一种分布式系统热点数据的管理方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及区块链技术领域,特别是涉及一种分布式系统热点数据的管理方法。
背景技术
在分布式存储系统面对的需求场景中,在某一段时间内,若一类数据对象的被访问次数明显高于平均水平,则称这一类数据为热点数据。热点数据的分布不均匀是导致集群负载不均衡的重要原因。由于实际的生成环境中,互联网内数据请求随时间表现出连续不断且不均匀不规律的特性,因此热点数据挖掘的方法也必须具有实时性和准确性。当前的热点数据挖掘方法均存在着各自的缺陷:如无法实时获得热点数据,或无法保证热点数据的准确性等。
因此,需要在分布式存储系统的需求场景中设计一种新的分布式系统热点数据管理方法,以克服现有技术中的一些限制和缺陷。
发明内容
本发明的目的在于提供一种分布式系统热点数据的管理方法,通过结合流式处理数据在时间维度中的连续性,和已有热点数据挖掘方法中的一些优秀的设计理念,达到热点数据探测的实时性和高效性,以解决上述背景技术中提出的问题。
本发明的目的在于提供一种分布式系统热点数据的管理方法,包括:
步骤1,输入一段数据访问请求流,基于三阶段流式热点数据探测算法进行数据抽样、数据过滤以及数据统计,获得所述请求流中的热点数据集合;
步骤2,基于集群负载均衡法对任意时刻所述分布式系统的整个集群负载情况进行分析;
步骤3,根据所述步骤2的分析结果确定是否建立所述热点数据集合的副本,如果确定建立,则基于副本自适应方法建立符合数据访问请求流的时间特征的所述热点数据集合的副本。
优选的,所述步骤1中所述三阶段流式热点数据探测算法的所述数据抽样采用简单随机抽样。
优选的,所述步骤1中所述三阶段流式热点数据探测算法的所述数据过滤采用改良多重布隆过滤器,在传统的布隆过滤器基础上,将过滤器的数量从1个拓展至k个,并且将传统布隆过滤器中的0/1标志位替换为整数计数器,过滤器上任意位置被访问一次,则对应的计数器值加一,当请求被抽样后,对一个数据请求进行分析时,由k个哈希函数对数据对象的key进行计算,生成k个不同的值组成数组P=[p1,p2,…pk],对应k个不同的位置;在拓展至k个过滤器的计数器数组中,依次从数组P中取出值,作为对应计数器数组的对应位置,获取该位置计数器的值,得到计数器值数组V[v1,v2,…vk];对于数组V中的元素,若最小的元素值大于多重布隆计数器的阈值Threshold,则此数据对象通过过滤,通过过滤的数据作为频繁数据进入下一个阶段。
优选的,所述步骤1中所述三阶段流式热点数据探测算法的所述数据统计基于时间窗口进行热点数据探测,在经历了数据抽样和数据过滤后,仍然留存的数据为频繁数据,所述频繁数据有成为热点数据的可能,为了体现所述热点数据的强时间特征,数据统计阶段将频繁数据对应的请求序列按照时间窗口划分,通过设定时间窗口的长度s,将发生时间相近的数据请求归为同一个处理集合sr,对于某一个sr集合,其中的任意一个数据请求r将会计算一个衡量参数f,计算公式如下:
f=df+pf
其中df代表了当前数据内容在当前时间窗口的访问次数,pf代表了当前数据内容在上一个时间窗口的访问次数,当数据请求r中的数据内容的衡量参数f大于数据统计阶段的Threshold-3,则将其判断为热点数据;数据统计阶段维护了一个长度为k的计数器池C。当出现了新的热点数据后,如果数据对象不在计数器池中,而且当前计数器池中数据对象的数目小于计数器池的最大长度k,则将当前数据对象放入计数器池中;如果数据对象不在计数器池中而且当前计数器池中数据对象的数目已经达到计数器池的最大长度,则对于当前计数器池中的所有数据对象,对应的计数器值减1,如果出现某个数据对象对应的计数器值为0,则将该数据对象移出计数器池,为了将时间参数与数据的访问情况向匹配,计数器池C中的计数器数字在每进行一轮新的数据统计阶段时,将减少为之前的1/2,向下取整。
优选的,所述步骤2中所述集群负载均衡法包括:
对任意时刻集群负载的情况作出评估,当集群完全负载均衡时,所有数据服务器节点的负载均等于平均负载量,通过考察集群不均衡系数avg衡量集群负载是否均衡,在本系统的集群负载均衡法中,所述avg的值等于各个数据服务器的负载量与集群平均负载量之差的绝对值之和占总负载的比率,计算公式如下:
其中,load
优选的,所述步骤3中所述副本自适应方法包括:当一次热点数据的挖掘结束后,检查每一个当前挖掘出的热点数据对象,如果数据对象在之前的热点数据挖掘中没有被判定为热点数据,则该热点数据的副本创建数量为1;如果数据对象在之前的热点数据挖掘中已经被判定为热点数据,则将该数据对应的副本创建数量加倍。之后对已经存在副本的数据对象进行检查,如果存在数据对象在本次热点数据挖掘中并没有被判断为热点数据,当本次时间窗口该数据未被访问,则将该数据设置为未访问状态,否则不改变其副本创建数量;当已创建副本的数据对象在多个时间窗口中均为未访问状态时,每经过一个时间窗口,该数据对象的副本创建数量以之前增长的方式减少,直到其副本创建数量小于1时,该数据不再拥有副本。
本发明的有益效果:
公共机器学习运行模型的系统调用客观上阻止了参与评测的用户进行虚假投票。参与评测的根本要求是用户需要真实而公正的使用公共机器学习运行模型运行需要评测的模型,并且将评测结果发送回评测平台。公共机器学习运行模型在评测结束后,使用基于加密的相关技术,获取了发布模型的用户指定的公钥——由于这一过程发生在模型评测结束、正确率数据已经获取成功后,该过程本身的发生就已经要求参与评测的用户需要真正的运行模型。在公共机器学习运行模型中对正确率数据加密,使得输出结果屏蔽了参与评测的用户,用户无法在模型测试结果生成后恶意修改该结果。
根据下文结合附图对本发明具体实施例的详细描述,本领域技术人员将会更加明了本发明的上述以及其他目的、优点和特征。
附图说明
后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比例绘制的。本发明的目标及特征考虑到如下结合附图的描述将更加明显,附图中:
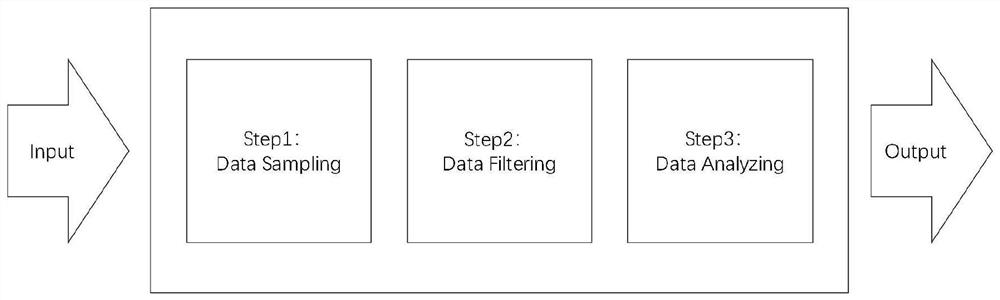
附图1为根据本发明实施例的三阶段流式热点数据探测方法流程图;
附图2为根据本发明实施例的从数据对象的key获取计数器值数组的过程流程图;
附图3为根据本发明实施例的数据副本自适应过程流程图。
具体实施方式
一、三阶段流式热点数据探测算法
三阶段流式热点数据探测方法的输入是一段数据访问请求流,输出是该请求流中热点数据的集合。三阶段流式热点数据探测方法将整个流程分为三个子流程:数据抽样阶段、数据过滤阶段和数据统计分析阶段。流程如图1所示。
分布式内存存储系统面对的数据访问请求有着海量并且高并发的特点。在保证三阶段流式热点数据探测算法能够实时输出热点数据集合的情况下,为了避免系统资源消耗过多,本算法对整个数据访问请求使用了随机抽样的方式。由于随机抽样不改变整个数据访问请求流的统计特征的情况,本算法在不影响输出结果正确性的基础上,保证了热点数据探测的效率。
(一)数据抽样——简单随机抽样
由于分布式存储系统中,数据请求序列可以视为完全随机。本算法在数据抽样中使用了简单随机抽样的方式。简单随机抽样的抽样比为a,即对于任意的数据请求序列中,每一个数据请求有a的概率被抽样。参数a的值可以在应用场景中进行调整,防止抽样数据量过大或过小,影响本算法的实际表现。
数据抽样阶段未改变数据请求序列的统计学特征,并且减少了进一步数据分析过程的压力。
(二)数据过滤——改良多重布隆过滤器
基于先验知识,热点数据拥有如下的两种特性:
(1)28定律:即80%的数据请求对应了20%的数据内容
(2)强时间特征:热点数据的访问次数会随着时间逐步减少
基于这些特性,在数据过滤阶段,本专利使用了改良多重布隆过滤器的方法。本方法在传统的布隆过滤器基础上,将过滤器的数量从1个拓展至k个,并且将传统布隆过滤器中的0/1标志位替换为整数计数器。过滤器上任意位置被访问一次,则对应的计数器值加一。
当请求被抽样后,当对一个数据请求进行分析时,由k个哈希函数对数据对象的key进行计算,生成k个不同的值组成数组P=[p1,p2,…pk],对应k个不同的位置。在拓展至k个过滤器的计数器数组中,依次从数组P中取出值,作为对应计数器数组的对应位置,获取该位置计数器的值,得到计数器值数组V[v1,v2,…vk]。对于数组V中的元素,若最小的元素值大于多重布隆计数器的阈值Threshold,则此数据对象通过过滤。通过过滤的数据被称为频繁数据,进入下一个阶段。图2为从数据对象的key获取计数器值数组的过程。
(三)数据统计——基于时间窗口的热点数据探测
在经历了数据抽样和数据过滤后,仍然留存的数据称之为频繁数据。频繁数据有成为热点数据的可能。为了体现热点数据的强时间特征,数据统计阶段将频繁数据对应的请求序列按照时间窗口划分。通过设定时间窗口的长度s,将发生时间相近的数据请求归为同一个处理集合sr。
对于某一个sr集合,其中的任意一个数据请求r将会计算一个衡量参数f,计算公式如下:
f=df+pf
其中df代表了当前数据内容在当前时间窗口的访问次数,pf代表了当前数据内容在上一个时间窗口的访问次数。当数据请求r中的数据内容的衡量参数f大于数据统计阶段的Threshold-3,则将其判断为热点数据。
借鉴TopK算法的原理,数据统计阶段维护了一个长度为k的计数器池C。当出现了新的热点数据后,如果数据对象不在计数器池中,而且当前计数器池中数据对象的数目小于计数器池的最大长度k,则将当前数据对象放入计数器池中;如果数据对象不在计数器池中而且当前计数器池中数据对象的数目已经达到计数器池的最大长度,则对于当前计数器池中的所有数据对象,对应的计数器值减1,如果出现某个数据对象对应的计数器值为0,则将该数据对象移出计数器池。
为了将时间参数与数据的访问情况向匹配,计数器池C中的计数器数字在每进行一轮新的数据统计阶段时,将减少为之前的1/2(向下取整)。
二、副本自适应管理方法
当分布式内存存储系统完成了热点数据的挖掘后,本专利提出了一种自适应的副本管理方法。副本自适应管理方法通过对整个集群负载情况的分析,对副本进行特定机制下的创建和回收,从而使得集群负载不均衡的问题得到解决。本实施例相比于现有的副本管理方法有着以下的特点:
(1)副本创建仅针对于热点数据,减少系统资源的浪费。
(2)动态回收副本,对已经不具备热点数据属性的数据对象进行副本回收,进一步了提高热点数据挖掘的准确性。
(3)对热点数据进行进一步分类,热点程度高的热点数据将会在更多的数据服务器节点上创建副本,副本创建更加灵活与可拓展。
(4)整个副本管理过程中,将热点数据挖掘,副本创建数目等参数自适应化,针对不同的数据请求流动态的调整各个流程的系数,使得副本管理更加合理。
当一次热点数据的挖掘结束后,副本自适应管理方法会检查每一个当前挖掘出的热点数据对象。如果数据对象在之前的热点数据挖掘中没有被判定为热点数据,则该热点数据的副本创建数量为1;如果数据对象在之前的热点数据挖掘中已经被判定为热点数据,则将该数据对应的副本创建数量加倍。之后对已经存在副本的数据对象进行检查,如果存在数据对象在本次热点数据挖掘中并没有被判断为热点数据,当本次时间窗口该数据未被访问,则将该数据设置为未访问状态,否则不改变其副本创建数量。当已创建副本的数据对象在多个时间窗口中均为未访问状态时,每经过一个时间窗口,该数据对象的副本创建数量以之前增长的方式减少,直到其副本创建数量小于1时,该数据不在拥有副本。图3为某数据的副本自适应过程实例:
当该数据成为热点数据后,该数据尚未被创建任何副本,则在任意一个节点创建一个副本;当后续的时间窗口(从1~4)中该数据一直被判定为热点数据,则增加副本数量直至16(设该集群的最大机器数为16)。在时间窗口10中,由于从时间窗口9开始,系统未访问该数据,则回收副本直至副本剩余数为2。之后重新开始以数据访问情况建立副本
由此,副本自适应方法中的副本创建和回收方法借鉴了TCP协议中快重传算法,保证了副本管理方法符合数据访问请求流的时间特征,并且规避了非热点数据的副本创建,节约了宝贵的系统资源。
三、集群负载均衡方法
在使用副本自适应方法进行副本创建的过程中,是否创建副本,向哪一个数据服务器节点或者哪几个数据服务器节点写入副本实例等问题是由系统的分布式内存存储系统的负载均衡算法决定的。在集群负载完全均衡的场景下,比如热点数据完全平均的存在于每一个数据服务器节点上,若每一个作为数据服务器节点的真实机器性能相同,则进行热点数据挖掘和副本创建并不能提高整个集群的性能。而热点数据副本被创建到哪一个数据服务器节点,将会导致整个热点数据访问请求改变之前的分布情况,从而对整个集群的性能产生至关重要的影响。
首先,集群负载均衡方法中要对任意时刻集群负载的情况作出评估。当集群完全负载均衡时,所有数据服务器节点的负载均等于平均负载量。本系统中,衡量集群负载均衡的方案为考察集群不均衡系数avg,在本系统的集群负载均衡方法中,avg的值等于各个数据服务器的负载量与集群平均负载量之差的绝对值之和占总负载的比率。计算公式如下:
其中,load
负载不均衡系数avg的计算方式借鉴了统计学中方差的概念,能清晰的刻画出整个集群的负载情况,从而对副本的创建提供了重要的辅助工作。在负载不均衡系数avg大于系统设定的阈值时,从热点数据挖掘方法中得到的热点数据开始进行副本创建和副本分配;否则不进行任何与数据副本相关的操作,从而节约了整个系统的资源消耗。
虽然本发明已经参考特定的说明性实施例进行了描述,但是不会受到这些实施例的限定而仅仅受到附加权利要求的限定。本领域技术人员应当理解可以在不偏离本发明的保护范围和精神的情况下对本发明的实施例能够进行改动和修改。
- 一种分布式系统热点数据的管理方法
- 一种分布式系统的数据管理方法及装置