一种基于分类模型的数据存储节能方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及存储技术领域,特别涉及一种基于分类模型的数据存储节能方法。
背景技术
数据存储是指将数据保存至计算机系统的过程,其方式往往通过磁盘、闪存设备、硬盘驱动器或云存储实现。随着数字经济大发展,数据存力成为存储应用中关键的部分,为金融交易、政务信息化、自动驾驶、自然资源勘探等领域中的数据分析或应用提供了有力的保障。
在信息技术的普遍应用下,数据规模的指数级增长,在对容量和性能提出了更高要求的同时,也为数据存储的能耗问题带来了严峻挑战,频繁重复地读写数据会导致大规模存储系统的高能耗,过多冗杂的存储数据会导致硬件或设备的储存空间增大,对存储系统造成不必要的能耗支出,如何在满足海量数据存储的基础上通过绿色节能的存储系统或存储方法,使得数据存储过程中的能耗尽可能降低,对数据价值而言具有重要的现实意义。
发明内容
本发明的目的在于提出一种基于分类模型的数据存储节能方法,以解决现有技术中所存在的一个或多个技术问题,至少提供一种有益的选择或创造条件。
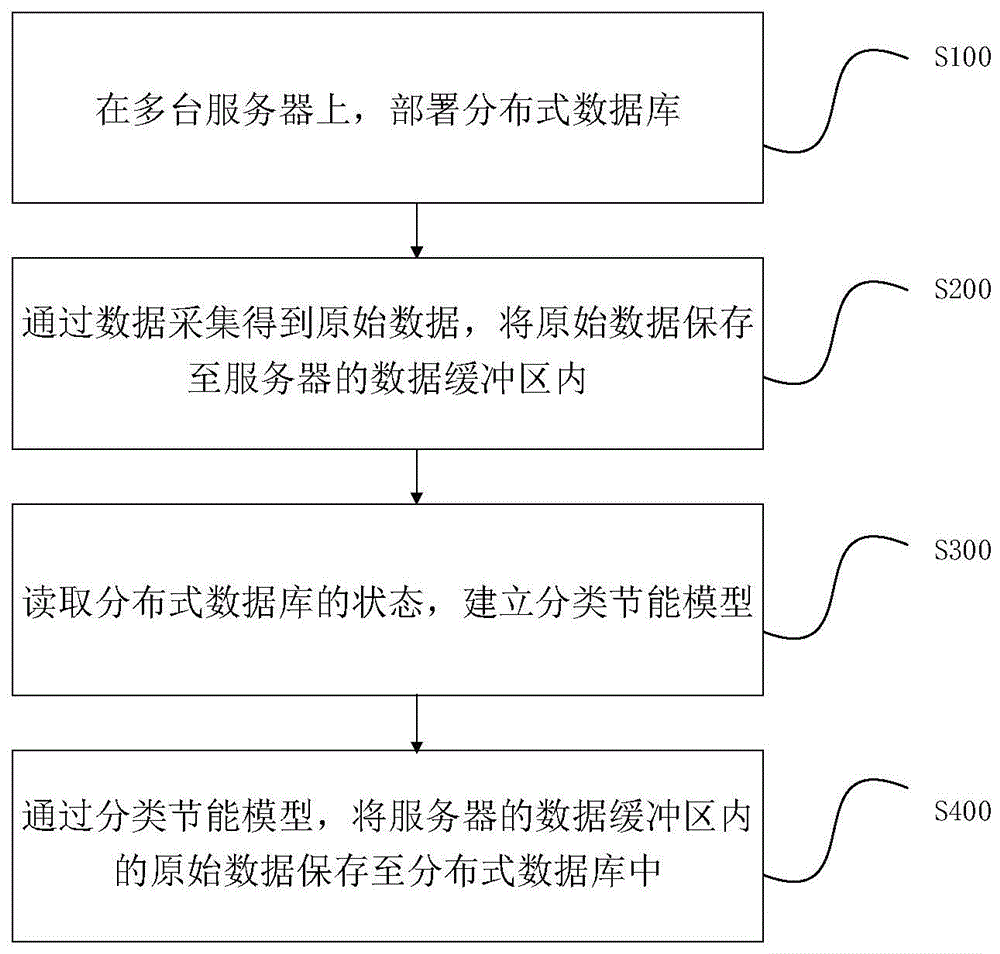
本发明提供了一种基于分类模型的数据存储节能方法,在多台服务器上,部署分布式数据库,通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内,读取分布式数据库的状态,建立分类节能模型,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。所述方法能够提高数据存储效率,减少存储能耗,通过合理分配负载节点,协调数据存储过程中的每个数据库的负载量,还能有效保证数据存储过程的安全,降低存储成本支出,实现存算并进、存算均衡。
为了实现上述目的,根据本公开的一方面,提供一种基于分类模型的数据存储节能方法,所述方法包括以下步骤:
S100,在多台服务器上,部署分布式数据库;
S200,通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内;
S300,读取分布式数据库的状态,建立分类节能模型;
S400,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。
可选地,步骤S100中,所述多台服务器通过有线或无线的连接方式实现信息传输,所述分布式数据库为RadonDB数据库、CockroachDB数据库、MongoDB数据库、Redis数据库、ScyllaDB数据库中的一种或多种。
可选地,步骤S200中,通过数据采集得到原始数据的方法具体为:通过数据采集工具获取原始数据,所述数据采集工具为传感器、摄像头、麦克风中的一种或多种,所述原始数据为几何量、数字量、物理量中的一种或多种,所述数据采集工具通过有线或无线的连接方式与所述多台服务器实现信息传输。
可选地,步骤S200中,将原始数据保存至服务器的数据缓冲区内的方法具体为:当数据采集工具将原始数据发送至服务器时,在服务器内按照原始数据发送时间先后的顺序将原始数据放入数据缓冲区内。
进一步地,步骤S300中,读取分布式数据库的状态,建立分类节能模型的方法具体为:
S301,记分布式数据库中的每个数据库为负载节点,以数字1,2,…,N为每个负载节点编号,N为所有负载节点的数量,以LN
S302,以每秒为间隔,实时记录每个负载节点的TPS值(即数据库的每秒事务处理量),记LN
S303,记LN
S304,依次将N个值HA
S305,记LN
S306,初始化整数变量K1=0,K2=1,转至S307;
S307,记第一能效等式为
式中,ln()表示取对数运算,X表示数组LNK中所有元素的总和;通过第一能效等式的值计算CA,比较CA与K1的值,转至S308;
S308,若CA的值大于K1的值,则将K1的值更新为当前CA的值,令K2的值增加1,转至S307;若CA的值小于K1的值,则转至S309;
S309,将当前K1的值记为Q1,将当前K2的值记为Q2,将数组LNM内值小于Q的所有元素的下标依次组成集合AM,记AM(k)为集合AM内的第k个元素,k=1,2,…,M,M为集合AM内所有元素的数量,转至S310;
S310,创建一个空白的数组LNU和一个空白数组LNH,将数组LNM内的所有元素复制至数组LNU中,将数组LNK内的所有元素复制至数组LNH中;依次将数组LNU内的下标为AM(k)的元素的值替换为IM(k)的值,保存替换后的数组LNU;将数组LNH中所有值小于LNA的元素的值更新为0,保存更新后的数组LNU,其中,LNA为数组LNU内所有元素的均值,IM(k)由第二能效等式计算:
式中,Q3为数组LNM中值最大的元素;
建立分类节能模型CGM(Y)如下:
式中,R
本步骤的有益效果为:在分布式数据库中,由于各个数据库在运行过程中各自的状态不尽相同,如部分数据库处于空闲状态,部分数据库处于忙碌状态,不同状态的数据库组成服务器中实现存储数据功能的结构,合理地分配一种稳定的数据库处理顺序有助于数据的快速调用或高频读写,本步骤的方法利用数据库在每秒的事务处理量的值,通过对数据进行形式转换,构建第一能效等式以及第二能效等式,从而建立分类节能模型,分类节能模型能够反映出当前分布式数据库中各个负载节点的处理效率,通过模型调用,在数据存储任务分配过程中,有效提高了存储数据的速度,同时防止由于数据库事务响应失败引起的数据丢失,还能够大幅降低能耗,在实际的存储场景中,保证存储数据过程的高效运转。
进一步地,步骤S400中,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中的方法具体为:
当分布式数据库接收到保存请求时,记接收到保存请求的时刻为t,记每个负载节点LN
本步骤的有益效果为:由于数据在读写的过程中存在受其他因素影响的可能,造成数据读写缓慢或异常,本步骤的方法可以确定最优的数据库处理顺序,相比于同步写入,能耗大幅降低,解决了数据处理排队拥堵的问题,有效地提高处理效率。
由于数据库每秒的事务处理量波动幅度大,导致负载节点未能充分利用,相对增加服务器的功耗,为解决该问题,并加快数据存储过程,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中的方法还可以为:
优选地,
S401,当分布式数据库接收到保存请求时,记接收到保存请求的时刻为t,初始化整数变量i1=1,i1∈[1,N],从i1=1开始遍历变量i1,设置P1为t时刻前的[30,60]秒,转至S402;
S402,以数组LTPS
S403,当变量i1的值小于N时,将i1的值增加1,转至S402;当变量i1的值等于N时,转至S404;
S404,初始化整数变量i2=1,i2∈[1,N],从i2=1开始遍历变量i2,转至S405;
S405,记浮标变量为数组LTPS
S406,若变量i3的值大于P,转至S408;若变量i3的值小于等于P,比较浮标变量的值与LTPS
S407,比较当前浮标变量的值与LTPS
S408,若变量i2的值小于N时,将变量i2的值增加1,转至S405;若变量i2的值大于N时,转至S409;
S409,将N个He
S410,将高能效节点置于节点处理顺序的前列,将服务器的数据缓冲区内的原始数据按照节点处理顺序保存至分布式数据库中。
本步骤的有益效果为:实际场景中数据库实时性能的变化存在众多因素的影响,在模型分析的过程中,考虑到TPS值的实时跳动,通过本步骤的方法可以进一步筛选空闲的负载节点,充分利用了分布式数据库的协调性,在单个负载节点出现事务响应异常的情况下,也能够保证数据存储过程稳定进行,有效提高整个数据存储系统的稳定性,同时能够避免频繁提交事务请求,降低系统能耗,加快存储速度。
本公开还提供了一种基于分类模型的数据存储节能系统,所述一种基于分类模型的数据存储节能系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现一种基于分类模型的数据存储节能方法中的步骤,所述基于分类模型的数据存储节能系统可以运行于桌上型计算机、笔记本电脑、移动电话、手提电话、平板电脑、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群,所述处理器执行所述计算机程序运行在以下系统的单元中:
节点部署单元,用于在多台服务器上,部署分布式数据库;
数据缓冲单元,用于通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内;
模型建立单元,用于读取分布式数据库的状态,建立分类节能模型;
数据存储单元,用于通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。
本发明的有益效果为:所述方法能够提高数据存储效率,减少存储能耗,通过合理分配负载节点,协调数据存储过程中的每个数据库的负载量,还能有效保证数据存储过程的安全,降低存储成本支出,实现存算并进、存算均衡。
附图说明
通过对结合附图所示出的实施方式进行详细说明,本公开的上述以及其他特征将更加明显,本公开附图中相同的参考标号表示相同或相似的元素,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,在附图中:
图1所示为一种基于分类模型的数据存储节能方法的流程图;
图2所示为一种基于分类模型的数据存储节能系统的系统结构图。
具体实施方式
以下将结合实施例和附图对本公开的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本公开的目的、方案和效果。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
如图1所示为根据本发明的一种基于分类模型的数据存储节能方法的流程图,下面结合图1来阐述根据本发明的实施方式的一种基于分类模型的数据存储节能方法。
本公开提出一种基于分类模型的数据存储节能方法,所述方法包括以下步骤:
S100,在多台服务器上,部署分布式数据库;
S200,通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内;
S300,读取分布式数据库的状态,建立分类节能模型;
S400,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。
可选地,步骤S100中,所述多台服务器通过有线或无线的连接方式实现信息传输,所述分布式数据库为RadonDB数据库、CockroachDB数据库、MongoDB数据库、Redis数据库、ScyllaDB数据库中的一种或多种。
可选地,步骤S200中,通过数据采集得到原始数据的方法具体为:通过数据采集工具获取原始数据,所述数据采集工具为传感器、摄像头、麦克风中的一种或多种,所述原始数据为几何量、数字量、物理量中的一种或多种,所述数据采集工具通过有线或无线的连接方式与所述多台服务器实现信息传输。
可选地,步骤S200中,将原始数据保存至服务器的数据缓冲区内的方法具体为:当数据采集工具将原始数据发送至服务器时,在服务器内按照原始数据发送时间先后的顺序将原始数据放入数据缓冲区内。
进一步地,步骤S300中,读取分布式数据库的状态,建立分类节能模型的方法具体为:
S301,记分布式数据库中的每个数据库为负载节点,以数字1,2,…,N为每个负载节点编号,N为所有负载节点的数量,以LN
S302,以每秒为间隔,实时记录每个负载节点的TPS值(即数据库的每秒事务处理量),记LN
S303,记LN
S304,依次将N个值HA
S305,记LN
S306,初始化整数变量K1=0,K2=1,转至S307;
S307,记第一能效等式为
式中,ln()表示取对数运算,X表示数组LNK中所有元素的总和;通过第一能效等式的值计算CA,比较CA与K1的值,转至S308;
S308,若CA的值大于K1的值,则将K1的值更新为当前CA的值,令K2的值增加1,转至S307;若CA的值小于K1的值,则转至S309;
S309,将当前K1的值记为Q1,将当前K2的值记为Q2,将数组LNM内值小于Q的所有元素的下标依次组成集合AM,记AM(k)为集合AM内的第k个元素,k=1,2,…,M,M为集合AM内所有元素的数量,转至S310;
S310,创建一个空白的数组LNU和一个空白数组LNH,将数组LNM内的所有元素复制至数组LNU中,将数组LNK内的所有元素复制至数组LNH中;依次将数组LNU内的下标为AM(k)的元素的值替换为IM(k)的值,保存替换后的数组LNU;将数组LNH中所有值小于LNA的元素的值更新为0,保存更新后的数组LNU,其中,LNA为数组LNU内所有元素的均值,IM(k)由第二能效等式计算:
式中,Q3为数组LNM中值最大的元素;
建立分类节能模型CGM(Y)如下:
式中,R
进一步地,步骤S400中,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中的方法具体为:
当分布式数据库接收到保存请求时,记接收到保存请求的时刻为t,记每个负载节点LN
由于数据库每秒的事务处理量波动幅度大,导致负载节点未能充分利用,相对增加服务器的功耗,为解决该问题,并加快数据存储过程,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中的方法还可以为:
优选地,
S401,当分布式数据库接收到保存请求时,记接收到保存请求的时刻为t,初始化整数变量i1=1,i1∈[1,N],从i1=1开始遍历变量i1,设置P1为t时刻前的[30,60]秒,转至S402;
S402,以数组LTPS
S403,当变量i1的值小于N时,将i1的值增加1,转至S402;当变量i1的值等于N时,转至S404;
S404,初始化整数变量i2=1,i2∈[1,N],从i2=1开始遍历变量i2,转至S405;
S405,记浮标变量为数组LTPS
S406,若变量i3的值大于P,转至S408;若变量i3的值小于等于P,比较浮标变量的值与LTPS
S407,比较当前浮标变量的值与LTPS
S408,若变量i2的值小于N时,将变量i2的值增加1,转至S405;若变量i2的值大于N时,转至S409;
S409,将N个He
S410,将高能效节点置于节点处理顺序的前列,将服务器的数据缓冲区内的原始数据按照节点处理顺序保存至分布式数据库中。
所述一种基于分类模型的数据存储节能系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于分类模型的数据存储节能方法实施例中的步骤,所述一种基于分类模型的数据存储节能系统可以运行于桌上型计算机、笔记本电脑、移动电话、手提电话、平板电脑、掌上电脑及云端数据中心等计算设备中,可运行的系统可包括,但不仅限于,处理器、存储器、服务器集群。
本公开的实施例提供的一种基于分类模型的数据存储节能系统,如图2所示,该实施例的一种基于分类模型的数据存储节能系统包括:处理器、存储器及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于分类模型的数据存储节能方法实施例中的步骤,所述处理器执行所述计算机程序运行在以下系统的单元中:
S100,在多台服务器上,部署分布式数据库;
S200,通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内;
S300,读取分布式数据库的状态,建立分类节能模型;
S400,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。
所述一种基于分类模型的数据存储节能系统可以运行于桌上型计算机、笔记本电脑、掌上电脑及云端数据中心等计算设备中。所述一种基于分类模型的数据存储节能系统包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述例子仅仅是一种基于分类模型的数据存储节能方法及系统的示例,并不构成对一种基于分类模型的数据存储节能方法及系统的限定,可以包括比例子更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述一种基于分类模型的数据存储节能系统还可以包括输入输出设备、网络接入设备、总线等。
所称处理器可以是中央处理单元(Central Processing Unit,CPU),还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立元器件门电路或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述一种基于分类模型的数据存储节能系统的控制中心,利用各种接口和线路连接整个一种基于分类模型的数据存储节能系统的各个分区域。
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述一种基于分类模型的数据存储节能方法及系统的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
本发明提供了一种基于分类模型的数据存储节能方法,在多台服务器上,部署分布式数据库,通过数据采集得到原始数据,将原始数据保存至服务器的数据缓冲区内,读取分布式数据库的状态,建立分类节能模型,通过分类节能模型,将服务器的数据缓冲区内的原始数据保存至分布式数据库中。所述方法能够提高数据存储效率,减少存储能耗,通过合理分配负载节点,协调数据存储过程中的每个数据库的负载量,还能有效保证数据存储过程的安全,降低存储成本支出,实现存算并进、存算均衡。尽管本公开的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,从而有效地涵盖本公开的预定范围。此外,上文以发明人可预见的实施例对本公开进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本公开的非实质性改动仍可代表本公开的等效改动。
- 一种基于目录树的分类数据存储及分类目录查询方法
- 一种基于生成模型与判别分类模型的图像半监督分类方法