将藻类血红素掺入到可食用产品中的组合物和方法
文献发布时间:2023-06-19 12:16:29
相关申请的交叉引用
根据《美国法典》第35章§119(e)条,本申请要求2019年6月24日提交的美国临时申请No.62/865,800、2019年5月20日提交的美国临时申请No.62/850,227及2018年11月8日提交的美国临时申请No.62/757,534的优先权,通过引用,这些临时申请全文纳入本申请中。
序列表
本申请包含以ASCII格式电子提交的序列表,通过引用,所述序列表纳入本申请中。所述ASCII副本创建于2019年11月6日,命名为20498-202379_SL.txt,大小为208KB。
背景技术
随着工业化畜牧业的出现,动物肉类的消费量持续上升。畜牧业需要大量土地使用和淡水,这些有限的资源越来越难以获得。
为了解决动物肉类消费的可持续性和道德问题,食品行业一直在积极尝试开发味道、口感和气味都像肉制品的植物替代品。然而,目前许多植物替代品还未能打入更大的食品和消费市场。为了提高食品生态系统的可持续性,必须开发出能够吸引目前偏爱肉类的消费者的产品。
最近取得的进展表明了这一潜力:利用从宿主生物中纯化的含血红素的蛋白质,使产品的味道和香气更接近肉类。人们认为,从含血红素的蛋白质中提取的血红素是赋予肉制品“肉”味和“肉”香的原因。然而,含血红素的蛋白质的可用来源昂贵且技术密集,限制了它们的用途。除了经济性不佳外,这种产品还是转基因的,因此对许多选择食用非基因工程食品的消费者而言吸引力较小。此外,出现了一种营养益处增加和热量摄入平衡的产品趋势。目前,许多肉类替代品不能完全满足这些需求,同时保持消费者期望的口味、质地和视觉吸引力。因此,需要掺入本文所述含血红素的蛋白质的可食用产品。
发明内容
为了解决与目前将血红素掺入到产品中的方法有关的经济和消费者问题,本文提供了组合物及所述组合物的生产方法,所述组合物能提供肉类的口味和营养的替代品。特别是,本文提供了包含来自藻类的血红素以及其他营养成分的组合物及所述组合物的生产方法。藻类不需要昂贵的纯化过程即可被掺入到成品中。
本发明包括血红素过表达或积累的工程藻类组合物以及将所述工程藻类用于食品的方法。因此,本发明的一个方面包括具有遗传修饰的工程藻类,其中与缺乏遗传修饰的藻类相比,所述遗传修饰引起藻类中血红素积累。在一些实施例中,所述工程藻类降低或缺少叶绿素产生。在一些实施例中,藻类具有红色或类似红色颜色。在一些实施例中,藻类能够在作为唯一碳源的葡萄糖上生长。
优选所述遗传修饰包括对叶绿素合成途径、原卟啉原IX合成途径或血红素合成途径的遗传改变。在一些实施例中,遗传修饰与镁螯合酶表达缺乏(a deficiency intheexpression)有关。替代地和/或另外地,所述遗传修饰包括CHLD、CHLI1、CHLI2或CHLH1中一个或多个的改变。替代地和/或另外地,所述遗传修饰包括上游调控区、下游调控区、外显子、内含子或其任何组合中的改变。在一些实施例中,所述遗传修饰包括插入、缺失、点突变、倒位、重复、移码或其任何组合。
在一些实施例中,工程藻类的血红素含量大于叶绿素含量。替代地和/或另外地,工程藻类的原卟啉原IX含量大于叶绿素含量。替代地和/或另外地,工程藻类减少了一种或多种脂肪酸的产生。
在一些实施例中,工程藻类进一步包括减少或消除非光依赖性原叶绿素酸酯(
本发明的另一方面包括包含藻类制品的可食用组合物,其中藻类制品包含如上所述的工程藻类或部分工程藻类。在一些实施例中,可食用组合物包括源自工程藻类的血红素。在一些实施例中,藻类制品包括藻类细胞。在一些实施例中,藻类制品是分离的藻类制品。在一些实施例中,藻类制品是红色或类似红色颜色。
在一些实施例中,可食用组合物具有源自藻类制品的红色或类似红色颜色。替代地和/或另外地,藻类制品赋予可食用组合物肉味或类肉味道。替代地和/或另外地,可食用组合物具有源自藻类制品的肉质或类似肉的质地。在所述实施例中,预期肉质或类似肉的质地包括牛肉或类牛肉质地、鱼肉或类鱼肉质地、鸡肉或类鸡肉质地、猪肉或类猪肉质地或肉类仿制品的质地。
在一些实施例中,可食用组合物是选自类牛肉食品、类鱼肉产品、类鸡肉产品、类猪肉产品和肉类仿制品的成品。替代地和/或另外地,可食用组合物是严格素食、素食或无麸质食物。替代地和/或另外地,可食用组合物具有源自藻类制品的血液外观。
替代地和/或另外地,所述藻类制品的血红素含量大于叶绿素含量。替代地和/或另外地,所述藻类制品的原卟啉原IX含量大于叶绿素含量。在一些实施例中,藻类制品为可食用组合物提供的蛋白质至少占总蛋白质含量的大约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%。替代地和/或另外地,藻类制品向组合物提供维生素A、β-胡萝卜素或其组合。任选维生素A、β-胡萝卜素或其组合的含量至少约为每日推荐需求量的5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%。替代地和/或另外地,藻类制品提供的饱和脂肪含量少于食用组合物中总饱和脂肪含量的大约0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.2%、1.5%、2%、5%或10%。替代地和/或另外地,藻类制品提供的饱和脂肪含量少于含所述食用组合物的成品中总饱和脂肪含量的大约0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.2%、1.5%、2%、5%或10%。替代地和/或另外地,藻类制品向可食用组合物提供至少约5mg、10mg、15mg、20mg、25mg、30mg、35mg、40mg、45mg、50mg、55mg、60mg、65mg、70mg、75mg、80mg、85mg、90mg、95mg、100mg、125mg、150mg、175mg、200mg、250mg、300mg、350mg、400mg、450mg或500mg的ω-3脂肪酸。替代地和/或另外地,藻类制品降低了脂肪酸含量。
在一些实施例中,可食用产品与蛋白质源、脂肪源、碳水化合物、淀粉、增稠剂、维生素、矿物质或其任何组合组合。在这些实施例中,优选蛋白质源选自小麦组织蛋白、大豆组织蛋白和豌豆组织蛋白、真菌蛋白或藻类蛋白。替代地和/或另外地,脂肪源包括精制椰子油或葵花籽油中的至少一种。在一些实施例中,可食用成分进一步包括马铃薯淀粉、甲基纤维素、水和调味料中的至少一种,其中所述调味料选自酵母提取物、大蒜粉、洋葱粉和盐中的至少一种。
在一些实施例中,可食用产品是汉堡、香肠、烤肉串、鱼片、鱼类替代品、绞肉类产品或肉丸成分。在一些实施例中,汉堡包括大约5%的藻类制品、大约20%的大豆组织蛋白和大约20%的精制椰子油。任选汉堡进一步包括大约3%的葵花籽油、大约2%的马铃薯淀粉、大约1%的甲基纤维素、大约45%的水和大约4-9%的调味料。替代地和/或另外地,汉堡进一步包括大约0.5%的魔芋胶、大约0.5%的黄原胶、大约45%的水和大约4-9%的调味料。在一些实施例中,鱼类替代品包括20%的大豆组织蛋白、大约5%的藻类制品、大约65%的水和大约10%的调味料。在一些实施例中,可食用组合物不含动物蛋白质。
在一些实施例中,藻类制品包括原卟啉原IX合成或积累增加的藻类。替代地和/或另外地,藻类制品包括在黑暗条件下生长时呈现红色或类似红色颜色的藻类。在一些实施例中,藻类制品中包括的藻类是重组或遗传修饰藻类。在一些实施例中,藻类制品包括衣藻。任选所述衣藻为莱茵衣藻。
本发明的另一方面包括生产可食用组合物的方法。所述方法包括以下步骤:(a)在工程藻类呈现红色或类似红色颜色且工程藻类产生血红素的条件下培养如上所述的工程藻类,(b)收集培养的工程藻类以生产藻类制品,以及(c)将藻类制品与至少一种可食用成分组合,以生产可食用组合物。在一些实施例中,所述条件包括发酵条件。替代地和/或另外地,所述条件包括乙酸盐作为工程藻类生长的还原碳源。替代地和/或另外地,所述条件包括糖作为工程藻类生长的还原碳源。替代地和/或另外地,所述条件包括黑暗或有限的光照条件。替代地和/或另外地,所述条件进一步包括铁补充。
在一些实施例中,所述方法进一步包括分离培养的藻类以生产藻类制品。在一些实施例中,所述藻类制品的血红素含量大于叶绿素含量。替代地和/或另外地,所述藻类制品的原卟啉原IX含量大于叶绿素含量。在一些实施例中,所述工程藻类是衣藻。任选所述工程藻类是莱茵衣藻。
在一些实施例中,所述可食用组合物具有以下至少一个特征:肉或类肉味道、肉或类肉质地、类似血液的外观及肉或类肉颜色,其中所述至少一个特征源自藻类制品。在一些实施例中,所述方法进一步包括生产包含可食用组合物的成品,其中所述成品是类牛肉食品、类鱼肉产品、类鸡肉产品、类猪肉产品或肉类仿制品。在一些实施例中,可食用组合物不含动物蛋白质。在一些实施例中,对藻类制品进行分离,以脱除淀粉、蛋白质、PPIX、脂肪酸和叶绿素组分中的一种或多种组分。
本发明的另一方面包括制备富含血红素的工程藻类的方法。所述方法包括以下步骤:(a)使藻类菌株经受产生遗传修饰的过程,以产生第一藻类种群,和(b)从第一藻类种群中选择富含血红素和可选地富含PPIX的第二藻类种群。在一些实施例中,所述过程包括随机UV诱变、随机化学诱变、重组基因工程、基因编辑或基因沉默中的至少一种过程。在一些实施例中,所述方法进一步包括在发酵条件下培养第一藻类种群的步骤。在一些实施例中,发酵条件包括以糖作为唯一碳源的培养基。在这些实施例中,优选糖选自葡萄糖、右旋糖、果糖、麦芽糖、半乳糖、蔗糖和核糖。替代地和/或另外地,发酵条件包括小于500勒克斯的亮度。
在一些实施例中,所述选择第二藻类种群的步骤包括分选或鉴定具有红色或类似红色的藻类细胞。替代地和/或另外地,所述选择第二藻类种群的步骤由FACS执行。在一些实施例中,根据其在发酵条件下生长的能力选择第二藻类种群。
附图说明
图1是藻类中示例性血红素产生途径示意图。这种示例性途径可以被野生型藻类用于产生叶绿素,但也可以用于产生血红素。
图2A和2B示出了示例性藻类生长培养基的组成(图2A)和选择过程(图2B)。
图3是在完全黑暗的条件下,以葡萄糖作为唯一碳源的藻类生长示意图。
图4是示意图,示出了血红素过表达藻类的示例性分离,示出了从淀粉和类胡萝卜素组分中分离出蛋白质和富含血红素的生物质。
图5是从红藻中提取PPIX和/或血红素的过程示意图。
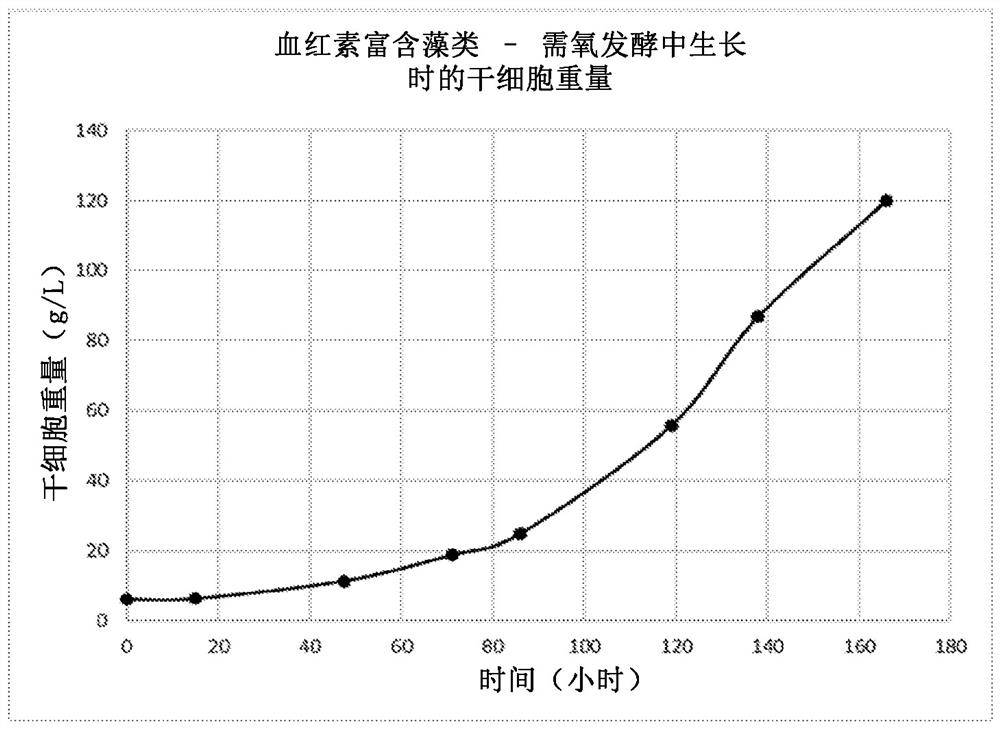
图6是血红素高产菌株在有氧发酵条件下生长时的示例性生长曲线(干细胞重量)示意图。
图7是含葡萄糖培养基中衣藻干细胞重量增加示意图。
图8是己烷提取前后红藻制品各分离组分示意图。
图9显示了野生型绿藻和红藻的部分序列比对,其中绿藻的CHLH基因突变(上序列(Seq_1)是部分核酸序列(SEQ ID NO:27的残基1621-1679)和部分氨基酸序列(SEQ ID NO:28的残基451-460),下序列(Seq_2)是红藻CHLH基因的部分核酸序列(SEQ ID NO:129的残基1621-1680)和部分氨基酸序列(SEQ ID NO:152的残基451-460)发生突变(星号)。如图所示,野生型CHLH核酸序列(SEQ ID NO:27)在1678位置处插入硫胺,导致脯氨酸的SEQ IDNO:28的野生型CHLH氨基酸序列改变为氨基酸位置560处的丝氨酸。
图10是用0.01克、0.1克、1.0克和5.0克富含血红素的藻类制作的汉堡示意图。
图11是示意图,示出了未加血红素富含藻类的植物汉堡成分混合物、添加血红素富含藻类的植物汉堡成分混合物,或添加血红素富含藻类的植物汉堡各成分混合物烹饪前后的情况。
图12是富含血红素的无肉“金枪鱼”实例示意图。
具体实施方式
在描述本发明的组合物和方法之前,应当理解的是,本发明不限于所描述的特定组合物、方法和实验条件,因为这些组合物、方法和条件可以改变。还应该理解的是,本文所用的术语仅用于描述特定的实施例,而不是用于限制本发明的范围,本发明的范围仅受所附权利要求书的限制。
除非上下文明确指明,否则,正如本专利说明书和权利要求书中所使用的那样,单数形式“一”和“所述”包括复数意义。因此,例如,“所述方法”包括本文所述类型的一个或多个方法和/或步骤,这些方法和/或步骤对于本领域技术人员在阅读本发明等时将变得显而易见。此外,对于详细说明或权利要求中使用的词语“包括”、“包含”、“具有”、“有”、“带”或它们的变体来说,这些词语旨在以类似“包括”的词语来说明包括。
词语“大约”或“约”是指在由本领域普通技术人员确定的特定值的可接受误差范围内,其将部分取决于所述值如何测量或测定,例如,测量系统的限制。例如,按照惯例,“大约”可以是指在给定值的1个或1个以上的标准偏差内。如果在申请和权利要求书中描述了特定值,除非另有说明,否则词语“大约”应假定指特定值的可接受误差范围。
本文所述一个或多个基因和/或酶的“缺乏(a deficiency in)”或“缺少”或“减少”包括例如基因序列的突变或缺失、基因(RNA和/或蛋白质)表达的减少或缺乏和/或基因产物(RNA和/或蛋白质)积累或稳定性的缺乏。
本文所述酶或基因的“过表达”包括例如基因(RNA和/或蛋白质)的表达增加和/或基因产物(RNA和/或蛋白质)的积累或稳定性增加。所述过表达可包括调控区和/或基因序列的改变,以及拷贝数、基因组位置和翻译后修饰的改变。
本文所述术语“工程藻类”是指包含一种或多种遗传修饰的藻类。在某些情况下,工程藻类通过重组技术将异源核酸整合到其基因组中时,其也是重组修饰的生物。在其他情况下,工程藻类不是重组修饰的生物(例如,当其通过紫外、化学或辐射诱变修饰时)。在某些情况下,不是重组修饰生物的藻类被称为非转基因生物,来自这种藻类的成分可以被称为非转基因生物成分。
本文所述术语“遗传修饰”用于指以在自然条件下不会发生的方式对生物的遗传物质进行的任何操作。遗传修饰可包括通过诱变(例如紫外线、X射线、γ射线照射和化学暴露)进行的修饰。遗传修饰可以包括基因编辑。在某些情况下,可以通过重组技术进行遗传修饰。本文所述“重组修饰生物”用于指通过重组技术将异源核酸(例如,重组核酸)整合到其基因组内的生物。执行此类操作的方法是本领域普通技术人员所熟知的,但不限于利用载体来转化具有所需核酸序列的细胞的技术。所述定义包括各种形式的基因编辑,其中使用工程核酸酶或“分子剪刀”在生物体的基因组中插入,删除或替换DNA。这些核酸酶在基因组中的期望位置产生位点特异性双链断裂(DSB)。诱导的双链断裂通过非同源末端连接(NHEJ)或同源重组(HR)修复,导致靶向突变(即编辑)。
除非特别规定,本发明使用的所有词语(包括技术名词和科学术语)的意义与本发明所属领域技术人员通常理解的相同。虽然本发明实践或试验中也可以使用与本文所述类似或相当的任何方法和材料,但是,现在描述的是优选的方法和材料。
本发明提供从藻类提供血红素和其他营养成分的组合物和方法。众所周知,藻类能产生许多化合物,使这些水生生物呈现各种颜色。这些化合物包括但不限于使藻类变绿的叶绿素、使藻类变黄或变橙的β-胡萝卜素、使藻类变红的虾青素或其他各种色素,例如使藻类变蓝的藻蓝蛋白。虽然上述每一种化合物都已被添加到食品中,但迄今为止,还没有任何产品含有血红素高产藻类,从而呈现红色和/或肉类口感和气味。
本发明提供了利用血红素高产藻类的菌株、方法和组合物。在一些实施例中,藻类菌株生长时呈红色或类似红色。正如本文所述,在一些实施例中,类似红色的颜色可以是波长在590nm到750nm之间的任何颜色或所述颜色的任何混合颜色。替代地和/或另外地,在一些实施例中,类似红色的颜色可定义为RGB(r.g.b)中r值在255和80之间且g或b值在0和80之间的任何颜色。在一些实施例中,从血红素高产藻类培养物制备的制品在掺入到食品和其他可食用产品中时使其呈粉红色或红色。在一些实施例中,从血红素高产藻类培养物制备的制品在掺入到食品和其他可食用产品中时使其具有“肉”味、肉香和/或肉质。在一些实施例中,从血红素高产藻类培养物制备的制品赋予所需的颜色、味道和/或气味,以及一种或多种其它营养成分,例如ω-3脂肪酸、饱和脂肪、蛋白质、维生素A、β-胡萝卜素或其任何组合。
藻类制备和高产血红素
本文提供了高产血红素的藻类菌株和产生或积累血红素和/或原卟啉IX(PPIX)含量大于叶绿素含量的菌株,它们可用于生产可食用组合物和成分。本文还提供了制备所述菌株以及由其生产的成分和组合物的方法。以及采用本文所述方法以制备所述组合物的用途。所述菌株是通过修饰产生血红素、PPIX和叶绿素的生化途径中的一个或多个步骤产生的。
不受理论限制,血红素途径是从叶绿素生化途径分支而来的生化途径,如图1所示。简而言之,该途径从谷氨酸tRNA开始,谷氨酸tRNA通过GlutRNA还原酶和GSA氨基转移酶转化为5-氨基乙酰丙酸(ALA)。然后,ALA被ALA脱氢酶转化为胆色素原。然后,胆色素原通过胆色素原脱氨酶转化为羟甲基胆色烷。然后,羟甲基胆色烷通过UPGⅢ合酶转化为尿卟啉原Ⅲ。然后,尿卟啉原III通过UPG III脱羧酶转化为粪卟啉原。然后,粪卟啉原被CPG氧化酶转化为原卟啉原IX。然后,原卟啉原IX被PPG氧化酶转化为原卟啉IX。原卟啉IX可穿梭于叶绿素产生途径或血红素B。最后,原卟啉IX通过铁螯合酶将铁附着在原卟啉IX上而转化为血红素B。
通过减少对叶绿素的代谢通量,有可能增加对血红素B的代谢通量。在本文的一些实施例中,在方法中使用的藻类菌株和由此产生的组合物对叶绿素的代谢通量减少并且对血红素B(本文亦称为“血红素”)的代谢通量增加。在一些实施例中,藻类菌株是其中叶绿素和类胡萝卜素合成减少且血红素合成或积累增加的菌株。在一些实施例中,藻类菌株的叶绿素含量缺乏或减少。在一些实施例中,藻类菌株是红色或类似红色的颜色。
在一些实施例中,藻类菌株缺乏叶绿素生物合成途径中的一种或多种酶。这些缺乏包括但不限于导致酶表达缺乏或酶功能缺乏的基因缺失、突变和其他改变。在一些实施例中,藻类菌株缺乏镁螯合酶,镁螯合酶是将原卟啉IX转化为叶绿素的第一步。在一些实施例中,藻类菌株缺乏将原叶绿素酸酯转化为叶绿素的光依赖性原叶绿素酸酯。在一些实施例中,藻类菌株缺乏在黑暗中将原叶绿素酸酯转化为叶绿素的非光依赖性原叶绿素酸酯。在一些实施例中,藻类菌株缺乏ChlB、ChlL或ChlN基因产物中的一种或多种基因产物,这些基因产物在叶绿体基因组中编码,并且是将原叶绿素酸酯转化为叶绿素的非光依赖性原叶绿素酸酯氧化还原酶(LIPOR)的亚基。这种酶在表达时,可以让衣藻(Chlamydomonas)等藻类产生叶绿素并保持绿色,即使不给藻类提供照明也是如此。当这些基因中的一个或多个基因被敲除时,藻类菌株在黑暗的生长条件下呈黄色。
在一些实施例中,藻类菌株缺乏或减少镁螯合酶、镁原卟啉原IX、原叶绿素酸酯、叶绿素酸酯和叶绿素中的一种或多种。
在一些实施例中,藻类菌株缺乏镁螯合酶亚基CHLD、CHLH和CHLI中的一种或多种亚基。这些亚基也用基因名称来指代,CHLD1(也称为CHlD1),与CHLD亚基相对应,CHLH1(也称为CHlH1),与CHLH亚基相对应,以及CHLI1和CHLI2,与由两个基因CHLI1和CHLI2编码的CHLI亚基相对应(也称为CHlI1和CHlI2)。
在一些实施例中,富含血红素的藻类菌株缺乏镁螯合酶的一个或多个核编码亚基,例如缺乏由亚基CHLD、CHLH和CHLI的基因编码的一个或多个亚基。这些亚基中一个或多个亚基的缺乏会减少或消除叶绿素的表达。在一些实施例中,编码亚基的基因可以被修饰,例如通过将密码子改变为终止密码子的一个或多个点突变,从而产生截短的编码区。在一些实施例中,编码亚基的基因可通过删除编码亚基的一些或全部基因的缺失来修饰。在一些实施例中,编码亚基的基因可以通过移码突变进行修饰,例如由一个或多个碱基的缺失或插入到编码区中引起的移码突变,从而导致无功能和/或截短的蛋白质。在一些实施例中,编码亚基的基因可通过插入产生非功能性蛋白质的编码区来修饰,例如通过在蛋白质内部或N末端或C末端添加一种或多种氨基酸进行修饰,产生非功能性亚基或降低亚基或酶的活性或稳定性。
在一些实施例中,富含血红素的藻类在编码CHLD、CHLI1、CHLI2或CHLH1的核苷酸序列(包括内含子、外显子、调控区或全基因序列)中具有至少一种修饰(例如,SEQ ID NO:23、25、27、153中的修饰)。在一些实施例中,富含血红素的藻类在编码CHLD、CHLI1、CHLI2或CHLH1的氨基酸序列中具有至少一种修饰(例如,SEQ ID NO:24、26、28、151中的修饰)。在一些实施例中,富含血红素的藻类菌株在编码CHLD、CHLI1、CHLI2或CHLH1的一部分的外显子中包含至少一种修饰(点突变、缺失或插入)。在一些实施例中,富含血红素的藻类菌株包含对所述外显子的野生型序列的至少一种修饰,例如在SEQ ID NO:47-58、72-80、91-102和132-141序列中任一序列中的修饰。
在一些实施例中,富含血红素的藻类菌株在CHLD、CHLI1、CHLI2或CHLH1的未翻译区(例如在5'未翻译区或3'未翻译区)中包含至少一种修饰(点突变、缺失或插入)。在一些实施例中,富含血红素的藻类菌株包含对所述未翻译区的野生型序列的至少一种修饰,例如在SEQ ID NO:45、46、70、71、89、90、130或131序列中任一序列中的修饰。
在一些实施例中,改变Mg-螯合酶一个或多个亚基的表达调控,以产生叶绿素含量减少的菌株。CHLD、CHLI1、CHLI2和CHLH1亚基中一个或多个亚基的调控区可以被修饰,以减少表达,例如通过插入、缺失或一个或多个点突变进行修饰。这种改变可以以减少或消除亚基基因转录的方式修饰例如转录因子结合位点、增强子位点、RNA聚合酶相互作用和转录起始位点。
在一些实施例中,一个或多个亚基的表达通过修饰内含子与亚基基因的剪接而改变,例如消除或改变剪接供体或受体位点或以其他方式改变基因剪接效率或准确性的突变、插入或缺失。在一些实施例中,富含血红素的藻类菌株在CHLD、CHLI1、CHLI2或CHLH1的内含子中包含至少一种修饰(点突变、缺失或插入)。在一些实施例中,富含血红素的藻类菌株包含对所述内含子的野生型序列的至少一种修饰,例如在SEQ ID NO:59-69、81-88、103-113、142-150序列中任一序列中的修饰。
在一些实施例中,藻类菌株过表达一种或多种酶,从而使路径平衡有利于血红素的产生。在一些实施例中,藻类菌株过表达谷氨酰-tRNA还原酶、谷氨酰-1-半醛氨基转移酶、丙氨酸脱氢酶、胆色素原脱氨酶、UPG III合酶、UPG III脱羧酶、CPG氧化酶、PPG氧化酶和铁螯合酶中的一种或多种。在一些实施例中,藻类菌株产生ALA(血红素B合成的限速前体)的能力得到改进。在一些实施例中,藻类菌株产生功能性铁螯合酶基因(负责将原卟啉IX转化为血红素B的酶)的能力得到改进。在一些实施例中,藻类菌株产生UPG III合酶、UPGIII脱羧酶、CPG氧化酶或PPG氧化酶的能力得到改进。在一些实施例中,与野生型菌株相比,所述藻类菌株血红素、含血红素的蛋白质、原卟啉原IX、胆绿素IX、光敏色素和铁螯合酶中一种或多种的含量增加。
在一些实施例中,藻类菌株产生类胡萝卜素或类胡萝卜素的前体。类胡萝卜素赋予颜色,并对植物替代品的视觉外观产生影响,但并不受理论的限制。示例性类胡萝卜素包括但不限于γ-胡萝卜素、β-胡萝卜素、β-隐黄质、玉米黄质、花药黄质、叶黄素、前番茄红素和番茄红素。
在一些实施例中,藻类菌株缺乏类胡萝卜素或类胡萝卜素前体。类胡萝卜素生物合成的缺乏可因突变而发生,例如影响类胡萝卜素生物合成的突变,例如,八氢番茄红素合酶基因中的突变。
在本文的一些实施例中,所述组合物和方法中使用的藻类是非转基因的,不包含异源核酸和/或不使用重组技术产生。在一些实施例中,所述组合物和方法中使用的藻类根据其颜色、血红素含量、血红素合成速率、血红素积累或原卟啉IX含量、合成速率或积累来选择。在一些实施例中,所述藻类的叶绿素含量降低和/或其叶绿素含量低于血红素和/或原卟啉IX的含量。在一些实施例中,本文所述组合物和方法中使用的藻类不包含多个涉及血红素生物合成或积累的基因的异源基因,例如,藻类不包含涉及血红素生物合成、血红素积累、原卟啉IX生物合成,或原卟啉IX积累的细菌、真菌、植物或动物源性基因或核酸。
在一些实施例中,藻类在有助于增加血红素合成或积累、减少叶绿素合成或积累或它们两者组合的一个或多个基因的表达方面被修饰。所述修饰可以通过诱变产生,例如暴露于紫外线、辐射或化学物质。
在一些实施例中,所述修饰可以通过基因编辑产生,例如通过精确工程化的核酸酶靶向来改变一个或多个组分的表达,例如通过CRISPR-CAS核酸酶。所述核酸酶可用于产生一个或多个核苷酸或核苷酸区域的插入、缺失、突变和替换,以修饰所述途径中一个或多个途径酶的表达,从而降低叶绿素和/或增加血红素的产生。产生修饰之后,藻类菌株可以生长和/或
有几个可用于本文所述基因编辑的工程化核酸酶家族,例如但不限于大范围核酸酶、锌指核酸酶(ZFN)、转录激活因子样效应物核酸酶(TALEN)、CRISPR-Cas系统和ARCUS。但是,应当理解的是,任何利用工程化核酸酶的已知基因编辑系统都可用于本文所述的方法。因此,在一些实施例中,可通过使用诸如CRISPR-Cas系统(例如CRISPR-CAS9)等技术或通过使用锌指核酸酶来产生血红素高产藻类菌株。
CRISPR(成簇的规律间隔的短回文重复序列)是包含多个简短而直接的重复碱基序列的DNA位点的首字母缩写。原核CRISPR/Cas系统已被改编用于真核生物的基因编辑(沉默、增强或改变特定基因)(参见,例如Cong,Science,15:339(6121):819-823(2013)andJinek,et al.,Science,337(6096):816-21(2012))。通过用包括Cas基因和特别设计的CRISPR的元件转染细胞,可以在任何所需位置切割和修饰核酸序列。利用CRISPR/Cas系统制备用于基因组编辑的组合物的方法在美国公开No.2016/0340661、美国公开No.2016/0340662、美国公开No.2016/0354487、美国公开No.2016/0355796、美国公开No.2016/0355797和WO 2014/018423中进行了详细描述,通过引用,这些文献的内容整体纳入本申请中。
锌指核酸酶(ZFN)是通过将锌指DNA-结合域与DNA-切割域融合而产生的人工限制酶。锌指域可以设计为靶向期望的特定DNA序列,这样做使锌指核酸酶能够靶向复杂基因组内唯一的序列。利用内源DNA修复机制,这些试剂可用于精确改变更高生物体的基因组。最常见的切割域是IIS型酶Fok1。Fok1催化DNA的双链切割,一条链上距其识别位点9个核苷酸,另一条链上距其识别位点13个核苷酸。参见,例如,美国专利No.5,356,802;5,436,150和5,487,994;以及Li et al.Proc.,Natl.Acad.Sci.USA 89(1992):4275-4279;Li etal.Proc.Natl.Acad.Sci.USA,90:2764-2768(1993);Kim etal.Proc.Natl.Acad.Sci.USA.91:883-887(1994a);Kim et al.J.Biol.Chem.269:31,978-31,982(1994b),通过引用,这些文献都纳入本申请中。这些酶中的一种或多种酶(或其酶功能片段)可以用作切割域的来源。
在一些实施例中,通过遗传修饰菌株从而修饰叶绿素和/或血红素途径来产生富含血红素的藻类。引入重组核酸,例如干扰、抑制或下调内源基因(例如CHLD、CHLI1、CHLI2或CHLH1中的一种或多种基因)的表达的核酸,可以改变通过所述途径的通量。所述遗传修饰可包括重组DNA整合到内源基因的调控区、外显子或内含子中,以及基因沉默(例如,引入反义或siRNA来下调或沉默一个或多个内源基因的表达)。在一些实施例中,可以上调所述途径内基因的表达,从而使所述途径产生更多可以转化为血红素的PPIX,或者上调铁螯合酶的表达或活性以在藻类中产生更多血红素。修饰铁螯合酶的核酸可包括调控区(例如SEQID NO:114、115的那些调控区)、外显子(例如SEQ ID NO:116-122的那些外显子)以及内含子(例如SEQ ID NO:123-128中的那些内含子)。在一些实施例中,富含血红素的藻类可包括增加铁螯合酶拷贝数或提供过表达铁螯合酶的构建体(例如由核酸序列SEQ ID NO:7,及蛋白序列SEQ ID NO:8提供的那些)。在一些实施例中,遗传修饰包括对叶绿体中一种或多种基因的修饰或表达。在一些实施例中,对核编码基因或所述基因的表达进行修饰。
组合物和方法中使用的藻类种属
本文提供的用于生产血红素和含血红素组合物的组合物和方法中,采用具有血红素生物合成途径的藻类菌株。在一些实施例中,提供血红素的藻类菌株是绿藻(绿藻)。在一些实施例中,绿藻选自衣藻、杜氏藻、红球藻、小球藻和栅藻。在一些实施例中,衣藻是莱茵衣藻。在不同的实施例中,绿藻可以是绿藻、衣藻、莱茵衣藻,莱茵衣藻137c或psbA缺乏莱茵衣藻菌株。在一些实施例中,选择的宿主是莱茵衣藻,例如Rasala and Mayfield,BioengBugs.(2011)2(1):50-4;Rasala,et al.,Plant Biotechnol J.(2011)May 2,PMID21535358;Coragliotti,et al.,Mol Biotechnol.(2011)48(1):60-75;Specht,et al.,Biotechnol Lett.(2010)32(10):1373-83;Rasala,et al.,Plant Biotechnol J.(2010)8(6):719-33;Mulo,et al.,Biochim Biophys Acta.(2011)May 2,PMID:21565160;和Bonente,et al.,Photosynth Res.(2011)May 6,PMID:21547493;US公开No.2012/0309939;美国公开No.2010/0129394;和国际公开No.WO 2012/170125。通过引用,上述所有参考文献全文纳入本申请中。
在一些实施例中,提供血红素的藻类菌株是单细胞藻类。示例性和其他感兴趣的微藻包括但不限于:东方曲壳藻(Achnanthes orientalis)、阿格门氏藻(Agmenellum)、透明茧形藻(Amphiprora hyaline)、咖啡形双眉藻(Amphora coffeiformis)、咖啡形双眉藻线性变种(Amphora coffeiformis linea)、咖啡形双眉藻斑点变种(Amphoracoffeiformispunctata)、咖啡形双眉藻泰勒氏变种(Amphora coffeiformis taylori)、咖啡形双眉藻细薄变种(Amphora coffeiformis tenuis)、优美双眉藻(Amphoradelicatissima)、优美双眉藻头状变种(Amphora delicatissima capitata)、双眉藻属、鱼腥藻属、纤维藻属、卷曲纤维藻(Ankistrodesmusfalcatus)、黄金色藻(Boekeloviahooglandii)、波氏藻属(Borodinella)、布朗葡萄藻(Botryococcus braunii)、苏台德克斯葡萄藻(Botryococcus sudeticus)、四鞭藻属(Carteria)、纤细角毛藻(Chaetocerosgracilis)、牟氏角毛藻(Chaetoceros muelleri)、牟氏角毛藻广盐变种(Chaetocerosmuelleri subsalsum)、角毛藻属、衣藻属、莱茵衣藻、无硝小球藻(Chlorella anitrata)、南极小球藻(Chlorella Antarctica)、黄绿小球藻(Chlorella aureoviridis)、念球菌小球藻(Chlorella candida)、囊状小球藻(Chlorella capsulate)、干燥小球藻(Chlorelladesiccate)、椭圆小球藻(Chlorella ellipsoidea)、浮水小球藻(Chlorella emersonii)、淡褐小球藻(Chlorellafusca)、淡褐小球藻空泡变种(Chlorellafusca var.vacuolata)、谷氏小球藻(Chlorellaglucotropha)、水溪小球藻(Chlorella infusionum)、水溪小球藻栖海岸变种(chlorella infusionum var.actophila)、水溪小球藻增大变种(Chlorellainfusionum var.auxenophila)、凯氏小球藻(Chlorella kessleri)、匍扇小球藻(Chlorella lobophora)(菌株SAG 37.88)、黄绿小球藻(Chlorella luteoviridis)、黄绿小球藻金绿变种(Chlorella luteoviridis var.aureoviridis)、黄绿小球藻淡黄变种(Chlorella luteoviridis var.lutescens)、红藻小球藻(Chlorella miniata)、微小小球藻(Chlorella minutissima)、突变小球藻(Chlorella mutabilis)、夜间小球藻(Chlorella nocturna)、巴夫氏小球藻(Chlorellaparva)、嗜光小球藻(Chlorellaphotophila)、普氏小球藻(Chlorellapringsheimii)、原始小球藻(Chlorellaprotothecoides)、原始小球藻耐酸变种(Chlorellaprotothecoidesvar.acidicola)、规则小球藻(Chlorella regularis)、规则小球藻小型变种(Chlorellaregularis var.minima)、规则小球藻伞状变种(Chlorella regularis var.umbricata)、瑞氏小球藻(Chlorella reisiglii)、嗜糖小球藻(Chlorella saccharophila)、嗜糖小球藻椭圆变种(Chlorella saccharophila var.ellipsoidea)、盐生小球藻(Chlorellasalina)、简单小球藻(Chlorella simplex)、耐热性小球藻(Chlorella sorokiniana)、小球藻属、球形小球藻(Chlorella sphaerica)、斯蒂格小球藻(Chlorella stigmatophora)、万尼氏小球藻(Chlorella vanniellii)、普通小球藻(Chlorella vulgaris)、普通小球藻粗皮变种(Chlorella vulgarisf.tertia)、普通小球藻自养变种(Chlorella vulgarisvar.autotrophica)、普通小球藻绿色变种(Chlorella vulgaris var.viridis)、普通小球藻普通变种(Chlorella vulgaris var.vulgaris)、普通小球藻普通变种粗皮变种(Chlorella vulgaris var.vulgarisf.tertia)、普通小球藻普通变种绿色变种(Chlorella vulgaris var.vulgarisf.viridis)、黄色小球藻(Chlorella xanthella)、左氏小球藻(Chlorellazofingiensis)、他伯氏小球藻(Chlorella trebouxioides)、普通小球藻(Chlorella vulgaris)、水溪绿球藻(Chlorococcum infusionum)、绿球藻属(Chlorococcum sp.)、绿梭藻(Chlorogonium)、蓝隐藻属(Chroomonas sp.)、金球藻属(Chrysosphaera sp.)、球钙板藻属(Cricosphaera sp.)、寇氏隐甲藻(Crypthecodiniumcohnii)、隐藻属(Cryptomonas sp.)、隐蔽小环藻(Cyclotella cryptica)、梅尼小环藻(Cyclotella meneghiniana)、小环藻属(Cyclotella sp.)、杜氏藻属(Dunaliella sp.)、拜尔代维勒杜氏藻(Dunaliella bardawil)、双眼杜氏藻(Dunaliella bioculata)、颗粒状杜氏藻(Dunaliella granulate)、海洋杜氏藻(Dunaliella maritime)、微小杜氏藻(Dunaliella minuta)、巴夫杜氏藻(Dunaliellaparva)、比雷杜氏藻(Dunaliellapeircei)、普林莫杜氏藻(Dunaliella primolecta)、盐生杜氏藻(Dunaliellasalina)、陆生杜氏藻(Dunaliella terricola)、特氏杜氏藻(Dunaliella tertiolecta)、绿色杜氏藻(Dunaliella viridis)、特氏杜氏藻(Dunaliella tertiolecta)、绿色独球藻(Eremosphaera viridis)、独球藻属(Eremosphaera sp.)、椭圆藻属(Ellipsoidon sp.)、裸藻属(Euglena)、伏氏藻属(Franceia sp.)、克罗脆杆藻(Fragilaria crotonensis)、脆杆藻属(Fragilaria sp.)、粘球藻属(Gleocapsa sp.)、丽丝藻属(Gloeothamnion sp.)、膜胞藻属(Hymenomonas sp.)、球等鞭金藻亲近种(Isochrysis aff.galbana)、球等鞭金藻(Isochrysis galbana)、鳞孔藻属(Lepocinclis)、微星藻属(Micractinium)、微星藻属(Micractinium)(UTEX LB 2614)、微小单针藻(Monoraphidium minutum)、单针藻属(Monoraphidium sp.)、微球藻属(Nannochlorissp.)、盐生拟微球藻(Nannochloropsissalina)、拟微球藻属(Nannochloropsis sp.)、适意舟形藻(Navicula acceptata)、毕氏舟形藻(Navicula biskanterae)、假卵泡舟形藻(Naviculapseudotenelloides)、薄膜舟形藻(Naviculapelliculosa)、嗜腐舟形藻(Navicula saprophila)、舟形藻属(Navicula sp.)、肾鞭藻属(Nephrochloris sp.)、肾藻属(Nephroselmis sp.)、普通菱形藻(Nitschiacommunis)、亚历山大菱形藻(Nitzschia alexandrina)、普通菱形藻(Nitzschiacommunis)、细端菱形藻(Nitzschia dissipata)、碎片菱形藻(Nitzschiafrustulum)、汉氏菱形藻(Nitzschia hantzschiana)、平庸菱形藻(Nitzschia inconspicua)、中型菱形藻(Nitzschia intermedia)、小头菱形藻(Nitzschia microcephala)、微小菱形藻(Nitzschiapusilla)、微小菱形藻椭圆变种(Nitzschiapusilla elliptica)、微小菱形藻椭圆变种莫纳变种(Nitzschiapusilla monoensis)、四边形菱形藻(Nitzschiaquadrangular)、菱形藻属(Nitzschia sp.)、掠鞭藻属(Ochromonas sp.)、小卵胞藻(Oocystisparva)、极小卵胞藻(Oocystispusilla)、卵胞藻属(Oocystis sp.)、沼泽颤藻(Oscillatoria limnetica)、颤藻属(Oscillatoria sp.)、亚短颤藻(Oscillatoriasubbrevis)、嗜酸帕氏藻(Pascheria acidophila)、巴夫藻属(Pavlova sp.)、噬菌体属(Phagus)、席藻属(Phormidium)、扁藻属(Platymonas sp.)、卡氏颗石藻(Pleurochrysiscarterae)、齿状颗石藻(Pleurochrysis dentate)、颗石藻属(Pleurochrysis sp.)、魏氏原壁藻(Prototheca wickerhamii)、雍滞原壁藻(Prototheca stagnora)、波多黎各原壁藻(Protothecaportoricensis)、桑葚形原壁藻(Prototheca moriformis)、饶氏原壁藻(Prototheca zopfii)、塔胞藻属(Pyramimonas sp.)、桑葚藻属(Pyrobotrys)、囊状金藻(Sarcinoidchrysophyte)、被甲栅藻(Scenedesmus armatus)、裂壶藻属(Schizochytrium)、水绵属(Spirogyra)、钝顶螺旋藻(Spirulinaplatensis)、裂丝藻属(Stichococcus sp.)、聚球藻属(Synechococcus sp.)、四角藻(Tetraedron)、四爿藻属(Tetraselmis sp.)、亚心形扁藻(Tetraselmis suecica)、威氏海链藻(Thalassiosiraweissflogii)和弗雷德鲜绿藻(Viridiellafridericiana)。在一些实施例中,所述藻类是衣藻。在一些实施例中,所述藻类是莱茵衣藻。在一些实施例中,所述藻类是绿色衣藻菌株的衍生物,所述绿色衣藻菌株通过诱变、筛选、选择或与另一藻类菌株交配(mating)而制备。
在一些实施例中,根据一个或多个表型和/或基因型选择或鉴定用于本文所述方法和用于制备含血红素组合物的藻类菌株。在一些实施例中,可通过交配过程产生血红素高产藻类菌株。在一些实施例中,可通过诱变(例如紫外线诱变)来产生血红素高产藻类菌株。在一些实施例中,可通过使用导致DNA改变的化合物开展化学诱变来产生血红素高产藻类菌株。
藻类的选择方法包括但不限于对叶绿素生物合成途径和/或叶绿素积累的缺乏、突变和变化进行基因筛选或表型筛选,以及通过对血红素、血红素生物合成中间体和血红素生物合成酶增加表达和/或积累进行基因筛选或表型筛选。在一些实施例中,根据其光谱和/或其红色或类似红色来选择或鉴定用于本文所述方法和用于制备含血红素组合物的藻类菌株。在一些实施例中,根据其在黑暗条件下的生长速率选择或鉴定用于本文所述方法和用于制备含血红素组合物的藻类菌株。在一些实施例中,根据黑暗条件下的生长速率和在黑暗条件下生长时红色或类似红色颜色的出现或增强来进行选择。在一些实施例中,选择类胡萝卜素产生或积累缺乏或减少的藻类菌株。
在一些实施例中,将藻类菌株进行交配以组合或增强有助于血红素产生、血红素积累、叶绿素减少和/或类胡萝卜素减少的特性。在一些实施例中,将在黑暗条件下快速生长的藻类菌株(例如,比野生型菌株快)与呈现红色或类似红色颜色的藻类菌株进行交配。在一些实施例中,将缺乏类胡萝卜素产生或积累的藻类菌株与呈现红色或类似红色颜色的藻类菌株进行交配。
在一些实施例中,诱变藻类菌株,然后选择或鉴定表现出血红素产生增加、血红素积累增加、叶绿素减少和/或类胡萝卜素减少中一个或多个特征的新菌株。在一些实施例中,通过诱变第一起始菌株和选择在黑暗中比第一起始菌株生长更快的第二菌株来产生藻类菌株。在一些实施例中,通过诱变第一起始菌株和选择缺乏一种或多种类胡萝卜素的第二菌株来产生藻类菌株。在一些实施例中,所述菌株包括进一步修饰,例如减少ω油(例如,ω-3脂肪酸)的修饰和/或允许菌株在特定碳源(例如葡萄糖、右旋糖、蔗糖等)上生长的修饰。
在一些实施例中,藻类是衣藻属,例如莱茵衣藻,并且菌株具有明显的红色或红棕色外观。在一些实施例中,菌株还表现出在葡萄糖上生长。在一些实施例中,菌株在叶绿素合成途径方面具有遗传修饰,例如在Mg-螯合酶的核编码亚基中,例如在编码CHLD、CHLI1、CHLI2或CHLH1的基因中,或在其内含子或调控区中具有遗传修饰,从而菌株过表达血红素或富集血红素。在一些实施例中,菌株还富含PPIX。在一些实施例中,菌株能够在发酵条件下生长到高培养密度。
血红素高产菌株的培养方法
在液体培养基中生长藻类的方法包括各种各样的选择,包括池塘、水渠、小型实验室系统以及封闭和部分封闭的生物反应器系统。藻类也可以直接在水中,例如海洋、湖泊、河流、水库等中生长。
在一些实施例中,在本文所提供的方法和组合物中使用的血红素高产藻类在受控培养系统中生长,例如在小型实验室系统、大型系统和封闭系统以及部分封闭的生物反应器系统中生长。小型实验室系统指培养体积小于大约6升,范围从大约1毫升或以下到大约6升。大型培养是指培养体积大于大约6升,可以从大约6升到大约200升,甚至更大规模的系统,面积为5到2500平方米,甚至更大。大型培养系统可包括大约10000至大约20000升和高达大约1000000升的液体培养系统。
与制备本文所述组合物的方法一起使用的培养系统包括环境控制比开放系统或半封闭系统更严格的封闭结构,例如生物反应器。光生物反应器是集成某种类型的光源以向反应器提供光能输入的生物反应器。词语“生物反应器”指的是与环境隔绝、与环境不存在直接的气体和污染物交换的封闭系统。生物反应器可以被描述为一个封闭的(在光生物反应器的情况下,是发光的)培养容器,设计用于液体细胞悬浮培养物的受控生物质生产。
在一些实施例中,本文所提供的方法和组合物中使用的藻类在发酵容器中生长。在一些实施例中,容器是不锈钢发酵容器。在一些实施例中,藻类在向培养物提供一种或多种碳源的异养条件下生长。在一些实施例中,藻类在需氧和异养条件下生长。在一些实施例中,藻类生长至密度大于或大约10g/L、大约20g/L、大约30g/L、大约40g/L、大约50g/L、大约75g/L、大约100g/L、大约125g/L或大约150g/L。
在一些实施例中,将藻类从种箱中接种至起始密度大于大约0.1g/L、大约1.0g/L、大约5.0g/L、大约10.0g/L、大约20.0g/L、大约50g/L、大约80g/L或大约100g/L。一旦接种,藻类利用好氧发酵过程异养生长。在此过程中,给藻类提供营养物质来维持生长。在一些实施例中,所述营养物质包括还原碳源。示例性好氧发酵过程和/或还原碳源包括但不限于醋酸盐、葡萄糖、蔗糖、果糖、甘油和其他类型的糖(例如,右旋糖、麦芽糖、半乳糖、蔗糖、核糖等)。在一些实施例中,给藻类培养补充铁。
在一些实施例中,藻类在黑暗条件下生长。优选黑暗条件的亮度小于1000勒克斯、小于750勒克斯、小于500勒克斯、小于400勒克斯、小于300勒克斯、小于200勒克斯、小于100勒克斯。在一些实施例中,与在
在一些实施例中,本文所述富含血红素的菌株在黑暗或有限光照条件下生长,从而使胆绿素IX和光敏色素途径的通量减少,并且所述菌株中血红素含量增加。在一些实施例中,本文所述富含血红素的菌株在黑暗或有限光照条件下生长并利用碳源(例如葡萄糖)。
可食用食品及成分
本发明提供供人类和动物食用的含藻类血红素的可食用产品。在一些实施例中,可食用产品是类牛肉产品、类鱼肉产品或肉类仿制品。在一些实施例中,可食用产品包含全细胞藻类,其中藻类向组合物提供血红素。在一些实施例中,通过其中藻类高产血红素的全细胞藻类成分将血红素赋予可食用产品。在一些实施例中,通过血红素含量大于藻类叶绿素含量的藻类将血红素赋予可食用产品。在一些实施例中,通过原卟啉含量大于叶绿素含量至少5%、至少10%、至少20%、至少30%、至少40%或至少50%的藻类将血红素赋予可食用产品。
在一些实施例中,可食用产品是类牛肉产品、类鱼肉产品或肉类仿制品,血红素由分离的藻类提供。例如,产生或高产血红素的全细胞藻类可经受分离方法,以从含血红素的组分中分离出一些或大量生物质。分离可脱除藻类生物质的一种或多种组分,同时留下与含血红素组分相关的其他组分,例如ω-3脂肪酸、脂肪、蛋白质、维生素A、β-胡萝卜素或它们的任何组合。在一些实施例中,血红素可与藻类的ω-3脂肪酸、饱和脂肪、蛋白质、维生素A和/或β-胡萝卜素中的一种或多种组分分离。可采用溶剂和缓冲液或它们的组合萃取来提供富含血红素的组分。例如,藻类生物质或其各组分可通过己烷萃取来富集血红素。
在一些实施例中,将生物质分离或以其他方式处理,从而分离出血红素和任选PPIX。所述分离可以包括从血红素中分离PPIX。例如,血红素结合蛋白质及蛋白质缔合血红素可与PPIX分离,PPIX不是蛋白质结合化合物或蛋白质缔合化合物。根据血红素与铁的缔合,游离血红素和蛋白质缔合血红素都可以与PPIX分离。PPIX不含铁单元,因此,这种特征可用于将PPIX从与含血红素的组分中分离出来。在一些实施例中,本文所述藻类生物质被分离或以其他方式处理,从而使血红素与其他组分(包括PPIX)分离。
在一些实施例中,含血红素组分的血红素含量比所述组分的叶绿素含量高至少5%、至少10%、至少20%、至少30%、至少40%或至少50%。在一些实施例中,含血红素组分的原卟啉IX含量比所述组分的叶绿素含量高至少5%、至少10%、至少20%、至少30%、至少40%或至少50%。在一些实施例中,含血红素组分不含叶绿素或基本上不含叶绿素。在一些实施例中,含血红素的组分不含叶绿素或基本上不含叶绿素,并且含大约4.5%的原卟啉IX(以重量/总重量计,例如,1克样品中含45mg的原卟啉IX)。在一些实施例中,含血红素的组分不含叶绿素或基本上不含叶绿素,并且含大约0.5%的血红素(以重量/总重量计,例如,1克样品中含5mg的血红素)。在一些实施例中,含血红素的组分不含叶绿素或基本上不含叶绿素,并且含大约4.5%的原卟啉IX和大约0.5%的血红素(以重量/总重量计)。
在一些实施例中,用于制备可食用组合物的全藻制品的血红素含量大于所述组分的叶绿素含量。在一些实施例中,全藻制品的原卟啉IX含量大于所述组分的叶绿素含量。在一些实施例中,全藻制品不含叶绿素或基本上不含叶绿素。在一些实施例中,全藻制品不含叶绿素或基本上不含叶绿素,并且含大约4.5%的原卟啉IX(以重量/总重量计,例如,1克样品中含45mg的原卟啉IX)。在一些实施例中,全藻制品不含叶绿素或基本上不含叶绿素,并且含大约0.5%的血红素(以重量/总重量计,例如,1克样品中含5mg的血红素)。在一些实施例中,全藻制品不含叶绿素或基本上不含叶绿素,并且含大约4.5%的原卟啉IX和大约0.5%的血红素(以重量/总重量计)。
在一些实施例中,全藻制品或分离藻类制品不含叶绿素或基本上不含叶绿素,并且由不产生或积累叶绿素的藻类菌株制备。在一些实施例中,全藻制品或分离藻类制品不含叶绿素或基本上不含叶绿素,并且由在叶绿素合成途径中具有一个或多个突变和/或在影响叶绿素积累或转换的途径中具有一个或多个突变的藻类菌株制备,例如,在镁-螯合酶的一个或多个亚基中具有修饰,例如在CHLD、CHLI1、CHLI2或CHLH1亚基中的一个或多个亚基中具有修饰。
在一些实施例中,全藻制品或分离藻类制品含有大约0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.1%、1.2%、1.3%、1.4%、1.5%、1.6%、1.7%、1.8%、1.9%、2.0%、2.5%或大于2.5%的血红素(以重量/总重量计)。在一些实施例中,全藻制品或分离藻类制品含有大约0.5%、1.0%、1.5%、2.0%、2.5%、3.0%、3.5%、4.5%、5.0%、5.5%、6.0%、6.5%、7.0%、7.5%、8.0%、8.5%、9.0%、9.5%、10.0%或大于10%的原卟啉IX(以重量/总重量计)。在一些实施例中,全藻制品或分离藻类制品中的血红素是游离血红素。在一些实施例中,全藻制品或分离藻类制品中的血红素与一种或多种蛋白质络合,例如与一种或多种截短血红蛋白络合。在一些实施例中,全藻制品或分离藻类制品中的血红素是游离血红素与蛋白质络合血红素的混合物。
在一些实施例中,全细胞或分离藻类为可食用组合物提供蛋白质以及提供血红素。
在一些实施例中,藻类为可食用组合物提供至少大约1%、2%、3%、4%、5%、6%、7%、8%、9%或10%的蛋白质。在一些实施例中,藻类为可食用组合物提供大于大约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的蛋白质。在一些实施例中,全细胞或分离藻类为可食用组合物提供蛋白质,并且可食用组合物还包含来自一种或多种其他来源,例如植物来源的蛋白质。在一些实施例中,与起始生物质相比,藻类组分富含蛋白质。可以使用己烷萃取或相当的溶剂来富集组分中的蛋白质。在一些实施例中,通过所述萃取,碳水化合物和/或脂肪酸被脱除或其含量减少,同时富集蛋白质和/或富集血红素。
在一些实施例中,全细胞或分离藻类为可食用组合物提供ω-3脂肪酸以及提供血红素。在一些实施例中,藻类为可食用产品提供每日推荐剂量的ω-3脂肪酸或部分ω-3脂肪酸。例如,全细胞或分离藻类为可食用组合物提供至少大约5mg、10mg、15mg、20mg、25mg、30mg、35mg、40mg、45mg、50mg、55mg、60mg、65mg、70mg、75mg、80mg、85mg、90mg、95mg、100mg、125mg、150mg、175mg、200mg、250mg、300mg、350mg、400mg、450mg或500mg的ω-3脂肪酸。
在一些实施例中,从藻类生物质或分离藻类样品中脱除诸如ω-3脂肪酸等ω-油。所述油脱除可以改变藻类生物质或组分的香气和味道,例如通过减少或脱除藻类衍生产品中可能存在的“腥”气或“腥”味。在一些实施例中,在藻类生物质制备或分离中采用己烷或类似溶剂(例如异己烷、庚烷、丁烷或其他醇),以改变香气和味道。在某些情况下,采用正己烷或类似溶剂萃取可脱除或减少油的含量,并可在所得产品中富集血红素和/或富集蛋白质。
在一些实施例中,使用缺乏一种或多种ω-油的菌株制备藻类生物质或分离藻类。所述菌株可与富含血红素的菌株结合,例如通过交配产生富含血红素且减少ω-油的菌株。
在一些实施例中,全细胞或分离藻类为可食用组合物提供维生素A以及提供血红素。在一些实施例中,藻类为可食用产品提供每日推荐剂量的维生素A或部分维生素A。例如,全细胞或分离藻类提供至少大约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的每日推荐维生素A剂量或至少大约20μg、50μg、100μg、200μg、300μg、400μg、500μg、600μg、700μg、800μg、900μg或1000μg视黄醇活性当量(RAE)的维生素A。在一些实施例中,全细胞或分离藻类提供不超过大约2000μg、2500μg或3000μg视黄醇活性当量(RAE)的维生素A。
在一些实施例中,全细胞或分离藻类为可食用组合物提供β胡萝卜素以及提供血红素。在一些实施例中,藻类为可食用产品提供每日推荐剂量的β胡萝卜素或部分β胡萝卜素。例如,全细胞或分离藻类提供至少大约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%的每日推荐β-胡萝卜素剂量。在一些实施例中,藻类提供大约0.25mg、0.5mg、1mg、1.5mg、2mg、2.5mg、3mg、4mg、5mg、6mg、9mg、10mg、12mg或15mgβ-胡萝卜素。
在一些实施例中,提供血红素的全细胞或分离藻类含有饱和脂肪。在一些实施例中,藻类为可食用产品提供的饱和脂肪低于每日推荐限值或提供每日推荐限值一部分的饱和脂肪。例如,全细胞或分离藻类提供的饱和脂肪不超过每日推荐剂量的大约1%、5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或100%。在一些实施例中,藻类提供的脂肪含量不超过可食用组合物或由可食用组合物制成的成品中总饱和脂肪的0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.2%、1.5%、2%、5%或10%。
在本文的一些实施例中,使用含血红素的全藻类或藻类组分来制备可食用组合物,然后将可食用组合物作为成品的成分。所述成分可提供血红素以及ω-3脂肪酸、脂肪、蛋白质、维生素A、β-胡萝卜素或它们的任何组合。所述成分可以是着色剂、定型剂、粘合剂、营养源、口味或风味增强剂或填充剂。
在一些实施例中,使用含血红素的全藻类或藻类组分来制备作为成品的可食用组合物。例如,成品可能是类肉产品,如汉堡、肉饼、蛋糕、碎“肉”、香肠、烤肉串、牛排、切成块的“肉”、“肉丸”、“肉片”、“鸡腿”、“鸡条”或“鸡块”。成品可以是类似牛肉、鸡肉、猪肉、野味、火鸡或其他消费性肉类产品的类肉产品。成品可以是类似鱼片、鱼饼或鱼糕、鱼丸、鱼沙拉、碎鱼肉、鱼块、鱼汉堡等的类鱼产品,例如金枪鱼产品、辛辣金枪鱼产品或鲑鱼产品。
全藻或藻类组分可为成品提供ω-3脂肪酸、饱和脂肪、蛋白质、维生素A、β-胡萝卜素或它们的任何组合。在一些实施例中,全藻或藻类组分的
在一些实施例中,包括全藻或藻类组分的成品是熟食产品。在一些实施例中,包括全藻或藻类组分的成品是未煮熟的产品或生产品。在一些实施例中,包括全藻或藻类组分的成品是部分-煮熟的产品。
含血红素的制品和产品
如本文所述的血红素高产藻类菌株和培养物可用于各种形式和制品中。在一些实施例中,含血红素的组合物由血红素高产藻类培养物制备,其中所述组合物为红色或类似红色。
在一些实施例中,含血红素的组合物由从培养藻类中分离出的生物质制备。在一些实施例中,所述生物质进一步分离以脱除一种或多种组分。在一些实施例中,所述生物质进一步分离以脱除淀粉。在一些实施例中,所述生物质进一步分离以脱除蛋白质。在一些实施例中,所述生物质进一步分离或以其它方式处理以脱除类胡萝卜素。在一些实施例中,所述生物质进一步分离或以其它方式处理以富集某些组分。在一些实施例中,分离或处理的生物质富含血红素。在一些实施例中,分离或处理的生物质富含蛋白质或富含蛋白质和血红素。在一些实施例中,分离或处理增强了制品的红色或类似红色。分离或处理后的生物质可富含蛋白质,从而组合物含大约10%蛋白质、大于大约10%蛋白质、或大于大约20%、大约30%、大约40%或大约50%蛋白质。
在一些实施例中,含血红素的组合物是由培养藻类的培养基制备的含血红素的液体。在一些实施例中,含血红素的组合物由藻类培养物中细胞外发现的血红素制备。在一些实施例中,将藻类培养物溶解或以其他方式处理以从细胞释放出血红素。在一些实施例中,将含血红素的液体进一步分离,以脱除一种或多种组分。在一些实施例中,将含血红素的液体分离以脱除淀粉。在一些实施例中,将含血红素的液体分离以脱除蛋白质。在一些实施例中,将含血红素的液体分离或以其它方式处理以脱除类胡萝卜素。在一些实施例中,将含血红素的液体分离或以其它方式处理以富集某些组分。在一些实施例中,分离或处理的含血红素的液体富含血红素。在一些实施例中,分离或处理增强了制品的红色或类似红色。
含有血红素的组合物,包括生物质、液体和分离制品可以进一步处理。所述处理可以包括浓缩、干燥、冻干和冷冻。在各种实施例中,含血红素的组合物可与其它组分和成分组合。在一些实施例中,将含血红素的组合物与其它成分组合以制备可食用产品。在一些实施例中,含血红素的组合物赋予可食用产品红色或类似红色。在一些实施例中,含血红素的组合物赋予可食用产品类似肉的特性,例如类肉味道、类肉香味和/或质地。在一些实施例中,含血红素的组合物为可食用产品(例如肉类仿制品、类牛肉产品、类鸡肉产品等)提供血液的外观。或者,肉或类似肉的风味或香气、肉或类似肉的质地、血液状外观、肉或类似肉的颜色中的至少一个特征来自藻类制品。
在一些实施例中,将含血红素的组合物与其它成分组合以制备类肉产品。所述类肉产品可包括清洁肉或人造肉(由实验室内或动物外部生长的动物细胞制备)、植物性和非动物性肉(由植物成分和/或非动物来源的成分制备)。在一些实施例中,将由高产藻类制备的含血红素的组合物与其它成分组合以制备类肉产品,其中添加含血红素的组合物赋予类肉产品红色或类似红色的颜色、类肉香气、类肉味道和/或类肉质地。在一些实施例中,将含血红素组合物赋予的类肉特征赋予生的或未煮熟的产品。在一些实施例中,将含血红素组合物赋予的类肉特征赋予煮熟的产品。
在一些实施例中,全藻或分离藻类与可食用组合物中的其它蛋白质源组合。例如,蛋白质源是小麦蛋白质,例如小麦蛋白质、组织化小麦蛋白质、豌豆蛋白质、组织化豌豆蛋白质、大豆蛋白质、组织化大豆蛋白质、马铃薯蛋白质、乳清蛋白质、酵母提取物或其他植物类蛋白质源或它们的任何组合。在一些实施例中,全藻或分离藻类与可食用组合物中的油或脂肪源组合。例如,油或脂肪源是椰子油、菜籽油、葵花籽油、红花油、玉米油、橄榄油、鳄梨油、坚果油或其他植物油或脂肪源或它们的任何组合。在一些实施例中,全藻或分离藻类与淀粉或其他碳水化合物来源(例如来自马铃薯、鹰嘴豆、小麦、大豆、豆子、玉米或其他植物淀粉或碳水化合物或它们的任何组合)组合。在一些实施例中,全藻或分离藻类与可食用组合物中的增稠剂组合。例如,如竹芋淀粉、玉米淀粉、片栗淀粉、马铃薯淀粉、西米淀粉、木薯淀粉及它们的淀粉衍生物可用作增稠剂;用作食品增稠剂的微生物胶和植物胶包括褐藻胶、瓜尔胶、刺槐豆胶、魔芋胶和黄原胶;蛋白质如胶原蛋白和蛋白可以用作增稠剂;用作增稠剂的糖聚合物包括琼脂、甲基纤维素、羧甲基纤维素、果胶和角叉菜胶。在一些实施例中,全藻或藻类组分可与可食用组合物中的维生素和矿物质组合,例如维生素E、维生素C、硫胺(维生素B1)、锌、烟酸、维生素B6、核黄素(维生素B2)和维生素B12混合。
在一些实施例中,全藻或藻类组分可与其它成分组合,从而使可食用组合物和/或成品是素食、严格素食或无麸质食品,因此符合犹太洁食教徒和清真教徒的饮食指南。因此,在一些实施例中,可食用组合物和/或成品可适合素食者、严格素食主义者、无麸质人群、犹太洁食教徒和清真教徒食用。在一些实施例中,全藻或藻类组分可与其它成分组合,从而使可食用组合物和/或成品不含转基因和/或不含任何来自转基因生物或细胞的成分。
示例性编号实施例
以下实施例叙述了本文公开特征各种组合的非限制性排列。也可以考虑各种特征组合的其他排列。特别是,这些编号实施例中的每一个实施例都被设想为依赖于或与前面或后面每个编号的实施例有关,而与它们所列出的顺序无关。
实施例1.一种具有遗传修饰的工程藻类,其中与缺乏遗传修饰的藻类相比,所述遗传修饰引起藻类中血红素积累。实施例2.根据实施例1所述的工程藻类,其中所述工程藻类降低或缺少叶绿素产生。实施例3.根据实施例1或实施例2所述的工程藻类,其中所述藻类具有红色或类似红色颜色。实施例4.根据实施例1-3中任一实施例所述的工程藻类,其中所述藻类能够在作为唯一碳源的葡萄糖上生长。实施例5.根据实施例1-4中任一实施例所述的工程藻类,其中所述遗传修饰包括对叶绿素合成途径、原卟啉原IX合成途径或血红素合成途径的遗传改变。实施例6.根据实施例1-5中任一实施例所述的工程藻类,其中所述遗传修饰与镁螯合酶表达缺乏有关。实施例7.根据实施例1-6中任一实施例所述的工程藻类,其中所述遗传修饰包括CHLD、CHLI1、CHLI2或CHLH1亚基中一个或多个亚基发生变化。实施例8.根据实施例7所述的工程藻类,其中所述遗传修饰包括上游调控区、下游调控区、外显子、内含子或其任何组合中的改变。实施例9.根据实施例5-8中任一实施例所述的工程藻类,其中所述遗传修饰包括插入、缺失、点突变、倒位、重复、移码或其任何组合。实施例10.根据实施例1-9中任一实施例所述的工程藻类,其中所述工程藻类中血红素的含量大于叶绿素的含量。实施例11.根据实施例1-10中任一实施例所述的工程藻类,其中所述工程藻类中原卟啉IX的含量大于叶绿素的含量。实施例12.根据实施例1-11中任一实施例所述的工程藻类,其中所述工程藻类中一种或多种脂肪酸的产生量降低。实施例13.根据实施例1-12中任一实施例所述的工程藻类,其中所述工程藻类进一步包括减少或消除非光依赖性原叶绿素酸酯氧化还原酶表达的遗传修饰。实施例14.根据实施例13所述的工程藻类,其中所述遗传修饰包括ChlB、ChlL或ChlN中一个或多个出现突变或缺失。实施例15.根据实施例1-14中任一实施例所述的工程藻类,其中所述工程藻类中铁螯合酶的表达上调。实施例16.根据实施例1-15中任一实施例所述的工程藻类,其中所述工程藻类中原卟啉原IX氧化酶的表达上调。实施例17.根据实施例1-16中任一实施例所述的工程藻类,其中所述藻类含有重组或异源核酸。实施例18.根据实施例1-17中任一实施例所述的工程藻类,其中所述工程藻类包括衣藻属。实施例19.根据实施例18所述的工程藻类,其中所述衣藻是莱茵衣藻。
实施例20.一种包含藻类制品的可食用组合物,其中所述藻类制品包含实施例1-19中任一实施例或其部分所述的工程藻类。实施例21.根据实施例20所述的可食用组合物,其中所述可食用组合物包括源于工程藻类的血红素。实施例22.根据实施例20所述的可食用组合物,其中所述藻类制品包括藻类细胞。实施例23.根据实施例20所述的可食用组合物,其中所述藻类制品是分离藻类制品。实施例24.根据实施例20-23中任一实施例所述的可食用组合物,其中所述藻类制品是红色或类似红色颜色。实施例25.根据实施例20-24中任一实施例所述的可食用组合物,其中所述可食用组合物具有源于所述藻类制品的红色或类似红色颜色。实施例26.根据实施例20-25中任一实施例所述的可食用组合物,其中所述藻类制品赋予所述可食用组合物肉味或类肉味道。实施例27.根据实施例20-26中任一实施例所述的可食用组合物,其中所述可食用组合物具有源于所述藻类制品的肉质或类肉质地。实施例28.根据实施例27所述的可食用组合物,其中肉质或类肉质地包括牛肉或类牛肉质地、鱼肉或类鱼肉质地、鸡肉或类鸡肉质地、猪肉或类猪肉质地或肉仿制品质地。实施例29.根据实施例20-28中任一实施例所述的可食用组合物,其中所述可食用组合物是选自类牛肉食品、类鱼肉产品、类鸡肉产品、类猪肉产品和肉类仿制品的成品。实施例30.根据实施例20-29中任一实施例所述的可食用组合物,其中所述可食用组合物是严格素食、素食或无麸质产品。实施例31.根据实施例20-30中任一实施例所述的可食用组合物,其中所述可食用组合物具有源于所述藻类制品的血液外观。实施例32.根据实施例20-31中任一实施例所述的可食用组合物,其中所述藻类制品中血红素的含量大于叶绿素的含量。实施例33.根据实施例20-32中任一实施例所述的可食用组合物,其中所述藻类制品中原卟啉IX的含量大于叶绿素的含量。实施例34.根据实施例20-33中任一实施例所述的可食用组合物,其中所述藻类制品为可食用组合物提供的蛋白质至少占总蛋白质含量的大约5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%。实施例35.根据实施例20-34中任一实施例所述的可食用组合物,其中所述藻类制品为所述组合物提供维生素A、β胡萝卜素或它们的组合。实施例36.根据实施例35所述的可食用组合物,其中维生素A、β-胡萝卜素或其组合至少约为每日推荐需求量的5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、99%或100%。实施例37.根据实施例20-36中任一实施例所述的可食用组合物,其中所述藻类制品提供的饱和脂肪少于可食用组合物中总饱和脂肪的大约0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.2%、1.5%、2%、5%或10%。实施例38.根据实施例20-37中任一实施例所述的可食用组合物,其中所述藻类制品提供的饱和脂肪少于含食用组合物的成品中总饱和脂肪的大约0.01%、0.05%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.2%、1.5%、2%、5%或10%。实施例39.根据实施例20-38中任一实施例所述的可食用组合物,其中所述藻类制品为可食用组合物提供至少大约5mg、10mg、15mg、20mg、25mg、30mg、35mg、40mg、45mg、50mg、55mg、60mg、65mg、70mg、75mg、80mg、85mg、90mg、95mg、100mg、125mg、150mg、175mg、200mg、250mg、300mg、350mg、400mg、450mg或500mg的ω-3脂肪酸。实施例40.根据实施例20-39中任一实施例所述的可食用组合物,其中所述藻类制品的脂肪酸含量减少。实施例41.根据实施例20-40中任一实施例所述的可食用组合物,其中所述可食用产品与蛋白质源、脂肪源、碳水化合物、淀粉、增稠剂、维生素、矿物质或其任何组合组合。实施例42.根据实施例41所述的可食用组合物,其中所述蛋白质源选自小麦组织蛋白、大豆组织蛋白和豌豆组织蛋白、真菌蛋白或藻类蛋白。实施例43.根据实施例41所述的可食用组合物,其中所述脂肪源包括精制椰子油或葵花籽油中的至少一种。实施例44.根据实施例41-43中任一实施例所述的可食用组合物,进一步包括马铃薯淀粉、甲基纤维素、水和调味料中的至少一种,其中所述调味料选自酵母提取物、大蒜粉、洋葱粉和盐中的至少一种。实施例45.根据实施例41-44中任一实施例所述的可食用组合物,其中所述可食用产品是汉堡、香肠、烤肉串、鱼片、鱼类替代品、绞肉类产品或肉丸的成分。实施例46.根据实施例45所述的可食用组合物,其中所述汉堡包括大约5%的藻类制品、大约20%的大豆组织蛋白和大约20%的精制椰子油。实施例47.根据实施例46所述的可食用组合物,进一步包括大约3%的葵花籽油、大约2%的马铃薯淀粉、大约1%的甲基纤维素、大约45%的水和大约4-9%的调味料。实施例48.根据实施例46所述的可食用组合物,进一步包括大约0.5%的魔芋胶、大约0.5%的黄原胶、大约45%的水和大约4-9%的调味料。实施例49.根据实施例45所述的可食用组合物,其中所述鱼类替代品包括20%的大豆组织蛋白、大约5%的藻类制品、大约65%的水和大约10%的调味料。实施例50.根据实施例20-49中任一实施例所述的可食用组合物,其中所述可食用组合物不含动物蛋白质。实施例51.根据实施例20-50中任一实施例所述的可食用组合物,其中所述藻类制品包括原卟啉原IX合成或积累增加的藻类。实施例52.根据实施例20-51中任一实施例所述的可食用组合物,其中所述藻类制品包括在黑暗条件下生长时呈红色或类似红色颜色的藻类。实施例53.根据实施例20-52中任一实施例所述的可食用组合物,其中所述藻类制品中包括的藻类是重组或转基因藻类。实施例54.根据实施例20-53中任一实施例所述的可食用组合物,其中所述藻类制品包括衣藻属。实施例55.根据实施例54所述的可食用组合物,其中所述衣藻是莱茵衣藻。
实施例56.一种生产可食用组合物的方法,包括:(a)在工程藻类呈现红色或类似红色颜色且工程藻类产生血红素的条件下培养实施例1-19中任一实施例所述的工程藻类,(b)收集培养的工程藻类以生产藻类制品,以及(c)将藻类制品与至少一种可食用成分组合,以生产可食用组合物。实施例57.根据实施例56所述的方法,其中所述条件包括发酵条件。实施例58.根据实施例56-57中任一实施例所述的方法,其中所述条件包括乙酸盐作为工程藻类生长的还原碳源。实施例59.根据实施例56-58中任一实施例所述的方法,其中所述条件包括糖作为工程藻类生长的还原碳源。实施例60.根据根据实施例56-59中任一实施例所述的方法,其中所述条件包括黑暗或有限光照条件。实施例61.根据实施例56-60中任一实施例所述的方法,其中所述方法进一步包括分离培养的藻类以生产藻类制品。实施例62.根据实施例56-61中任一实施例所述的方法,其中所述藻类制品中血红素的含量大于叶绿素的含量。实施例63.根据实施例56-62中任一实施例所述的方法,其中所述藻类制品中原卟啉IX的含量大于叶绿素的含量。实施例64.根据实施例56-63中任一实施例所述的方法,其中所述条件进一步包括铁补充。实施例65.根据实施例56-64中任一实施例所述的方法,其中所述藻类制品是衣藻属。实施例66.根据实施例65所述的方法,其中所述工程藻类是莱茵衣藻。实施例67.根据实施例56-66中任一实施例所述的方法,其中所述可食用组合物具有以下至少一个特征:肉味或类似肉味、肉质或类肉质地、类似血液的外观及肉或类似肉的颜色,其中所述至少一个特征源自藻类制品。实施例68.根据实施例56-67中任一实施例所述的方法,其中所述方法进一步包括生产包含可食用组合物的成品,其中所述成品是类牛肉食品、类鱼肉产品、类鸡肉产品、类猪肉产品和肉类仿制品。实施例69.根据实施例56-68中任一实施例所述的方法,其中所述可食用组合物不含动物蛋白质。实施例70.根据实施例56-69中任一实施例所述的方法,其中对藻类制品进行分离,以脱除淀粉、蛋白质、PPIX、脂肪酸和叶绿素中的一种或多种。
实施例71.一种制备富含血红素的工程藻类的方法,包括:(a)使藻类菌株经受产生遗传修饰的过程,以产生第一藻类种群,和(b)从第一藻类种群中选择富含血红素和可选地富含PPIX的第二藻类种群。实施例72.根据实施例71所述的方法,其中所述过程包括随机UV诱变、随机化学诱变、重组基因工程、基因编辑或基因沉默中的至少一种过程。实施例73.根据实施例71或实施例72所述的方法,进一步包括在发酵条件下培养第一藻类种群。实施例74.根据实施例73所述的方法,其中所述发酵条件包括以糖作为唯一碳源的培养基。实施例75.根据实施例74所述的方法,其中所述糖选自葡萄糖、右旋糖、果糖、麦芽糖、半乳糖、蔗糖和核糖。实施例76.根据实施例73-75中任一实施例所述的方法,其中所述发酵条件包括亮度小于500勒克斯。实施例77.根据实施例73-76中任一实施例所述的方法,其中所述选择第二藻类种群包括分选或鉴定具有红色或类似红色颜色的藻类细胞。实施例78.根据实施例73-77中任一实施例所述的方法,其中所述选择由FACS执行。实施例79.根据实施例73-78中任一实施例所述的方法,其中所述第二藻类种群是根据其在发酵条件下的生长能力进行选择。
实例
实例1:藻类的诱变及菌株的筛选
用激发波长为420nm、发射波长为635nm的紫外光照射野生型藻类菌株(衣藻属)。首先这些菌株是根据其在葡萄糖等替代碳源上生长的能力选择。使用类似条件对这些挑选菌株中的一个菌株进行进一步诱变,使用荧光筛选(例如,荧光激活细胞分选(FACS))或磁性或微珠细胞分选来选择和/或鉴定红色菌株。这些选择如图2所示,并且在下文进一步详细说明。
血红素过表达藻类菌株(莱茵衣藻)根据其不能产生叶绿素而被鉴定出来。此外,这些菌株呈现出红色、棕色、橙色或所列颜色的某些变化。鉴定出的菌株对光敏感,并且在大于10μE m
为了产生血红素过表达藻类菌株,将莱茵衣藻的绿色亲本菌株置于紫外光交联仪中,暴露于25-300mJ/cm
对这些红色菌株中一个菌株的涉及叶绿素和血红素生物合成的基因座处进行基因组测序。测序结果表明,遗传修饰发生在CHLH基因座。红色菌株的CHLH序列在SEQ ID NO:129(核苷酸序列)和SEQ ID NO:152(氨基酸序列)中提供。与绿色菌株相比,这种修饰删除了CHLH中的单个碱基对,导致CHLH开放阅读框中的移码和/或产生终止密码子,从而蛋白质被翻译成截短形式。序列比较如图9所示(上序列(Seq_1)是绿藻CHLH基因的部分核酸序列(SEQ ID NO:27的残基1621-1679)和部分氨基酸序列(SEQ ID NO:28的残基451-460),且下序列(Seq_2)是红藻CHLH基因的部分核酸序列(SEQ ID NO:129的残基1621-1680)和部分氨基酸序列(SEQ ID NO:152的残基451-460)发生突变(星号))。本文提供了可在所述藻类菌株中改变的其它基因的核酸序列。
实例1A:在作为唯一还原碳源的糖上生长的血红素富含衣藻的鉴定
与乙酸盐相比,使用糖作为碳源对生产衣藻的成本具有经济效益。到目前为止,尚未鉴定出以糖作为碳源生长的莱茵衣藻菌株。通常,如图3所示,莱茵衣藻需要乙酸盐或阳光和二氧化碳才能生长。将来自野生或不同培养收集中心的藻类菌株接种在琼脂生长培养基上,葡萄糖加入量为25g/L。然后将平板置于黑暗中以确保不会发生光合作用。让培养物生长2周。两周后,研究培养物在无光照条件下的生长能力。然后将能够在黑暗中以葡萄糖为主要碳源生长的菌株置于装有生长培养基的摇瓶中,以25g/L葡萄糖作为主要碳源,并在黑暗中生长一周。每天监测培养基的培养密度和糖的浓度,以确定葡萄糖是否被菌株代谢。
在鉴定之后,将在作为碳源的葡萄糖上生长的衣藻菌株使用紫外光交联仪进行诱变。将培养物暴露于25-300mJ/cm
表1-5示出了一种示例性已鉴定红色血红素藻类的特征分析(菌株编号:TAI114,藻类种属名称:莱茵衣藻)。
表1:微生物分析
表2:重金属分析
表3:生物质分析
表4:卟啉(血红素)分析
表5:氨基酸组合物
实例1B:血红素高产藻类的鉴定
将鉴定菌株中的其中一个菌株在补料分批需氧发酵条件下生长,其中乙酸盐作为培养物营养的还原碳源。所述菌株是在发酵罐中生长,在发酵罐中,到达培养物的光照非常少。将菌株培养至密度大于120g/L,并通过离心收获。收获的菌株呈红色,可以添加到组合物中,例如食品中,以赋予组合物红色、橙色或棕色。图6示出了在好氧发酵条件下生长的血红素高产菌株的细胞重量。
实例1C:血红素高产藻类的高密度生长
将之前根据其过表达血红素的能力而筛选出来的衣藻菌株生长到高密度。为此,开发了包含培养基成分的基础培养基,所述培养基可使培养物达到每升120克。菌株是淡水藻类,从而当用水溶解时,此类培养基成分不超过10mS/cm。然后,利用好氧补料分批发酵过程培养培养物。培养物采用含醋酸盐作为碳源、氢氧化铵作为氮源和磷酸作为磷酸盐源的培养基喂养。培养物使用单侧酸性pH值恒定器进行喂养,以保持pH值为6.8。如图6所示,使培养物生长7天,并达到120g/L生物质的效价。血红素和原卟啉IX通过血红素定量分析法(Abnova KA1617)进行定量。血红素和原卟啉的含量大于生物质的5%(按重量计)。血红素和原卟啉IX的效价大于1g/L。简而言之,通过将藻类培养物与1.7M HCL和80%丙酮的溶液混合,从一定量的藻类培养物中提取血红素/原卟啉IX。让混合物静置30分钟。30分钟后,将样品离心分离,从藻类生物质中分离出血红素/原卟啉IX提取物。可溶性血红素/原卟啉IX样品用于Abnova的测定,并与标准曲线进行比较,以确定藻类生物质中血红素/原卟啉IX的含量。
实例2:分离
从发酵培养物收获来自莱茵衣藻血红素高产菌株的细胞。通过超声破碎收获的细胞,然后通过10,000x G离心分离样品,从样品中分离出类胡萝卜素、淀粉和蛋白质/血红素生物质组分。然后将蛋白质/血红素生物质重新悬浮在pH 7.4的磷酸盐缓冲盐水中。如图4所示,图中示出了离心后的分离(左)及含血红素组分的重悬浮(右)。亦如图5所示,图中示出了PPIX和血红素分离过程和/或产生生物质、提取物和/或冻干产品的过程。
实例3:血红素产生的表征
多种血红素分析方法可用于测定血红素的浓度。在一个实例中,可通过将藻类生物质混合到碱性水溶液中,使血红素转化为均匀的颜色来定量测定血红素的含量。颜色的强度可以通过400nm处的吸光度来测定,该吸光度与样品中血红素的浓度成正比。然后,将这些测定值与根据已知浓度血红素产生的标准值进行比较,从而确定藻类样品中血红素的含量。
实例4:富含血红素的“无肉”汉堡的制作
富含血红素的样品可用于制作由植物材料和血红素富含藻类制成的类肉产品组合物。为了制作富含血红素的汉堡,将各种成分按以下比例混合,并制作成一个圆盘状的藻类植物汉堡:20%或约20%的组织化小麦蛋白、20%或约20%精制椰子油、3%或约3%葵花籽油、2%或约2%马铃薯淀粉、0.5%或约0.5%魔芋胶、0.5%或约0.5%黄原胶、45%或约
在此实例中,富含血红素的藻类组合物含4.5%原卟啉IX、0.5%血红素、0%叶绿素、24.4%蛋白质、9%膳食纤维、40%淀粉、0.8%ω-3-脂肪酸、3.9%其他脂肪、7.5%水分和8.4%灰分。
实例5:富含血红素的植物汉堡的制作
富含血红素的样品可用于采用植物材料和富含血红素的藻类制作汉堡组合物。为了制作富含血红素的植物汉堡,将各种成分按以下比例混合,并制成圆形:20%或约20%的组织化大豆蛋白、20%或约20%的精制椰子油、3%或约3%的葵花籽油、2%或约2%的马铃薯淀粉、1%或约1%的甲基纤维素、45%或约45%的水和4-9%或约4-9%调味料(包括酵母提取物、大蒜粉、洋葱粉、盐),以及富含血红素(“红色”)的藻类。图11示出了植物汉堡各成分的成分混合物,其中未添加富含血红素的藻类(最左边)、添加了富含血红素的藻类(左二图)、添加富含血红素的藻类制作成的汉堡在烹饪前后的情况(分别为左三图和最右图)。如图中所示,添加富含血红素的藻类会使各成分混合物和汉堡呈现出红色/类似红色的颜色(类似于含有动物血液的汉堡),并且这种颜色在烹饪时会发生转变。
在此实例中,富含血红素的藻类组合物含4.5%原卟啉IX、0.5%血红素、0%叶绿素、24.4%蛋白质、9%膳食纤维、40%淀粉、0.8%ω-3-脂肪酸、3.9%其他脂肪、7.5%水分和8.4%灰分。
实例6:富含血红素的无肉“金枪鱼”的制作
富含血红素的样品可用于制作类鱼组合物,如图12所示。为了制作富含血红素的无肉“鱼”,各种成分按以下比例混合:20%或约20%的组织化大豆蛋白、65%或约65%的水和10%或约10%的调味料以及5%或约5%的富含血红素(“红色”)的藻类。图12是无肉“金枪鱼”的方形部分。
在此实例中,富含血红素的藻类组合物含4.5%原卟啉IX、0.5%血红素、0%叶绿素、24.4%蛋白质、9%膳食纤维、40%淀粉、0.8%ω-3-脂肪酸、3.9%其他脂肪、7.5%水分和8.4%灰分。
实例7:富含血红素的藻类菌株在葡萄糖上的生长
将富含血红素的藻类菌株在以葡萄糖作为唯一碳源的培养基中生长。简而言之,如图2所示,培养基在水中制备,每升总体积提供25g无水葡萄糖、5g KNO
将培养物置于黑暗的培养箱(无光照)中,并在30℃在旋转摇床平台上生长。每天测定培养密度(以干细胞重量计)和培养基中残余葡萄糖的浓度。图7显示干细胞重量随时间增加,同时培养基中残余葡萄糖减少。本实验中干细胞重量达到25g/L以上。
实例8:从整个生物质中提取血红素组分
使用富含血红素的藻类(按照类似于实例1的方式生长),制备富含血红素的组分。将约100g藻类生物质与含有80%丙酮和20%1.7M HCL的1.0L溶液混合30分钟。让生物质沉淀,然后将水层(含血红素和原卟啉IX)从固体中萃取到新容器中。对萃取的水层进行离心分离,或者在一些实验中,用分子截留值为0.4um的过滤器过滤样品。将得到的水组分用10MNaOH中和。然后每100毫升样品中加入100毫升水。在这种混合物之后,血红素和原卟啉IX变得不溶并从溶液中沉淀出来。然后将溶液离心分离,收集固体(包含血红素和原卟啉IX),并干燥,得到红色粉末。图5显示了通过该程序步骤收集到的类红色组分(包含血红素和原卟啉IX)。从160克红藻生物质中提取了7.7克PPIX/血红素。
实例9:脱除藻类生物质中的脂肪酸以富集血红素
将干衣藻细胞与水、乙醇和己烷按6:77:17的比例混合。将样品分离4小时。然后脱除含有脂肪酸的水层。然后对样品进行离心分离,将固体生物质层与任何剩余脂肪酸完全分离。在进一步分析之前,将生物质进行干燥。图8显示了脂肪酸萃取前后藻类生物质的生化分析,结果表明,萃取程序后脂肪酸含量减少了10倍以上。
实例10:靶向修饰叶绿素途径以产生富含血红素的菌株
导向RNA(sgRNA)可以针对镁螯合酶基因的任何亚基设计,从而导致使蛋白复合物失去功能的缺失或插入。设计好后,sgRNA可通过在37℃培养与Cas9蛋白结合,形成核糖核蛋白(RNP)。然后,将这些携带sgRNA靶向镁螯合酶的RNP电穿孔到绿藻培养物中。将3x10
实例11:修改叶绿素途径,产生富含血红素的菌株,改善不同的肉类仿制品
增加血红素前体(如氨基乙酰丙酸)的藻类菌株可与血红素过表达菌株交配,以进一步增加血红素或原卟啉IX的产生量。可以通过鉴定相反交配类型的衣藻菌株,然后使其缺乏氮来进行交配。缺氮后,将菌株重悬浮在水中以促进鞭毛的形成。不同交配类型的鞭毛有助于藻类菌株的融合,导致合子的形成。然后将交配的培养物暴露于氯仿中,杀死未交配的菌株。氯仿不会杀死合子。然后将合子置于生长培养基中并使其繁殖。然后鉴定单个菌落,并通过测定前体原卟啉IX的荧光增加或通过生化分析(Abnova KA1617)筛选血红素增加的菌落。
血红素过表达藻类菌株也可以与过低或过量产生ω-3s、ω-6s或ω-9s的菌株交配。对于鱼类仿制品来说,在血红素过表达藻类菌株中增加ω-油是理想的。对于牛肉仿制品来说,在血红素过表达藻类菌株中减少ω-油是理想的。因此,可以将高表达或低表达ω-油的突变体藻类菌株与血红素过表达藻类菌株交配,形成适用于各种肉类产品的更理想的藻类。
序列
丙氨酸脱水酶(ALAD)核酸序列(SEQ ID NO:1):
atgcagatgatgcagcgcaacgttgtgggccagcgccccgtcgctggctcccgccgctcgctggtggttgccaacgttgcggaggtgacccgccccgcggtcagcaccaacggcaagcaccggactggtgtgccggagggaactcccatcgtcacccctcaggacctgccctcgcgccctcgccgcaaccgccgcagcgagagcttccgtgcttccgttcgtgaggtgaacgtgtcgcccgccaacttcatcctgccgatcttcatccacgaggagagcaaccagaacgtgcccatcgcctccatgcctggcatcaaccgcctggcgtatggcaagaacgtgattgactacgttgctgaggctcgctcttacggtgtcaaccaggtcgtggttttccccaagacgcccgaccacctgaagacgcaaaccgcggaggaggcgttcaacaagaacggcctcagccagcgcacgatccgcctgctgaaggactctttccctgacctggaggtgtacacggacgtggctctggacccctacaactcggacggccacgacggtatcgtgtcggacgccggtgtgatcctgaacgacgagaccatcgagtacctgtgccgccaggccgtgagccaggccgaggccggtgccgacgtggtgtcgccctctgacatgatggacggccgcgtgggcgccatccgccgcgccctggaccgcgagggcttcaccaacgtgtccatcatgtcctacaccgccaagtacgcctccgcctactacggccccttccgtgacgccctggcgtccgcgcccaagcccggccaggcgcaccgccgcatcccccccaacaagaagacctaccagatggaccccgccaactaccgcgaggccatccgcgaggccaaggccgacgaggccgagggcgctgacatcatgatggtcaagcccggcatgccgtacctggacgtggtacgcctgctgcgtgagaccagcccgctgcccgtggccgtgtaccacgtgtcgggcgagtacgccatgctcaaggcggcggcggagcgcggctggctgaacgagaaggatgccgtgcttgaggccatgacctgcttccgccgcgccggcgctgacctcatcctcacctactacggcattgaggcctccaagtggctggcgggcgagaagtaa
丙氨酸脱水酶(ALAD)氨基酸序列(SEQ ID NO:2):
MQMMQRNVVGQRPVAGSRRSLVVANVAEVTRPAVSTNGKHRTGVPEGTPIVTPQDLPSRPRRNRRSESFRASVREVNVSPANFILPIFIHEESNQNVPIASMPGINRLAYGKNVIDYVAEARSYGVNQVVVFPKTPDHLKTQTAEEAFNKNGLSQRTIRLLKDSFPDLEVYTDVALDPYNSDGHDGIVSDAGVILNDETIEYLCRQAVSQAEAGADVVSPSDMMDGRVGAIRRALDREGFTNVSIMSYTAKYASAYYGPFRDALASAPKPGQAHRRIPPNKKTYQMDPANYREAIREAKADEAEGADIMMVKPGMPYLDVVRLLRETSPLPVAVYHVSGEYAMLKAAAERGWLNEKDAVLEAMTCFRRAGADLILTYYGIEASKWLAGEK
粪卟啉原III氧化酶(CPX1)核酸序列(SEQ ID NO:3):
atggcactgcaagcctcaacccgctcgctccagcagcgccgcgccttctcttcggcccagacctccaagcgtgtgtctgtgaccaaggtccgcgcgacggctatcgaggcggagaactatgtgaagcaggctccccagtcgctggtccgcccgggcatcgacactgaggactctatgcgcgctcgcttcgagaaggtgatccgcaacgcccaggactccatctgcaatgctatctccgagatcgatggcaagccgttccaccaggacgcctggacccgccccggcggcggtggcggcatcagccgcgtgctgcaggacggcaacgtgtgggagaaggccggcgtcaacgtgtccgtggtctacggcaccatgccccctgaggcctaccgcgctgccactggcaacgccgagaagctgaagaacaagggtgacggtggccgcgtgcccttcttcgccgccggcatctcgtcggtgatgcacccccgcaacccccactgccccaccatgcacttcaactaccgctacttcgagactgaggagtggaacggcatccccggccagtggtggttcggcggcggcaccgacatcacccccagctatgtggtgcccgaggacatgaagcacttccacggcacctacaaggcggtgtgcgaccgccacgatcccgcttactacgagaagttccgcacctggtgcgatgagtacttcctcatcaagcaccgcggcgagcgccgcggcctgggcggcatcttcttcgatgacctgaacgaccgcaaccccgaggacatcctgaagttctcgaccgacgccgtgaacaacgtggtggaggcatactgccccatcatcaagaagcacatgaacgacccctacacccccgaggagaaggagtggcagcagatccgccgcggccgctacgtggagttcaacctggtctatgaccgcggcaccaccttcggcctgaagaccggcggccgcattgagtcgatcctcatgtccatgccccagaccgcctcatggctgtacgaccaccagcccaaggccggctcgcccgaggccgagctgctcgacgcctgccgcaacccccgcgtctgggtgtaa
粪卟啉原III氧化酶(CPX1)氨基酸序列(SEQ ID NO:4):
MALQASTRSLQQRRAFSSAQTSKRVSVTKVRATAIEAENYVKQAPQSLVRPGIDTEDSMRARFEKVIRNAQDSICNAISEIDGKPFHQDAWTRPGGGGGISRVLQDGNVWEKAGVNVSVVYGTMPPEAYRAATGNAEKLKNKGDGGRVPFFAAGISSVMHPRNPHCPTMHFNYRYFETEEWNGIPGQWWFGGGTDITPSYVVPEDMKHFHGTYKAVCDRHDPAYYEKFRTWCDEYFLIKHRGERRGLGGIFFDDLNDRNPEDILKFSTDAVNNVVEAYCPIIKKHMNDPYTPEEKEWQQIRRGRYVEFNLVYDRGTTFGLKTGGRIESILMSMPQTASWLYDHQPKAGSPEAELLDACRNPRVWV
粪卟啉原III氧化酶(CPX1)(CPX2)核酸序列(SEQ ID NO:5):
atgctgaggaagcagattggtggatctggccagcagcgggcgggcctccgacgggtgaaccaaggacctgcgcgtcggcggttggcaccctgccgcgtggcggcccccgtgcaaacctcgtcctccgtcgccacattcaatggcttcgtggactacattcacggactccagaagaacattctgagcactgctgaggatctggagaacggcgagcggaagtttgttgttgaccgctgggagcgcgacgccagcaaccccaacgccgggtatggcattacgtgcgtgcttgaggacgggaaggtgctggagaaggccgcagccaatatctcagtggtgcgcgggacgctgtcggcgcagcgcgcagtggccatgagctcccgcggccgcagcagcatcgaccccaagggcgggcagccctacgccgcggccgccatgagcctagtgttccacagcgcgcacccgctcatccccacgctgcgcgcgacgtgcggttgttccaggtgggcgatgaggcgtggtacggcggtggctgtgacctgacgcccaactacctagacgtggaggactcgcagtccttccaccgctactggaaggacgtgtgcggcaagtacaagccgggcctgtacaccgagctcaaggagtggtgcgacaggtacttctacatcccggcccgcaaagagcaccgtggcattggcggcctgttctttgatgacatggccactgcggaggcgggctgcgatgtggaggcgtttgtgcgggaagtgggagatggcatcctgccctgctggctgcccatcgtggcgcggcaccgtggccagcccttcacggagcagcagcggcaatggcagctgctgcgccgcggtcgctacatcgagttcaacctgctgtacgaccgcggcatcaagttcggtctggacggcggccgcatcgagagcatcatggtgtcggcgccgccgctgatcgcgtggaagtacaacgtggtgccacagccgggcagccccgaggaggagatgctgaaggtgcttcagcagccccgcgagtgggcctga
粪卟啉原III氧化酶(CPX2)氨基酸序列(SEQ ID NO:6):
MLRKQIGGSGQQRAGLRRVNQGPARRRLAPCRVAAPVQTSSSVATFNGFVDYIHGLQKNILSTAEDLENGERKFVVDRWERDASNPNAGYGITCVLEDGKVLEKAAANISVVRGTLSAQRAVAMSSRGRSSIDPKGGQPYAAAAMSLVFHSAHPLIPTLRADVRLFQVGDEAWYGGGCDLTPNYLDVEDSQSFHRYWKDVCGKYKPGLYTELKEWCDRYFYIPARKEHRGIGGLFFDDMATAEAGCDVEAFVREVGDGILPCWLPIVARHRGQPFTEQQRQWQLLRRGRYIEFNLLYDRGIKFGLDGGRIESIMVSAPPLIAWKYNVVPQPGSPEEEMLKVLQQPREWA
莱茵衣藻铁螯合酶核酸序列(SEQ ID NO:7):
atggcgtcgtttggattgatgcaaaggacggtgcactgtccccagcttgtggaggagcggtgttcgccggtcgctggctgctctggtcgtggcctgccagttatccagcggcaacggcgtggcgtgtgcagtgccaccaacggtgtccagcgagggcgtgtgctgcgccggacggccgcttcgaccgacgtggtctccttcgtggaccccaatgacattagaaaacccgcagcagcagcagctggccctgcggtggataaggtcggcgttctgctgttaaaccttggcgggcccgaaaagctcgacgacgtcaagcctttcctgtataacctattcgccgacccagaaattattcgcctgccagcggcagctcagttcctgcagccgctgctcgcgacgatcatctccacgcttcgcgccccgaagagcgcggagggctatgaggccattggcggtggtagcccgttgcgtaggattacagacgagcaggcggaggcgctggcggagtctctgcgcgccaagggccaacctgcgaacgtgtacgtgggcatgcgctattggcacccctacacggaggaggcgctggagcacattaaggccgacggcgtcacgcgcctggtcatcctcccgctgtaccctcagttctccatctctaccagcggctccagccttcgactgcttgagtcgctcttcaagagcgacatcgcgctcaagtcgctgcggcacacggtcatcccgtcctggtaccagcggcggggctacgtgagcgcgatggcggacctgattgtagaggagctgaagaagttccgggacgtgcccagcgtggagctgtttttctccgcgcacggcgtgcccaagtcctacgtggaggaggcgggcgacccatacaaggaggagatggaggagtgcgtgcggctcattacggacgaggtcaagcggcgcggcttcgccaacacgcacacgctggcctaccagagccgcgtgggccccgcggaatggctcaagccgtacacggatgagtccatcaaggagctgggcaagcgcggcgtcaagtcgctgctggcggtgcccatcagctttgtcagcgagcacattgagacgttggaggagatcgacatggagtaccgcgagctggcggaggagagcggcatccgcaactggggccgcgtgccggcgctgaacaccaacgccgccttcatcgacgacctggcggacgcggtgatggaggcgctgccctacgtgggctgcctggccgggccgacagactcgctggtgccgctgggcgacctggagatgctgctgcaggcctacgaccgcgagcgccgcacgctgccgtcaccggtggtgatgtgggagtggggctggaccaagagcgcggagacgtggaacggccgcattgccatgattgccatcatcatcatcctggcgctggaggcagccagcggccagtccatcctcaaaaacctgttcctggcggagtag
莱茵衣藻铁螯合酶氨基酸序列(SEQ ID NO:8):
MASFGLMQRTVHCPQLVEERCSPVAGCSGRGLPVIQRQRRGVCSATNGVQRGRVLRRTAASTDVVSFVDPNDIRKPAAAAAGPAVDKVGVLLLNLGGPEKLDDVKPFLYNLFADPEIIRLPAAAQFLQPLLATIISTLRAPKSAEGYEAIGGGSPLRRITDEQAEALAESLRAKGQPANVYVGMRYWHPYTEEALEHIKADGVTRLVILPLYPQFSISTSGSSLRLLESLFKSDIALKSLRHTVIPSWYQRRGYVSAMADLIVEELKKFRDVPSVELFFSAHGVPKSYVEEAGDPYKEEMEECVRLITDEVKRRGFANTHTLAYQSRVGPAEWLKPYTDESIKELGKRGVKSLLAVPISFVSEHIETLEEIDMEYRELAEESGIRNWGRVPALNTNAAFIDDLADAVMEALPYVGCLAGPTDSLVPLGDLEMLLQAYDRERRTLPSPVVWEWGWTKSAETWNGRIAMIAIIIILALEAASGQSILKNLFLAE
谷氨酸-1-半醛氨基转移酶(GSA)核酸序列(SEQ ID NO:9):
atgcagatgcagctgaacgccaagaccgtgcagggcgccttcaaggcgcagcgccctcgctctgtccgcggcaacgtggcggtgcgcgcagtggccgctccccctaagctggtcaccaagcgctccgaggagatcttcaaggaggctcaggagctgctgcccggtggcgtgaactcgcccgtgcgcgctttccgctcggttggtggcggccccatcgtcttcgacagggtcaagggtgcctactgctgggacgtcgatggcaacaagtacatcgactacgttggctcttggggccctgccatttgcggccacggcaacgacgaggtcaacaacgccctgaaggcgcagatcgacaagggcacctcgttcggtgctccctgcgagctggagaacgtgctggccaagatggtgattgaccgcgtgccctcggtggagatggtgcgcttcgtgtcctcgggcactgaggcgtgcctgtcggtgctgcgcctgatgcgcgcatacaccggccgcgagaaggtgctgaagttcaccggctgctaccacggccacgccgactccttcctggtgaaggccggctccggtgtgatcaccctgggcctgcccgactcgcccggtgtgcccaagagcaccgccgccgccaccctgaccgccacctacaacaacctggactccgtgcgcgagctgttcgccgccaacaagggcgagattgccggtgtgatcctggagcccgtggtcggcaacagcggcttcattgtgcccaccaaggagttcctgcagggcctgcgcgagatctgcacggctgagggcgccgtgctgtgcttcgatgaggtcatgaccggcttccgcattgccaagggctgcgcccaggagcacttcggtatcacccccgacctgaccaccatgggcaaggtcattggtggcggcatgcctgtgggcgcctacggcggcaagaaggagatcatgaagatggtcgcccccgccggccccatgtaccaggccggcaccctttcgggcaaccccatggccatgactgccggcatcaagacgctggagatcctgggccgccccggcgcctacgagcacctggagaaggtgaccaagcgcctgatcgacggcatcatggccgccgccaaggagcacagccacgagatcaccggcggcaacatcagcggcatgtttggcttcttcttctgcaagggccctgtgacctgcttcgaggacgccctggcggccgacactgccaagttcgcgcgcttccaccgcggcatgctggaggagggcgtctacctggctccctcgcagttcgaggccggcttcacctctctggcccactccgaggcggacgtggatgccacgatcgccgccgctcgccgcgtgttcgcccgcatctaa
谷氨酸-1-半醛氨基转移酶(GSA)氨基酸序列(SEQ ID NO:10):
MQMQLNAKTVQGAFKAQRPRSVRGNVAVRAVAAPPKLVTKRSEEIFKEAQELLPGGVNSPVRAFRSVGGGPIVFDRVKGAYCWDVDGNKYIDYVGSWGPAICGHGNDEVNNALKAQIDKGTSFGAPCELENVLAKMVIDRVPSVEMVRFVSSGTEACLSVLRLMRAYTGREKVLKFTGCYHGHADSFLVKAGSGVITLGLPDSPGVPKSTAAATLTATYNNLDSVRELFAANKGEIAGVILEPVVGNSGFIVPTKEFLQGLREICTAEGAVLCFDEVMTGFRIAKGCAQEHFGITPDLTTMGKVIGGGMPVGAYGGKKEIMKMVAPAGPMYQAGTLSGNPMAMTAGIKTLEILGRPGAYEHLEKVTKRLIDGIMAAAKEHSHEITGGNISGMFGFFFCKGPVTCFEDALAADTAKFARFHRGMLEEGVYLAPSQFEAGFTSLAHSEADVDATIAAARRVFARI
谷氨酰-trna还原酶(HEMA)核酸序列(SEQ ID NO:11):
atgcagaccactatgcagcagcgtctccagggccgtaacgtggccgggcggagcgtcgctccctcggtccctgcccatcgctccttccactcacaccgggctgccactcaaaccgctacgatcagcgctgctgctagctcaaccaccaagctgccagcttcgcatctggagagcagcaagaaggcgctggattcgctgaagcagcaggccgtcaatcgctacgcgggtgacaagaagagctccattattgccattggtctcaccattcacaacgcacccgtggagctgcgcgagaagctggctgtgcctgaggctgaatggccgcgtgctattgaggagctctgccagttcccgcacatcgaggaggccgcggtgctgtcgacgtgcaatcgcatggagctctacgttgtcggtctgtcgtggcaccgcggcgttcgcgaggtggaggagtggctgtctcgcaccagcggcgtgcctctggatgagctgcgcccctacctgttcctgctgcgcgaccgcgacgccacgcaccacctgatgcgcgtgtcgggtggccttgactcgctggttatgggcgagggccagattctcgcccaagtgcgccaggtctacaaggtcggccagaactgccccggcttcggtcgccacctgaacggcctgttcaagcaggctatcaccgctggcaagcgcgtgcgtgccgagacctccatctccaccggctccgtctccgtctcatccgccgccgtcgagctggcgcagctcaagctccccacccacaactggtccgacgctaaggtctgcatcatcggcgctggcaagatgtctacgctgctggtgaagcacctgcagagcaagggctgcaaggaggtgacggtgctcaaccgctctctgccgcgcgcccaggcgctggcggaggagttccctgaggtcaagttcaacatccacctgatgcccgacctgctgcagtgcgtggaggccagcgacgtcatcttcgccgcctccggctctgaggagatcctcatccacaaggagcatgtcgaggccatgtccaagccatcggacgttgttggctccaagcgccgcttcgtcgacatctccgtgccccgcaacatcgcccccgccatcaacgagctggagcacggcatcgtctacaacgtcgacgacctgaaggaggttgtggccgccaacaaggagggccgcgcgcaggcggccgccgaggccgaggtgctgatccgcgaggagcagcgcgcgttcgaggcctggcgtgactctctggagaccgtgcccaccatcaaggcgctgcgctccaaggccgagaccatccgcgccgccgagtttgagaaggccgtgtctcgcctgggcgaggggctatccaagaagcagctcaaggcggtggaggagctcagcaagggcatcgtcaacaagctgctgcacgggcccatgacggcactgcgctgcgacggcaccgatccggatgccgtgggccagaccctcgcgaacatggaggccctggagcgcatgttccagctctcggaggtggacgtggccgcgctggcgggcaagcagtaa
谷氨酰-trna还原酶(HEMA)氨基酸序列(SEQ ID NO:12):
MQTTMQQRLQGRNVAGRSVAPSVPAHRSFHSHRAATQTATISAAASSTTKLPASHLESSKKALDSLKQQAVNRYAGDKKSSIIAIGLTIHNAPVELREKLAVPEAEWPRAIEELCQFPHIEEAAVLSTCNRMELYVVGLSWHRGVREVEEWLSRTSGVPLDELRPYLFLLRDRDATHHLMRVSGGLDSLVMGEGQILAQVRQVYKVGQNCPGFGRHLNGLFKQAITAGKRVRAETSISTGSVSVSSAAVELAQLKLPTHNWSDAKVCIIGAGKMSTLLVKHLQSKGCKEVTVLNRSLPRAQALAEEFPEVKFNIHLMPDLLQCVEASDVIFAASGSEEILIHKEHVEAMSKPSDVVGSKRRFVDISVPRNIAPAINELEHGIVYNVDDLKEVVAANKEGRAQAAAEAEVLIREEQRAFEAWRDSLETVPTIKALRSKAETIRAAEFEKAVSRLGEGLSKKQLKAVEELSKGIVNKLLHGPMTALRCDGTDPDAVGQTLANMEALERMFQLSEVDVAALAGKQ
非光依赖性原叶绿素酸酯还原酶亚基N(ch1N)核酸序列(SEQ ID NO:13):
atgttatactcacaatttaaacattcggtgcctttaggccgtaagtctccccttctttcagggggccccccttctgggggtcgcccaacaacggctgcctcaggcctaggtcgcaacgtggccgtaagaattgggaccccgttgggctttgcccttcgggcccaggtaattatggcagctgcgggcaatactagcggtgcgccgcaccccgtaggggagtcccagcctgcgttgtcccaggtggattctcaacttgtaattgagtgtgaaacaggaaattaccatactttttgcccaattagttgtgtttcttggttataccaaaaaattgaagatagttttttcttagttattggtacaaaaacgtgtgggtattttttacaaaatgctttaggggttatgatttttgccgaacctcgttacgctatggcggaattagaagaaagcgatatttcggcgcaattaaatgattacaaagaattaaaacgtctatgtttacaaattaaacaagaccgtaacccaagtgttattgtgtggattggcacatgcacaaccgaaattattaaaatggatttagaaggtatggcaccgaaactagaagctgaaatcggtattccaattgtggtagcacgcgcaaatggacttgattatgcttttacacaaggtgaagatactgttttagctgcgatggtccaaaaatgcccggaattaggcgctattccagctattgtacctcagattccttctgactctcgtacacttagccaactatctgtagcggcttcggtacccgaaaacagtgcgtctgggccagaaggggagccttcactagcccagaagggaatggattctaagttaacaaacaactctccatgccgagtagattctgtctcagaatctaccccggcgtttcctggacgtgctccgcacgtcgggaaaagtactcctcaaaatttagttttatttggttcattacctagcacgatggcaaatcaactggagtttgaattaaaacgccaaggtattaatgttactgggtggttacctgcggctcgctattcatctttacctgcattaggtgaaaacgtgtatgtttgtgggattaatccatttttaagtcgaactgctacttctttaatgcgtcgtcgtaaatgcaaattaatttcagctcctttcccaattggtccagatggtacaaaagcttgggtcgaaaaaatttgtaatgttttcggtgttacaccaactggtttagaagatcgtgaacgtcttgtttgggaaggtttaaaagattatttaaatttcgtaaaagggaaatctgttttctttatgggtgataatctgttagaaatttcattagcccgttttttaattcgctgtggtatgaccgtttatgaaatcggtattccgtacatggaccaacgatttcaagctggggaattagaattattaaaaaaaacatgcatggaaatgaacgtgcccctaccgcgtattgttgaaaaacctgataattactatcaaattcaacgtattaaagaattacaaccagatttagttattaccggcatggcccatgcaaacccactggaagcgcgcggcattactacgaaatggtccgttgaatttacgtttgcgcaaattcatgggtttggcaacgcacgtgatatcttagaattagttacaaaaccgttacgtcgtaataaaaatctatctaaatatcaatttccgttagatagctgggacaagcctgcttccgtaggcgctcacgaactgtcggcctaa
非光依赖性原叶绿素酸酯还原酶亚基N(ch1N)氨基酸序列(SEQ ID NO:14):
MLYSQFKHSVPLGRKSPLLSGGPPSGGRPTTAASGLGRNVAVRIGTPLGFALRAQVIMAAAGNTSGAPHPVGESQPALSQVDSQLVIECETGNYHTFCPISCVSWLYQKIEDSFFLVIGTKTCGYFLQNALGVMIFAEPRYAMAELEESDISAQLNDYKELKRLCLQIKQDRNPSVIVWIGTCTTEIIKMDLEGMAPKLEAEIGIPIVVARANGLDYAFTQGEDTVLAAMVQKCPELGAIPAIVPQIPSDSRTLSQLSVAASVPENSASGPEGEPSLAQKGMDSKLTNNSPCRVDSVSESTPAFPGRAPHVGKSTPQNLVLFGSLPSTMANQLEFELKRQGINVTGWLPAARYSSLPALGENVYVCGINPFLSRTATSLMRRRKCKLISAPFPIGPDGTKAWVEKICNVFGVTPTGLEDRERLVWEGLKDYLNFVKGKSVFFMGDNLLEISLARFLIRCGMTVYEIGIPYMDQRFQAGELELLKKTCMEMNVPLPRIVEKPDNYYQIQRIKELQPDLVITGMAHANPLEARGITTKWSVEFTFAQIHGFGNARDILELVTKPLRRNKNLSKYQFPLDSWDKPASVGAHELSA
非光依赖性原叶绿素酸酯亚基B(ch1B)核酸序列(SEQ ID NO:15):
atgaaattagcgtattggatgtatgcgggaccggctcatattggaacattacgagttgcaagctcgtttcgaaatgtgcatgctattatgcatgctcccttaggcgatgattattttaacgtaatgcgttcaatgttagaacgtgaacgtgattttacgccagtgacggcaagtattgttgatcgtcatgttttagctcgtggttcacaagaaaaagttgttgaaaacattcaacgaaaagataaagaagaatgtccggatttaattttattaacaccaacatgtacctcaagtattttgcaagaagatttacaaaattttgtaaatcgcgcggccgaagtagcaaagcgttcggatgttttattagctgacgttaaccattaccgagtgaatgaattacaagcggctgaccgtacgttagagcaaattgtacgcttttatttagaaaaagaagtaaataaacttcacgcggagttaggcggccttaaaaaaccgcttcgctttgcccagcgtacccaaaagccgtctgccaatattttaggcatgtttacactaggtttccataatcaacatgactgtcgtgaattaaaacgtttattaaatgatttaggtatcgaagtcaatgaagtgattcctgaaggtagttttgtacatggattaaaaaatttaccaaaagcgtggtttaacatcgtcccgtatcgtgaagttggtttaatgacggcaatttatttagaaaaagaatttggcatgccttatacctcaatcacgccaatgggcattattgacaccgcggcgtttattcgtgaaattgcggccatttgtagtcaaattagcacttcacaggcatctacaaactcaactgaaggactccagaggggagaaaatgtcagtttaactgaaactaattcgattatttttaataaagcaaaatatgaacaatacattaatcaacaaacgcattttgtttctcaagcagcttggttttcacgttctattgactgtcaaaatttaaccggtaaaaaaaccgttgtgtttggtgatgcaactcacgcggcaagtatgacgaaaattcttgtgcgcgaaatgggtattcatgttgtttgcgcgggcacgtattgtaaacatgatgcagattggtttagagagcaagtttcaggtttttgtgatcaagttttaattacagatgatcacagccaaattgcggaaatcattgctcaaattgaacctgcagccatttttggtacacaaatggaacgtcatgttgggaaaaggttagatattccttgtggggttatttctgcaccggtacatattcaaaacttcccactaggctttagaccgtttttagggtatgaaggtactaatcaaatttccgatttagtttataattcgtttagtttaggtatggaagatcacttactagaaattttcaacggtcatgacaataaagaagttattacacgttcgtattcttcagaaactgatttagaatggacaaaagaagcattagatgaactagctcgtgttcctggttttgttcgttcaaaagttaaacgtaatactgaaaaatttgcgcgtacaaataaaaatcaagttattactattgaagttatgtacgcagctaaagaagcggtatcagcgtaa
非光依赖性原叶绿素酸酯亚基B(ch1B)氨基酸序列(SEQ ID NO:16):
MKLAYWMYAGPAHIGTLRVASSFRNVHAIMHAPLGDDYFNVMRSMLERERDFTPVTASIVDRHVLARGSQEKVVENIQRKDKEECPDLILLTPTCTSSILQEDLQNFVNRAAEVAKRSDVLLADVNHYRVNELQAADRTLEQIVRFYLEKEVNKLHAELGGLKKPLRFAQRTQKPSANILGMFTLGFHNQHDCRELKRLLNDLGIEVNEVIPEGSFVHGLKNLPKAWFNIVPYREVGLMTAIYLEKEFGMPYTSITPMGIIDTAAFIREIAAICSQISTSQASTNSTEGLQRGENVSLTETNSIIFNKAKYEQYINQQTHFVSQAAWFSRSIDCQNLTGKKTVVFGDATHAASMTKILVREMGIHVVCAGTYCKHDADWFREQVSGFCDQVLITDDHSQIAEIIAQIEPAAIFGTQMERHVGKRLDIPCGVISAPVHIQNFPLGFRPFLGYEGTNQISDLVYNSFSLGMEDHLLEIFNGHDNKEVITRSYSSETDLEWTKEALDELARVPGFVRSKVKRNTEKFARTNKNQVITIEVMYAAKEAVSA
非光依赖性原叶绿素酸酯还原酶亚基L(ch1L)核酸序列(SEQ ID NO:17):
atgaaattagcagtttatggcaaaggtggtattggtaaatccacaacaagttgtaacatttcaattgcattagcaaaacgtggcaaaaaagtattacaaattggttgtgatccaaaacacgatagtacttttacattaaccggttttttaattccaacaattattgatactttacaaagtaaagattatcattacgaagatgtttggccggaagatgttatttaccaaggctacgggagtgtggattgtgttgaagcaggtggcccgccagccggcgccggctgtggtgggtatgttgttggtgaaacagttaaattattaaaagaattaaatgcattttatgaatatgatgttattctgtttgatgttttaggggatgttgtatgtggtgggtttgctgcacctttaaattacgccgactattgcattattgtcacagataatggctttgatgcgttatttgccgcaaaccgtattgctgcttcagtgcgcgaaaaagcgcgcattcacccattacgtttagctgggttaattgggaatcgtacagccaaacgcgatttaatcgataaatacgttgaagcgtgcccgatgccagtcttagaggtattaccgttaattgaagacattcgtgtgtcacgcgtaaaaggtaaaacattatttgaaatggcagaacatgattcatcattacactacatttgtgacttttatttaaatattgcggatcaattattaactgaaccagaaggtgttgttccgcgcgaattagcagaccgtgaattatttactctattatcagatttctatttaaacgctgggactcctagccctagtggatctgagttcggctcaggcgcccttagcggaacgagcggcgaaacagctcccggtaatatgggtcagcacatgagtaacgcagtaaaaacaaacgaacaggaaatgaatttctttcttgtgtaa
非光依赖性原叶绿素酸酯还原酶亚基L(ch1L)氨基酸序列(SEQ ID NO:18):
MKLAVYGKGGIGKSTTSCNISIALAKRGKKVLQIGCDPKHDSTFTLTGFLIPTIIDTLQSKDYHYEDVWPEDVIYQGYGSVDCVEAGGPPAGAGCGGYVVGETVKLLKELNAFYEYDVILFDVLGDVVCGGFAAPLNYADYCIIVTDNGFDALFAANRIAASVREKARIHPLRLAGLIGNRTAKRDLIDKYVEACPMPVLEVLPLIEDIRVSRVKGKTLFEMAEHDSSLHYICDFYLNIADQLLTEPEGVVPRELADRELFTLLSDFYLNAGTPSPSGSEFGSGALSGTSGETAPGNMGQHMSNAVKTNEQEMNFFLV
镁螯合酶亚基H(CHLH2)核酸序列(SEQ ID NO:19):
atgcggattgtgctggtcagcggcttcgagagctttaacgtgggcctgtacaaggatgcggcggagctgctgaagcgctccatgcccaacgtcacactccaggtgttctccgaccgcgacctggcctccgacgccacccgctcccggctggaggcggctctggggcgcgccgacatcttcttcggatcactgctgttcgactacgaccaggtggagtggctacgggcccggctggagcgggtgcctgtgcggctagtgtttgagtcggcgttggagctcatgagctgcaacaaggtggggtcgttcatgatgggcggcggcggtcccggcggcggcccgcccggcaaggcgcccggcccgccgcccgcggtgaagaaggttctctccatgtttggaagcggtcgcgaggaggacaagatgggcggctcctccaatgtggtggccatgttcagttacctggtggagaccctgatggagccaacgggtgggttatttggtagttggtggttgtgttatggttggccgtttcggttgggtgatctgggctggtatctacaacccccctcaaccctcacgcctccaggctacgtgccgccgcctgtggtggagactcccgcactgggctgcctccacccctccgcgcccggccgctacttcgagtcccccgccgagtacatgaagtggtacgccagggagggcccgctgcgcggcacgggcgccccggtggttggcgtgctgctgtaccgcaagcatgtgatcaccgaccagccgtacatcccgcagctggtcagccagctggaggcggaggggctgctgcccgtgcccatcttcatcaacggcgtggaggcgcacaccgtggttcgcgacctgctgacctccgtgcacgagcaggatctgcttgcacgcggcgagacgggcgccatcagccccaccctgaagcgggacgcggtcaaggtggacgcggtggtgagcaccattggcttcccgctggtgggcggccccgccggcaccatggagggcgggcggcaggcggaggtggccaaggccatcctgggcgccaaggacgtgccgtacacggtggcggcgccgctgcttattcaggacatggagagctggagcagggacggcgtggcgggtctccagagtgtggtgctgtactcgctgccggagctggacggcgcagtggacacggtgccactgggggggctggtgggggacgacatctacctggtgccggagcgggtgaagaagctggcggggcggctcaagtcgtggcgtacgacacgcactaagcatgcctctgtttgtgacgtccagcccctcccccccccgtctcccctctccaccctccctctcccttcctctcccttcctctcactctccaccctcttccccctccgcccaaacataacgaggcgggggctgctgggcgcaagcgggccctggagtacccgctgcgacctagctagtccaactccacccatcccccaatgccgcaatagctttccggagatgagcacacacacacacacacacacacacacacacacacacacacacacacacacacacacacgccacccacgcacacacacacacacacacgctccccccgctcgccacacccccatcccaccccacccgcaggagctgctgacgtaccccgcggactggggcccggccgagtggggcccgctgccctacctgcccgaccccgacgtgctggttcgccgcatggaggcgcagtggggcgagctgcgagcctaccgcggcctcaacacctcggcgcgcggcatgttccaggagtacggggctgacgtggtcctgcacttcggcatgcacggcaccgtggagtggttgcctggggcgccgctggggaacaacggcctcagctggagcgacgtgctgctcggcgagctgccaaacgtgtacgtgtacgctgccaacaacccctccgagtccatcgtggcaaagcggcgcggctacggcaccatcgtcagccacaacgtgccgccgtacgggcgggcgggtctgtacaagcagctttccagcctcaaggagacgcttcaggagtaccgcgaggccgcgcaggccgcacgtgcccgagcaggagccagcagcagcagcggcagtagcagcagtagcagtagcagcggcagtggcagtagcagcagcagtgtggagctgcgggcggcgttggcaccggtgttcgacgcctacactgaccgcctgtatgcctacctgcagctgctggaggggcggctgttcagcgaggggctacacgtactgggagcgccgccggcgccgccgcaggtgggtggttttcccgcgagcttccaacggtaccgtaaactgcccaactgcccaacttctccccaaacacaggaggctgtcaagatccggaacctgctcatgcagaacacgcaggagctggacgggctgctcaagggcctgggtgggcgttacgtgcttcccgaggcgggcggcgacctgctgcgggacgggtcgggcgtgctgcccaccggccgcaacatccacgcactggacccctaccgcatgccctcccccgccgccatggcccgtggggcggcggtggcggcggccattcttgagcagcaccgggcggctaacagcggggcgtggcccgagacctgcgccgtcaacctgtgggggctggactccatcaagagcaagggcgagagtgtgggggtggtgctggcgctggtgggggcggtgccggtgcgcgagggtacgggccgcgtcgcgcgcttccaactggtgccgctgtcagagttgggccggccgcgtgtggacgtgctttgtaacatgagcggcatcttccgcgactccttccagaacgtggtggagctgctcgacgacctgtttgcaagggccgccgccgccgctgacgagccagatgacatgaacttcatcgccaaacacgcccgagccatggagaagcagggcctgtccgccacctcggcccgcctgttctccaacccggctggcgactacgggtcgatggtcaacgagcgagtggggcagggcagctgggccaacggcgacgagctgggtgacacgtgggcggcccgcaacgccttcagctacggccgaggcaaggagcgaggcacggcgcggcccgaggtgctgcaggcgctgctcaagaccacggaccggatcgtgcagcagatcgacagtgtggagtacggcctgacagacatccaggagtactacgccaacacgggcgccctcaagagagccgccgaggtggccaaaggcgacccgggccccggtggccggcggccgcgcgtggggtgttccattgtggaggcctttggcggcgcgggcgcgggcgcgggcggcgccggtggagcgggcgtgccgccgcctcgcgagctggaggaggtgctgcgcctggagtaccgctcgaagctgctcaaccccaagtgggcccgggccatggcggcgcagggcagcggcggcgcctacgagatcagtcagcgcatgacggcgttggtgggctggggcgccaccaccgatttcagggagggctgggtgtgggacccaggcgccatggacacgtatgtgggcgatgaggagatggccagcaagctcaagaagaacaacccgcaggcctttgccaacgtgctgcggcgcatgctggaggcggcgggccgcggcatgtggagccccaacaaggaccagctggcacagctcaagtcgctgtacagcgagatggacgaccagctggagggggtgacg
镁螯合酶亚基H(CHLH2)氨基酸序列(SEQ ID NO:20):
MRIVLVSGFESFNVGLYKDAAELLKRSMPNVTLQVFSDRDLASDATRSRLEAALGRADIFFGSLLFDYDQVEWLRARLERVPVRLVFESALELMSCNKVGSFMMGGGGPGGGPPGKAPGPPPAVKKVLSMFGSGREEDKMGGSSNVVAMFSYLVETLMEPTGGLFGSWWLCYGWPFRLGDLGWYLQPPSTLTPPGYVPPPVVETPALGCLHPSAPGRYFESPAEYMKWYAREGPLRGTGAPVVGVLLYRKHVITDQPYIPQLVSQLEAEGLLPVPIFINGVEAHTVVRDLLTSVHEQDLLARGETGAISPTLKRDAVKVDAVVSTIGFPLVGGPAGTMEGGRQAEVAKAILGAKDVPYTVAAPLLIQDMESWSRDGVAGLQSVVLYSLPELDGAVDTVPLGGLVGDDIYLVPERVKKLAGRLKSWRTTRTKHASVCDVQPLPPPSPLSTLPLPSSPFLSLSTLFPLRPNITRRGLLGASGPWSTRCDLASPTPPIPQCRNSFPEMSTHTHTHTHTHTHTHTHTHTRHPRTHTHTHAPPARHTPIPPHPQELLTYPADWGPAEWGPLPYLPDPDVLVRRMEAQWGELRAYRGLNTSARGMFQEYGADVVLHFGMHGTVEWLPGAPLGNNGLSWSDVLLGELPNVYVYAANNPSESIVAKRRGYGTIVSHNVPPYGRAGLYKQLSSLKETLQEYREAAQAARARAGASSSSGSSSSSSSSGSGSSSSSVELRAALAPVFDAYTDRLYAYLQLLEGRLFSEGLHVLGAPPAPPQVGGFPASFQRYRKLPNCPTSPQTQEAVKIRNLLMQNTQELDGLLKGLGGRYVLPEAGGDLLRDGSGVLPTGRNIHALDPYRMPSPAAMARGAAVAAAILEQHRAANSGAWPETCAVNLWGLDSIKSKGESVGVVLALVGAVPVREGTGRVARFQLVPLSELGRPRVDVLCNMSGIFRDSFQNVVELLDDLFARAAAAADEPDDMNFIAKHARAMEKQGLSATSARLFSNPAGDYGSMVNERVGQGSWANGDELGDTWAARNAFSYGRGKERGTARPEVLQALLKTTDRIVQQIDSVEYGLTDIQEYYANTGALKRAAEVAKGDPGPGGRRPRVGCSIVEAFGGAGAGAGGAGGAGVPPPRELEEVLRLEYRSKLLNPKWARAMAAQGSGGAYEISQRMTALVGWGATTDFREGWVWDPGAMDTYVGDEEMASKLKKNNPQAFANVLRRMLEAAGRGMWSPNKDQLAQLKSLYSEMDDQLEGVT
镁螯合酶亚基1(CHLI1)莱茵衣藻核酸序列(SEQ ID NO:21):
atggccctgaacatgcgtgtttcctcttccaaggtcgctgccaagcagcagggccgcatctccgcggtgccggttgtgtcgagcaaggtggcctcctccgcccgcgtggcccccttccagggcgctcccgtggccgcgcagcgcgctgctctgctggtgcgcgccgctgccgctactgaggtcaaggctgctgagggccgcactgagaaggagctgggccaggcccgccccatcttccccttcaccgccatcgtgggccaggatgagatgaagctggcgctgattctgaacgtgatcgaccccaagatcggtggtgtcatgatcatgggcgaccgtggcactggcaagtccaccaccattcgtgccctggcggatctgctgcccgagatgcaggtggttgccaacgacccctttaactcggaccccaccgaccccgagctgatgagcgaggaggtgcgcaaccgcgtcaaggccggcgagcagctgcccgtgtcttccaagaagattcccatggtggacctgcccctgggcgccactgaggaccgcgtgtgcggcaccatcgacatcgagaaggcgctgaccgagggtgtcaaggcgttcgagcccggcctgctggccaaggccaaccgcggcatcctgtacgtggatgaggtcaacctgctggacgaccacctggtcgatgtgctgctggactcggccgcctccggctggaacaccgtggagcgcgagggtatctccatcagccaccccgcccgcttcatcctggtcggctcgggcaaccccgaggagggtgagctgcgcccccagctgctggatcgcttcggcatgcacgcccagatcggcaccgtcaaggacccccgcctgcgtgtgcagatcgtgtcgcagcgctcgaccttcgacgagaaccccgccgccttccgcaaggactacgaggccggccagatggcgctgacccagcgcatcgtggacgcgcgcaagctgctgaagcagggcgaggtcaactacgacttccgcgtcaagatcagccagatctgctcggacctgaacgtggacggcatccgcggcgacatcgtgaccaaccgcgccgccaaggccctggccgccttcgagggccgcaccgaggtgacccccgaggacatctaccgtgtcattcccctgtgcctgcgccaccgcctccggaaagaccccctggctgagatcgacgacggtgaccgcgtgcgtgagatcttcaagcaggtgttcggcatggagtaa
镁螯合酶亚基1(CHLI1)莱茵衣藻氨基酸序列(SEQ ID NO:22):
MALNMRVSSSKVAAKQQGRISAVPVVSSKVASSARVAPFQGAPVAAQRAALLVRAAAATEVKAAEGRTEKELGQARPIFPFTAIVGQDEMKLALILNVIDPKIGGVMIMGDRGTGKSTTIRALADLLPEMQVVANDPFNSDPTDPELMSEEVRNRVKAGEQLPVSSKKIPMVDLPLGATEDRVCGTIDIEKALTEGVKAFEPGLLAKANRGILYVDEVNLLDDHLVDVLLDSAASGWNTVEREGISISHPARFILVGSGNPEEGELRPQLLDRFGMHAQIGTVKDPRLRVQIVSQRSTFDENPAAFRKDYEAGQMALTQRIVDARKLLKQGEVNYDFRVKISQICSDLNVDGIRGDIVTNRAAKALAAFEGRTEVTPEDIYRVIPLCLRHRLRKDPLAEIDDGDRVREIFKQVFGME
镁螯合酶亚基1(CHLI2)莱茵衣藻核酸序列(SEQ ID NO:23):
atgcagagtctccagggtcagcgcgcgttcactgcggtgcgccagggtcgggcgggtcccctgcggactcgcctggtcgtgcgctcgtctgttgccttgccatccacgaaagccgcgaagaagccgaacttcccgttcgtcaagattcagggccaggaggagatgaagcttgcactgctgctgaacgtggtcgaccccaacatcggcggagtgcttattatgggtgaccgcggcactgccaagtcggtcgcggtccgcgccctggtggatatgcttcccgacattgacgtggttgagggcgacgccttcaacagctcccccaccgaccccaagttcatgggccccgacaccctgcagcgcttccgcaacggcgagaagctgcccaccgtccgcatgcggacccccctggtggagctgcctctgggcgccaccgaggaccgcatctgcggcaccatcgacatcgagaaggcgctgacgcagggcatcaaggcctacgagcccggcctgctggccaaggccaaccgcggcatcctgtatgtggacgaggtgaacctgctggatgatggcctggttgatgtcgtgctggactcgtcggctagcggcctgaacactgtggagcgtgagggtgtgtccattgtgcaccctgcccgcttcatcatgattggctcaggcaacccccaggagggtgagctgcgcccgcagctgctggatcgcttcggcatgagcgtcaacgtggccacgctgcaggacaccaagcagcgcacgcagctggtgctggaccggcttgcgtacgaggcggaccctgacgcatttgtggactcgtgcaaggccgagcagacggcgctcacggacaagctggaggcggcccgccagcgcctgcggtccgtcaagatcagcgaggagctgcagatcctgatctcggacatttgctcgcgcctggatgtggatggcctgcgcggtgacattgtgatcaaccgcgccgccaaggcgcttgtggccttcgagggccgcaccgaggtgaccacgaatgacgtggagcgcgtcatctcgggctgcctcaaccaccgcctgcgcaaggacccgctggaccccattgacaacggcaccaaggtggccatcctgttcaagcgcatgaccgaccccgagatcatgaagcgcgaggaggaggccaagaagaagcgcgaggaggcggccgccaaggccaaggcggagggcaaggcggaccgccccacgggcgccaaggctggcgcctgggctggcttgccccctcgtcggtaa
镁螯合酶亚基1(CHLI2)莱茵衣藻氨基酸序列(SEQ ID NO:24):
MQSLQGQRAFTAVRQGRAGPLRTRLVVRSSVALPSTKAAKKPNFPFVKIQGQEEMKLALLLNVVDPNIGGVLIMGDRGTAKSVAVRALVDMLPDIDVVEGDAFNSSPTDPKFMGPDTLQRFRNGEKLPTVRMRTPLVELPLGATEDRICGTIDIEKALTQGIKAYEPGLLAKANRGILYVDEVNLLDDGLVDVVLDSSASGLNTVEREGVSIVHPARFIMIGSGNPQEGELRPQLLDRFGMSVNVATLQDTKQRTQLVLDRLAYEADPDAFVDSCKAEQTALTDKLEAARQRLRSVKISEELQILISDICSRLDVDGLRGDIVINRAAKALVAFEGRTEVTTNDVERVISGCLNHRLRKDPLDPIDNGTKVAILFKRMTDPEIMKREEEAKKKREEAAAKAKAEGKADRPTGAKAGAWAGLPPRR
镁螯合酶亚基D(CHLD)莱茵衣藻核酸序列(SEQ ID NO:25):
atgaagtctctctgccatgagctcgctggccccagcgttactgggtgcggccggcgaagcctccggaaggctttcagcggtgccaagattgcgcaggtctctcgccccgctgtgcttaacagcgtgcagcgccaacagcgtctcgcctgttctgccgtggccgagctctccgctgctgagctgcgcgccatgaaggtgtctgaggaggactccaagggcttcgatgcggatgtgtcgacccgcctggcccgctcgtaccctctggcggccgtggtgggccaggacaacatcaagcaggcgctgctgctgggcgccgtggacaccgggctgggcggcatcgccatcgccggtcgccgcggtaccgccaagtccatcatggctcgcggcctgcacgctctgctgccgcccattgaggtggtggagggcagcatctgcaacgccgaccccgaggacccccgctcctgggaggctggcctggctgagaagtatgcgggcggccctgtgaagaccaagatgcgctcggcgccgtttgtgcagatccctctgggtgtgactgaggaccgcttggtgggcactgtggacattgaggcgtccatgaaggagggcaagactgtgttccagcccggcctgctggctgaggcgcaccgcggcatcctgtacgtggacgagatcaacctgctggatgacggcattgccaacctgctgctgtccatcctgtcggacggagtcaacgtggtggagcgcgagggcatctccatcagccacccctgccggccgctgctgattgccacctacaaccccgaggagggccctctgcgtgagcacctgctggaccgcatcgccattggcctcagcgccgacgtccccagcaccagcgacgagcgcgtcaaggccattgacgcagccatccgcttccaggacaagccgcaggacactattgacgacaccgcggagctcaccgacgccctgcgcacctcggtcatcctggctcgcgagtacctgaaggacgtgaccatcgcgccggagcaggtgacctacattgtggaggaggcgcgccgcggcggagtccaggggcaccgcgcggagctgtacgcggtcaagtgtgccaaggcgtgtgcggctctggagggccgtgagcgtgtgaacaaggatgacctgcgccaggccgtgcagctggtcatcctgccgcgcgccaccatcctggaccagcccccgcccgagcaggagcagcccccgccgccgcccccgccccctcccccgccgccgccgcaggaccaaatggaggacgaggaccaggaggagaaggaggacgagaaggaggaggaggagaaggagaacgaggaccaggacgagcccgagatccctcaggagttcatgtttgagtccgagggcgtcatcatggacccctccatcctcatgttcgcgcagcagcagcagcgcgcgcagggccgctccggccgcgccaagacgctcatcttcagcgacgaccgcggccgctacatcaagcccatgctgcccaagggtgacaaggtcaagcgcctggcagtggacgccacgcttcgcgccgccgcgccctaccagaagattcgccggcagcaggccatcagcgagggcaaggtgcagcgcaaggtgtacgtggacaagccagacatgcgctccaagaagctggcccgcaaggccggtgcgctggtgatttttgttgtggacgcgtccggctccatggctctgaaccgcatgagcgccgccaagggcgcctgcatgcgcctgctggctgagtcgtacaccagccgcgaccaggtgtgcctcatccccttctacggcgacaaggccgaggtgctgctgccgccctccaagtccatcgccatggcccgccgccgcctggactcgctgccctgcggcggcggctcgccccttgcgcacggcctgtccacggcggtacgtgtgggcatgcaggccagccaggcgggcgaggtgggccgcgtcatgatggtgctcatcacggacggccgcgccaacgtcagcctggccaagtccaacgaggaccccgaggcgctcaagcccgacgcgcccaagcccaccgccgactcgctgaaggacgaggtgcgcgacatggccaagaaggccgcgtccgccggcatcaacgtgcttgtcattgacacggagaacaagttcgtgagcaccggctttgcggaggagatctccaaggcagcgcagggcaagtactactacctgcccaacgccagcgacgccgccatcgcggcggccgcgtccggcgccatggccgcggccaagggcggctactag
镁螯合酶亚基D(CHLD)莱茵衣藻氨基酸序列(SEQ ID NO:26):
MKSLCHELAGPSVTGCGRRSLRKAFSGAKIAQVSRPAVLNSVQRQQRLACSAVAELSAAELRAMKVSEEDSKGFDADVSTRLARSYPLAAVVGQDNIKQALLLGAVDTGLGGIAIAGRRGTAKSIMARGLHALLPPIEVVEGSICNADPEDPRSWEAGLAEKYAGGPVKTKMRSAPFVQIPLGVTEDRLVGTVDIEASMKEGKTVFQPGLLAEAHRGILYVDEINLLDDGIANLLLSILSDGVNVVEREGISISHPCRPLLIATYNPEEGPLREHLLDRIAIGLSADVPSTSDERVKAIDAAIRFQDKPQDTIDDTAELTDALRTSVILAREYLKDVTIAPEQVTYIVEEARRGGVQGHRAELYAVKCAKACAALEGRERVNKDDLRQAVQLVILPRATILDQPPPEQEQPPPPPPPPPPPPPQDQMEDEDQEEKEDEKEEEEKENEDQDEPEIPQEFMFESEGVIMDPSILMFAQQQQRAQGRSGRAKTLIFSDDRGRYIKPMLPKGDKVKRLAVDATLRAAAPYQKIRRQQAISEGKVQRKVYVDKPDMRSKKLARKAGALVIFVVDASGSMALNRMSAAKGACMRLLAESYTSRDQVCLIPFYGDKAEVLLPPSKSIAMARRRLDSLPCGGGSPLAHGLSTAVRVGMQASQAGEVGRVMMVLITDGRANVSLAKSNEDPEALKPDAPKPTADSLKDEVRDMAKKAASAGINVLVIDTENKFVSTGFAEEISKAAQGKYYYLPNASDAAIAAAASGAMAAAKGGY
镁螯合酶亚基H(CHLH1)莱茵衣藻核酸序列(SEQ ID NO:27):
atgcagacttcctcgcttcttggccggcgcacggcccacccggctgcgggcgcgacgcccaagccggttgcgccctcgccccgcgtggctagcacccgccaggtcgcgtgcaatgtggcgactggaccccggccgcccatgaccaccttcaccggtggcaacaagggccctgctaagcagcaggtgtcgctggatctgcgcgacgagggcgctggcatgttcaccagcaccagcccggagatgcgccgtgtcgtccctgacgatgtgaagggtcgcgttaaggtgaaggttgtgtacgtggtgctggaggcccagtaccagtcggccatcagcgctgcggtgaagaacatcaacgccaagaactccaaggtgtgcttcgaggtggtgggctacctgctggaggagctgcgtgaccagaagaacctcgatatgctcaaggaggatgtggcctctgccaacatcttcatcggctcgctcatcttcattgaggagcttgccgagaagattgtggaggcggtgagccccctgcgcgagaagctggacgcgtgcctgatcttcccgtccatgccggcggtcatgaagctgaacaagctgggcacgttttcgatggctcagctgggccagtcgaagtcggtgttctcggagttcatcaagtctgctcgcaagaacaacgacaacttcgaggagggcttgctgaagctggtgcgcaccctgcctaaggtgctgaagtatctgccctcggacaaggcgcaggacgccaagaacttcgtgaacagcctgcagtactggctgggcggtaactcggacaacctggagaacctgctgctgaacaccgtcagcaactacgtgcccgctctgaagggcgtggacttcagcgtggctgagcccaccgcctaccccgatgtgggtatctggcaccctctggcctcgggcatgtacgaggacctgaaggagtacctgaactggtacgacacccgcaaggacatggtcttcgccaaggacgcccccgtcattggcctggtgctgcagcgctcgcacctggtgactggcgatgagggccactacagcggcgtggtcgctgagctggagagccgcggtgctaaggtcatccccgtctttgccggtggcctggacttctccgcccccgtcaagaagttcttctacgaccccctgggctctggccgcacgttcgtggacaccgttgtgtcgctgaccggcttcgcgctggtgggcggccccgcgcgccaggacgcgccgaaggccattgaggcgctgaagaacctgaacgtgccctacctggtgtcgctgccgctggtgttccagaccactgaggagtggctggacagcgagctgggcgtgcaccccgtccaggtggctctgcaggttgccctgcccgagctggatggtgccatggagcccatcgtgttcgctggccgtgactcgaacaccggcaagtcgcactcgctgcccgaccgcatcgcttcgctgtgcgctcgcgccgtgaactgggccaacctgcgcaagaagcgcaacgccgagaagaagctggccgtcaccgtgttcagcttcccccctgacaagggcaacgtcggcactgccgcctacctgaacgtgttcggctccatctaccgcgtgctgaagaacctgcagcgcgagggctacgacgtgggcgccctgccgccctcggaggaggatctgatccagtcggtgctgacccagaaggaggccaagttcaactcgaccgacctgcacatcgcctacaagatgaaggtggacgagtaccagaagctgtgcccttacgccgaggcgctggaggagaactggggcaagccccccggcaccctgaacaccaacggccaggagctgctggtgtacggccgccagtacggcaacgtcttcatcggcgtgcagcccaccttcggctacgagggcgacccgatgcgcctgctgttctcgaagtcggccagcccccaccacggcttcgccgcctactacaccttcctggagaagatcttcaaggccgacgccgtgctgcacttcggcacccacggctcgctggagttcatgcccggcaagcaggtcggcatgtcgggtgtgtgctaccccgactcgctgatcggcaccatccccaacctctactactacgccgccaacaacccgtctgaggccaccatcgccaagcgccgctcgtacgccaacaccatttcgtacctgacgccgcctgccgagaacgccggcctgtacaagggcctgaaggagctgaaggagctgatcagctcgtaccagggcatgcgtgagtctggccgcgccgagcagatctgcgccaccatcattgagaccgccaagctgtgcaacctggaccgcgacgtgaccctgcccgacgctgacgccaaggacctgaccatggacatgcgcgacagcgttgtgggccaggtgtaccgcaagctgatggagattgagtcccgcctgctgccctgcggcctgcacgtggtgggctgcccgcccaccgccgaggaggccgtggccaccctggtcaacatcgctgagctggaccgcccggacaacaacccccccatcaagggcatgcccggcatcctggcccgcgccattggtcgcgacatcgagtcgatttacagcggcaacaacaagggcgtcctggctgacgttgaccagctgcagcgcatcaccgaggcctcccgcacctgcgtgcgcgagttcgtgaaggaccgcaccggcctgaacggccgcatcggcaccaactggatcaccaacctgctcaagttcaccggcttctacgtggacccctgggtgcgcggcctgcagaacggcgagttcgccagcgccaaccgcgaggagctgatcaccctgttcaactacctggagttctgcctgacccaggtggtcaaggacaacgagctgggcgccctggtagaggcgctgaacggccagtacgtcgagcccggccccggcggtgaccccatccgcaaccccaacgtgctgcccaccggcaagaacatccacgccctggaccctcagtcgattcccactcaggccgcgctgaagagcgcccgcctggtggtggaccgcctgctggaccgcgagcgcgacaacaacggcggcaagtaccccgagaccatcgcgctggtgctgtggggcactgacaacatcaagacctacggcgagtcgctggcccaggtcatgatgatggtcggtgtcaagcccgtggccgacgccctgggccgcgtgaacaagctggaggtgatccctctggaggagctgggccgcccccgcgtggacgtggttgtcaactgctcgggtgtgttccgcgacctgttcgtgaaccagatgctgctgctggaccgcgccatcaagctggcggccgagcaggacgagcccgatgagatgaacttcgtgcgcaagcacgccaagcagcaggcggcggagctgggcctgcagagcctgcgcgacgcggccacccgtgtgttctccaacagctcgggctcctactcgtccaacgtcaacctggcggtggagaacagcagctggagcgacgagtcgcagctgcaggagatgtacctgaagcgcaagtcgtacgccttcaactcggaccgccccggcgccggtggcgagatgcagcgcgacgtgttcgagacggccatgaagaccgtggacgtgaccttccagaacctggactcgtccgagatctcgctgaccgatgtgtcgcactacttcgactccgaccccaccaagctggtggcgtcgctgcgcaacgacggccgcacccccaacgcctacatcgccgacaccaccaccgccaacgcgcaggtccgcactctgggtgagaccgtgcgcctggacgcccgcaccaagctgctcaaccccaagtggtacgagggcatgcttgcctcgggctacgagggcgtgcgcgagatccagaagcgcatgaccaacaccatgggctggtcggccacctcgggcatggtggacaactgggtgtacgacgaggccaactcgaccttcatcgaggatgcggccatggccgagcgcctgatgaacaccaaccccaacagcttccgcaagctggtggccaccttcctggaggccaacggccgcggctactgggacgccaagcccgagcagctggagcgcctgcgccagctgtacatggacgtggaggacaagattgagggcgtcgaataa
镁螯合酶亚基H(CHLH1)莱茵衣藻氨基酸序列(SEQ ID NO:28):
MQTSSLLGRRTAHPAAGATPKPVAPSPRVASTRQVACNVATGPRPPMTTFTGGNKGPAKQQVSLDLRDEGAGMFTSTSPEMRRVVPDDVKGRVKVKVVYVVLEAQYQSAISAAVKNINAKNSKVCFEVVGYLLEELRDQKNLDMLKEDVASANIFIGSLIFIEELAEKIVEAVSPLREKLDACLIFPSMPAVMKLNKLGTFSMAQLGQSKSVFSEFIKSARKNNDNFEEGLLKLVRTLPKVLKYLPSDKAQDAKNFVNSLQYWLGGNSDNLENLLLNTVSNYVPALKGVDFSVAEPTAYPDVGIWHPLASGMYEDLKEYLNWYDTRKDMVFAKDAPVIGLVLQRSHLVTGDEGHYSGVVAELESRGAKVIPVFAGGLDFSAPVKKFFYDPLGSGRTFVDTVVSLTGFALVGGPARQDAPKAIEALKNLNVPYLVSLPLVFQTTEEWLDSELGVHPVQVALQVALPELDGAMEPIVFAGRDSNTGKSHSLPDRIASLCARAVNWANLRKKRNAEKKLAVTVFSFPPDKGNVGTAAYLNVFGSIYRVLKNLQREGYDVGALPPSEEDLIQSVLTQKEAKFNSTDLHIAYKMKVDEYQKLCPYAEALEENWGKPPGTLNTNGQELLVYGRQYGNVFIGVQPTFGYEGDPMRLLFSKSASPHHGFAAYYTFLEKIFKADAVLHFGTHGSLEFMPGKQVGMSGVCYPDSLIGTIPNLYYYAANNPSEATIAKRRSYANTISYLTPPAENAGLYKGLKELKELISSYQGMRESGRAEQICATIIETAKLCNLDRDVTLPDADAKDLTMDMRDSVVGQVYRKLMEIESRLLPCGLHVVGCPPTAEEAVATLVNIAELDRPDNNPPIKGMPGILARAIGRDIESIYSGNNKGVLADVDQLQRITEASRTCVREFVKDRTGLNGRIGTNWITNLLKFTGFYVDPWVRGLQNGEFASANREELITLFNYLEFCLTQVVKDNELGALVEALNGQYVEPGPGGDPIRNPNVLPTGKNIHALDPQSIPTQAALKSARLVVDRLLDRERDNNGGKYPETIALVLWGTDNIKTYGESLAQVMMMVGVKPVADALGRVNKLEVIPLEELGRPRVDVVVNCSGVFRDLFVNQMLLLDRAIKLAAEQDEPDEMNFVRKHAKQQAAELGLQSLRDAATRVFSNSSGSYSSNVNLAVENSSWSDESQLQEMYLKRKSYAFNSDRPGAGGEMQRDVFETAMKTVDVTFQNLDSSEISLTDVSHYFDSDPTKLVASLRNDGRTPNAYIADTTTANAQVRTLGETVRLDARTKLLNPKWYEGMLASGYEGVREIQKRMTNTMGWSATSGMVDNWVYDEANSTFIEDAAMAERLMNTNPNSFRKLVATFLEANGRGYWDAKPEQLERLRQLYMDVEDKIEGVE
光叶绿素酸酯(Photochlorophyllide)还原酶亚基B(ch1B)核酸序列(SEQ ID NO:29):
atgaaattagcttattggatgtacgcaggtcccgctcatatcggtgtgttgcgtgttagcagctcttttaaaaatgtacatgccattatgcatgctcctttaggagatgattattttaatgtaatgcgttccatgttagaacgtgaacgtgattttacaccagtaacagccagtattgtagatcgtcatgttttagcaagaggatcgcaagaaaaagtggttgaaaatattacgcgaaaaaataaagaagaaactcctgatttaattttattaactcctacttgtacgtcaagcattttacaagaagatttacacaattttgttgaatcggcattagctaaaccagtacaaatagatgaacatgcagaccataaagtaactcaacaaagtgcactttcaagtgtatcccctttactaccgcttgaagaaaatacattaatagtaagtgaactagataagaagcttagcccgtctagcaagttgcatattaatatgcccaatatttgtattcccgaaggagaaggggaaggggagcagactaaaaattcaatttttgttaaatctgcaactttaacaaatttgtcagaagaggaactattaaatcaagaacatcataccaaaacaagaaatcactctgacgttattttagctgatgtaaaccattatcgtgtaaatgaattacaagctgcagatcgtactcttgaacaaattgtacgttattatatttctcaagcacaaaaacaaaattgtttaaacattactaaaacagccaaaccatctgtaaatattattggtatttttactttgggttttcataatcaacatgattgtcgtgaattaaaacgtttatttaatgatttaggtattcaaatcaatgaaatcatacctgaaggcggaaatgtacacaacttaaaaaaattaccccaagcttggtttaattttgtgccctaccgtgaaattggcttaatgactgctatgtatttaaaatccgagtttaatatgccttacgtcgcaattactcctatgggattaattgatacggctgcttgtattcgttcaatttgtaaaatcattacaactcaattattaaatcagacggctacagtgcaggagccatcaaaatttatttacccgaaggcgacgtcattagaacaaaccaatattctcgaaacctctcaaaaagaaactattcttaaagacaatccagatagcggaaataccctttctacaactgtagaagaaattgaaactttatttaataaatatatcgatcaacaaactcgttttgtttcccaagcagcctggttttcacgttctattgactgtcaaaatttaacaggtaaaaaagccgtagttttcggagatgctacacattcagctgccatgacaaaattattagcacgtgaaatgggtattaaggtttcatgcgctggaacttattgcaaacacgatgcggattggtttagagagcaagttagtgggttttgtgatcaagttttaattaccgatgatcacacacaagtaggggatatgattgcacaattagaacctgcagccatttttgggacacaaatggaacgtcacgttggtaaacgtttagatattccatgtggtgttatatctgctcctgtgcatattcaaaactttccgttaggttatcgaccttttttaggttatgaaggtacaaatcaaatagctgatttagtgtataattcatttaatcttggaatggaagaccatttattacaaatttttggaggtcatgattcagaaaacaattcgtcaattgcaacgcatttgaatacaaataacgcaataaatttagcgccaggatatttacctgagggagaaggcagtagtagaacttcaaatgtagtgtctacaatttctagtgaaaaaaaagccattgtatggtctccagaaggtttagcagaattaaataaagtcccaggatttgttcgaggaaaagttaaacgtaatacggaaaaatatgctttacaaaaaaattgttcgatgattactgtagaagttatgtatgcagcaaaagaagctttgtcggcttaa
光叶绿素酸酯(Photochlorophyllide)还原酶亚基B(ch1B)氨基酸序列(SEQ IDNO:30):
MKLAYWMYAGPAHIGVLRVSSSFKNVHAIMHAPLGDDYFNVMRSMLERERDFTPVTASIVDRHVLARGSQEKVVENITRKNKEETPDLILLTPTCTSSILQEDLHNFVESALAKPVQIDEHADHKVTQQSALSSVSPLLPLEENTLIVSELDKKLSPSSKLHINMPNICIPEGEGEGEQTKNSIFVKSATLTNLSEEELLNQEHHTKTRNHSDVILADVNHYRVNELQAADRTLEQIVRYYISQAQKQNCLNITKTAKPSVNIIGIFTLGFHNQHDCRELKRLFNDLGIQINEIIPEGGNVHNLKKLPQAWFNFVPYREIGLMTAMYLKSEFNMPYVAITPMGLIDTAACIRSICKIITTQLLNQTATVQEPSKFIYPKATSLEQTNILETSQKETILKDNPDSGNTLSTTVEEIETLFNKYIDQQTRFVSQAAWFSRSIDCQNLTGKKAVVFGDATHSAAMTKLLAREMGIKVSCAGTYCKHDADWFREQVSGFCDQVLITDDHTQVGDMIAQLEPAAIFGTQMERHVGKRLDIPCGVISAPVHIQNFPLGYRPFLGYEGTNQIADLVYNSFNLGMEDHLLQIFGGHDSENNSSIATHLNTNNAINLAPGYLPEGEGSSRTSNVVSTISSEKKAIVWSPEGLAELNKVPGFVRGKVKRNTEKYALQKNCSMITVEVMYAAKEALSA
光叶绿素酸酯(Photochlorophyllide)还原酶亚基L(chIL)核酸序列(SEQ ID NO:31):
atgaaattagctgtttacggaaaaggtggtattggaaaatcaacgacaagttgtaatatttcgattgctttacgaaaacgtggtaaaaaagtgttacaaattggttgtgatcctaaacatgatagtacttttacattgacagggtttttaattccaaccattattgatacattaagttctaaagattatcattatgaagatatttggcccgaagatgttatttacggaggttatgggggtgtagattgtgttgaagctggaggaccacctgccggtgcggggtgtggtggttatgttgtaggtgaaacggtaaaacttttaaaagagttaaatgcttttttcgaatacgatgttattttatttgatgttttaggtgatgttgtttgtggtggctttgctgctccattaaactacgctgattattgtattattgtaactgataatggttttgatgctttatttgctgcaaatcgtattgcagcttcagttcgtgaaaaagcacgtacacatccattgcgtttagcgggtttaatcggaaatcgtacatcaaaacgtgatttaattgataaatatgtagaagcttgtcctatgccagtattagaagttttaccattaattgaagaaattcgtatttcacgtgttaaaggcaaaactttatttgaaatgtcaaataaaaataatatgacttcggctcatatggatggctctaaaggtgacaattctacagtaggagtgtcagaaactccatcggaagattatatttgtaatttttatttaaatattgctgatcaattattaacagaaccagaaggagttattccacgtgaattagcagataaagaactttttactcttttatcagatttctatcttaaaatttaa
光叶绿素酸酯(Photochlorophyllide)还原酶亚基L(chIL)氨基酸序列(SEQ IDNO:32):
MKLAVYGKGGIGKSTTSCNISIALRKRGKKVLQIGCDPKHDSTFTLTGFLIPTIIDTLSSKDYHYEDIWPEDVIYGGYGGVDCVEAGGPPAGAGCGGYVVGETVKLLKELNAFFEYDVILFDVLGDVVCGGFAAPLNYADYCIIVTDNGFDALFAANRIAASVREKARTHPLRLAGLIGNRTSKRDLIDKYVEACPMPVLEVLPLIEEIRISRVKGKTLFEMSNKNNMTSAHMDGSKGDNSTVGVSETPSEDYICNFYLNIADQLLTEPEGVIPRELADKELFTLLSDFYLKI
光叶绿素酸酯(Photochlorophyllide)还原酶亚基N(ch1N)核酸序列(SEQ ID NO:33):
atgttagatggtgccacaacgattttaaatttaaatagtttttttgaatgtgaaactggcaattatcatactttttgcccgattagctgtgtagcttggttatatcaaaaaatcgaagatagcttttttttagtaattgggacaaaaacatgtggttattttttacaaaatgcccttggagttatgatttttgccgaacctaggtatgctatggcagaattagaagaaagtgatatttcagcacaattaaacgattataaagaattaaaacgtttatgtttacaaattaaacaagatagaaatcccagcgttattgtttggattggaacttgtacaactgaaattatcaaaatggatttagaagggatggctccacgtttagaaactgaaatcggcatacccattgttgtagcacgtgctaatggtttagattatgcttttacacaaggtgaagacacagttttatcagcaatggccttagcatccttaaaaaaagatgttccttttttagtaggtaatactgggttaacaaacaaccagcttctccttgaaaaatcaacttcttcagttaatgggacagacggaaaggaattacttaaaaaatctcttgtattatttggttccgtaccaagtacagttactacacaattaactttagaattaaaaaaagaaggtattaatgtatctggatggcttccatctgctaattataaagatttacctacttttaataaagatacacttgtatgtggtataaatccttttttaagtcgaacagctaccacgttaatgcgtcgtagtaagtgcacattaatttgtgcaccctttccaataggccccgatggcacaagagtttggattgaaaaaatttgtggtgcttttggcattaatcctagtcttaatccaattactggtaatactaatttatatgatcgtgaacaaaaaattttcaacgggctagaagattatttaaaattattacgtggaaaatctgtattttttatgggtgataatttattagaaatttctttagcacgttttttaacacgttgtggtatgattgtttatgaaatcggaattccatatttagataaacgatttcaagcagcagaattagctttattagaacaaacttgtaaagaaatgaatgtaccaatgccgcgcattgtagaaaaaccagataattattatcaaattcgacgtatacgtgaattaaaacctgatttaacgattactggaatggcacatgcaaatccattagaagctcgaggtattacaacaaaatggtcagttgaatttacttttgctcaaattcatggatttactaatacacgtgaaattttagaattagtaacacagcctcttagacgcaatctaatgtcaaatcaatctgtaaatgctatttcttaa
光叶绿素酸酯(Photochlorophyllide)还原酶亚基N(ch1N)氨基酸序列(SEQ IDNO:34):
MLDGATTILNLNSFFECETGNYHTFCPISCVAWLYQKIEDSFFLVIGTKTCGYFLQNALGVMIFAEPRYAMAELEESDISAQLNDYKELKRLCLQIKQDRNPSVIVWIGTCTTEIIKMDLEGMAPRLETEIGIPIVVARANGLDYAFTQGEDTVLSAMALASLKKDVPFLVGNTGLTNNQLLLEKSTSSVNGTDGKELLKKSLVLFGSVPSTVTTQLTLELKKEGINVSGWLPSANYKDLPTFNKDTLVCGINPFLSRTATTLMRRSKCTLICAPFPIGPDGTRVWIEKICGAFGINPSLNPITGNTNLYDREQKIFNGLEDYLKLLRGKSVFFMGDNLLEISLARFLTRCGMIVYEIGIPYLDKRFQAAELALLEQTCKEMNVPMPRIVEKPDNYYQIRRIRELKPDLTITGMAHANPLEARGITTKWSVEFTFAQIHGFTNTREILELVTQPLRRNLMSNQSVNAIS
胆色素原脱氨酶(PBGD1)核酸序列(SEQ ID NO:35):
atgcagcagtgcgttggccgctccgtccgcgctccgtccagcagggcggtcgcgcccaaggtcgctggcgctcgtgtcagccgccgcgtgtgccgcgtctatgcctccgctgttgctaccaagacggtgaagattggcacgcgcggctcgcccctggctctggcccaggcttacatgactcgcgacctgctgaagaagagcttccctgagctgagcgaggagggtgctctggagatcgtgatcatcaagaccaccggtgacaaaatcctgaaccagcccctggctgacatcggtggcaagggtctgtttaccaaggagatcgatgatgctctgctgagcggcaagattgacatcgccgtgcactccatgaaggacgtgcccacctacctgcccgagggcaccatcctgccctgcaacctgccccgcgaggatgtgcgcgatgtgttcatctcgcctgtcgccaaggacctgagcgagctgcccgccggcgccattgtgggctcggcctcgctgcgccgtcaggcccagatcctggccaagtacccccacctcaaggtggagaacttccgcggcaacgtgcagacccgcctgcgcaagctgaacgagggcgcctgctccgccaccctgctggctctggccggtctgaagcgcctggacatgactgagcacatcaccaagaccctcagcattgacgagatgctgcccgccgtgagccagggcgccattggcattgcctgccgcaccgacgacggcgccagccgcaacctgctggccgccctgaaccacgaggagacccgcatcgccgtggtgtgcgagcgcgccttcctgaccgccctggacggctcttgccgcacccccattgccggctacgcgcacaagggcgccgacggcatgctgcacttcagcggcctggtggccaccccggacggcaagcagatcatgcgcgctagccgcgtggtgcccttcacggaggcggatgccgtcaagtgcggcgaggaggccggcaaggagctcaaggccaacggccccaaggagctgttcatgtactaa
胆色素原脱氨酶(PBGD1)氨基酸序列(SEQ ID NO:36):
MQQCVGRSVRAPSSRAVAPKVAGARVSRRVCRVYASAVATKTVKIGTRGSPLALAQAYMTRDLLKKSFPELSEEGALEIVIIKTTGDKILNQPLADIGGKGLFTKEIDDALLSGKIDIAVHSMKDVPTYLPEGTILPCNLPREDVRDVFISPVAKDLSELPAGAIVGSASLRRQAQILAKYPHLKVENFRGNVQTRLRKLNEGACSATLLALAGLKRLDMTEHITKTLSIDEMLPAVSQGAIGIACRTDDGASRNLLAALNHEETRIAVVCERAFLTALDGSCRTPIAGYAHKGADGMLHFSGLVATPDGKQIMRASRVVPFTEADAVKCGEEAGKELKANGPKELFMY
胆色素原脱氨酶(PBGD2)核酸序列(SEQ ID NO:37):
atgcgatcgtatctgctcaaggctcaagtggcctcatgtcagttttcgcgcacgtcgaaggtctggagactggcgccgggttctgacagacgacggtgtcggggcctcactcggacaccgcactgcgcggcccccaccagcgagcccgccccgccatccagcagcggcaagagcgggcaacgaccactcgtgatagccacgcggccatctaagcttgcaaaggagcagacgcggcaggtgcagcagctgctgctggcggcggcgcagctcaaggacgagcagctgcagctgagcaccctggaactggcgtctaggggcgacacgactcagggtgtgtcgctgcgcagtctgggctcgggcgcattcaccgaggagctggaccaggctgtgctgtcgggcgctgccgacatgtcggtgcacagcctgaaggactgccccgccgccctggcgcccgggctgctgctggccgcctgcctgccgcgggccgacccccgggacgtcctcatcgcgcccgaggccacctcgctgggcgagctggtgccgggcagccgtgtgggcaccagcagcagccgccgcgcggcgcagatcaagcactccttcccccacctgcaggttgtgcagctgcgcggcaatgtggactcgcggctggggcgcatccgcagccgcgacatcggcgccacagtgctggcggcggcgggcctcaagcggctgggtgtgatgaactcggacgagggtgacactaccgctacgggcgccgtgggggtggtgtgcagggcagacgatgagtgggtggtcggcctgctggacgccatctcgcaccgcggcacggccctggaggtggcggcggagcgggcgtgcctggcagcgctgctgggcggcggcggcgcgtgccagcgttcagcgttcccggacattgcgtgggcctgccacacgcggcacgaccccgacagcaacacaatggacctggattgcctggtggcggacctggagggcaaggagctcttcaggtacacggagttctaccggccggtcattgacgaggtggacgcggtgtcgctggggtcgctgtacggcagcctgctgcgcatgatggcgccaccaggcgcggccccctgttggcagctaccttcctcgcggcattag
胆色素原脱氨酶(PBGD2)氨基酸序列(SEQ ID NO:38):
MRSYLLKAQVASCQFSRTSKVWRLAPGSDRRRCRGLTRTPHCAAPTSEPAPPSSSGKSGQRPLVIATRPSKLAKEQTRQVQQLLLAAAQLKDEQLQLSTLELASRGDTTQGVSLRSLGSGAFTEELDQAVLSGAADMSVHSLKDCPAALAPGLLLAACLPRADPRDVLIAPEATSLGELVPGSRVGTSSSRRAAQIKHSFPHLQVVQLRGNVDSRLGRIRSRDIGATVLAAAGLKRLGVMNSDEGDTTATGAVGVVCRADDEWVVGLLDAISHRGTALEVAAERACLAALLGGGGACQRSAFPDIAWACHTRHDPDSNTMDLDCLVADLEGKELFRYTEFYRPVIDEVDAVSLGSLYGSLLRMMAPPGAAPCWQLPSSRH
原卟啉原氧化酶(PPX1)核酸序列(SEQ ID NO:39):
atgatgttgacccagactcctgggaccgccacggcttctagccggcggtcgcagatccgctcggctgcgcacgtctccgccaaggtcgcgcctcggcccacgccattctcggtcgcgagccccgcgaccgctgcgagccccgcgaccgcggcggcccgccgcacactccaccgcactgctgcggcggccactggtgctcccacggcgtccggagccggcgtcgccaagacgctcgacaatgtgtatgacgtgatcgtggtcggtggaggtctctcgggcctggtgaccggccaggccctggcggctcagcacaaaattcagaacttccttgttacggaggctcgcgagcgcgtcggcggcaacattacgtccatgtcgggcgatggctacgtgtgggaggagggcccgaacagcttccagcccaacgatagcatgctgcagattgcggtggactctggctgcgagaaggaccttgtgttcggtgaccccacggctccccgcttcgtgtggtgggagggcaagctgcgccccgtgccctcgggcctggacgccttcaccttcgacctcatgtccatccccggcaagatccgcgccgggctgggcgccatcggcctcatcaacggagccatgccctccttcgaggagagtgtggagcagttcatccgccgcaacctgggcgatgaggtgttcttccgcctgatcgagcccttctgctccggcgtgtacgcgggcgacccctccaagctgtccatgaaggcggccttcaacaggatctggattctggagaagaacggcggcagcctggtgggaggtgccatcaagctgttccaggaacgccagtccaacccggccccgccgcgggacccgcgcctgccgcccaagcccaagggccagacggtgggctcgttccgcaagggcctgaagatgctgccggacgccattgagcgcaacatccccgacaagatccgcgtgaactggaagctggtgtctctgggccgcgaggcggacgggcggtacgggctggtgtacgacacgcccgagggccgtgtcaaggtgtttgcccgcgccgtggctctgaccgcgcccagctacgtggtggcggacctggtcaaggagcaggcgcccgccgccgccgaggccctgggctccttcgactacccgccggtgggcgccgtgacgctgtcgtacccgctgagcgccgtgcgggaggagcgcaaggcctcggacgggtccgtgccgggcttcggtcagctgcacccgcgcacgcagggcatcaccactctgggcaccatctacagctccagcctgttccccggccgcgcgcccgagggccacatgctgctgctcaactacatcggcggcaccaccaaccgcggcatcgtcaaccagaccaccgagcagctggtggagcaggtggacaaggacctgcgcaacatggtcatcaagcccgacgcgcccaagccccgtgtggtgggcgtgcgcgtgtggccgcgcgccatcccgcagttcaacctgggccacctggagcagctggacaaggcgcgcaaggcgctggacgcggcggggctgcagggcgtgcacctggggggcaactacgtcagcggtgtggccctgggcaaggtggtggagcacggctacgagtccgcagccaacctggccaagagcgtgtccaaggccgcagtcaaggcctaa
原卟啉原氧化酶(PPX1)氨基酸序列(SEQ ID NO:40):
MMLTQTPGTATASSRRSQIRSAAHVSAKVAPRPTPFSVASPATAASPATAAARRTLHRTAAAATGAPTASGAGVAKTLDNVYDVIVVGGGLSGLVTGQALAAQHKIQNFLVTEARERVGGNITSMSGDGYVWEEGPNSFQPNDSMLQIAVDSGCEKDLVFGDPTAPRFVWWEGKLRPVPSGLDAFTFDLMSIPGKIRAGLGAIGLINGAMPSFEESVEQFIRRNLGDEVFFRLIEPFCSGVYAGDPSKLSMKAAFNRIWILEKNGGSLVGGAIKLFQERQSNPAPPRDPRLPPKPKGQTVGSFRKGLKMLPDAIERNIPDKIRVNWKLVSLGREADGRYGLVYDTPEGRVKVFARAVALTAPSYVVADLVKEQAPAAAEALGSFDYPPVGAVTLSYPLSAVREERKASDGSVPGFGQLHPRTQGITTLGTIYSSSLFPGRAPEGHMLLLNYIGGTTNRGIVNQTTEQLVEQVDKDLRNMVIKPDAPKPRVVGVRVWPRAIPQFNLGHLEQLDKARKALDAAGLQGVHLGGNYVSGVALGKVVEHGYESAANLAKSVSKAAVKA
尿卟啉原Ⅲ脱羧酶(UROD1)核酸序列(SEQ ID NO:41):
atgcagaccaaggctttcacctctgcgcgcccccagcgggccgctgcgctcaaggcgcagcgcacctcgtcggtgaccgtgcgcgcgaccgcggcccccgccgtggcctctgcccccgccgcctcgggctctgcctctgaccccctgatgctgcgcgccatccgcggcgacaaggtggagcgcccgcccgtgtggatgatgcgccaggccggccgctaccagaaggtgtaccaggacctgtgcaagaagcaccccacgttccgtgagcgctcggagcgcgtggacctggcggtggagatctctctgcagccgtggcacgcgttcaagcccgacggcgtcatcctgttcagcgacattctgacccccctgcccggcatgaacatccccttcgacatggcgcccggccccatcatcatggaccccatccgcaccatggcgcaagtggagaaggtgacgaagctggacgctgaggccgcctgccccttcgtgggcgagtcgctgcgccagctgcgcacctacatcggcaaccaggccgcggtcctgggcttcgtgggcgcccccttcaccctggccacctacattgtggagggcggcagctccaagaacttcgcgcacatcaagaagatggctttctccacccccgagatcctgcacgccctgctggacaagctggctgacaacgtggccgactacgtccgctaccaggccgacgccggcgcccaggtggtgcagatcttcgactcgtgggccagcgagctgcagccccaggacttcgacgtgttctccggcccctacatcaagaaggtgatcgacagcgtgcgcaagacccaccccgacctgcccatcatcctctacatcagcggctctggcggcctgctggagcgcatggcctcttgctcgcccgacatcatctcgctggaccagtcggtggacttcaccgacggcgtcaagcgctgcggcaccaacttcgccttccagggcaacatggaccccggcgtcctgttcggctccaaggacttcatcgagaagcgcgtcatggacaccatcaaggctgcccgcgacgccgacgtgcgccacgtgatgaacctgggccacggcgtgctgcccggcacccccgaggaccacgtgggccactacttccacgtcgcccgcaccgcccacgagcgcatgtaa
尿卟啉原Ⅲ脱羧酶(UROD1)氨基酸序列(SEQ ID NO:42):
MQTKAFTSARPQRAAALKAQRTSSVTVRATAAPAVASAPAASGSASDPLMLRAIRGDKVERPPVWMMRQAGRYQKVYQDLCKKHPTFRERSERVDLAVEISLQPWHAFKPDGVILFSDILTPLPGMNIPFDMAPGPIIMDPIRTMAQVEKVTKLDAEAACPFVGESLRQLRTYIGNQAAVLGFVGAPFTLATYIVEGGSSKNFAHIKKMAFSTPEILHALLDKLADNVADYVRYQADAGAQVVQIFDSWASELQPQDFDVFSGPYIKKVIDSVRKTHPDLPIILYISGSGGLLERMASCSPDIISLDQSVDFTDGVKRCGTNFAFQGNMDPGVLFGSKDFIEKRVMDTIKAARDADVRHVMNLGHGVLPGTPEDHVGHYFHVARTAHERM
尿卟啉原Ⅲ合酶(HEM4)核酸序列(SEQ ID NO:43):
atgtcggccctggacgccgccgccatcccctacgagctagtgccgggtgtgtcctccgctctggccgccccgctgttcgccggcgtcccgctcacacacgtcagcctgagcccctcgttcaccgtggtcagcgggcacgacgtggccggcaccgactgggcggcgttccgggggctgcccacgctggtggttctgatggcgggtcgtaacctggggcagatagcccggcggcttgtgcaggacgcggggtgggcgcccgatacacctgtaagtcaacctagtggctag
尿卟啉原Ⅲ合酶(HEM4)氨基酸序列(SEQ ID NO:44):
MSALDAAAIPYELVPGVSSALAAPLFAGVPLTHVSLSPSFTVVSGHDVAGTDWAAFRGLPTLVVLMAGRNLGQIARRLVQDAGWAPDTPVSQPSG
CHLD 5'非翻译区(调控区)(SEQ ID NO:45):
ggcgtccccacaaccaggacagcctacttcttgaccttattaataagtcgctgcgtgtcgcgactgaccattttggcccggacttgcgtgcttgtgatttgtgcttcgactagatccgcgggcaccaagggacgcggacagctgatagtcaagaactagatcctctgggagcgtctggggctgtccccgctgctcgccaaggaa
CHLD 3'非翻译区(调控区)(SEQ ID NO:46):
gtgccgagtgactgaggtggcaaggtgcagtggcggcggaggcagttgtgctggggtggcaaggcggacaggcgaagctggtgggttgcgacgaggaggaggtgcacgtgcacgcgtaacataagaagaacagtgggaggacaggtagcgtgacttgactgggacgaggagcgtactgatgtgtggcgtgtgttggtatgtgagcgttacccctcccctagatagcggcggtctccactttcaggaggatgagagccatcatgaggctttgagggggcactggttcgtgtgtaggctgaggctgctgttgaagtcacaaggcagcactgcatgcgcgagtgagtgtggccggatatgcatcgagttgcaggtacactgaaatgaggtgactgcggcgtatatcgctgccagtacaggttgaagcggcgggcacggtgaatggagtactcggcctggaacgcttgcgatcagatggtcgagctcaagaagatttggttgagccgttgggtcgtgcgtcatattatggcttgcatcttcggggagcggcaagaaacggactccaatgcaggccctcgggcgagaaagattgggcgtgtccgggggtgcattctcgccgcgtggggctgcatcgaatttcgcttgagtgccccttcccggggagggggggcggtagttcaaccccatcatcgtaggggggttgtaaatgccagcccaaactaaa
CHLD外显子1(SEQ ID NO:47):
atgaagtctctctgccatgagctcgctggccccagcgttactgggtgcggccggcgaagcctccggaaggctttcagcggtgccaagattgcgcaggtctctcgccccgctgtgcttaacagcgtgcagcgccaacagcgtctcgcctgttctgccgtggccgagctctccgctgctgagctgcgcg
CHLD外显子2(SEQ ID NO:48):
ccatgaaggtgtctgaggaggactccaagggcttcgatgcggatgtgtcgacccgcctggcccgctcgtaccctctggcggccgtggtgggccaggacaacatcaagcaggcgctgctgctgggcgccgtggacaccgggctgggcggcatcgccatcgccggtcgccgcggtaccgccaagtccatcatggctcgcggcctgcacgctctgctgccgcccattgaggtggtggagggcagcatctgcaacgccgaccccgaggacccccgctcctgggag
CHLD外显子3(SEQ ID NO:49):
gctggcctggctgagaagtatgcgggcggccctgtgaagaccaagatgcgctcggcgccgtttgtgcagatccctctgggtgtgactgaggaccgcttggtgggcactgtggacattgaggcgtccatgaag
CHLD外显子4(SEQ ID NO:50):
gagggcaagactgtgttccagcccggcctgctggctgaggcgcaccgcggcatcctgtacgtggacgagatcaacctgctggatgacggcattgccaacctgctgctgtccatcctgtcggacggagtcaacgtggtggagcgcgagggcatctccatcagccaccc
CHLD外显子5(SEQ ID NO:51):
ctgccggccgctgctgattgccacctacaaccccgaggagggccctctgcgtgagcacctgctggaccgcatcgccattggcctcagcgccgacgtccccagcaccagcgacgagcgcgtcaaggc cattgacgcagccatccgcttccaggacaagccgcag
CHLD外显子6(SEQ ID NO:52):
gacactattgacgacacc gcggagctcaccgacgccctgcgcacctcg
CHLD外显子7(SEQ ID NO:53):
gtcatcctggctcgcgagtacctgaaggacgtgaccatcgcgccggagcaggtgacctacattgtggaggaggcgcgccgcggcggagtccaggggcaccgcgcggagctgtacgcggtcaag
CHLD外显子8(SEQ ID NO:54):
tgtgccaaggcgtgtgcggctctggagggccgtgagcgtgtgaacaaggatgacctgcgccaggccgtgcagctggtcatcctgccgcgcgccaccatcctggaccagcccccgcccgagcaggagcagcccccgccgccgcccccgccccctcccccgccgccgccgcag
CHLD外显子9(SEQ ID NO:55):
gaccaaatggaggacgaggaccaggaggagaaggaggacgagaaggaggaggaggagaaggagaacgaggaccaggacgagcccgag
CHLD外显子10(SEQ ID NO:56):
atccctcaggagttcatgtttgagtccgagggcgtcatcatggacccctccatcctcatgttcgcgcagcagcagcagcgcgcgcagggccgctccggccgcgccaagacgctcatcttcagcgacgaccgcggccgctacatcaagcccatgctgcccaagggtgacaaggtcaagcgcctggcagtggacgccacgcttcgcgccgccgcgccctaccagaag
CHLD外显子11(SEQ ID NO:57):
attcgccggcagcaggccatcagcgagggcaaggtgcagcgcaaggtgtacgtggacaagccagaca
CHLD外显子12(SEQ ID NO:58):
tgcgctccaagaagctggcccgcaaggccggtgcgctggtgatttttgttgtggacgcgtccggctccatggctctgaaccgcatgagcgccgccaagggcgcctgcatgcgcctgctggctgagtcgtacaccagccgcgaccaggtgtgcctcatccccttctacggcgacaaggccgaggtgctgctgccgccctccaagtccatcgccatggcccgccgccgcctggactcgctgccctgcggcggcggctcgccccttgcgcacggcctgtccacggcggtacgtgtgggcatgcaggccagccaggcgggcgaggtgggccgcgtcatgatggtgctcatcacggacggccgcgccaacgtcagcctggccaagtccaacgaggaccccgaggcgctcaagcccgacgcgcccaagcccaccgccgactcgctgaaggacgaggtgcgcgacatggccaagaaggccgcgtccgccggcatcaacgtgcttgtcattgacacggagaacaagttcgtgagcaccggctttgcggaggagatctccaaggcagcgcagggcaagtactactacctgcccaacgccagcgacgccgccatcgcggcggccgcgtccggcgccatggccgcggccaagggcggctactag
CHLD内含子1(SEQ ID NO:59):
gtgagcgcctactttgatatgtaccaaagataccactgataggtttaggcacggaagatctggacttggaccccgtttgcgcaagccgggcgatgcacccatttcgcggtcacgccgagcgctggggtgcaatttagcgtgcccgacaagctagaaaacagggaattaccatttgtttaattttgttgcgagagatctttgcttgtgtccaccggccgcgcgggggaacttccggtgttgcgcaaggttgcgtgcgtgcccaccatcaacacctgtgccaggtctgtgtcacccccaggttccaccaccctgcaatcttccaattgtgtctcgtttgctcgttgtctaatagtcgtcctttgctcatccctacctgcag
CHLD内含子2(SEQ ID NO:60):
gtgaggcagggaaggtgacacaggaggttttgaaagagagacagggaggcaaagatggatggcggggcgggcagtgactttggggcggcatggagtgggattggtggagtgggattgggcaccatgtatcacagatgttggcaacacagcgcagggccttgctctgtgcttgtgttgaccgtctagtcccccgtgccctgaaccaagtctttcctcctgacacggtcctccatgtcctccttccggcattcccttcctcgtccacag
CHLD内含子3(SEQ ID NO:61):
gtgagccagcaagggaggagaggggaacggccgggtagggcagccggagtttaaccacgccaattcaacggggagcaacggggaagaggaagggccggaagaggacggcaaaagcatttggtgggggcagcggctgtagtcagaagcgcaaaggctgccacagtgtggcccgcaccctcctcaccaccagtttggcatgatcgtttagcatgggctggaatactcaccgccagttctctcctctcccctctcctcccctgtccccgcctgcagCHLD内含子4(SEQ ID NO:62):
gtgagtgcgcgcgctgggtgtgtttgtgggacggcgcggcattggagcgcaggtgcgggtgctgggccgtgcacttgtccgttggttcccttggaagcttcgatacacactcttactgcacgctctttaaccgccccccccctccacctctgcccgccccgtgcag
CHLD内含子5(SEQ ID NO:63):
gtgggtgggggaaagtgactggatgtcggtgggttttaggtatgtgcgtgtgtacgatgcggggagcagtacggaagcgggcacgagcggtgagggggcaggattgtggcgcacgctcgggccaagcccgggctcgcgacagagggtgggcttgtattcgtagtcaagcgcatcaggaagtgcagttgactggattcacctgaaacggcgctgagcgggcggctaatagaatcccgcttcctgtccgcccctccccttgcccttcaatccgtcag
CHLD内含子6(SEQ ID NO:64):
gtgagtggcgggggccgtgcgtttgtttgttgcgtgggctggctggctggctttgttggatgagggcgctgctcaccactcatctctttgaatccccacttatccagttgcctgcatgaaaccccgcctgactcactccccaccatcctgtaccgcttttccaaacatccttgcaaccatcccgccatccccacccgcag
CHLD内含子7(SEQ ID NO:65):
gtgaggagttggagggggaaggggcgaggggatgcgacagaagcgagggcgaggggagccggggtgggttgttgcaagtgtcgtgaattatagaatgaccccaaaagcgccggcccaacagggcctattacttgcgagtcaatccaacccctgatatagggagaatggggtagaggtcgtatcacgacagcaaggatgtacagtgggccttggggttgggaggtacagggaaaaaggagaggacatggggttgggtaagcggggaataacaaatatacacccagcgtttatggaagtgggagatggaaacgggggcggacgaacaggaacaggggccggatggaggggctatgggggcatggtgggtgggggtacggcgcggggcagagcagggtcttgggtgaatgggcaagatgctgatgcttgggatgaagacactatgagcaaagaaatggttgttgacgattgccatgatcatcgcagtgggggaggcggggtggcaataccggcagtcaacagttggggtgcgatcaagattgattggagtaccagcagtggccgggatctggctgacgtgtctcgagcgagttgctggggtggcaaggagatgcaggggcagacgacgttgtgcgaccacacttacacacatttccttccccttgcgtgtgtccgtgcgccctgtgcctccag
CHLD内含子8(SEQ ID NO:66):
gtacgtaaacgtatttgattgctcaggtggttagccttggtgtggctgctgtttgacttgtgcagctgtctttgtgtacatgttccacaaccctgtactccccatattccgcccccattccag
CHLD内含子9(SEQ ID NO:67):
gtgagaggcggcgcggcggcttgcgggcgaaggcggggggcggggcggaggcaatgcggccgcgcatggccagcaacggaagggctggctatcaacacggcgagcgcacgatattcatataagagtgccatcgtgcaatgctgaatacttgcgccaaccggatctcgctgctccgcttccaccggactgctttctcatctctccccttcaccctgtgtgtatccacag
CHLD内含子10(SEQ ID NO:68):
gtgagtgcccgaggtggtgggtggtgaattggggcacgagggtatgtgggcctaagggagctgaatggggcatgttttcttctgagcatcacggtcagagcttgacctgtcctccccgctgtacccccgtgcacggtccgacacag
CHLD内含子11(SEQ ID NO:69):
gtgagtacagcgcatcccggcgcaatcattgggcctagttactgctgcaggactcgtgtgctcttaagggctggcagctgtcagaagctctactcctcgcactgaccactgtgcctttctctccttcctctctccctccccgcacccctcctcccacttcctcaacag
CHLI25’-非翻译区(调控区)(SEQ ID NO:70):
gcagacttccataaagctcttgtaacgctgtaccaactagtaagcggtacaattcgcctgagcccgagcaacgcgacctttcttgctctgtggatctctgataatctaaccagaccaaaaccttttcactaatctaggcaaca
CHLI23’-非翻译区(调控区)(SEQ ID NO:71):
aaaaggctggtgtaggcctgtcgggtcgtgttaaaggttgctgcgtgaacgtgtaagtgtgacagtgtgccggtatgtgtgtgtatacatgtgttgcggtgtgcttttgtggcggtacatggtgatgactgagcgggtgggacagagcacggttaactgacgagggcagtccgtgcgagacggacgtttttgtagccgaggtgcaaggactgatgacgggctaagctgctggagacttggagttgagagtgcaggtggatcgacggtttctctaaggagtatgaataggcaggagggctggagacatttggggtgcaaggaggcggtagtatgggagatgtccatgggcggattttggcctctgtaacttcttaacgccca
CHLI2外显子1(SEQ ID NO:72):
atgcagagtctccagggtcagcgcgcgttcactgcggtgcgccagggtcgggcgggtcccctgcggactcgcctggtcgtgcgctcgtctgttgccttgccatccacgaaagccgcgaagaagccgaacttcccgttcgtcaagattcagggccaggaggagatgaagcttgcactgctgctgaacgtggtcgaccccaacatcggcggagtgcttattatgggtgaccgcggcactgccaagtcggtcgcg
CHLI2外显子2(SEQ ID NO:73):
gtccgcgccctggtggatatgcttcccgacattgacgtggttgagggcgacgccttcaacagctcccccaccgaccccaagttcatgggccccgacaccctgcagcgcttccgcaacggcgagaagctgcccaccgtccgcatgcggacccccctg
CHLI2外显子3(SEQ ID NO:74):
gtggagctgcctctgggcgccaccgaggaccgcatctgcggcaccatcgacatcgagaaggcgctgacgcagggcatcaaggcctacgagcccggcctgctg
CHLI2外显子4(SEQ ID NO:75):
gccaaggccaaccgcggcatcctgtatgtggacgaggtgaacctgctggatgatggcctg
CHLI2外显子5(SEQ ID NO:76):
gttgatgtcgtgctggactcgtcggctagcggcctgaacactgtggagcgtgagggtgtgtccattgtgcaccctgcccgcttcatcatgattggctcaggcaacccccag
CHLI2外显子6(SEQ ID NO:77):
gagggtgagctgcgcccgcagctgctggatcgcttcggcatgagcgtcaacgtggccacgctgcaggacaccaagcagcgcacgcagctggtgctggaccg
CHLI2外显子7(SEQ ID NO:78):
gcttgcgtacgaggcggaccctgacgcatttgtggactcgtgcaaggccgagcagacggcgctcacggacaagctggaggcggcccgccagcgcctgcggtccgtcaagatcagcgaggagctgcag
CHLI2外显子8(SEQ ID NO:79):
atcctgatctcggacatttgctcgcgcctggatgtggatggcctgcgcggtgacattgtgatcaaccgcgccgccaaggcgcttgtggccttcgagggccgcaccgaggtgaccacgaatgacgtggagcgcgtcatctcgggctgcctcaaccaccg
CHLI2外显子9(SEQ ID NO:80):
cctgcgcaaggacccgctggaccccattgacaacggcaccaaggtggccatcctgttcaagcgcatgaccgaccccgagatcatgaagcgcgaggaggaggccaagaagaagcgcgaggaggcggccgccaaggccaaggcggagggcaaggcggaccgccccacgggcgccaaggctggcgcctgggctggcttgccccctcgtcggtaa
CHLI2内含子1(SEQ ID NO:81):
gtaggtaacacaagcaattatggggcgaagatctaggctccgctgatccgggcgggcaatcggcatcgtcggtgcaaccgtggggcgtctgtgcaccctttgctggtgccaggttgcctgactcgcctgcattcctgtaccgagccacattggctgctttgcagcgtgcatgggacgggtgtaggataagcgctatgtatgcgatagcgcgggtgcaccggcttggcatggcaaggttgcggggtgcacatgcgtgccagcgtcccctcagcatcagagtctggatctaagggctcagcggcttcctgcgcatgtgggtctttgcgtagtgctacgaagccttataattaaagctcatgtattgagtggtccgggtttggggcactagtagtgccaggaggcgcgtgccaggttgatatgagcatatcagcacccgttccttgcgaaacgcttccgttgtgctcccttccccaccacctccccgctcatacccatacatatggctatccgtcctctcattgcttgcccctacag
CHLI2内含子2(SEQ ID NO:82):
gtgagcgggcctaccttctgaagacagtcttacgtgttgcactgcagcggtgttgcgcacctctgcttttgcgtgcgccgggaagcgcggattgcggcctcacagatcaagcccggaaacgcttgttgtttccagcgggtggcacacacgcgcgcgcgcgcacagtgacaccctcacggccgcgctgccctgcag
CHLI2内含子3(SEQ ID NO:83):
gtgcgtagtgcatggggagaggggacgaggggaggagggcagggccaataaaccgaaccccaagtcatcgagacacagaacccgataatagctcccagatcgccaaggggtgaggcgggaagccaaggatgatgcgttggccgcattgcgtgttgacgtcaggcttacacagggtctgactggctgtgcttggggtttggcacgcttcttgactggccccgtacgcatgctgcag
CHLI2内含子4(SEQ ID NO:84):
gtgagtggtggtggtttctgggtcagcagaggacttctgtagtaggtaatgtgggccagggaagtgtggctaacatgccaaacacgggggcgcaccagtgcaagctgcattcgctgacgtgcacgggtgcaatgggtgcaaggcgaactgcaatcgcggtgcacagttgccagggctgcgctcacgcttgagtgtctgcacacgcactgcag
CHLI2内含子5(SEQ ID NO:85):
gtgcgtagcgtgcgcgcatgtacttgtctcccttgtcatgttgggaaaggtcggtccccagcctgcttgcaagatgcggccggtcagcagctgcggacggtcagcacctacgtgccgaggttgtgtaacatgaatggcgttggggcggccgacctgccacaagctgaactgcgaccagcaaggcagctgccagcaacgcacacccgacgtgctacacgcttgtgttttgacctcctaaacacacccgcccgctgtctgtcacgtccacag
CHLI2内含子6(SEQ ID NO:86):
gtaagcggcggcggcgcggggacacggagggacatttcgcgagcatgggttgaggagtcgggaggattcggtggctggccggagtcgggagtcggagtcgcgagtcggaagtcaagcttctggcggcttcgtgctgtcgggtgcgctcgccatgatggcgctgaccggagggcgtcacgctgtgtatgtgggcgcgcag
CHLI2内含子7(SEQ ID NO:87):
gtacggggcgtacagcgggggcggctgcacggggccagtgaccgacagggcagcacgcggctggcgaagagcgacaaagtgacagggtgaccaagaccgggtgatgccacgagaggggcgcgggagccgtgcattgggtcgaggagggaggaatgcaactttacactgatgcctctgtatacggccgccttccgagccctgcaaaccttcgctttcccccgacgcacgcag
CHLI2内含子8(SEQ ID NO:88):
gtgagcgcagcgtgcggtggatgcggtgcgcgtgcgggttgccaacttattattttgtacgtggacgcgtggctggcgatggcatgtcatggcgcgaatggatattgggcgaatggataccggtaatggtagcacggggcggcagggcctggcggtagtggggttgagggggcgaggactccagcgcgcgatacatgccatgttcagcatggccccaactgacagcgcccgctgccctgtgcgccccgctccctccgcgcacccgctcctcctacacag
CHLH15’-非翻译区(调控区)(SEQ ID NO:89):ctagtctagagggaactagggaggggcaacagagaa
CHLH13’-非翻译区(调控区)(SEQ ID NO:90):
gcggcctccccttcatggtagcactagttggcgggttgtggttggactaggcggctagggtatatacctagtagcggcggctgcggagtggagggctggcgcccagcgcgagggcgtggcctttcctcctggacccgagagcgctccgcgaggagacggcgagtgagataggcagcagcgagcggagatcgatttgtgaacagttttgtggcgggatcccatagcggatgcagagaagaccttagagcagcttcctcggtggagtgaacgagccagagcggagggaaggcgcatgagggaactgcagggactggaactgcgggagtgcaggtccggtgctaggtccgctaaacagtgcggtctacgcctgtgtgtgaggtgtgcgtgtgtgtgtgagctgtgcggttttgttgtgcaaagtaggagtgagccgagccgcgcgtactttgtggcgtgtttggctgctggcgctgagagccaagagagggtaaacgggtttggtattttatggtgcggggtgaaagcagccctcgcaggaatggagcgattctgcagcatgatgcacgtgtgcctgcgcgtggatggtggctgttgatatggctctgccactccggcagcaccgctacgatacctagcggtgcctggagtggtctctctgtttggtgcgtgatgtttgggtttgccgttttgattctttgtttcgtgctgaatggctgaggcggcaagacccctcgtgccagtgtacagagcctcacggctccctcggaccccgcgtggggacgtccattcccggtggcggtgtcgcctcggcggtgtaaagcaaaaaatatttt
CHLH1外显子1(SEQ ID NO:91):
atgcagacttcctcgcttcttggccggcgcacggcccacccggctgcgggcgcgacgcccaagccg
CHLH1外显子2(SEQ ID NO:92):
gttgcgccctcgccccgcgtggctagcacccgccag
CHLH1外显子3(SEQ ID NO:93):
gtcgcgtgcaatgtggcgactggaccccggccgcccatgaccaccttcaccggtggcaacaagggccctgctaagcagcaggtgtcgctggatctgcgcgacgagg
CHLH1外显子4(SEQ ID NO:94):
gcgctggcatgttcaccagcaccagcccggagatgcgccgtgtcgtccctgacgatgtgaagggtcgcgttaaggtgaaggttgtgtacgtggtgctggaggcccagtaccagtcggccatcagcgctgcggtgaagaacatcaacgccaagaactccaag
CHLH1外显子5(SEQ ID NO:95):
gtgtgcttcgaggtggtgggctacctgctggaggagctgcgtgaccagaagaacctcgatatgctcaaggaggatgtggcctctgccaacatcttcatcggctcgctcatcttcattgaggagcttgccgagaag
CHLH1外显子6(SEQ ID NO:96):
attgtggaggcggtgagccccctgcgcgagaagctggacgcgtgcctgatcttcccgtccatgccggcggtcatgaagctgaacaagctgggcacgttttcgatggctcagctgggccagtcgaagtcggtgttctcggagttcatcaagtctgctcgcaag
CHLH1外显子7(SEQ ID NO:97):
aacaacgacaacttcgaggagggcttgctgaagctggtgcgcaccctgcctaaggtgctgaagtatctgccctcggacaaggcgcaggacgccaagaacttcgtgaacagcctgcagtactggctgggcggtaactcggacaacctggagaacctgctgctgaacaccgtcagcaactacgtgcccgctctgaagggcgtggacttcagcgtggctgagcccaccgcctaccccgatgtgggtatctggcaccctctggcctcgggcatgtacgaggacctgaaggagtacctgaactg
CHLH1外显子8(SEQ ID NO:98):
gtacgacacccgcaaggacatggtcttcgccaaggacgcccccgtcattggcctggtgctgcagcgctcgcacctggtgactggcgatgagggccactacagcggcgtggtcgctgagctggagagccgcggtgctaaggtcatccccgtctttgccg
CHLH1外显子9(SEQ ID NO:99):
gtggcctggacttctccgcccccgtcaagaagttcttctacgaccccctgggctctggccgcacgttcgtggacaccgttgtgtcgctgaccggcttcgcgctggtgggcggccccgcgcgccaggacgcgccgaaggccattgaggcgctgaagaacctgaacgtgccctacctggtgtcgctgccgctggtgttccagaccactgaggagtggctggacagcgagctgggcgtgcaccccgtccaggtggctctgcag
CHLH1外显子10(SEQ ID NO:100):
gttgccctgcccgagctggatggtgccatggagcccatcgtgttcgctggccgtgactcgaacaccggcaagtcgcactcgctgcccgaccgcatcgcttcgctgtgcgctcgcgccgtgaactgggccaacctgcgcaagaagcgcaacgccgagaagaagctggccgtcaccgtgttcagcttcccccctgacaagggcaacgtcggcactgccgcctacctgaacgtgttcggctccatctaccgcgtgctgaagaacctgcagcgcgagggctacgacgtgggcgccctgccgccctcggaggaggatctgatccagtcggtgctgacccagaaggaggccaagttcaactcgaccgacctgcacatcgcctacaagatgaaggtggacgagtaccagaagctgtgcccttacgccgaggcgctggaggagaactggggcaagccccccggcaccctgaacaccaacggccaggagctgctggtgtacggccgccagtacggcaacgtcttcatcggcgtgcagcccaccttcggctacgagggcgacccgatgcgcctgctgttctcgaagtcggccagcccccaccacggcttcgccgcctactacaccttcctggagaagatcttcaaggccgacgccgtgctgcacttcggcacccacggctcgctggagttcatgcccggcaagcaggtcggcatgtcgggtgtgtgctaccccgactcgctgatcggcaccatccccaacctctactactacgccgccaacaacccgtctgaggccaccatcgccaagcgccgctcgtacgccaacaccatttcgtacctgacgccgcctgccgagaacgccggcctgtacaagggcctgaaggagctgaaggagctgatcagctcgtaccagggcatgcgtgagtctggccgcgccgagcagatctgcgccaccatcattgagaccgccaagctgtgcaacctggaccgcgacgtgaccctgcccgacgctgacgccaaggacctgaccatggacatgcgcgacagcgttgtgggccaggtgtaccgcaagctgatggagattgagtcccgcctgctgccctgcggcctgcacgtggtgggctgcccgcccaccgccgaggaggccgtggccaccctggtcaacatcgctgagctggaccgcccggacaacaacccccccatcaagggcatgcccggcatcctggcccgcgccattggtcgcgacatcgagtcgatttacagcggcaacaacaagggcgtcctggctgacgttgaccagctgcagcgcatcaccgaggcctcccgcacctgcgtgcgcgagttcgtgaaggaccgcaccggcctgaacggccgcatcggcaccaactggatcaccaacctgctcaagttcaccggcttctacgtggacccctgggtgcgcggcctgcagaacggcgagttcgccagcgccaaccgcgaggagctgatcaccctgttcaactacctggagttctgcctgacccag
CHLH1外显子11(SEQ ID NO:101):
gtggtcaaggacaacgagctgggcgccctggtagaggcgctgaacggccagtacgtcgagcccggccccggcggtgaccccatccgcaaccccaacgtgctgcccaccggcaagaacatccacgccctggaccctcagtcgattcccactcaggccgcgctgaagagcgcccgcctggtggtggaccgcctgctggaccgcgagcgcgacaacaacggcggcaagtaccccgagaccatcgcgctggtgctgtggggcactgacaacatcaagacctacggcgagtcgctggcccaggtcatgatgatggtcggtgtcaagcccgtggccgacgccctgggccgcgtgaacaagctggaggtgatccctctggaggagctgggccgcccccgcgtggacgtggttgtcaactgctcgggtgtgttccgcgacctgttcgtgaaccagatgctgctgctggaccgcgccatcaagctggcggccgagcaggacgagcccgatgagatgaacttcgtgcgcaagcacgccaagcagcaggcggcggagctgggcctgcagagcctgcgcgacgcggccacccgtgtgttctccaacagctcgggctcctactcgtccaacgtcaacctggcggtggagaacagcagctggagcgacgagtcgcagctgcaggagatgtacctgaagcgcaagtcgtacgccttcaactcggaccg
CHLH1外显子12(SEQ ID NO:102):
ccccggcgccggtggcgagatgcagcgcgacgtgttcgagacggccatgaagaccgtggacgtgaccttccagaacctggactcgtccgagatctcgctgaccgatgtgtcgcactacttcgactccgaccccaccaagctggtggcgtcgctgcgcaacgacggccgcacccccaacgcctacatcgccgacaccaccaccgccaacgcgcaggtccgcactctgggtgagaccgtgcgcctggacgcccgcaccaagctgctcaaccccaagtggtacgagggcatgcttgcctcgggctacgagggcgtgcgcgagatccagaagcgcatgaccaacaccatgggctggtcggccacctcgggcatggtggacaactgggtgtacgacgaggccaactcgaccttcatcgaggatgcggccatggccgagcgcctgatgaacaccaaccccaacagcttccgcaagctggtggccaccttcctggaggccaacggccgcggctactgggacgccaagcccgagcagctggagcgcctgcgccagctgtacatggacgtggaggacaagattgagggcgtcgaataa
CHLH1内含子1(SEQ ID NO:103):
gtaggtgtaattagaaggatcaaaacctagcggcctgatctgggactgacggcctcgcgcttcaatcactctgatgcag
CHLH1内含子2(SEQ ID NO:104):
gtaggcacggcagaatgctcaatgaacatgcagctacatatgtttgggatcatggctgatctctgtgcgacgggtccgcgcag
CHLH1内含子3(SEQ ID NO:105):
gtgagcagcgcggaccgagcaagcgctggcgatgcagttggatttgttgttcttgggtcaggcgctcgctcgatggccagcgcgtgtatttaatgggataagggttgagacaaagcatctcttcgggtaaaaatcttagttttcgacagcacgttgagaggcatgcaacttgctctttcgcag
CHLH1内含子4(SEQ ID NO:106):
gtgggtaaggagttgcattatcagtgtggcatggtgttgcgggcgtctggggcgctgcaacagcggcatcgtgccgaactgaccgtgccgggctacccgcgtgcag
CHLH1内含子5(SEQ ID NO:107):
gtgcgctagggttggggtctggagggtgtggattgcgcccaagtgccctgttgcgcttggcggtcgctgtcatgatgtgagggtgacgtagtgcactcaattgcctgctacgtcaccacctttgatgggctggatctgaggcaggtcagctcggttccctgctgcatccagtgtccctgtcgccctgcacgtttgacgctgttcccccttccgcactgtctcgctttgcag
CHLH1内含子6(SEQ ID NO:108):
gtgtgggcacgcgctttgggaagggaggcatacatttttggttgcggttaggctgggcgcggacttggcactcacacggtcattgcacactcatgtctcaccttcatttacggtcccttgtgccgaactacctacag
CHLH1内含子7(SEQ ID NO:109):
gtgagcagcatcagggcagagtgcatgaacggattggtggcagtggggaatggaattagacggacacgtctgggcggcaatatgttgcgctgcagtttttggggtgtagtgaactagaaaatagggaagagataggccacataacatccgaaagctcatatttttgcaaccggcgcacctatcacagcccacctgaagggttttgtagtcaacgcgtgcaactgactagatgtccccttacctgtctgatttcag
CHLH1内含子8(SEQ ID NO:110):gtgaggcggggcggcgctgccctcggtaggggttgcagatggtgatgggtaaccgaatgcatggccaatggggagtgaaatcaggaaaggaggggtaacacaatgcagggcagcacctgaatcgtgaaggcggagttaggcagggatctgtcagttcgcctgtcacgtggatgggcgcagctgacctttgtggtgttgtggtgtggcgcag
CHLH1内含子9(SEQ ID NO:111):
gtgagctcagctgggacatgtaggggctcgggtcgccggagcatcgatgtagaattacgggaggaggggagaggggagaggattgcacgaaccgagatgagggcggtggttcgggatttcgggcaaaagctcgtgcggcaagcgttcagtgactgaagagcagtgtgcttcaactgcccctctgtccctcag
CHLH1内含子10(SEQ ID NO:112):
gtgcgaccggtgccgctgcgtggccaacagcttggtgccaccttcctgcggtgttgatttacactgtgtgcgtggatgtgttggtttttcgcaactttagtctgggctccagctctttgccttcattgatcactcgtcttacctcctgcgccatcatttgaatacag
CHLH1内含子11(SEQ ID NO:113):
gtgagccttaatgcaacacgtgtagccgttcgcatgggtggctgggtcatgctatggttggatcggcgtccgcctgcttgctactgcctgttcggtaccagcgtttactgaccccgcgtgtgccattcccaccacctaccccctcgccttgcag
铁螯合酶5’-非翻译区(调控区)(SEQ ID NO:114):
gacagtgatatagcaataccgatataataggtttggcgggcttcaccttgtccttacccagaatgtggccctgacagtcgatttccagcccccttgccactcgctccctgatttcttcaatcaactagttgggtcgttttctcgtaagg
铁螯合酶3’-非翻译区(调控区)(SEQ ID NO:115):
gggggcgggtggcgagtaaggcgtatggcggagcgaggagatgggctgtggcgtggccggtgttcttttgtgtgattggaaacatagacggggtgcggcacgcggcctgactgctgcgcggttggtgtggttgcggggggagcggggtcgatggggcagcgcgcacgagttggttgaaggaggagggccaggcgctgggctacacccatggtttgaggatgctagtgagtgatgtgtgcggggggcatggtgtgtaccattcagagtccagatgcacgcacggttgcgtgggagcgttccctgctgtgcatgatgatggcgccttcgatgaatcatctcttgaaggtccaaatgaaacgtctgaagtctgcagagggtggtgctggacatgccatccaggcggaagtgggcagctgtgtctgactacaaagtaggtcttgttttgcttggatagcgtttggctatgtagcgtgtattctgctcatcaatcacgccaggcgtcagggactacccatgcaagtcgggagcgtggctggctctggaaaagttgtagctgctaggtggcgttggctggggtgtcatgcatctcggcaggtaggcggtagcggtggacgacctctgcagcggagcatgtgcacaagatgtgactgcgcatgcacccgtatatgacggcgttggcgtcagttgttgagagtgaacagaggagagacgagcgaagctgccatgcccttagtggctggtgcgagaggggaagaaagagagaggaaggactttgcggcagtgccccacgccggagttggggacacggtcatcaacagggcggcggagctgggcggagtgggtgtgtgatgggacagggttcaaggcaggttggcgaggtcggagtgggtagaccagtccttcagtgcaagggcattagggcatgatgtaagggctgaagcttg
铁螯合酶外显子1(SEQ ID NO:116):
atggcgtcgtttggattgatgcaaaggacggtgcactgtccccagcttgtggaggagcggtgttcgccggtcgctggctgctctggtcgtggcctgccagttatccagcggcaacg
铁螯合酶外显子2(SEQ ID NO:117):gcgtggcgtgtgcagtgccaccaacggtgtccagcgagggcgtgtgctgcgccggacggccgcttcgaccgacgtggtctccttcgtggaccccaatgacattagaaaacccgcagcagcagcagctggccctgcggtggataaggtcggcgttctgctgttaaaccttggcgggcccgaaaagctcgacgacgtcaagcctttcctgtataacctattcgccgacccagaaattattcgcctgccagcggcagctcagttcctgcagccgctgctcgcgacgatcatctccacgcttcgcgccccgaagagcgcggagggctatgaggccattggcggtggtagcccgttgcgtaggattacagacgagcaggcggaggcgctggcggagtctctgcgcgccaagggccaacctgcgaacgtgtacgtgggcatgcgctattggcacccctacacggaggaggcgctggagcacattaaggccgacggcgtcacgcgcctggtcatcctcccgctgtaccctcagttctccatctctaccagcggctccagccttcgactgcttgagtcgctcttcaagagcgacatcgcgctcaagtcgctgcggcacacggtcatcccgtcctggtaccagcggcggggctacgtgagcgcgatggcggacctgattgtagag
铁螯合酶外显子3(SEQ ID NO:118):
gagctgaagaagttccgggacgtgcccagcgtggagctgtttttctccgcgcacggcgtgcccaagtcctacgtggaggaggcgggcgacccatacaaggaggagatggaggagtgcgtgcggctcattacggacgag
铁螯合酶外显子4(SEQ ID NO:119):
gtcaagcggcgcggcttcgccaacacgcacacgctggcctaccagagccgcgtgggccccgcggaatggctcaagccgtacacggatgagtccatcaa
铁螯合酶外显子5(SEQ ID NO:120):
ggagctgggcaagcgcggcgtcaagtcgctgctggcggtgcccatcagctttgtcagcgagcacattgagacgttggaggagatcgacatggagtaccgcgagctggcggaggagagcg
铁螯合酶外显子6(SEQ ID NO:121):
gcatccgcaactggggccgcgtgccggcgctgaacaccaacgccgccttcatcgacgacctggcggacgcggtgatggaggcgctgccctacgtgggctgcctggccgggccgacagactcgctggtgccgctgg
铁螯合酶外显子7(SEQ ID NO:122):
gcgacctggagatgctgctgcaggcctacgaccgcgagcgccgcacgctgccgtcaccggtggtgatgtgggagtggggctggaccaagagcgcggagacgtggaacggccgcattgccatgattgccatcatcatcatcctggcgctggaggcagccagcggccagtccatcctcaaaaacctgttcctggcggagtag
铁螯合酶内含子1(SEQ ID NO:123):
gtgcgataataaatttgcatccttatgaattgctcaatgactaacgagcagcgtccgcgaccacag
铁螯合酶内含子2(SEQ ID NO:124):
gtgagggtggcattctgtaaagggagttgtggagttgggcagagcgagtgggtttggtcgccagggcgaggatgttgcgcgggcgttggcaggaacagggctgctagggcttgcgtggccagcgactagggtttcgactggccagcgccgccggggcgcgcttgccgaagctgcacagccccaagcgcttctgtggatcaaatggaaacttgtggcagtgtgtatgctagcgccttggcgcaagaccaattttagtggtattactgttattactgtggtagcggtgggtattcggcggcgtggttgttgttgcagccccgtgcgactaagaccgctggcaacgacagcaagccgccgcacccaggcatatacggcccaccagcaccaccgtacacaaccacgtgcctttgcactctacgcaccacagcgcgctgctgccgctcccacctcccatcccaacggcccctcttacccccacttcacaacccctcctctcacacgccctcctcttccccctcctcttccag
铁螯合酶内含子3(SEQ ID NO:125):
gtgggccgggcgcagcgggcgggcgggaggggcaggaggggcaggaggggaggaagggaggggaggaagggatggaaagctggcgcagcggcagcggcgggacaggtagagggcgctgccccagcggcggcaggtgggcatggtgggcgggtaggggcgacgcgtgagggactcgtcaggcatccgcatggcggcgacttgctgctcctcaccgctgacggctgcatctgctgtgtgcgtaacctggcctggctggcaccgcag
铁螯合酶内含子4(SEQ ID NO:126):
gtgaggcccgtgggtgggacgcggggagggacgcggggagggggagacgcgggagcgggacaagggtgaggatacggggagggaataggagaggccatggggagggatggggacacgggaggatgcacgggcctgggtggagccagggggaagtggacgacgagcccggcgggaggagggctgggtagaaggacgcgggaggtggttgggacaggtggacggggcgtgtggagcatacggcgcaagaagcgggactgagcgggttgcagggatggatgtaatcacggcaagtaagaaccccgagtggggctcagcgtgtcagcctgccttatctttcgcgcaagcgctggggttttatttcgctgtacacacgtcgcgcctttctgccgcag
铁螯合酶内含子5(SEQ ID NO:127):
gtgaggaggcgccggagttttgggggaaggggtgcggcgtgaagcgagatggcaggggcgaaggaaggagcggatggtggctgggtgcaagcggagaggcgacagagagtggaggttttggtggagcggttggggagaggggcgcagcagggatgcggccctggggatggcgggacagaagggagcaagtttgccaagtgaagggggggggtgctcaagaggagagggcggtggaggttaagacggccgtgctggttatgctggggttgcaaggcgcatgggcgcatggagccgggggagtttggctgtggatgggcactgcggatgggcacggcttgctactcatgtgcggtcgcggtccgcggtgtgtcagccagccaggacccatcccactgggtcttcctgcgtgcctgggactgcttgccgccacccacccattcatcaccaccactgcgcagacccaccaacaccgctgccctgaactgctctgactcttggcgctcctcag
铁螯合酶内含子6(SEQ ID NO:128):
gtgagtcgcgccgtcgcggttggttcgcggatgccggttggcggatgacgttcggcggttggcattgggtttgggtttgaggggttgttgggtgaggtcgggattggggtcgggattgggggtcgagcgtggggctggcgtggatgatggcgtggtctttggaaggggcttggggaggttgcgcgtgtggatgcggacagcatgggcgcgacagtgcgcatgtgcatgtgctgtgtcaaacgtctggtgcgttcagtgtgtccttgcgtgcctcccaccgtacgcagccatcccgcgcgcctggaccgtagagaccgcctacgtgtccgctagcggcctcggcctcagcctaagcgccagtagcgccagcgacacaagcaacactgtcgctaatggcagcagcggcagcagcagcagtcacgagaatgcccgcggccgggagaaagtgctcctagccgggggccgccgctagctggtttcctcagcgcgtggacggtggtgccttcatcccgaccaccccaggcgcgtccccagtcccgtcgagctcgcctgccttgtggcccgccttgaccgccctggcgccacccggtggctcgcataacgactcgctttccgttctccgcctgacgctgtccgcctgacgctctgcgcttgactctttgcgccttcctcccctcttcccccag
突变序列红藻CHLH DNA(SEQ ID NO:129):
atgcagacttcctcgcttcttggccggcgcacggcccacccggctgcgggcgcgacgcccaagccggttgcgccctcgccccgcgtggctagcacccgccaggtcgcgtgcaatgtggcgactggaccccggccgcccatgaccaccttcaccggtggcaacaagggccctgctaagcagcaggtgtcgctggatctgcgcgacgagggcgctggcatgttcaccagcaccagcccggagatgcgccgtgtcgtccctgacgatgtgaagggtcgcgttaaggtgaaggttgtgtacgtggtgctggaggcccagtaccagtcggccatcagcgctgcggtgaagaacatcaacgccaagaactccaaggtgtgcttcgaggtggtgggctacctgctggaggagctgcgtgaccagaagaacctcgatatgctcaaggaggatgtggcctctgccaacatcttcatcggctcgctcatcttcattgaggagcttgccgagaagattgtggaggcggtgagccccctgcgcgagaagctggacgcgtgcctgatcttcccgtccatgccggcggtcatgaagctgaacaagctgggcacgttttcgatggctcagctgggccagtcgaagtcggtgttctcggagttcatcaagtctgctcgcaagaacaacgacaacttcgaggagggcttgctgaagctggtgcgcaccctgcctaaggtgctgaagtatctgccctcggacaaggcgcaggacgccaagaacttcgtgaacagcctgcagtactggctgggcggtaactcggacaacctggagaacctgctgctgaacaccgtcagcaactacgtgcccgctctgaagggcgtggacttcagcgtggctgagcccaccgcctaccccgatgtgggtatctggcaccctctggcctcgggcatgtacgaggacctgaaggagtacctgaactggtacgacacccgcaaggacatggtcttcgccaaggacgcccccgtcattggcctggtgctgcagcgctcgcacctggtgactggcgatgagggccactacagcggcgtggtcgctgagctggagagccgcggtgctaaggtcatccccgtctttgccggtggcctggacttctccgcccccgtcaagaagttcttctacgaccccctgggctctggccgcacgttcgtggacaccgttgtgtcgctgaccggcttcgcgctggtgggcggccccgcgcgccaggacgcgccgaaggccattgaggcgctgaagaacctgaacgtgccctacctggtgtcgctgccgctggtgttccagaccactgaggagtggctggacagcgagctgggcgtgcaccccgtccaggtggctctgcaggttgccctgcccgagctggatggtgccatggagcccatcgtgttcgctggccgtgactcgaacaccggcaagtcgcactcgctgcccgaccgcatcgcttcgctgtgcgctcgcgccgtgaactgggccaacctgcgcaagaagcgcaacgccgagaagaagctggccgtcaccgtgttcagcttcccccctgacaagggcaacgtcggcactgccgcctacctgaacgtgttcggctccatctaccgcgtgctgaagaacctgcagcgcgagggctacgacgtgggcgccctgtccgccctcggaggaggatctgatccagtcggtgctgacccagaaggaggccaagttcaactcgaccgacctgcacatcgcctacaagatgaaggtggacgagtaccagaagctgtgcccttacgccgaggcgctggaggagaactggggcaagccccccggcaccctgaacaccaacggccaggagctgctggtgtacggccgccagtacggcaacgtcttcatcggcgtgcagcccaccttcggctacgagggcgacccgatgcgcctgctgttctcgaagtcggccagcccccaccacggcttcgccgcctactacaccttcctggagaagatcttcaaggccgacgccgtgctgcacttcggcacccacggctcgctggagttcatgcccggcaagcaggtcggcatgtcgggtgtgtgctaccccgactcgctgatcggcaccatccccaacctctactactacgccgccaacaacccgtctgaggccaccatcgccaagcgccgctcgtacgccaacaccatttcgtacctgacgccgcctgccgagaacgccggcctgtacaagggcctgaaggagctgaaggagctgatcagctcgtaccagggcatgcgtgagtctggccgcgccgagcagatctgcgccaccatcattgagaccgccaagctgtgcaacctggaccgcgacgtgaccctgcccgacgctgacgccaaggacctgaccatggacatgcgcgacagcgttgtgggccaggtgtaccgcaagctgatggagattgagtcccgcctgctgccctgcggcctgcacgtggtgggctgcccgcccaccgccgaggaggccgtggccaccctggtcaacatcgctgagctggaccgcccggacaacaacccccccatcaagggcatgcccggcatcctggcccgcgccattggtcgcgacatcgagtcgatttacagcggcaacaacaagggcgtcctggctgacgttgaccagctgcagcgcatcaccgaggcctcccgcacctgcgtgcgcgagttcgtgaaggaccgcaccggcctgaacggccgcatcggcaccaactggatcaccaacctgctcaagttcaccggcttctacgtggacccctgggtgcgcggcctgcagaacggcgagttcgccagcgccaaccgcgaggagctgatcaccctgttcaactacctggagttctgcctgacccaggtggtcaaggacaacgagctgggcgccctggtagaggcgctgaacggccagtacgtcgagcccggccccggcggtgaccccatccgcaaccccaacgtgctgcccaccggcaagaacatccacgccctggaccctcagtcgattcccactcaggccgcgctgaagagcgcccgcctggtggtggaccgcctgctggaccgcgagcgcgacaacaacggcggcaagtaccccgagaccatcgcgctggtgctgtggggcactgacaacatcaagacctacggcgagtcgctggcccaggtcatgatgatggtcggtgtcaagcccgtggccgacgccctgggccgcgtgaacaagctggaggtgatccctctggaggagctgggccgcccccgcgtggacgtggttgtcaactgctcgggtgtgttccgcgacctgttcgtgaaccagatgctgctgctggaccgcgccatcaagctggcggccgagcaggacgagcccgatgagatgaacttcgtgcgcaagcacgccaagcagcaggcggcggagctgggcctgcagagcctgcgcgacgcggccacccgtgtgttctccaacagctcgggctcctactcgtccaacgtcaacctggcggtggagaacagcagctggagcgacgagtcgcagctgcaggagatgtacctgaagcgcaagtcgtacgccttcaactcggaccgccccggcgccggtggcgagatgcagcgcgacgtgttcgagacggccatgaagaccgtggacgtgaccttccagaacctggactcgtccgagatctcgctgaccgatgtgtcgcactacttcgactccgaccccaccaagctggtggcgtcgctgcgcaacgacggccgcacccccaacgcctacatcgccgacaccaccaccgccaacgcgcaggtccgcactctgggtgagaccgtgcgcctggacgcccgcaccaagctgctcaaccccaagtggtacgagggcatgcttgcctcgggctacgagggcgtgcgcgagatccagaagcgcatgaccaacaccatgggctggtcggccacctcgggcatggtggacaactgggtgtacgacgaggccaactcgaccttcatcgaggatgcggccatggccgagcgcctgatgaacaccaaccccaacagcttccgcaagctggtggccaccttcctggaggccaacggccgcggctactgggacgccaagcccgagcagctggagcgcctgcgccagctgtacatggacgtggaggacaagattgagggcgtcgaataa
CHLI15’-非翻译区(调控区)(SEQ ID NO:130):
tcctacagagtaaaggtctaggcgatgcgcgactgaaagactgtgaatcccggcgtcgccgtggtgggatgtgggccggtgcgctgtcgcagaggataaattacaggtatcaaacaaggttagggcgttggaaggagcggcgctagggaactgaaatcggatctgcatcggaccctcattccgcgacttgtccttcttttgcctcgccccgcagctcttgagttttgttcttgaccctttgacacgaaccaaccgatataaaa
CHLI13’-非翻译区(调控区)(SEQ ID NO:131):
gcggcaggccttcatggtcgtcgttggagcatttgcggaaaggctgatggcagcagatgcagccatgtcagttgtggctgaagttgttggctggggcgggagcgggcagcagctgctgcgagcggccgaagcagcggtgctgctttgcgtatgagaggaagaccagtgccctcgaggaggcgagtgcctgtgtgagtgtcaggacgtgtgacttcggaaactgagggcggtgagtagatgtgactggggcttgcaggaagcctactgaccctatcagaaaaggtgagcaggggtatatggtctaggagcgttgccggagcgtggctggccagtgctagccgcgcgggctctgttgctcgctggcgcgccgccgccttcacaacagatgccgtagaaatgcagcgatgtgacgaggcgtggcctattctgcaatgtgtgaggcgccaatggcgccactgacaaatggaggagtggtcaaagcttgggtacgttttgagagctgcatcgggcagcgaggatcagtgtgcggtaagaccgacggcagacggattggcaagggaataggagggacgtgggcgtgggcgcccgcgctttgtcgaggccgcatgagccggccgcttctagacccgtagcccattttgaacaagcgcccacgcgtgctcccgatgggggacatcgatcacgggaattgattaaggggcatgtgtggtgtgcaagtgagtgactggtggttccgtccctgtgaggttgtttcgttggacgtggctgccgggttgcgcgcgggctaagcgggcctgaggcagagcgctggcgtgtagccgcgagtatcgatctgtaacgtgc
CHLI1外显子1(SEQ ID NO:132):
atggccctgaacatgcgtgtttcctcttccaaggtcgctgccaagcagcagggccgcatctccgcggtgccggttgtgtcgagcaaggtggcctcctccgcccgcgtggcccccttccag
CHLI1外显子2(SEQ ID NO:133):
ggcgctcccgtggccgcgcagcgcgctgctctgctgg
CHLI1外显子3(SEQ ID NO:134):
tgcgcgccgctgccgctactgaggtcaaggctgctgagggccgcactgagaaggagctgg
CHLI1外显子4(SEQ ID NO:135):
gccaggcccgccccatcttccccttcaccgccatcgtgggccaggatgagatgaagctggcgctgattctgaacgtgatcgaccccaagatcggtggtgtcatgatcatgggcgaccgtggcactggcaagtccaccaccattcgtgccctggcggatctgctgcccgagatgcag
CHLI1外显子5(SEQ ID NO:136):
gtggttgccaacgacccctttaactcggaccccaccgaccccgagctgatgagcgaggaggtgcgcaaccgcgtcaaggccggcgagcagctgcccgtgtcttccaagaagattcccatggtggacctgcccctgggcgccactgaggaccgcgtgtgcggcaccatcgacatcgagaaggcgctgaccgagg
CHLI1外显子6(SEQ ID NO:137):
gtgtcaaggcgttcgagcccggcctgctggccaaggccaaccgcggcatcctgtacgtggatgaggtcaacctgctggacgaccacctg
CHLI1外显子7(SEQ ID NO:138):
gtcgatgtgctgctggactcggccgcctccggctggaacaccgtggagcgcgagggtatctccatcagccaccccgcccgcttcatcctggtcggctcgg
CHLI1外显子8(SEQ ID NO:139):
gcaaccccgaggagggtgagctgcgcccccagctgctggatcgcttcggcatgcacgcccagatcggcaccgtcaaggacccccgcctgcgtgtgcagatcgtgtcgcagcgctcgaccttcgacgagaaccccgccgccttccg
CHLI1外显子9(SEQ ID NO:140):
caaggactacgaggccggccagatggcgctgacccagcgcatcgtggacgcgcgcaagctgctgaagcagggcgaggtcaactacgacttccgcgtcaagatcagccagatctgctcggacctgaacgtggacggcatccgcggcgacatcgtgaccaaccgcgccgccaaggccctggccgccttcgagggccgcaccgag
CHLI1外显子10(SEQ ID NO:141):
gtgacccccgaggacatctaccgtgtcattcccctgtgcctgcgccaccgcctccggaaagaccccctggctgagatcgacgacggtgaccgcgtgcgtgagatcttcaagcaggtgttcggcatggagtaa
CHLI1内含子1(SEQ ID NO:142):
gtgtgcagttgcatctaaagaacgtccaattcatggttactgctcgtggatctaagcggttggctcaccagcgttccatggtccccgattcgtgcacgcag
CHLI1内含子2(SEQ ID NO:143):
gtgagaagccatgatacaaatataaggatttgaagcggtagatctaggacccatcgaacttgagcaccgacttgcagtccttgccttgtccggcgactgaacttctgcgcttgctttgcag
CHLI1内含子3(SEQ ID NO:144):
gtaagtgtcgcgcaaagattttctgccgggacgggtctccctcgcaacatctgaacccatggctcgtttttttgccccgcag
CHLI1内含子4(SEQ ID NO:145):
gtgcgcgcctcccccaaccccagtttggcaaatgtgtggttaagcgtcgaaagcgtgaacagaaacaggtgttgcgggggccgcggaatggctgcaatgggtgctgggggcttcggagggtctgggggcgagtttgggtatacacgggcgcgcacacttgaaggaacgctcaaggacgacagcggaggcgtggagacagcgccggcccaagcagcctgtacttgtagctgctggtcagctgaggcatcacgacttgggaccagcacccggcctcacggttgcacaaggccatcaccgcgcgccaccacccacgcctcttcaaacccatgccggcacctaccgctacccctgtgacacgctccgcacacgccgccccgcacaccccaccatgtgacag
CHLI1内含子5(SEQ ID NO:146):
gtgagagcgaggcgcggggcgtgctctgcaggctagggtgaagatcaggagagccgaagcgggcccgaacagcgcagagagaggcaagacgacacccctgccgcgttttgatcacaagattcacacccttgctctccccaacgctcccgcacatag
CHLI1内含子6(SEQ ID NO:147):
gtgagcaggggcagataggcggtcgggcggctgggcggcaggggctgtgttggctgtgttgggtgtgggctgaggctggtgggtgggctggcgggtggcagggatagcggtgaggggatggtgatggggcagaatgggcgggtgggcggacacgtggggtcgttgaagggtgtgtggggacggcaactggtatgcgatatgtcggcttggccctggcggggaaagcattcgcagaatggcgcacgaacgaggccggggagcgagcggggatgggagacgcaacctgcgctgcgaagtgcggcgcgcgctccagttgacacgttgcacgaatgtggccagtgttcgcctgagagttatgggttagaccgccagatgagccggttaagctggtggtcgcggttgatcggctgcttcccttccggttgcacgcctggcaccctaacattaccctgtccgctgctgccctttgcccacag
CHLI1内含子7(SEQ ID NO:148):
gtgagtgcagctgccgctgcggctgctgatggtgacctgtgcgaccacggggctccgcatttctggacgaagcgttgtaccatagccgtcttggtccctgatttgggccggctctggtccgaagccttgacatctacagttcaacatggccgtataacgatcctgtgcccacccacacgccaccccgccag
CHLI1内含子8(SEQ ID NO:149):
gtgagcgcgcgctctacgatacggcagacatgtacacactgcggcgcactgtagagcttgcattgcatttcaaggcctcgaaagagtagggtggtcgttctctggtggtgtccggccacaattatgcaccccggtgttggtgcagcagctgtgatgtcacaccttgcatcacccccctactgctgccgcctctcctctcttctcgcccgcag
CHLI1内含子9(SEQ ID NO:150):
gtgagcagagcaatattgcagagggaagggtggcggaagggtgataacggttggggatctagaggggcgagatggatgcacacagcgcggggttggttatgcatgcctgcatggacgcgtgcacgcacccctgatctgccggttttccaactggcgatgccgtattatgacctgcagctcaccatcctcatgcttgatttgcctcgctcag
CHLI1蛋白质序列(SEQ ID NO:151):
MALNMRVSSSKVAAKQQGRISAVPVVSSKVASSARVAPFQGAPVAAQRAALLVRAAAATEVKAAEGRTEKELGQARPIFPFTAIVGQDEMKLALILNVIDPKIGGVMIMGDRGTGKSTTIRALADLLPEMQVVANDPFNSDPTDPELMSEEVRNRVKAGEQLPVSSKKIPMVDLPLGATEDRVCGTIDIEKALTEGVKAFEPGLLAKANRGILYVDEVNLLDDHLVDVLLDSAASGWNTVEREGISISHPARFILVGSGNPEEGELRPQLLDRFGMHAQIGTVKDPRLRVQIVSQRSTFDENPAAFRKDYEAGQMALTQRIVDARKLLKQGEVNYDFRVKISQICSDLNVDGIRGDIVTNRAAKALAAFEGRTEVTPEDIYRVIPLCLRHRLRKDPLAEIDDGDRVREIFKQVFGME
突变蛋白质序列红藻CHLH(SEQ ID NO:152):
MQTSSLLGRRTAHPAAGATPKPVAPSPRVASTRQVACNVATGPRPPMTTFTGGNKGPAKQQVSLDLRDEGAGMFTSTSPEMRRVVPDDVKGRVKVKVVYVVLEAQYQSAISAAVKNINAKNSKVCFEVVGYLLEELRDQKNLDMLKEDVASANIFIGSLIFIEELAEKIVEAVSPLREKLDACLIFPSMPAVMKLNKLGTFSMAQLGQSKSVFSEFIKSARKNNDNFEEGLLKLVRTLPKVLKYLPSDKAQDAKNFVNSLQYWLGGNSDNLENLLLNTVSNYVPALKGVDFSVAEPTAYPDVGIWHPLASGMYEDLKEYLNWYDTRKDMVFAKDAPVIGLVLQRSHLVTGDEGHYSGVVAELESRGAKVIPVFAGGLDFSAPVKKFFYDPLGSGRTFVDTVVSLTGFALVGGPARQDAPKAIEALKNLNVPYLVSLPLVFQTTEEWLDSELGVHPVQVALQVALPELDGAMEPIVFAGRDSNTGKSHSLPDRIASLCARAVNWANLRKKRNAEKKLAVTVFSFPPDKGNVGTAAYLNVFGSIYRVLKNLQREGYDVGALSALGGGSDPVGADPEGGQVQLDRPAHRLQDEGGRVPEAVPLRRGAGGELGQAPRHPEHQRPGAAGVRPPVRQRLHRRAAHLRLRGRPDAPAVLEVGQPPPRLRRLLHLPGEDLQGRRRAALRHPRLAGVHARQAGRHVGCVLPRLADRHHPQPLLLRRQQPV
CHLI1 DNA序列(SEQ ID NO:153):
atggccctgaacatgcgtgtttcctcttccaaggtcgctgccaagcagcagggccgcatctccgcggtgccggttgtgtcgagcaaggtggcctcctccgcccgcgtggcccccttccagggcgctcccgtggccgcgcagcgcgctgctctgctggtgcgcgccgctgccgctactgaggtcaaggctgctgagggccgcactgagaaggagctgggccaggcccgccccatcttccccttcaccgccatcgtgggccaggatgagatgaagctggcgctgattctgaacgtgatcgaccccaagatcggtggtgtcatgatcatgggcgaccgtggcactggcaagtccaccaccattcgtgccctggcggatctgctgcccgagatgcaggtggttgccaacgacccctttaactcggaccccaccgaccccgagctgatgagcgaggaggtgcgcaaccgcgtcaaggccggcgagcagctgcccgtgtcttccaagaagattcccatggtggacctgcccctgggcgccactgaggaccgcgtgtgcggcaccatcgacatcgagaaggcgctgaccgagggtgtcaaggcgttcgagcccggcctgctggccaaggccaaccgcggcatcctgtacgtggatgaggtcaacctgctggacgaccacctggtcgatgtgctgctggactcggccgcctccggctggaacaccgtggagcgcgagggtatctccatcagccaccccgcccgcttcatcctggtcggctcgggcaaccccgaggagggtgagctgcgcccccagctgctggatcgcttcggcatgcacgcccagatcggcaccgtcaaggacccccgcctgcgtgtgcagatcgtgtcgcagcgctcgaccttcgacgagaaccccgccgccttccgcaaggactacgaggccggccagatggcgctgacccagcgcatcgtggacgcgcgcaagctgctgaagcagggcgaggtcaactacgacttccgcgtcaagatcagccagatctgctcggacctgaacgtggacggcatccgcggcgacatcgtgaccaaccgcgccgccaaggccctggccgccttcgagggccgcaccgaggtgacccccgaggacatctaccgtgtcattcccctgtgcctgcgccaccgcctccggaaagaccccctggctgagatcgacgacggtgaccgcgtgcgtgagatcttcaagcaggtgttcggcatggagtaa
尽管已经参考上述实例对本发明进行了描述,但是,应当理解的是,各种修改和变形都包括在本发明的精神和范围内。因此,本发明仅由所附权利要求书限制。
序列表
<110> 特里同阿盖亚创新公司
<120> 将藻类血红素掺入到可食用产品中的组合物和方法
<130> 20498-202379
<150> 62/865,800
<151> 2019-06-24
<150> 62/850,227
<151> 2019-05-20
<150> 62/757,534
<151> 2018-11-08
<160> 153
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1173
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 1
atgcagatga tgcagcgcaa cgttgtgggc cagcgccccg tcgctggctc ccgccgctcg 60
ctggtggttg ccaacgttgc ggaggtgacc cgccccgcgg tcagcaccaa cggcaagcac 120
cggactggtg tgccggaggg aactcccatc gtcacccctc aggacctgcc ctcgcgccct 180
cgccgcaacc gccgcagcga gagcttccgt gcttccgttc gtgaggtgaa cgtgtcgccc 240
gccaacttca tcctgccgat cttcatccac gaggagagca accagaacgt gcccatcgcc 300
tccatgcctg gcatcaaccg cctggcgtat ggcaagaacg tgattgacta cgttgctgag 360
gctcgctctt acggtgtcaa ccaggtcgtg gttttcccca agacgcccga ccacctgaag 420
acgcaaaccg cggaggaggc gttcaacaag aacggcctca gccagcgcac gatccgcctg 480
ctgaaggact ctttccctga cctggaggtg tacacggacg tggctctgga cccctacaac 540
tcggacggcc acgacggtat cgtgtcggac gccggtgtga tcctgaacga cgagaccatc 600
gagtacctgt gccgccaggc cgtgagccag gccgaggccg gtgccgacgt ggtgtcgccc 660
tctgacatga tggacggccg cgtgggcgcc atccgccgcg ccctggaccg cgagggcttc 720
accaacgtgt ccatcatgtc ctacaccgcc aagtacgcct ccgcctacta cggccccttc 780
cgtgacgccc tggcgtccgc gcccaagccc ggccaggcgc accgccgcat cccccccaac 840
aagaagacct accagatgga ccccgccaac taccgcgagg ccatccgcga ggccaaggcc 900
gacgaggccg agggcgctga catcatgatg gtcaagcccg gcatgccgta cctggacgtg 960
gtacgcctgc tgcgtgagac cagcccgctg cccgtggccg tgtaccacgt gtcgggcgag 1020
tacgccatgc tcaaggcggc ggcggagcgc ggctggctga acgagaagga tgccgtgctt 1080
gaggccatga cctgcttccg ccgcgccggc gctgacctca tcctcaccta ctacggcatt 1140
gaggcctcca agtggctggc gggcgagaag taa 1173
<210> 2
<211> 390
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 2
Met Gln Met Met Gln Arg Asn Val Val Gly Gln Arg Pro Val Ala Gly
1 5 10 15
Ser Arg Arg Ser Leu Val Val Ala Asn Val Ala Glu Val Thr Arg Pro
20 25 30
Ala Val Ser Thr Asn Gly Lys His Arg Thr Gly Val Pro Glu Gly Thr
35 40 45
Pro Ile Val Thr Pro Gln Asp Leu Pro Ser Arg Pro Arg Arg Asn Arg
50 55 60
Arg Ser Glu Ser Phe Arg Ala Ser Val Arg Glu Val Asn Val Ser Pro
65 70 75 80
Ala Asn Phe Ile Leu Pro Ile Phe Ile His Glu Glu Ser Asn Gln Asn
85 90 95
Val Pro Ile Ala Ser Met Pro Gly Ile Asn Arg Leu Ala Tyr Gly Lys
100 105 110
Asn Val Ile Asp Tyr Val Ala Glu Ala Arg Ser Tyr Gly Val Asn Gln
115 120 125
Val Val Val Phe Pro Lys Thr Pro Asp His Leu Lys Thr Gln Thr Ala
130 135 140
Glu Glu Ala Phe Asn Lys Asn Gly Leu Ser Gln Arg Thr Ile Arg Leu
145 150 155 160
Leu Lys Asp Ser Phe Pro Asp Leu Glu Val Tyr Thr Asp Val Ala Leu
165 170 175
Asp Pro Tyr Asn Ser Asp Gly His Asp Gly Ile Val Ser Asp Ala Gly
180 185 190
Val Ile Leu Asn Asp Glu Thr Ile Glu Tyr Leu Cys Arg Gln Ala Val
195 200 205
Ser Gln Ala Glu Ala Gly Ala Asp Val Val Ser Pro Ser Asp Met Met
210 215 220
Asp Gly Arg Val Gly Ala Ile Arg Arg Ala Leu Asp Arg Glu Gly Phe
225 230 235 240
Thr Asn Val Ser Ile Met Ser Tyr Thr Ala Lys Tyr Ala Ser Ala Tyr
245 250 255
Tyr Gly Pro Phe Arg Asp Ala Leu Ala Ser Ala Pro Lys Pro Gly Gln
260 265 270
Ala His Arg Arg Ile Pro Pro Asn Lys Lys Thr Tyr Gln Met Asp Pro
275 280 285
Ala Asn Tyr Arg Glu Ala Ile Arg Glu Ala Lys Ala Asp Glu Ala Glu
290 295 300
Gly Ala Asp Ile Met Met Val Lys Pro Gly Met Pro Tyr Leu Asp Val
305 310 315 320
Val Arg Leu Leu Arg Glu Thr Ser Pro Leu Pro Val Ala Val Tyr His
325 330 335
Val Ser Gly Glu Tyr Ala Met Leu Lys Ala Ala Ala Glu Arg Gly Trp
340 345 350
Leu Asn Glu Lys Asp Ala Val Leu Glu Ala Met Thr Cys Phe Arg Arg
355 360 365
Ala Gly Ala Asp Leu Ile Leu Thr Tyr Tyr Gly Ile Glu Ala Ser Lys
370 375 380
Trp Leu Ala Gly Glu Lys
385 390
<210> 3
<211> 1098
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 3
atggcactgc aagcctcaac ccgctcgctc cagcagcgcc gcgccttctc ttcggcccag 60
acctccaagc gtgtgtctgt gaccaaggtc cgcgcgacgg ctatcgaggc ggagaactat 120
gtgaagcagg ctccccagtc gctggtccgc ccgggcatcg acactgagga ctctatgcgc 180
gctcgcttcg agaaggtgat ccgcaacgcc caggactcca tctgcaatgc tatctccgag 240
atcgatggca agccgttcca ccaggacgcc tggacccgcc ccggcggcgg tggcggcatc 300
agccgcgtgc tgcaggacgg caacgtgtgg gagaaggccg gcgtcaacgt gtccgtggtc 360
tacggcacca tgccccctga ggcctaccgc gctgccactg gcaacgccga gaagctgaag 420
aacaagggtg acggtggccg cgtgcccttc ttcgccgccg gcatctcgtc ggtgatgcac 480
ccccgcaacc cccactgccc caccatgcac ttcaactacc gctacttcga gactgaggag 540
tggaacggca tccccggcca gtggtggttc ggcggcggca ccgacatcac ccccagctat 600
gtggtgcccg aggacatgaa gcacttccac ggcacctaca aggcggtgtg cgaccgccac 660
gatcccgctt actacgagaa gttccgcacc tggtgcgatg agtacttcct catcaagcac 720
cgcggcgagc gccgcggcct gggcggcatc ttcttcgatg acctgaacga ccgcaacccc 780
gaggacatcc tgaagttctc gaccgacgcc gtgaacaacg tggtggaggc atactgcccc 840
atcatcaaga agcacatgaa cgacccctac acccccgagg agaaggagtg gcagcagatc 900
cgccgcggcc gctacgtgga gttcaacctg gtctatgacc gcggcaccac cttcggcctg 960
aagaccggcg gccgcattga gtcgatcctc atgtccatgc cccagaccgc ctcatggctg 1020
tacgaccacc agcccaaggc cggctcgccc gaggccgagc tgctcgacgc ctgccgcaac 1080
ccccgcgtct gggtgtaa 1098
<210> 4
<211> 365
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 4
Met Ala Leu Gln Ala Ser Thr Arg Ser Leu Gln Gln Arg Arg Ala Phe
1 5 10 15
Ser Ser Ala Gln Thr Ser Lys Arg Val Ser Val Thr Lys Val Arg Ala
20 25 30
Thr Ala Ile Glu Ala Glu Asn Tyr Val Lys Gln Ala Pro Gln Ser Leu
35 40 45
Val Arg Pro Gly Ile Asp Thr Glu Asp Ser Met Arg Ala Arg Phe Glu
50 55 60
Lys Val Ile Arg Asn Ala Gln Asp Ser Ile Cys Asn Ala Ile Ser Glu
65 70 75 80
Ile Asp Gly Lys Pro Phe His Gln Asp Ala Trp Thr Arg Pro Gly Gly
85 90 95
Gly Gly Gly Ile Ser Arg Val Leu Gln Asp Gly Asn Val Trp Glu Lys
100 105 110
Ala Gly Val Asn Val Ser Val Val Tyr Gly Thr Met Pro Pro Glu Ala
115 120 125
Tyr Arg Ala Ala Thr Gly Asn Ala Glu Lys Leu Lys Asn Lys Gly Asp
130 135 140
Gly Gly Arg Val Pro Phe Phe Ala Ala Gly Ile Ser Ser Val Met His
145 150 155 160
Pro Arg Asn Pro His Cys Pro Thr Met His Phe Asn Tyr Arg Tyr Phe
165 170 175
Glu Thr Glu Glu Trp Asn Gly Ile Pro Gly Gln Trp Trp Phe Gly Gly
180 185 190
Gly Thr Asp Ile Thr Pro Ser Tyr Val Val Pro Glu Asp Met Lys His
195 200 205
Phe His Gly Thr Tyr Lys Ala Val Cys Asp Arg His Asp Pro Ala Tyr
210 215 220
Tyr Glu Lys Phe Arg Thr Trp Cys Asp Glu Tyr Phe Leu Ile Lys His
225 230 235 240
Arg Gly Glu Arg Arg Gly Leu Gly Gly Ile Phe Phe Asp Asp Leu Asn
245 250 255
Asp Arg Asn Pro Glu Asp Ile Leu Lys Phe Ser Thr Asp Ala Val Asn
260 265 270
Asn Val Val Glu Ala Tyr Cys Pro Ile Ile Lys Lys His Met Asn Asp
275 280 285
Pro Tyr Thr Pro Glu Glu Lys Glu Trp Gln Gln Ile Arg Arg Gly Arg
290 295 300
Tyr Val Glu Phe Asn Leu Val Tyr Asp Arg Gly Thr Thr Phe Gly Leu
305 310 315 320
Lys Thr Gly Gly Arg Ile Glu Ser Ile Leu Met Ser Met Pro Gln Thr
325 330 335
Ala Ser Trp Leu Tyr Asp His Gln Pro Lys Ala Gly Ser Pro Glu Ala
340 345 350
Glu Leu Leu Asp Ala Cys Arg Asn Pro Arg Val Trp Val
355 360 365
<210> 5
<211> 1049
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 5
atgctgagga agcagattgg tggatctggc cagcagcggg cgggcctccg acgggtgaac 60
caaggacctg cgcgtcggcg gttggcaccc tgccgcgtgg cggcccccgt gcaaacctcg 120
tcctccgtcg ccacattcaa tggcttcgtg gactacattc acggactcca gaagaacatt 180
ctgagcactg ctgaggatct ggagaacggc gagcggaagt ttgttgttga ccgctgggag 240
cgcgacgcca gcaaccccaa cgccgggtat ggcattacgt gcgtgcttga ggacgggaag 300
gtgctggaga aggccgcagc caatatctca gtggtgcgcg ggacgctgtc ggcgcagcgc 360
gcagtggcca tgagctcccg cggccgcagc agcatcgacc ccaagggcgg gcagccctac 420
gccgcggccg ccatgagcct agtgttccac agcgcgcacc cgctcatccc cacgctgcgc 480
gcgacgtgcg gttgttccag gtgggcgatg aggcgtggta cggcggtggc tgtgacctga 540
cgcccaacta cctagacgtg gaggactcgc agtccttcca ccgctactgg aaggacgtgt 600
gcggcaagta caagccgggc ctgtacaccg agctcaagga gtggtgcgac aggtacttct 660
acatcccggc ccgcaaagag caccgtggca ttggcggcct gttctttgat gacatggcca 720
ctgcggaggc gggctgcgat gtggaggcgt ttgtgcggga agtgggagat ggcatcctgc 780
cctgctggct gcccatcgtg gcgcggcacc gtggccagcc cttcacggag cagcagcggc 840
aatggcagct gctgcgccgc ggtcgctaca tcgagttcaa cctgctgtac gaccgcggca 900
tcaagttcgg tctggacggc ggccgcatcg agagcatcat ggtgtcggcg ccgccgctga 960
tcgcgtggaa gtacaacgtg gtgccacagc cgggcagccc cgaggaggag atgctgaagg 1020
tgcttcagca gccccgcgag tgggcctga 1049
<210> 6
<211> 349
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 6
Met Leu Arg Lys Gln Ile Gly Gly Ser Gly Gln Gln Arg Ala Gly Leu
1 5 10 15
Arg Arg Val Asn Gln Gly Pro Ala Arg Arg Arg Leu Ala Pro Cys Arg
20 25 30
Val Ala Ala Pro Val Gln Thr Ser Ser Ser Val Ala Thr Phe Asn Gly
35 40 45
Phe Val Asp Tyr Ile His Gly Leu Gln Lys Asn Ile Leu Ser Thr Ala
50 55 60
Glu Asp Leu Glu Asn Gly Glu Arg Lys Phe Val Val Asp Arg Trp Glu
65 70 75 80
Arg Asp Ala Ser Asn Pro Asn Ala Gly Tyr Gly Ile Thr Cys Val Leu
85 90 95
Glu Asp Gly Lys Val Leu Glu Lys Ala Ala Ala Asn Ile Ser Val Val
100 105 110
Arg Gly Thr Leu Ser Ala Gln Arg Ala Val Ala Met Ser Ser Arg Gly
115 120 125
Arg Ser Ser Ile Asp Pro Lys Gly Gly Gln Pro Tyr Ala Ala Ala Ala
130 135 140
Met Ser Leu Val Phe His Ser Ala His Pro Leu Ile Pro Thr Leu Arg
145 150 155 160
Ala Asp Val Arg Leu Phe Gln Val Gly Asp Glu Ala Trp Tyr Gly Gly
165 170 175
Gly Cys Asp Leu Thr Pro Asn Tyr Leu Asp Val Glu Asp Ser Gln Ser
180 185 190
Phe His Arg Tyr Trp Lys Asp Val Cys Gly Lys Tyr Lys Pro Gly Leu
195 200 205
Tyr Thr Glu Leu Lys Glu Trp Cys Asp Arg Tyr Phe Tyr Ile Pro Ala
210 215 220
Arg Lys Glu His Arg Gly Ile Gly Gly Leu Phe Phe Asp Asp Met Ala
225 230 235 240
Thr Ala Glu Ala Gly Cys Asp Val Glu Ala Phe Val Arg Glu Val Gly
245 250 255
Asp Gly Ile Leu Pro Cys Trp Leu Pro Ile Val Ala Arg His Arg Gly
260 265 270
Gln Pro Phe Thr Glu Gln Gln Arg Gln Trp Gln Leu Leu Arg Arg Gly
275 280 285
Arg Tyr Ile Glu Phe Asn Leu Leu Tyr Asp Arg Gly Ile Lys Phe Gly
290 295 300
Leu Asp Gly Gly Arg Ile Glu Ser Ile Met Val Ser Ala Pro Pro Leu
305 310 315 320
Ile Ala Trp Lys Tyr Asn Val Val Pro Gln Pro Gly Ser Pro Glu Glu
325 330 335
Glu Met Leu Lys Val Leu Gln Gln Pro Arg Glu Trp Ala
340 345
<210> 7
<211> 1482
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 7
atggcgtcgt ttggattgat gcaaaggacg gtgcactgtc cccagcttgt ggaggagcgg 60
tgttcgccgg tcgctggctg ctctggtcgt ggcctgccag ttatccagcg gcaacggcgt 120
ggcgtgtgca gtgccaccaa cggtgtccag cgagggcgtg tgctgcgccg gacggccgct 180
tcgaccgacg tggtctcctt cgtggacccc aatgacatta gaaaacccgc agcagcagca 240
gctggccctg cggtggataa ggtcggcgtt ctgctgttaa accttggcgg gcccgaaaag 300
ctcgacgacg tcaagccttt cctgtataac ctattcgccg acccagaaat tattcgcctg 360
ccagcggcag ctcagttcct gcagccgctg ctcgcgacga tcatctccac gcttcgcgcc 420
ccgaagagcg cggagggcta tgaggccatt ggcggtggta gcccgttgcg taggattaca 480
gacgagcagg cggaggcgct ggcggagtct ctgcgcgcca agggccaacc tgcgaacgtg 540
tacgtgggca tgcgctattg gcacccctac acggaggagg cgctggagca cattaaggcc 600
gacggcgtca cgcgcctggt catcctcccg ctgtaccctc agttctccat ctctaccagc 660
ggctccagcc ttcgactgct tgagtcgctc ttcaagagcg acatcgcgct caagtcgctg 720
cggcacacgg tcatcccgtc ctggtaccag cggcggggct acgtgagcgc gatggcggac 780
ctgattgtag aggagctgaa gaagttccgg gacgtgccca gcgtggagct gtttttctcc 840
gcgcacggcg tgcccaagtc ctacgtggag gaggcgggcg acccatacaa ggaggagatg 900
gaggagtgcg tgcggctcat tacggacgag gtcaagcggc gcggcttcgc caacacgcac 960
acgctggcct accagagccg cgtgggcccc gcggaatggc tcaagccgta cacggatgag 1020
tccatcaagg agctgggcaa gcgcggcgtc aagtcgctgc tggcggtgcc catcagcttt 1080
gtcagcgagc acattgagac gttggaggag atcgacatgg agtaccgcga gctggcggag 1140
gagagcggca tccgcaactg gggccgcgtg ccggcgctga acaccaacgc cgccttcatc 1200
gacgacctgg cggacgcggt gatggaggcg ctgccctacg tgggctgcct ggccgggccg 1260
acagactcgc tggtgccgct gggcgacctg gagatgctgc tgcaggccta cgaccgcgag 1320
cgccgcacgc tgccgtcacc ggtggtgatg tgggagtggg gctggaccaa gagcgcggag 1380
acgtggaacg gccgcattgc catgattgcc atcatcatca tcctggcgct ggaggcagcc 1440
agcggccagt ccatcctcaa aaacctgttc ctggcggagt ag 1482
<210> 8
<211> 492
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 8
Met Ala Ser Phe Gly Leu Met Gln Arg Thr Val His Cys Pro Gln Leu
1 5 10 15
Val Glu Glu Arg Cys Ser Pro Val Ala Gly Cys Ser Gly Arg Gly Leu
20 25 30
Pro Val Ile Gln Arg Gln Arg Arg Gly Val Cys Ser Ala Thr Asn Gly
35 40 45
Val Gln Arg Gly Arg Val Leu Arg Arg Thr Ala Ala Ser Thr Asp Val
50 55 60
Val Ser Phe Val Asp Pro Asn Asp Ile Arg Lys Pro Ala Ala Ala Ala
65 70 75 80
Ala Gly Pro Ala Val Asp Lys Val Gly Val Leu Leu Leu Asn Leu Gly
85 90 95
Gly Pro Glu Lys Leu Asp Asp Val Lys Pro Phe Leu Tyr Asn Leu Phe
100 105 110
Ala Asp Pro Glu Ile Ile Arg Leu Pro Ala Ala Ala Gln Phe Leu Gln
115 120 125
Pro Leu Leu Ala Thr Ile Ile Ser Thr Leu Arg Ala Pro Lys Ser Ala
130 135 140
Glu Gly Tyr Glu Ala Ile Gly Gly Gly Ser Pro Leu Arg Arg Ile Thr
145 150 155 160
Asp Glu Gln Ala Glu Ala Leu Ala Glu Ser Leu Arg Ala Lys Gly Gln
165 170 175
Pro Ala Asn Val Tyr Val Gly Met Arg Tyr Trp His Pro Tyr Thr Glu
180 185 190
Glu Ala Leu Glu His Ile Lys Ala Asp Gly Val Thr Arg Leu Val Ile
195 200 205
Leu Pro Leu Tyr Pro Gln Phe Ser Ile Ser Thr Ser Gly Ser Ser Leu
210 215 220
Arg Leu Leu Glu Ser Leu Phe Lys Ser Asp Ile Ala Leu Lys Ser Leu
225 230 235 240
Arg His Thr Val Ile Pro Ser Trp Tyr Gln Arg Arg Gly Tyr Val Ser
245 250 255
Ala Met Ala Asp Leu Ile Val Glu Glu Leu Lys Lys Phe Arg Asp Val
260 265 270
Pro Ser Val Glu Leu Phe Phe Ser Ala His Gly Val Pro Lys Ser Tyr
275 280 285
Val Glu Glu Ala Gly Asp Pro Tyr Lys Glu Glu Met Glu Glu Cys Val
290 295 300
Arg Leu Ile Thr Asp Glu Val Lys Arg Arg Gly Phe Ala Asn Thr His
305 310 315 320
Thr Leu Ala Tyr Gln Ser Arg Val Gly Pro Ala Glu Trp Leu Lys Pro
325 330 335
Tyr Thr Asp Glu Ser Ile Lys Glu Leu Gly Lys Arg Gly Val Lys Ser
340 345 350
Leu Leu Ala Val Pro Ile Ser Phe Val Ser Glu His Ile Glu Thr Leu
355 360 365
Glu Glu Ile Asp Met Glu Tyr Arg Glu Leu Ala Glu Glu Ser Gly Ile
370 375 380
Arg Asn Trp Gly Arg Val Pro Ala Leu Asn Thr Asn Ala Ala Phe Ile
385 390 395 400
Asp Asp Leu Ala Asp Ala Val Met Glu Ala Leu Pro Tyr Val Gly Cys
405 410 415
Leu Ala Gly Pro Thr Asp Ser Leu Val Pro Leu Gly Asp Leu Glu Met
420 425 430
Leu Leu Gln Ala Tyr Asp Arg Glu Arg Arg Thr Leu Pro Ser Pro Val
435 440 445
Val Trp Glu Trp Gly Trp Thr Lys Ser Ala Glu Thr Trp Asn Gly Arg
450 455 460
Ile Ala Met Ile Ala Ile Ile Ile Ile Leu Ala Leu Glu Ala Ala Ser
465 470 475 480
Gly Gln Ser Ile Leu Lys Asn Leu Phe Leu Ala Glu
485 490
<210> 9
<211> 1392
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 9
atgcagatgc agctgaacgc caagaccgtg cagggcgcct tcaaggcgca gcgccctcgc 60
tctgtccgcg gcaacgtggc ggtgcgcgca gtggccgctc cccctaagct ggtcaccaag 120
cgctccgagg agatcttcaa ggaggctcag gagctgctgc ccggtggcgt gaactcgccc 180
gtgcgcgctt tccgctcggt tggtggcggc cccatcgtct tcgacagggt caagggtgcc 240
tactgctggg acgtcgatgg caacaagtac atcgactacg ttggctcttg gggccctgcc 300
atttgcggcc acggcaacga cgaggtcaac aacgccctga aggcgcagat cgacaagggc 360
acctcgttcg gtgctccctg cgagctggag aacgtgctgg ccaagatggt gattgaccgc 420
gtgccctcgg tggagatggt gcgcttcgtg tcctcgggca ctgaggcgtg cctgtcggtg 480
ctgcgcctga tgcgcgcata caccggccgc gagaaggtgc tgaagttcac cggctgctac 540
cacggccacg ccgactcctt cctggtgaag gccggctccg gtgtgatcac cctgggcctg 600
cccgactcgc ccggtgtgcc caagagcacc gccgccgcca ccctgaccgc cacctacaac 660
aacctggact ccgtgcgcga gctgttcgcc gccaacaagg gcgagattgc cggtgtgatc 720
ctggagcccg tggtcggcaa cagcggcttc attgtgccca ccaaggagtt cctgcagggc 780
ctgcgcgaga tctgcacggc tgagggcgcc gtgctgtgct tcgatgaggt catgaccggc 840
ttccgcattg ccaagggctg cgcccaggag cacttcggta tcacccccga cctgaccacc 900
atgggcaagg tcattggtgg cggcatgcct gtgggcgcct acggcggcaa gaaggagatc 960
atgaagatgg tcgcccccgc cggccccatg taccaggccg gcaccctttc gggcaacccc 1020
atggccatga ctgccggcat caagacgctg gagatcctgg gccgccccgg cgcctacgag 1080
cacctggaga aggtgaccaa gcgcctgatc gacggcatca tggccgccgc caaggagcac 1140
agccacgaga tcaccggcgg caacatcagc ggcatgtttg gcttcttctt ctgcaagggc 1200
cctgtgacct gcttcgagga cgccctggcg gccgacactg ccaagttcgc gcgcttccac 1260
cgcggcatgc tggaggaggg cgtctacctg gctccctcgc agttcgaggc cggcttcacc 1320
tctctggccc actccgaggc ggacgtggat gccacgatcg ccgccgctcg ccgcgtgttc 1380
gcccgcatct aa 1392
<210> 10
<211> 463
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 10
Met Gln Met Gln Leu Asn Ala Lys Thr Val Gln Gly Ala Phe Lys Ala
1 5 10 15
Gln Arg Pro Arg Ser Val Arg Gly Asn Val Ala Val Arg Ala Val Ala
20 25 30
Ala Pro Pro Lys Leu Val Thr Lys Arg Ser Glu Glu Ile Phe Lys Glu
35 40 45
Ala Gln Glu Leu Leu Pro Gly Gly Val Asn Ser Pro Val Arg Ala Phe
50 55 60
Arg Ser Val Gly Gly Gly Pro Ile Val Phe Asp Arg Val Lys Gly Ala
65 70 75 80
Tyr Cys Trp Asp Val Asp Gly Asn Lys Tyr Ile Asp Tyr Val Gly Ser
85 90 95
Trp Gly Pro Ala Ile Cys Gly His Gly Asn Asp Glu Val Asn Asn Ala
100 105 110
Leu Lys Ala Gln Ile Asp Lys Gly Thr Ser Phe Gly Ala Pro Cys Glu
115 120 125
Leu Glu Asn Val Leu Ala Lys Met Val Ile Asp Arg Val Pro Ser Val
130 135 140
Glu Met Val Arg Phe Val Ser Ser Gly Thr Glu Ala Cys Leu Ser Val
145 150 155 160
Leu Arg Leu Met Arg Ala Tyr Thr Gly Arg Glu Lys Val Leu Lys Phe
165 170 175
Thr Gly Cys Tyr His Gly His Ala Asp Ser Phe Leu Val Lys Ala Gly
180 185 190
Ser Gly Val Ile Thr Leu Gly Leu Pro Asp Ser Pro Gly Val Pro Lys
195 200 205
Ser Thr Ala Ala Ala Thr Leu Thr Ala Thr Tyr Asn Asn Leu Asp Ser
210 215 220
Val Arg Glu Leu Phe Ala Ala Asn Lys Gly Glu Ile Ala Gly Val Ile
225 230 235 240
Leu Glu Pro Val Val Gly Asn Ser Gly Phe Ile Val Pro Thr Lys Glu
245 250 255
Phe Leu Gln Gly Leu Arg Glu Ile Cys Thr Ala Glu Gly Ala Val Leu
260 265 270
Cys Phe Asp Glu Val Met Thr Gly Phe Arg Ile Ala Lys Gly Cys Ala
275 280 285
Gln Glu His Phe Gly Ile Thr Pro Asp Leu Thr Thr Met Gly Lys Val
290 295 300
Ile Gly Gly Gly Met Pro Val Gly Ala Tyr Gly Gly Lys Lys Glu Ile
305 310 315 320
Met Lys Met Val Ala Pro Ala Gly Pro Met Tyr Gln Ala Gly Thr Leu
325 330 335
Ser Gly Asn Pro Met Ala Met Thr Ala Gly Ile Lys Thr Leu Glu Ile
340 345 350
Leu Gly Arg Pro Gly Ala Tyr Glu His Leu Glu Lys Val Thr Lys Arg
355 360 365
Leu Ile Asp Gly Ile Met Ala Ala Ala Lys Glu His Ser His Glu Ile
370 375 380
Thr Gly Gly Asn Ile Ser Gly Met Phe Gly Phe Phe Phe Cys Lys Gly
385 390 395 400
Pro Val Thr Cys Phe Glu Asp Ala Leu Ala Ala Asp Thr Ala Lys Phe
405 410 415
Ala Arg Phe His Arg Gly Met Leu Glu Glu Gly Val Tyr Leu Ala Pro
420 425 430
Ser Gln Phe Glu Ala Gly Phe Thr Ser Leu Ala His Ser Glu Ala Asp
435 440 445
Val Asp Ala Thr Ile Ala Ala Ala Arg Arg Val Phe Ala Arg Ile
450 455 460
<210> 11
<211> 1569
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 11
atgcagacca ctatgcagca gcgtctccag ggccgtaacg tggccgggcg gagcgtcgct 60
ccctcggtcc ctgcccatcg ctccttccac tcacaccggg ctgccactca aaccgctacg 120
atcagcgctg ctgctagctc aaccaccaag ctgccagctt cgcatctgga gagcagcaag 180
aaggcgctgg attcgctgaa gcagcaggcc gtcaatcgct acgcgggtga caagaagagc 240
tccattattg ccattggtct caccattcac aacgcacccg tggagctgcg cgagaagctg 300
gctgtgcctg aggctgaatg gccgcgtgct attgaggagc tctgccagtt cccgcacatc 360
gaggaggccg cggtgctgtc gacgtgcaat cgcatggagc tctacgttgt cggtctgtcg 420
tggcaccgcg gcgttcgcga ggtggaggag tggctgtctc gcaccagcgg cgtgcctctg 480
gatgagctgc gcccctacct gttcctgctg cgcgaccgcg acgccacgca ccacctgatg 540
cgcgtgtcgg gtggccttga ctcgctggtt atgggcgagg gccagattct cgcccaagtg 600
cgccaggtct acaaggtcgg ccagaactgc cccggcttcg gtcgccacct gaacggcctg 660
ttcaagcagg ctatcaccgc tggcaagcgc gtgcgtgccg agacctccat ctccaccggc 720
tccgtctccg tctcatccgc cgccgtcgag ctggcgcagc tcaagctccc cacccacaac 780
tggtccgacg ctaaggtctg catcatcggc gctggcaaga tgtctacgct gctggtgaag 840
cacctgcaga gcaagggctg caaggaggtg acggtgctca accgctctct gccgcgcgcc 900
caggcgctgg cggaggagtt ccctgaggtc aagttcaaca tccacctgat gcccgacctg 960
ctgcagtgcg tggaggccag cgacgtcatc ttcgccgcct ccggctctga ggagatcctc 1020
atccacaagg agcatgtcga ggccatgtcc aagccatcgg acgttgttgg ctccaagcgc 1080
cgcttcgtcg acatctccgt gccccgcaac atcgcccccg ccatcaacga gctggagcac 1140
ggcatcgtct acaacgtcga cgacctgaag gaggttgtgg ccgccaacaa ggagggccgc 1200
gcgcaggcgg ccgccgaggc cgaggtgctg atccgcgagg agcagcgcgc gttcgaggcc 1260
tggcgtgact ctctggagac cgtgcccacc atcaaggcgc tgcgctccaa ggccgagacc 1320
atccgcgccg ccgagtttga gaaggccgtg tctcgcctgg gcgaggggct atccaagaag 1380
cagctcaagg cggtggagga gctcagcaag ggcatcgtca acaagctgct gcacgggccc 1440
atgacggcac tgcgctgcga cggcaccgat ccggatgccg tgggccagac cctcgcgaac 1500
atggaggccc tggagcgcat gttccagctc tcggaggtgg acgtggccgc gctggcgggc 1560
aagcagtaa 1569
<210> 12
<211> 522
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 12
Met Gln Thr Thr Met Gln Gln Arg Leu Gln Gly Arg Asn Val Ala Gly
1 5 10 15
Arg Ser Val Ala Pro Ser Val Pro Ala His Arg Ser Phe His Ser His
20 25 30
Arg Ala Ala Thr Gln Thr Ala Thr Ile Ser Ala Ala Ala Ser Ser Thr
35 40 45
Thr Lys Leu Pro Ala Ser His Leu Glu Ser Ser Lys Lys Ala Leu Asp
50 55 60
Ser Leu Lys Gln Gln Ala Val Asn Arg Tyr Ala Gly Asp Lys Lys Ser
65 70 75 80
Ser Ile Ile Ala Ile Gly Leu Thr Ile His Asn Ala Pro Val Glu Leu
85 90 95
Arg Glu Lys Leu Ala Val Pro Glu Ala Glu Trp Pro Arg Ala Ile Glu
100 105 110
Glu Leu Cys Gln Phe Pro His Ile Glu Glu Ala Ala Val Leu Ser Thr
115 120 125
Cys Asn Arg Met Glu Leu Tyr Val Val Gly Leu Ser Trp His Arg Gly
130 135 140
Val Arg Glu Val Glu Glu Trp Leu Ser Arg Thr Ser Gly Val Pro Leu
145 150 155 160
Asp Glu Leu Arg Pro Tyr Leu Phe Leu Leu Arg Asp Arg Asp Ala Thr
165 170 175
His His Leu Met Arg Val Ser Gly Gly Leu Asp Ser Leu Val Met Gly
180 185 190
Glu Gly Gln Ile Leu Ala Gln Val Arg Gln Val Tyr Lys Val Gly Gln
195 200 205
Asn Cys Pro Gly Phe Gly Arg His Leu Asn Gly Leu Phe Lys Gln Ala
210 215 220
Ile Thr Ala Gly Lys Arg Val Arg Ala Glu Thr Ser Ile Ser Thr Gly
225 230 235 240
Ser Val Ser Val Ser Ser Ala Ala Val Glu Leu Ala Gln Leu Lys Leu
245 250 255
Pro Thr His Asn Trp Ser Asp Ala Lys Val Cys Ile Ile Gly Ala Gly
260 265 270
Lys Met Ser Thr Leu Leu Val Lys His Leu Gln Ser Lys Gly Cys Lys
275 280 285
Glu Val Thr Val Leu Asn Arg Ser Leu Pro Arg Ala Gln Ala Leu Ala
290 295 300
Glu Glu Phe Pro Glu Val Lys Phe Asn Ile His Leu Met Pro Asp Leu
305 310 315 320
Leu Gln Cys Val Glu Ala Ser Asp Val Ile Phe Ala Ala Ser Gly Ser
325 330 335
Glu Glu Ile Leu Ile His Lys Glu His Val Glu Ala Met Ser Lys Pro
340 345 350
Ser Asp Val Val Gly Ser Lys Arg Arg Phe Val Asp Ile Ser Val Pro
355 360 365
Arg Asn Ile Ala Pro Ala Ile Asn Glu Leu Glu His Gly Ile Val Tyr
370 375 380
Asn Val Asp Asp Leu Lys Glu Val Val Ala Ala Asn Lys Glu Gly Arg
385 390 395 400
Ala Gln Ala Ala Ala Glu Ala Glu Val Leu Ile Arg Glu Glu Gln Arg
405 410 415
Ala Phe Glu Ala Trp Arg Asp Ser Leu Glu Thr Val Pro Thr Ile Lys
420 425 430
Ala Leu Arg Ser Lys Ala Glu Thr Ile Arg Ala Ala Glu Phe Glu Lys
435 440 445
Ala Val Ser Arg Leu Gly Glu Gly Leu Ser Lys Lys Gln Leu Lys Ala
450 455 460
Val Glu Glu Leu Ser Lys Gly Ile Val Asn Lys Leu Leu His Gly Pro
465 470 475 480
Met Thr Ala Leu Arg Cys Asp Gly Thr Asp Pro Asp Ala Val Gly Gln
485 490 495
Thr Leu Ala Asn Met Glu Ala Leu Glu Arg Met Phe Gln Leu Ser Glu
500 505 510
Val Asp Val Ala Ala Leu Ala Gly Lys Gln
515 520
<210> 13
<211> 1779
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 13
atgttatact cacaatttaa acattcggtg cctttaggcc gtaagtctcc ccttctttca 60
gggggccccc cttctggggg tcgcccaaca acggctgcct caggcctagg tcgcaacgtg 120
gccgtaagaa ttgggacccc gttgggcttt gcccttcggg cccaggtaat tatggcagct 180
gcgggcaata ctagcggtgc gccgcacccc gtaggggagt cccagcctgc gttgtcccag 240
gtggattctc aacttgtaat tgagtgtgaa acaggaaatt accatacttt ttgcccaatt 300
agttgtgttt cttggttata ccaaaaaatt gaagatagtt ttttcttagt tattggtaca 360
aaaacgtgtg ggtatttttt acaaaatgct ttaggggtta tgatttttgc cgaacctcgt 420
tacgctatgg cggaattaga agaaagcgat atttcggcgc aattaaatga ttacaaagaa 480
ttaaaacgtc tatgtttaca aattaaacaa gaccgtaacc caagtgttat tgtgtggatt 540
ggcacatgca caaccgaaat tattaaaatg gatttagaag gtatggcacc gaaactagaa 600
gctgaaatcg gtattccaat tgtggtagca cgcgcaaatg gacttgatta tgcttttaca 660
caaggtgaag atactgtttt agctgcgatg gtccaaaaat gcccggaatt aggcgctatt 720
ccagctattg tacctcagat tccttctgac tctcgtacac ttagccaact atctgtagcg 780
gcttcggtac ccgaaaacag tgcgtctggg ccagaagggg agccttcact agcccagaag 840
ggaatggatt ctaagttaac aaacaactct ccatgccgag tagattctgt ctcagaatct 900
accccggcgt ttcctggacg tgctccgcac gtcgggaaaa gtactcctca aaatttagtt 960
ttatttggtt cattacctag cacgatggca aatcaactgg agtttgaatt aaaacgccaa 1020
ggtattaatg ttactgggtg gttacctgcg gctcgctatt catctttacc tgcattaggt 1080
gaaaacgtgt atgtttgtgg gattaatcca tttttaagtc gaactgctac ttctttaatg 1140
cgtcgtcgta aatgcaaatt aatttcagct cctttcccaa ttggtccaga tggtacaaaa 1200
gcttgggtcg aaaaaatttg taatgttttc ggtgttacac caactggttt agaagatcgt 1260
gaacgtcttg tttgggaagg tttaaaagat tatttaaatt tcgtaaaagg gaaatctgtt 1320
ttctttatgg gtgataatct gttagaaatt tcattagccc gttttttaat tcgctgtggt 1380
atgaccgttt atgaaatcgg tattccgtac atggaccaac gatttcaagc tggggaatta 1440
gaattattaa aaaaaacatg catggaaatg aacgtgcccc taccgcgtat tgttgaaaaa 1500
cctgataatt actatcaaat tcaacgtatt aaagaattac aaccagattt agttattacc 1560
ggcatggccc atgcaaaccc actggaagcg cgcggcatta ctacgaaatg gtccgttgaa 1620
tttacgtttg cgcaaattca tgggtttggc aacgcacgtg atatcttaga attagttaca 1680
aaaccgttac gtcgtaataa aaatctatct aaatatcaat ttccgttaga tagctgggac 1740
aagcctgctt ccgtaggcgc tcacgaactg tcggcctaa 1779
<210> 14
<211> 592
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 14
Met Leu Tyr Ser Gln Phe Lys His Ser Val Pro Leu Gly Arg Lys Ser
1 5 10 15
Pro Leu Leu Ser Gly Gly Pro Pro Ser Gly Gly Arg Pro Thr Thr Ala
20 25 30
Ala Ser Gly Leu Gly Arg Asn Val Ala Val Arg Ile Gly Thr Pro Leu
35 40 45
Gly Phe Ala Leu Arg Ala Gln Val Ile Met Ala Ala Ala Gly Asn Thr
50 55 60
Ser Gly Ala Pro His Pro Val Gly Glu Ser Gln Pro Ala Leu Ser Gln
65 70 75 80
Val Asp Ser Gln Leu Val Ile Glu Cys Glu Thr Gly Asn Tyr His Thr
85 90 95
Phe Cys Pro Ile Ser Cys Val Ser Trp Leu Tyr Gln Lys Ile Glu Asp
100 105 110
Ser Phe Phe Leu Val Ile Gly Thr Lys Thr Cys Gly Tyr Phe Leu Gln
115 120 125
Asn Ala Leu Gly Val Met Ile Phe Ala Glu Pro Arg Tyr Ala Met Ala
130 135 140
Glu Leu Glu Glu Ser Asp Ile Ser Ala Gln Leu Asn Asp Tyr Lys Glu
145 150 155 160
Leu Lys Arg Leu Cys Leu Gln Ile Lys Gln Asp Arg Asn Pro Ser Val
165 170 175
Ile Val Trp Ile Gly Thr Cys Thr Thr Glu Ile Ile Lys Met Asp Leu
180 185 190
Glu Gly Met Ala Pro Lys Leu Glu Ala Glu Ile Gly Ile Pro Ile Val
195 200 205
Val Ala Arg Ala Asn Gly Leu Asp Tyr Ala Phe Thr Gln Gly Glu Asp
210 215 220
Thr Val Leu Ala Ala Met Val Gln Lys Cys Pro Glu Leu Gly Ala Ile
225 230 235 240
Pro Ala Ile Val Pro Gln Ile Pro Ser Asp Ser Arg Thr Leu Ser Gln
245 250 255
Leu Ser Val Ala Ala Ser Val Pro Glu Asn Ser Ala Ser Gly Pro Glu
260 265 270
Gly Glu Pro Ser Leu Ala Gln Lys Gly Met Asp Ser Lys Leu Thr Asn
275 280 285
Asn Ser Pro Cys Arg Val Asp Ser Val Ser Glu Ser Thr Pro Ala Phe
290 295 300
Pro Gly Arg Ala Pro His Val Gly Lys Ser Thr Pro Gln Asn Leu Val
305 310 315 320
Leu Phe Gly Ser Leu Pro Ser Thr Met Ala Asn Gln Leu Glu Phe Glu
325 330 335
Leu Lys Arg Gln Gly Ile Asn Val Thr Gly Trp Leu Pro Ala Ala Arg
340 345 350
Tyr Ser Ser Leu Pro Ala Leu Gly Glu Asn Val Tyr Val Cys Gly Ile
355 360 365
Asn Pro Phe Leu Ser Arg Thr Ala Thr Ser Leu Met Arg Arg Arg Lys
370 375 380
Cys Lys Leu Ile Ser Ala Pro Phe Pro Ile Gly Pro Asp Gly Thr Lys
385 390 395 400
Ala Trp Val Glu Lys Ile Cys Asn Val Phe Gly Val Thr Pro Thr Gly
405 410 415
Leu Glu Asp Arg Glu Arg Leu Val Trp Glu Gly Leu Lys Asp Tyr Leu
420 425 430
Asn Phe Val Lys Gly Lys Ser Val Phe Phe Met Gly Asp Asn Leu Leu
435 440 445
Glu Ile Ser Leu Ala Arg Phe Leu Ile Arg Cys Gly Met Thr Val Tyr
450 455 460
Glu Ile Gly Ile Pro Tyr Met Asp Gln Arg Phe Gln Ala Gly Glu Leu
465 470 475 480
Glu Leu Leu Lys Lys Thr Cys Met Glu Met Asn Val Pro Leu Pro Arg
485 490 495
Ile Val Glu Lys Pro Asp Asn Tyr Tyr Gln Ile Gln Arg Ile Lys Glu
500 505 510
Leu Gln Pro Asp Leu Val Ile Thr Gly Met Ala His Ala Asn Pro Leu
515 520 525
Glu Ala Arg Gly Ile Thr Thr Lys Trp Ser Val Glu Phe Thr Phe Ala
530 535 540
Gln Ile His Gly Phe Gly Asn Ala Arg Asp Ile Leu Glu Leu Val Thr
545 550 555 560
Lys Pro Leu Arg Arg Asn Lys Asn Leu Ser Lys Tyr Gln Phe Pro Leu
565 570 575
Asp Ser Trp Asp Lys Pro Ala Ser Val Gly Ala His Glu Leu Ser Ala
580 585 590
<210> 15
<211> 1644
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 15
atgaaattag cgtattggat gtatgcggga ccggctcata ttggaacatt acgagttgca 60
agctcgtttc gaaatgtgca tgctattatg catgctccct taggcgatga ttattttaac 120
gtaatgcgtt caatgttaga acgtgaacgt gattttacgc cagtgacggc aagtattgtt 180
gatcgtcatg ttttagctcg tggttcacaa gaaaaagttg ttgaaaacat tcaacgaaaa 240
gataaagaag aatgtccgga tttaatttta ttaacaccaa catgtacctc aagtattttg 300
caagaagatt tacaaaattt tgtaaatcgc gcggccgaag tagcaaagcg ttcggatgtt 360
ttattagctg acgttaacca ttaccgagtg aatgaattac aagcggctga ccgtacgtta 420
gagcaaattg tacgctttta tttagaaaaa gaagtaaata aacttcacgc ggagttaggc 480
ggccttaaaa aaccgcttcg ctttgcccag cgtacccaaa agccgtctgc caatatttta 540
ggcatgttta cactaggttt ccataatcaa catgactgtc gtgaattaaa acgtttatta 600
aatgatttag gtatcgaagt caatgaagtg attcctgaag gtagttttgt acatggatta 660
aaaaatttac caaaagcgtg gtttaacatc gtcccgtatc gtgaagttgg tttaatgacg 720
gcaatttatt tagaaaaaga atttggcatg ccttatacct caatcacgcc aatgggcatt 780
attgacaccg cggcgtttat tcgtgaaatt gcggccattt gtagtcaaat tagcacttca 840
caggcatcta caaactcaac tgaaggactc cagaggggag aaaatgtcag tttaactgaa 900
actaattcga ttatttttaa taaagcaaaa tatgaacaat acattaatca acaaacgcat 960
tttgtttctc aagcagcttg gttttcacgt tctattgact gtcaaaattt aaccggtaaa 1020
aaaaccgttg tgtttggtga tgcaactcac gcggcaagta tgacgaaaat tcttgtgcgc 1080
gaaatgggta ttcatgttgt ttgcgcgggc acgtattgta aacatgatgc agattggttt 1140
agagagcaag tttcaggttt ttgtgatcaa gttttaatta cagatgatca cagccaaatt 1200
gcggaaatca ttgctcaaat tgaacctgca gccatttttg gtacacaaat ggaacgtcat 1260
gttgggaaaa ggttagatat tccttgtggg gttatttctg caccggtaca tattcaaaac 1320
ttcccactag gctttagacc gtttttaggg tatgaaggta ctaatcaaat ttccgattta 1380
gtttataatt cgtttagttt aggtatggaa gatcacttac tagaaatttt caacggtcat 1440
gacaataaag aagttattac acgttcgtat tcttcagaaa ctgatttaga atggacaaaa 1500
gaagcattag atgaactagc tcgtgttcct ggttttgttc gttcaaaagt taaacgtaat 1560
actgaaaaat ttgcgcgtac aaataaaaat caagttatta ctattgaagt tatgtacgca 1620
gctaaagaag cggtatcagc gtaa 1644
<210> 16
<211> 547
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 16
Met Lys Leu Ala Tyr Trp Met Tyr Ala Gly Pro Ala His Ile Gly Thr
1 5 10 15
Leu Arg Val Ala Ser Ser Phe Arg Asn Val His Ala Ile Met His Ala
20 25 30
Pro Leu Gly Asp Asp Tyr Phe Asn Val Met Arg Ser Met Leu Glu Arg
35 40 45
Glu Arg Asp Phe Thr Pro Val Thr Ala Ser Ile Val Asp Arg His Val
50 55 60
Leu Ala Arg Gly Ser Gln Glu Lys Val Val Glu Asn Ile Gln Arg Lys
65 70 75 80
Asp Lys Glu Glu Cys Pro Asp Leu Ile Leu Leu Thr Pro Thr Cys Thr
85 90 95
Ser Ser Ile Leu Gln Glu Asp Leu Gln Asn Phe Val Asn Arg Ala Ala
100 105 110
Glu Val Ala Lys Arg Ser Asp Val Leu Leu Ala Asp Val Asn His Tyr
115 120 125
Arg Val Asn Glu Leu Gln Ala Ala Asp Arg Thr Leu Glu Gln Ile Val
130 135 140
Arg Phe Tyr Leu Glu Lys Glu Val Asn Lys Leu His Ala Glu Leu Gly
145 150 155 160
Gly Leu Lys Lys Pro Leu Arg Phe Ala Gln Arg Thr Gln Lys Pro Ser
165 170 175
Ala Asn Ile Leu Gly Met Phe Thr Leu Gly Phe His Asn Gln His Asp
180 185 190
Cys Arg Glu Leu Lys Arg Leu Leu Asn Asp Leu Gly Ile Glu Val Asn
195 200 205
Glu Val Ile Pro Glu Gly Ser Phe Val His Gly Leu Lys Asn Leu Pro
210 215 220
Lys Ala Trp Phe Asn Ile Val Pro Tyr Arg Glu Val Gly Leu Met Thr
225 230 235 240
Ala Ile Tyr Leu Glu Lys Glu Phe Gly Met Pro Tyr Thr Ser Ile Thr
245 250 255
Pro Met Gly Ile Ile Asp Thr Ala Ala Phe Ile Arg Glu Ile Ala Ala
260 265 270
Ile Cys Ser Gln Ile Ser Thr Ser Gln Ala Ser Thr Asn Ser Thr Glu
275 280 285
Gly Leu Gln Arg Gly Glu Asn Val Ser Leu Thr Glu Thr Asn Ser Ile
290 295 300
Ile Phe Asn Lys Ala Lys Tyr Glu Gln Tyr Ile Asn Gln Gln Thr His
305 310 315 320
Phe Val Ser Gln Ala Ala Trp Phe Ser Arg Ser Ile Asp Cys Gln Asn
325 330 335
Leu Thr Gly Lys Lys Thr Val Val Phe Gly Asp Ala Thr His Ala Ala
340 345 350
Ser Met Thr Lys Ile Leu Val Arg Glu Met Gly Ile His Val Val Cys
355 360 365
Ala Gly Thr Tyr Cys Lys His Asp Ala Asp Trp Phe Arg Glu Gln Val
370 375 380
Ser Gly Phe Cys Asp Gln Val Leu Ile Thr Asp Asp His Ser Gln Ile
385 390 395 400
Ala Glu Ile Ile Ala Gln Ile Glu Pro Ala Ala Ile Phe Gly Thr Gln
405 410 415
Met Glu Arg His Val Gly Lys Arg Leu Asp Ile Pro Cys Gly Val Ile
420 425 430
Ser Ala Pro Val His Ile Gln Asn Phe Pro Leu Gly Phe Arg Pro Phe
435 440 445
Leu Gly Tyr Glu Gly Thr Asn Gln Ile Ser Asp Leu Val Tyr Asn Ser
450 455 460
Phe Ser Leu Gly Met Glu Asp His Leu Leu Glu Ile Phe Asn Gly His
465 470 475 480
Asp Asn Lys Glu Val Ile Thr Arg Ser Tyr Ser Ser Glu Thr Asp Leu
485 490 495
Glu Trp Thr Lys Glu Ala Leu Asp Glu Leu Ala Arg Val Pro Gly Phe
500 505 510
Val Arg Ser Lys Val Lys Arg Asn Thr Glu Lys Phe Ala Arg Thr Asn
515 520 525
Lys Asn Gln Val Ile Thr Ile Glu Val Met Tyr Ala Ala Lys Glu Ala
530 535 540
Val Ser Ala
545
<210> 17
<211> 957
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 17
atgaaattag cagtttatgg caaaggtggt attggtaaat ccacaacaag ttgtaacatt 60
tcaattgcat tagcaaaacg tggcaaaaaa gtattacaaa ttggttgtga tccaaaacac 120
gatagtactt ttacattaac cggtttttta attccaacaa ttattgatac tttacaaagt 180
aaagattatc attacgaaga tgtttggccg gaagatgtta tttaccaagg ctacgggagt 240
gtggattgtg ttgaagcagg tggcccgcca gccggcgccg gctgtggtgg gtatgttgtt 300
ggtgaaacag ttaaattatt aaaagaatta aatgcatttt atgaatatga tgttattctg 360
tttgatgttt taggggatgt tgtatgtggt gggtttgctg cacctttaaa ttacgccgac 420
tattgcatta ttgtcacaga taatggcttt gatgcgttat ttgccgcaaa ccgtattgct 480
gcttcagtgc gcgaaaaagc gcgcattcac ccattacgtt tagctgggtt aattgggaat 540
cgtacagcca aacgcgattt aatcgataaa tacgttgaag cgtgcccgat gccagtctta 600
gaggtattac cgttaattga agacattcgt gtgtcacgcg taaaaggtaa aacattattt 660
gaaatggcag aacatgattc atcattacac tacatttgtg acttttattt aaatattgcg 720
gatcaattat taactgaacc agaaggtgtt gttccgcgcg aattagcaga ccgtgaatta 780
tttactctat tatcagattt ctatttaaac gctgggactc ctagccctag tggatctgag 840
ttcggctcag gcgcccttag cggaacgagc ggcgaaacag ctcccggtaa tatgggtcag 900
cacatgagta acgcagtaaa aacaaacgaa caggaaatga atttctttct tgtgtaa 957
<210> 18
<211> 318
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 18
Met Lys Leu Ala Val Tyr Gly Lys Gly Gly Ile Gly Lys Ser Thr Thr
1 5 10 15
Ser Cys Asn Ile Ser Ile Ala Leu Ala Lys Arg Gly Lys Lys Val Leu
20 25 30
Gln Ile Gly Cys Asp Pro Lys His Asp Ser Thr Phe Thr Leu Thr Gly
35 40 45
Phe Leu Ile Pro Thr Ile Ile Asp Thr Leu Gln Ser Lys Asp Tyr His
50 55 60
Tyr Glu Asp Val Trp Pro Glu Asp Val Ile Tyr Gln Gly Tyr Gly Ser
65 70 75 80
Val Asp Cys Val Glu Ala Gly Gly Pro Pro Ala Gly Ala Gly Cys Gly
85 90 95
Gly Tyr Val Val Gly Glu Thr Val Lys Leu Leu Lys Glu Leu Asn Ala
100 105 110
Phe Tyr Glu Tyr Asp Val Ile Leu Phe Asp Val Leu Gly Asp Val Val
115 120 125
Cys Gly Gly Phe Ala Ala Pro Leu Asn Tyr Ala Asp Tyr Cys Ile Ile
130 135 140
Val Thr Asp Asn Gly Phe Asp Ala Leu Phe Ala Ala Asn Arg Ile Ala
145 150 155 160
Ala Ser Val Arg Glu Lys Ala Arg Ile His Pro Leu Arg Leu Ala Gly
165 170 175
Leu Ile Gly Asn Arg Thr Ala Lys Arg Asp Leu Ile Asp Lys Tyr Val
180 185 190
Glu Ala Cys Pro Met Pro Val Leu Glu Val Leu Pro Leu Ile Glu Asp
195 200 205
Ile Arg Val Ser Arg Val Lys Gly Lys Thr Leu Phe Glu Met Ala Glu
210 215 220
His Asp Ser Ser Leu His Tyr Ile Cys Asp Phe Tyr Leu Asn Ile Ala
225 230 235 240
Asp Gln Leu Leu Thr Glu Pro Glu Gly Val Val Pro Arg Glu Leu Ala
245 250 255
Asp Arg Glu Leu Phe Thr Leu Leu Ser Asp Phe Tyr Leu Asn Ala Gly
260 265 270
Thr Pro Ser Pro Ser Gly Ser Glu Phe Gly Ser Gly Ala Leu Ser Gly
275 280 285
Thr Ser Gly Glu Thr Ala Pro Gly Asn Met Gly Gln His Met Ser Asn
290 295 300
Ala Val Lys Thr Asn Glu Gln Glu Met Asn Phe Phe Leu Val
305 310 315
<210> 19
<211> 3762
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 19
atgcggattg tgctggtcag cggcttcgag agctttaacg tgggcctgta caaggatgcg 60
gcggagctgc tgaagcgctc catgcccaac gtcacactcc aggtgttctc cgaccgcgac 120
ctggcctccg acgccacccg ctcccggctg gaggcggctc tggggcgcgc cgacatcttc 180
ttcggatcac tgctgttcga ctacgaccag gtggagtggc tacgggcccg gctggagcgg 240
gtgcctgtgc ggctagtgtt tgagtcggcg ttggagctca tgagctgcaa caaggtgggg 300
tcgttcatga tgggcggcgg cggtcccggc ggcggcccgc ccggcaaggc gcccggcccg 360
ccgcccgcgg tgaagaaggt tctctccatg tttggaagcg gtcgcgagga ggacaagatg 420
ggcggctcct ccaatgtggt ggccatgttc agttacctgg tggagaccct gatggagcca 480
acgggtgggt tatttggtag ttggtggttg tgttatggtt ggccgtttcg gttgggtgat 540
ctgggctggt atctacaacc cccctcaacc ctcacgcctc caggctacgt gccgccgcct 600
gtggtggaga ctcccgcact gggctgcctc cacccctccg cgcccggccg ctacttcgag 660
tcccccgccg agtacatgaa gtggtacgcc agggagggcc cgctgcgcgg cacgggcgcc 720
ccggtggttg gcgtgctgct gtaccgcaag catgtgatca ccgaccagcc gtacatcccg 780
cagctggtca gccagctgga ggcggagggg ctgctgcccg tgcccatctt catcaacggc 840
gtggaggcgc acaccgtggt tcgcgacctg ctgacctccg tgcacgagca ggatctgctt 900
gcacgcggcg agacgggcgc catcagcccc accctgaagc gggacgcggt caaggtggac 960
gcggtggtga gcaccattgg cttcccgctg gtgggcggcc ccgccggcac catggagggc 1020
gggcggcagg cggaggtggc caaggccatc ctgggcgcca aggacgtgcc gtacacggtg 1080
gcggcgccgc tgcttattca ggacatggag agctggagca gggacggcgt ggcgggtctc 1140
cagagtgtgg tgctgtactc gctgccggag ctggacggcg cagtggacac ggtgccactg 1200
ggggggctgg tgggggacga catctacctg gtgccggagc gggtgaagaa gctggcgggg 1260
cggctcaagt cgtggcgtac gacacgcact aagcatgcct ctgtttgtga cgtccagccc 1320
ctcccccccc cgtctcccct ctccaccctc cctctccctt cctctccctt cctctcactc 1380
tccaccctct tccccctccg cccaaacata acgaggcggg ggctgctggg cgcaagcggg 1440
ccctggagta cccgctgcga cctagctagt ccaactccac ccatccccca atgccgcaat 1500
agctttccgg agatgagcac acacacacac acacacacac acacacacac acacacacac 1560
acacacacac acacacgcca cccacgcaca cacacacaca cacacgctcc ccccgctcgc 1620
cacaccccca tcccacccca cccgcaggag ctgctgacgt accccgcgga ctggggcccg 1680
gccgagtggg gcccgctgcc ctacctgccc gaccccgacg tgctggttcg ccgcatggag 1740
gcgcagtggg gcgagctgcg agcctaccgc ggcctcaaca cctcggcgcg cggcatgttc 1800
caggagtacg gggctgacgt ggtcctgcac ttcggcatgc acggcaccgt ggagtggttg 1860
cctggggcgc cgctggggaa caacggcctc agctggagcg acgtgctgct cggcgagctg 1920
ccaaacgtgt acgtgtacgc tgccaacaac ccctccgagt ccatcgtggc aaagcggcgc 1980
ggctacggca ccatcgtcag ccacaacgtg ccgccgtacg ggcgggcggg tctgtacaag 2040
cagctttcca gcctcaagga gacgcttcag gagtaccgcg aggccgcgca ggccgcacgt 2100
gcccgagcag gagccagcag cagcagcggc agtagcagca gtagcagtag cagcggcagt 2160
ggcagtagca gcagcagtgt ggagctgcgg gcggcgttgg caccggtgtt cgacgcctac 2220
actgaccgcc tgtatgccta cctgcagctg ctggaggggc ggctgttcag cgaggggcta 2280
cacgtactgg gagcgccgcc ggcgccgccg caggtgggtg gttttcccgc gagcttccaa 2340
cggtaccgta aactgcccaa ctgcccaact tctccccaaa cacaggaggc tgtcaagatc 2400
cggaacctgc tcatgcagaa cacgcaggag ctggacgggc tgctcaaggg cctgggtggg 2460
cgttacgtgc ttcccgaggc gggcggcgac ctgctgcggg acgggtcggg cgtgctgccc 2520
accggccgca acatccacgc actggacccc taccgcatgc cctcccccgc cgccatggcc 2580
cgtggggcgg cggtggcggc ggccattctt gagcagcacc gggcggctaa cagcggggcg 2640
tggcccgaga cctgcgccgt caacctgtgg gggctggact ccatcaagag caagggcgag 2700
agtgtggggg tggtgctggc gctggtgggg gcggtgccgg tgcgcgaggg tacgggccgc 2760
gtcgcgcgct tccaactggt gccgctgtca gagttgggcc ggccgcgtgt ggacgtgctt 2820
tgtaacatga gcggcatctt ccgcgactcc ttccagaacg tggtggagct gctcgacgac 2880
ctgtttgcaa gggccgccgc cgccgctgac gagccagatg acatgaactt catcgccaaa 2940
cacgcccgag ccatggagaa gcagggcctg tccgccacct cggcccgcct gttctccaac 3000
ccggctggcg actacgggtc gatggtcaac gagcgagtgg ggcagggcag ctgggccaac 3060
ggcgacgagc tgggtgacac gtgggcggcc cgcaacgcct tcagctacgg ccgaggcaag 3120
gagcgaggca cggcgcggcc cgaggtgctg caggcgctgc tcaagaccac ggaccggatc 3180
gtgcagcaga tcgacagtgt ggagtacggc ctgacagaca tccaggagta ctacgccaac 3240
acgggcgccc tcaagagagc cgccgaggtg gccaaaggcg acccgggccc cggtggccgg 3300
cggccgcgcg tggggtgttc cattgtggag gcctttggcg gcgcgggcgc gggcgcgggc 3360
ggcgccggtg gagcgggcgt gccgccgcct cgcgagctgg aggaggtgct gcgcctggag 3420
taccgctcga agctgctcaa ccccaagtgg gcccgggcca tggcggcgca gggcagcggc 3480
ggcgcctacg agatcagtca gcgcatgacg gcgttggtgg gctggggcgc caccaccgat 3540
ttcagggagg gctgggtgtg ggacccaggc gccatggaca cgtatgtggg cgatgaggag 3600
atggccagca agctcaagaa gaacaacccg caggcctttg ccaacgtgct gcggcgcatg 3660
ctggaggcgg cgggccgcgg catgtggagc cccaacaagg accagctggc acagctcaag 3720
tcgctgtaca gcgagatgga cgaccagctg gagggggtga cg 3762
<210> 20
<211> 1254
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 20
Met Arg Ile Val Leu Val Ser Gly Phe Glu Ser Phe Asn Val Gly Leu
1 5 10 15
Tyr Lys Asp Ala Ala Glu Leu Leu Lys Arg Ser Met Pro Asn Val Thr
20 25 30
Leu Gln Val Phe Ser Asp Arg Asp Leu Ala Ser Asp Ala Thr Arg Ser
35 40 45
Arg Leu Glu Ala Ala Leu Gly Arg Ala Asp Ile Phe Phe Gly Ser Leu
50 55 60
Leu Phe Asp Tyr Asp Gln Val Glu Trp Leu Arg Ala Arg Leu Glu Arg
65 70 75 80
Val Pro Val Arg Leu Val Phe Glu Ser Ala Leu Glu Leu Met Ser Cys
85 90 95
Asn Lys Val Gly Ser Phe Met Met Gly Gly Gly Gly Pro Gly Gly Gly
100 105 110
Pro Pro Gly Lys Ala Pro Gly Pro Pro Pro Ala Val Lys Lys Val Leu
115 120 125
Ser Met Phe Gly Ser Gly Arg Glu Glu Asp Lys Met Gly Gly Ser Ser
130 135 140
Asn Val Val Ala Met Phe Ser Tyr Leu Val Glu Thr Leu Met Glu Pro
145 150 155 160
Thr Gly Gly Leu Phe Gly Ser Trp Trp Leu Cys Tyr Gly Trp Pro Phe
165 170 175
Arg Leu Gly Asp Leu Gly Trp Tyr Leu Gln Pro Pro Ser Thr Leu Thr
180 185 190
Pro Pro Gly Tyr Val Pro Pro Pro Val Val Glu Thr Pro Ala Leu Gly
195 200 205
Cys Leu His Pro Ser Ala Pro Gly Arg Tyr Phe Glu Ser Pro Ala Glu
210 215 220
Tyr Met Lys Trp Tyr Ala Arg Glu Gly Pro Leu Arg Gly Thr Gly Ala
225 230 235 240
Pro Val Val Gly Val Leu Leu Tyr Arg Lys His Val Ile Thr Asp Gln
245 250 255
Pro Tyr Ile Pro Gln Leu Val Ser Gln Leu Glu Ala Glu Gly Leu Leu
260 265 270
Pro Val Pro Ile Phe Ile Asn Gly Val Glu Ala His Thr Val Val Arg
275 280 285
Asp Leu Leu Thr Ser Val His Glu Gln Asp Leu Leu Ala Arg Gly Glu
290 295 300
Thr Gly Ala Ile Ser Pro Thr Leu Lys Arg Asp Ala Val Lys Val Asp
305 310 315 320
Ala Val Val Ser Thr Ile Gly Phe Pro Leu Val Gly Gly Pro Ala Gly
325 330 335
Thr Met Glu Gly Gly Arg Gln Ala Glu Val Ala Lys Ala Ile Leu Gly
340 345 350
Ala Lys Asp Val Pro Tyr Thr Val Ala Ala Pro Leu Leu Ile Gln Asp
355 360 365
Met Glu Ser Trp Ser Arg Asp Gly Val Ala Gly Leu Gln Ser Val Val
370 375 380
Leu Tyr Ser Leu Pro Glu Leu Asp Gly Ala Val Asp Thr Val Pro Leu
385 390 395 400
Gly Gly Leu Val Gly Asp Asp Ile Tyr Leu Val Pro Glu Arg Val Lys
405 410 415
Lys Leu Ala Gly Arg Leu Lys Ser Trp Arg Thr Thr Arg Thr Lys His
420 425 430
Ala Ser Val Cys Asp Val Gln Pro Leu Pro Pro Pro Ser Pro Leu Ser
435 440 445
Thr Leu Pro Leu Pro Ser Ser Pro Phe Leu Ser Leu Ser Thr Leu Phe
450 455 460
Pro Leu Arg Pro Asn Ile Thr Arg Arg Gly Leu Leu Gly Ala Ser Gly
465 470 475 480
Pro Trp Ser Thr Arg Cys Asp Leu Ala Ser Pro Thr Pro Pro Ile Pro
485 490 495
Gln Cys Arg Asn Ser Phe Pro Glu Met Ser Thr His Thr His Thr His
500 505 510
Thr His Thr His Thr His Thr His Thr His Thr His Thr Arg His Pro
515 520 525
Arg Thr His Thr His Thr His Ala Pro Pro Ala Arg His Thr Pro Ile
530 535 540
Pro Pro His Pro Gln Glu Leu Leu Thr Tyr Pro Ala Asp Trp Gly Pro
545 550 555 560
Ala Glu Trp Gly Pro Leu Pro Tyr Leu Pro Asp Pro Asp Val Leu Val
565 570 575
Arg Arg Met Glu Ala Gln Trp Gly Glu Leu Arg Ala Tyr Arg Gly Leu
580 585 590
Asn Thr Ser Ala Arg Gly Met Phe Gln Glu Tyr Gly Ala Asp Val Val
595 600 605
Leu His Phe Gly Met His Gly Thr Val Glu Trp Leu Pro Gly Ala Pro
610 615 620
Leu Gly Asn Asn Gly Leu Ser Trp Ser Asp Val Leu Leu Gly Glu Leu
625 630 635 640
Pro Asn Val Tyr Val Tyr Ala Ala Asn Asn Pro Ser Glu Ser Ile Val
645 650 655
Ala Lys Arg Arg Gly Tyr Gly Thr Ile Val Ser His Asn Val Pro Pro
660 665 670
Tyr Gly Arg Ala Gly Leu Tyr Lys Gln Leu Ser Ser Leu Lys Glu Thr
675 680 685
Leu Gln Glu Tyr Arg Glu Ala Ala Gln Ala Ala Arg Ala Arg Ala Gly
690 695 700
Ala Ser Ser Ser Ser Gly Ser Ser Ser Ser Ser Ser Ser Ser Gly Ser
705 710 715 720
Gly Ser Ser Ser Ser Ser Val Glu Leu Arg Ala Ala Leu Ala Pro Val
725 730 735
Phe Asp Ala Tyr Thr Asp Arg Leu Tyr Ala Tyr Leu Gln Leu Leu Glu
740 745 750
Gly Arg Leu Phe Ser Glu Gly Leu His Val Leu Gly Ala Pro Pro Ala
755 760 765
Pro Pro Gln Val Gly Gly Phe Pro Ala Ser Phe Gln Arg Tyr Arg Lys
770 775 780
Leu Pro Asn Cys Pro Thr Ser Pro Gln Thr Gln Glu Ala Val Lys Ile
785 790 795 800
Arg Asn Leu Leu Met Gln Asn Thr Gln Glu Leu Asp Gly Leu Leu Lys
805 810 815
Gly Leu Gly Gly Arg Tyr Val Leu Pro Glu Ala Gly Gly Asp Leu Leu
820 825 830
Arg Asp Gly Ser Gly Val Leu Pro Thr Gly Arg Asn Ile His Ala Leu
835 840 845
Asp Pro Tyr Arg Met Pro Ser Pro Ala Ala Met Ala Arg Gly Ala Ala
850 855 860
Val Ala Ala Ala Ile Leu Glu Gln His Arg Ala Ala Asn Ser Gly Ala
865 870 875 880
Trp Pro Glu Thr Cys Ala Val Asn Leu Trp Gly Leu Asp Ser Ile Lys
885 890 895
Ser Lys Gly Glu Ser Val Gly Val Val Leu Ala Leu Val Gly Ala Val
900 905 910
Pro Val Arg Glu Gly Thr Gly Arg Val Ala Arg Phe Gln Leu Val Pro
915 920 925
Leu Ser Glu Leu Gly Arg Pro Arg Val Asp Val Leu Cys Asn Met Ser
930 935 940
Gly Ile Phe Arg Asp Ser Phe Gln Asn Val Val Glu Leu Leu Asp Asp
945 950 955 960
Leu Phe Ala Arg Ala Ala Ala Ala Ala Asp Glu Pro Asp Asp Met Asn
965 970 975
Phe Ile Ala Lys His Ala Arg Ala Met Glu Lys Gln Gly Leu Ser Ala
980 985 990
Thr Ser Ala Arg Leu Phe Ser Asn Pro Ala Gly Asp Tyr Gly Ser Met
995 1000 1005
Val Asn Glu Arg Val Gly Gln Gly Ser Trp Ala Asn Gly Asp Glu Leu
1010 1015 1020
Gly Asp Thr Trp Ala Ala Arg Asn Ala Phe Ser Tyr Gly Arg Gly Lys
1025 1030 1035 1040
Glu Arg Gly Thr Ala Arg Pro Glu Val Leu Gln Ala Leu Leu Lys Thr
1045 1050 1055
Thr Asp Arg Ile Val Gln Gln Ile Asp Ser Val Glu Tyr Gly Leu Thr
1060 1065 1070
Asp Ile Gln Glu Tyr Tyr Ala Asn Thr Gly Ala Leu Lys Arg Ala Ala
1075 1080 1085
Glu Val Ala Lys Gly Asp Pro Gly Pro Gly Gly Arg Arg Pro Arg Val
1090 1095 1100
Gly Cys Ser Ile Val Glu Ala Phe Gly Gly Ala Gly Ala Gly Ala Gly
1105 1110 1115 1120
Gly Ala Gly Gly Ala Gly Val Pro Pro Pro Arg Glu Leu Glu Glu Val
1125 1130 1135
Leu Arg Leu Glu Tyr Arg Ser Lys Leu Leu Asn Pro Lys Trp Ala Arg
1140 1145 1150
Ala Met Ala Ala Gln Gly Ser Gly Gly Ala Tyr Glu Ile Ser Gln Arg
1155 1160 1165
Met Thr Ala Leu Val Gly Trp Gly Ala Thr Thr Asp Phe Arg Glu Gly
1170 1175 1180
Trp Val Trp Asp Pro Gly Ala Met Asp Thr Tyr Val Gly Asp Glu Glu
1185 1190 1195 1200
Met Ala Ser Lys Leu Lys Lys Asn Asn Pro Gln Ala Phe Ala Asn Val
1205 1210 1215
Leu Arg Arg Met Leu Glu Ala Ala Gly Arg Gly Met Trp Ser Pro Asn
1220 1225 1230
Lys Asp Gln Leu Ala Gln Leu Lys Ser Leu Tyr Ser Glu Met Asp Asp
1235 1240 1245
Gln Leu Glu Gly Val Thr
1250
<210> 21
<211> 1254
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 21
atggccctga acatgcgtgt ttcctcttcc aaggtcgctg ccaagcagca gggccgcatc 60
tccgcggtgc cggttgtgtc gagcaaggtg gcctcctccg cccgcgtggc ccccttccag 120
ggcgctcccg tggccgcgca gcgcgctgct ctgctggtgc gcgccgctgc cgctactgag 180
gtcaaggctg ctgagggccg cactgagaag gagctgggcc aggcccgccc catcttcccc 240
ttcaccgcca tcgtgggcca ggatgagatg aagctggcgc tgattctgaa cgtgatcgac 300
cccaagatcg gtggtgtcat gatcatgggc gaccgtggca ctggcaagtc caccaccatt 360
cgtgccctgg cggatctgct gcccgagatg caggtggttg ccaacgaccc ctttaactcg 420
gaccccaccg accccgagct gatgagcgag gaggtgcgca accgcgtcaa ggccggcgag 480
cagctgcccg tgtcttccaa gaagattccc atggtggacc tgcccctggg cgccactgag 540
gaccgcgtgt gcggcaccat cgacatcgag aaggcgctga ccgagggtgt caaggcgttc 600
gagcccggcc tgctggccaa ggccaaccgc ggcatcctgt acgtggatga ggtcaacctg 660
ctggacgacc acctggtcga tgtgctgctg gactcggccg cctccggctg gaacaccgtg 720
gagcgcgagg gtatctccat cagccacccc gcccgcttca tcctggtcgg ctcgggcaac 780
cccgaggagg gtgagctgcg cccccagctg ctggatcgct tcggcatgca cgcccagatc 840
ggcaccgtca aggacccccg cctgcgtgtg cagatcgtgt cgcagcgctc gaccttcgac 900
gagaaccccg ccgccttccg caaggactac gaggccggcc agatggcgct gacccagcgc 960
atcgtggacg cgcgcaagct gctgaagcag ggcgaggtca actacgactt ccgcgtcaag 1020
atcagccaga tctgctcgga cctgaacgtg gacggcatcc gcggcgacat cgtgaccaac 1080
cgcgccgcca aggccctggc cgccttcgag ggccgcaccg aggtgacccc cgaggacatc 1140
taccgtgtca ttcccctgtg cctgcgccac cgcctccgga aagaccccct ggctgagatc 1200
gacgacggtg accgcgtgcg tgagatcttc aagcaggtgt tcggcatgga gtaa 1254
<210> 22
<211> 417
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 22
Met Ala Leu Asn Met Arg Val Ser Ser Ser Lys Val Ala Ala Lys Gln
1 5 10 15
Gln Gly Arg Ile Ser Ala Val Pro Val Val Ser Ser Lys Val Ala Ser
20 25 30
Ser Ala Arg Val Ala Pro Phe Gln Gly Ala Pro Val Ala Ala Gln Arg
35 40 45
Ala Ala Leu Leu Val Arg Ala Ala Ala Ala Thr Glu Val Lys Ala Ala
50 55 60
Glu Gly Arg Thr Glu Lys Glu Leu Gly Gln Ala Arg Pro Ile Phe Pro
65 70 75 80
Phe Thr Ala Ile Val Gly Gln Asp Glu Met Lys Leu Ala Leu Ile Leu
85 90 95
Asn Val Ile Asp Pro Lys Ile Gly Gly Val Met Ile Met Gly Asp Arg
100 105 110
Gly Thr Gly Lys Ser Thr Thr Ile Arg Ala Leu Ala Asp Leu Leu Pro
115 120 125
Glu Met Gln Val Val Ala Asn Asp Pro Phe Asn Ser Asp Pro Thr Asp
130 135 140
Pro Glu Leu Met Ser Glu Glu Val Arg Asn Arg Val Lys Ala Gly Glu
145 150 155 160
Gln Leu Pro Val Ser Ser Lys Lys Ile Pro Met Val Asp Leu Pro Leu
165 170 175
Gly Ala Thr Glu Asp Arg Val Cys Gly Thr Ile Asp Ile Glu Lys Ala
180 185 190
Leu Thr Glu Gly Val Lys Ala Phe Glu Pro Gly Leu Leu Ala Lys Ala
195 200 205
Asn Arg Gly Ile Leu Tyr Val Asp Glu Val Asn Leu Leu Asp Asp His
210 215 220
Leu Val Asp Val Leu Leu Asp Ser Ala Ala Ser Gly Trp Asn Thr Val
225 230 235 240
Glu Arg Glu Gly Ile Ser Ile Ser His Pro Ala Arg Phe Ile Leu Val
245 250 255
Gly Ser Gly Asn Pro Glu Glu Gly Glu Leu Arg Pro Gln Leu Leu Asp
260 265 270
Arg Phe Gly Met His Ala Gln Ile Gly Thr Val Lys Asp Pro Arg Leu
275 280 285
Arg Val Gln Ile Val Ser Gln Arg Ser Thr Phe Asp Glu Asn Pro Ala
290 295 300
Ala Phe Arg Lys Asp Tyr Glu Ala Gly Gln Met Ala Leu Thr Gln Arg
305 310 315 320
Ile Val Asp Ala Arg Lys Leu Leu Lys Gln Gly Glu Val Asn Tyr Asp
325 330 335
Phe Arg Val Lys Ile Ser Gln Ile Cys Ser Asp Leu Asn Val Asp Gly
340 345 350
Ile Arg Gly Asp Ile Val Thr Asn Arg Ala Ala Lys Ala Leu Ala Ala
355 360 365
Phe Glu Gly Arg Thr Glu Val Thr Pro Glu Asp Ile Tyr Arg Val Ile
370 375 380
Pro Leu Cys Leu Arg His Arg Leu Arg Lys Asp Pro Leu Ala Glu Ile
385 390 395 400
Asp Asp Gly Asp Arg Val Arg Glu Ile Phe Lys Gln Val Phe Gly Met
405 410 415
Glu
<210> 23
<211> 1278
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 23
atgcagagtc tccagggtca gcgcgcgttc actgcggtgc gccagggtcg ggcgggtccc 60
ctgcggactc gcctggtcgt gcgctcgtct gttgccttgc catccacgaa agccgcgaag 120
aagccgaact tcccgttcgt caagattcag ggccaggagg agatgaagct tgcactgctg 180
ctgaacgtgg tcgaccccaa catcggcgga gtgcttatta tgggtgaccg cggcactgcc 240
aagtcggtcg cggtccgcgc cctggtggat atgcttcccg acattgacgt ggttgagggc 300
gacgccttca acagctcccc caccgacccc aagttcatgg gccccgacac cctgcagcgc 360
ttccgcaacg gcgagaagct gcccaccgtc cgcatgcgga cccccctggt ggagctgcct 420
ctgggcgcca ccgaggaccg catctgcggc accatcgaca tcgagaaggc gctgacgcag 480
ggcatcaagg cctacgagcc cggcctgctg gccaaggcca accgcggcat cctgtatgtg 540
gacgaggtga acctgctgga tgatggcctg gttgatgtcg tgctggactc gtcggctagc 600
ggcctgaaca ctgtggagcg tgagggtgtg tccattgtgc accctgcccg cttcatcatg 660
attggctcag gcaaccccca ggagggtgag ctgcgcccgc agctgctgga tcgcttcggc 720
atgagcgtca acgtggccac gctgcaggac accaagcagc gcacgcagct ggtgctggac 780
cggcttgcgt acgaggcgga ccctgacgca tttgtggact cgtgcaaggc cgagcagacg 840
gcgctcacgg acaagctgga ggcggcccgc cagcgcctgc ggtccgtcaa gatcagcgag 900
gagctgcaga tcctgatctc ggacatttgc tcgcgcctgg atgtggatgg cctgcgcggt 960
gacattgtga tcaaccgcgc cgccaaggcg cttgtggcct tcgagggccg caccgaggtg 1020
accacgaatg acgtggagcg cgtcatctcg ggctgcctca accaccgcct gcgcaaggac 1080
ccgctggacc ccattgacaa cggcaccaag gtggccatcc tgttcaagcg catgaccgac 1140
cccgagatca tgaagcgcga ggaggaggcc aagaagaagc gcgaggaggc ggccgccaag 1200
gccaaggcgg agggcaaggc ggaccgcccc acgggcgcca aggctggcgc ctgggctggc 1260
ttgccccctc gtcggtaa 1278
<210> 24
<211> 425
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 24
Met Gln Ser Leu Gln Gly Gln Arg Ala Phe Thr Ala Val Arg Gln Gly
1 5 10 15
Arg Ala Gly Pro Leu Arg Thr Arg Leu Val Val Arg Ser Ser Val Ala
20 25 30
Leu Pro Ser Thr Lys Ala Ala Lys Lys Pro Asn Phe Pro Phe Val Lys
35 40 45
Ile Gln Gly Gln Glu Glu Met Lys Leu Ala Leu Leu Leu Asn Val Val
50 55 60
Asp Pro Asn Ile Gly Gly Val Leu Ile Met Gly Asp Arg Gly Thr Ala
65 70 75 80
Lys Ser Val Ala Val Arg Ala Leu Val Asp Met Leu Pro Asp Ile Asp
85 90 95
Val Val Glu Gly Asp Ala Phe Asn Ser Ser Pro Thr Asp Pro Lys Phe
100 105 110
Met Gly Pro Asp Thr Leu Gln Arg Phe Arg Asn Gly Glu Lys Leu Pro
115 120 125
Thr Val Arg Met Arg Thr Pro Leu Val Glu Leu Pro Leu Gly Ala Thr
130 135 140
Glu Asp Arg Ile Cys Gly Thr Ile Asp Ile Glu Lys Ala Leu Thr Gln
145 150 155 160
Gly Ile Lys Ala Tyr Glu Pro Gly Leu Leu Ala Lys Ala Asn Arg Gly
165 170 175
Ile Leu Tyr Val Asp Glu Val Asn Leu Leu Asp Asp Gly Leu Val Asp
180 185 190
Val Val Leu Asp Ser Ser Ala Ser Gly Leu Asn Thr Val Glu Arg Glu
195 200 205
Gly Val Ser Ile Val His Pro Ala Arg Phe Ile Met Ile Gly Ser Gly
210 215 220
Asn Pro Gln Glu Gly Glu Leu Arg Pro Gln Leu Leu Asp Arg Phe Gly
225 230 235 240
Met Ser Val Asn Val Ala Thr Leu Gln Asp Thr Lys Gln Arg Thr Gln
245 250 255
Leu Val Leu Asp Arg Leu Ala Tyr Glu Ala Asp Pro Asp Ala Phe Val
260 265 270
Asp Ser Cys Lys Ala Glu Gln Thr Ala Leu Thr Asp Lys Leu Glu Ala
275 280 285
Ala Arg Gln Arg Leu Arg Ser Val Lys Ile Ser Glu Glu Leu Gln Ile
290 295 300
Leu Ile Ser Asp Ile Cys Ser Arg Leu Asp Val Asp Gly Leu Arg Gly
305 310 315 320
Asp Ile Val Ile Asn Arg Ala Ala Lys Ala Leu Val Ala Phe Glu Gly
325 330 335
Arg Thr Glu Val Thr Thr Asn Asp Val Glu Arg Val Ile Ser Gly Cys
340 345 350
Leu Asn His Arg Leu Arg Lys Asp Pro Leu Asp Pro Ile Asp Asn Gly
355 360 365
Thr Lys Val Ala Ile Leu Phe Lys Arg Met Thr Asp Pro Glu Ile Met
370 375 380
Lys Arg Glu Glu Glu Ala Lys Lys Lys Arg Glu Glu Ala Ala Ala Lys
385 390 395 400
Ala Lys Ala Glu Gly Lys Ala Asp Arg Pro Thr Gly Ala Lys Ala Gly
405 410 415
Ala Trp Ala Gly Leu Pro Pro Arg Arg
420 425
<210> 25
<211> 2304
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 25
atgaagtctc tctgccatga gctcgctggc cccagcgtta ctgggtgcgg ccggcgaagc 60
ctccggaagg ctttcagcgg tgccaagatt gcgcaggtct ctcgccccgc tgtgcttaac 120
agcgtgcagc gccaacagcg tctcgcctgt tctgccgtgg ccgagctctc cgctgctgag 180
ctgcgcgcca tgaaggtgtc tgaggaggac tccaagggct tcgatgcgga tgtgtcgacc 240
cgcctggccc gctcgtaccc tctggcggcc gtggtgggcc aggacaacat caagcaggcg 300
ctgctgctgg gcgccgtgga caccgggctg ggcggcatcg ccatcgccgg tcgccgcggt 360
accgccaagt ccatcatggc tcgcggcctg cacgctctgc tgccgcccat tgaggtggtg 420
gagggcagca tctgcaacgc cgaccccgag gacccccgct cctgggaggc tggcctggct 480
gagaagtatg cgggcggccc tgtgaagacc aagatgcgct cggcgccgtt tgtgcagatc 540
cctctgggtg tgactgagga ccgcttggtg ggcactgtgg acattgaggc gtccatgaag 600
gagggcaaga ctgtgttcca gcccggcctg ctggctgagg cgcaccgcgg catcctgtac 660
gtggacgaga tcaacctgct ggatgacggc attgccaacc tgctgctgtc catcctgtcg 720
gacggagtca acgtggtgga gcgcgagggc atctccatca gccacccctg ccggccgctg 780
ctgattgcca cctacaaccc cgaggagggc cctctgcgtg agcacctgct ggaccgcatc 840
gccattggcc tcagcgccga cgtccccagc accagcgacg agcgcgtcaa ggccattgac 900
gcagccatcc gcttccagga caagccgcag gacactattg acgacaccgc ggagctcacc 960
gacgccctgc gcacctcggt catcctggct cgcgagtacc tgaaggacgt gaccatcgcg 1020
ccggagcagg tgacctacat tgtggaggag gcgcgccgcg gcggagtcca ggggcaccgc 1080
gcggagctgt acgcggtcaa gtgtgccaag gcgtgtgcgg ctctggaggg ccgtgagcgt 1140
gtgaacaagg atgacctgcg ccaggccgtg cagctggtca tcctgccgcg cgccaccatc 1200
ctggaccagc ccccgcccga gcaggagcag cccccgccgc cgcccccgcc ccctcccccg 1260
ccgccgccgc aggaccaaat ggaggacgag gaccaggagg agaaggagga cgagaaggag 1320
gaggaggaga aggagaacga ggaccaggac gagcccgaga tccctcagga gttcatgttt 1380
gagtccgagg gcgtcatcat ggacccctcc atcctcatgt tcgcgcagca gcagcagcgc 1440
gcgcagggcc gctccggccg cgccaagacg ctcatcttca gcgacgaccg cggccgctac 1500
atcaagccca tgctgcccaa gggtgacaag gtcaagcgcc tggcagtgga cgccacgctt 1560
cgcgccgccg cgccctacca gaagattcgc cggcagcagg ccatcagcga gggcaaggtg 1620
cagcgcaagg tgtacgtgga caagccagac atgcgctcca agaagctggc ccgcaaggcc 1680
ggtgcgctgg tgatttttgt tgtggacgcg tccggctcca tggctctgaa ccgcatgagc 1740
gccgccaagg gcgcctgcat gcgcctgctg gctgagtcgt acaccagccg cgaccaggtg 1800
tgcctcatcc ccttctacgg cgacaaggcc gaggtgctgc tgccgccctc caagtccatc 1860
gccatggccc gccgccgcct ggactcgctg ccctgcggcg gcggctcgcc ccttgcgcac 1920
ggcctgtcca cggcggtacg tgtgggcatg caggccagcc aggcgggcga ggtgggccgc 1980
gtcatgatgg tgctcatcac ggacggccgc gccaacgtca gcctggccaa gtccaacgag 2040
gaccccgagg cgctcaagcc cgacgcgccc aagcccaccg ccgactcgct gaaggacgag 2100
gtgcgcgaca tggccaagaa ggccgcgtcc gccggcatca acgtgcttgt cattgacacg 2160
gagaacaagt tcgtgagcac cggctttgcg gaggagatct ccaaggcagc gcagggcaag 2220
tactactacc tgcccaacgc cagcgacgcc gccatcgcgg cggccgcgtc cggcgccatg 2280
gccgcggcca agggcggcta ctag 2304
<210> 26
<211> 767
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 26
Met Lys Ser Leu Cys His Glu Leu Ala Gly Pro Ser Val Thr Gly Cys
1 5 10 15
Gly Arg Arg Ser Leu Arg Lys Ala Phe Ser Gly Ala Lys Ile Ala Gln
20 25 30
Val Ser Arg Pro Ala Val Leu Asn Ser Val Gln Arg Gln Gln Arg Leu
35 40 45
Ala Cys Ser Ala Val Ala Glu Leu Ser Ala Ala Glu Leu Arg Ala Met
50 55 60
Lys Val Ser Glu Glu Asp Ser Lys Gly Phe Asp Ala Asp Val Ser Thr
65 70 75 80
Arg Leu Ala Arg Ser Tyr Pro Leu Ala Ala Val Val Gly Gln Asp Asn
85 90 95
Ile Lys Gln Ala Leu Leu Leu Gly Ala Val Asp Thr Gly Leu Gly Gly
100 105 110
Ile Ala Ile Ala Gly Arg Arg Gly Thr Ala Lys Ser Ile Met Ala Arg
115 120 125
Gly Leu His Ala Leu Leu Pro Pro Ile Glu Val Val Glu Gly Ser Ile
130 135 140
Cys Asn Ala Asp Pro Glu Asp Pro Arg Ser Trp Glu Ala Gly Leu Ala
145 150 155 160
Glu Lys Tyr Ala Gly Gly Pro Val Lys Thr Lys Met Arg Ser Ala Pro
165 170 175
Phe Val Gln Ile Pro Leu Gly Val Thr Glu Asp Arg Leu Val Gly Thr
180 185 190
Val Asp Ile Glu Ala Ser Met Lys Glu Gly Lys Thr Val Phe Gln Pro
195 200 205
Gly Leu Leu Ala Glu Ala His Arg Gly Ile Leu Tyr Val Asp Glu Ile
210 215 220
Asn Leu Leu Asp Asp Gly Ile Ala Asn Leu Leu Leu Ser Ile Leu Ser
225 230 235 240
Asp Gly Val Asn Val Val Glu Arg Glu Gly Ile Ser Ile Ser His Pro
245 250 255
Cys Arg Pro Leu Leu Ile Ala Thr Tyr Asn Pro Glu Glu Gly Pro Leu
260 265 270
Arg Glu His Leu Leu Asp Arg Ile Ala Ile Gly Leu Ser Ala Asp Val
275 280 285
Pro Ser Thr Ser Asp Glu Arg Val Lys Ala Ile Asp Ala Ala Ile Arg
290 295 300
Phe Gln Asp Lys Pro Gln Asp Thr Ile Asp Asp Thr Ala Glu Leu Thr
305 310 315 320
Asp Ala Leu Arg Thr Ser Val Ile Leu Ala Arg Glu Tyr Leu Lys Asp
325 330 335
Val Thr Ile Ala Pro Glu Gln Val Thr Tyr Ile Val Glu Glu Ala Arg
340 345 350
Arg Gly Gly Val Gln Gly His Arg Ala Glu Leu Tyr Ala Val Lys Cys
355 360 365
Ala Lys Ala Cys Ala Ala Leu Glu Gly Arg Glu Arg Val Asn Lys Asp
370 375 380
Asp Leu Arg Gln Ala Val Gln Leu Val Ile Leu Pro Arg Ala Thr Ile
385 390 395 400
Leu Asp Gln Pro Pro Pro Glu Gln Glu Gln Pro Pro Pro Pro Pro Pro
405 410 415
Pro Pro Pro Pro Pro Pro Pro Gln Asp Gln Met Glu Asp Glu Asp Gln
420 425 430
Glu Glu Lys Glu Asp Glu Lys Glu Glu Glu Glu Lys Glu Asn Glu Asp
435 440 445
Gln Asp Glu Pro Glu Ile Pro Gln Glu Phe Met Phe Glu Ser Glu Gly
450 455 460
Val Ile Met Asp Pro Ser Ile Leu Met Phe Ala Gln Gln Gln Gln Arg
465 470 475 480
Ala Gln Gly Arg Ser Gly Arg Ala Lys Thr Leu Ile Phe Ser Asp Asp
485 490 495
Arg Gly Arg Tyr Ile Lys Pro Met Leu Pro Lys Gly Asp Lys Val Lys
500 505 510
Arg Leu Ala Val Asp Ala Thr Leu Arg Ala Ala Ala Pro Tyr Gln Lys
515 520 525
Ile Arg Arg Gln Gln Ala Ile Ser Glu Gly Lys Val Gln Arg Lys Val
530 535 540
Tyr Val Asp Lys Pro Asp Met Arg Ser Lys Lys Leu Ala Arg Lys Ala
545 550 555 560
Gly Ala Leu Val Ile Phe Val Val Asp Ala Ser Gly Ser Met Ala Leu
565 570 575
Asn Arg Met Ser Ala Ala Lys Gly Ala Cys Met Arg Leu Leu Ala Glu
580 585 590
Ser Tyr Thr Ser Arg Asp Gln Val Cys Leu Ile Pro Phe Tyr Gly Asp
595 600 605
Lys Ala Glu Val Leu Leu Pro Pro Ser Lys Ser Ile Ala Met Ala Arg
610 615 620
Arg Arg Leu Asp Ser Leu Pro Cys Gly Gly Gly Ser Pro Leu Ala His
625 630 635 640
Gly Leu Ser Thr Ala Val Arg Val Gly Met Gln Ala Ser Gln Ala Gly
645 650 655
Glu Val Gly Arg Val Met Met Val Leu Ile Thr Asp Gly Arg Ala Asn
660 665 670
Val Ser Leu Ala Lys Ser Asn Glu Asp Pro Glu Ala Leu Lys Pro Asp
675 680 685
Ala Pro Lys Pro Thr Ala Asp Ser Leu Lys Asp Glu Val Arg Asp Met
690 695 700
Ala Lys Lys Ala Ala Ser Ala Gly Ile Asn Val Leu Val Ile Asp Thr
705 710 715 720
Glu Asn Lys Phe Val Ser Thr Gly Phe Ala Glu Glu Ile Ser Lys Ala
725 730 735
Ala Gln Gly Lys Tyr Tyr Tyr Leu Pro Asn Ala Ser Asp Ala Ala Ile
740 745 750
Ala Ala Ala Ala Ser Gly Ala Met Ala Ala Ala Lys Gly Gly Tyr
755 760 765
<210> 27
<211> 4200
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 27
atgcagactt cctcgcttct tggccggcgc acggcccacc cggctgcggg cgcgacgccc 60
aagccggttg cgccctcgcc ccgcgtggct agcacccgcc aggtcgcgtg caatgtggcg 120
actggacccc ggccgcccat gaccaccttc accggtggca acaagggccc tgctaagcag 180
caggtgtcgc tggatctgcg cgacgagggc gctggcatgt tcaccagcac cagcccggag 240
atgcgccgtg tcgtccctga cgatgtgaag ggtcgcgtta aggtgaaggt tgtgtacgtg 300
gtgctggagg cccagtacca gtcggccatc agcgctgcgg tgaagaacat caacgccaag 360
aactccaagg tgtgcttcga ggtggtgggc tacctgctgg aggagctgcg tgaccagaag 420
aacctcgata tgctcaagga ggatgtggcc tctgccaaca tcttcatcgg ctcgctcatc 480
ttcattgagg agcttgccga gaagattgtg gaggcggtga gccccctgcg cgagaagctg 540
gacgcgtgcc tgatcttccc gtccatgccg gcggtcatga agctgaacaa gctgggcacg 600
ttttcgatgg ctcagctggg ccagtcgaag tcggtgttct cggagttcat caagtctgct 660
cgcaagaaca acgacaactt cgaggagggc ttgctgaagc tggtgcgcac cctgcctaag 720
gtgctgaagt atctgccctc ggacaaggcg caggacgcca agaacttcgt gaacagcctg 780
cagtactggc tgggcggtaa ctcggacaac ctggagaacc tgctgctgaa caccgtcagc 840
aactacgtgc ccgctctgaa gggcgtggac ttcagcgtgg ctgagcccac cgcctacccc 900
gatgtgggta tctggcaccc tctggcctcg ggcatgtacg aggacctgaa ggagtacctg 960
aactggtacg acacccgcaa ggacatggtc ttcgccaagg acgcccccgt cattggcctg 1020
gtgctgcagc gctcgcacct ggtgactggc gatgagggcc actacagcgg cgtggtcgct 1080
gagctggaga gccgcggtgc taaggtcatc cccgtctttg ccggtggcct ggacttctcc 1140
gcccccgtca agaagttctt ctacgacccc ctgggctctg gccgcacgtt cgtggacacc 1200
gttgtgtcgc tgaccggctt cgcgctggtg ggcggccccg cgcgccagga cgcgccgaag 1260
gccattgagg cgctgaagaa cctgaacgtg ccctacctgg tgtcgctgcc gctggtgttc 1320
cagaccactg aggagtggct ggacagcgag ctgggcgtgc accccgtcca ggtggctctg 1380
caggttgccc tgcccgagct ggatggtgcc atggagccca tcgtgttcgc tggccgtgac 1440
tcgaacaccg gcaagtcgca ctcgctgccc gaccgcatcg cttcgctgtg cgctcgcgcc 1500
gtgaactggg ccaacctgcg caagaagcgc aacgccgaga agaagctggc cgtcaccgtg 1560
ttcagcttcc cccctgacaa gggcaacgtc ggcactgccg cctacctgaa cgtgttcggc 1620
tccatctacc gcgtgctgaa gaacctgcag cgcgagggct acgacgtggg cgccctgccg 1680
ccctcggagg aggatctgat ccagtcggtg ctgacccaga aggaggccaa gttcaactcg 1740
accgacctgc acatcgccta caagatgaag gtggacgagt accagaagct gtgcccttac 1800
gccgaggcgc tggaggagaa ctggggcaag ccccccggca ccctgaacac caacggccag 1860
gagctgctgg tgtacggccg ccagtacggc aacgtcttca tcggcgtgca gcccaccttc 1920
ggctacgagg gcgacccgat gcgcctgctg ttctcgaagt cggccagccc ccaccacggc 1980
ttcgccgcct actacacctt cctggagaag atcttcaagg ccgacgccgt gctgcacttc 2040
ggcacccacg gctcgctgga gttcatgccc ggcaagcagg tcggcatgtc gggtgtgtgc 2100
taccccgact cgctgatcgg caccatcccc aacctctact actacgccgc caacaacccg 2160
tctgaggcca ccatcgccaa gcgccgctcg tacgccaaca ccatttcgta cctgacgccg 2220
cctgccgaga acgccggcct gtacaagggc ctgaaggagc tgaaggagct gatcagctcg 2280
taccagggca tgcgtgagtc tggccgcgcc gagcagatct gcgccaccat cattgagacc 2340
gccaagctgt gcaacctgga ccgcgacgtg accctgcccg acgctgacgc caaggacctg 2400
accatggaca tgcgcgacag cgttgtgggc caggtgtacc gcaagctgat ggagattgag 2460
tcccgcctgc tgccctgcgg cctgcacgtg gtgggctgcc cgcccaccgc cgaggaggcc 2520
gtggccaccc tggtcaacat cgctgagctg gaccgcccgg acaacaaccc ccccatcaag 2580
ggcatgcccg gcatcctggc ccgcgccatt ggtcgcgaca tcgagtcgat ttacagcggc 2640
aacaacaagg gcgtcctggc tgacgttgac cagctgcagc gcatcaccga ggcctcccgc 2700
acctgcgtgc gcgagttcgt gaaggaccgc accggcctga acggccgcat cggcaccaac 2760
tggatcacca acctgctcaa gttcaccggc ttctacgtgg acccctgggt gcgcggcctg 2820
cagaacggcg agttcgccag cgccaaccgc gaggagctga tcaccctgtt caactacctg 2880
gagttctgcc tgacccaggt ggtcaaggac aacgagctgg gcgccctggt agaggcgctg 2940
aacggccagt acgtcgagcc cggccccggc ggtgacccca tccgcaaccc caacgtgctg 3000
cccaccggca agaacatcca cgccctggac cctcagtcga ttcccactca ggccgcgctg 3060
aagagcgccc gcctggtggt ggaccgcctg ctggaccgcg agcgcgacaa caacggcggc 3120
aagtaccccg agaccatcgc gctggtgctg tggggcactg acaacatcaa gacctacggc 3180
gagtcgctgg cccaggtcat gatgatggtc ggtgtcaagc ccgtggccga cgccctgggc 3240
cgcgtgaaca agctggaggt gatccctctg gaggagctgg gccgcccccg cgtggacgtg 3300
gttgtcaact gctcgggtgt gttccgcgac ctgttcgtga accagatgct gctgctggac 3360
cgcgccatca agctggcggc cgagcaggac gagcccgatg agatgaactt cgtgcgcaag 3420
cacgccaagc agcaggcggc ggagctgggc ctgcagagcc tgcgcgacgc ggccacccgt 3480
gtgttctcca acagctcggg ctcctactcg tccaacgtca acctggcggt ggagaacagc 3540
agctggagcg acgagtcgca gctgcaggag atgtacctga agcgcaagtc gtacgccttc 3600
aactcggacc gccccggcgc cggtggcgag atgcagcgcg acgtgttcga gacggccatg 3660
aagaccgtgg acgtgacctt ccagaacctg gactcgtccg agatctcgct gaccgatgtg 3720
tcgcactact tcgactccga ccccaccaag ctggtggcgt cgctgcgcaa cgacggccgc 3780
acccccaacg cctacatcgc cgacaccacc accgccaacg cgcaggtccg cactctgggt 3840
gagaccgtgc gcctggacgc ccgcaccaag ctgctcaacc ccaagtggta cgagggcatg 3900
cttgcctcgg gctacgaggg cgtgcgcgag atccagaagc gcatgaccaa caccatgggc 3960
tggtcggcca cctcgggcat ggtggacaac tgggtgtacg acgaggccaa ctcgaccttc 4020
atcgaggatg cggccatggc cgagcgcctg atgaacacca accccaacag cttccgcaag 4080
ctggtggcca ccttcctgga ggccaacggc cgcggctact gggacgccaa gcccgagcag 4140
ctggagcgcc tgcgccagct gtacatggac gtggaggaca agattgaggg cgtcgaataa 4200
<210> 28
<211> 1399
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 28
Met Gln Thr Ser Ser Leu Leu Gly Arg Arg Thr Ala His Pro Ala Ala
1 5 10 15
Gly Ala Thr Pro Lys Pro Val Ala Pro Ser Pro Arg Val Ala Ser Thr
20 25 30
Arg Gln Val Ala Cys Asn Val Ala Thr Gly Pro Arg Pro Pro Met Thr
35 40 45
Thr Phe Thr Gly Gly Asn Lys Gly Pro Ala Lys Gln Gln Val Ser Leu
50 55 60
Asp Leu Arg Asp Glu Gly Ala Gly Met Phe Thr Ser Thr Ser Pro Glu
65 70 75 80
Met Arg Arg Val Val Pro Asp Asp Val Lys Gly Arg Val Lys Val Lys
85 90 95
Val Val Tyr Val Val Leu Glu Ala Gln Tyr Gln Ser Ala Ile Ser Ala
100 105 110
Ala Val Lys Asn Ile Asn Ala Lys Asn Ser Lys Val Cys Phe Glu Val
115 120 125
Val Gly Tyr Leu Leu Glu Glu Leu Arg Asp Gln Lys Asn Leu Asp Met
130 135 140
Leu Lys Glu Asp Val Ala Ser Ala Asn Ile Phe Ile Gly Ser Leu Ile
145 150 155 160
Phe Ile Glu Glu Leu Ala Glu Lys Ile Val Glu Ala Val Ser Pro Leu
165 170 175
Arg Glu Lys Leu Asp Ala Cys Leu Ile Phe Pro Ser Met Pro Ala Val
180 185 190
Met Lys Leu Asn Lys Leu Gly Thr Phe Ser Met Ala Gln Leu Gly Gln
195 200 205
Ser Lys Ser Val Phe Ser Glu Phe Ile Lys Ser Ala Arg Lys Asn Asn
210 215 220
Asp Asn Phe Glu Glu Gly Leu Leu Lys Leu Val Arg Thr Leu Pro Lys
225 230 235 240
Val Leu Lys Tyr Leu Pro Ser Asp Lys Ala Gln Asp Ala Lys Asn Phe
245 250 255
Val Asn Ser Leu Gln Tyr Trp Leu Gly Gly Asn Ser Asp Asn Leu Glu
260 265 270
Asn Leu Leu Leu Asn Thr Val Ser Asn Tyr Val Pro Ala Leu Lys Gly
275 280 285
Val Asp Phe Ser Val Ala Glu Pro Thr Ala Tyr Pro Asp Val Gly Ile
290 295 300
Trp His Pro Leu Ala Ser Gly Met Tyr Glu Asp Leu Lys Glu Tyr Leu
305 310 315 320
Asn Trp Tyr Asp Thr Arg Lys Asp Met Val Phe Ala Lys Asp Ala Pro
325 330 335
Val Ile Gly Leu Val Leu Gln Arg Ser His Leu Val Thr Gly Asp Glu
340 345 350
Gly His Tyr Ser Gly Val Val Ala Glu Leu Glu Ser Arg Gly Ala Lys
355 360 365
Val Ile Pro Val Phe Ala Gly Gly Leu Asp Phe Ser Ala Pro Val Lys
370 375 380
Lys Phe Phe Tyr Asp Pro Leu Gly Ser Gly Arg Thr Phe Val Asp Thr
385 390 395 400
Val Val Ser Leu Thr Gly Phe Ala Leu Val Gly Gly Pro Ala Arg Gln
405 410 415
Asp Ala Pro Lys Ala Ile Glu Ala Leu Lys Asn Leu Asn Val Pro Tyr
420 425 430
Leu Val Ser Leu Pro Leu Val Phe Gln Thr Thr Glu Glu Trp Leu Asp
435 440 445
Ser Glu Leu Gly Val His Pro Val Gln Val Ala Leu Gln Val Ala Leu
450 455 460
Pro Glu Leu Asp Gly Ala Met Glu Pro Ile Val Phe Ala Gly Arg Asp
465 470 475 480
Ser Asn Thr Gly Lys Ser His Ser Leu Pro Asp Arg Ile Ala Ser Leu
485 490 495
Cys Ala Arg Ala Val Asn Trp Ala Asn Leu Arg Lys Lys Arg Asn Ala
500 505 510
Glu Lys Lys Leu Ala Val Thr Val Phe Ser Phe Pro Pro Asp Lys Gly
515 520 525
Asn Val Gly Thr Ala Ala Tyr Leu Asn Val Phe Gly Ser Ile Tyr Arg
530 535 540
Val Leu Lys Asn Leu Gln Arg Glu Gly Tyr Asp Val Gly Ala Leu Pro
545 550 555 560
Pro Ser Glu Glu Asp Leu Ile Gln Ser Val Leu Thr Gln Lys Glu Ala
565 570 575
Lys Phe Asn Ser Thr Asp Leu His Ile Ala Tyr Lys Met Lys Val Asp
580 585 590
Glu Tyr Gln Lys Leu Cys Pro Tyr Ala Glu Ala Leu Glu Glu Asn Trp
595 600 605
Gly Lys Pro Pro Gly Thr Leu Asn Thr Asn Gly Gln Glu Leu Leu Val
610 615 620
Tyr Gly Arg Gln Tyr Gly Asn Val Phe Ile Gly Val Gln Pro Thr Phe
625 630 635 640
Gly Tyr Glu Gly Asp Pro Met Arg Leu Leu Phe Ser Lys Ser Ala Ser
645 650 655
Pro His His Gly Phe Ala Ala Tyr Tyr Thr Phe Leu Glu Lys Ile Phe
660 665 670
Lys Ala Asp Ala Val Leu His Phe Gly Thr His Gly Ser Leu Glu Phe
675 680 685
Met Pro Gly Lys Gln Val Gly Met Ser Gly Val Cys Tyr Pro Asp Ser
690 695 700
Leu Ile Gly Thr Ile Pro Asn Leu Tyr Tyr Tyr Ala Ala Asn Asn Pro
705 710 715 720
Ser Glu Ala Thr Ile Ala Lys Arg Arg Ser Tyr Ala Asn Thr Ile Ser
725 730 735
Tyr Leu Thr Pro Pro Ala Glu Asn Ala Gly Leu Tyr Lys Gly Leu Lys
740 745 750
Glu Leu Lys Glu Leu Ile Ser Ser Tyr Gln Gly Met Arg Glu Ser Gly
755 760 765
Arg Ala Glu Gln Ile Cys Ala Thr Ile Ile Glu Thr Ala Lys Leu Cys
770 775 780
Asn Leu Asp Arg Asp Val Thr Leu Pro Asp Ala Asp Ala Lys Asp Leu
785 790 795 800
Thr Met Asp Met Arg Asp Ser Val Val Gly Gln Val Tyr Arg Lys Leu
805 810 815
Met Glu Ile Glu Ser Arg Leu Leu Pro Cys Gly Leu His Val Val Gly
820 825 830
Cys Pro Pro Thr Ala Glu Glu Ala Val Ala Thr Leu Val Asn Ile Ala
835 840 845
Glu Leu Asp Arg Pro Asp Asn Asn Pro Pro Ile Lys Gly Met Pro Gly
850 855 860
Ile Leu Ala Arg Ala Ile Gly Arg Asp Ile Glu Ser Ile Tyr Ser Gly
865 870 875 880
Asn Asn Lys Gly Val Leu Ala Asp Val Asp Gln Leu Gln Arg Ile Thr
885 890 895
Glu Ala Ser Arg Thr Cys Val Arg Glu Phe Val Lys Asp Arg Thr Gly
900 905 910
Leu Asn Gly Arg Ile Gly Thr Asn Trp Ile Thr Asn Leu Leu Lys Phe
915 920 925
Thr Gly Phe Tyr Val Asp Pro Trp Val Arg Gly Leu Gln Asn Gly Glu
930 935 940
Phe Ala Ser Ala Asn Arg Glu Glu Leu Ile Thr Leu Phe Asn Tyr Leu
945 950 955 960
Glu Phe Cys Leu Thr Gln Val Val Lys Asp Asn Glu Leu Gly Ala Leu
965 970 975
Val Glu Ala Leu Asn Gly Gln Tyr Val Glu Pro Gly Pro Gly Gly Asp
980 985 990
Pro Ile Arg Asn Pro Asn Val Leu Pro Thr Gly Lys Asn Ile His Ala
995 1000 1005
Leu Asp Pro Gln Ser Ile Pro Thr Gln Ala Ala Leu Lys Ser Ala Arg
1010 1015 1020
Leu Val Val Asp Arg Leu Leu Asp Arg Glu Arg Asp Asn Asn Gly Gly
1025 1030 1035 1040
Lys Tyr Pro Glu Thr Ile Ala Leu Val Leu Trp Gly Thr Asp Asn Ile
1045 1050 1055
Lys Thr Tyr Gly Glu Ser Leu Ala Gln Val Met Met Met Val Gly Val
1060 1065 1070
Lys Pro Val Ala Asp Ala Leu Gly Arg Val Asn Lys Leu Glu Val Ile
1075 1080 1085
Pro Leu Glu Glu Leu Gly Arg Pro Arg Val Asp Val Val Val Asn Cys
1090 1095 1100
Ser Gly Val Phe Arg Asp Leu Phe Val Asn Gln Met Leu Leu Leu Asp
1105 1110 1115 1120
Arg Ala Ile Lys Leu Ala Ala Glu Gln Asp Glu Pro Asp Glu Met Asn
1125 1130 1135
Phe Val Arg Lys His Ala Lys Gln Gln Ala Ala Glu Leu Gly Leu Gln
1140 1145 1150
Ser Leu Arg Asp Ala Ala Thr Arg Val Phe Ser Asn Ser Ser Gly Ser
1155 1160 1165
Tyr Ser Ser Asn Val Asn Leu Ala Val Glu Asn Ser Ser Trp Ser Asp
1170 1175 1180
Glu Ser Gln Leu Gln Glu Met Tyr Leu Lys Arg Lys Ser Tyr Ala Phe
1185 1190 1195 1200
Asn Ser Asp Arg Pro Gly Ala Gly Gly Glu Met Gln Arg Asp Val Phe
1205 1210 1215
Glu Thr Ala Met Lys Thr Val Asp Val Thr Phe Gln Asn Leu Asp Ser
1220 1225 1230
Ser Glu Ile Ser Leu Thr Asp Val Ser His Tyr Phe Asp Ser Asp Pro
1235 1240 1245
Thr Lys Leu Val Ala Ser Leu Arg Asn Asp Gly Arg Thr Pro Asn Ala
1250 1255 1260
Tyr Ile Ala Asp Thr Thr Thr Ala Asn Ala Gln Val Arg Thr Leu Gly
1265 1270 1275 1280
Glu Thr Val Arg Leu Asp Ala Arg Thr Lys Leu Leu Asn Pro Lys Trp
1285 1290 1295
Tyr Glu Gly Met Leu Ala Ser Gly Tyr Glu Gly Val Arg Glu Ile Gln
1300 1305 1310
Lys Arg Met Thr Asn Thr Met Gly Trp Ser Ala Thr Ser Gly Met Val
1315 1320 1325
Asp Asn Trp Val Tyr Asp Glu Ala Asn Ser Thr Phe Ile Glu Asp Ala
1330 1335 1340
Ala Met Ala Glu Arg Leu Met Asn Thr Asn Pro Asn Ser Phe Arg Lys
1345 1350 1355 1360
Leu Val Ala Thr Phe Leu Glu Ala Asn Gly Arg Gly Tyr Trp Asp Ala
1365 1370 1375
Lys Pro Glu Gln Leu Glu Arg Leu Arg Gln Leu Tyr Met Asp Val Glu
1380 1385 1390
Asp Lys Ile Glu Gly Val Glu
1395
<210> 29
<211> 2064
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 29
atgaaattag cttattggat gtacgcaggt cccgctcata tcggtgtgtt gcgtgttagc 60
agctctttta aaaatgtaca tgccattatg catgctcctt taggagatga ttattttaat 120
gtaatgcgtt ccatgttaga acgtgaacgt gattttacac cagtaacagc cagtattgta 180
gatcgtcatg ttttagcaag aggatcgcaa gaaaaagtgg ttgaaaatat tacgcgaaaa 240
aataaagaag aaactcctga tttaatttta ttaactccta cttgtacgtc aagcatttta 300
caagaagatt tacacaattt tgttgaatcg gcattagcta aaccagtaca aatagatgaa 360
catgcagacc ataaagtaac tcaacaaagt gcactttcaa gtgtatcccc tttactaccg 420
cttgaagaaa atacattaat agtaagtgaa ctagataaga agcttagccc gtctagcaag 480
ttgcatatta atatgcccaa tatttgtatt cccgaaggag aaggggaagg ggagcagact 540
aaaaattcaa tttttgttaa atctgcaact ttaacaaatt tgtcagaaga ggaactatta 600
aatcaagaac atcataccaa aacaagaaat cactctgacg ttattttagc tgatgtaaac 660
cattatcgtg taaatgaatt acaagctgca gatcgtactc ttgaacaaat tgtacgttat 720
tatatttctc aagcacaaaa acaaaattgt ttaaacatta ctaaaacagc caaaccatct 780
gtaaatatta ttggtatttt tactttgggt tttcataatc aacatgattg tcgtgaatta 840
aaacgtttat ttaatgattt aggtattcaa atcaatgaaa tcatacctga aggcggaaat 900
gtacacaact taaaaaaatt accccaagct tggtttaatt ttgtgcccta ccgtgaaatt 960
ggcttaatga ctgctatgta tttaaaatcc gagtttaata tgccttacgt cgcaattact 1020
cctatgggat taattgatac ggctgcttgt attcgttcaa tttgtaaaat cattacaact 1080
caattattaa atcagacggc tacagtgcag gagccatcaa aatttattta cccgaaggcg 1140
acgtcattag aacaaaccaa tattctcgaa acctctcaaa aagaaactat tcttaaagac 1200
aatccagata gcggaaatac cctttctaca actgtagaag aaattgaaac tttatttaat 1260
aaatatatcg atcaacaaac tcgttttgtt tcccaagcag cctggttttc acgttctatt 1320
gactgtcaaa atttaacagg taaaaaagcc gtagttttcg gagatgctac acattcagct 1380
gccatgacaa aattattagc acgtgaaatg ggtattaagg tttcatgcgc tggaacttat 1440
tgcaaacacg atgcggattg gtttagagag caagttagtg ggttttgtga tcaagtttta 1500
attaccgatg atcacacaca agtaggggat atgattgcac aattagaacc tgcagccatt 1560
tttgggacac aaatggaacg tcacgttggt aaacgtttag atattccatg tggtgttata 1620
tctgctcctg tgcatattca aaactttccg ttaggttatc gacctttttt aggttatgaa 1680
ggtacaaatc aaatagctga tttagtgtat aattcattta atcttggaat ggaagaccat 1740
ttattacaaa tttttggagg tcatgattca gaaaacaatt cgtcaattgc aacgcatttg 1800
aatacaaata acgcaataaa tttagcgcca ggatatttac ctgagggaga aggcagtagt 1860
agaacttcaa atgtagtgtc tacaatttct agtgaaaaaa aagccattgt atggtctcca 1920
gaaggtttag cagaattaaa taaagtccca ggatttgttc gaggaaaagt taaacgtaat 1980
acggaaaaat atgctttaca aaaaaattgt tcgatgatta ctgtagaagt tatgtatgca 2040
gcaaaagaag ctttgtcggc ttaa 2064
<210> 30
<211> 687
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 30
Met Lys Leu Ala Tyr Trp Met Tyr Ala Gly Pro Ala His Ile Gly Val
1 5 10 15
Leu Arg Val Ser Ser Ser Phe Lys Asn Val His Ala Ile Met His Ala
20 25 30
Pro Leu Gly Asp Asp Tyr Phe Asn Val Met Arg Ser Met Leu Glu Arg
35 40 45
Glu Arg Asp Phe Thr Pro Val Thr Ala Ser Ile Val Asp Arg His Val
50 55 60
Leu Ala Arg Gly Ser Gln Glu Lys Val Val Glu Asn Ile Thr Arg Lys
65 70 75 80
Asn Lys Glu Glu Thr Pro Asp Leu Ile Leu Leu Thr Pro Thr Cys Thr
85 90 95
Ser Ser Ile Leu Gln Glu Asp Leu His Asn Phe Val Glu Ser Ala Leu
100 105 110
Ala Lys Pro Val Gln Ile Asp Glu His Ala Asp His Lys Val Thr Gln
115 120 125
Gln Ser Ala Leu Ser Ser Val Ser Pro Leu Leu Pro Leu Glu Glu Asn
130 135 140
Thr Leu Ile Val Ser Glu Leu Asp Lys Lys Leu Ser Pro Ser Ser Lys
145 150 155 160
Leu His Ile Asn Met Pro Asn Ile Cys Ile Pro Glu Gly Glu Gly Glu
165 170 175
Gly Glu Gln Thr Lys Asn Ser Ile Phe Val Lys Ser Ala Thr Leu Thr
180 185 190
Asn Leu Ser Glu Glu Glu Leu Leu Asn Gln Glu His His Thr Lys Thr
195 200 205
Arg Asn His Ser Asp Val Ile Leu Ala Asp Val Asn His Tyr Arg Val
210 215 220
Asn Glu Leu Gln Ala Ala Asp Arg Thr Leu Glu Gln Ile Val Arg Tyr
225 230 235 240
Tyr Ile Ser Gln Ala Gln Lys Gln Asn Cys Leu Asn Ile Thr Lys Thr
245 250 255
Ala Lys Pro Ser Val Asn Ile Ile Gly Ile Phe Thr Leu Gly Phe His
260 265 270
Asn Gln His Asp Cys Arg Glu Leu Lys Arg Leu Phe Asn Asp Leu Gly
275 280 285
Ile Gln Ile Asn Glu Ile Ile Pro Glu Gly Gly Asn Val His Asn Leu
290 295 300
Lys Lys Leu Pro Gln Ala Trp Phe Asn Phe Val Pro Tyr Arg Glu Ile
305 310 315 320
Gly Leu Met Thr Ala Met Tyr Leu Lys Ser Glu Phe Asn Met Pro Tyr
325 330 335
Val Ala Ile Thr Pro Met Gly Leu Ile Asp Thr Ala Ala Cys Ile Arg
340 345 350
Ser Ile Cys Lys Ile Ile Thr Thr Gln Leu Leu Asn Gln Thr Ala Thr
355 360 365
Val Gln Glu Pro Ser Lys Phe Ile Tyr Pro Lys Ala Thr Ser Leu Glu
370 375 380
Gln Thr Asn Ile Leu Glu Thr Ser Gln Lys Glu Thr Ile Leu Lys Asp
385 390 395 400
Asn Pro Asp Ser Gly Asn Thr Leu Ser Thr Thr Val Glu Glu Ile Glu
405 410 415
Thr Leu Phe Asn Lys Tyr Ile Asp Gln Gln Thr Arg Phe Val Ser Gln
420 425 430
Ala Ala Trp Phe Ser Arg Ser Ile Asp Cys Gln Asn Leu Thr Gly Lys
435 440 445
Lys Ala Val Val Phe Gly Asp Ala Thr His Ser Ala Ala Met Thr Lys
450 455 460
Leu Leu Ala Arg Glu Met Gly Ile Lys Val Ser Cys Ala Gly Thr Tyr
465 470 475 480
Cys Lys His Asp Ala Asp Trp Phe Arg Glu Gln Val Ser Gly Phe Cys
485 490 495
Asp Gln Val Leu Ile Thr Asp Asp His Thr Gln Val Gly Asp Met Ile
500 505 510
Ala Gln Leu Glu Pro Ala Ala Ile Phe Gly Thr Gln Met Glu Arg His
515 520 525
Val Gly Lys Arg Leu Asp Ile Pro Cys Gly Val Ile Ser Ala Pro Val
530 535 540
His Ile Gln Asn Phe Pro Leu Gly Tyr Arg Pro Phe Leu Gly Tyr Glu
545 550 555 560
Gly Thr Asn Gln Ile Ala Asp Leu Val Tyr Asn Ser Phe Asn Leu Gly
565 570 575
Met Glu Asp His Leu Leu Gln Ile Phe Gly Gly His Asp Ser Glu Asn
580 585 590
Asn Ser Ser Ile Ala Thr His Leu Asn Thr Asn Asn Ala Ile Asn Leu
595 600 605
Ala Pro Gly Tyr Leu Pro Glu Gly Glu Gly Ser Ser Arg Thr Ser Asn
610 615 620
Val Val Ser Thr Ile Ser Ser Glu Lys Lys Ala Ile Val Trp Ser Pro
625 630 635 640
Glu Gly Leu Ala Glu Leu Asn Lys Val Pro Gly Phe Val Arg Gly Lys
645 650 655
Val Lys Arg Asn Thr Glu Lys Tyr Ala Leu Gln Lys Asn Cys Ser Met
660 665 670
Ile Thr Val Glu Val Met Tyr Ala Ala Lys Glu Ala Leu Ser Ala
675 680 685
<210> 31
<211> 882
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 31
atgaaattag ctgtttacgg aaaaggtggt attggaaaat caacgacaag ttgtaatatt 60
tcgattgctt tacgaaaacg tggtaaaaaa gtgttacaaa ttggttgtga tcctaaacat 120
gatagtactt ttacattgac agggttttta attccaacca ttattgatac attaagttct 180
aaagattatc attatgaaga tatttggccc gaagatgtta tttacggagg ttatgggggt 240
gtagattgtg ttgaagctgg aggaccacct gccggtgcgg ggtgtggtgg ttatgttgta 300
ggtgaaacgg taaaactttt aaaagagtta aatgcttttt tcgaatacga tgttatttta 360
tttgatgttt taggtgatgt tgtttgtggt ggctttgctg ctccattaaa ctacgctgat 420
tattgtatta ttgtaactga taatggtttt gatgctttat ttgctgcaaa tcgtattgca 480
gcttcagttc gtgaaaaagc acgtacacat ccattgcgtt tagcgggttt aatcggaaat 540
cgtacatcaa aacgtgattt aattgataaa tatgtagaag cttgtcctat gccagtatta 600
gaagttttac cattaattga agaaattcgt atttcacgtg ttaaaggcaa aactttattt 660
gaaatgtcaa ataaaaataa tatgacttcg gctcatatgg atggctctaa aggtgacaat 720
tctacagtag gagtgtcaga aactccatcg gaagattata tttgtaattt ttatttaaat 780
attgctgatc aattattaac agaaccagaa ggagttattc cacgtgaatt agcagataaa 840
gaacttttta ctcttttatc agatttctat cttaaaattt aa 882
<210> 32
<211> 293
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 32
Met Lys Leu Ala Val Tyr Gly Lys Gly Gly Ile Gly Lys Ser Thr Thr
1 5 10 15
Ser Cys Asn Ile Ser Ile Ala Leu Arg Lys Arg Gly Lys Lys Val Leu
20 25 30
Gln Ile Gly Cys Asp Pro Lys His Asp Ser Thr Phe Thr Leu Thr Gly
35 40 45
Phe Leu Ile Pro Thr Ile Ile Asp Thr Leu Ser Ser Lys Asp Tyr His
50 55 60
Tyr Glu Asp Ile Trp Pro Glu Asp Val Ile Tyr Gly Gly Tyr Gly Gly
65 70 75 80
Val Asp Cys Val Glu Ala Gly Gly Pro Pro Ala Gly Ala Gly Cys Gly
85 90 95
Gly Tyr Val Val Gly Glu Thr Val Lys Leu Leu Lys Glu Leu Asn Ala
100 105 110
Phe Phe Glu Tyr Asp Val Ile Leu Phe Asp Val Leu Gly Asp Val Val
115 120 125
Cys Gly Gly Phe Ala Ala Pro Leu Asn Tyr Ala Asp Tyr Cys Ile Ile
130 135 140
Val Thr Asp Asn Gly Phe Asp Ala Leu Phe Ala Ala Asn Arg Ile Ala
145 150 155 160
Ala Ser Val Arg Glu Lys Ala Arg Thr His Pro Leu Arg Leu Ala Gly
165 170 175
Leu Ile Gly Asn Arg Thr Ser Lys Arg Asp Leu Ile Asp Lys Tyr Val
180 185 190
Glu Ala Cys Pro Met Pro Val Leu Glu Val Leu Pro Leu Ile Glu Glu
195 200 205
Ile Arg Ile Ser Arg Val Lys Gly Lys Thr Leu Phe Glu Met Ser Asn
210 215 220
Lys Asn Asn Met Thr Ser Ala His Met Asp Gly Ser Lys Gly Asp Asn
225 230 235 240
Ser Thr Val Gly Val Ser Glu Thr Pro Ser Glu Asp Tyr Ile Cys Asn
245 250 255
Phe Tyr Leu Asn Ile Ala Asp Gln Leu Leu Thr Glu Pro Glu Gly Val
260 265 270
Ile Pro Arg Glu Leu Ala Asp Lys Glu Leu Phe Thr Leu Leu Ser Asp
275 280 285
Phe Tyr Leu Lys Ile
290
<210> 33
<211> 1410
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 33
atgttagatg gtgccacaac gattttaaat ttaaatagtt tttttgaatg tgaaactggc 60
aattatcata ctttttgccc gattagctgt gtagcttggt tatatcaaaa aatcgaagat 120
agcttttttt tagtaattgg gacaaaaaca tgtggttatt ttttacaaaa tgcccttgga 180
gttatgattt ttgccgaacc taggtatgct atggcagaat tagaagaaag tgatatttca 240
gcacaattaa acgattataa agaattaaaa cgtttatgtt tacaaattaa acaagataga 300
aatcccagcg ttattgtttg gattggaact tgtacaactg aaattatcaa aatggattta 360
gaagggatgg ctccacgttt agaaactgaa atcggcatac ccattgttgt agcacgtgct 420
aatggtttag attatgcttt tacacaaggt gaagacacag ttttatcagc aatggcctta 480
gcatccttaa aaaaagatgt tcctttttta gtaggtaata ctgggttaac aaacaaccag 540
cttctccttg aaaaatcaac ttcttcagtt aatgggacag acggaaagga attacttaaa 600
aaatctcttg tattatttgg ttccgtacca agtacagtta ctacacaatt aactttagaa 660
ttaaaaaaag aaggtattaa tgtatctgga tggcttccat ctgctaatta taaagattta 720
cctactttta ataaagatac acttgtatgt ggtataaatc cttttttaag tcgaacagct 780
accacgttaa tgcgtcgtag taagtgcaca ttaatttgtg caccctttcc aataggcccc 840
gatggcacaa gagtttggat tgaaaaaatt tgtggtgctt ttggcattaa tcctagtctt 900
aatccaatta ctggtaatac taatttatat gatcgtgaac aaaaaatttt caacgggcta 960
gaagattatt taaaattatt acgtggaaaa tctgtatttt ttatgggtga taatttatta 1020
gaaatttctt tagcacgttt tttaacacgt tgtggtatga ttgtttatga aatcggaatt 1080
ccatatttag ataaacgatt tcaagcagca gaattagctt tattagaaca aacttgtaaa 1140
gaaatgaatg taccaatgcc gcgcattgta gaaaaaccag ataattatta tcaaattcga 1200
cgtatacgtg aattaaaacc tgatttaacg attactggaa tggcacatgc aaatccatta 1260
gaagctcgag gtattacaac aaaatggtca gttgaattta cttttgctca aattcatgga 1320
tttactaata cacgtgaaat tttagaatta gtaacacagc ctcttagacg caatctaatg 1380
tcaaatcaat ctgtaaatgc tatttcttaa 1410
<210> 34
<211> 469
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 34
Met Leu Asp Gly Ala Thr Thr Ile Leu Asn Leu Asn Ser Phe Phe Glu
1 5 10 15
Cys Glu Thr Gly Asn Tyr His Thr Phe Cys Pro Ile Ser Cys Val Ala
20 25 30
Trp Leu Tyr Gln Lys Ile Glu Asp Ser Phe Phe Leu Val Ile Gly Thr
35 40 45
Lys Thr Cys Gly Tyr Phe Leu Gln Asn Ala Leu Gly Val Met Ile Phe
50 55 60
Ala Glu Pro Arg Tyr Ala Met Ala Glu Leu Glu Glu Ser Asp Ile Ser
65 70 75 80
Ala Gln Leu Asn Asp Tyr Lys Glu Leu Lys Arg Leu Cys Leu Gln Ile
85 90 95
Lys Gln Asp Arg Asn Pro Ser Val Ile Val Trp Ile Gly Thr Cys Thr
100 105 110
Thr Glu Ile Ile Lys Met Asp Leu Glu Gly Met Ala Pro Arg Leu Glu
115 120 125
Thr Glu Ile Gly Ile Pro Ile Val Val Ala Arg Ala Asn Gly Leu Asp
130 135 140
Tyr Ala Phe Thr Gln Gly Glu Asp Thr Val Leu Ser Ala Met Ala Leu
145 150 155 160
Ala Ser Leu Lys Lys Asp Val Pro Phe Leu Val Gly Asn Thr Gly Leu
165 170 175
Thr Asn Asn Gln Leu Leu Leu Glu Lys Ser Thr Ser Ser Val Asn Gly
180 185 190
Thr Asp Gly Lys Glu Leu Leu Lys Lys Ser Leu Val Leu Phe Gly Ser
195 200 205
Val Pro Ser Thr Val Thr Thr Gln Leu Thr Leu Glu Leu Lys Lys Glu
210 215 220
Gly Ile Asn Val Ser Gly Trp Leu Pro Ser Ala Asn Tyr Lys Asp Leu
225 230 235 240
Pro Thr Phe Asn Lys Asp Thr Leu Val Cys Gly Ile Asn Pro Phe Leu
245 250 255
Ser Arg Thr Ala Thr Thr Leu Met Arg Arg Ser Lys Cys Thr Leu Ile
260 265 270
Cys Ala Pro Phe Pro Ile Gly Pro Asp Gly Thr Arg Val Trp Ile Glu
275 280 285
Lys Ile Cys Gly Ala Phe Gly Ile Asn Pro Ser Leu Asn Pro Ile Thr
290 295 300
Gly Asn Thr Asn Leu Tyr Asp Arg Glu Gln Lys Ile Phe Asn Gly Leu
305 310 315 320
Glu Asp Tyr Leu Lys Leu Leu Arg Gly Lys Ser Val Phe Phe Met Gly
325 330 335
Asp Asn Leu Leu Glu Ile Ser Leu Ala Arg Phe Leu Thr Arg Cys Gly
340 345 350
Met Ile Val Tyr Glu Ile Gly Ile Pro Tyr Leu Asp Lys Arg Phe Gln
355 360 365
Ala Ala Glu Leu Ala Leu Leu Glu Gln Thr Cys Lys Glu Met Asn Val
370 375 380
Pro Met Pro Arg Ile Val Glu Lys Pro Asp Asn Tyr Tyr Gln Ile Arg
385 390 395 400
Arg Ile Arg Glu Leu Lys Pro Asp Leu Thr Ile Thr Gly Met Ala His
405 410 415
Ala Asn Pro Leu Glu Ala Arg Gly Ile Thr Thr Lys Trp Ser Val Glu
420 425 430
Phe Thr Phe Ala Gln Ile His Gly Phe Thr Asn Thr Arg Glu Ile Leu
435 440 445
Glu Leu Val Thr Gln Pro Leu Arg Arg Asn Leu Met Ser Asn Gln Ser
450 455 460
Val Asn Ala Ile Ser
465
<210> 35
<211> 1050
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 35
atgcagcagt gcgttggccg ctccgtccgc gctccgtcca gcagggcggt cgcgcccaag 60
gtcgctggcg ctcgtgtcag ccgccgcgtg tgccgcgtct atgcctccgc tgttgctacc 120
aagacggtga agattggcac gcgcggctcg cccctggctc tggcccaggc ttacatgact 180
cgcgacctgc tgaagaagag cttccctgag ctgagcgagg agggtgctct ggagatcgtg 240
atcatcaaga ccaccggtga caaaatcctg aaccagcccc tggctgacat cggtggcaag 300
ggtctgttta ccaaggagat cgatgatgct ctgctgagcg gcaagattga catcgccgtg 360
cactccatga aggacgtgcc cacctacctg cccgagggca ccatcctgcc ctgcaacctg 420
ccccgcgagg atgtgcgcga tgtgttcatc tcgcctgtcg ccaaggacct gagcgagctg 480
cccgccggcg ccattgtggg ctcggcctcg ctgcgccgtc aggcccagat cctggccaag 540
tacccccacc tcaaggtgga gaacttccgc ggcaacgtgc agacccgcct gcgcaagctg 600
aacgagggcg cctgctccgc caccctgctg gctctggccg gtctgaagcg cctggacatg 660
actgagcaca tcaccaagac cctcagcatt gacgagatgc tgcccgccgt gagccagggc 720
gccattggca ttgcctgccg caccgacgac ggcgccagcc gcaacctgct ggccgccctg 780
aaccacgagg agacccgcat cgccgtggtg tgcgagcgcg ccttcctgac cgccctggac 840
ggctcttgcc gcacccccat tgccggctac gcgcacaagg gcgccgacgg catgctgcac 900
ttcagcggcc tggtggccac cccggacggc aagcagatca tgcgcgctag ccgcgtggtg 960
cccttcacgg aggcggatgc cgtcaagtgc ggcgaggagg ccggcaagga gctcaaggcc 1020
aacggcccca aggagctgtt catgtactaa 1050
<210> 36
<211> 349
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 36
Met Gln Gln Cys Val Gly Arg Ser Val Arg Ala Pro Ser Ser Arg Ala
1 5 10 15
Val Ala Pro Lys Val Ala Gly Ala Arg Val Ser Arg Arg Val Cys Arg
20 25 30
Val Tyr Ala Ser Ala Val Ala Thr Lys Thr Val Lys Ile Gly Thr Arg
35 40 45
Gly Ser Pro Leu Ala Leu Ala Gln Ala Tyr Met Thr Arg Asp Leu Leu
50 55 60
Lys Lys Ser Phe Pro Glu Leu Ser Glu Glu Gly Ala Leu Glu Ile Val
65 70 75 80
Ile Ile Lys Thr Thr Gly Asp Lys Ile Leu Asn Gln Pro Leu Ala Asp
85 90 95
Ile Gly Gly Lys Gly Leu Phe Thr Lys Glu Ile Asp Asp Ala Leu Leu
100 105 110
Ser Gly Lys Ile Asp Ile Ala Val His Ser Met Lys Asp Val Pro Thr
115 120 125
Tyr Leu Pro Glu Gly Thr Ile Leu Pro Cys Asn Leu Pro Arg Glu Asp
130 135 140
Val Arg Asp Val Phe Ile Ser Pro Val Ala Lys Asp Leu Ser Glu Leu
145 150 155 160
Pro Ala Gly Ala Ile Val Gly Ser Ala Ser Leu Arg Arg Gln Ala Gln
165 170 175
Ile Leu Ala Lys Tyr Pro His Leu Lys Val Glu Asn Phe Arg Gly Asn
180 185 190
Val Gln Thr Arg Leu Arg Lys Leu Asn Glu Gly Ala Cys Ser Ala Thr
195 200 205
Leu Leu Ala Leu Ala Gly Leu Lys Arg Leu Asp Met Thr Glu His Ile
210 215 220
Thr Lys Thr Leu Ser Ile Asp Glu Met Leu Pro Ala Val Ser Gln Gly
225 230 235 240
Ala Ile Gly Ile Ala Cys Arg Thr Asp Asp Gly Ala Ser Arg Asn Leu
245 250 255
Leu Ala Ala Leu Asn His Glu Glu Thr Arg Ile Ala Val Val Cys Glu
260 265 270
Arg Ala Phe Leu Thr Ala Leu Asp Gly Ser Cys Arg Thr Pro Ile Ala
275 280 285
Gly Tyr Ala His Lys Gly Ala Asp Gly Met Leu His Phe Ser Gly Leu
290 295 300
Val Ala Thr Pro Asp Gly Lys Gln Ile Met Arg Ala Ser Arg Val Val
305 310 315 320
Pro Phe Thr Glu Ala Asp Ala Val Lys Cys Gly Glu Glu Ala Gly Lys
325 330 335
Glu Leu Lys Ala Asn Gly Pro Lys Glu Leu Phe Met Tyr
340 345
<210> 37
<211> 1143
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 37
atgcgatcgt atctgctcaa ggctcaagtg gcctcatgtc agttttcgcg cacgtcgaag 60
gtctggagac tggcgccggg ttctgacaga cgacggtgtc ggggcctcac tcggacaccg 120
cactgcgcgg cccccaccag cgagcccgcc ccgccatcca gcagcggcaa gagcgggcaa 180
cgaccactcg tgatagccac gcggccatct aagcttgcaa aggagcagac gcggcaggtg 240
cagcagctgc tgctggcggc ggcgcagctc aaggacgagc agctgcagct gagcaccctg 300
gaactggcgt ctaggggcga cacgactcag ggtgtgtcgc tgcgcagtct gggctcgggc 360
gcattcaccg aggagctgga ccaggctgtg ctgtcgggcg ctgccgacat gtcggtgcac 420
agcctgaagg actgccccgc cgccctggcg cccgggctgc tgctggccgc ctgcctgccg 480
cgggccgacc cccgggacgt cctcatcgcg cccgaggcca cctcgctggg cgagctggtg 540
ccgggcagcc gtgtgggcac cagcagcagc cgccgcgcgg cgcagatcaa gcactccttc 600
ccccacctgc aggttgtgca gctgcgcggc aatgtggact cgcggctggg gcgcatccgc 660
agccgcgaca tcggcgccac agtgctggcg gcggcgggcc tcaagcggct gggtgtgatg 720
aactcggacg agggtgacac taccgctacg ggcgccgtgg gggtggtgtg cagggcagac 780
gatgagtggg tggtcggcct gctggacgcc atctcgcacc gcggcacggc cctggaggtg 840
gcggcggagc gggcgtgcct ggcagcgctg ctgggcggcg gcggcgcgtg ccagcgttca 900
gcgttcccgg acattgcgtg ggcctgccac acgcggcacg accccgacag caacacaatg 960
gacctggatt gcctggtggc ggacctggag ggcaaggagc tcttcaggta cacggagttc 1020
taccggccgg tcattgacga ggtggacgcg gtgtcgctgg ggtcgctgta cggcagcctg 1080
ctgcgcatga tggcgccacc aggcgcggcc ccctgttggc agctaccttc ctcgcggcat 1140
tag 1143
<210> 38
<211> 380
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 38
Met Arg Ser Tyr Leu Leu Lys Ala Gln Val Ala Ser Cys Gln Phe Ser
1 5 10 15
Arg Thr Ser Lys Val Trp Arg Leu Ala Pro Gly Ser Asp Arg Arg Arg
20 25 30
Cys Arg Gly Leu Thr Arg Thr Pro His Cys Ala Ala Pro Thr Ser Glu
35 40 45
Pro Ala Pro Pro Ser Ser Ser Gly Lys Ser Gly Gln Arg Pro Leu Val
50 55 60
Ile Ala Thr Arg Pro Ser Lys Leu Ala Lys Glu Gln Thr Arg Gln Val
65 70 75 80
Gln Gln Leu Leu Leu Ala Ala Ala Gln Leu Lys Asp Glu Gln Leu Gln
85 90 95
Leu Ser Thr Leu Glu Leu Ala Ser Arg Gly Asp Thr Thr Gln Gly Val
100 105 110
Ser Leu Arg Ser Leu Gly Ser Gly Ala Phe Thr Glu Glu Leu Asp Gln
115 120 125
Ala Val Leu Ser Gly Ala Ala Asp Met Ser Val His Ser Leu Lys Asp
130 135 140
Cys Pro Ala Ala Leu Ala Pro Gly Leu Leu Leu Ala Ala Cys Leu Pro
145 150 155 160
Arg Ala Asp Pro Arg Asp Val Leu Ile Ala Pro Glu Ala Thr Ser Leu
165 170 175
Gly Glu Leu Val Pro Gly Ser Arg Val Gly Thr Ser Ser Ser Arg Arg
180 185 190
Ala Ala Gln Ile Lys His Ser Phe Pro His Leu Gln Val Val Gln Leu
195 200 205
Arg Gly Asn Val Asp Ser Arg Leu Gly Arg Ile Arg Ser Arg Asp Ile
210 215 220
Gly Ala Thr Val Leu Ala Ala Ala Gly Leu Lys Arg Leu Gly Val Met
225 230 235 240
Asn Ser Asp Glu Gly Asp Thr Thr Ala Thr Gly Ala Val Gly Val Val
245 250 255
Cys Arg Ala Asp Asp Glu Trp Val Val Gly Leu Leu Asp Ala Ile Ser
260 265 270
His Arg Gly Thr Ala Leu Glu Val Ala Ala Glu Arg Ala Cys Leu Ala
275 280 285
Ala Leu Leu Gly Gly Gly Gly Ala Cys Gln Arg Ser Ala Phe Pro Asp
290 295 300
Ile Ala Trp Ala Cys His Thr Arg His Asp Pro Asp Ser Asn Thr Met
305 310 315 320
Asp Leu Asp Cys Leu Val Ala Asp Leu Glu Gly Lys Glu Leu Phe Arg
325 330 335
Tyr Thr Glu Phe Tyr Arg Pro Val Ile Asp Glu Val Asp Ala Val Ser
340 345 350
Leu Gly Ser Leu Tyr Gly Ser Leu Leu Arg Met Met Ala Pro Pro Gly
355 360 365
Ala Ala Pro Cys Trp Gln Leu Pro Ser Ser Arg His
370 375 380
<210> 39
<211> 1692
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 39
atgatgttga cccagactcc tgggaccgcc acggcttcta gccggcggtc gcagatccgc 60
tcggctgcgc acgtctccgc caaggtcgcg cctcggccca cgccattctc ggtcgcgagc 120
cccgcgaccg ctgcgagccc cgcgaccgcg gcggcccgcc gcacactcca ccgcactgct 180
gcggcggcca ctggtgctcc cacggcgtcc ggagccggcg tcgccaagac gctcgacaat 240
gtgtatgacg tgatcgtggt cggtggaggt ctctcgggcc tggtgaccgg ccaggccctg 300
gcggctcagc acaaaattca gaacttcctt gttacggagg ctcgcgagcg cgtcggcggc 360
aacattacgt ccatgtcggg cgatggctac gtgtgggagg agggcccgaa cagcttccag 420
cccaacgata gcatgctgca gattgcggtg gactctggct gcgagaagga ccttgtgttc 480
ggtgacccca cggctccccg cttcgtgtgg tgggagggca agctgcgccc cgtgccctcg 540
ggcctggacg ccttcacctt cgacctcatg tccatccccg gcaagatccg cgccgggctg 600
ggcgccatcg gcctcatcaa cggagccatg ccctccttcg aggagagtgt ggagcagttc 660
atccgccgca acctgggcga tgaggtgttc ttccgcctga tcgagccctt ctgctccggc 720
gtgtacgcgg gcgacccctc caagctgtcc atgaaggcgg ccttcaacag gatctggatt 780
ctggagaaga acggcggcag cctggtggga ggtgccatca agctgttcca ggaacgccag 840
tccaacccgg ccccgccgcg ggacccgcgc ctgccgccca agcccaaggg ccagacggtg 900
ggctcgttcc gcaagggcct gaagatgctg ccggacgcca ttgagcgcaa catccccgac 960
aagatccgcg tgaactggaa gctggtgtct ctgggccgcg aggcggacgg gcggtacggg 1020
ctggtgtacg acacgcccga gggccgtgtc aaggtgtttg cccgcgccgt ggctctgacc 1080
gcgcccagct acgtggtggc ggacctggtc aaggagcagg cgcccgccgc cgccgaggcc 1140
ctgggctcct tcgactaccc gccggtgggc gccgtgacgc tgtcgtaccc gctgagcgcc 1200
gtgcgggagg agcgcaaggc ctcggacggg tccgtgccgg gcttcggtca gctgcacccg 1260
cgcacgcagg gcatcaccac tctgggcacc atctacagct ccagcctgtt ccccggccgc 1320
gcgcccgagg gccacatgct gctgctcaac tacatcggcg gcaccaccaa ccgcggcatc 1380
gtcaaccaga ccaccgagca gctggtggag caggtggaca aggacctgcg caacatggtc 1440
atcaagcccg acgcgcccaa gccccgtgtg gtgggcgtgc gcgtgtggcc gcgcgccatc 1500
ccgcagttca acctgggcca cctggagcag ctggacaagg cgcgcaaggc gctggacgcg 1560
gcggggctgc agggcgtgca cctggggggc aactacgtca gcggtgtggc cctgggcaag 1620
gtggtggagc acggctacga gtccgcagcc aacctggcca agagcgtgtc caaggccgca 1680
gtcaaggcct aa 1692
<210> 40
<211> 563
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 40
Met Met Leu Thr Gln Thr Pro Gly Thr Ala Thr Ala Ser Ser Arg Arg
1 5 10 15
Ser Gln Ile Arg Ser Ala Ala His Val Ser Ala Lys Val Ala Pro Arg
20 25 30
Pro Thr Pro Phe Ser Val Ala Ser Pro Ala Thr Ala Ala Ser Pro Ala
35 40 45
Thr Ala Ala Ala Arg Arg Thr Leu His Arg Thr Ala Ala Ala Ala Thr
50 55 60
Gly Ala Pro Thr Ala Ser Gly Ala Gly Val Ala Lys Thr Leu Asp Asn
65 70 75 80
Val Tyr Asp Val Ile Val Val Gly Gly Gly Leu Ser Gly Leu Val Thr
85 90 95
Gly Gln Ala Leu Ala Ala Gln His Lys Ile Gln Asn Phe Leu Val Thr
100 105 110
Glu Ala Arg Glu Arg Val Gly Gly Asn Ile Thr Ser Met Ser Gly Asp
115 120 125
Gly Tyr Val Trp Glu Glu Gly Pro Asn Ser Phe Gln Pro Asn Asp Ser
130 135 140
Met Leu Gln Ile Ala Val Asp Ser Gly Cys Glu Lys Asp Leu Val Phe
145 150 155 160
Gly Asp Pro Thr Ala Pro Arg Phe Val Trp Trp Glu Gly Lys Leu Arg
165 170 175
Pro Val Pro Ser Gly Leu Asp Ala Phe Thr Phe Asp Leu Met Ser Ile
180 185 190
Pro Gly Lys Ile Arg Ala Gly Leu Gly Ala Ile Gly Leu Ile Asn Gly
195 200 205
Ala Met Pro Ser Phe Glu Glu Ser Val Glu Gln Phe Ile Arg Arg Asn
210 215 220
Leu Gly Asp Glu Val Phe Phe Arg Leu Ile Glu Pro Phe Cys Ser Gly
225 230 235 240
Val Tyr Ala Gly Asp Pro Ser Lys Leu Ser Met Lys Ala Ala Phe Asn
245 250 255
Arg Ile Trp Ile Leu Glu Lys Asn Gly Gly Ser Leu Val Gly Gly Ala
260 265 270
Ile Lys Leu Phe Gln Glu Arg Gln Ser Asn Pro Ala Pro Pro Arg Asp
275 280 285
Pro Arg Leu Pro Pro Lys Pro Lys Gly Gln Thr Val Gly Ser Phe Arg
290 295 300
Lys Gly Leu Lys Met Leu Pro Asp Ala Ile Glu Arg Asn Ile Pro Asp
305 310 315 320
Lys Ile Arg Val Asn Trp Lys Leu Val Ser Leu Gly Arg Glu Ala Asp
325 330 335
Gly Arg Tyr Gly Leu Val Tyr Asp Thr Pro Glu Gly Arg Val Lys Val
340 345 350
Phe Ala Arg Ala Val Ala Leu Thr Ala Pro Ser Tyr Val Val Ala Asp
355 360 365
Leu Val Lys Glu Gln Ala Pro Ala Ala Ala Glu Ala Leu Gly Ser Phe
370 375 380
Asp Tyr Pro Pro Val Gly Ala Val Thr Leu Ser Tyr Pro Leu Ser Ala
385 390 395 400
Val Arg Glu Glu Arg Lys Ala Ser Asp Gly Ser Val Pro Gly Phe Gly
405 410 415
Gln Leu His Pro Arg Thr Gln Gly Ile Thr Thr Leu Gly Thr Ile Tyr
420 425 430
Ser Ser Ser Leu Phe Pro Gly Arg Ala Pro Glu Gly His Met Leu Leu
435 440 445
Leu Asn Tyr Ile Gly Gly Thr Thr Asn Arg Gly Ile Val Asn Gln Thr
450 455 460
Thr Glu Gln Leu Val Glu Gln Val Asp Lys Asp Leu Arg Asn Met Val
465 470 475 480
Ile Lys Pro Asp Ala Pro Lys Pro Arg Val Val Gly Val Arg Val Trp
485 490 495
Pro Arg Ala Ile Pro Gln Phe Asn Leu Gly His Leu Glu Gln Leu Asp
500 505 510
Lys Ala Arg Lys Ala Leu Asp Ala Ala Gly Leu Gln Gly Val His Leu
515 520 525
Gly Gly Asn Tyr Val Ser Gly Val Ala Leu Gly Lys Val Val Glu His
530 535 540
Gly Tyr Glu Ser Ala Ala Asn Leu Ala Lys Ser Val Ser Lys Ala Ala
545 550 555 560
Val Lys Ala
<210> 41
<211> 1173
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 41
atgcagacca aggctttcac ctctgcgcgc ccccagcggg ccgctgcgct caaggcgcag 60
cgcacctcgt cggtgaccgt gcgcgcgacc gcggcccccg ccgtggcctc tgcccccgcc 120
gcctcgggct ctgcctctga ccccctgatg ctgcgcgcca tccgcggcga caaggtggag 180
cgcccgcccg tgtggatgat gcgccaggcc ggccgctacc agaaggtgta ccaggacctg 240
tgcaagaagc accccacgtt ccgtgagcgc tcggagcgcg tggacctggc ggtggagatc 300
tctctgcagc cgtggcacgc gttcaagccc gacggcgtca tcctgttcag cgacattctg 360
acccccctgc ccggcatgaa catccccttc gacatggcgc ccggccccat catcatggac 420
cccatccgca ccatggcgca agtggagaag gtgacgaagc tggacgctga ggccgcctgc 480
cccttcgtgg gcgagtcgct gcgccagctg cgcacctaca tcggcaacca ggccgcggtc 540
ctgggcttcg tgggcgcccc cttcaccctg gccacctaca ttgtggaggg cggcagctcc 600
aagaacttcg cgcacatcaa gaagatggct ttctccaccc ccgagatcct gcacgccctg 660
ctggacaagc tggctgacaa cgtggccgac tacgtccgct accaggccga cgccggcgcc 720
caggtggtgc agatcttcga ctcgtgggcc agcgagctgc agccccagga cttcgacgtg 780
ttctccggcc cctacatcaa gaaggtgatc gacagcgtgc gcaagaccca ccccgacctg 840
cccatcatcc tctacatcag cggctctggc ggcctgctgg agcgcatggc ctcttgctcg 900
cccgacatca tctcgctgga ccagtcggtg gacttcaccg acggcgtcaa gcgctgcggc 960
accaacttcg ccttccaggg caacatggac cccggcgtcc tgttcggctc caaggacttc 1020
atcgagaagc gcgtcatgga caccatcaag gctgcccgcg acgccgacgt gcgccacgtg 1080
atgaacctgg gccacggcgt gctgcccggc acccccgagg accacgtggg ccactacttc 1140
cacgtcgccc gcaccgccca cgagcgcatg taa 1173
<210> 42
<211> 390
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 42
Met Gln Thr Lys Ala Phe Thr Ser Ala Arg Pro Gln Arg Ala Ala Ala
1 5 10 15
Leu Lys Ala Gln Arg Thr Ser Ser Val Thr Val Arg Ala Thr Ala Ala
20 25 30
Pro Ala Val Ala Ser Ala Pro Ala Ala Ser Gly Ser Ala Ser Asp Pro
35 40 45
Leu Met Leu Arg Ala Ile Arg Gly Asp Lys Val Glu Arg Pro Pro Val
50 55 60
Trp Met Met Arg Gln Ala Gly Arg Tyr Gln Lys Val Tyr Gln Asp Leu
65 70 75 80
Cys Lys Lys His Pro Thr Phe Arg Glu Arg Ser Glu Arg Val Asp Leu
85 90 95
Ala Val Glu Ile Ser Leu Gln Pro Trp His Ala Phe Lys Pro Asp Gly
100 105 110
Val Ile Leu Phe Ser Asp Ile Leu Thr Pro Leu Pro Gly Met Asn Ile
115 120 125
Pro Phe Asp Met Ala Pro Gly Pro Ile Ile Met Asp Pro Ile Arg Thr
130 135 140
Met Ala Gln Val Glu Lys Val Thr Lys Leu Asp Ala Glu Ala Ala Cys
145 150 155 160
Pro Phe Val Gly Glu Ser Leu Arg Gln Leu Arg Thr Tyr Ile Gly Asn
165 170 175
Gln Ala Ala Val Leu Gly Phe Val Gly Ala Pro Phe Thr Leu Ala Thr
180 185 190
Tyr Ile Val Glu Gly Gly Ser Ser Lys Asn Phe Ala His Ile Lys Lys
195 200 205
Met Ala Phe Ser Thr Pro Glu Ile Leu His Ala Leu Leu Asp Lys Leu
210 215 220
Ala Asp Asn Val Ala Asp Tyr Val Arg Tyr Gln Ala Asp Ala Gly Ala
225 230 235 240
Gln Val Val Gln Ile Phe Asp Ser Trp Ala Ser Glu Leu Gln Pro Gln
245 250 255
Asp Phe Asp Val Phe Ser Gly Pro Tyr Ile Lys Lys Val Ile Asp Ser
260 265 270
Val Arg Lys Thr His Pro Asp Leu Pro Ile Ile Leu Tyr Ile Ser Gly
275 280 285
Ser Gly Gly Leu Leu Glu Arg Met Ala Ser Cys Ser Pro Asp Ile Ile
290 295 300
Ser Leu Asp Gln Ser Val Asp Phe Thr Asp Gly Val Lys Arg Cys Gly
305 310 315 320
Thr Asn Phe Ala Phe Gln Gly Asn Met Asp Pro Gly Val Leu Phe Gly
325 330 335
Ser Lys Asp Phe Ile Glu Lys Arg Val Met Asp Thr Ile Lys Ala Ala
340 345 350
Arg Asp Ala Asp Val Arg His Val Met Asn Leu Gly His Gly Val Leu
355 360 365
Pro Gly Thr Pro Glu Asp His Val Gly His Tyr Phe His Val Ala Arg
370 375 380
Thr Ala His Glu Arg Met
385 390
<210> 43
<211> 288
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 43
atgtcggccc tggacgccgc cgccatcccc tacgagctag tgccgggtgt gtcctccgct 60
ctggccgccc cgctgttcgc cggcgtcccg ctcacacacg tcagcctgag cccctcgttc 120
accgtggtca gcgggcacga cgtggccggc accgactggg cggcgttccg ggggctgccc 180
acgctggtgg ttctgatggc gggtcgtaac ctggggcaga tagcccggcg gcttgtgcag 240
gacgcggggt gggcgcccga tacacctgta agtcaaccta gtggctag 288
<210> 44
<211> 95
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 44
Met Ser Ala Leu Asp Ala Ala Ala Ile Pro Tyr Glu Leu Val Pro Gly
1 5 10 15
Val Ser Ser Ala Leu Ala Ala Pro Leu Phe Ala Gly Val Pro Leu Thr
20 25 30
His Val Ser Leu Ser Pro Ser Phe Thr Val Val Ser Gly His Asp Val
35 40 45
Ala Gly Thr Asp Trp Ala Ala Phe Arg Gly Leu Pro Thr Leu Val Val
50 55 60
Leu Met Ala Gly Arg Asn Leu Gly Gln Ile Ala Arg Arg Leu Val Gln
65 70 75 80
Asp Ala Gly Trp Ala Pro Asp Thr Pro Val Ser Gln Pro Ser Gly
85 90 95
<210> 45
<211> 204
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 45
ggcgtcccca caaccaggac agcctacttc ttgaccttat taataagtcg ctgcgtgtcg 60
cgactgacca ttttggcccg gacttgcgtg cttgtgattt gtgcttcgac tagatccgcg 120
ggcaccaagg gacgcggaca gctgatagtc aagaactaga tcctctggga gcgtctgggg 180
ctgtccccgc tgctcgccaa ggaa 204
<210> 46
<211> 721
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 46
gtgccgagtg actgaggtgg caaggtgcag tggcggcgga ggcagttgtg ctggggtggc 60
aaggcggaca ggcgaagctg gtgggttgcg acgaggagga ggtgcacgtg cacgcgtaac 120
ataagaagaa cagtgggagg acaggtagcg tgacttgact gggacgagga gcgtactgat 180
gtgtggcgtg tgttggtatg tgagcgttac ccctccccta gatagcggcg gtctccactt 240
tcaggaggat gagagccatc atgaggcttt gagggggcac tggttcgtgt gtaggctgag 300
gctgctgttg aagtcacaag gcagcactgc atgcgcgagt gagtgtggcc ggatatgcat 360
cgagttgcag gtacactgaa atgaggtgac tgcggcgtat atcgctgcca gtacaggttg 420
aagcggcggg cacggtgaat ggagtactcg gcctggaacg cttgcgatca gatggtcgag 480
ctcaagaaga tttggttgag ccgttgggtc gtgcgtcata ttatggcttg catcttcggg 540
gagcggcaag aaacggactc caatgcaggc cctcgggcga gaaagattgg gcgtgtccgg 600
gggtgcattc tcgccgcgtg gggctgcatc gaatttcgct tgagtgcccc ttcccgggga 660
gggggggcgg tagttcaacc ccatcatcgt aggggggttg taaatgccag cccaaactaa 720
a 721
<210> 47
<211> 187
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 47
atgaagtctc tctgccatga gctcgctggc cccagcgtta ctgggtgcgg ccggcgaagc 60
ctccggaagg ctttcagcgg tgccaagatt gcgcaggtct ctcgccccgc tgtgcttaac 120
agcgtgcagc gccaacagcg tctcgcctgt tctgccgtgg ccgagctctc cgctgctgag 180
ctgcgcg 187
<210> 48
<211> 281
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 48
ccatgaaggt gtctgaggag gactccaagg gcttcgatgc ggatgtgtcg acccgcctgg 60
cccgctcgta ccctctggcg gccgtggtgg gccaggacaa catcaagcag gcgctgctgc 120
tgggcgccgt ggacaccggg ctgggcggca tcgccatcgc cggtcgccgc ggtaccgcca 180
agtccatcat ggctcgcggc ctgcacgctc tgctgccgcc cattgaggtg gtggagggca 240
gcatctgcaa cgccgacccc gaggaccccc gctcctggga g 281
<210> 49
<211> 132
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 49
gctggcctgg ctgagaagta tgcgggcggc cctgtgaaga ccaagatgcg ctcggcgccg 60
tttgtgcaga tccctctggg tgtgactgag gaccgcttgg tgggcactgt ggacattgag 120
gcgtccatga ag 132
<210> 50
<211> 167
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 50
gagggcaaga ctgtgttcca gcccggcctg ctggctgagg cgcaccgcgg catcctgtac 60
gtggacgaga tcaacctgct ggatgacggc attgccaacc tgctgctgtc catcctgtcg 120
gacggagtca acgtggtgga gcgcgagggc atctccatca gccaccc 167
<210> 51
<211> 163
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 51
ctgccggccg ctgctgattg ccacctacaa ccccgaggag ggccctctgc gtgagcacct 60
gctggaccgc atcgccattg gcctcagcgc cgacgtcccc agcaccagcg acgagcgcgt 120
caaggccatt gacgcagcca tccgcttcca ggacaagccg cag 163
<210> 52
<211> 48
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 52
gacactattg acgacaccgc ggagctcacc gacgccctgc gcacctcg 48
<210> 53
<211> 123
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 53
gtcatcctgg ctcgcgagta cctgaaggac gtgaccatcg cgccggagca ggtgacctac 60
attgtggagg aggcgcgccg cggcggagtc caggggcacc gcgcggagct gtacgcggtc 120
aag 123
<210> 54
<211> 171
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 54
tgtgccaagg cgtgtgcggc tctggagggc cgtgagcgtg tgaacaagga tgacctgcgc 60
caggccgtgc agctggtcat cctgccgcgc gccaccatcc tggaccagcc cccgcccgag 120
caggagcagc ccccgccgcc gcccccgccc cctcccccgc cgccgccgca g 171
<210> 55
<211> 87
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 55
gaccaaatgg aggacgagga ccaggaggag aaggaggacg agaaggagga ggaggagaag 60
gagaacgagg accaggacga gcccgag 87
<210> 56
<211> 225
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 56
atccctcagg agttcatgtt tgagtccgag ggcgtcatca tggacccctc catcctcatg 60
ttcgcgcagc agcagcagcg cgcgcagggc cgctccggcc gcgccaagac gctcatcttc 120
agcgacgacc gcggccgcta catcaagccc atgctgccca agggtgacaa ggtcaagcgc 180
ctggcagtgg acgccacgct tcgcgccgcc gcgccctacc agaag 225
<210> 57
<211> 67
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 57
attcgccggc agcaggccat cagcgagggc aaggtgcagc gcaaggtgta cgtggacaag 60
ccagaca 67
<210> 58
<211> 653
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 58
tgcgctccaa gaagctggcc cgcaaggccg gtgcgctggt gatttttgtt gtggacgcgt 60
ccggctccat ggctctgaac cgcatgagcg ccgccaaggg cgcctgcatg cgcctgctgg 120
ctgagtcgta caccagccgc gaccaggtgt gcctcatccc cttctacggc gacaaggccg 180
aggtgctgct gccgccctcc aagtccatcg ccatggcccg ccgccgcctg gactcgctgc 240
cctgcggcgg cggctcgccc cttgcgcacg gcctgtccac ggcggtacgt gtgggcatgc 300
aggccagcca ggcgggcgag gtgggccgcg tcatgatggt gctcatcacg gacggccgcg 360
ccaacgtcag cctggccaag tccaacgagg accccgaggc gctcaagccc gacgcgccca 420
agcccaccgc cgactcgctg aaggacgagg tgcgcgacat ggccaagaag gccgcgtccg 480
ccggcatcaa cgtgcttgtc attgacacgg agaacaagtt cgtgagcacc ggctttgcgg 540
aggagatctc caaggcagcg cagggcaagt actactacct gcccaacgcc agcgacgccg 600
ccatcgcggc ggccgcgtcc ggcgccatgg ccgcggccaa gggcggctac tag 653
<210> 59
<211> 379
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 59
gtgagcgcct actttgatat gtaccaaaga taccactgat aggtttaggc acggaagatc 60
tggacttgga ccccgtttgc gcaagccggg cgatgcaccc atttcgcggt cacgccgagc 120
gctggggtgc aatttagcgt gcccgacaag ctagaaaaca gggaattacc atttgtttaa 180
ttttgttgcg agagatcttt gcttgtgtcc accggccgcg cgggggaact tccggtgttg 240
cgcaaggttg cgtgcgtgcc caccatcaac acctgtgcca ggtctgtgtc acccccaggt 300
tccaccaccc tgcaatcttc caattgtgtc tcgtttgctc gttgtctaat agtcgtcctt 360
tgctcatccc tacctgcag 379
<210> 60
<211> 267
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 60
gtgaggcagg gaaggtgaca caggaggttt tgaaagagag acagggaggc aaagatggat 60
ggcggggcgg gcagtgactt tggggcggca tggagtggga ttggtggagt gggattgggc 120
accatgtatc acagatgttg gcaacacagc gcagggcctt gctctgtgct tgtgttgacc 180
gtctagtccc ccgtgccctg aaccaagtct ttcctcctga cacggtcctc catgtcctcc 240
ttccggcatt cccttcctcg tccacag 267
<210> 61
<211> 273
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 61
gtgagccagc aagggaggag aggggaacgg ccgggtaggg cagccggagt ttaaccacgc 60
caattcaacg gggagcaacg gggaagagga agggccggaa gaggacggca aaagcatttg 120
gtgggggcag cggctgtagt cagaagcgca aaggctgcca cagtgtggcc cgcaccctcc 180
tcaccaccag tttggcatga tcgtttagca tgggctggaa tactcaccgc cagttctctc 240
ctctcccctc tcctcccctg tccccgcctg cag 273
<210> 62
<211> 166
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 62
gtgagtgcgc gcgctgggtg tgtttgtggg acggcgcggc attggagcgc aggtgcgggt 60
gctgggccgt gcacttgtcc gttggttccc ttggaagctt cgatacacac tcttactgca 120
cgctctttaa ccgccccccc cctccacctc tgcccgcccc gtgcag 166
<210> 63
<211> 275
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 63
gtgggtgggg gaaagtgact ggatgtcggt gggttttagg tatgtgcgtg tgtacgatgc 60
ggggagcagt acggaagcgg gcacgagcgg tgagggggca ggattgtggc gcacgctcgg 120
gccaagcccg ggctcgcgac agagggtggg cttgtattcg tagtcaagcg catcaggaag 180
tgcagttgac tggattcacc tgaaacggcg ctgagcgggc ggctaataga atcccgcttc 240
ctgtccgccc ctccccttgc ccttcaatcc gtcag 275
<210> 64
<211> 200
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 64
gtgagtggcg ggggccgtgc gtttgtttgt tgcgtgggct ggctggctgg ctttgttgga 60
tgagggcgct gctcaccact catctctttg aatccccact tatccagttg cctgcatgaa 120
accccgcctg actcactccc caccatcctg taccgctttt ccaaacatcc ttgcaaccat 180
cccgccatcc ccacccgcag 200
<210> 65
<211> 690
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 65
gtgaggagtt ggagggggaa ggggcgaggg gatgcgacag aagcgagggc gaggggagcc 60
ggggtgggtt gttgcaagtg tcgtgaatta tagaatgacc ccaaaagcgc cggcccaaca 120
gggcctatta cttgcgagtc aatccaaccc ctgatatagg gagaatgggg tagaggtcgt 180
atcacgacag caaggatgta cagtgggcct tggggttggg aggtacaggg aaaaaggaga 240
ggacatgggg ttgggtaagc ggggaataac aaatatacac ccagcgttta tggaagtggg 300
agatggaaac gggggcggac gaacaggaac aggggccgga tggaggggct atgggggcat 360
ggtgggtggg ggtacggcgc ggggcagagc agggtcttgg gtgaatgggc aagatgctga 420
tgcttgggat gaagacacta tgagcaaaga aatggttgtt gacgattgcc atgatcatcg 480
cagtggggga ggcggggtgg caataccggc agtcaacagt tggggtgcga tcaagattga 540
ttggagtacc agcagtggcc gggatctggc tgacgtgtct cgagcgagtt gctggggtgg 600
caaggagatg caggggcaga cgacgttgtg cgaccacact tacacacatt tccttcccct 660
tgcgtgtgtc cgtgcgccct gtgcctccag 690
<210> 66
<211> 123
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 66
gtacgtaaac gtatttgatt gctcaggtgg ttagccttgg tgtggctgct gtttgacttg 60
tgcagctgtc tttgtgtaca tgttccacaa ccctgtactc cccatattcc gcccccattc 120
cag 123
<210> 67
<211> 228
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 67
gtgagaggcg gcgcggcggc ttgcgggcga aggcgggggg cggggcggag gcaatgcggc 60
cgcgcatggc cagcaacgga agggctggct atcaacacgg cgagcgcacg atattcatat 120
aagagtgcca tcgtgcaatg ctgaatactt gcgccaaccg gatctcgctg ctccgcttcc 180
accggactgc tttctcatct ctccccttca ccctgtgtgt atccacag 228
<210> 68
<211> 146
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 68
gtgagtgccc gaggtggtgg gtggtgaatt ggggcacgag ggtatgtggg cctaagggag 60
ctgaatgggg catgttttct tctgagcatc acggtcagag cttgacctgt cctccccgct 120
gtacccccgt gcacggtccg acacag 146
<210> 69
<211> 168
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 69
gtgagtacag cgcatcccgg cgcaatcatt gggcctagtt actgctgcag gactcgtgtg 60
ctcttaaggg ctggcagctg tcagaagctc tactcctcgc actgaccact gtgcctttct 120
ctccttcctc tctccctccc cgcacccctc ctcccacttc ctcaacag 168
<210> 70
<211> 143
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 70
gcagacttcc ataaagctct tgtaacgctg taccaactag taagcggtac aattcgcctg 60
agcccgagca acgcgacctt tcttgctctg tggatctctg ataatctaac cagaccaaaa 120
ccttttcact aatctaggca aca 143
<210> 71
<211> 381
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 71
aaaaggctgg tgtaggcctg tcgggtcgtg ttaaaggttg ctgcgtgaac gtgtaagtgt 60
gacagtgtgc cggtatgtgt gtgtatacat gtgttgcggt gtgcttttgt ggcggtacat 120
ggtgatgact gagcgggtgg gacagagcac ggttaactga cgagggcagt ccgtgcgaga 180
cggacgtttt tgtagccgag gtgcaaggac tgatgacggg ctaagctgct ggagacttgg 240
agttgagagt gcaggtggat cgacggtttc tctaaggagt atgaataggc aggagggctg 300
gagacatttg gggtgcaagg aggcggtagt atgggagatg tccatgggcg gattttggcc 360
tctgtaactt cttaacgccc a 381
<210> 72
<211> 252
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 72
atgcagagtc tccagggtca gcgcgcgttc actgcggtgc gccagggtcg ggcgggtccc 60
ctgcggactc gcctggtcgt gcgctcgtct gttgccttgc catccacgaa agccgcgaag 120
aagccgaact tcccgttcgt caagattcag ggccaggagg agatgaagct tgcactgctg 180
ctgaacgtgg tcgaccccaa catcggcgga gtgcttatta tgggtgaccg cggcactgcc 240
aagtcggtcg cg 252
<210> 73
<211> 156
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 73
gtccgcgccc tggtggatat gcttcccgac attgacgtgg ttgagggcga cgccttcaac 60
agctccccca ccgaccccaa gttcatgggc cccgacaccc tgcagcgctt ccgcaacggc 120
gagaagctgc ccaccgtccg catgcggacc cccctg 156
<210> 74
<211> 102
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 74
gtggagctgc ctctgggcgc caccgaggac cgcatctgcg gcaccatcga catcgagaag 60
gcgctgacgc agggcatcaa ggcctacgag cccggcctgc tg 102
<210> 75
<211> 60
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 75
gccaaggcca accgcggcat cctgtatgtg gacgaggtga acctgctgga tgatggcctg 60
<210> 76
<211> 111
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 76
gttgatgtcg tgctggactc gtcggctagc ggcctgaaca ctgtggagcg tgagggtgtg 60
tccattgtgc accctgcccg cttcatcatg attggctcag gcaaccccca g 111
<210> 77
<211> 101
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 77
gagggtgagc tgcgcccgca gctgctggat cgcttcggca tgagcgtcaa cgtggccacg 60
ctgcaggaca ccaagcagcg cacgcagctg gtgctggacc g 101
<210> 78
<211> 127
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 78
gcttgcgtac gaggcggacc ctgacgcatt tgtggactcg tgcaaggccg agcagacggc 60
gctcacggac aagctggagg cggcccgcca gcgcctgcgg tccgtcaaga tcagcgagga 120
gctgcag 127
<210> 79
<211> 158
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 79
atcctgatct cggacatttg ctcgcgcctg gatgtggatg gcctgcgcgg tgacattgtg 60
atcaaccgcg ccgccaaggc gcttgtggcc ttcgagggcc gcaccgaggt gaccacgaat 120
gacgtggagc gcgtcatctc gggctgcctc aaccaccg 158
<210> 80
<211> 211
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 80
cctgcgcaag gacccgctgg accccattga caacggcacc aaggtggcca tcctgttcaa 60
gcgcatgacc gaccccgaga tcatgaagcg cgaggaggag gccaagaaga agcgcgagga 120
ggcggccgcc aaggccaagg cggagggcaa ggcggaccgc cccacgggcg ccaaggctgg 180
cgcctgggct ggcttgcccc ctcgtcggta a 211
<210> 81
<211> 534
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 81
gtaggtaaca caagcaatta tggggcgaag atctaggctc cgctgatccg ggcgggcaat 60
cggcatcgtc ggtgcaaccg tggggcgtct gtgcaccctt tgctggtgcc aggttgcctg 120
actcgcctgc attcctgtac cgagccacat tggctgcttt gcagcgtgca tgggacgggt 180
gtaggataag cgctatgtat gcgatagcgc gggtgcaccg gcttggcatg gcaaggttgc 240
ggggtgcaca tgcgtgccag cgtcccctca gcatcagagt ctggatctaa gggctcagcg 300
gcttcctgcg catgtgggtc tttgcgtagt gctacgaagc cttataatta aagctcatgt 360
attgagtggt ccgggtttgg ggcactagta gtgccaggag gcgcgtgcca ggttgatatg 420
agcatatcag cacccgttcc ttgcgaaacg cttccgttgt gctcccttcc ccaccacctc 480
cccgctcata cccatacata tggctatccg tcctctcatt gcttgcccct acag 534
<210> 82
<211> 195
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 82
gtgagcgggc ctaccttctg aagacagtct tacgtgttgc actgcagcgg tgttgcgcac 60
ctctgctttt gcgtgcgccg ggaagcgcgg attgcggcct cacagatcaa gcccggaaac 120
gcttgttgtt tccagcgggt ggcacacacg cgcgcgcgcg cacagtgaca ccctcacggc 180
cgcgctgccc tgcag 195
<210> 83
<211> 235
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 83
gtgcgtagtg catggggaga ggggacgagg ggaggagggc agggccaata aaccgaaccc 60
caagtcatcg agacacagaa cccgataata gctcccagat cgccaagggg tgaggcggga 120
agccaaggat gatgcgttgg ccgcattgcg tgttgacgtc aggcttacac agggtctgac 180
tggctgtgct tggggtttgg cacgcttctt gactggcccc gtacgcatgc tgcag 235
<210> 84
<211> 212
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 84
gtgagtggtg gtggtttctg ggtcagcaga ggacttctgt agtaggtaat gtgggccagg 60
gaagtgtggc taacatgcca aacacggggg cgcaccagtg caagctgcat tcgctgacgt 120
gcacgggtgc aatgggtgca aggcgaactg caatcgcggt gcacagttgc cagggctgcg 180
ctcacgcttg agtgtctgca cacgcactgc ag 212
<210> 85
<211> 270
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 85
gtgcgtagcg tgcgcgcatg tacttgtctc ccttgtcatg ttgggaaagg tcggtcccca 60
gcctgcttgc aagatgcggc cggtcagcag ctgcggacgg tcagcaccta cgtgccgagg 120
ttgtgtaaca tgaatggcgt tggggcggcc gacctgccac aagctgaact gcgaccagca 180
aggcagctgc cagcaacgca cacccgacgt gctacacgct tgtgttttga cctcctaaac 240
acacccgccc gctgtctgtc acgtccacag 270
<210> 86
<211> 199
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 86
gtaagcggcg gcggcgcggg gacacggagg gacatttcgc gagcatgggt tgaggagtcg 60
ggaggattcg gtggctggcc ggagtcggga gtcggagtcg cgagtcggaa gtcaagcttc 120
tggcggcttc gtgctgtcgg gtgcgctcgc catgatggcg ctgaccggag ggcgtcacgc 180
tgtgtatgtg ggcgcgcag 199
<210> 87
<211> 231
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 87
gtacggggcg tacagcgggg gcggctgcac ggggccagtg accgacaggg cagcacgcgg 60
ctggcgaaga gcgacaaagt gacagggtga ccaagaccgg gtgatgccac gagaggggcg 120
cgggagccgt gcattgggtc gaggagggag gaatgcaact ttacactgat gcctctgtat 180
acggccgcct tccgagccct gcaaaccttc gctttccccc gacgcacgca g 231
<210> 88
<211> 279
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 88
gtgagcgcag cgtgcggtgg atgcggtgcg cgtgcgggtt gccaacttat tattttgtac 60
gtggacgcgt ggctggcgat ggcatgtcat ggcgcgaatg gatattgggc gaatggatac 120
cggtaatggt agcacggggc ggcagggcct ggcggtagtg gggttgaggg ggcgaggact 180
ccagcgcgcg atacatgcca tgttcagcat ggccccaact gacagcgccc gctgccctgt 240
gcgccccgct ccctccgcgc acccgctcct cctacacag 279
<210> 89
<211> 36
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 89
ctagtctaga gggaactagg gaggggcaac agagaa 36
<210> 90
<211> 833
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 90
gcggcctccc cttcatggta gcactagttg gcgggttgtg gttggactag gcggctaggg 60
tatataccta gtagcggcgg ctgcggagtg gagggctggc gcccagcgcg agggcgtggc 120
ctttcctcct ggacccgaga gcgctccgcg aggagacggc gagtgagata ggcagcagcg 180
agcggagatc gatttgtgaa cagttttgtg gcgggatccc atagcggatg cagagaagac 240
cttagagcag cttcctcggt ggagtgaacg agccagagcg gagggaaggc gcatgaggga 300
actgcaggga ctggaactgc gggagtgcag gtccggtgct aggtccgcta aacagtgcgg 360
tctacgcctg tgtgtgaggt gtgcgtgtgt gtgtgagctg tgcggttttg ttgtgcaaag 420
taggagtgag ccgagccgcg cgtactttgt ggcgtgtttg gctgctggcg ctgagagcca 480
agagagggta aacgggtttg gtattttatg gtgcggggtg aaagcagccc tcgcaggaat 540
ggagcgattc tgcagcatga tgcacgtgtg cctgcgcgtg gatggtggct gttgatatgg 600
ctctgccact ccggcagcac cgctacgata cctagcggtg cctggagtgg tctctctgtt 660
tggtgcgtga tgtttgggtt tgccgttttg attctttgtt tcgtgctgaa tggctgaggc 720
ggcaagaccc ctcgtgccag tgtacagagc ctcacggctc cctcggaccc cgcgtgggga 780
cgtccattcc cggtggcggt gtcgcctcgg cggtgtaaag caaaaaatat ttt 833
<210> 91
<211> 66
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 91
atgcagactt cctcgcttct tggccggcgc acggcccacc cggctgcggg cgcgacgccc 60
aagccg 66
<210> 92
<211> 36
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 92
gttgcgccct cgccccgcgt ggctagcacc cgccag 36
<210> 93
<211> 106
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 93
gtcgcgtgca atgtggcgac tggaccccgg ccgcccatga ccaccttcac cggtggcaac 60
aagggccctg ctaagcagca ggtgtcgctg gatctgcgcg acgagg 106
<210> 94
<211> 161
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 94
gcgctggcat gttcaccagc accagcccgg agatgcgccg tgtcgtccct gacgatgtga 60
agggtcgcgt taaggtgaag gttgtgtacg tggtgctgga ggcccagtac cagtcggcca 120
tcagcgctgc ggtgaagaac atcaacgcca agaactccaa g 161
<210> 95
<211> 135
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 95
gtgtgcttcg aggtggtggg ctacctgctg gaggagctgc gtgaccagaa gaacctcgat 60
atgctcaagg aggatgtggc ctctgccaac atcttcatcg gctcgctcat cttcattgag 120
gagcttgccg agaag 135
<210> 96
<211> 162
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 96
attgtggagg cggtgagccc cctgcgcgag aagctggacg cgtgcctgat cttcccgtcc 60
atgccggcgg tcatgaagct gaacaagctg ggcacgtttt cgatggctca gctgggccag 120
tcgaagtcgg tgttctcgga gttcatcaag tctgctcgca ag 162
<210> 97
<211> 299
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 97
aacaacgaca acttcgagga gggcttgctg aagctggtgc gcaccctgcc taaggtgctg 60
aagtatctgc cctcggacaa ggcgcaggac gccaagaact tcgtgaacag cctgcagtac 120
tggctgggcg gtaactcgga caacctggag aacctgctgc tgaacaccgt cagcaactac 180
gtgcccgctc tgaagggcgt ggacttcagc gtggctgagc ccaccgccta ccccgatgtg 240
ggtatctggc accctctggc ctcgggcatg tacgaggacc tgaaggagta cctgaactg 299
<210> 98
<211> 158
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 98
gtacgacacc cgcaaggaca tggtcttcgc caaggacgcc cccgtcattg gcctggtgct 60
gcagcgctcg cacctggtga ctggcgatga gggccactac agcggcgtgg tcgctgagct 120
ggagagccgc ggtgctaagg tcatccccgt ctttgccg 158
<210> 99
<211> 260
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 99
gtggcctgga cttctccgcc cccgtcaaga agttcttcta cgaccccctg ggctctggcc 60
gcacgttcgt ggacaccgtt gtgtcgctga ccggcttcgc gctggtgggc ggccccgcgc 120
gccaggacgc gccgaaggcc attgaggcgc tgaagaacct gaacgtgccc tacctggtgt 180
cgctgccgct ggtgttccag accactgagg agtggctgga cagcgagctg ggcgtgcacc 240
ccgtccaggt ggctctgcag 260
<210> 100
<211> 1515
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 100
gttgccctgc ccgagctgga tggtgccatg gagcccatcg tgttcgctgg ccgtgactcg 60
aacaccggca agtcgcactc gctgcccgac cgcatcgctt cgctgtgcgc tcgcgccgtg 120
aactgggcca acctgcgcaa gaagcgcaac gccgagaaga agctggccgt caccgtgttc 180
agcttccccc ctgacaaggg caacgtcggc actgccgcct acctgaacgt gttcggctcc 240
atctaccgcg tgctgaagaa cctgcagcgc gagggctacg acgtgggcgc cctgccgccc 300
tcggaggagg atctgatcca gtcggtgctg acccagaagg aggccaagtt caactcgacc 360
gacctgcaca tcgcctacaa gatgaaggtg gacgagtacc agaagctgtg cccttacgcc 420
gaggcgctgg aggagaactg gggcaagccc cccggcaccc tgaacaccaa cggccaggag 480
ctgctggtgt acggccgcca gtacggcaac gtcttcatcg gcgtgcagcc caccttcggc 540
tacgagggcg acccgatgcg cctgctgttc tcgaagtcgg ccagccccca ccacggcttc 600
gccgcctact acaccttcct ggagaagatc ttcaaggccg acgccgtgct gcacttcggc 660
acccacggct cgctggagtt catgcccggc aagcaggtcg gcatgtcggg tgtgtgctac 720
cccgactcgc tgatcggcac catccccaac ctctactact acgccgccaa caacccgtct 780
gaggccacca tcgccaagcg ccgctcgtac gccaacacca tttcgtacct gacgccgcct 840
gccgagaacg ccggcctgta caagggcctg aaggagctga aggagctgat cagctcgtac 900
cagggcatgc gtgagtctgg ccgcgccgag cagatctgcg ccaccatcat tgagaccgcc 960
aagctgtgca acctggaccg cgacgtgacc ctgcccgacg ctgacgccaa ggacctgacc 1020
atggacatgc gcgacagcgt tgtgggccag gtgtaccgca agctgatgga gattgagtcc 1080
cgcctgctgc cctgcggcct gcacgtggtg ggctgcccgc ccaccgccga ggaggccgtg 1140
gccaccctgg tcaacatcgc tgagctggac cgcccggaca acaacccccc catcaagggc 1200
atgcccggca tcctggcccg cgccattggt cgcgacatcg agtcgattta cagcggcaac 1260
aacaagggcg tcctggctga cgttgaccag ctgcagcgca tcaccgaggc ctcccgcacc 1320
tgcgtgcgcg agttcgtgaa ggaccgcacc ggcctgaacg gccgcatcgg caccaactgg 1380
atcaccaacc tgctcaagtt caccggcttc tacgtggacc cctgggtgcg cggcctgcag 1440
aacggcgagt tcgccagcgc caaccgcgag gagctgatca ccctgttcaa ctacctggag 1500
ttctgcctga cccag 1515
<210> 101
<211> 713
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 101
gtggtcaagg acaacgagct gggcgccctg gtagaggcgc tgaacggcca gtacgtcgag 60
cccggccccg gcggtgaccc catccgcaac cccaacgtgc tgcccaccgg caagaacatc 120
cacgccctgg accctcagtc gattcccact caggccgcgc tgaagagcgc ccgcctggtg 180
gtggaccgcc tgctggaccg cgagcgcgac aacaacggcg gcaagtaccc cgagaccatc 240
gcgctggtgc tgtggggcac tgacaacatc aagacctacg gcgagtcgct ggcccaggtc 300
atgatgatgg tcggtgtcaa gcccgtggcc gacgccctgg gccgcgtgaa caagctggag 360
gtgatccctc tggaggagct gggccgcccc cgcgtggacg tggttgtcaa ctgctcgggt 420
gtgttccgcg acctgttcgt gaaccagatg ctgctgctgg accgcgccat caagctggcg 480
gccgagcagg acgagcccga tgagatgaac ttcgtgcgca agcacgccaa gcagcaggcg 540
gcggagctgg gcctgcagag cctgcgcgac gcggccaccc gtgtgttctc caacagctcg 600
ggctcctact cgtccaacgt caacctggcg gtggagaaca gcagctggag cgacgagtcg 660
cagctgcagg agatgtacct gaagcgcaag tcgtacgcct tcaactcgga ccg 713
<210> 102
<211> 589
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 102
ccccggcgcc ggtggcgaga tgcagcgcga cgtgttcgag acggccatga agaccgtgga 60
cgtgaccttc cagaacctgg actcgtccga gatctcgctg accgatgtgt cgcactactt 120
cgactccgac cccaccaagc tggtggcgtc gctgcgcaac gacggccgca cccccaacgc 180
ctacatcgcc gacaccacca ccgccaacgc gcaggtccgc actctgggtg agaccgtgcg 240
cctggacgcc cgcaccaagc tgctcaaccc caagtggtac gagggcatgc ttgcctcggg 300
ctacgagggc gtgcgcgaga tccagaagcg catgaccaac accatgggct ggtcggccac 360
ctcgggcatg gtggacaact gggtgtacga cgaggccaac tcgaccttca tcgaggatgc 420
ggccatggcc gagcgcctga tgaacaccaa ccccaacagc ttccgcaagc tggtggccac 480
cttcctggag gccaacggcc gcggctactg ggacgccaag cccgagcagc tggagcgcct 540
gcgccagctg tacatggacg tggaggacaa gattgagggc gtcgaataa 589
<210> 103
<211> 79
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 103
gtaggtgtaa ttagaaggat caaaacctag cggcctgatc tgggactgac ggcctcgcgc 60
ttcaatcact ctgatgcag 79
<210> 104
<211> 83
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 104
gtaggcacgg cagaatgctc aatgaacatg cagctacata tgtttgggat catggctgat 60
ctctgtgcga cgggtccgcg cag 83
<210> 105
<211> 183
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 105
gtgagcagcg cggaccgagc aagcgctggc gatgcagttg gatttgttgt tcttgggtca 60
ggcgctcgct cgatggccag cgcgtgtatt taatgggata agggttgaga caaagcatct 120
cttcgggtaa aaatcttagt tttcgacagc acgttgagag gcatgcaact tgctctttcg 180
cag 183
<210> 106
<211> 106
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 106
gtgggtaagg agttgcatta tcagtgtggc atggtgttgc gggcgtctgg ggcgctgcaa 60
cagcggcatc gtgccgaact gaccgtgccg ggctacccgc gtgcag 106
<210> 107
<211> 231
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 107
gtgcgctagg gttggggtct ggagggtgtg gattgcgccc aagtgccctg ttgcgcttgg 60
cggtcgctgt catgatgtga gggtgacgta gtgcactcaa ttgcctgcta cgtcaccacc 120
tttgatgggc tggatctgag gcaggtcagc tcggttccct gctgcatcca gtgtccctgt 180
cgccctgcac gtttgacgct gttccccctt ccgcactgtc tcgctttgca g 231
<210> 108
<211> 137
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 108
gtgtgggcac gcgctttggg aagggaggca tacatttttg gttgcggtta ggctgggcgc 60
ggacttggca ctcacacggt cattgcacac tcatgtctca ccttcattta cggtcccttg 120
tgccgaacta cctacag 137
<210> 109
<211> 255
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 109
gtgagcagca tcagggcaga gtgcatgaac ggattggtgg cagtggggaa tggaattaga 60
cggacacgtc tgggcggcaa tatgttgcgc tgcagttttt ggggtgtagt gaactagaaa 120
atagggaaga gataggccac ataacatccg aaagctcata tttttgcaac cggcgcacct 180
atcacagccc acctgaaggg ttttgtagtc aacgcgtgca actgactaga tgtcccctta 240
cctgtctgat ttcag 255
<210> 110
<211> 211
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 110
gtgaggcggg gcggcgctgc cctcggtagg ggttgcagat ggtgatgggt aaccgaatgc 60
atggccaatg gggagtgaaa tcaggaaagg aggggtaaca caatgcaggg cagcacctga 120
atcgtgaagg cggagttagg cagggatctg tcagttcgcc tgtcacgtgg atgggcgcag 180
ctgacctttg tggtgttgtg gtgtggcgca g 211
<210> 111
<211> 192
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 111
gtgagctcag ctgggacatg taggggctcg ggtcgccgga gcatcgatgt agaattacgg 60
gaggagggga gaggggagag gattgcacga accgagatga gggcggtggt tcgggatttc 120
gggcaaaagc tcgtgcggca agcgttcagt gactgaagag cagtgtgctt caactgcccc 180
tctgtccctc ag 192
<210> 112
<211> 167
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 112
gtgcgaccgg tgccgctgcg tggccaacag cttggtgcca ccttcctgcg gtgttgattt 60
acactgtgtg cgtggatgtg ttggtttttc gcaactttag tctgggctcc agctctttgc 120
cttcattgat cactcgtctt acctcctgcg ccatcatttg aatacag 167
<210> 113
<211> 154
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 113
gtgagcctta atgcaacacg tgtagccgtt cgcatgggtg gctgggtcat gctatggttg 60
gatcggcgtc cgcctgcttg ctactgcctg ttcggtacca gcgtttactg accccgcgtg 120
tgccattccc accacctacc ccctcgcctt gcag 154
<210> 114
<211> 149
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 114
gacagtgata tagcaatacc gatataatag gtttggcggg cttcaccttg tccttaccca 60
gaatgtggcc ctgacagtcg atttccagcc cccttgccac tcgctccctg atttcttcaa 120
tcaactagtt gggtcgtttt ctcgtaagg 149
<210> 115
<211> 944
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 115
gggggcgggt ggcgagtaag gcgtatggcg gagcgaggag atgggctgtg gcgtggccgg 60
tgttcttttg tgtgattgga aacatagacg gggtgcggca cgcggcctga ctgctgcgcg 120
gttggtgtgg ttgcgggggg agcggggtcg atggggcagc gcgcacgagt tggttgaagg 180
aggagggcca ggcgctgggc tacacccatg gtttgaggat gctagtgagt gatgtgtgcg 240
gggggcatgg tgtgtaccat tcagagtcca gatgcacgca cggttgcgtg ggagcgttcc 300
ctgctgtgca tgatgatggc gccttcgatg aatcatctct tgaaggtcca aatgaaacgt 360
ctgaagtctg cagagggtgg tgctggacat gccatccagg cggaagtggg cagctgtgtc 420
tgactacaaa gtaggtcttg ttttgcttgg atagcgtttg gctatgtagc gtgtattctg 480
ctcatcaatc acgccaggcg tcagggacta cccatgcaag tcgggagcgt ggctggctct 540
ggaaaagttg tagctgctag gtggcgttgg ctggggtgtc atgcatctcg gcaggtaggc 600
ggtagcggtg gacgacctct gcagcggagc atgtgcacaa gatgtgactg cgcatgcacc 660
cgtatatgac ggcgttggcg tcagttgttg agagtgaaca gaggagagac gagcgaagct 720
gccatgccct tagtggctgg tgcgagaggg gaagaaagag agaggaagga ctttgcggca 780
gtgccccacg ccggagttgg ggacacggtc atcaacaggg cggcggagct gggcggagtg 840
ggtgtgtgat gggacagggt tcaaggcagg ttggcgaggt cggagtgggt agaccagtcc 900
ttcagtgcaa gggcattagg gcatgatgta agggctgaag cttg 944
<210> 116
<211> 116
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 116
atggcgtcgt ttggattgat gcaaaggacg gtgcactgtc cccagcttgt ggaggagcgg 60
tgttcgccgg tcgctggctg ctctggtcgt ggcctgccag ttatccagcg gcaacg 116
<210> 117
<211> 676
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 117
gcgtggcgtg tgcagtgcca ccaacggtgt ccagcgaggg cgtgtgctgc gccggacggc 60
cgcttcgacc gacgtggtct ccttcgtgga ccccaatgac attagaaaac ccgcagcagc 120
agcagctggc cctgcggtgg ataaggtcgg cgttctgctg ttaaaccttg gcgggcccga 180
aaagctcgac gacgtcaagc ctttcctgta taacctattc gccgacccag aaattattcg 240
cctgccagcg gcagctcagt tcctgcagcc gctgctcgcg acgatcatct ccacgcttcg 300
cgccccgaag agcgcggagg gctatgaggc cattggcggt ggtagcccgt tgcgtaggat 360
tacagacgag caggcggagg cgctggcgga gtctctgcgc gccaagggcc aacctgcgaa 420
cgtgtacgtg ggcatgcgct attggcaccc ctacacggag gaggcgctgg agcacattaa 480
ggccgacggc gtcacgcgcc tggtcatcct cccgctgtac cctcagttct ccatctctac 540
cagcggctcc agccttcgac tgcttgagtc gctcttcaag agcgacatcg cgctcaagtc 600
gctgcggcac acggtcatcc cgtcctggta ccagcggcgg ggctacgtga gcgcgatggc 660
ggacctgatt gtagag 676
<210> 118
<211> 138
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 118
gagctgaaga agttccggga cgtgcccagc gtggagctgt ttttctccgc gcacggcgtg 60
cccaagtcct acgtggagga ggcgggcgac ccatacaagg aggagatgga ggagtgcgtg 120
cggctcatta cggacgag 138
<210> 119
<211> 98
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 119
gtcaagcggc gcggcttcgc caacacgcac acgctggcct accagagccg cgtgggcccc 60
gcggaatggc tcaagccgta cacggatgag tccatcaa 98
<210> 120
<211> 119
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 120
ggagctgggc aagcgcggcg tcaagtcgct gctggcggtg cccatcagct ttgtcagcga 60
gcacattgag acgttggagg agatcgacat ggagtaccgc gagctggcgg aggagagcg 119
<210> 121
<211> 135
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 121
gcatccgcaa ctggggccgc gtgccggcgc tgaacaccaa cgccgccttc atcgacgacc 60
tggcggacgc ggtgatggag gcgctgccct acgtgggctg cctggccggg ccgacagact 120
cgctggtgcc gctgg 135
<210> 122
<211> 200
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 122
gcgacctgga gatgctgctg caggcctacg accgcgagcg ccgcacgctg ccgtcaccgg 60
tggtgatgtg ggagtggggc tggaccaaga gcgcggagac gtggaacggc cgcattgcca 120
tgattgccat catcatcatc ctggcgctgg aggcagccag cggccagtcc atcctcaaaa 180
acctgttcct ggcggagtag 200
<210> 123
<211> 66
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 123
gtgcgataat aaatttgcat ccttatgaat tgctcaatga ctaacgagca gcgtccgcga 60
ccacag 66
<210> 124
<211> 527
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 124
gtgagggtgg cattctgtaa agggagttgt ggagttgggc agagcgagtg ggtttggtcg 60
ccagggcgag gatgttgcgc gggcgttggc aggaacaggg ctgctagggc ttgcgtggcc 120
agcgactagg gtttcgactg gccagcgccg ccggggcgcg cttgccgaag ctgcacagcc 180
ccaagcgctt ctgtggatca aatggaaact tgtggcagtg tgtatgctag cgccttggcg 240
caagaccaat tttagtggta ttactgttat tactgtggta gcggtgggta ttcggcggcg 300
tggttgttgt tgcagccccg tgcgactaag accgctggca acgacagcaa gccgccgcac 360
ccaggcatat acggcccacc agcaccaccg tacacaacca cgtgcctttg cactctacgc 420
accacagcgc gctgctgccg ctcccacctc ccatcccaac ggcccctctt acccccactt 480
cacaacccct cctctcacac gccctcctct tccccctcct cttccag 527
<210> 125
<211> 264
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 125
gtgggccggg cgcagcgggc gggcgggagg ggcaggaggg gcaggagggg aggaagggag 60
gggaggaagg gatggaaagc tggcgcagcg gcagcggcgg gacaggtaga gggcgctgcc 120
ccagcggcgg caggtgggca tggtgggcgg gtaggggcga cgcgtgaggg actcgtcagg 180
catccgcatg gcggcgactt gctgctcctc accgctgacg gctgcatctg ctgtgtgcgt 240
aacctggcct ggctggcacc gcag 264
<210> 126
<211> 392
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 126
gtgaggcccg tgggtgggac gcggggaggg acgcggggag ggggagacgc gggagcggga 60
caagggtgag gatacgggga gggaatagga gaggccatgg ggagggatgg ggacacggga 120
ggatgcacgg gcctgggtgg agccaggggg aagtggacga cgagcccggc gggaggaggg 180
ctgggtagaa ggacgcggga ggtggttggg acaggtggac ggggcgtgtg gagcatacgg 240
cgcaagaagc gggactgagc gggttgcagg gatggatgta atcacggcaa gtaagaaccc 300
cgagtggggc tcagcgtgtc agcctgcctt atctttcgcg caagcgctgg ggttttattt 360
cgctgtacac acgtcgcgcc tttctgccgc ag 392
<210> 127
<211> 508
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 127
gtgaggaggc gccggagttt tgggggaagg ggtgcggcgt gaagcgagat ggcaggggcg 60
aaggaaggag cggatggtgg ctgggtgcaa gcggagaggc gacagagagt ggaggttttg 120
gtggagcggt tggggagagg ggcgcagcag ggatgcggcc ctggggatgg cgggacagaa 180
gggagcaagt ttgccaagtg aagggggggg gtgctcaaga ggagagggcg gtggaggtta 240
agacggccgt gctggttatg ctggggttgc aaggcgcatg ggcgcatgga gccgggggag 300
tttggctgtg gatgggcact gcggatgggc acggcttgct actcatgtgc ggtcgcggtc 360
cgcggtgtgt cagccagcca ggacccatcc cactgggtct tcctgcgtgc ctgggactgc 420
ttgccgccac ccacccattc atcaccacca ctgcgcagac ccaccaacac cgctgccctg 480
aactgctctg actcttggcg ctcctcag 508
<210> 128
<211> 686
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 128
gtgagtcgcg ccgtcgcggt tggttcgcgg atgccggttg gcggatgacg ttcggcggtt 60
ggcattgggt ttgggtttga ggggttgttg ggtgaggtcg ggattggggt cgggattggg 120
ggtcgagcgt ggggctggcg tggatgatgg cgtggtcttt ggaaggggct tggggaggtt 180
gcgcgtgtgg atgcggacag catgggcgcg acagtgcgca tgtgcatgtg ctgtgtcaaa 240
cgtctggtgc gttcagtgtg tccttgcgtg cctcccaccg tacgcagcca tcccgcgcgc 300
ctggaccgta gagaccgcct acgtgtccgc tagcggcctc ggcctcagcc taagcgccag 360
tagcgccagc gacacaagca acactgtcgc taatggcagc agcggcagca gcagcagtca 420
cgagaatgcc cgcggccggg agaaagtgct cctagccggg ggccgccgct agctggtttc 480
ctcagcgcgt ggacggtggt gccttcatcc cgaccacccc aggcgcgtcc ccagtcccgt 540
cgagctcgcc tgccttgtgg cccgccttga ccgccctggc gccacccggt ggctcgcata 600
acgactcgct ttccgttctc cgcctgacgc tgtccgcctg acgctctgcg cttgactctt 660
tgcgccttcc tcccctcttc ccccag 686
<210> 129
<211> 4201
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 129
atgcagactt cctcgcttct tggccggcgc acggcccacc cggctgcggg cgcgacgccc 60
aagccggttg cgccctcgcc ccgcgtggct agcacccgcc aggtcgcgtg caatgtggcg 120
actggacccc ggccgcccat gaccaccttc accggtggca acaagggccc tgctaagcag 180
caggtgtcgc tggatctgcg cgacgagggc gctggcatgt tcaccagcac cagcccggag 240
atgcgccgtg tcgtccctga cgatgtgaag ggtcgcgtta aggtgaaggt tgtgtacgtg 300
gtgctggagg cccagtacca gtcggccatc agcgctgcgg tgaagaacat caacgccaag 360
aactccaagg tgtgcttcga ggtggtgggc tacctgctgg aggagctgcg tgaccagaag 420
aacctcgata tgctcaagga ggatgtggcc tctgccaaca tcttcatcgg ctcgctcatc 480
ttcattgagg agcttgccga gaagattgtg gaggcggtga gccccctgcg cgagaagctg 540
gacgcgtgcc tgatcttccc gtccatgccg gcggtcatga agctgaacaa gctgggcacg 600
ttttcgatgg ctcagctggg ccagtcgaag tcggtgttct cggagttcat caagtctgct 660
cgcaagaaca acgacaactt cgaggagggc ttgctgaagc tggtgcgcac cctgcctaag 720
gtgctgaagt atctgccctc ggacaaggcg caggacgcca agaacttcgt gaacagcctg 780
cagtactggc tgggcggtaa ctcggacaac ctggagaacc tgctgctgaa caccgtcagc 840
aactacgtgc ccgctctgaa gggcgtggac ttcagcgtgg ctgagcccac cgcctacccc 900
gatgtgggta tctggcaccc tctggcctcg ggcatgtacg aggacctgaa ggagtacctg 960
aactggtacg acacccgcaa ggacatggtc ttcgccaagg acgcccccgt cattggcctg 1020
gtgctgcagc gctcgcacct ggtgactggc gatgagggcc actacagcgg cgtggtcgct 1080
gagctggaga gccgcggtgc taaggtcatc cccgtctttg ccggtggcct ggacttctcc 1140
gcccccgtca agaagttctt ctacgacccc ctgggctctg gccgcacgtt cgtggacacc 1200
gttgtgtcgc tgaccggctt cgcgctggtg ggcggccccg cgcgccagga cgcgccgaag 1260
gccattgagg cgctgaagaa cctgaacgtg ccctacctgg tgtcgctgcc gctggtgttc 1320
cagaccactg aggagtggct ggacagcgag ctgggcgtgc accccgtcca ggtggctctg 1380
caggttgccc tgcccgagct ggatggtgcc atggagccca tcgtgttcgc tggccgtgac 1440
tcgaacaccg gcaagtcgca ctcgctgccc gaccgcatcg cttcgctgtg cgctcgcgcc 1500
gtgaactggg ccaacctgcg caagaagcgc aacgccgaga agaagctggc cgtcaccgtg 1560
ttcagcttcc cccctgacaa gggcaacgtc ggcactgccg cctacctgaa cgtgttcggc 1620
tccatctacc gcgtgctgaa gaacctgcag cgcgagggct acgacgtggg cgccctgtcc 1680
gccctcggag gaggatctga tccagtcggt gctgacccag aaggaggcca agttcaactc 1740
gaccgacctg cacatcgcct acaagatgaa ggtggacgag taccagaagc tgtgccctta 1800
cgccgaggcg ctggaggaga actggggcaa gccccccggc accctgaaca ccaacggcca 1860
ggagctgctg gtgtacggcc gccagtacgg caacgtcttc atcggcgtgc agcccacctt 1920
cggctacgag ggcgacccga tgcgcctgct gttctcgaag tcggccagcc cccaccacgg 1980
cttcgccgcc tactacacct tcctggagaa gatcttcaag gccgacgccg tgctgcactt 2040
cggcacccac ggctcgctgg agttcatgcc cggcaagcag gtcggcatgt cgggtgtgtg 2100
ctaccccgac tcgctgatcg gcaccatccc caacctctac tactacgccg ccaacaaccc 2160
gtctgaggcc accatcgcca agcgccgctc gtacgccaac accatttcgt acctgacgcc 2220
gcctgccgag aacgccggcc tgtacaaggg cctgaaggag ctgaaggagc tgatcagctc 2280
gtaccagggc atgcgtgagt ctggccgcgc cgagcagatc tgcgccacca tcattgagac 2340
cgccaagctg tgcaacctgg accgcgacgt gaccctgccc gacgctgacg ccaaggacct 2400
gaccatggac atgcgcgaca gcgttgtggg ccaggtgtac cgcaagctga tggagattga 2460
gtcccgcctg ctgccctgcg gcctgcacgt ggtgggctgc ccgcccaccg ccgaggaggc 2520
cgtggccacc ctggtcaaca tcgctgagct ggaccgcccg gacaacaacc cccccatcaa 2580
gggcatgccc ggcatcctgg cccgcgccat tggtcgcgac atcgagtcga tttacagcgg 2640
caacaacaag ggcgtcctgg ctgacgttga ccagctgcag cgcatcaccg aggcctcccg 2700
cacctgcgtg cgcgagttcg tgaaggaccg caccggcctg aacggccgca tcggcaccaa 2760
ctggatcacc aacctgctca agttcaccgg cttctacgtg gacccctggg tgcgcggcct 2820
gcagaacggc gagttcgcca gcgccaaccg cgaggagctg atcaccctgt tcaactacct 2880
ggagttctgc ctgacccagg tggtcaagga caacgagctg ggcgccctgg tagaggcgct 2940
gaacggccag tacgtcgagc ccggccccgg cggtgacccc atccgcaacc ccaacgtgct 3000
gcccaccggc aagaacatcc acgccctgga ccctcagtcg attcccactc aggccgcgct 3060
gaagagcgcc cgcctggtgg tggaccgcct gctggaccgc gagcgcgaca acaacggcgg 3120
caagtacccc gagaccatcg cgctggtgct gtggggcact gacaacatca agacctacgg 3180
cgagtcgctg gcccaggtca tgatgatggt cggtgtcaag cccgtggccg acgccctggg 3240
ccgcgtgaac aagctggagg tgatccctct ggaggagctg ggccgccccc gcgtggacgt 3300
ggttgtcaac tgctcgggtg tgttccgcga cctgttcgtg aaccagatgc tgctgctgga 3360
ccgcgccatc aagctggcgg ccgagcagga cgagcccgat gagatgaact tcgtgcgcaa 3420
gcacgccaag cagcaggcgg cggagctggg cctgcagagc ctgcgcgacg cggccacccg 3480
tgtgttctcc aacagctcgg gctcctactc gtccaacgtc aacctggcgg tggagaacag 3540
cagctggagc gacgagtcgc agctgcagga gatgtacctg aagcgcaagt cgtacgcctt 3600
caactcggac cgccccggcg ccggtggcga gatgcagcgc gacgtgttcg agacggccat 3660
gaagaccgtg gacgtgacct tccagaacct ggactcgtcc gagatctcgc tgaccgatgt 3720
gtcgcactac ttcgactccg accccaccaa gctggtggcg tcgctgcgca acgacggccg 3780
cacccccaac gcctacatcg ccgacaccac caccgccaac gcgcaggtcc gcactctggg 3840
tgagaccgtg cgcctggacg cccgcaccaa gctgctcaac cccaagtggt acgagggcat 3900
gcttgcctcg ggctacgagg gcgtgcgcga gatccagaag cgcatgacca acaccatggg 3960
ctggtcggcc acctcgggca tggtggacaa ctgggtgtac gacgaggcca actcgacctt 4020
catcgaggat gcggccatgg ccgagcgcct gatgaacacc aaccccaaca gcttccgcaa 4080
gctggtggcc accttcctgg aggccaacgg ccgcggctac tgggacgcca agcccgagca 4140
gctggagcgc ctgcgccagc tgtacatgga cgtggaggac aagattgagg gcgtcgaata 4200
a 4201
<210> 130
<211> 263
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 130
tcctacagag taaaggtcta ggcgatgcgc gactgaaaga ctgtgaatcc cggcgtcgcc 60
gtggtgggat gtgggccggt gcgctgtcgc agaggataaa ttacaggtat caaacaaggt 120
tagggcgttg gaaggagcgg cgctagggaa ctgaaatcgg atctgcatcg gaccctcatt 180
ccgcgacttg tccttctttt gcctcgcccc gcagctcttg agttttgttc ttgacccttt 240
gacacgaacc aaccgatata aaa 263
<210> 131
<211> 843
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 131
gcggcaggcc ttcatggtcg tcgttggagc atttgcggaa aggctgatgg cagcagatgc 60
agccatgtca gttgtggctg aagttgttgg ctggggcggg agcgggcagc agctgctgcg 120
agcggccgaa gcagcggtgc tgctttgcgt atgagaggaa gaccagtgcc ctcgaggagg 180
cgagtgcctg tgtgagtgtc aggacgtgtg acttcggaaa ctgagggcgg tgagtagatg 240
tgactggggc ttgcaggaag cctactgacc ctatcagaaa aggtgagcag gggtatatgg 300
tctaggagcg ttgccggagc gtggctggcc agtgctagcc gcgcgggctc tgttgctcgc 360
tggcgcgccg ccgccttcac aacagatgcc gtagaaatgc agcgatgtga cgaggcgtgg 420
cctattctgc aatgtgtgag gcgccaatgg cgccactgac aaatggagga gtggtcaaag 480
cttgggtacg ttttgagagc tgcatcgggc agcgaggatc agtgtgcggt aagaccgacg 540
gcagacggat tggcaaggga ataggaggga cgtgggcgtg ggcgcccgcg ctttgtcgag 600
gccgcatgag ccggccgctt ctagacccgt agcccatttt gaacaagcgc ccacgcgtgc 660
tcccgatggg ggacatcgat cacgggaatt gattaagggg catgtgtggt gtgcaagtga 720
gtgactggtg gttccgtccc tgtgaggttg tttcgttgga cgtggctgcc gggttgcgcg 780
cgggctaagc gggcctgagg cagagcgctg gcgtgtagcc gcgagtatcg atctgtaacg 840
tgc 843
<210> 132
<211> 120
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 132
atggccctga acatgcgtgt ttcctcttcc aaggtcgctg ccaagcagca gggccgcatc 60
tccgcggtgc cggttgtgtc gagcaaggtg gcctcctccg cccgcgtggc ccccttccag 120
<210> 133
<211> 37
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 133
ggcgctcccg tggccgcgca gcgcgctgct ctgctgg 37
<210> 134
<211> 60
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 134
tgcgcgccgc tgccgctact gaggtcaagg ctgctgaggg ccgcactgag aaggagctgg 60
<210> 135
<211> 176
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 135
gccaggcccg ccccatcttc cccttcaccg ccatcgtggg ccaggatgag atgaagctgg 60
cgctgattct gaacgtgatc gaccccaaga tcggtggtgt catgatcatg ggcgaccgtg 120
gcactggcaa gtccaccacc attcgtgccc tggcggatct gctgcccgag atgcag 176
<210> 136
<211> 193
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 136
gtggttgcca acgacccctt taactcggac cccaccgacc ccgagctgat gagcgaggag 60
gtgcgcaacc gcgtcaaggc cggcgagcag ctgcccgtgt cttccaagaa gattcccatg 120
gtggacctgc ccctgggcgc cactgaggac cgcgtgtgcg gcaccatcga catcgagaag 180
gcgctgaccg agg 193
<210> 137
<211> 89
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 137
gtgtcaaggc gttcgagccc ggcctgctgg ccaaggccaa ccgcggcatc ctgtacgtgg 60
atgaggtcaa cctgctggac gaccacctg 89
<210> 138
<211> 100
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 138
gtcgatgtgc tgctggactc ggccgcctcc ggctggaaca ccgtggagcg cgagggtatc 60
tccatcagcc accccgcccg cttcatcctg gtcggctcgg 100
<210> 139
<211> 145
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 139
gcaaccccga ggagggtgag ctgcgccccc agctgctgga tcgcttcggc atgcacgccc 60
agatcggcac cgtcaaggac ccccgcctgc gtgtgcagat cgtgtcgcag cgctcgacct 120
tcgacgagaa ccccgccgcc ttccg 145
<210> 140
<211> 202
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 140
caaggactac gaggccggcc agatggcgct gacccagcgc atcgtggacg cgcgcaagct 60
gctgaagcag ggcgaggtca actacgactt ccgcgtcaag atcagccaga tctgctcgga 120
cctgaacgtg gacggcatcc gcggcgacat cgtgaccaac cgcgccgcca aggccctggc 180
cgccttcgag ggccgcaccg ag 202
<210> 141
<211> 132
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 141
gtgacccccg aggacatcta ccgtgtcatt cccctgtgcc tgcgccaccg cctccggaaa 60
gaccccctgg ctgagatcga cgacggtgac cgcgtgcgtg agatcttcaa gcaggtgttc 120
ggcatggagt aa 132
<210> 142
<211> 101
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 142
gtgtgcagtt gcatctaaag aacgtccaat tcatggttac tgctcgtgga tctaagcggt 60
tggctcacca gcgttccatg gtccccgatt cgtgcacgca g 101
<210> 143
<211> 121
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 143
gtgagaagcc atgatacaaa tataaggatt tgaagcggta gatctaggac ccatcgaact 60
tgagcaccga cttgcagtcc ttgccttgtc cggcgactga acttctgcgc ttgctttgca 120
g 121
<210> 144
<211> 82
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 144
gtaagtgtcg cgcaaagatt ttctgccggg acgggtctcc ctcgcaacat ctgaacccat 60
ggctcgtttt tttgccccgc ag 82
<210> 145
<211> 397
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 145
gtgcgcgcct cccccaaccc cagtttggca aatgtgtggt taagcgtcga aagcgtgaac 60
agaaacaggt gttgcggggg ccgcggaatg gctgcaatgg gtgctggggg cttcggaggg 120
tctgggggcg agtttgggta tacacgggcg cgcacacttg aaggaacgct caaggacgac 180
agcggaggcg tggagacagc gccggcccaa gcagcctgta cttgtagctg ctggtcagct 240
gaggcatcac gacttgggac cagcacccgg cctcacggtt gcacaaggcc atcaccgcgc 300
gccaccaccc acgcctcttc aaacccatgc cggcacctac cgctacccct gtgacacgct 360
ccgcacacgc cgccccgcac accccaccat gtgacag 397
<210> 146
<211> 156
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 146
gtgagagcga ggcgcggggc gtgctctgca ggctagggtg aagatcagga gagccgaagc 60
gggcccgaac agcgcagaga gaggcaagac gacacccctg ccgcgttttg atcacaagat 120
tcacaccctt gctctcccca acgctcccgc acatag 156
<210> 147
<211> 476
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 147
gtgagcaggg gcagataggc ggtcgggcgg ctgggcggca ggggctgtgt tggctgtgtt 60
gggtgtgggc tgaggctggt gggtgggctg gcgggtggca gggatagcgg tgaggggatg 120
gtgatggggc agaatgggcg ggtgggcgga cacgtggggt cgttgaaggg tgtgtgggga 180
cggcaactgg tatgcgatat gtcggcttgg ccctggcggg gaaagcattc gcagaatggc 240
gcacgaacga ggccggggag cgagcgggga tgggagacgc aacctgcgct gcgaagtgcg 300
gcgcgcgctc cagttgacac gttgcacgaa tgtggccagt gttcgcctga gagttatggg 360
ttagaccgcc agatgagccg gttaagctgg tggtcgcggt tgatcggctg cttcccttcc 420
ggttgcacgc ctggcaccct aacattaccc tgtccgctgc tgccctttgc ccacag 476
<210> 148
<211> 191
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 148
gtgagtgcag ctgccgctgc ggctgctgat ggtgacctgt gcgaccacgg ggctccgcat 60
ttctggacga agcgttgtac catagccgtc ttggtccctg atttgggccg gctctggtcc 120
gaagccttga catctacagt tcaacatggc cgtataacga tcctgtgccc acccacacgc 180
caccccgcca g 191
<210> 149
<211> 212
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 149
gtgagcgcgc gctctacgat acggcagaca tgtacacact gcggcgcact gtagagcttg 60
cattgcattt caaggcctcg aaagagtagg gtggtcgttc tctggtggtg tccggccaca 120
attatgcacc ccggtgttgg tgcagcagct gtgatgtcac accttgcatc acccccctac 180
tgctgccgcc tctcctctct tctcgcccgc ag 212
<210> 150
<211> 211
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 150
gtgagcagag caatattgca gagggaaggg tggcggaagg gtgataacgg ttggggatct 60
agaggggcga gatggatgca cacagcgcgg ggttggttat gcatgcctgc atggacgcgt 120
gcacgcaccc ctgatctgcc ggttttccaa ctggcgatgc cgtattatga cctgcagctc 180
accatcctca tgcttgattt gcctcgctca g 211
<210> 151
<211> 417
<212> PRT
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 151
Met Ala Leu Asn Met Arg Val Ser Ser Ser Lys Val Ala Ala Lys Gln
1 5 10 15
Gln Gly Arg Ile Ser Ala Val Pro Val Val Ser Ser Lys Val Ala Ser
20 25 30
Ser Ala Arg Val Ala Pro Phe Gln Gly Ala Pro Val Ala Ala Gln Arg
35 40 45
Ala Ala Leu Leu Val Arg Ala Ala Ala Ala Thr Glu Val Lys Ala Ala
50 55 60
Glu Gly Arg Thr Glu Lys Glu Leu Gly Gln Ala Arg Pro Ile Phe Pro
65 70 75 80
Phe Thr Ala Ile Val Gly Gln Asp Glu Met Lys Leu Ala Leu Ile Leu
85 90 95
Asn Val Ile Asp Pro Lys Ile Gly Gly Val Met Ile Met Gly Asp Arg
100 105 110
Gly Thr Gly Lys Ser Thr Thr Ile Arg Ala Leu Ala Asp Leu Leu Pro
115 120 125
Glu Met Gln Val Val Ala Asn Asp Pro Phe Asn Ser Asp Pro Thr Asp
130 135 140
Pro Glu Leu Met Ser Glu Glu Val Arg Asn Arg Val Lys Ala Gly Glu
145 150 155 160
Gln Leu Pro Val Ser Ser Lys Lys Ile Pro Met Val Asp Leu Pro Leu
165 170 175
Gly Ala Thr Glu Asp Arg Val Cys Gly Thr Ile Asp Ile Glu Lys Ala
180 185 190
Leu Thr Glu Gly Val Lys Ala Phe Glu Pro Gly Leu Leu Ala Lys Ala
195 200 205
Asn Arg Gly Ile Leu Tyr Val Asp Glu Val Asn Leu Leu Asp Asp His
210 215 220
Leu Val Asp Val Leu Leu Asp Ser Ala Ala Ser Gly Trp Asn Thr Val
225 230 235 240
Glu Arg Glu Gly Ile Ser Ile Ser His Pro Ala Arg Phe Ile Leu Val
245 250 255
Gly Ser Gly Asn Pro Glu Glu Gly Glu Leu Arg Pro Gln Leu Leu Asp
260 265 270
Arg Phe Gly Met His Ala Gln Ile Gly Thr Val Lys Asp Pro Arg Leu
275 280 285
Arg Val Gln Ile Val Ser Gln Arg Ser Thr Phe Asp Glu Asn Pro Ala
290 295 300
Ala Phe Arg Lys Asp Tyr Glu Ala Gly Gln Met Ala Leu Thr Gln Arg
305 310 315 320
Ile Val Asp Ala Arg Lys Leu Leu Lys Gln Gly Glu Val Asn Tyr Asp
325 330 335
Phe Arg Val Lys Ile Ser Gln Ile Cys Ser Asp Leu Asn Val Asp Gly
340 345 350
Ile Arg Gly Asp Ile Val Thr Asn Arg Ala Ala Lys Ala Leu Ala Ala
355 360 365
Phe Glu Gly Arg Thr Glu Val Thr Pro Glu Asp Ile Tyr Arg Val Ile
370 375 380
Pro Leu Cys Leu Arg His Arg Leu Arg Lys Asp Pro Leu Ala Glu Ile
385 390 395 400
Asp Asp Gly Asp Arg Val Arg Glu Ile Phe Lys Gln Val Phe Gly Met
405 410 415
Glu
<210> 152
<211> 721
<212> PRT
<213> 人工序列(Artificial Sequence)
<400> 152
Met Gln Thr Ser Ser Leu Leu Gly Arg Arg Thr Ala His Pro Ala Ala
1 5 10 15
Gly Ala Thr Pro Lys Pro Val Ala Pro Ser Pro Arg Val Ala Ser Thr
20 25 30
Arg Gln Val Ala Cys Asn Val Ala Thr Gly Pro Arg Pro Pro Met Thr
35 40 45
Thr Phe Thr Gly Gly Asn Lys Gly Pro Ala Lys Gln Gln Val Ser Leu
50 55 60
Asp Leu Arg Asp Glu Gly Ala Gly Met Phe Thr Ser Thr Ser Pro Glu
65 70 75 80
Met Arg Arg Val Val Pro Asp Asp Val Lys Gly Arg Val Lys Val Lys
85 90 95
Val Val Tyr Val Val Leu Glu Ala Gln Tyr Gln Ser Ala Ile Ser Ala
100 105 110
Ala Val Lys Asn Ile Asn Ala Lys Asn Ser Lys Val Cys Phe Glu Val
115 120 125
Val Gly Tyr Leu Leu Glu Glu Leu Arg Asp Gln Lys Asn Leu Asp Met
130 135 140
Leu Lys Glu Asp Val Ala Ser Ala Asn Ile Phe Ile Gly Ser Leu Ile
145 150 155 160
Phe Ile Glu Glu Leu Ala Glu Lys Ile Val Glu Ala Val Ser Pro Leu
165 170 175
Arg Glu Lys Leu Asp Ala Cys Leu Ile Phe Pro Ser Met Pro Ala Val
180 185 190
Met Lys Leu Asn Lys Leu Gly Thr Phe Ser Met Ala Gln Leu Gly Gln
195 200 205
Ser Lys Ser Val Phe Ser Glu Phe Ile Lys Ser Ala Arg Lys Asn Asn
210 215 220
Asp Asn Phe Glu Glu Gly Leu Leu Lys Leu Val Arg Thr Leu Pro Lys
225 230 235 240
Val Leu Lys Tyr Leu Pro Ser Asp Lys Ala Gln Asp Ala Lys Asn Phe
245 250 255
Val Asn Ser Leu Gln Tyr Trp Leu Gly Gly Asn Ser Asp Asn Leu Glu
260 265 270
Asn Leu Leu Leu Asn Thr Val Ser Asn Tyr Val Pro Ala Leu Lys Gly
275 280 285
Val Asp Phe Ser Val Ala Glu Pro Thr Ala Tyr Pro Asp Val Gly Ile
290 295 300
Trp His Pro Leu Ala Ser Gly Met Tyr Glu Asp Leu Lys Glu Tyr Leu
305 310 315 320
Asn Trp Tyr Asp Thr Arg Lys Asp Met Val Phe Ala Lys Asp Ala Pro
325 330 335
Val Ile Gly Leu Val Leu Gln Arg Ser His Leu Val Thr Gly Asp Glu
340 345 350
Gly His Tyr Ser Gly Val Val Ala Glu Leu Glu Ser Arg Gly Ala Lys
355 360 365
Val Ile Pro Val Phe Ala Gly Gly Leu Asp Phe Ser Ala Pro Val Lys
370 375 380
Lys Phe Phe Tyr Asp Pro Leu Gly Ser Gly Arg Thr Phe Val Asp Thr
385 390 395 400
Val Val Ser Leu Thr Gly Phe Ala Leu Val Gly Gly Pro Ala Arg Gln
405 410 415
Asp Ala Pro Lys Ala Ile Glu Ala Leu Lys Asn Leu Asn Val Pro Tyr
420 425 430
Leu Val Ser Leu Pro Leu Val Phe Gln Thr Thr Glu Glu Trp Leu Asp
435 440 445
Ser Glu Leu Gly Val His Pro Val Gln Val Ala Leu Gln Val Ala Leu
450 455 460
Pro Glu Leu Asp Gly Ala Met Glu Pro Ile Val Phe Ala Gly Arg Asp
465 470 475 480
Ser Asn Thr Gly Lys Ser His Ser Leu Pro Asp Arg Ile Ala Ser Leu
485 490 495
Cys Ala Arg Ala Val Asn Trp Ala Asn Leu Arg Lys Lys Arg Asn Ala
500 505 510
Glu Lys Lys Leu Ala Val Thr Val Phe Ser Phe Pro Pro Asp Lys Gly
515 520 525
Asn Val Gly Thr Ala Ala Tyr Leu Asn Val Phe Gly Ser Ile Tyr Arg
530 535 540
Val Leu Lys Asn Leu Gln Arg Glu Gly Tyr Asp Val Gly Ala Leu Ser
545 550 555 560
Ala Leu Gly Gly Gly Ser Asp Pro Val Gly Ala Asp Pro Glu Gly Gly
565 570 575
Gln Val Gln Leu Asp Arg Pro Ala His Arg Leu Gln Asp Glu Gly Gly
580 585 590
Arg Val Pro Glu Ala Val Pro Leu Arg Arg Gly Ala Gly Gly Glu Leu
595 600 605
Gly Gln Ala Pro Arg His Pro Glu His Gln Arg Pro Gly Ala Ala Gly
610 615 620
Val Arg Pro Pro Val Arg Gln Arg Leu His Arg Arg Ala Ala His Leu
625 630 635 640
Arg Leu Arg Gly Arg Pro Asp Ala Pro Ala Val Leu Glu Val Gly Gln
645 650 655
Pro Pro Pro Arg Leu Arg Arg Leu Leu His Leu Pro Gly Glu Asp Leu
660 665 670
Gln Gly Arg Arg Arg Ala Ala Leu Arg His Pro Arg Leu Ala Gly Val
675 680 685
His Ala Arg Gln Ala Gly Arg His Val Gly Cys Val Leu Pro Arg Leu
690 695 700
Ala Asp Arg His His Pro Gln Pro Leu Leu Leu Arg Arg Gln Gln Pro
705 710 715 720
Val
<210> 153
<211> 1254
<212> DNA
<213> 莱茵衣藻(Chlamydomonas reinhardtii)
<400> 153
atggccctga acatgcgtgt ttcctcttcc aaggtcgctg ccaagcagca gggccgcatc 60
tccgcggtgc cggttgtgtc gagcaaggtg gcctcctccg cccgcgtggc ccccttccag 120
ggcgctcccg tggccgcgca gcgcgctgct ctgctggtgc gcgccgctgc cgctactgag 180
gtcaaggctg ctgagggccg cactgagaag gagctgggcc aggcccgccc catcttcccc 240
ttcaccgcca tcgtgggcca ggatgagatg aagctggcgc tgattctgaa cgtgatcgac 300
cccaagatcg gtggtgtcat gatcatgggc gaccgtggca ctggcaagtc caccaccatt 360
cgtgccctgg cggatctgct gcccgagatg caggtggttg ccaacgaccc ctttaactcg 420
gaccccaccg accccgagct gatgagcgag gaggtgcgca accgcgtcaa ggccggcgag 480
cagctgcccg tgtcttccaa gaagattccc atggtggacc tgcccctggg cgccactgag 540
gaccgcgtgt gcggcaccat cgacatcgag aaggcgctga ccgagggtgt caaggcgttc 600
gagcccggcc tgctggccaa ggccaaccgc ggcatcctgt acgtggatga ggtcaacctg 660
ctggacgacc acctggtcga tgtgctgctg gactcggccg cctccggctg gaacaccgtg 720
gagcgcgagg gtatctccat cagccacccc gcccgcttca tcctggtcgg ctcgggcaac 780
cccgaggagg gtgagctgcg cccccagctg ctggatcgct tcggcatgca cgcccagatc 840
ggcaccgtca aggacccccg cctgcgtgtg cagatcgtgt cgcagcgctc gaccttcgac 900
gagaaccccg ccgccttccg caaggactac gaggccggcc agatggcgct gacccagcgc 960
atcgtggacg cgcgcaagct gctgaagcag ggcgaggtca actacgactt ccgcgtcaag 1020
atcagccaga tctgctcgga cctgaacgtg gacggcatcc gcggcgacat cgtgaccaac 1080
cgcgccgcca aggccctggc cgccttcgag ggccgcaccg aggtgacccc cgaggacatc 1140
taccgtgtca ttcccctgtg cctgcgccac cgcctccgga aagaccccct ggctgagatc 1200
gacgacggtg accgcgtgcg tgagatcttc aagcaggtgt tcggcatgga gtaa 1254
- 将藻类血红素掺入到可食用产品中的组合物和方法
- 水溶性萘醌衍生物组合物和其制备方法、有害藻类控制用水溶性组合物、大规模有害藻类控制方法、以及大规模有害藻类人工智能监控、去除以及预防自动化系统