一种基于云凌容器云平台的云原生数据流处理架构
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于云原生数据流处理技术领域,具体地,涉及一种基于云凌容器云平台的云原生数据流处理架构。
背景技术
云原生数据流处理技术是在云计算和大数据技术的背景下应运而生的一种数据处理方式。云计算的兴起使得企业能够将应用程序和数据存储在云端,通过弹性资源的分配和管理,实现高可靠性、高可扩展性和高性能的计算。而大数据的涌现则带来了海量数据的挑战,传统的批处理方式已经不能满足实时数据处理的需求。因此,云原生数据流处理技术应运而生,旨在处理实时生成的数据流,实现实时计算、过滤、聚合和转换。
云原生数据流处理技术的背景可以追溯到分布式流处理系统的发展,早期的分布式流处理系统,如Apache Storm和Apache Flink,解决了实时数据处理的问题,但它们在部署和管理上存在一些挑战。随着云计算的普及和发展,云原生架构应运而生,提供了更高效、灵活和弹性的方式来构建和管理应用程序。云原生架构的核心理念是将应用程序设计为一组微服务,利用容器化和编排技术,实现了高度可扩展性和容错性,允许根据实际需求动态调整计算资源,提供弹性的处理能力,从而适应不断变化的数据流量。
在云原生数据流处理技术的背景下,还出现了一些相关的技术和工具。例如,Kubernetes作为一个容器编排平台,可以管理和调度数据流处理任务的容器,实现高可用性和自动化管理。另外,Apache Kafka作为一种高吞吐量的分布式消息队列系统,为数据流处理提供了可靠的数据传输和缓冲功能。
云原生数据流处理技术的不足是处理延迟,由于数据流处理系统需要保证实时性,但在处理大规模数据流时,处理延迟可能会增加,导致实时性下降,这可能由于数据流量过大、计算任务复杂或者系统负载过高等原因引起,影响系统的响应时间和性能。
发明内容
针对现有技术中存在的问题,本发明提供了一种基于云凌容器云平台的云原生数据流处理架构,降低数据流处理的延迟并保持较高的吞吐量。
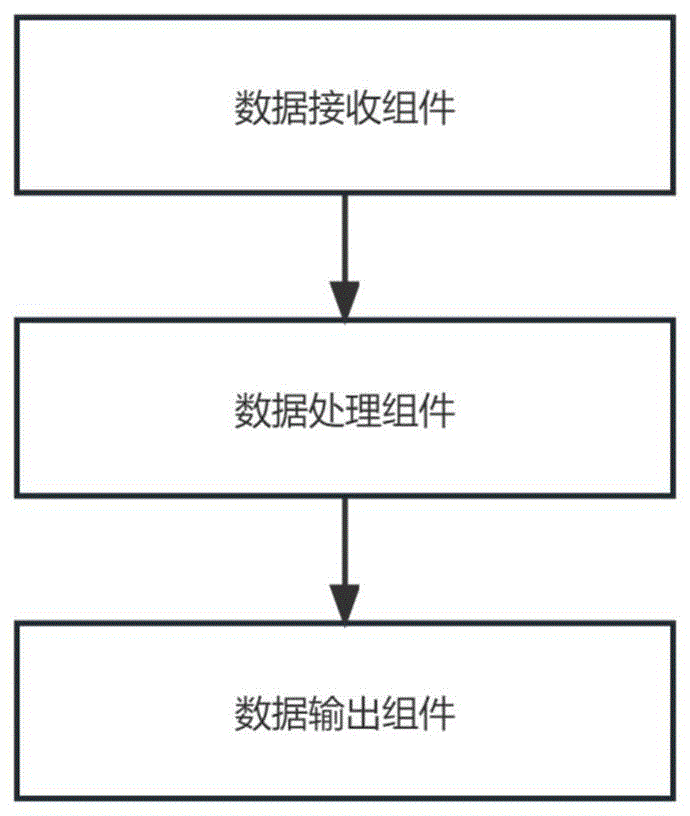
为实现上述技术目的,本发明采用如下技术方案:一种基于云凌容器云平台的云原生数据流处理架构,包括依次连接的数据接收组件、数据处理组件和数据输出组件,所述数据接收组件利用Count-Min Sketch对容器的资源使用情况进行频率统计;所述数据处理组件对资源使用的频率确定延迟源原因,并制定降低延迟策略;所述数据输出组件通过降低延迟策略为容器分配资源。
进一步地,所述数据接收组件利用Count-Min Sketch对容器的资源使用情况进行频率统计的具体过程为:
A、创建了一个Count-Min Sketch实例,包含:哈希函数的数量k和二维数组的宽度w,将[k,w]组成一个二维数组CM,每个元素初始化为0:CM[i][j]=0,其中,1 B、处理云凌容器云平台的云原生数据流中的每个数据x时,使用k个哈希函数h1,h2,...,hk计算k个哈希索引h1(x),h2(x),...,hk(x),并在对应的计数器中加一,对所有i执行:CM[i][hi(x)]=CM[i][hi(x)]+1; C、当想要查询某个特定数据的资源使用频率时,使用B中的方法计算特定数据的哈希索引,并找到各个哈希函数对应的计数器中的最小值,将最小值将作为对特定数据的资源使用频率的估计:f(x)=min(CM[i][hi(x)]),其中1 D、将估计的资源使用频率求均值,预测出特定数据的资源使用频率。 进一步地,所述数据处理组件对资源使用的频率确定延迟源原因的具体过程为: (1)当预测出特定数据的资源使用率为(0,0.4)时,存在计算任务复杂度高的问题; (2)当预测出特定数据的资源使用率为[0.4,0.7)时,存在系统负载过高的问题; (3)当预测出特定数据的资源使用率为[0.7,1]时,存在数据流量大的问题。 进一步地,所述降低延迟策略具体为: (1)当云原生数据流中数据流量超过网络带宽的有效利用范围,需要进行数据压缩; (2)当系统负载高到存在任务排队等待资源,进行资源扩容; (3)当计算任务复杂度高导致单次处理时间加长,进行资源扩容。 进一步地,还包括:对云原生数据流按照阶段划分并使用缓冲区进行优化处理,将云原生数据流并行执行。 进一步地,对云原生数据流进行优化处理的过程具体为:通过merge_aggregations函数遍历云原生数据流,将计算任务聚合;通过process_data函数调整任务顺序;通过pipeline_processing函数对云原生数据流进行流水线处理;通过incremental_processing函数进行云原生数据流的增量计算。 与现有技术相比,本发明具有如下有益效果:本发明基于云凌容器云平台的云原生数据流处理架构通过Count-Min Sketch对容器的资源使用情况进行频率统计,并利用哈希函数进行压缩,以牺牲一定的精确性来提高计算效率,这样可以减少存储和计算的开销,从而降低数据流处理的延迟,并保持较高的吞吐量。本发明的云原生数据流处理方法在一定程度上解决了处理延迟的问题,提高了系统的实时性和性能。 附图说明 图1为本发明基于云凌容器云平台的云原生数据流处理架构的示意图。 具体实施方式 下面结合附图对本发明的技术方案作进一步地解释说明。 云凌云平台是一个云计算资源管理平台,用于管理容器和资源分配,云凌云平台需要实时监测资源使用情况,以便合理分配计算资源,优化云计算体验。如图1为本发明基于云凌容器云平台的云原生数据流处理架构的示意图,该云原生数据流处理架构包括依次连接的数据接收组件、数据处理组件和数据输出组件。云凌云平台会监测各个容器和容器的资源使用情况,如果某个容器的资源占用量急剧增加,系统会识别到资源使用峰值,可能导致延迟增加,在这种情况下,系统可以暂时限制容器的资源分配,以保障其他容器的稳定运行。因此,数据接收组件利用Count-Min Sketch对容器的资源使用情况进行频率统计。 在高峰时段,系统可能因为资源分配调整和容器管理等任务而出现计算任务复杂度升高,影响资源管理效率。系统可以通过智能调度,将资源分配任务分发到多个处理节点,以分散计算负载,降低延迟。因此,数据处理组件对资源使用的频率确定延迟源原因,并制定降低延迟策略。 需要进行识别延迟源系统实时输出资源分配结果时,监测输出延迟,确保用户和应用程序能够及时获取资源调整的反馈。如果延迟较高,数据输出组件通过降低延迟策略为容器分配资源,降低响应时间。 本发明通过对云原生数据流处理架构进行设计,实现数据流处理的并行处理,提高系统的处理能力和效率。通过使用容器化技术,实现资源的动态调度和管理,提高系统的可扩展性和弹性,同时增强系统的稳定性和安全性。 本发明中数据接收组件利用Count-Min Sketch对容器的资源使用情况进行频率统计,减小计算复杂度和存储需求,提升数据流处理效率,具体过程如下: A、创建了一个Count-Min Sketch实例,包含:哈希函数的数量k和二维数组的宽度w,这些参数会影响云原生数据流处理的精度和内存消耗,将[k,w]组成一个二维数组CM,每个元素初始化为0:CM[i][j]=0,其中,1 B、处理云凌容器云平台的云原生数据流中的每个数据x时,使用k个哈希函数h1,h2,...,hk计算k个哈希索引h1(x),h2(x),...,hk(x),并在对应的计数器中加一,对所有i执行:CM[i][hi(x)]=CM[i][hi(x)]+1; C、当想要查询某个特定数据的资源使用频率时,使用B中的方法计算特定数据的哈希索引,并找到各个哈希函数对应的计数器中的最小值,将最小值将作为对特定数据的资源使用频率的估计:f(x)=min(CM[i][hi(x)]),其中1 D、将估计的资源使用频率求均值,预测出特定数据的资源使用频率。 在Count-Min Sketch中,参数`w`和`k`的确定分别受到误差率和置信度的影响。`w`反映了所接受的相对误差上限,近似于自然数底除以误差率,而`k`则根据所需的误差概率置信度决定,近似于置信度的自然对数的负值。在实际应用中,`w`的取值受限于内存,而`k`通常介于2到10之间,以权衡误差、置信度。 在对频率估计要求极高精度的场景,可考虑将误差率设置为0.001,置信度设置为0.01,建议使用宽度`w`约为2718的二维数组以及大约5个独立哈希函数。在对频率估计中等精度需求场景下,如:对于网站点击流统计等需要相对准确但允许一定误差的场景,将误差率设置为0.01,置信度设置为0.05,使用宽度`w`约为272的数组和大约3个独立哈希函数。针对物联网设备数据流处理等大规模场景,可降低精度要求,将误差率设置为0.05,置信度设置为0.1,使用较小的宽度`w`约为55的数组和大约3个独立哈希函数,以实现高效计算。对于实时流分析、初步数据筛查等场景,考虑快速估计,将误差率设置为0.1,置信度设置为0.2,使用更小的宽度`w`约为28的数组和大约2个独立哈希函数,以快速获取初步结果。 通过调整参数`w`和`k`,提升Count-Min Sketch在云凌容器云平台通过集成监控和日志记录功能,可以实时监测系统的性能指标和运行状态,及时发现问题并进行调优。Count-Min Sketch是一种基于哈希函数和二维数组的近似计算算法,用于数据流处理中的频率统计,通过压缩数据和降低计算复杂度,能够在较小的存储空间和较快的计算速度下实现频率统计,在一定程度上降低处理延迟。 本发明中数据处理组件对资源使用的频率确定延迟源原因的具体过程为: (1)当预测出特定数据的资源使用率为(0,0.4)时,由于复杂计算任务的比例上升,导致处理时间变长,存在计算任务复杂度高的问题; (2)当预测出特定数据的资源使用率为[0.4,0.7)时,由于系统资源有限,任务排队等待资源,导致存在系统负载过高的问题; (3)当预测出特定数据的资源使用率为[0.7,1]时,此时,数据流量接近或超过网络带宽极限,存在数据流量大的问题。 采取针对性的优化策略,动态调整资源分配、任务调度等,以最大限度地降低延迟、优化系统吞吐量和提升用户体验。 针对不同延迟源,使用低延迟的数据处理技术来处理实时数据流,本发明中降低延迟策略具体为: (1)当云原生数据流中数据流量超过网络带宽的有效利用范围,需要进行数据压缩; (2)当系统负载高到存在任务排队等待资源,进行资源扩容; (3)当计算任务复杂度高导致单次处理时间加长,进行资源扩容。 在本发明的一个技术方案中,还包括:对云原生数据流按照阶段划分并使用缓冲区进行优化处理,将云原生数据流并行执行,最小化等待时间和数据传输,从而降低延迟。具体地,对云原生数据流进行优化处理的过程具体为: 通过merge_aggregations函数遍历云原生数据流,将计算任务聚合,有助于减少对相同数据的重复计算,提高计算效率;通过process_data函数调整任务顺序,通过对任务依赖关系进行排序,确保相互依赖的任务在合适的顺序执行,减少等待时间,从而优化数据流处理的速度;通过pipeline_processing函数对云原生数据流进行流水线处理,将数据分批处理,并在每个阶段之间传递结果,从而实现并行处理,提高处理效率;通过incremental_processing函数进行云原生数据流的增量计算,在处理数据流时,初始化增量计算状态,然后对每个数据元素执行增量计算操作,更新状态。这样可以避免对整个数据集进行重复计算,提高计算效率。 本发明基于云凌容器云平台的云原生数据流处理方法适用于各种大规模数据处理场景,例如,实时监控系统、实时分析和预测、大数据流量处理等。该方法可以快速部署、弹性伸缩,并具备高性能、稳定和安全的特性,满足了各种实时数据处理需求。通过提高数据处理的效率和实时性,可以帮助企业实现更快速的决策和响应,提升业务的竞争力。同时,采用容器化部署和自动化运维可以降低成本和管理复杂性。这种高性能、稳定和安全的数据流处理技术在各个行业的实时数据处理应用中具有广泛的商业应用前景和市场潜力。 以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施方式,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 一种基于云原生架构的大数据流处理方法和装置
- 一种基于云原生架构的大数据流处理方法和装置