基于多模态模型的证照识别方法及系统
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及多模态模型及图像识别技术领域,具体地说是一种基于多模态模型的证照识别方法及系统。
背景技术
随着深度学习相关技术不断发展,神经网络模型在很多行业和场景得到广泛应用,尤其是在类似证照识别的通用领域,神经网络模型由于可以训练的数据量大,模型更加复杂,往往取得更好的结果,深度学习模型已经在证照识别领域成为主流,识别准确率较高。证照识别技术目前广泛应用到智慧城市、智能审批等各个领域。首先,使用现成的OCR引擎阅读文本,然后从获得的文本中提取目标字段。这些方法的主要缺点是依赖于外部OCR引擎。
故如何直接将输入的文本图像映射到期望的结构化输出,提高证照识别的准确率是目前亟待解决的技术问题。
发明内容
本发明的技术任务是提供一种基于多模态模型的证照识别方法及系统,来解决如何直接将输入的文本图像映射到期望的结构化输出,提高证照识别的准确率的问题。
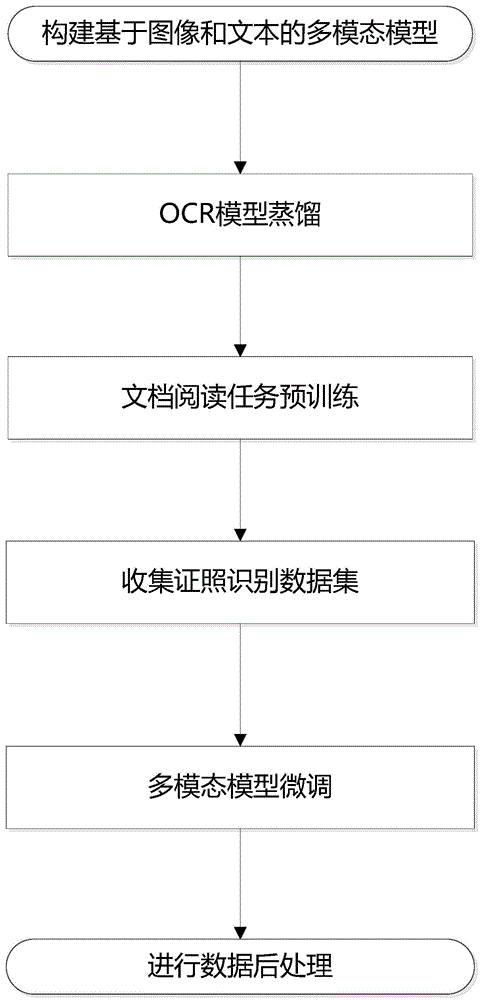
本发明的技术任务是按以下方式实现的,一种基于多模态模型的证照识别方法,该方法具体如下:
构建基于图像和文本的多模态模型;
蒸馏OCR模型;
预训练文档阅读任务;
收集证照识别数据集;
微调多模态模型;
数据后处理。
作为优选,构建基于图像和文本的多模态模型具体如下:
多模态模型由基于Transformer的视觉编码器和文本解码器模块组成;其中,视觉编码器由旨在提取字符内部的局部模式的卷积神经网络ConvNet和旨在捕获长期依赖关系的Swin Transformer模型构成;具体如下:
将输入的图像通过视觉编码器进行编码,生成包含相关视觉信息的特征数据;
将图像特征数据与任务令牌一起馈送到文本解码器,自动回归地生成目标令牌;其中,文本解码器由n个Transformer层组成,每一层由多头自注意子层、多头交叉注意子层和前馈子层组成。
更优地,蒸馏OCR模型具体如下:
使用PP-OCR-V3的识别网络将pointwise卷积应用于基于ConvNet块的输出,获得与PP-OCR-V3识别骨干相同的输出通道数,并使用L2损失计算两个网络输出的损失,通过模型训练优化使得ConvNet学习字符识别能力;其中,训练数据使用开源的OCR相关数据集。
更优地,预训练文档阅读任务具体如下:
多模态模型以先前的文本标记和输入图像为条件,学习预测下一个字符;将输入图像分成32×32的块,并掩蔽大约15%的块,让多模态模型预测被掩盖的块的文字;
收集证照识别数据集具体如下:
通过互联网或业务渠道搜集证照识别相关数据集,并使用商业OCR软件配合人工对数据集进行标注。
更优地,微调多模态模型具体如下:
在预训练阶段后,多模态模型将对信息提取任务进行微调;
在证照识别数据集上对多模态模型进行微调;
文本解码器最后一层transformer block输出的所有输出序列的隐藏层状态的特征表示向量,再将其输入进额外的线性多分类器中进行分类,即可完成块序列分类。
更优地,数据后处理具体如下:
将输出令牌序列转换为JSON格式,添加两个特殊标记[Start*]和[End*];其中,*表示要提取的每个字段;
若输出令牌序列的结构错误,简单地将该字段视为丢失。
一种基于多模态模型的证照识别系统,该系统包括:
构建模块,用于构建基于图像和文本的多模态模型;
蒸馏模块,用于蒸馏OCR模型;
预训练模块,用于预训练文档阅读任务;
收集模块,用于收集证照识别数据集;
微调模块,用于微调多模态模型;
数据处理模块,用于数据后处理。
作为优选,所述构建模块中的多模态模型由基于Transformer的视觉编码器和文本解码器模块组成;其中,视觉编码器由旨在提取字符内部的局部模式的卷积神经网络ConvNet和旨在捕获长期依赖关系的Swin Transformer模型构成;构建模块的工作过程具体为:将输入的图像通过视觉编码器进行编码,生成包含相关视觉信息的特征数据;再将图像特征数据与任务令牌一起馈送到文本解码器,自动回归地生成目标令牌;其中,文本解码器由n个Transformer层组成,每一层由多头自注意子层、多头交叉注意子层和前馈子层组成;
所述蒸馏模块的工作过程具体为:使用PP-OCR-V3的识别网络将pointwise卷积应用于基于ConvNet块的输出,获得与PP-OCR-V3识别骨干相同的输出通道数,并使用L2损失计算两个网络输出的损失,通过模型训练优化使得ConvNet学习字符识别能力;其中,训练数据使用开源的OCR相关数据集;
所述预训练模块的工作过程具体为:多模态模型以先前的文本标记和输入图像为条件,学习预测下一个字符;将输入图像分成32×32的块,并掩蔽大约15%的块,让多模态模型预测被掩盖的块的文字;
所述收集模块的工作过具体为:通过互联网或业务渠道搜集证照识别相关数据集,并使用商业OCR软件配合人工对数据集进行标注;
所述微调模块的工作过具体为:在预训练阶段后,多模态模型将对信息提取任务进行微调;在证照识别数据集上对多模态模型进行微调;文本解码器最后一层transformerblock输出的所有输出序列的隐藏层状态的特征表示向量,再将其输入进额外的线性多分类器中进行分类,即可完成块序列分类;
所述数据处理模块的工作过程具体为:将输出令牌序列转换为JSON格式,添加两个特殊标记[Start*]和[End*];其中,*表示要提取的每个字段;若输出令牌序列的结构错误,简单地将该字段视为丢失。
一种电子设备,包括:存储器和至少一个处理器;
其中,所述存储器上存储有计算机程序;
所述至少一个处理器执行所述存储器存储的计算机程序,使得所述至少一个处理器执行如上述的基于多模态模型的证照识别方法。
一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序可被处理器执行以实现如上述的基于多模态模型的证照识别方法。
本发明的基于多模态模型的证照识别方法及系统具有以下优点:
(一)本发明直接将输入的文档图像映射到期望的结构化输出,不依赖于OCR,可以轻松地以端到端的方式进行训练;同时相比以前的端到端方法的不同之处在于它能够更好地提取区分字符特征,使其能够高效地感知字符内部模式和字符间依赖关系;
(二)本发明通过结合多模态预训练模型以及特定任务数据微调,模型准确率得到大幅提升,具有较高的实用价值和创新价值;
(三)本发明将Transformer模型在到文本、图像等领域得到广泛应用,使用端到端的Transformer模型解决图像关键信息提取成为可能。
附图说明
下面结合附图对本发明进一步说明。
附图1为基于多模态模型的证照识别方法的流程框图。
具体实施方式
参照说明书附图和具体实施例对本发明的基于多模态模型的证照识别方法及系统作以下详细地说明。
实施例1:
如附图1所示,本实施例提供了一种基于多模态模型的证照识别方法,该方法具体如下:
S1、构建基于图像和文本的多模态模型;
S2、蒸馏OCR模型;
S3、预训练文档阅读任务;
S4、收集证照识别数据集;
S5、微调多模态模型;
S6、数据后处理。
本实施例步骤S1中的构建基于图像和文本的多模态模型具体如下:
多模态模型由基于Transformer的视觉编码器和文本解码器模块组成;其中,视觉编码器由旨在提取字符内部的局部模式的卷积神经网络ConvNet和旨在捕获长期依赖关系的Swin Transformer模型构成;具体如下:
S101、将输入的图像通过视觉编码器进行编码,生成包含相关视觉信息的特征数据;
S102、将图像特征数据与任务令牌一起馈送到文本解码器,自动回归地生成目标令牌;其中,文本解码器由n个Transformer层组成,每一层由多头自注意子层、多头交叉注意子层和前馈子层组成。
本实施例步骤S2中的蒸馏OCR模型具体如下:
使用PP-OCR-V3的识别网络将pointwise卷积应用于基于ConvNet块的输出,获得与PP-OCR-V3识别骨干相同的输出通道数,并使用L2损失计算两个网络输出的损失,通过模型训练优化使得ConvNet学习字符识别能力;其中,训练数据使用开源的OCR相关数据集。
本实施例步骤S3中的预训练文档阅读任务具体如下:
多模态模型以先前的文本标记和输入图像为条件,学习预测下一个字符;将输入图像分成32×32的块,并掩蔽大约15%的块,让多模态模型预测被掩盖的块的文字。
本实施例步骤S4中的收集证照识别数据集具体如下:
通过互联网或业务渠道搜集证照识别相关数据集,并使用商业OCR软件配合人工对数据集进行标注。
本实施例步骤S5中的微调多模态模型具体如下:
S501、在预训练阶段后,多模态模型将对信息提取任务进行微调;
S502、在证照识别数据集上对多模态模型进行微调;
S503、文本解码器最后一层transformer block输出的所有输出序列的隐藏层状态的特征表示向量,再将其输入进额外的线性多分类器中进行分类,即可完成块序列分类。
本实施例步骤S6中的数据后处理具体如下:
将输出令牌序列转换为JSON格式,添加两个特殊标记[Start*]和[End*];其中,*表示要提取的每个字段;
若输出令牌序列的结构错误,简单地将该字段视为丢失。
实施例2:
本实施例提供了一种基于多模态模型的证照识别系统,该系统包括:
构建模块,用于构建基于图像和文本的多模态模型;
蒸馏模块,用于蒸馏OCR模型;
预训练模块,用于预训练文档阅读任务;
收集模块,用于收集证照识别数据集;
微调模块,用于微调多模态模型;
数据处理模块,用于数据后处理。
本实施例中的构建模块中的多模态模型由基于Transformer的视觉编码器和文本解码器模块组成;其中,视觉编码器由旨在提取字符内部的局部模式的卷积神经网络ConvNet和旨在捕获长期依赖关系的Swin Transformer模型构成;构建模块的工作过程具体为:将输入的图像通过视觉编码器进行编码,生成包含相关视觉信息的特征数据;再将图像特征数据与任务令牌一起馈送到文本解码器,自动回归地生成目标令牌;其中,文本解码器由n个Transformer层组成,每一层由多头自注意子层、多头交叉注意子层和前馈子层组成。
本实施例中的蒸馏模块的工作过程具体为:使用PP-OCR-V3的识别网络将pointwise卷积应用于基于ConvNet块的输出,获得与PP-OCR-V3识别骨干相同的输出通道数,并使用L2损失计算两个网络输出的损失,通过模型训练优化使得ConvNet学习字符识别能力;其中,训练数据使用开源的OCR相关数据集。
本实施例中的预训练模块的工作过程具体为:多模态模型以先前的文本标记和输入图像为条件,学习预测下一个字符;将输入图像分成32×32的块,并掩蔽大约15%的块,让多模态模型预测被掩盖的块的文字。
本实施例中的收集模块的工作过具体为:通过互联网或业务渠道搜集证照识别相关数据集,并使用商业OCR软件配合人工对数据集进行标注。
本实施例中的微调模块的工作过具体为:在预训练阶段后,多模态模型将对信息提取任务进行微调;在证照识别数据集上对多模态模型进行微调;文本解码器最后一层transformer block输出的所有输出序列的隐藏层状态的特征表示向量,再将其输入进额外的线性多分类器中进行分类,即可完成块序列分类。
本实施例中的数据处理模块的工作过程具体为:将输出令牌序列转换为JSON格式,添加两个特殊标记[Start*]和[End*];其中,*表示要提取的每个字段;若输出令牌序列的结构错误,简单地将该字段视为丢失。
实施例3:
本实施例还提供了一种电子设备,包括:存储器和处理器;
其中,存储器存储计算机执行指令;
处理器执行所述存储器存储的计算机执行指令,使得处理器执行本发明任一实施例中的基于多模态模型的证照识别方法。
处理器可以是中央处理单元(CPU),还可以是其他通用处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现成可编程门阵列(FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通过处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
存储器可用于储存计算机程序和/或模块,处理器通过运行或执行存储在存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现电子设备的各种功能。存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序等;存储数据区可存储根据终端的使用所创建的数据等。此外,存储器还可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,只能存储卡(SMC),安全数字(SD)卡,闪存卡、至少一个磁盘存储期间、闪存器件、或其他易失性固态存储器件。
实施例4:
本实施例还提供了一种计算机可读存储介质,其中存储有多条指令,指令由处理器加载,使处理器执行本发明任一实施例中的基于多模态模型的证照识别方法。具体地,可以提供配有存储介质的系统或者装置,在该存储介质上存储着实现上述实施例中任一实施例的功能的软件程序代码,且使该系统或者装置的计算机(或CPU或MPU)读出并执行存储在存储介质中的程序代码。
在这种情况下,从存储介质读取的程序代码本身可实现上述实施例中任何一项实施例的功能,因此程序代码和存储程序代码的存储介质构成了本发明的一部分。
用于提供程序代码的存储介质实施例包括软盘、硬盘、磁光盘、光盘(如CD-ROM、CD-R、CD-RW、DVD-ROM、DVD-RYM、DVD-RW、DVD+RW)、磁带、非易失性存储卡和ROM。可选择地,可以由通信网络从服务器计算机上下载程序代码。
此外,应该清楚的是,不仅可以通过执行计算机所读出的程序代码,而且可以通过基于程序代码的指令使计算机上操作的操作系统等来完成部分或者全部的实际操作,从而实现上述实施例中任意一项实施例的功能。
此外,可以理解的是,将由存储介质读出的程序代码写到插入计算机内的扩展板中所设置的存储器中或者写到与计算机相连接的扩展单元中设置的存储器中,随后基于程序代码的指令使安装在扩展板或者扩展单元上的CPU等来执行部分和全部实际操作,从而实现上述实施例中任一实施例的功能。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种基于多模态数据融合模型的抑郁识别方法和系统
- 一种基于双模态分类模型融合的扫视信号识别方法及系统