文本数据增强方法
文献发布时间:2023-06-19 12:19:35
技术领域
本发明涉及自然语言处理及深度学习领域,特别是涉及一种文本数据增强方法。
背景技术
情感分类是自然语言处理(NLP)的一个重要研究方向,情感分类是指根据文本所表达的含义和情感信息将文本划分成两种或多种类型。而在自然语言处理(NLP)中,面临的主要挑战是标注样本数据少,特别是对于低资源的语种数据。人工收集和标注额外的数据是一个耗时且低效的工作,极大地增加了劳动强度和成本。
现有的文本数据增强方法主要针对句子通过同义词替换、回译、调换文本顺序和生成式模型等方法。这些方法都存在各种各样的不足之处。
现有技术提出了一种文本情感分类数据增强分析方法,能够实现文本数据增强处理,便于实现文本的情感分析,该方法包括:获取待处理的原始句子文本;对所述原始句子文本进行处理,得到与所述原始句子文本语义相同的处理语句文本;应用所述原始句子文本及所述处理语句文本进行情感分析。
这种方法虽然实现了一定程度的文本数据增强,但是该方法长短期记忆网络模型泛化能力弱,并受限于替换词的词库,会存在子句中某些词缺少匹配的同义词,甚至出现一词多意的现象,造成增强后的子句发生语义转移。
因此,设计一种标注样本多、长短期记忆网络模型泛化能力强、文本情感分类精确度高的一种文本数据增强方法就很有必要。
发明内容
为了克服上述问题,本发明提供了一种文本数据增强方法,利用少样本数据,提出了基于词性和双语料库的同义词替换方案,主要遍历句中那些词性是名词、动词、形容词和副词的原词,然后遍历同义词库筛选出相似度值最高的同义词后,对原词进行替换,使增强后的数据集与增强前的数据集的集合的三类极性子句数量达到接近或相等,解决了方面级细粒度情感分类任务中标注样本少,长短期记忆网络模型泛化能力不够的问题。
为实现上述的目的,本发明采用的技术方案是:
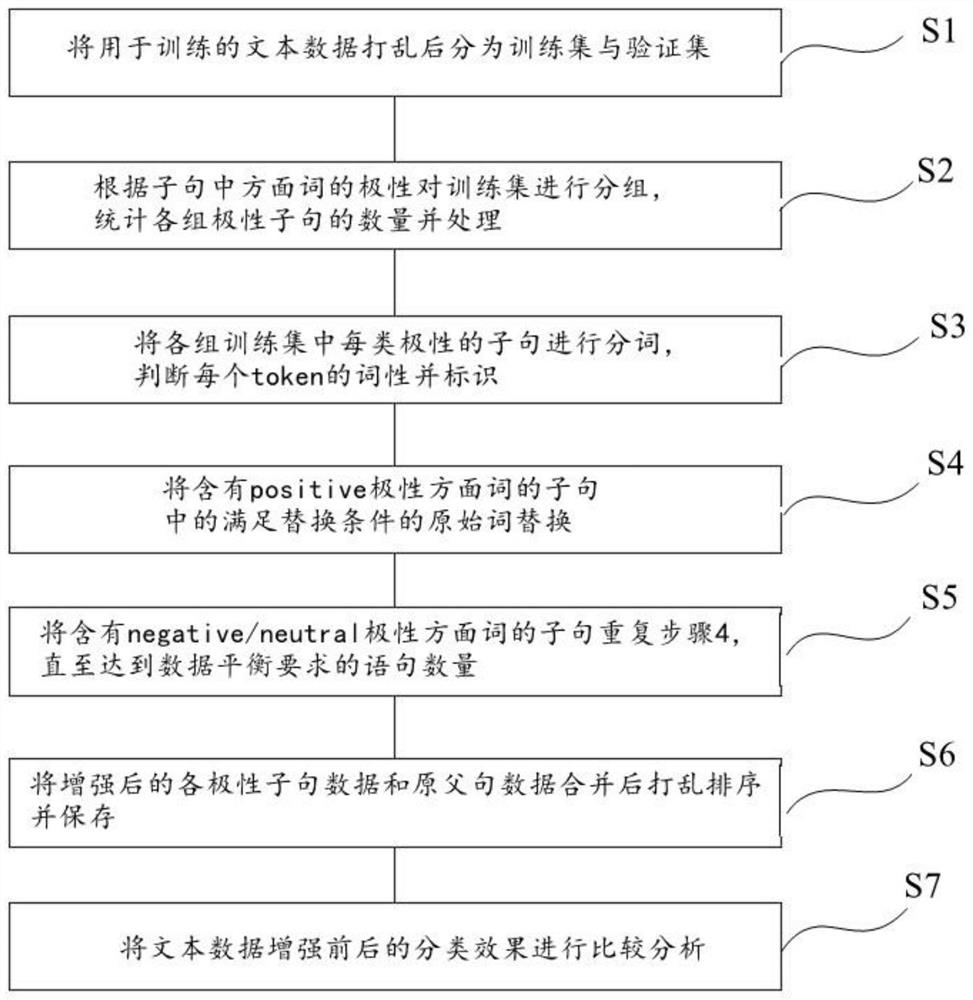
一种文本数据增强方法,包括以下步骤:
S1、将用于训练的文本数据打乱后分为训练集与验证集;
S2、根据子句中方面词的情感极性(positive,negative,neutral)对训练集进行分组,统计各组极性子句的数量并处理;
S3、将各组训练集中每类极性的子句进行分词,判断每个token的词性并标识;
S4、将含有positive极性方面词的子句中的满足替换条件的原始词替换;
S5、将含有negative/neutral极性方面词的子句重复步骤4,直至达到数据平衡要求的语句数量;
S6、将增强后的各极性子句数据和原父句数据合并后打乱排序并保存;
S7、将文本数据增强前后的分类效果进行比较分析。
进一步的,在步骤S1中,文本数据按预设比例打乱成训练集与验证集,所述训练集的比重大于所述验证集的比重;所述验证集用于验证所述训练集的学习效果,并及时调整更新超参数。
进一步的,在步骤S2中,统计各组极性子句的数量并处理,包括:
S21、根据所述训练集子句的数量d
x=d
S22、将三类极性的子句数量增减,以使增强后的数据集与增强前的数据集的集合的三类极性子句数量接近或相等;
X
进一步的,在步骤S3中,所述分词的方法为通过spaCy库进行分词;所述标识为找出各组训练集中每类极性子句中词性为名词或动词或形容词或副词的token,并用标识符进行标记,以确定是否对被标记的方面词进行替换。
进一步的,所述标识符为flag(1,0);当flag=1时,调用被标记的方面词在WordNet中的同词性的同义词,并用所述同词性的同义词替换所述被标记的方面词;当flag=0时,不对被标记的方面词进行替换。
进一步的,在步骤S4中,原始词的替换方法包括:
S41、从WordNet中查找原始词的同词性的同义词,按与原始词的词义相似度值高低降序排列;
S42、将原始词替换为相似度值最高且非原始词的同词性的同义词;
S43、当在WordNet中查找不到该原始词的同义词或不存在该原始词的同词性的同义词时,从语料库中筛选该原始词的同义词,并扩充该原始词对应的同义词典;
S44、对每个原始词所对应且符合类别分布的候选同义词进行采样,并完成替换工作,如果原始词的候选同义词表为空,则跳过该步骤。
进一步的,在步骤S5中,数据平衡要求的语句数量为原始语句增强后的数据集与增强前的数据集的集合的语句数量的三分之一。
进一步的,在步骤S6中,将保存后的数据输入至长短期记忆网络深度学习模型并进行分类精度训练的微调。
进一步的,在步骤S7中,比较分析的方法为:在公开数据集上对增强前后的文本数据进行长短期记忆网络训练。
进一步的,所述公开数据集为SemEval-2014 Task 4的Laptop以及SemEval-2014的Restaurant。
与现有技术相比,本发明的有益效果是:
1.本发明的文本数据增强方法,通过将文本数据根据方面词的情感极性进行分类,对分类后的训练集进行子句增强,遍历每个分类的原词并将其替换,使增强后的数据集与增强前的数据集的集合的三类极性子句数量接近或相等,将增强后的各极性子句数据和原父句数据合并后打乱排序并保存,最后对文本数据增强前后的分类效果进行比较分析。解决了方面级细粒度情感分类任务中标注样本少,长短期记忆网络模型泛化能力不够的问题。此外,还提高了分类器的学习效率,以及方面级文本情感分类精确度,同时,还加强了分类模型的可移植性和可解释性。
2.本发明的文本数据增强方法,通过采用spaCy语料库,当在WordNet中查找不到该原始词的同义词或不存在该原始词的同词性的同义词时,能够从spaCy的en_core_web_md语料库中筛选原始词的同义词,并扩充原始词对应的同义词典,从而大大增加了同义词的规模,能够在线实时扩充同义词词库。
3.本发明的文本数据增强方法,通过将训练用的文本数据打乱,使得文本数据随机化,避免文本数据过拟合,并增强了模型的返回能力。
附图说明
图1是本发明的文本数据增强方法的流程图;
图2是本发明的文本数据增强方法的步骤S2的流程图;
图3是本发明的文本数据增强方法的步骤S4的流程图;
图4是本发明的文本数据增强方法的实验结果折线图;
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施例,都属于本发明所保护的范围。
实施例1
如图1所示,一种文本数据增强方法,利用少样本数据,提出了基于词性和双语料库的同义词替换方案,主要遍历句中那些词性是名词、动词、形容词和副词的原词,然后遍历同义词库筛选出相似度值最高的同义词后,对原词进行替换,使增强后的数据集与增强前的数据集的集合的三类极性子句数量达到接近或相等,解决了方面级细粒度情感分类任务中标注样本少,长短期记忆网络模型泛化能力不够的问题。
为了更好的凸显本发明的方法的有益效果并帮助理解,先对常用的数据增强方法作出简要说明。
常用的文本数据增强方法主要包括同义词替换、回译、调换文本顺序和生成式模型等方法。同义词替换是在保持增强后子句的原始语义的前提下,将父句中部分单词用来自WordNet的同义词替换,但是该方法受同义词表规模的限制,会发现句子中的某些词无匹配的同义词,同时由于一词多义的情况,会使增强后子句可能发生语义转移。回议是将父句在源语言与多个目标语言之间翻译多次,最后再翻译回源语言,该方法简单高效,可直接调用在线翻译服务的API将整个句子增强生成新的子句,达到样本数据扩充的目的;但该方法常受限于翻译接口的调用频率限制,无法保证翻译后的子句的多样性。生成式模型主要利用Bert等预训练语言模型来预测生成哪些在句子中被MASK替换的单词,并结合序列标签,利用模型补全被MASK的单词来得到新的子句;该方法保证了增强子句表达方式的多样性,但常需要较多次的超参数优化及高配置的运行环境来保证预测的精度。
具体来讲,本发明的文本数据增强方法包括以下步骤:
S1、将用于训练的文本数据打乱后分为训练集与验证集。
文本数据需按预设比例打乱成训练集与验证集,所述训练集的比重大于所述验证集的比重。将文本数据打乱使得文本数据随机化,避免文本数据过拟合,并增强了模型的返回能力。所述验证集用于验证所述训练集的学习效果,根据验证集在训练过程中损失值的变化来判断模型是否过拟合,从而及时调整模型的超参数,使得模型在验证集上的效果最好。特别的,预设比例可设置为90:10或者80:20或者70:30,预设比例也可以为其它训练集比重大于验证集比重的比例,具体并不以此为限。
S2、根据子句中方面词的情感极性(positive,negative,neutral)对训练集进行分组,统计各组极性子句的数量并处理。
其中,极性为词句中蕴含的情感倾向,positive为偏正面,negative为偏负面,neutral为偏中性。
如图2所示,具体来讲,统计各组极性子句的数量并处理,包括以下步骤:
S21、根据训练集子句的数量d
增强倍率根据具体的训练集子句的数量选择。
S22、将三类极性的子句数量增减,以使增强后的数据集与增强前的数据集的集合的三类极性子句数量接近或相等;X
值得注意的是,保证增强前数据集与增强后数据集的集合中三类极性的子句数量相等或接近,以使三类极性的子句数据平衡。由于在训练过程中,当数据不平衡时,大类的数据样本携带的信息量会比小类的数据样本的信息量多。那么,在训练的过程中,训练模型会“偏爱”大类,从而对整体分类效果造成影响。因此保证类别间的句子数量相等是为了减少模型对小类的预测结果错误,使得训练集从整体上获得较好的分类效果。
在采用具体的实施方式时,原始句子中的positive,negative,neutral的三类词性句的数据量分别为30、50与70。并选用增强倍率为1对数据进行增强,增强后的训练集总子句数为150×1=150。增强前总子句数量与增强后总子句的数量和为150×(1+1)=300。如此,positive分组需新增的句子为300/3-30=70条,negative分组需新增的句子为300/3-50=50条,neutral分组需新增的句子为300/3-70=30条。其他的训练集和增强倍率的增强方式如上述所示。
S3、将各组训练集中每类极性的子句进行分词,判断每个token的词性并标识。
在本实施例中,分词优选为spaCy库进行分词。spaCy库是Python和Cython中的高级自然语言处理库,它建立在最新的研究基础之上,被设计用于实际产品。spaCy库带有预先训练的统计模型和单词向量,目前支持20多种语言的标记。它具有世界上速度最快的句法分析器,用于标签的卷积神经网络模型,解析和命名实体识别以及与深度学习整合。在本发明中采用spaCy库进行分词能够大大提高分词效率以及精准度。
在本实施例中,标识是找出各组训练集中每类极性子句中词性为名词或动词或形容词或副词的token,并用标识符进行标记,以确定是否对被标记的方面词进行替换。
具体来讲,标识符为flag(1,0)。当flag=1时,调用被标记的方面词在WordNet中的同词性的同义词,并用所述同词性的同义词替换所述被标记的方面词;当flag=0时,不对被标记的方面词进行替换。
S4、将含有positive极性方面词的子句中的满足替换条件的原始词替换。
如图3所示,在本实施例中,原始词的替换方法包括:
S41、从WordNet中查找原始词的同词性的同义词,按与原始词的词义相似度值高低降序排列。
从WordNet中查找原始词的全部同词性的同义词,增强了数据的数量,并且按照词义相似度排序能够比较替换成不同的同义词的语句与原始语句的区别。
S42、将原始词替换为相似度值最高且非原始词的同词性的同义词。
如此,能够保证替换后的语句与原始语句最相似,保证语句增强的可靠性。
S43、当在WordNet中查找不到该原始词的同义词或不存在该原始词的同词性的同义词时,从语料库中筛选该原始词的同义词,并扩充该原始词对应的同义词典。
语料库优选为语料库为spaCy的en_core_web_md语料库,大大增加了同义词的规模,能够在线实时扩充同义词词库。
S44、对每个原始词所对应且符合类别分布的候选同义词进行采样,并完成替换工作,如果原始词的候选同义词表为空,则跳过该步骤。
S5、将含有negative/neutral极性方面词的子句重复步骤4,直至达到数据平衡要求的语句数量。
具体来讲,数据平衡要求的语句数量为原始语句增强后的数据集与增强前的数据集的集合的语句数量的三分之一。例如,对数量为150条的原始语句数据按照增强倍率1采用数据增强方法后,新的语句数量与旧的语句数量的总和为300条。那么,平衡要求的语句数量为增强前数据集与增强后数据集的集合的语句数量均分成positive,negative与neutral后的三组训练集,且每一组训练集的数量为100。
S6、将增强后的各极性子句数据和原父句数据合并后打乱排序并保存。
特别的,将保存后的数据输入至长短期记忆网络深度学习模型并进行分类精度训练的微调。从而提高模型训练的性能,包括识别率与分类准确率等。
S7、将文本数据增强前后的分类效果进行比较分析。
比较分析的方法为:在公开数据集上对增强前后的文本数据进行长短期记忆网络训练,从而验证本增强方法的有效性。特别的,公开数据集为SemEval-2014 Task 4的Laptop以及SemEval-2014的Restaurant。
在采用具体的实施方式时,在14_laptop与14_rest两套评论数据集上进行试验,其实验对象均为英文数据集,实验后发现本方法与基线方法相比取得明显效果。具体的实验操作如下:
进行实验数据准备,其中,SemEval-2014 Task 4中Laptop(14_laptop)的评论样本含正类,负类和中性的句子数量分别为:970,843和455。SemEval-2014中Restaurant(14_rest)的评论样本含正类,负类和中性的句子数量分别为:2151,794和632。值得注意的是,上述各类极性的句子数量随预处理的规则(包括增强率以及分类比例等)变化而变化。试验中将训练数据分为85:15的训练集和验证集,评价指标采用F1值(F1-score)。
如图4所示,其中op0表示未用增强方法的基线模型训练结果,op1表示采用同义词替换的增强方法后的训练结果,F1值(F1-score)表示方面词情感分类准确率,其数值越大越好,可以看出本发明在当前轮试验的两套数据集上的分类性能表现都很好。
通过本方法的上述各个步骤,本方法将文本数据根据情感极性进行分类,对分类后的训练集进行子句增强,遍历每个分类的原词并将其替换,使增强后的数据集与增强前的数据集的集合的三类极性子句数量接近或相等,将增强后的各极性子句数据和原父句数据合并后打乱排序并保存,最后对文本数据增强前后的分类效果进行比较分析。解决了方面级细粒度情感分类任务中标注样本少,长短期记忆网络模型泛化能力不够的问题。此外,还提高了分类器的学习效率,以及方面级文本情感分类精确度,同时,还加强了分类模型的可移植性和可解释性。
以上所述仅用以说明本发明的技术方案,而非对其进行限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 文本数据增强方法、装置、设备和介质
- 文本数据增强方法