,例如以提供计数器对队列中的数据帧的数量进行计数,并产生指示在时间增量内填充的队列的百分比的度量值。例如,队列百分比度量值可以用作队列填充状态的指示,该队列填充状态指示队列中的帧数是否将很快超过某个阈值数。可替选地,探测逻辑实例114Pi可以根据第二块604的实现被配置成提供两个或更多个计数器来监测两个或更多个不同队列中的队列深度,并产生指示两个或更多个队列中的帧数的变化的度量值。例如,变化度量值可以用作两个或更多个队列的负载平衡状态的指示,该负载平衡状态指示变化是否将很快超过某个变化阈值。第三探测判定块606监测在时间增量期间规定状况的发生的度量。继续上面的示例,例如,如果队列中的帧数超过某个阈值数可能构成规定状况的发生,并且不同队列中的帧数的变化超过阈值可能会构成负载平衡事件。响应于当前时间增量期间事件的发生,探测块608在存储设备122内存储针对当前时间增量的事件的发生的指示。在块608之后或在判定块606之后,响应于确定在当前时间增量期间没有发生事件,控制流向探测块610,探测块610存储针对当前时间增量的网络数据流度量。
每个网络控制器114可以被配置成实现多个不同的探测逻辑实例114Pi,每个不同的探测逻辑实例接收DCN 200内的网络数据的不同部分,并且产生并存储指示在DCN 200的其部分处的网络数据流的不同网络数据流度量和事件发生。可以由不同的探测逻辑实例114Pi产生和存储的数据流度量的其他示例包括端口利用率、队列深度、队列丢弃、错误计数和数据管道中各个点处的丢弃计数、转发表、地址利用率和指示节点如何互连和划分以及如何在各个节点内对应用实例进行分组的集群网络拓扑结构。关注事件的其他示例包括:队列丢弃、负载平衡超过变化阈值、丢弃率超过规定阈值、协议健康检查失败以及延迟超过规定阈值。另一示例是查看采样分组的报头,以确定到来以及离开的IP地址;与历史数据进行比较,可以将异常标记为可能的安全漏洞或攻击。
图7是表示根据一些实施方式的实施存储在其中的示例探测向量P
DCH探测逻辑实例可以被配置成产生与DCH(或通用服务器)的端口组件相对应的探测向量,并且例如根据图6的第一流程600配置的相应探测逻辑实例(未示出)可以产生指示在时间序列t
因此,如下面更全面地说明的,参与集群的各个DCH可以使用其本地CPU资源来本地执行网络数据的收集和管理,以在将探测向量发送至聚合点用于更广泛的集群数据的查看之前生成探测向量。因此,由于每个DCH节点都包括CPU资源,因此对应于多个探测的数据处理会自动随群集的大小而缩放。此方法不同于集中式模型,在集中式模型中,随着群集大小的增长来分别地缩放“中央”计算。根据一些实施方式,由DCH对网络数据的预处理产生探测向量,探测向量提供本地事件的详细记录,并且由多个DCH产生的探测向量的集合又用作预处理数据,该预处理数据提供例如可以在训练网络管理系统以管理DCN 200时使用的网络行为的全局图。如以下参照图14所说明的,一旦基于探测向量训练推断引擎1404,则推断引擎1404可以响应于新数据1416实时地预测事件的发生。
H.汇总监测时间序列数据集和探测时间序列数据集
DCN 200的DCH实例200a至200f的网络电路(X)104被配置成将它们各自的探测向量P1至PX发布给主设备203a。在一些实施方式中,用于收集探测数据的主设备也可以是跨多个服务器或DCH的服务。此外,用于数据收集的主机不必与用于协调容器的主机相同。如上所述,在kubernetes环境中,容器410可以被分组在pod 408中,pod 408包括代理414以将关于pod 408内的容器410的状态信息报告给主设备/计算机203a。更具体地,在其中主机203a将DCH实例200a至200f的集群配置成托管实现探测逻辑114P的容器化应用“N”(容器N)的一些实施方式中,每个交换机/路由器104处的代理410将探测向量P
图8是表示根据一些实施方式的用于多个DCH的探测向量800的示例集合的说明图。图8中的每一列表示跨时间间隔t
图9是表示根据一些实施方式的将主设备203a配置成从DCH实例200a至200f实例的集群收集探测向量702的方法的说明性第三流程图。第一探测收集块902从DCN 200的DCH实例200a至200f中的每个DCH实例的每个网络控制器组件114接收探测数据702。主设备203a根据定义N将DCH实例200a至200f配置成用作节点的集群以托管应用N的实例。用作集群的节点的DCH实例200a至200f将其探测数据702发布给主设备203a。第二探测收集块904汇总所接收的探测数据702以产生探测向量的集合800。
再次参照图8,探测向量的说明性示例集合800提供了多维时间序列数据,在多维时间序列数据中每个探测向量表示包括数据值的时间序列的维。由探测向量的集合提供的多维时间序列数据可以提供如下信息:该信息可以用于指示例如节点如何互连和划分、如何平衡节点之间的网络流量负荷、集群中的拥塞点在哪里、正在通过集群的流量/流的类型。如下面更全面地说明的,在实时操作期间收集的探测向量的集合800可以用于训练推断引擎1404以预测网络事件的发生。
I.实时检测网络状况
探测向量702对应于物理硬件DCH实例的组件。各个DCH实例200a至200f包括硬件组件,例如端口、队列、表或管道。例如,各个DCH可以托管虚拟机,虚拟机包括虚拟组件,例如端口、队列、表或管道,这些虚拟组件是DCH的托管组件。例如,各个DCH实例200a至200f包括软件组件,比如可以实现应用子功能或微服务的应用程序或容器。各个DCH的探测逻辑实例114Pi本地产生指示各个DCH处的网络相关活动的探测向量。从各个DCH收集的探测向量的集合800提供了多维数据,这些多维数据共同包括提供指示网络相关功能的值的数据,这些网络相关功能发生在用作集群的节点的物理硬件DCH内或之间,例如队列丢弃、负载平衡、队列丢弃率、协议健康检查和分组延迟。
返回参照图2和图5,管理员可以在管理系统228的UI 229处观测多维数据。管理员可以例如通过经由直接阈值或算法监测来观测多维数据800内的值,从而来观测DCN 200的状态,或更具体地,观测节点200a至200f的集群的状态。在操作中,多维数据800可能包括以下维度:如果网络管理人员实时观测到这些维度,则如果不是彻底恐慌,也可能会引起严重的担忧,其会提示立即采取纠正措施,例如将流量重新定向到其他地方、关闭集群的多个部分、调试、隔离和/或其他缓解技术。管理员可以从多维数据800中挑选出时间增量或时间增量序列,并分析一个或更多个时间增量内的所有维度或维度的子集,以排除网络相关的错误(例如,丢弃、无法到达的节点/服务、高延迟)或针对与网络相关的性能以及非网络相关的性能进行优化(例如,通过改变与网络通信相关的算法来更好地实现负载平衡、通过来回移动应用来更好地利用资源、通过对集群网络进行不同的划分来更好地利用带宽、通过将数据移动到不同的缓存层来更好地利用存储资源)。
再次参照图7,例如,管理员可以经由UI 229实时观测到由(P
J.用于机器学习以预测网络状况的自标记训练数据
图10A是表示根据一些实施方式的将计算机系统配置成产生自标记训练数据的方法的说明性第四流程图1000。DCH或服务器可以根据程序指令被配置成根据图10A的过程产生自标记训练数据。如下面参照图13更全面地说明的,机器学习引擎1402可以被配置成基于自标记训练数据来训练推断引擎1404,以预先而不是在已经发生事件之后预测网络状况。第一块1002接收探测向量。例如,第一1002可以接收图7的探测向量P
第五块1010选择一个或更多个探测向量以包括在一组自标记的训练快照中。例如,根据一些实施方式,第五块1010可以基于事件的类型或基于事件的共同发生来选择要包括在一组训练快照中的探测向量的集合。一组训练快照可以包括不同的探测向量,这些探测向量包括不同的事件,以便涵盖某个时间范围内事件的共同发生。例如,入侵(例如黑客攻击)的检测可能与采样的IP地址和端口利用率高度相关,而与负载平衡变化或存储利用率较不太相关。例如,根据一些实施方式,第五块1010可以例如基于与发生事件的设备的网络接近度来选择要包括在一组训练快照中的探测向量的集合。网络接近度可以例如基于BGP对等设备、流路径内的节点、同一网络名称空间内的节点。例如,根据一些实施方式,第五块1010可以基于与事件的时间接近度来选择要包括在一组训练快照中的探测向量的集合。例如,拥塞事件可能与仅在事件的几秒钟之内的数据相关。
第六块1012产生包括多个训练数据快照的快照数据结构,其包括在不同范围内的所选择的探测向量的数据元素,所述不同范围可以在时间戳指示的时间之前延伸并延伸直到由时间戳指示的时间,并且还可以包括由时间戳指示的时间。每个快照都是数据结构,并且不同的快照可以包括来自相同的探测向量的集合但是在不同的时间范围内并且可能针对不同的DCH的时间序列数据元素。第七块1014标记与在块1006处确定的标签一致的快照。多个快照可以由下面描述的机器学习系统1502使用,该机器学习系统1502被配置成训练推断引擎1404以预测由第二判定块1004识别的状况,例如事件的发生。块1010、1012可以生成用于训练推断引擎1404以预先预测事件的发生的多个训练探测向量快照。
训练探测向量快照被称为“自标记”,因为它们的标记是基于第二判定块1004检测到训练数据集本身内的数据而产生的,指示关注的状况的发生。换句话说,探测向量本身包含由判定块1004识别的数据,该数据指示探测向量将被用作带标记的训练数据。因此,过程1000识别要被标记例如以指示关注的事件的探测向量,并生成多个对应的带标记的快照,这些快照可能包括探测向量或其部分的大得多的集合的子集,对应于不同的节点、事件和时间序列时间增量,以辅助训练。此外,将理解的是,主设备203a可以将探测向量的集合800的时间序列发送至单独的计算机系统(未示出),该单独的计算机系统根据第四流程图1000被配置成产生训练探测向量快照,这不需要实时发生。根据一些实施方式,“主设备”可以被实现为分布在集群内的软件过程。因此,主设备不必锁定到任何特定的机器,并且可以具有内置的冗余(即,具有多个容器的应用/过程),因此它可以容忍任何单个机器故障。
应当理解,数据结构包括多个训练快照,这些训练快照共同表示在一个或更多个事件发生之前的一组时间间隔期间在DCN 200内的一个或更多个集群内的多个DCH的多个组件的同时物理状态。如下所说明的,可以使用快照数据结构来训练推断引擎1404,以在可能在一个或更多个事件发生之前的一组实时时间间隔内预测DCN 200内的一个或更多个集群内的多个DCH的多个组件的实时物理状态。这样的预测可以用作采取纠正措施来避免一个或更多个预测事件的发生的基础。
图10B是表示根据一些实施方式的将计算机系统配置成产生自标记的训练数据的替选方法的说明性第五图1050。DCH或服务器可以根据程序指令被配置成根据图10B的过程产生自标记训练数据。如下面参照图13更全面地说明的,机器学习引擎1402可以被配置成基于自标记训练数据来训练推断引擎1404,以预先而不是在已经发生事件之后预测网络状况预测网络状况。
第一块1052在机器可读存储设备中提供多个不同组合事件集选择标准,以选择要针对其创建训练快照的一个或更多个事件的集。下表列出了事件选择的说明性示例标准。第一块1052可以被配置成提出包括组合的标准,组合可以包括例如事件类型、时间范围、硬件设备或软件过程中的一个或更多个。
表格-事件选择标准
第二块1054选择由第一块1052提供的一组事件选择标准。第三块1056基于当前选择的事件选择标准,针对一个或更多个事件的发生来扫描图8的探测向量的集合800。例如,当前选择的事件选择标准可以指示第三块1406针对队列丢弃事件与负载平衡超过变化阈值事件的共同发生来扫描探测向量的集合800。第四判定块1058确定当前选择的事件选择标准与探测向量的集合800内的一个或更多个事件内的事件之间是否存在匹配。如果当前选择的事件选择标准与探测向量的集合800内的一个或更多个事件内的事件之间不存在匹配,则控制流回到第二块1054,其可以选择由第一块1052提供的另一组事件选择标准。如果当前选择的事件选择标准与探测向量的集合800内的一个或更多个事件内的事件之间存在匹配,则第五块1060将标签与包含与事件选择标准匹配的事件的一个或更多个向量相关联。第六块1062将时间戳标记与匹配一个或更多个事件匹配标准的一个或更多个向量的关注的最新向量的发生时间相关联。训练数据可以包括在可以在关注的最新事件之前延伸并延伸直到关注的最新事件的不同时间范围内选择/匹配的探测向量的探测向量数据元素。但是,该训练数据的标签将引用组合事件,而不是单个最新事件。因此,在一些实施方式中,第六块1062将时间戳标记与探测向量内的数据序列元素处的向量探测相关联,所述探测向量在时间上对应于一个或更多个匹配事件之中最新发生的事件的发生。第七块1064选择一个或更多个探测向量以包括在多个自标记的训练快照中。第八块1066产生多个快照,所述多个快照包括在时间戳指示的时间处或时间戳指示的时间之前的不同范围内的所选择的探测向量的数据元素。第七块1064和第八块1066可以以例如以上参照图10A的块1010、1012所描述的方式选择探测向量并产生快照。第九块1068标记与在块1060处确定的标签一致的快照。多个快照可以由如下描述的机器学习系统1402使用,该机器学习系统1402被配置成训练推断引擎1404以预测由第二块1406、1058识别的状况诸如一组事件的发生。
图11是表示根据一些实施方式的示例快照数据结构1100的说明图,该示例快照数据结构1100包括根据图10A或图10B的过程产生的第一组带标记的快照训练数据。作为数据结构1100的组件的标签A 1103包括四个示例快照1102至1108,所述示例快照1102至1108共同表示在组件A处的队列丢弃事件之前的一组时间序列上的DCH 200a的组件A(未示出)的物理状态。快照数据结构1100包括在每个时间戳组件处的时间戳“T”1105,指示关注事件的发生时间,在这种情况下为t
注意,快照1108包括以下数据元素的子序列,该数据元素的子序列包括对应于时间增量t
图12是根据一些实施方式的表示示例快照数据结构1150的说明图,该示例快照数据结构1150包括根据图10A或图10B的过程产生的第二组自标记的快照训练数据。作为数据结构1150的组件的标签B 1153包括四个示例快照1152至1158,所述四个示例快照1152至1158共同表示在一组时间序列上的DCH 200a的组件B(未示出)的物理状态,该组时间序列在由在时间t
图13是表示根据一些实施方式的示例快照数据结构1300的说明图,该示例快照数据结构1300包括根据图10A或图10B的过程产生的第三组自标记的快照训练数据1300。作为数据结构1300的组件的标签C 1303包括十二个示例快照1302至1304,所述十二个示例快照1302至1304共同表示在一组时间序列上DCH 200a的组件C(未示出)的物理状态,该组时间序列在时间
事件之前的时序数据(例如,事件的时间戳之前的一个或更多个探测向量内的时序数据)可以提供与事件具有相关性和/或因果关系的数据。快照数据结构1100、1150、1300用时间戳标记并且被标记以指示相应的事件。数据结构1100、1150、1300的训练快照组件可以用于训练推断引擎1404以预测事件的发生,从而例如可以在事件发生之前主动采取预防措施。对于预测的队列丢弃事件,预防措施可能包括例如重新定向流量、改变负载平衡方案、将应用(容器)移动到DCN 200内的不同位置、将流控制发送至主机(即服务器)或存储目标、速率限制端口、对网络进行不同的划分。对于预测的负载平衡超出变化阈值事件,预防措施可以包括例如改变负载平衡方案、将应用(容器)移动到200内的不同位置、在DCN 200内重新分配IP寻址方案、对网络进行不同的划分。
自标记的带标记的探测向量快照训练数据包括在不同时间增量处的探测向量数据元素,以用于训练推断引擎1404以预先预测事件的发生。一组自标记的带标记探测向量快照训练数据内的不同快照包括在事件发生之前的不同时间增量范围。可以基于事件发生之前的一个或更多个探测向量的时间元素数据来预测在给定时间增量处的事件的发生。一组快照训练数据包括不同的时间增量范围,该时间增量范围包括不同的最新时间的时间增量。因此,一组快照训练数据可以包括快照的时间序列,在快照的时间序列中快照覆盖不同的时间增量范围,在不同的时间增量范围中序列中的每个快照具有与该序列中的下一快照的最新时间增量不同的最新时间增量。在一些实施方式中,快照序列中的每个快照具有最新时间增量,所述最新时间增量在时间上早于该快照序列中的下一快照的最新时间增量。在一些实施方式中,除了序列中的最后一个快照之外的每个快照具有最新时间增量,所述最新时间增量在时间上迟于该序列中的至少一个其他快照的最新时间增量。由于数据变得与事件不相关,因此产生在时间上倒退太多的带标记的训练探测向量快照不太可能进一步改善机器学习引擎的训练,并且可能损害准确性并产生假阳性。因此,可能需要对训练集在时间上倒退的程度进行限制或约束。可能需要在预测准确性与推断引擎提前多久预测关注状况之间进行权衡。
自标记的带标记的探测向量快照训练数据可以包括来自探测向量的不同组合的数据元素,因为某些探测向量可能比其他探测向量更能预测事件的发生。此外,由于探测向量可能非常大,因此机器学习算法所需的训练时间和所需的计算能力可能变得太大或太昂贵。可以减少用于训练的多维时间序列向量内的数据量,以得到每个时间戳上的更小维度的训练数据,同时针对可预测性来保持要包括的倒退的历史时间增量的数量。关于特定于状况进行训练时要包括哪些数据,管理员可以合理地应用某些先验情报(intelligence)。带标记的训练探测向量快照的大小不必对于每种状况都相同。因此,尽管构建训练数据所根据的探测向量的集合800可能不会改变,但是针对特定标签/状况的训练集所包括的数据可能会变化。
在某些情况下,可以从探测向量中省略数据,这不仅是为了减少机器学习的收敛时间,而且是为了提高准确性。例如,通过从训练数据中移除已知的不相关维度,可以为机器学习算法提供更少的“噪声”,并且可以进行更准确的预测。
K.机器学习以预测网络状况
图14是表示根据一些实施方式的监督学习系统1402的说明图,监督学习系统1402被配置成基于带标记的训练探测向量快照来训练推断引擎1404以预测网络状况。随着生成大量探测向量(每秒每个节点可能包括数万个探测向量),可能无法在人类时间执行实时网络分析以识别网络状况的发生。同样,机器可能无法基于当前可用的监测和探测时间序列数据集以公式化的提议措施(例如,警报、警告、预测、动作)实时(例如,毫秒级)了解网络状况。根据一些实施方式,机器学习可以被应用以从包含在探测向量内的历史数据中学习以基于这样的数据产生推断模型以预测网络状况的发生。在一些实施方式中,推断模型可以包括传递函数,该传递函数可以接收多维向量作为输入并且可以提供网络状况的指示作为输出。
机器学习引擎1402可以包括根据机器学习(ML)算法1406配置的计算机系统1403。推断引擎1404可以包括根据传递函数1414配置的计算机系统1405。例如,算法1406,例如决策树、朴素贝叶斯分类、最小二乘回归、SVM、PCA、ICA或聚类,用于训练事件发生预测传递函数1414以检测事件的发生。如图14所示的监督学习系统1402接收带标记的训练探测向量快照1412。在训练期间,可以包括在多个时间增量上产生的多个探测向量的未带标记的训练向量1410,以及带标记的训练探测向量快照1412可以被输入至ML引擎1402以训练推断引擎1404。在推断期间,新数据1416,新数据1416是“新的”,因为尚未将其用于训练。新数据1416可以包括在多个时间增量上的实时探测向量数据,实时探测向量数据已经被转换为新的探测向量1418,探测向量1418被提供给推断引擎1404以基于传递函数1414产生指示预测状况例如诸如事件的推断值。在一些实施方式中,主设备203a可以被配置成包括推断引擎1404。主设备203a还可以被配置成接收新探测向量800作为新数据1416,新数据1416包括新向量1418,例如用于DCH 200a至200f的探测向量P
预测传递函数可以在多个时间增量的滚动窗口上接收多维向量1418作为输入,并且可以预测在将来的一定数量的时间增量处是否会发生状况。如果输出为正(将发生状况),则可以采取一些步骤以在状况发生之前避免该状况。可能采取的步骤/动作的示例包括改变一个或更多个盒子(box)上的负载平衡算法、改变应用的部署位置、将以太网暂停帧发送至直接附接的服务器或存储设备以及关闭链路。
呈现以上描述是为了使本领域的任何技术人员能够制造和使用用于对运行或托管应用的节点的数据中心集群的训练数据进行自标记的系统和方法。实施方式的各种修改对于本领域技术人员将是明显的,并且在不脱离发明的精神和范围的情况下,本文中定义的一般原理可以应用于其他实施方式和应用。在前面的描述中,出于解释的目的阐述了许多细节。例如,电外科信号发生器电路可以包括配置有指令的单个处理器,以运行单独的过程来控制封闭器阶段和解剖阶段。然而,本领域普通技术人员将意识到,可以在不使用这些特定细节的情况下实践本发明。在其他情况下,以框图形式示出了众所周知的过程,以免不必要的细节使本发明的描述不清楚。相同的附图标记可以用于表示不同附图中相同或相似项目的不同视图。因此,根据本发明的实施方式的前述描述和附图仅是对本发明的原理的说明。因此,将理解,本领域技术人员可以在不脱离由所附权利要求限定的本发明的精神和范围的情况下对实施方式进行各种修改。
- 训练数据中心硬件实例网络
- 实例分割以及实例分割网络训练方法和装置、介质、设备