一种结合抽取与分类任务的资管事件抽取方法及系统
文献发布时间:2024-01-17 01:24:51
技术领域
本申请涉及资产管理领域,具体涉及一种结合抽取与分类任务的资管事件抽取方法及系统。
背景技术
资管行业即资产管理行业,指投资者委托金融机构对其资产进行投资与管理,包括了基金、银行理财、保险、信托等机构。目前,资管行业规模不断扩大,但主要依赖于基金经理的个人能力对投资者的财产进行管理与配置,金融科技的融入程度还不够高。但面对互联网时代市场产生的海量信息,个人与团队难以快速从中过滤出高价值信息,并及时对事件进行响应。
事件抽取技术是一种关键信息抽取技术,即在给定自然语言文本中提取相关事件信息,并识别事件的组成要素如时间、地点、国家等。但目前针对资管行业的事件抽取技术还不够成熟,无法有效的在长文本组成的文档抽取事件;若事件中的论元在原文中没有出现,即无法抽取,需要进行分类时,难以处理此类任务等等。且基于序列标注的模型无法解决实体重叠问题,即同一个词可能表示多个事件抽取论元。
发明内容
本申请提供了一种结合抽取与分类任务的资管事件抽取方法,用于在资管领域解决文档级别的事件抽取任务。
为达到上述目的,本申请提供了以下方案:
一种结合抽取与分类任务的资管事件抽取方法,包括以下步骤:
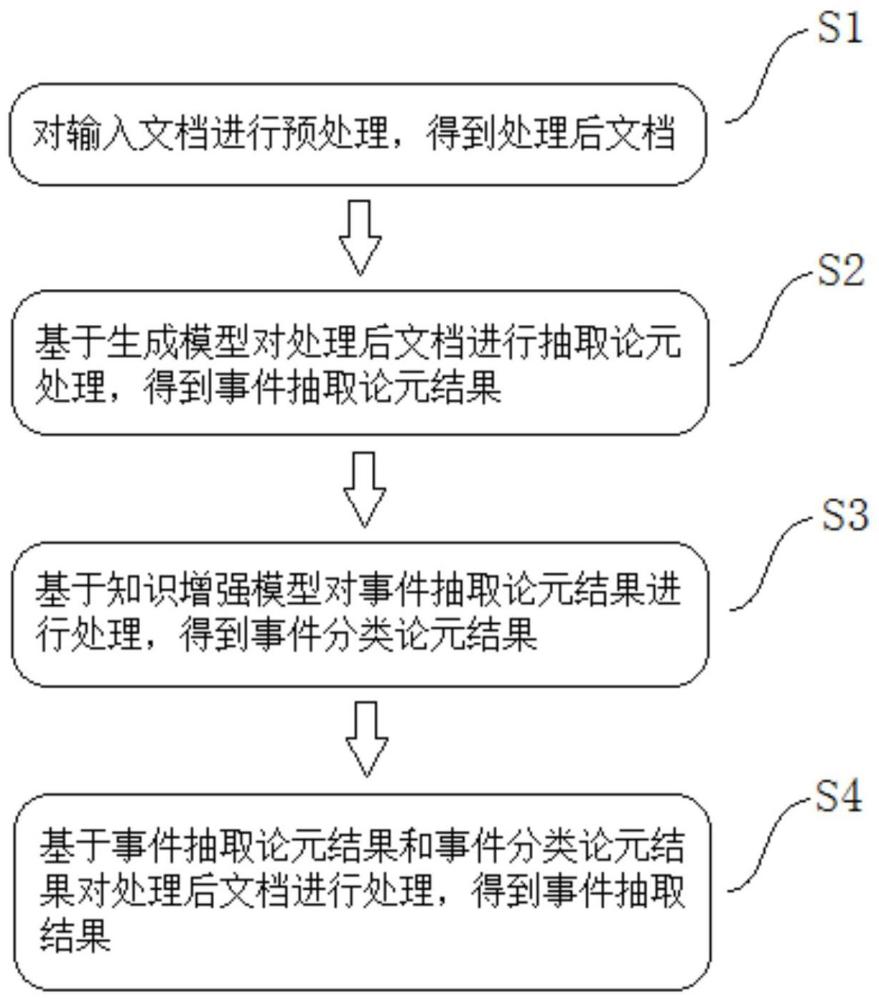
对输入文档进行预处理,得到处理后文档;
基于生成模型对所述处理后文档进行抽取论元处理,得到事件抽取论元结果;
基于知识增强模型对所述事件抽取论元结果进行处理,得到事件分类论元结果;
基于所述事件抽取论元结果和所述事件分类论元结果对所述处理后文档进行处理,得到事件抽取结果。
优选的,所述预处理方法包括:
去除所述输入文档中多余的空格、换行符以及非中英文的符号;
去除所述输入文档中中文占整体文本比例过少的语句;
去除所述输入文档中过短和过长的中文文本。
优选的,所述抽取论元处理的方法包括:
基于所述生成模型,将所述处理后文档转换为词嵌入向量,并构造提示语;
基于所述提示语进行特征提取得到提示语特征,并基于所述提示语特征进行事件抽取论元,得到所述事件抽取论元结果。
优选的,所述事件分类论元结果的获取方法包括:
基于所述事件抽取论元结果构造分类论元提示语;
通过知识增强模型对所述分类论元提示进行分类处理,得到事件分类论元结果。
优选的,所述事件抽取结果的获得方法包括:
结合预训练模型词嵌入表示、关键词字典技术对所述事件抽取论元进行后处理,并与数据库数据进行链接,得到第一结果;
提取所述第一结果中的全部事件,判断所述事件的事件类型;
对相同所述事件类型的所述事件进行合并补全,得到所述事件抽取结果。
本申请还提供了一种结合抽取与分类任务的资管事件抽取系统,包括:文档预处理模块、抽取论元模块、分类论元模块和实体链接模块;
所述文档预处理模块用于对输入文档进行预处理,得到处理后文档;
所述抽取论元模块用于基于生成模型对所述处理后文档进行抽取论元处理,得到事件抽取论元结果;
所述分类论元模块用于基于知识增强模型对所述事件抽取论元结果进行处理,得到事件分类论元结果;
所述实体连接模块用于基于所述事件抽取论元结果和所述事件分类论元结果对所述处理后文档进行处理,得到事件抽取结果。
优选的,所述文档预处理模块的工作流程包括:
去除所述输入文档中多余的空格、换行符以及非中英文的符号;
去除所述输入文档中中文占整体文本比例过少的语句;
去除所述输入文档中过短和过长的中文文本。
优选的,所述抽取论元模块的工作流程包括:
基于所述生成模型,将所述处理后文档转换为词嵌入向量,并构造提示语;
基于所述提示语进行特征提取得到提示语特征,并基于所述提示语特征进行事件抽取论元,得到所述事件抽取论元结果。
优选的,所述分类论元模块的工作流程包括:
基于所述事件抽取论元结果构造分类论元提示语;
通过知识增强模型对所述分类论元提示进行分类处理,得到事件分类论元结果。
优选的,所述实体链接模块的工作流程包括:
结合预训练模型词嵌入表示、关键词字典技术对所述事件抽取论元进行后处理,并与数据库数据进行链接,得到第一结果;
提取所述第一结果中的全部事件,判断所述事件的事件类型;
对相同所述事件类型的所述事件进行合并补全,得到所述事件抽取结果。
本申请的有益效果为:
本申请能够同时处理事件中的抽取论元与分类论元,给事件模板的定义带来更大的灵活性,以适用于更广阔的应用场景。并且由于应用生成模型,能够很好的解决实体重叠的问题。
附图说明
为了更清楚地说明本申请的技术方案,下面对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例一的方法流程示意图;
图2为本申请实施例一的具体事件模板示意图;
图3为本申请实施例二的系统结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
首先介绍本实施例中的技术名词:
抽取论元定义为与事件相关的能在原文中确定论元起始位置和终止位置的论元,例如“今年下半年天然气价格有望翻倍”中的“价格上涨”事件中“产品”论元就是抽取论元,其内容为“天然气”,论元起始位置为5,终止位置为8。
分类论元定义为与事件相关但是不能在原文中确定论元起始位置和终止位置的论元,需要通过分类方法进行另外分类的论元。例如“今年下半年天然气价格有望翻倍”中的“价格上涨”事件中“REALIS”论元(判定一个事件是已经发生还是未来预计发生)就是分类论元,其分类为未来预计发生。
为使本申请的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本申请作进一步详细的说明。
实施例一
在本实施例一中,如图1所示,一种结合抽取与分类任务的资管事件抽取方法,包括以下步骤:
S1.对输入文档进行预处理,得到处理后文档。
其中,预处理方法包括:去除输入文档中多余的空格、换行符以及非中英文的符号;去除输入文档中中文占整体文本比例过少的语句;去除输入文档中过短和过长的中文文本。
在本实施例中,首先定义首先定义资管领域的13种事件模板,事件模板包括事件名以及需要抽取的事件要素,具体事件模板如图2所示;再对输入文档Text进行预处理,以去除多余的空格、换行符以及非中英文的符号;去除中文占整体文本比例小于30%的语句;去除过短和过长的中文文本,其中,过短文本为字符数小于3个的文本,过长文本为字符数大于512个的文本。
S2.基于生成模型对处理后文档进行抽取论元处理,得到事件抽取论元结果。
其中,抽取论元处理的方法包括:基于生成模型,将处理后文档转换为词嵌入向量,并构造提示语;基于提示语进行特征提取得到提示语特征,并基于提示语特征进行事件抽取论元,得到事件抽取论元结果。
在本实施例中,构建用于提示生成模型的提示语(prompt)输入生成模型。具体构建方法为,假设x为事件名,而s
[event]x[/event][asso_type]s
其中,event表示事件,而asso_type表示实体类型。将prompt构造好以后,在其后拼接上原始文本,并对超出长度的文本进行截断处理,最终生成模型的输入x_ext如下:
[Prompt_ext]+[Text]
之后将文本输入至经过资管事件微调后的T5生成模型进行预测,T5生成模型由编码器和解码器组成,编码器负责编码文本的语义特征信息,解码器用于生成抽取结果。模型具体结构如下:
编码器由12个编码块顺序堆叠组成,每个编码块存在多头注意力网络层、前馈神经网络层,并且每一层均应用残差避免深度神经网络的梯度消失与爆炸问题。每个多头注意力网络由16个自注意力网络组成。
解码器由12个解码块顺序堆叠组成,每个解码块存在掩码多头注意力层、多头注意力层、前馈神经网络层,每一层同样使用残差技术。掩码多头注意力层在多头注意力层的基础上添加掩码机制防止训练时的信息泄漏问题。解码块的多头注意力层的key和value为编码器的特征向量。
输入文本至生成模型后,将自回归的生成结构化的输出,输出结果y
y
S3.基于知识增强模型对事件抽取论元结果进行处理,得到事件分类论元结果。
其中,事件分类论元结果的获取方法包括:基于事件抽取论元结果构造分类论元提示语;通过知识增强模型对分类论元提示进行分类处理,得到事件分类论元结果。
在本实施例中,将结合输出结果y
将y
事件:[X],事件触发词:[Trigger],事件要素:[Cls]
之后将prompt_cls与原始文本Text拼接作为知识模型的输入x_cls:
[prompt_cls]+[Text]
之后针对每个需要进行分类的论元ci,均构造一个x_cls作为输入并使用经过资管事件微调的知识增强模型Ernie进行分类处理。最后将每个c
y
其中,c
S4.基于事件抽取论元结果和所述事件分类论元结果对所述处理后文档进行处理,得到事件抽取结果。
其中,事件抽取结果的获得方法包括:结合预训练模型词嵌入表示、关键词字典技术对事件抽取论元进行后处理,并与数据库数据进行链接,得到第一结果;提取第一结果中的全部事件,判断事件的事件类型;对相同事件类型的事件进行合并补全,得到事件抽取结果。
在本实施例中,将y
首先将s
其中x
y
提取y
根据基于ERNIE的命名实体识别模型识别新闻标题关键实体,本系统中定义的关键实体表示标题中与资管领域相关的关键主体,例如企业名、国家名、行业名、产品名等。之后遍历抽取出的事件,将每个事件中缺失的事件论元根据预设的事件模板进行填槽补全,最终得到文档级别的事件抽取结果。
实施例二
在本实施例二中,如图3所示,一种结合抽取与分类任务的资管事件抽取系统,包括:文档预处理模块、抽取论元模块、分类论元模块和实体链接模块;
文档预处理模块用于对输入文档进行预处理,得到处理后文档;文档预处理模块的工作流程包括:去除输入文档中多余的空格、换行符以及非中英文的符号;去除输入文档中中文占整体文本比例过少的语句;去除输入文档中过短和过长的中文文本。
抽取论元模块用于基于生成模型对处理后文档进行抽取论元处理,得到事件抽取论元结果;抽取论元模块的工作流程包括:基于生成模型,将处理后文档转换为词嵌入向量,并构造提示语;基于提示语进行特征提取得到提示语特征,并基于提示语特征进行事件抽取论元,得到事件抽取论元结果。
分类论元模块用于基于知识增强模型对事件抽取论元结果进行处理,得到事件分类论元结果;分类论元模块的工作流程包括:基于事件抽取论元结果构造分类论元提示语;通过知识增强模型对分类论元提示进行分类处理,得到事件分类论元结果。
实体连接模块用于基于事件抽取论元结果和事件分类论元结果对处理后文档进行处理,得到事件抽取结果;实体链接模块的工作流程包括:结合预训练模型词嵌入表示、关键词字典技术对所述事件抽取论元进行后处理,并与数据库数据进行链接,得到第一结果;提取第一结果中的全部事件,判断事件的事件类型;对相同事件类型的事件进行合并补全,得到事件抽取结果。
以上所述的实施例仅是对本申请优选方式进行的描述,并非对本申请的范围进行限定,在不脱离本申请设计精神的前提下,本领域普通技术人员对本申请的技术方案做出的各种变形和改进,均应落入本申请权利要求书确定的保护范围内。
- 一种用于中文新闻突发事件的文本分类与抽取方法
- 一种建筑施工工序约束的自动抽取和分类方法及系统
- 一种文本抽取任务中的事件分割抽取方法及系统
- 提升事件抽取标注效率的系统及方法、事件抽取方法及系统