一种基于IP访问特征的用户群体画像方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及网络治理技术领域,具体是一种基于IP访问特征的用户群体画像方法。
背景技术
随着信息化建设的快速发展,流量需求迅速增长,网络设备如交换机、路由器、防火墙以及服务器等负荷越来越大,业务不断复杂。相关系统记录了大量的日志,日志中蕴含着用户行为。随着用户数的基数增大,数据分析工作越发的困难,同时在众多的用户访问数据中存在着大量的非真实访问数据,其来源大多是爬虫程序或者是恶意攻击行为。目前互联网用户行为分析及群体画像往往用于营销目的,且数据来源是全网数据、数据格式为文本数据,研究如何在海量的网络日志中挖掘真实用户的访问行为,并进行用户群体划分,对提升网络治理能力、治理水平具有重要意义。
针对上述问题,现在设计一种改进的基于IP访问特征的用户群体画像方法。
发明内容
本发明的目的在于提供一种基于IP访问特征的用户群体画像方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
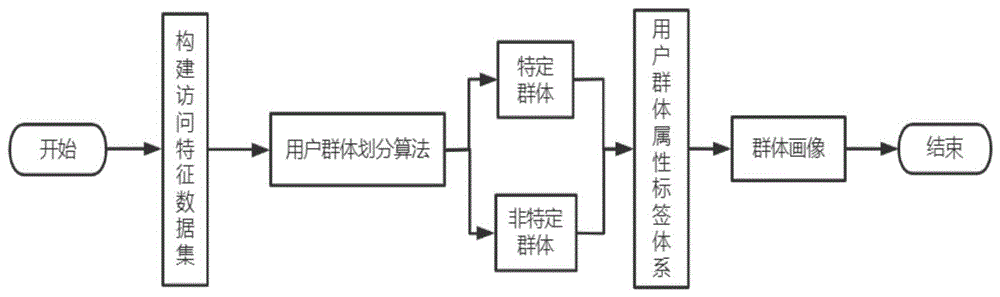
一种基于IP访问特征的用户群体画像方法,包括以下步骤:
步骤1:根据日志的访问域名的类别信息,通过数理统计的方法构建IP访问特征数据集。
步骤2:基于用户群体划分算法识别特定群体和非特定群体。
步骤3:构建用户群体属性标签体系,为方便对划分好的用户群体从多维度进行描述,构建了如下群体属性标签体系,包含三类属性,分别为静态属性、动态属性、描述属性。其中,静态属性主要描述了用户的基本属性,动态属性描述了用户的活跃状态,描述属性体现了用户价值度信息。
步骤4:基于用户群体属性标签体系生成用户群体画像。
作为本发明进一步的方案:本方法不同于一般的网站日志,本方法涉及的网络日志为网络中心的日志数据,涵盖了多类日志信息,以HTTP请求产生的日志为例,其中classify_type表示的是域名的分类信息,通过对classify_type字段的统计分析,可以得到一定时间内源IP的访问频次,进而构建基于源IP的访问特征数据集,为后续群体划分提供数据支撑。
作为本发明再进一步的方案:基于规则与统计的特定群体划分算法:依据访问域名的类型,如站长之家的网站分类标签,例如:将特定群体确立为休闲娱乐、购物、教育文化、生活服务、体育健身、医疗健康、交通旅游、新闻媒体8类。以购物类网站为例,该类群体的IP用户以购物为主要的兴趣。由于特定群体数量固定,且每类群体的偏好明显,故根据帕累托法则确定阈值,并构建基于规则的特定群体划分算法,具体过程如下:
Step1.根据公式1计算每个IP的特征倾向度Q
Step2.设定阈值T
Step3.将该IP划分到最大特征属性对应的特定群体;
Step4.将未分类的日志数据形成待分类数据集合,转到基于DBScan的新群体划分算法;
Step5.算法结束。
公式1如下:
其中,N
作为本发明再进一步的方案:基于DBSCAN的非特定群体划分算法:基于规则的特定群体划分算法能够识别出特定的8类群体,但日志中仍存在大量的未完成分类的用户IP,故采用DBSCAN算法完成非特定群体的识别。针对DBSCAN算法在单机上的计算瓶颈,设计基于Spark的并行DBSCAN算法来提升效率。
DBSCAN算法分为两步,第一步是根据邻域半径ε和邻域密度MinPts找到核心点并形成临时簇,第二步是将相连的临时簇合并得到最终的结果簇。在第一步中,需要计算任意两点之间的距离,在单机环境上计算比较简单,由于所有的数据点都在内存里,直接双重遍历即可。在分布式环境中,由于数据点分布在不同的分区,无法直接计算不同分区间数据点的距离,采用将不同分区的数据分批拉到Driver端并广播到executor分别计算距离,将最终的结果进行合并,从而间接计算任意两点间的距离。在第二步中,首先在每个分区内部进行合并,然后减少分区数量重新分区,在新的分区继续合并临时簇,不断重复,直到划为一个分区,完成对全部临时簇的合并,具体过程如下:
Step1.将无法识别为特定群体的IP封装到数据集合D中;
Step2.将不同分区的数据分批次广播并计算两点之间的距离;
Step3.计算每个数据点邻域ε内的样本点数量,若大于MinPts则构造为临时簇,并标记为核心点,加入到核心点列表中;
Step4.将每个分区内的点都划分为一个个临时簇,不在临时簇内的点即为噪声点;
Step5.对每一个临时簇,判断其中的样本点是都在核心点列表中,若是,则将样本点所在的临时簇与当前临时簇合并,并在核心点列表中删除该样本点;
Step6.重复Step5,直至当前临时簇中的所有点都不在核心点列表中,完成一个分区内的合并;
Step7.减少分区数量,将数据重新分区,跳转到Step5;
Step8.当分区数量变为1时,完成全部的临时簇合并,得到最终的聚类结果。
作为本发明再进一步的方案:用户群体静态属性的量化方法设计:用户群体的静态属性可直接从日志中获取或者通过简单映射、解析及查找获得。包括地理位置属性、终端属性、网段属性、请求方法四种。
1)请求方法属性:从原始网络出口服务器日志中解析获取。
2)网段属性:解析ASN信息后得到。
3)地理位置属性:查询IP归属地中获取。
终端属性:基于原始日志的user_agent字段,使用正则表达式匹配获得浏览器、操作系统等终端属性。
作为本发明再进一步的方案:用户群体动态属性的量化方法设计:用户群体的动态属性通过数理统计的方法得到,包括用户访问量、用户日活跃时长DailyActiveTime、用户活跃度等,指标量化公式如下所示:
用户访问量=count
作为本发明再进一步的方案:用户群体描述属性的量化方法设计:用户群体描述属性主要是通过用户的价值度及域名信息来对用户群体进行描述,包含用户价值属性、用户访问的域名变化属性、用户访问的域名类型等。
1)用户价值属性
用户价值度可以通过对一段时间内的访问量变化情况进行分析而得出,该属性反映用户的重要程度。采用方差评价模型构建的价值度计算模型如公式2所示。
公式2:
其中m
2)域名变化属性
域名变化属性反映的是服务器IP承载的任意两个域名的距离,采用编辑距离计算其相似度,经过统计分析后建立基于相似度的IP域名变化规律分类规则,分为以下4类:
a)承载域名固定不变且唯一
XXX.com……XXX.com
b)在承载域名的集合内变化
XXX.com YYY.com……XXX.com YYY.com
c)承载域名的末级字段按照某种模式变化
Z1.XXX.com Z15.XXX.com Z7.XXX.com…Z8.XXX.com
d)承载的域名无规律变化
函数edit(i,j)的定义如公式3所示,表示第一个域名长度为i的子串到第二个域名长度为j的子串的距离。
公式3:
若每一个域名与其他n-1个域名的编辑距离均为edit(i,j)==0,则域名变化属性为a类,即承载域名固定不变且唯一;
若每一个域名与其他n-1个域名的编辑距离均为edit(i,j)==L(L为一常数),则域名变化属性为b类,即在承载域名的集合内变化;
若每一个域名与其他n-1个域名的编辑距离均满足0<edit(i,j)<6,则域名变化属性为c类,即承载域名的末级字段按照某种模式变化;
若每一个域名与其他n-1个域名的编辑距离均满足edit(i,j)≥6,则域名变化属性为d类,即承载的域名无规律变化。
3)域名随机性属性
域名随机性属性用信息熵来衡量。信息熵用来描述随机变量的不确定性程度,随机变量的不确定性越大,信息熵越大,反之越小。信息熵也可以用来判断一个域名的混乱程度,关于熵的定义如公式4所示,其中p(i)表示给定字符出现的概率。
公式4:
用户IP的域名随机性属性计算公式如公式5,其中count(client_ip)代表源IP的访问次数,H(x
公式5:
与现有技术相比,本发明的有益效果是:
1、本发明设计了用户群体属性标签体系;
通过对用户群体的分析与研究,提出了一套基于属性的知识融合方法,设计了包含静态属性、动态属性、描述属性等三类属性的用户群体属性标签体系。
2、本发明设计了指标量化模型;
对用户群体属性标签体系中具体属性值进行量化计算,将模糊的指标转化为具体的数值,为下一步用户群体画像提供了数据支撑。
3、本发明设计了基于IP访问特征的用户群体划分算法;
在充分研究原始日志的基础上,以IP访问特征为着力点,设计了基于规则和机器学习相结合的用户群体划分算法。根据日志数据量大的特点,研究了在大数据情况下,优化机器学习算法效率的方法。
附图说明
图1为本发明的整体流程图。
图2为本发明的IP群体属性标签特征体系。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-图2,本发明实施例中,一种基于IP访问特征的用户群体画像方法,包括以下步骤:
步骤1:根据日志的访问域名的类别信息,通过数理统计的方法构建IP访问特征数据集。
本方法不同于一般的网站日志,本方法涉及的网络日志为网络中心的日志数据,涵盖了多类日志信息。以HTTP请求产生的日志为例,其主要字段如表1所示。其中classify_type表示的是域名的分类信息。通过对classify_type字段的统计分析,可以得到一定时间内源IP的访问频次,进而构建基于源IP的访问特征数据集,为后续群体划分提供数据支撑。
表1URL日志格式
步骤2:基于用户群体划分算法识别特定群体和非特定群体。
1、基于规则与统计的特定群体划分算法:
依据访问域名的类型,如站长之家的网站分类标签,例如:将特定群体确立为休闲娱乐、购物、教育文化、生活服务、体育健身、医疗健康、交通旅游、新闻媒体8类。以购物类网站为例,该类群体的IP用户以购物为主要的兴趣。由于特定群体数量固定,且每类群体的偏好明显,故根据帕累托法则确定阈值,并构建基于规则的特定群体划分算法,具体过程如下:
Step1.根据公式1计算每个IP的特征倾向度Q
Step2.设定阈值T
Step3.将该IP划分到最大特征属性对应的特定群体;
Step4.将未分类的日志数据形成待分类数据集合,转到基于DBScan的新群体划分算法;
Step5.算法结束。
公式1如下:
其中,N
2、基于DBSCAN的非特定群体划分算法:
基于规则的特定群体划分算法能够识别出特定的8类群体,但日志中仍存在大量的未完成分类的用户IP,故采用DBSCAN算法完成非特定群体的识别。针对DBSCAN算法在单机上的计算瓶颈,设计基于Spark的并行DBSCAN算法来提升效率。
DBSCAN算法分为两步,第一步是根据邻域半径ε和邻域密度MinPts找到核心点并形成临时簇,第二步是将相连的临时簇合并得到最终的结果簇。在第一步中,需要计算任意两点之间的距离,在单机环境上计算比较简单,由于所有的数据点都在内存里,直接双重遍历即可。在分布式环境中,由于数据点分布在不同的分区,无法直接计算不同分区间数据点的距离,采用将不同分区的数据分批拉到Driver端并广播到executor分别计算距离,将最终的结果进行合并,从而间接计算任意两点间的距离。在第二步中,首先在每个分区内部进行合并,然后减少分区数量重新分区,在新的分区继续合并临时簇,不断重复,直到划为一个分区,完成对全部临时簇的合并,具体过程如下:
Step1.将无法识别为特定群体的IP封装到数据集合D中;
Step2.将不同分区的数据分批次广播并计算两点之间的距离;
Step3.计算每个数据点邻域ε内的样本点数量,若大于MinPts则构造为临时簇,并标记为核心点,加入到核心点列表中;
Step4.将每个分区内的点都划分为一个个临时簇,不在临时簇内的点即为噪声点;
Step5.对每一个临时簇,判断其中的样本点是都在核心点列表中,若是,则将样本点所在的临时簇与当前临时簇合并,并在核心点列表中删除该样本点;
Step6.重复Step5,直至当前临时簇中的所有点都不在核心点列表中,完成一个分区内的合并;
Step7.减少分区数量,将数据重新分区,跳转到Step5;
Step8.当分区数量变为1时,完成全部的临时簇合并,得到最终的聚类结果。
步骤3:构建用户群体属性标签体系。
为方便对划分好的用户群体从多维度进行描述,构建了如下群体属性标签体系,包含三类属性,分别为静态属性、动态属性、描述属性。其中,静态属性主要描述了用户的基本属性,动态属性描述了用户的活跃状态,描述属性体现了用户价值度信息。
1、用户群体静态属性的量化方法设计
用户群体的静态属性可直接从日志中获取或者通过简单映射、解析及查找获得。包括地理位置属性、终端属性、网段属性、请求方法四种。
4)请求方法属性:从原始网络出口服务器日志中解析获取。
5)网段属性:解析ASN信息后得到。
6)地理位置属性:查询IP归属地中获取。
7)终端属性:基于原始日志的user_agent字段,使用正则表达式匹配获得浏览器、操作系统等终端属性。
2、用户群体动态属性的量化方法设计
用户群体的动态属性通过数理统计的方法得到,包括用户访问量、用户日活跃时长DailyActiveTime、用户活跃度等,指标量化公式如下所示:
用户访问量=count
3、用户群体描述属性的量化方法设计
用户群体描述属性主要是通过用户的价值度及域名信息来对用户群体进行描述,包含用户价值属性、用户访问的域名变化属性、用户访问的域名类型等。
4)用户价值属性
用户价值度可以通过对一段时间内的访问量变化情况进行分析而得出,该属性反映用户的重要程度。采用方差评价模型构建的价值度计算模型如公式2所示。
公式2:
其中m
5)域名变化属性
域名变化属性反映的是服务器IP承载的任意两个域名的距离,采用编辑距离计算其相似度,经过统计分析后建立基于相似度的IP域名变化规律分类规则,分为以下4类:
a)承载域名固定不变且唯一
XXX.com……XXX.com
b)在承载域名的集合内变化
XXX.com YYY.com……XXX.com YYY.com
c)承载域名的末级字段按照某种模式变化
Z1.XXX.com Z15.XXX.com Z7.XXX.com…Z8.XXX.com
d)承载的域名无规律变化
函数edit(i,j)的定义如公式3所示,表示第一个域名长度为i的子串到第二个域名长度为j的子串的距离。
公式3:
若每一个域名与其他n-1个域名的编辑距离均为edit(i,j)==0,则域名变化属性为a类,即承载域名固定不变且唯一;
若每一个域名与其他n-1个域名的编辑距离均为edit(i,j)==L(L为一常数),则域名变化属性为b类,即在承载域名的集合内变化;
若每一个域名与其他n-1个域名的编辑距离均满足0<edit(i,j)<6,则域名变化属性为c类,即承载域名的末级字段按照某种模式变化;
若每一个域名与其他n-1个域名的编辑距离均满足edit(i,j)≥6,则域名变化属性为d类,即承载的域名无规律变化。
6)域名随机性属性
域名随机性属性用信息熵来衡量。信息熵用来描述随机变量的不确定性程度,随机变量的不确定性越大,信息熵越大,反之越小。信息熵也可以用来判断一个域名的混乱程度,关于熵的定义如公式4所示,其中p(i)表示给定字符出现的概率。
公式4:
用户IP的域名随机性属性计算公式如公式5,其中count(client_ip)代表源IP的访问次数,H(x
公式5:
步骤4:基于用户群体属性标签体系生成用户群体画像。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。
- 基于群体行为的用户画像群体获取方法、系统、设备和计算机可读存储介质
- 群体的群体用户画像获取方法和装置