抗人FcRn单域抗体及其应用
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于肿瘤免疫疗法和分子免疫学领域,具体涉及抗体领域。
背景技术
药物研发过程中,抗体药物的半衰期和渗透性是需要关注的内容。目前市场上常用的抗体药物包括全抗体药物,如IgG,和抗体片段药物,如VHH、sdAb和Fab等。这两种药物各有利弊。IgG抗体的半衰期一般相对较长,这主要源于FcRn介导的代谢调控。当IgG被血液内皮细胞胞吞后,在溶酶体酸性条件下,IgG的Fc片段与FcRn结合,避免被溶酶体降解,进而通过胞吐循环到细胞表面,在pH 7.4的环境下,IgG抗体被FcRn释放出来。通过这种受体介导的再循环机制,FcRn从溶酶体中有效援救出IgG,从而延长了循环IgG的半衰期。片段型抗体由于分子量较小,相较于传统的全抗体,其具有渗透性高、免疫原性低等优势,越来越受到重视并被广泛应用。
但是片段型抗体缺乏与FcRn pH依赖性结合的能力,半衰期较短。目前市场上常规的方法是通过偶联Fc或者HSA,赋予片段型抗体与FcRn pH依赖结合的能力,从而提高半衰期,例如康宁杰瑞的KN035。然而,对非细胞毒性的抗体药物,例如治疗自身免疫疾病的药物,其作用机制并不依靠Fc介导的ADCC或者CDC作用,对于这些药物,偶联Fc或HSA这样分子量较大的片段反而会削弱片段型抗体高渗透性、地免疫原性的优势。因此有必要开发一种能够抗体半衰期长同时不破坏抗体渗透性高免疫原性低的抗体。
发明内容
在一方面,本文提供了靶向FcRn蛋白的抗体或其抗原结合片段,其中所述抗体包括重链可变区,所述重链可变区包括HCDR1、HCDR2和HCDR3,所述HCDR1、HCDR2和HCDR3选自如下组合之一:
(1)HCDR1的氨基酸序列如SEQ ID NO:3所示;
HCDR2的氨基酸序列如SEQ ID NO:5所示;
HCDR3的氨基酸序列如SEQ ID NO:7所示;
(2)HCDR1的氨基酸序列如SEQ ID NO:11所示;
HCDR2的氨基酸序列如SEQ ID NO:13所示;
HCDR3的氨基酸序列如SEQ ID NO:15所示;
(3)HCDR1的氨基酸序列如SEQ ID NO:19所示;
HCDR2的氨基酸序列如SEQ ID NO:21所示;
HCDR3的氨基酸序列如SEQ ID NO:23所示;
(4)HCDR1的氨基酸序列如SEQ ID NO:27所示;
HCDR2的氨基酸序列如SEQ ID NO:29所示;
HCDR3的氨基酸序列如SEQ ID NO:31所示;
(5)HCDR1的氨基酸序列如SEQ ID NO:35所示;
HCDR2的氨基酸序列如SEQ ID NO:37所示;
HCDR3的氨基酸序列如SEQ ID NO:39所示;
(6)HCDR1的氨基酸序列如SEQ ID NO:43所示;
HCDR2的氨基酸序列如SEQ ID NO:45所示;
HCDR3的氨基酸序列如SEQ ID NO:47所示;以及
(7)HCDR1的氨基酸序列如SEQ ID NO:51所示;
HCDR2的氨基酸序列如SEQ ID NO:53所示;
HCDR3的氨基酸序列如SEQ ID NO:55所示,
或者,
所述抗体为(1)-(7)任一项中通过HCDR1、HCDR2和HCDR3的氨基酸序列定义的抗体的变体,其中所述变体与(1)-(7)任一项中定义的抗体相比,在HCDR1、HCDR2和HCDR3序列上共包含至少1个且不超过10个、9个、8个、7个、6个、5个、4个、3个或2个氨基酸改变。
在一些实施方案中,所述重链可变区的氨基酸序列选自如下任一项:
(1)SEQ ID NO:1所示序列或与其有至少90%序列一致性的重链可变区序列;
(2)SEQ ID NO:9所示序列或与其有至少90%序列一致性的重链可变区序列;
(3)SEQ ID NO:17所示序列或与其有至少90%序列一致性的重链可变区序列;
(4)SEQ ID NO:25所示序列或与其有至少90%序列一致性的重链可变区序列;
(5)SEQ ID NO:33所示序列或与其有至少90%序列一致性的重链可变区序列;
(6)SEQ ID NO:41所示序列或与其有至少90%序列一致性的重链可变区序列;以及
(7)SEQ ID NO:49所示序列或与其有至少90%序列一致性的重链可变区序列。
在一些实施方案中,所述抗体为单域抗体。
在一些实施方案中,所述FcRn蛋白为人FcRn蛋白或猴FcRn蛋白。
在一些实施方案中,所述抗体或其抗原结合片段在细胞溶酶体内对所述FcRn的结合亲和力高于在细胞质内对所述FcRn蛋白的结合亲和力。
在一些实施方案中,所述抗体或其抗原结合片段在pH 5.5-6.5时对所述FcRn的结合亲和力高于在pH 7.0-8.0时对所述FcRn蛋白的结合亲和力。
在一些实施方案中,通过表面等离子共振技术测定,所述抗体或其抗原结合片段其pH 6.0时与人FcRn蛋白结合的KD值为不高于10
另一方面,本文提供了蛋白构建体,包括第一功能部分和第二功能部分,其中所述第二功能部分能够靶向FcRn蛋白,并由此赋予所述第一功能部分在体内增加的半衰期。
在一些实施方案中,所述第二功能部分在细胞溶酶体内对所述FcRn蛋白的结合亲和力高于在细胞质内对所述FcRn蛋白的结合亲和力。
在一些实施方案中,所述第二功能部分在pH 5.5-6.5时与所述FcRn蛋白的结合亲和力高于在pH 7.0-8.0时对所述FcRn的结合亲和力。
在一些实施方案中,所述第二功能部分为抗体或其抗原结合片段。
在一些实施方案中,所述第二功能部分为本文提供的抗体或其抗原结合片段。
在一些实施方案中,所述第一功能部分为治疗性蛋白,例如酶、蛋白类激素、细胞因子。
在一些实施方案中,所述第一功能部分为不同于所述第二功能部分的抗体或其抗原结合片段,优选为抗癌症抗原的抗体或抗免疫检查点抗体。
在一些实施方案中,所述第一功能部分与所述第二部分通过共价键连接。
在一些实施方案中,所述蛋白构建体为融合蛋白形式,优选所述第一功能部分位于所述第二功能部分的N端。
在一些实施方案中,所述第一功能部分与所述第二功能部分之间通过短肽接头连接。
在一些实施方案中,所述FcRn蛋白为人FcRn蛋白或猴FcRn蛋白。
另一方面,本文提供了增加目的蛋白在体内的半衰期的方法,包括将所述目的蛋白与能够靶向FcRn蛋白的功能部分连接。
在一些实施方案中,所述功能部分在细胞溶酶体内对所述FcRn的结合亲和力高于在细胞质内对所述FcRn的结合亲和力。
在一些实施方案中,所述功能部分在pH 5.5-6.5时与所述FcRn蛋白的结合亲和力高于在pH 7.0-8.0时对所述FcRn的结合亲和力。
在一些实施方案中,所述功能部分为抗体或其抗原结合片段。
在一些实施方案中,所述功能部分为本文提供的抗体或其抗原结合片段。
在一些实施方案中,所述目的蛋白为治疗性蛋白,例如酶、蛋白类激素、细胞因子。
在一些实施方案中,所述目的蛋白为不同于所述功能部分的抗体或其抗原结合片段,优选为抗癌症抗原的抗体或抗免疫检查点抗体。
在一些实施方案中,所述目的蛋白和所述第二功能部分存在于同一融合蛋白中,优选所述第一功能部分位于所述第二功能部分的N端。
在一些实施方案中,所述目的蛋白和所述第二功能部分通过短肽接头连接。
另一方面,本文提供了核酸分子,其编码本文提供的抗体或其抗原结合片段或融合蛋白。
另一方面,本文提供了表达载体,其包括上述核酸分子。
另一方面,本文提供了宿主细胞,其包括上述表达载体或表达本文提供的抗体或其抗原结合片段或上述的融合蛋白。
本文提供的单域抗体与FcRn蛋白的结合亲和力随pH变化,当其与功能性蛋白(如治疗性蛋白或抗体)融合后可增加后者在体内的半衰期。
附图说明
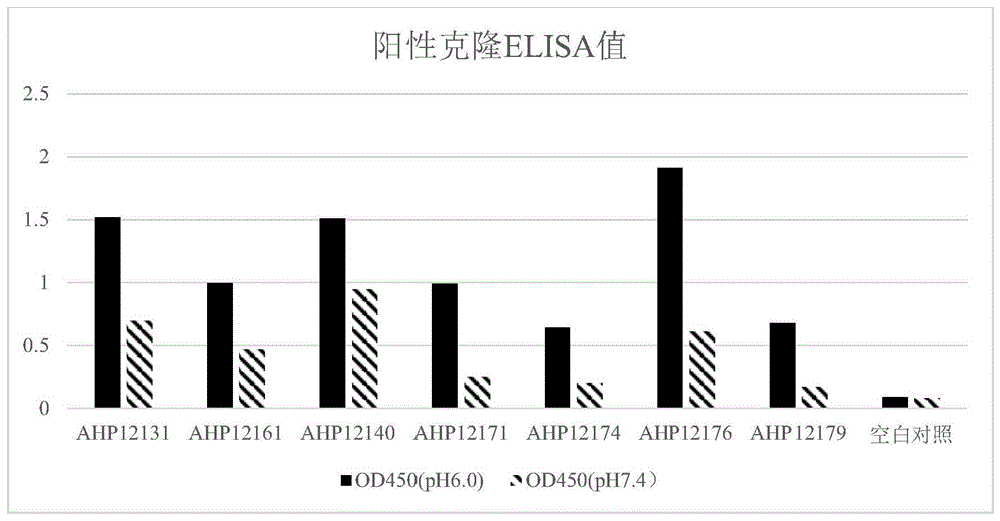
图1显示了一些实施例中阳性克隆的ELISA检测结果。
图2显示了一些实施例中四种融合抗体结构示意图。
图3显示了一些实施例中融合抗体对靶抗原人源PDL1蛋白的亲和力检测结果。
图4显示了一些实施例中在特定pH条件下融合抗体对人源FcRn蛋白的亲和力检测结果。
图5显示了一些实施例中在特定pH条件下融合抗体对人源FcRn蛋白的亲和力检测结果。
图6显示了一些实施例中在特定pH条件下融合抗体对猴源FcRn蛋白的亲和力检测结果。
具体实施方式
除非另有说明,本文使用的所有技术和科学术语具有本领域普通技术人员所通常理解的含义。
术语“或”是指列举的可选择要素中的单个要素,除非上下文明确地另外指出。术语“和/或”是指所列举的可选择要素中的任意一个、任意两个、任意三个、任意更多个或其全部。
术语“约”通常是指在指定数值以上或以下10%的范围内变动,例如在指定数值以上或以下0.5%、1%、1.5%、2%、2.5%、3%、3.5%、4%、4.5%、5%、5.5%、6%、6.5%、7%、7.5%、8%、8.5%、9%、9.5%、或10%的范围内变动。
术语“包含”或“包括”指包括所述的要素、整数或步骤,但是不排除任意其他要素、整数或步骤。在文中,当使用术语“包含”或“包括”时,除非另有指明,否则也涵盖由所述及的要素、整数或步骤组成的情形。例如,当提及“包括”某个具体序列的抗体可变区时,也旨在涵盖由该具体序列组成的抗体可变区。
本文使用的术语“抗体”以它的最广泛意义使用,包括包含一个或更多个特异性结合抗原的抗原结合结构域的免疫球蛋白或其他类型分子,为对特定抗原表现出结合特异性的蛋白质或多肽。抗体的具体实例可包括完整抗体(例如经典四链抗体分子)、单链抗体、单域抗体、多特异性抗体等。经典抗体分子通常为由2个相同重链和2个相同轻链通过二硫键相互连接组成的四聚体。根据氨基酸序列的保守性差异,将重链和轻链分为位于氨基端的可变区(V)和位于羧基端的恒定区(C)。可变区用于识别和结合抗原,恒定区(如Fc片段)用于启动下游效应,比如抗体依赖性细胞介导的细胞毒作用(ADCC)。在重链和轻链的可变区内,分别有三个局部区域的氨基酸组成和排列顺序具有更高的变异程度,为抗体与抗原结合的关键位置,因而也称为互补决定区(CDR)。CDR的氨基酸序列可以使用本领域公认的编号方案,例如Kabat、Chothia、IMGT、AbM或Contact容易地确定。重链的三个互补决定区分别称为HCDR1、HCDR2和HCDR3,轻链的三个互补决定区分别称为LCDR1、LCDR2和LCDR3。每个重链可变区(VH)和轻链可变区(VL)可由三个CDR和四个FR区构成,它们从氨基端至羧基端可按以下顺序排列:FR1、CDR1、FR2、CDR2、FR3、CDR3和FR4。在一个具体实施方案中,已经根据Kabat编号方案确定了本文所述的抗体的CDR序列。
抗体分子的“抗原结合片段”指包括了来源抗体的部分序列(尤其是CDR序列)并且同时具有来源抗体结合特异性的多肽。该抗原结合片段通常至少包括来源抗体的重链可变区,并具备抗原结合能力。抗原结合片段的形式有多种,例如Fab、Fab’、F(ab’)
“单域抗体(single domain antibody,sdAb)”,或者也称为“V
“Fc片段”指Y”形抗体分子的柄部区域,即可结晶片段包括重链的第二和第三恒定结构域(CH2和CH3结构域)。可通过蛋白水解酶(如木瓜蛋白酶)水解抗体分子得到抗体Fc区。“Fc片段”的效应功能可包括与Fc受体的结合、Clq结合和补体依赖性细胞毒性(CDC)、抗体依赖性细胞介导的细胞毒性(ADCC)、介导吞噬作用等。
对于抗体或其抗原结合片段来说,“靶向”、“针对”或“特异性结合”指,相对于环境中同时存在的其他分子,一种分子(例如抗体或其抗原结合片段)对另一种分子(如抗原)具有更高的结合亲和力。一种分子可以靶向、针对或特异性结合一种以上的分子,例如双特异性抗体可以对两种不同抗原具有相对于其他分子而言更高的结合亲和力。可以通过一些参数测量来衡量抗体对抗原的结合亲和力,例如抗体与抗原结合的EC
“KD值”可以用于衡量抗体与其抗原之间的结合亲和力。KD值是抗体与其抗原之间的平衡解离常数,即k
“表面等离子共振技术(SPR)”指利用光在不同介质中产生消逝波后与等离子波产生共振,进而可以构建生物分子间相互作用的生物传感分析技术,用以检测生物传感芯片上配体与分析物之间的相互作用情况。采用SPR检测分子间相互作用时不需要对配体或分析物进行标记。在一个具体实例中,SPR生物传感器的光源为偏振光,传感芯片表面镀有一层金膜,在实验时,先将一种生物分子(如靶分子)固定在金膜表面,然后将与之相互作用的分子溶于溶液(或混合液)后流过芯片表面。在金膜芯片上的蛋白和流路中的分子结合和解离的过程中,共振角(即SPR角)就会随之发生变化,检测器检测到这种变化,根据此变化曲线作图分析,可得出分子间的结合常数Ka、解离常数Kd或亲和力常数KD。
“半衰期”指生物活性物质或药物在体内被消除一半时所需的时间。通常可通过测定该生物活性物质或药物在血浆中浓度下降一半所需的时间作为半衰期。通过测定半衰期,能够了解生物活性物质或药物在体内的代谢速度,对指导临床用药具有非常重要的意义。例如,如果一种药物的半衰期较长,在用药时,给药的间隔时间可以较长,可以每日一次或者两日、多日一次;如果半衰期较短,说明药物在短时间内可以降至正常浓度的一半,这时用药的间隔时间需要缩短,例如6小时或8小时一次,以保证药物浓度保持在有效范围之内。
“FcRn蛋白”指位于细胞膜表面的受体分子,其蛋白结构和MHC-I分子类似。FcRn在体内许多组织的上皮细胞、内皮细胞及多种免疫细胞(如单核巨噬细胞)中广泛表达。FcRn可以和IgG的Fc部分结合,阻止IgG分子被溶酶体裂解,可以起到增长IgG体内半衰期的作用。血管内皮细胞是FcRn保护IgG免于被分解代谢的主要部位。在这些地方,FcRn与血液的接触面积很大。当血管内皮细胞大量内吞血液中的蛋白和其他物质时,FcRn可以通过与IgG的Fc部分结合而有效地拦截IgG并将其返还到血液循环中,从而延长IgG体内半衰期。FcRn与IgG的结合是pH依赖性的,例如它们只在酸性条件(如pH 6.0-6.5)下结合,在中性(如pH7.0-7.5)条件下解离。因此,在酸化的溶酶体中中,IgG能与FcRn有效结合,并跟随FcRn被转运至细胞膜表面。由于细胞外血液的pH值为微碱性(pH 7.3-7.5),IgG与FcRn解离,被“回收”至血液循环中。
“溶酶体(lysosome)”指广泛存在于真核细胞内的一种细胞器,为单层包被的囊泡,在其中能降解蛋白质、脂肪、氨基酸、衰老细胞器及失活细胞等多种底物,并为新的生物大分子提供原料,可以看作是细胞内的“回收站”。溶酶体含有众多酸性水解酶,蛋白酶、核酸酶、糖苷酶、酯酶、磷酸酶、硫酸酯酶、磷脂酶等。溶酶体通过溶酶体膜上的质子泵,依赖ATP水解释放能量将H+泵入其中以维持其内腔的酸性pH,为这些酸性水解酶提供适宜的pH环境。但近年来的研究发现,除了降解功能外,溶酶体还在信号转导、细胞死亡、质膜修复、抗原加工和呈递等过程中发挥重要作用。
“蛋白构建体”指包括两个或更多个功能部分的蛋白复合体,这些功能部分通常在自然界中并非都一起存在,而是人为地通过共价键或非共价相互作用让它们存在于同一复合体中。使不同功能部分存在于同一复合体中的方法例如包括以融合蛋白的形式表达或通过化学偶联分子使它们结合在一起。这里所用的“融合蛋白”指人为生成(例如通过基因工程技术)的由至少两个不同肽段构成的蛋白分子。这些肽段在自然界中不存在同一个蛋白分子中。融合蛋白的实例包括抗体-细胞因子融合蛋白、抗体-细胞毒素融合蛋白于免疫检测的酶标抗体、嵌合抗原受体(CAR)、连接有纯化标签的天然蛋白分子等。非共价连接的实例可包括通过生物素-亲和素系统(Biotin-Avidin System)。通过偶联分子共价连接的实例可包括各种化学接头。例如6-顺丁烯二酰亚胺基己酰基(MC)、顺丁烯二酰亚胺基丙酰基(MP)、对氨基苯甲氧基羰基(PAB)、N-丁二酰亚胺基4-(2-吡啶基硫基)戊酸酯(SPP)、N-丁二酰亚胺基4-(N-顺丁烯二酰亚胺基甲基)环己烷-1甲酸酯(SMCC)和N-丁二酰亚胺基(4-碘-乙酰基)胺基苯甲酸酯(SIAB)等;双官能蛋白质偶合剂,例如N-丁二酰亚胺基-3-(2-吡啶基二硫醇)丙酸酯(SPDP)、亚胺基硫杂环戊烷(IT)、酰亚胺酯的双官能衍生物(诸如己二酰亚胺酸二甲酯HCl)、活性酯(诸如二丁二酰亚胺基基质)、醛(诸如戊二醛)、双叠氮基化合物(诸如双(对叠氮基苯甲酰基)己二胺)、双重氮衍生物(诸如双-(对重氮苯甲酰基)-乙二胺)、二异氰酸酯(诸如甲苯2,6-二异氰酸酯)和双活性氟化合物(诸如1,5-二氟-2,4-二硝基苯)等。
“功能部分”在本文中指具有任何功能的蛋白、蛋白结构域或多肽片段。蛋白构建体或融合蛋白中的一个功能部分可以为蛋白类药物,具有特定的生物学活性,例如酶学活性、调节基因表达、促进或抑制其他蛋白的活性,对特定配体(如抗原)具有结合特异性等,例如蛋白类激素、细胞因子、蛋白酶、核酸酶等。
术语“多肽”和“蛋白质”可互换使用且指氨基酸残基的聚合物。氨基酸残基的此类聚合物可含有天然或非天然氨基酸残基且包括但不限于氨基酸残基构成的肽、寡肽、二聚体、三聚体和多聚体。全长蛋白与其片段皆涵盖于该定义中。该术语亦包括多肽的表达后修饰,例如糖基化、唾液酸化、乙酰化、磷酸化和类似修饰。此外,出于本发明的目的,“多肽”指一种蛋白质,其包括对天然序列的修饰,诸如缺失、添加和取代(实际上通常为保守的),只要该蛋白质保持所需活性即可。这些修饰可为有目的的,如经由定点突变诱发;或可为偶然的,诸如经由产生蛋白质的宿主的突变或因PCR扩增所致的误差。
提及抗体或其抗原结合片段时,本文所用的术语“变体”指,在母体抗体分子基础上引入一个或多个氨基酸插入、缺失或替换后所获得的蛋白,其仍然保留了母体抗体分子的至少部分功能(尤其是所关注的功能,例如与对应抗原的结合能力)。例如,抗体分子的性变体可保留其母体抗体分子对抗原结合能力的至少20%、30%、40%、50%、60%、70%、80%、90%,或甚至具有比母体抗体分子更高的结合能力。在一些实施方案中,抗体分子的变体可保留其母体抗体分子对抗原结合亲和力的至少80%、85%、90%、95%或甚至100%或以上。对于抗体分子或其抗原结合片段来说,其变体通常包括在可变区骨架序列和/或恒定区存在氨基酸改变,但并不排除可对CDR区序列进行一个或少数几个氨基酸改动。因此,本领域技术人员还可以理解的是,在本文提供的具体抗体序列基础上,可以通过对少数氨基酸进行替换、删除、添加并验证或筛选所得产物与相应抗原(FcRn蛋白)的结合能力或生物学活性,从而获得本发明提供的抗FcRn抗体分子的相应变体,这些变体也应包括在本发明的范围内。
本文中,术语“核酸分子”、“核酸”和“多核苷酸”可互换使用,指核苷酸聚合物。此类核苷酸聚合物可含有天然和/或非天然核苷酸且包括(但不限于)DNA、RNA和PNA。“核酸序列”指包含于核酸分子或多核苷酸中的核苷酸线性序列。
术语“载体”指可经工程改造以含有目的多核苷酸(例如目的多肽的编码序列)的核酸分子或可在宿主细胞中复制的核酸分子(例如,核酸、质粒或病毒等)。载体可包括以下组件中的一个或更多个:复制起点、一或更多个调控目的多核苷酸的表达的调控序列(诸如启动子和/或增强子)和/或一个或更多个可选择标记物基因(诸如抗生素抗性基因和可用于比色分析中的基因,例如β-半乳糖)。术语“表达载体”指用于在宿主细胞中表达目的多肽或蛋白蛋白的载体。
“宿主细胞”指可为或已为载体或经分离多核苷酸的接受体的细胞。宿主细胞可为原核细胞或真核细胞。示例性真核细胞包括哺乳动物细胞,诸如灵长类动物或非灵长类动物细胞;真菌细胞,诸如酵母;植物细胞;以及昆虫细胞。非限制性示例性哺乳动物细胞包括(但不限于)CHO细胞、HEK-293细胞、BHK细胞或PER-C6细胞,以及其衍生细胞,诸如293-6E、CHO-DG44、CHO-K1、CHO-S和CHO-DS细胞。在一些实施方案中,本文提供的单域抗体可由哺乳动物细胞分泌产生。宿主细胞包括单个宿主细胞的后代,且后代可能由于自然、偶然或故意突变而不一定与原始亲代细胞完全一致(在形态或基因组DNA互补方面)。宿主细胞可以分离的细胞或细胞系,也包括在活体内经本文提供的核酸分子或表达载体转染的细胞。
提及氨基酸或核苷酸序列时,术语“序列一致性(Sequence identity)”(也称为“序列同一性”)指两氨基酸或核苷酸序列(例如查询序列和参照序列)之间一致性程度的量,一般以百分比表示。通常,在计算两氨基酸或核苷酸序列之间的一致性百分比之前,先进行序列比对(alignment)并引入缺口(gap)(如果有的话)。如果在某个比对位置,两序列中的氨基酸残基或碱基相同,则认为两序列在该位置一致或匹配;两序列中的氨基酸残基或碱基不同,则认为在该位置不一致或错配。在一些算法中,用匹配位置数除以比对窗口中的位置总数以获得序列一致性。在另一些算法中,还将缺口数量和/或缺口长度考虑在内。出于本发明的目的,可以采用公开的比对软件BLAST(可在网页ncbi.nlm.nih.gov找到),通过使用缺省设置来获得最佳序列比对并计算出两氨基酸或核苷酸序列之间的序列一致性。在一些实施方案中,本文所述“至少90%序列一致性”包括但不限于:至少95%、至少98%、至少99%或甚至100%序列一致性的情形。
本发明在一方面提供了一种抗人FcRn的单域抗体AHP12161。
所述单域抗体包含CDR1、CDR2和CDR3三个CDR区,序列分别为如SEQ ID NO:3、SEQID NO:5和SEQ ID NO:7所示的氨基酸序列。
所述抗体优选与人源FcRn在pH 6.0条件下结合,在pH7.4条件下不结合。
所述单域抗体还包括FR1、FR2和FR3三个框架区,序列分别包含如SEQ ID NO:2、SEQ ID NO:4和SEQ ID NO:6所示序列或与其具有至少90%相似性的氨基酸序列。
在一些实施例中,所述单域抗体的重链可变区包含SEQ ID NO:1所示的序列或与其具有至少95%相似性的序列。
所述单域抗体与第二抗体融合,可延长第二抗体的半衰期。
本发明另一方面提供了一种融合抗体,包含所述抗人FcRn单域抗体AHP12161和第二抗体部分。
所述第二抗体部分选自sdAb、ScFv和Fab中至少一种。
所述第二抗体部分融合在所述单域抗体AHP12161的N端。
所述第二抗体部分融合与所述单域抗体AHP12161之间以linker连接。
在一些实施例中,所述Linker为(G4S)3。
在一些具体的实施例中,所述第二抗体部分可以特异性结合肿瘤相关抗原。
在一些具体的实施例中,所述第二抗体部分特异性结合免疫检查点,如PDL1、PD1、CTLA4等等。
本发明的另一目的在于提供上述人源FcRn单克隆抗体的编码基因。
本发明的又一目的在于提供上述人源FcRn单克隆抗体的制备方法。
本发明的另一目的在于提供含有上述编码基因的重组载体、表达盒、转基因细胞系或重组菌。
本发明还提供了上述重组表达载体、表达盒、转基因细胞系或重组菌在制备人源FcRn单克隆抗体中的应用。
本发明所述的单域抗体可与人源FcRn pH依赖性结合,在pH 5.5-6.5下结合,在pH7.0-8.0条件下不结合。借助SPR检测,确定了所筛选到的分子与FcRn pH依赖性结合的能力与Fc相当;由于该分子为VHH分子,分子量仅为Fc,HSA的1/4,对片段型抗体的渗透性影响不大,且无ADCC和CDC效应,降低免疫反应强度。
本发明所述的单域抗体拥有以下有益效果:
1)与人FcRn结合亲和力高,与Fc相当;
2)可与第二抗体部分融合,不影响第二抗体部分的功能;
3)与FcRn的结合具有pH依赖性,pH 6时结合,pH 7时不结合,可延长融合抗体半衰期以及降低药物的免疫原性,提升了肿瘤抑制的效果。
本发明涉及一种与人源FcRn pH依赖性结合的抗体,下面将结合实施例对本发明的实施方案进行详细描述。除非另有说明,下文描述的实施例的方法和材料均为可以通过市场购买获得的常规产品。本发明所属领域技术员将会理解,下文描述的方法和材料,仅是示例性的,而不应视为限定本发明的范围。
实施例1利用羊驼天然文库淘选特异靶向人源FcRn且具有特定pH依赖的先导抗体分子
离子依赖型淘选:将100ul带有链霉亲和素的磁珠(赛默飞,货号:60210)和蓬勃生物自主研发的羊驼天然噬菌体文库分别用终浓度3%的脱脂牛奶(pH 6.0醋酸钠配制)37℃封闭1小时,将100nM生物素化的人源FcRn(百普赛斯,货号:FCM-H82W7)与磁珠室温结合30分钟后,弃去与磁珠不结合的抗原,将封闭好的噬菌体展示文库投入到磁珠中,室温结合1小时,用含0.05%吐温20的醋酸钠溶液洗去与抗原不结合的噬菌体,用pH7.4的Tris缓冲盐水溶液洗脱能与抗原结合的噬菌体,将得到的噬菌体洗脱液加入到准备好的TG1宿主菌中,37℃侵染45分钟。取出部分菌液进行梯度稀释后,涂到2YT+羧苄青霉素固体培养基的平皿中,37℃过夜培养,用于后续轮次的加压淘选或单克隆筛选;
进行了三轮pH依赖型淘选,分别通过调整抗原投入量,洗涤次数,更换使用耗材等方法达到充分洗去非特异结合克隆及获得高亲和pH依赖型阳性克隆,从第三轮的洗脱液侵染涂布的平板中挑取单克隆进行后续特定pH条件下的结合检测。
实施例2靶点人源FcRn的pH依赖型阳性单域抗体克隆的筛选
将淘选得到的噬菌体洗脱液侵染准备好的TG1宿主菌液,37℃侵染45分钟,用2YT培养基梯度稀释,用涂布棒均匀涂在2YT平板(带有羧卞青霉素)上。次日,挑取平板上的单克隆至96孔板(加有羧卞青霉素及葡萄糖的2YT液体培养基)中培养5~6小时。转接部分到新的96孔板(加有羧卞青霉素的2YT液体培养基)中,37℃220rpm培养2小时至生长对数期,加入辅助噬菌体37℃侵染45分钟,然后置于30℃过夜培养进行。
不同pH条件下的单克隆ELISA结合检测:用0.1M碳酸盐缓冲溶液稀释人源FcRn蛋白至1ug/ml,每孔100ul加到酶标板中,4℃过夜包被。用含0.05%吐温20的醋酸钠或磷酸盐溶液洗板1次后,每孔加入300ul的含3%脱脂牛奶的醋酸钠或磷酸盐溶液,37℃封闭1小时。用含0.05%吐温20的醋酸钠或磷酸盐溶液洗板2次后,每孔加入50ul的含0.05%吐温20的醋酸钠或磷酸盐溶液和50ul过夜展示的噬菌体上清,室温下结合2小时。用含0.05%吐温20的醋酸钠或磷酸盐溶液洗板3次后,每孔加入100ul用含0.05%吐温20的醋酸钠或磷酸盐溶液1:25000稀释的抗M13二抗,室温下避光结合45分钟。二抗结合后,用含0.05%吐温20的醋酸钠或磷酸盐溶液洗板6次,加入100ul显色液避光显色10分钟后加入50ul 1mol/L盐酸终止显色。用酶标仪读取OD450的值。用pH6.0的醋酸钠相关溶液进行的检测代表pH6.0条件下单克隆的结合情况,相反用pH7.4的磷酸盐相关溶液进行的检测代表pH7.4条件下单克隆的结合情况。检测结果见图1,结果表明共获得7株具有特定pH依赖(pH6.0检测条件下结合(OD450>0.8),pH7.4检测条件下不结合(OD450<0.5)或pH 6.0的结合值为pH 7.4的结合值的2.5倍以上)的阳性克隆(它们的氨基酸序列列在下文中)。
实施例3阳性克隆的可变区测序及单克隆抗体重组生产
根据ELISA结合检测结果选择阳性克隆,吸取阳性克隆对应原始菌落进行菌液培养,表达质粒抽提,PCR及单克隆Sanger测序,分析测序结果获得阳性单克隆的对应的DNA序列及氨基酸序列。根据结合检测结果及测序分析结果选择克隆AHP12161进行基于特定构型的纯化抗体表达及后续检测。AHP12161单域抗体的序列如下。
AHP12161单域抗体重链可变区氨基酸序列SEQ ID NO:1
AHP12161 FR1区氨基酸序列SEQ ID NO:2
AHP12161 CDR1区氨基酸序列SEQ ID NO:3
AHP12161 FR2区氨基酸序列SEQ ID NO:4
AHP12161 CDR2区氨基酸序列SEQ ID NO:5
AHP12161 FR3区氨基酸序列SEQ ID NO:6
AHP12161 CDR3区氨基酸序列SEQ ID NO:7
AHP12161 FR4区氨基酸序列SEQ ID NO:8
AHP12161单域抗体重链可变区DNA序列SEQ ID NO:9
实施例4融合抗体的重组生产
为展示所选阳性克隆具有靶向人源FcRn的pH依赖特性,且其融合对抗体特异性靶向无影响,设计四种融合抗体用于后续检测,抗体融合方法如图2所示,不同抗体部分用(G4S)3linker融合。四种融合抗体为:
基础抗体:抗人源PDL1的上市药物恩维达单抗单域抗体重链可变区(简写为抗-PDL1 VHH)融合10个组氨酸蛋白标签,抗体命名为Ab1:抗-PDL1 VHH-His;
抗-PDL1 VHH结构融合人源IgG1 Fc片段,抗体命名为Ab2:抗-PDL1 VHH-Fc(HuIgG1);
抗-PDL1 VHH结构融合抗人源FcRn且具有特定pH依赖阳性克隆AHP12161可变区及10个组氨酸蛋白标签,抗体命名为Ab3:抗-PDL1 VHH-AHP12161-His;
两个串联的抗-PDL1 VHH结构融合抗人源FcRn且具有特定pH依赖阳性克隆AHP12161可变区及10个组氨酸蛋白标签,模拟常规IgG1的双抗原结合表位,抗体命名为Ab4:2抗-PDL1 VHH-AHP12161-His。
实施例5融合抗体针对靶抗原人源PDL1蛋白的亲和力检测
通过SPR亲和力测定来判断AHP12161的融合是否会影响抗体片段与其靶抗原的结合特异性或亲和力表征,用预包被链霉亲和素的芯片对带有生物素化标记的人源PD-L1抗原蛋白进行捕获,融合抗体分别作为分析物进行检测。所有数据均使用Biacore 8k评估软件3.0版获得解离(kd)和缔合(ka)速率常数的数据。平衡解离常数(KD)由kd与ka的比率计算。每个循环中流动池1和缓冲液的空白注射用作响应单位减法的双重参考。结合动力学数据见表1,结果显示两组(单价抗体:Ab1和Ab3,双价抗体:Ab2和Ab4)亲和力结果基本相当,表明AHP12161的融合不会对抗体本身的特异性及亲和力产生影响,结果如图3所示。
表1.PDL1抗体的结合动力学
实施例6融合抗体针对人源FcRn蛋白的在特定pH条件下亲和力检测
为了进一步比较AHP12161融合抗体与Fc融合抗体在不同pH条件下与人源FcRn结合的亲和力高低,用预包被链霉亲和素的芯片对带有生物素化标记的人源FcRn抗原蛋白进行捕获,融合抗体分别作为分析物进行检测。融合抗体与人源FcRn结合的具体参数及检测方法如表2所示。蛋白所有数据均使用Biacore 8k评估软件获得解离(kd)和缔合(ka)速率常数的数据。平衡解离常数(KD)由kd与ka的比率计算。整个实验分别在pH6.0或pH7.4的检测试剂中进行。结果如图4-5、表3-4,表明AHP12161融合抗体与FcRn pH依赖结合的亲和力水平与Fc融合抗体一致,表现为pH6.0条件下结合且亲和力相当,pH7.4条件下不结合。
表2.结合参数及检测方法
表3.融合抗体与人源FcRn在pH6.0的结合动力学
表4.融合抗体与人源FcRn在pH7.4的结合动力学
实施例7融合抗体针对猴源FcRn蛋白的在特定pH条件下亲和力检测
为了后续动物实验的进行,进一步比较AHP12161融合抗体与Fc融合抗体在pH6.0条件下与猴源FcRn结合的亲和力高低,用CM5传感芯片猴源FcRn抗原蛋白(百普赛斯,货号:FCM-C5284)进行捕获,融合抗体分别作为分析物进行检测。融合抗体与猴源FcRn蛋白结合参数及检测方法如表5所示。所有数据均使用Biacore 8k评估软件获得解离(kd)和缔合(ka)速率常数的数据。平衡解离常数(KD)由kd与ka的比率计算得到,或由软件通过稳态拟合得到。整个实验分别在pH6.0检测试剂中进行。结果如图6、表6所示,表明AHP12161融合抗体与FcRn pH6.0结合的亲和力水平与Fc融合抗体一致,pH6.0条件下结合且亲和力相当。
表5.结合参数及检测方法
表6.抗体与猴源FcRn在pH6.0的结合动力学
本文提及的抗体分子的氨基酸序列如下。
AHP12161单域抗体重链可变区氨基酸序列SEQ ID NO:1:
QVQLVESGGGLVQPGGSLRLSCTGSGSGFQYHAIGWFRQAPGKERKFVAGLSWSGSRIWYGDSV KGRFTISRDNAKNVVYLQMNDLQPEDTGVYYCTADRMLGYPQGHEDDYWGQGTEVTVSS
AHP12161 FR1区氨基酸序列SEQ ID NO:2
QVQLVESGGGLVQPGGSLRLSCTGS
AHP12161 CDR1区氨基酸序列SEQ ID NO:3
GSGFQYHA
AHP12161 FR2区氨基酸序列SEQ ID NO:4
IGWFRQAPGKERKFVAG
AHP12161 CDR2区氨基酸序列SEQ ID NO:5
LSWSGSRI
AHP12161 FR3区氨基酸序列SEQ ID NO:6
WYGDSVKGRFTISRDNAKNVVYLQMNDLQPEDTGVYYC
AHP12161 CDR3区氨基酸序列SEQ ID NO:7
TADRMLGYPQGHEDDY
AHP12161 FR4区氨基酸序列SEQ ID NO:8
WGQGTEVTVSS
AHP12176单域抗体重链可变区氨基酸序列SEQ ID NO:9:
QVQLVESGGGLVQAGGSLRLSCVASGRGFTDFGVGWFRQPPGKEREFVATISWSGHSTYYRDSV KGRFTISRDNAKNTVYLQMNSLKPEDTALYQCGVIGLHLWGQGTQVTVSS
AHP12176 FR1区氨基酸序列SEQ ID NO:10
QVQLVESGGGLVQAGGSLRLSCVAS
AHP12176 CDR1区氨基酸序列SEQ ID NO:11
GRGFTDFG
AHP12176 FR2区氨基酸序列SEQ ID NO:12
VGWFRQPPGKEREFVAT
AHP12176 CDR2区氨基酸序列SEQ ID NO:13
ISWSGHST
AHP12176 FR3区氨基酸序列SEQ ID NO:14
YYRDSVKGRFTISRDNAKNTVYLQMNSLKPEDTALYQC
AHP12176 CDR3区氨基酸序列SEQ ID NO:15
GVIGLHL
AHP12176 FR4区氨基酸序列SEQ ID NO:16
WGQGTQVTVSS
AHP12171单域抗体重链可变区氨基酸序列SEQ ID NO:17:
AVQLVDSGGGLVQAGGSLRLSCEASGFTFDDYEIGWFRQAPGKEREGVSWIIPKYGDTYYADPV KGRFTISRGNAKSTVSLQMNSLKPEDTAVYYCAADVRTTEWGAPLRYWGQGTQVTVSS
AHP12171 FR1区氨基酸序列SEQ ID NO:18
AVQLVDSGGGLVQAGGSLRLSCEAS
AHP12171 CDR1区氨基酸序列SEQ ID NO:19
GFTFDDYE
AHP12171 FR2区氨基酸序列SEQ ID NO:20
IGWFRQAPGKEREGVSW
AHP12171 CDR2区氨基酸序列SEQ ID NO:21
IIPKYGDT
AHP12171 FR3区氨基酸序列SEQ ID NO:22
YYADPVKGRFTISRGNAKSTVSLQMNSLKPEDTAVYYC
AHP12171 CDR3区氨基酸序列SEQ ID NO:23
AADVRTTEWGAPLRY
AHP12171 FR4区氨基酸序列SEQ ID NO:24
WGQGTQVTVSS
AHP12179单域抗体重链可变区氨基酸序列SEQ ID NO:25:
QVQLVESGGGLVQAGGSLRLSCAASGRTFSSYAMGWFRQAPGKEREFVAAINWNGDRSYYADS VKGRFTVSRDSATNDLLLHMDNLKPEDTARYYCTNEGYYTDFDFWGQGTQVTVSP
AHP12179 FR1区氨基酸序列SEQ ID NO:26
QVQLVESGGGLVQAGGSLRLSCAAS
AHP12179 CDR1区氨基酸序列SEQ ID NO:27
GRTFSSYA
AHP12179 FR2区氨基酸序列SEQ ID NO:28
MGWFRQAPGKEREFVAA
AHP12179 CDR2区氨基酸序列SEQ ID NO:29
INWNGDRS
AHP12179 FR3区氨基酸序列SEQ ID NO:30
YYADSVKGRFTVSRDSATNDLLLHMDNLKPEDTARYYC
AHP12179 CDR3区氨基酸序列SEQ ID NO:31
TNEGYYTDFDF
AHP12179 FR4区氨基酸序列SEQ ID NO:32
WGQGTQVTVSS
AHP12174单域抗体重链可变区氨基酸序列SEQ ID NO:33:
AVQLVESGGGLAQRGGSLTLSCVASGSISDLAMAWYRQAPGKERDLIAYISTGSATAYADSVKDRF AISRDNDKKTMYLQMNNLKTEDTAVYYCNADLDYGDSDYWGQGTQVTVSS
AHP12174 FR1区氨基酸序列SEQ ID NO:34
AVQLVESGGGLAQRGGSLTLSCVA
AHP12174 CDR1区氨基酸序列SEQ ID NO:35
SGSISDLA
AHP12174 FR2区氨基酸序列SEQ ID NO:36
MAWYRQAPGKERDLIAY
AHP12174 CDR2区氨基酸序列SEQ ID NO:37
ISTGSAT
AHP12174 FR3区氨基酸序列SEQ ID NO:38
AYADSVKDRFAISRDNDKKTMYLQMNNLKTEDTAVYYC
AHP12174 CDR3区氨基酸序列SEQ ID NO:39
NADLDYGDSDY
AHP12174 FR4区氨基酸序列SEQ ID NO:40
WGQGTQVTVSS
AHP12140单域抗体重链可变区氨基酸序列SEQ ID NO:41:
AVQLVDSGGGLVQAGGSLRLSCAASGRSFSNYAMGWFRQAPGKEREFLAVIKWNGGDPYYADS VKGRFTISRDNAKSTVYLQMNSLKPEDTAMYYCLVQDGNNYWGRGTQVTVSS
AHP12140 FR1区氨基酸序列SEQ ID NO:42
AVQLVDSGGGLVQAGGSLRLSCAAS
AHP12140 CDR1区氨基酸序列SEQ ID NO:43
GRSFSNYA
AHP12140 FR2区氨基酸序列SEQ ID NO:44
MGWFRQAPGKEREFLAV
AHP12140 CDR2区氨基酸序列SEQ ID NO:45
IKWNGGDP
AHP12140 FR3区氨基酸序列SEQ ID NO:46
YYADSVKGRFTISRDNAKSTVYLQMNSLKPEDTAMYYC
AHP12140 CDR3区氨基酸序列SEQ ID NO:47
LVQDGNNY
AHP12140 FR4区氨基酸序列SEQ ID NO:48
WGRGTQVTVSS
AHP12131单域抗体重链可变区氨基酸序列SEQ ID NO:49:
QVQLVESGGGLVQTGDSLRLSCLGSGRNFSRDAMGWFRQAPGKEREFVAAIIWSGLNTYYSDSV RGRFTVSRDNAKNTVYLQMNDLNLEDTAAYYCNAETTWGDYWGQGTQVTVSS
AHP12131 FR1区氨基酸序列SEQ ID NO:50
QVQLVESGGGLVQTGDSLRLSCLGS
AHP12131 CDR1区氨基酸序列SEQ ID NO:51
GRNFSRDA
AHP12131 FR2区氨基酸序列SEQ ID NO:52
MGWFRQAPGKEREFVAA
AHP12131 CDR2区氨基酸序列SEQ ID NO:53
IIWSGLNT
AHP12131 FR3区氨基酸序列SEQ ID NO:54
YYSDSVRGRFTVSRDNAKNTVYLQMNDLNLEDTAAYYC
AHP12131 CDR3区氨基酸序列SEQ ID NO:55
NAETTWGDY
AHP12131 FR4区氨基酸序列SEQ ID NO:56
WGQGTQVTVSS
抗PDL1单域抗体(Envafolimab)重链可变区氨基酸序列SEQ ID NO:57:
QVQLVESGGGLVQPGGSLRLSCAASGKMSSRRCMAWFRQAPGKERERVAKLLTTSGSTYLADSV KGRFTISRDNSKNTVYLQMNSLRAEDTAVYYCAADSFEDPTCTLVTSSGAFQYWGQGTLVTVSS
- 抗IGF1R单域抗体及其融合蛋白和人源化单域抗体的制备及应用
- 抗CEACAM6单域抗体、人源化单域抗体及其融合蛋白和应用