一种用真实流量进行测试的方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于网约车技术领域,具体涉及一种用真实流量进行测试的方法。
背景技术
随着网约车业务越来越复杂,功能越来越多样,用户场景越来越多,每次改动需要回归的点也就越多,简单的使用模拟流量已经很难覆盖到线上真实的流量情况;尤其是LBS里程计算这部分,逻辑功能复杂,影响较大,一个小的点的改动,可能造成里程计算的失误,导致计费不准的问题,一旦出现,就会给公司造成不可估量的损失。
所以,每次改动,必须在保证现有逻辑的完整性和正确性的基础上,同时保证新增逻辑的正确性,新逻辑的改动点,可以通过场景设计来针对性的测试,复杂的历史逻辑回归是一个很大的挑战,目前采用小流量灰度->观察发现问题->回滚解决问题->再次小流量发布->观察发现问题->回滚解决,直到灰度没有问题,才真正完成上线过程,复杂性高,且极易出现问题。
里程计算模块逻辑复杂,逻辑计算的改动,会带来极大的风险,甚至造成不可估量的损失;
真实场景较多,修改后历史逻辑的正确性,人工模拟案例,无法充分验证;
无法确定逻辑修改后,同样的订单,里程偏差有多少,对线上的影响程度未知;
小流量灰度->观察发现问题->回滚解决问题->重新发布的小流量循环发布方式,成本较高,且不确定性较高。
发明内容
本发明的目的在于提供一种用真实流量进行测试的方法,方便逻辑修改后,随时使用线上流量进行历史逻辑测试;减少上线风险;将风险控制在上线前。
为实现上述目的,本发明提供如下技术方案:本发明是从hbase获取线上流量数据,得到总体样本数据,经过数据抽样模块,按一定比例和规则抽取线上数据,将抽样后的订单数据放入Pika,根据订单数据,从hbase拉取订单和轨迹列表,然后将轨迹数据模拟心跳时间按照原时间序列发送给LBS系统,重新进行里程计算,订单模拟完成后,从里程计算服务接口获取本次计算的里程结果,并通过Kafka最终存储到大数据系统Hive,供后续对比分析使用;具体如下:
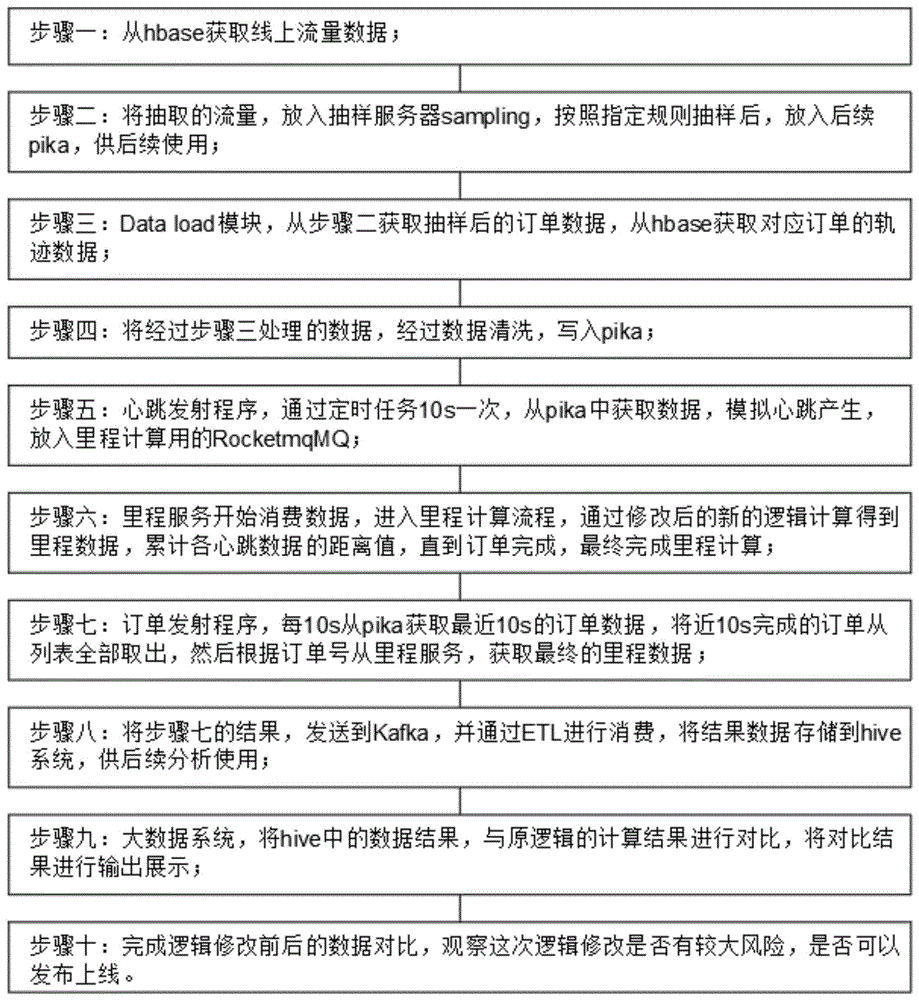
步骤一:从hbase获取线上流量数据;
步骤二:将抽取的流量,放入抽样服务器sampling,按照指定规则抽样后,放入后续pika,供后续使用;
步骤三:Data load模块,从步骤二获取抽样后的订单数据,从hbase获取对应订单的轨迹数据;
步骤四:将经过步骤三处理的数据,经过数据清洗,写入pika;
步骤五:心跳发射程序,通过定时任务10s一次,从pika中获取数据,模拟心跳产生,放入里程计算用的RocketmqMQ;
步骤六:里程服务开始消费数据,进入里程计算流程,通过修改后的新的逻辑计算得到里程数据,累计各心跳数据的距离值,直到订单完成,最终完成里程计算;
步骤七:订单发射程序,每10s从pika获取最近10s的订单数据,将近10s完成的订单从列表全部取出,然后根据订单号从里程服务,获取最终的里程数据;
步骤八:将步骤七的结果,发送到Kafka,并通过ETL进行消费,将结果数据存储到hive系统,供后续分析使用;
步骤九:大数据系统,将hive中的数据结果,与原逻辑的计算结果进行对比,将对比结果进行输出展示;
步骤十:完成逻辑修改前后的数据对比,观察这次逻辑修改是否有较大风险,是否可以发布上线。
作为本发明的一种优选的技术方案,所述hbase用来存储线上订单数据,包括每个时间点上报的司机心跳数据。
作为本发明的一种优选的技术方案,所述抽样服务器sampling包括指定比例、指定来源、指定城市规则进行抽样。
作为本发明的一种优选的技术方案,所述步骤四中,写入pika,具体如下:10s写一次,将完成时间在最近10s的订单放入一个列表中,用cityName_时间作为缓存key,eg。
作为本发明的一种优选的技术方案,所述步骤五中,定时任务10s一次是为了与原心跳采集时间间隔保持一致。
作为本发明的一种优选的技术方案,所述ETL用来消费kafka的结果信息消息,将计算结果存储到hiva中保存。
作为本发明的一种优选的技术方案,所述hive中的数据结果为逻辑修改后的里程计算结果。
与现有技术相比,本发明的有益效果是:
方便逻辑修改后,随时使用线上流量进行历史逻辑测试;
对比逻辑修改前后,计算得到的里程偏差,若有较大偏差,及时解决,减少上线风险;
避免小流量灰度->发现问题->回滚解决->小流量灰度的过程,将风险控制在上线前。
附图说明
图1为本发明的测试方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种用真实流量进行测试的方法,包括如下步骤:
步骤一:从hbase中抽取线上订单数据;hbase是一种高性能的分布式存储数据库,支持海量数据存储,本设计中用来存储线上订单数据,包括每个时间点上报的司机心跳数据,即:司机定位点数据,10s从APP上报一次当前位置,用来计算里程;
步骤二:将抽取的流量,放入抽样服务器sampling,按照指定规则抽样后,放入后续pika,供后续使用;抽样服务器sampling里边是各种抽样规则,可以按照各种规则,包括指定比例、指定来源、指定城市规则进行抽样;pika是一种大容量缓存服务,可以存储大量数据,并快速提取,比hbase的读写效率高,一般用来临时存储数据,这里用来缓存订单数据和步骤三抽样组装后的订单及其心跳数据;
步骤三:Data load模块,从步骤二获取抽样后的订单数据,从hbase获取对应订单的轨迹数据;habase分成不同的数据库,每个数据库取一个名字,用来存储不同的数据,比如:order数据库用来存储订单数据,heartbeat数据库用来存储心跳数据,订单和心跳数据通过订单号来关联,比如:订单号X20230602230232,order库会存储订单基本数据,包括乘车人、预订人、用车时间、上下车地址;heartbeat数据库存储心跳数据,包括定位信息,上报时间,踩点类型,每10s上报一次,假设一个单服务时长20min,会有120条心跳数据记录;
步骤四:将经过步骤三处理的数据,经过数据清洗,写入pika;数据清洗如下:将日期信息换成当前时间数据,不然订单已完成,无法正常流转,进入lbs系统后,会重新记录当前时间,作为订单心跳时间,将订单完成时间与订单号一起,作为缓存key,eg.订单X20230602230232,订单完成时间10:10:20,换算成当天该时间点对应的时间戳,比如是1685671820,则记为X20230602230232_1685671820;写入pika具体如下:10s写一次,将完成时间在最近10s的订单放入一个列表中,用cityName_时间作为缓存key,eg.还以上述示例订单为例,则key为,BeiJing_1685671820;
步骤五:心跳发射程序,通过定时任务10s一次,与原心跳采集时间间隔保持一致,从pika中获取数据,模拟心跳产生,放入里程计算用的RocketmqMQ;RocketmqMQ,是一种消息队列服务,可以将生产者和消费者解耦,生产者专注于数据生产,消费者专注于自己的消费逻辑,可以同时支持多个消费组,多组业务逻辑;
步骤六:里程服务开始消费数据,进入里程计算流程,通过修改后的新的逻辑计算得到里程数据,累计各心跳数据的距离值,直到订单完成,最终完成里程计算;
步骤七:订单发射程序,每10s从pika获取最近10s的订单数据,将近10s完成的订单从列表全部取出,然后根据订单号从里程服务,获取最终的里程数据;每10s从pika获取最近10s的订单数据,比如当前时间时间戳为1685671820上述订单示例时间戳,则,取缓存key为cityName_1685671820的订单列表;
步骤八:将步骤七的结果,发送到Kafka,并通过ETL进行消费,将结果数据存储到hive系统,供后续分析使用;kafka是一种大数据消息队列,也可以用Rocketmq,这里是为了与原有业务系统保持一致,才使用kafka;ETL是服务名称,用来消费kafka的结果信息消息,将计算结果存储到hiva中保存,也可以在步骤七中,直接将数据写入hive,不经过kafka和ETL,但由于数据量较大,而且时间集中,对hive的写入性能有很大的挑战,所以这里使用kafka来进行服务解耦,kafka负责将结果写入消息队列,ETL服务根据hive的写入能力,灵活存入;
步骤九:大数据系统,将hive中的数据结果,与原逻辑的计算结果进行对比,将对比结果进行输出展示;hive中的数据结果为逻辑修改后的里程计算结果;原逻辑的计算结果为线上里程结果;
步骤十:完成逻辑修改前后的数据对比,观察这次逻辑修改是否有较大风险,是否可以发布上线。
尽管已经示出和描述了本发明的实施例,详见上述详尽的描述,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种限速阀瞬时流量特性测试装置及其测试方法
- 一种在整车上进行变速箱机械效率测试系统及测试方法
- 一种阀门流量流阻测试系统及其进行小微流量测试的方法
- 一种阀门流量流阻测试系统及其进行小微流量测试的方法