一种基于KDE-FA的冷水机组故障特征刻画方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于空调系统中冷水机组故障检测领域,具体涉及一种基于非参数核密度估计和因子分析(KDE-FA)的冷水机组故障特征刻画方法。
背景技术
冷水机组是暖通空调系统中的主要耗能设备,通过冷水机组的故障检测(FD),及时发现和识别故障,并作出相应决策,对实现空调系统节能,保持空调系统高能效运行和维持室内环境舒适度具有重要的工程意义和经济意义。
故障特征刻画主要包括故障数据特征选择和特征降维。选择合适的故障特征是FD的前提和关键,特征选择的好坏很大程度上决定了故障检测的性能。故障特征维度较高及特征之间具有信息冗余性是现有FD方法研究所面临的主要问题之一,这会导致维度灾难,增加工作量,需要更多的时间和空间,从而降低故障检测效率。
大多数现有FD方法通常以其检测性能最佳为原则选择表征故障的特征参数,这往往导致获取这些特征参数的传感器数量多、成本高。冷水机组现场传感器安装现状的调研结果显示:温度传感器是现场存在最多且成本较低的传感器,压力和流量传感器成本较高且现场大量缺乏。因此选择大量压力或流量特征进行FD工作不具备经济意义,基于成本进行特征刻画成为FD方法的出发点。
目前,在冷水机组故障检测技术中,故障特征刻画的传统技术途径有:1)考虑现场成本和特征敏感性进行特征选择;2)基于PCA等方法进行特征降维。然而,上述两条传统途径常常存在两大问题:1)不能完全从样本数据本身出发,反映故障特征的真实分布,从而导致对FD有用的敏感特征可能被遗漏;2)原始变量和公共因子之间的关系无法得到较好解释,提取出来的主成分无法清晰地解释其代表的含义。
发明内容
为解决现有技术中存在的上述缺陷,本发明提出了一种基于KDE-FA的冷水机组故障特征刻画方法,根据该方法所确定的故障特征以及匹配的故障检测方法,在现场冷水机组故障检测应用中,既可以不遗漏有用的敏感特征,真实刻画故障数据特征,又可以降低特征维度,减少工作量,提高检测效率及精度,从而有效克服目前故障特征刻画存在的主要问题。
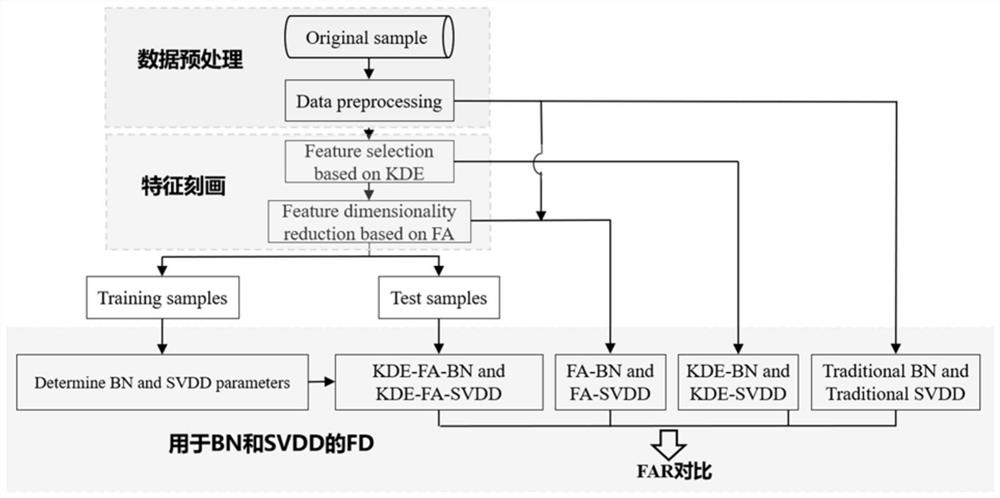
实现本发明的技术路径是:首先基于KDE进行敏感特征选择,然后基于FA进行特征降维,从而达到在不影响检测精度的条件下,以最少特征表征冷水机组故障的目的;最后基于KDE-FA方法建立特征刻画模型,并将此模型用于BN和SVDD的FD技术。其中,融入KDE-FA特征刻画方法的FD包括三个过程:1)数据预处理;2)特征刻画;3)故障检测过程。
本发明具体技术方案如下。
一种基于KDE-FA模型的冷水机组故障特征刻画方法,包括下述步骤:
步骤1:选用移动平均滤波器法对冷水机组原始故障数据进行平滑处理,然后选用计算几何加权运行平均值和几何加权运行方差的方法对平滑数据进行稳态筛选;
步骤2:采用KDE方法对稳态筛选后的故障数据进行故障特征选择:
步骤3:采用FA方法对KDE选择出的冷水机组故障特征进行特征降维,完成故障特征刻画工作。采用FA方法对KDE选择出的故障特征进行特征降维时,包括因子描述、因子提取、因子旋转和因子得分四个环节。
步骤4:构建KDE-BN模型、FA-BN模型及KDE-FA-BN模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价;
步骤5:构建KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价;
步骤6:分别将构建的KDE-BN模型、FA-BN模型及KDE-FA-BN模型与传统BN模型的检测性能进行比较,若正常状态被误判为故障状态的概率越低,则判定该FD方法效果越好;
步骤7:分别将构建的KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型与传统SVDD模型的检测性能进行比较,若正常状态被误判为故障状态的概率越低,则判定该FD方法效果越好。
本发明的有益效果是:
引入能反映故障特征真实分布的KDE方法从原始特征集中尽可能选择出所有敏感特征;引入能对原始变量和公共因子之间进行解释的FA方法大幅降低特征维度,且去除特征间冗余度;提出一种基于非参数核密度估计和因子分析(KDE-FA)的冷水机组故障特征刻画方法,以解决以上存在的技术问题。
本发明先基于KDE进行敏感特征选择,然后基于FA进行特征降维。在不影响检测精度的条件下,以最少特征表征冷水机组故障;然后基于贝叶斯网络(BN)和支持向量数据描述(SVDD)两个模型的FD方法对特征选择结果进行评价。
本发明提出的一种基于KDE-FA的冷水机组故障特征刻画方法,KDE方法基于敏感最大化的原则,尽量选出原始故障特征集中的所有敏感特征,相对于其他特征选择方法,所选出的敏感特征更多,保留信息更完整;FA方法去除了特征之间的冗余性,在保证不损失特征信息的基础上,大幅度降低特征维度,简化后续FD方法模型的结构复杂度;KDE-FA方法在实现特征维度降低的同时,保证FD方法模型的检测性能提高。
其中,KDE是一种不对故障数据总体做任何假设,完全从故障样本数据本身出发,估计故障数据总体概率密度函数的方法。将KDE应用于冷水机组FD的特征选择,能反映故障特征的真实分布,提高特征对故障类型的敏感分辨率;能刻画特征与故障类型之间的映射差异性。因此,该方法能够从原始故障特征集中尽可能选择出所有敏感特征。
FA是从故障特征中提取共性因子,根据数据的内在逻辑性将多个变量归纳为少数几个因子,从而进行降维处理,避免信息重叠。通过数学变换得到的新特征能够反映更多的原始信息;新特征和原始故障特征之间的可解释性较强,能够解释每个原始故障特征对每个新特征的贡献度。因此,该方法大幅降低特征维度,且去除特征间冗余度。
附图说明
图1为融入KDE-FA特征刻画方法的FD框架图;
图2为BN的结构图;
图3为SVDD的原理图;
图4为碎石图;
图5为三维因子空间的载荷散点图;
图6为四种BN模型的FAR对比;
图7为传统SVDD模型正常样本检测结果;
图8为KDE-SVDD模型正常样本检测结果;
图9为FA-SVDD模型正常样本检测结果;
图10为KDE-FA-SVDD模型正常样本检测结果;
图11为四种SVDD模型的FAR对比。
具体实施方式
下面结合附图和实施例对发明作进一步的详细说明,但并不作为对发明做任何限制的依据。
如图1所示,对本发明提出的一种基于KDE-FA的冷水机组故障特征刻画的具体实施步骤说明如下:
步骤1:本发明首先选用移动平均滤波器法对冷水机组原始故障数据进行平滑处理,然后选用计算几何加权运行平均值和几何加权运行方差的方法对平滑数据进行稳态筛选。
步骤2:采用KDE方法对稳态筛选后的故障数据进行特征选择。
采用KDE方法对冷水机组故障的稳态数据进行特征选择:
对于某一故障,设X
其中,K()称为某一故障的核函数,h称为某一故障窗宽或带宽,n为故障数据的样本容量。
核函数选择Gaussian核函数,故障的最优带宽h
其中,S为故障数据的样本标准差。
利用上述方法生成故障数据与正常数据的核密度对比图,然后基于尽量保证数据信息完整、尽量选择温度和压力参数以节约传感器成本两个原则,对核密度对比图中正常数据曲线与故障数据曲线的偏离度进行判断,最终选出故障的敏感特征,即为利用KDE方法所选出来的特征。
假设冷水机组有k类故障,每类故障有w个劣化等级,加上正常状况,则冷水机组共有wk+1种状况,假设每种状况可获得的特征参数有q个,均来自传感器。利用KDE方法对冷水机组的wk+1种状况的q个特征参数进行估计,共得到q(wk+1)个概率密度函数(pdf)估计图和累积分布函数(cdf)估计图。然后针对每一类故障的每一个参数,将w个劣化等级数据的pdf曲线与正常数据的pdf曲线进行对比,观察各劣化等级状况和正常状况之间的pdf曲线偏离度,进而判断此参数对此故障的敏感度,并作出决策是否选择此参数作为此故障的特征。
步骤3:采用FA方法对KDE选择出的冷水机组故障特征进行特征降维,完成故障特征工作。采用FA方法对KDE选择出的故障特征进行特征降维时,包括因子描述、因子提取、因子旋转和因子得分四个环节:
3a)在因子描述环节,进行Bartlett球形检验和KMO统计量检验;当Bartlett球形检验结果中的卡方统计量足够大、显著性值小于0.05、KMO统计量检验结果中的KMO大于0.5三个条件满足其一,则认为故障特征之间的冗余性较强,此时应采用FA方法进行特征降维;
3b)在因子提取环节,采用方差贡献率法和碎石图法确定公共因子的提取个数;因子提取后输出的公共因子能够反映全部数据信息的95%时,选取此时对应的故障特征的公共因子个数;碎石图中以曲线由陡峭变平缓的转折点为判断点,选取陡峭曲线对应的故障特征的公共因子个数;
3c)在因子旋转环节,当故障特征原始变量和提取出的公共因子之间的关系不确定时,采用正交旋转法对因子载荷矩阵进行旋转,使故障特征原始变量和公共因子两者之间的关系明确;对公共因子命名;
3d)在因子得分环节,确定每一样本在公共因子上的具体数值,将其作为新的变量运用于下一步模型构建;选择回归法确定正常状态和各故障状态在因子变量的数值
其中,A为因子载荷矩阵,∑为标准化故障特征原始变量的协方差矩阵,X为故障特征原始变量矩阵。
步骤4:构建KDE-BN模型、FA-BN模型及KDE-FA-BN模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价。
基于KDE-BN模型进行FD故障检测包括下述过程:
41a)确定KDE-BN模型结构:
如图2所示,用于FD的KDE-BN的结构包括:第1层检测层和第2层特征层;第1层中的节点代表冷水机组检测结果,即正常和故障状态;第2层中的节点由n个特征组成;
41b)确定KDE-BN模型参数:
包括每个根节点的先验概率和每个子节点的条件概率;第一层检测层的正常状态和故障状态的先验概率由专家经验或通过对维修服务的历史记录统计其发生频率确定;
第二层特征层中的特征节点的条件概率通过对历史数据采用KDE方法进行故障特征选择后,带入5维核密度函数估计得到,由下式确定:
其中,K()表示高斯核函数;h
41c)基于KDE-BN模型进行FD故障检测:
进行故障检测的规则如下:
其中,s为故障特征,F
基于FA-BN模型进行FD故障检测包括下述过程:
42a)按照步骤41a)的方法确定FA-BN模型结构;
42b)确定FA-BN模型参数:
包括每个根节点的先验概率和每个子节点的条件概率;第一层检测层的正常状态和故障状态的先验概率由专家经验或通过对维修服务的历史记录统计其发生频率确定;
第二层特征层中的特征节点的条件概率通过对历史数据采用FA方法进行故障特征降维后,带入5维核密度函数估计得到;
42c)按照步骤41c)的方法基于FA-BN模型进行FD故障检测。
基于KDE-FA-BN模型进行FD故障检测包括下述过程:
43a)按照步骤41a)的方法确定KDE-FA-BN模型结构;
43b)确定KDE-FA-BN模型参数:
包括每个根节点的先验概率和每个子节点的条件概率;第一层检测层的正常状态和故障状态的先验概率由专家经验或通过对维修服务的历史记录统计其发生频率确定。
第二层特征层中的特征节点的条件概率通过对历史数据先采用KDE方法进行故障特征选择,再采用FA方法进行故障特征降维后,最后带入5维核密度函数估计得到;
43c)按照步骤41c)的方法基于KDE-FA-BN模型进行FD故障检测。
步骤5:构建KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价:
基于KDE-SVDD模型进行FD故障检测包括下述过程:
51a)确定KDE-SVDD模型结构:
KDE-SVDD模型的结构是:将目标数据映射到高维空间,在高维空间构建出一个以a为中心R为半径且体积最小的超球体;
51b)确定KDE-SVDD模型参数:
对所有历史数据采用KDE方法进行故障特征选择后确定KDE-SVDD模型的参数;
51c)基于KDE-SVDD模型进行FD故障检测:
SVDD的原理如图3所示,KDE-SVDD模型的目标数据为冷水机组正常运行数据,SVDD判别方法即故障检测边界内为正常运行区域,边界外为故障区域;比较冷水机组的观测数据z到超球体中心距离D(z)与超球体半径R的大小来判断是否发生故障;若D(z)≤R,观测数据z在超球体内,判定为正常;反之,判定为故障。
基于FA-SVDD模型进行FD故障检测包括下述过程:
52a)按照步骤51a)的方法确定FA-SVDD模型结构;
52b)确定FA-SVDD模型参数:
对所有历史数据采用FA方法进行故障特征降维后确定KDE-SVDD模型的参数;
52c)按照步骤51c)的方法基于FA-SVDD模型进行FD故障检测。
基于KDE-FA-SVDD模型进行FD故障检测包括下述过程:
53a)按照步骤51a)的方法确定KDE-FA-SVDD模型结构;
53b)确定KDE-FA-SVDD模型参数:
对所有历史数据先采用KDE方法进行故障特征选择,再采用FA方法进行故障特征降维后确定KDE-FA-SVDD模型的参数;
53c)按照步骤51c)的方法基于KDE-FA-SVDD模型进行FD故障检测。
步骤6:分别将构建的KDE-BN模型、FA-BN模型及KDE-FA-BN模型与传统BN模型的检测性能进行比较,若正常状态被误判为故障状态的概率越低,则判定该FD方法效果越好。
步骤7:分别将构建的KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型与传统SVDD模型的检测性能进行比较,若正常状态被误判为故障状态的概率越低,则判定该FD方法效果越好。
下面通过具体实施例进一步阐述本发明提出的一种基于KDE-FA的冷水机组故障特征刻画方法的检测步骤和验证本发明的有益效果:
实施例:
本实施例使用的故障历史数据来源于ASHRAE RP-1043故障实验,为一台90冷吨(约316kW)的离心式冷水机组,热交换器(冷凝器、蒸发器和其他换热器)均为满液式壳管式换热器,膨胀阀为热力膨胀阀,制冷剂选用R134a。实验通过改变参数模拟了27个运行工况;通过实验模拟了7类典型软故障,且每类故障划分为4个劣化等级,从低到高依次为SL1,SL2,SL3,SL4,7类典型故障见表1;通过传感器以10秒的间隔进行数据采样,共需要采集29组数据集,其中包括一组正常数据集和28组故障数据集(7类故障,每类故障分4个劣化等级),每一组数据包含64个特征参数,每一个特征参数包含5191个数据。
表1 7类典型软故障
步骤1:选用移动平均滤波器法对冷水机组原始故障数据进行平滑处理,然后选用计算几何加权运行平均值和几何加权运行方差的方法对平滑数据进行稳态筛选;
步骤2:采用KDE方法对稳态筛选后的故障数据进行特征选择:
基于尽量选出所有敏感特征和尽量选择温度参数以节约传感器成本两个原则,对核密度对比图中正常数据曲线与故障数据曲线的偏离度进行主观判断,分别选出7类软故障的敏感特征,结果见表2。7类故障所有的敏感特征即为本研究利用KDE方法所选出来的特征,特征选择结果见表3。
表2各故障的敏感特征
表3特征选择结果
步骤3:采用FA方法对KDE选择出的21个故障特征进行特征降维:
3a)在因子描述环节,进行Bartlett球形检验和KMO统计量检验,当Bartlett球形检验结果中的卡方统计量足够大、显著性值小于0.05,KMO统计量检验结果中的KMO大于0.5三个条件满足其一,则认为特征之间的冗余性较强,此时应进行FA特征降维。
FA方法的Bartlett球形检验和KMO统计量检验结果见表4,由结果可知应进行FA特征降维。
表4 Bartlett球形检验和KMO统计量检验结果
3b)在因子提取环节,采用方差贡献率法和碎石图法确定公共因子的提取个数;因子提取后输出的公共因子能够反映全部数据信息的95%时,选取此时对应的故障特征的公共因子个数;碎石图中以曲线由陡峭变平缓的转折点为判断点,选取陡峭曲线对应的故障特征的公共因子个数。
因子提取结果见表5和图4由结果可知应提取5个公共因子。
表5公共因子的累积方差贡献率
3c)在因子旋转环节,当故障特征原始变量和提取出的公共因子之间的关系无法得到较好解释时,采用正交旋转法对因子载荷矩阵进行旋转,使两者之间的关系更明确;然后对公共因子的物理意义给出合理解释,并对公共因子命名。首先计算因子载荷矩阵,然后采用最大方差法对因子载荷矩阵进行旋转,输出旋转后的因子载荷矩阵、三维因子空间的载荷散点图(若公共因子数目多于3个,只能输出前3个公共因子的因子空间载荷散点图)。最后根据输出结果对目标变量和公共因子之间的关系进行解释。
以上输出结果分别见表6、表7和图5。
表6因子载荷矩阵
表7旋转后的因子载荷矩阵
由表7可知,目标变量TEO、TEI、TRE、PRE、TEA、T_suc、Tsh_suc在公共因子1上的载荷较大,所以公共因子1主要解释了蒸发器特征参数和压缩机吸气口处特征参数的信息;目标变量TCO、TCI、PRC、TRC在公共因子2上的载荷较大,所以公共因子2主要解释了冷凝器特征参数的信息;目标变量TR_dis、Tsh_dis、kW、Tcwd、Tewd在公共因子3上的载荷较大,所以公共因子3主要解释了压缩机排气口处特征参数和热交换器温差特征参数的信息;目标变量TRC_sub、TCA在公共因子4上的载荷较大,所以公共因子4主要解释了制冷剂本身温度和过冷度特征参数的信息;目标变量PO_feed、TO_sump、TO_feed在公共因子5上的载荷较大,所以公共因子5主要解释了润滑油特征参数的信息,这也正好说明了为什么公共因子5解释目标变量信息的累积贡献相对其他4个公共因子较少的原因。
从以上数据可知,目标变量和公共因子在因子旋转后能够更好的解释之间的关系,公共因子的物理意义也更加明确。
3d)在因子得分环节,确定每一样本在公共因子上的具体数值,将其作为新的变量运用于下一步的模型构建工作;选择回归法确定正常状态和各故障状态在因子变量上的具体数值。
通过FA方法,本发明将21个特征参数的维度降到5维,将新生成的5个因子变量用于后续的FD研究工作。本发明从新变量的正常样本和7类故障的所有劣化等级样本中共随机选取1800个样本,并划分为1200个样本的训练集和600个样本的测试集。训练集的样本数据用于确定FD模型的参数,测试集的样本数据用于对模型的验证。
步骤4:构建KDE-BN模型、FA-BN模型及KDE-FA-BN模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价。
分别使用1200个训练样本确定传统BN模型、KDE-BN模型、FA-BN模型和KDE-FA-BN模型的参数,即各故障的先验概率和各类故障发生时各特征参数的条件概率。然后基于四个训练好的模型对600个测试样本进行判定,并对比FD结果。
传统BN模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见表8。
表8传统BN模型的FD结果矩阵
KDE-BN模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见表9。
表9 KDE-BN模型的FD结果矩阵
FA-BN模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见表10。
表10 FA-BN模型的FD结果矩阵
KDE-FA-BN模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见表11。
表11 KDE-FA-BN模型的FD结果矩阵
由表8至表11可计算四种模型的FAR分别为25.3(152/600)、22.7%(136/600)、23.3%(140/600)、20.2%(121/600);如图6,KDE-FA-BN模型相对于其他三类BN模型,检测结果变化不大,且FAR相对降低。
步骤5:构建KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型,进行FD故障检测,对冷水机组的故障特征刻画的结果进行评价。
分别使用1200个训练样本确定传统SVDD模型、KDE-SVDD模型、FA-SVDD模型、KDE-FA-SVDD模型的参数,即惩罚因子和松弛变量,然后基于四个训练好的模型对600个测试样本进行判定,并对比FD结果。
传统SVDD模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见图7。
KDE-SVDD模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见图8。
FA-SVDD模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见图9。
KDE-FA-SVDD模型分别对冷水机组8个状态(正常状态和7类故障状态)下的600个测试样本进行FD判定,结果见图10。
由图7至图10可计算四种方法的FAR分别为23.8%(143/600)、18.7%(112/600)、22%(132/600)、16.2%(97/600)。如图11,KDE-FA-SVDD相对于三类SVDD模型,检测结果变化不大,且FAR相对降低。
步骤6:分别将构建的KDE-BN模型、FA-BN模型及KDE-FA-BN模型与传统BN模型的检测性能进行比较,构建的3种BN模型的FAR均低于传统BN模型,且KDE-FA-BN模型的FAR最低,为20.2%。
步骤7:分别将构建的KDE-SVDD模型、FA-SVDD模型及KDE-FA-SVDD模型与传统SVDD模型的检测性能进行比较,构建的3种SVDD模型的FAR均低于传统SVDD模型,且KDE-FA-SVDD模型的FAR最低,为16.2%。
结果同时显示:本发明提出的一种基于KDE-FA的冷水机组故障特征刻画方法,KDE方法基于敏感最大化的原则,尽量选出原始特征集中的所有敏感特征,相对于其他特征选择方法,所选出的敏感特征更多,保留信息更完整;FA方法去除了特征之间的冗余性,在保证不损失特征信息的基础上,大幅度降低特征维度,简化后续FD方法的结构复杂度;KDE-FA方法在实现特征维度降低的同时,保证FD方法的检测性能提高。
本发明并不局限于上述实施例,在本发明公开的技术方案的基础上,本领域的技术人员根据所公开的技术内容,不需要创造性的劳动就可以对其中的一些技术特征作出一些替换和变形,这些替换和变形均在本发明的保护范围内。
- 一种基于KDE-FA的冷水机组故障特征刻画方法
- 一种基于DR‑BN模型的冷水机组故障特征选择方法