一种融合机器学习的埃达克质岩构造背景判别图解方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及地学大数据技术领域,尤其涉及一种融合机器学习的埃达克质岩构造背景判别图解方法。
背景技术
埃达克质岩是一类富集轻稀土元素(LREE),强烈亏损重稀土元素(如Yb≤1.9×10
埃达克质岩为岩浆起源、熔体-地幔作用、板块构造启动、地壳生长和恢复构造演化过程提供关键证据。尽管不同构造背景下形成的埃达克质岩具有不同的地球化学特征,但是埃达克质岩的源区、热源、产生机制、迁移和演化过程复杂,所以利用地球化学特征去破译地质历史时期的古构造环境充满挑战和争议。主微量元素图解((Yb+Ta)vs.Rb;(Y+Nb)vs.Rb;Rh/30vs.Hf vs.Ta×3;Nb/Yb vs.Th/Yb;Hf/3vs.Th vs.Nb/16;Th vs.La/Yb;Mg
同时,随着地学数据的指数增长和人工智能的发展,机器学习为解决该问题提供了新方法。
具体可知,机器学习是多领域交叉学科,涉及的学科较多,如概率论、统计学、逼近论、凸分析和算法复杂度理论等。它是人工智能的核心,是让计算机更加智能化的根本方法,是一个源于数据训练过程的模型,最终给出一个最优的性能度量决策。地球大数据和人工智能技术的发展推动了新研究范式的产生,新世纪的地学发展日益呈现密集数据驱动和学科交叉的趋势。
机器学习可以分为无监督学习和有监督学习。在无监督式学习中,数据并没有被特别标识,学习模型是为了对数据内部的一些结构进行推断,主成分分析(PCA)和t分布-随机近邻嵌入(t-SNE)是两种常用的无监督学习方法。其中PCA通常以原始变量的某种线性组合来表示,其通过降维技术将多个原始变量重新组合成几个互不相关的少数主成分的一种统计分析方法,主成分可以反映原始变量的绝大部分信息。t-SNE是一种非线性无监督降维技术,通过对两个分布之间的距离散度进行优化,得到低维空间的样本分布,能够有效解决数据拥挤问题。
随机森林、高斯核支持向量机、人工神经网络和K近邻是当前机器学习领域普遍使用的四种经典监督学习分类算法。在有监督学习中,每组训练数据都有一个标识值或者结果值。监督式学习在建立预测模型时,建立一个学习过程,将预测结果与训练数据的实际结果相比较,不断对预测模型进行调整,直到模型的预测结果达到预期的准确度为止。
现有技术中,例如焦守涛,周永章,张旗等在《基于GEOROC数据库的全球辉长岩大数据的大地构造环境智能判别研究》中开展了对辉长岩构造背景智能判别的研究;ZHAO Y,ZHANG Y,GENG M等在《Involvement of Slab〥erived Fluid in the Generation ofCenozoic Basalts in Northeast China Inferred From Machine Learning》中分析了中国东北新生代玄武岩,揭示其形成与太平洋板块的俯冲流体密切相关。DOUCET L S,TETLEYM G,LI Z等在《Geochemical fingerprinting of continental and oceanic basalts:Amachine learning approach》中分析地质历史时期的玄武岩,结合板块重建模型,完善全球古地理恢复工作。
可知现有将融合机器学习应用于岩石构造背景的主要研究如下:分析地质历史时期的玄武岩,结合板块重建模型,完善全球古地理恢复工作。
虽然机器学习在揭示岩石构造背景中具有良好的应用前景,但已有的研究较少且集中在玄武岩等基性岩构造背景与源区性质领域。且目前尚未开展融合机器学习揭示埃达克质岩构造背景的研究。
发明内容
为解决上述问题,本发明提供一种融合机器学习的埃达克质岩构造背景判别图解方法,将机器学习与地质大数据相结合,构建高精度构造背景判别模型和可视化图解,为构造-岩浆作用研究带来新的思路。
为实现上述目的,本发明提供了一种融合机器学习的埃达克质岩构造背景判别图解方法,包括以下步骤:
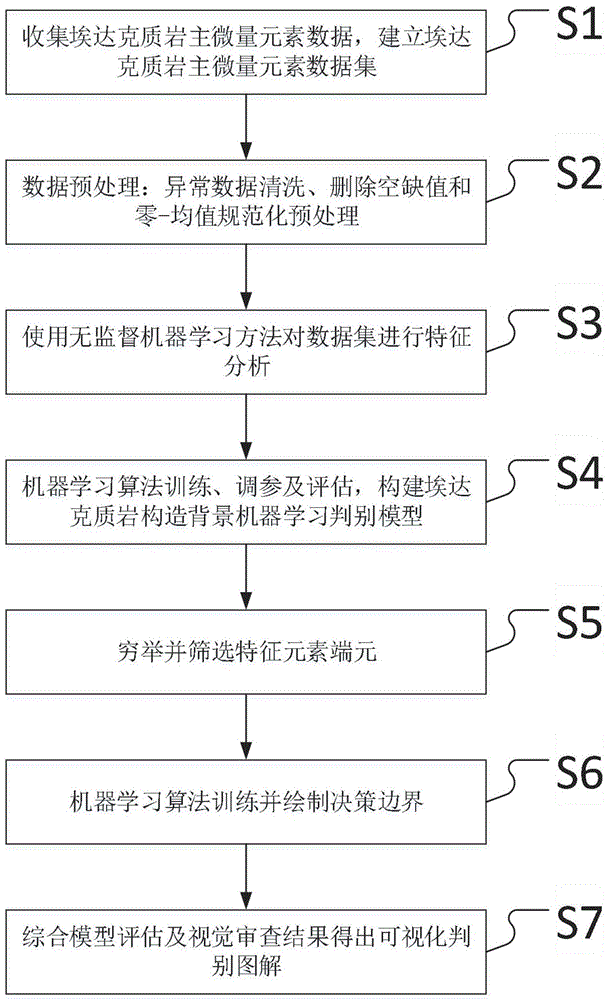
S1、收集埃达克质岩主微量元素数据,建立埃达克质岩主微量元素数据集;
S2、数据预处理:异常数据清洗、删除空缺值和零-均值规范化预处理;
S3、使用无监督机器学习方法对数据集进行特征分析;
S4、机器学习算法训练、调参及评估,构建埃达克质岩构造背景机器学习判别模型;
S5、穷举并筛选特征元素端元;
S6、机器学习算法训练并绘制决策边界;
S7、综合模型评估及视觉审查结果得出可视化判别图解。
优选的,步骤S1中所述的埃达克质岩主微量元素数据为由9个主量元素和22个微量元素组成的31个特征元素;
主量元素包括SiO
微量元素包括Sr、Rb、Zr、Y、Ba、La、Nb、Nd、Th、Yb、Ce、Eu、Sm、Ni、U、Dy、Hf、Er、Lu、Gd、Pr和Ho。
优选的,步骤S2所述的异常数据清洗具体为:首先删除负值和异常值,而后采用数据插补的方式对空白值进行插值处理,获得利于机器学习训练分布相对集中的数据集。
优选的,在步骤S3使用PCA与t-SNE相结合的方式进行特征分析和数据深层次关系分析,其具体包括以下步骤:
S31、利用PCA输出载荷图,展示原始数据和主成分之间的关系;
S32、利用t-SNE将高维数据映射到二维或三维空间,降低数据的维度。
优选的,步骤S4具体包括以下步骤:
S41、分别使用随机森林、高斯核支持向量机、人工神经网络或者K近邻方法进行机器学习算法训练;
S42、使用网格搜索结合K折交叉验证的方式进行调参:
通过网格搜索5折交叉验证,以设定分数作为评价模型的标准,针对每个特征元素的机器学习模型,寻找上述四种机器学习方法埃达克质岩构造背景类型分类最优的超参数;
S43、使用数据集中未用过的测试数据利用混淆矩阵或者学习曲线进行预测评估;
S44、选出准确率最高的机器学习方法:高斯核支持向量机作为埃达克质岩构造背景判别模型,埃达克质岩构造背景判别模型用于区分汇聚板块边缘、板内火山活动和太古代克拉通。
优选的,步骤S5具体包括以下步骤:
S51、将31特征元素与计算后的特征元素含量比值联合,进行对数转换,得到图解的端元;
S52、对二维图解的轮廓系数进行计算,并将其降序排列。
优选的,步骤S51具体包括以下步骤:
S511、使用穷举端元法计算31个特征元素中任意两个特征元素的比值,得到465个元素比值;
S512、将31个特征元素与计算后的465个元素比值联合,进行对数转换,得到496个构建图解的端元。
优选的,步骤S52具体包括以下步骤:
S521、利用正态化的数据,穷举投图得到122760幅二维图解;
S522、计算二维图解的轮廓系数并降序,为使得二维图解显示更多元素信息,取出横纵坐标无重复元素的端元组合,得到埃达克质岩判别效果最好的前9个二维图解分别为Ba vs.Sr/Nd图解,轮廓系数为0.505;
S523、结合PCA输出结果,使用Ba和Sr/Nd组合作为判别图解的端元元素。
优选的,步骤S6具体包括以下步骤:
S61、将数据集分为训练集和测试集;
S62、利用高斯核支持向量机对Ba和Sr/Nd特征元素的训练集进行训练,然后使用测试集对所拟合的模型进行评测,得到最佳图解端元的特征数据训练机器学习分类器;
S63、以最佳图解端元的特征数据训练机器学习分类器,再利用所得分类模型对二维平面中的所有点数据进行预测计算,推断出决策边界。
优选的,步骤S7具体包括以下步骤:
将随机森林、高斯核支持向量机、人工神经网络或者K近邻方法的预测准确率作为权重,按照随机森林、K近邻、高斯核支持向量机和人工神经网络的决策边界线的顺序,选择符合要求的线条进行边界拟合,得到最终的判别图解图。
本发明具有以下有益效果:
(1)本发明经过超参数调整优化,对比多种机器学习算法,得出准确率为98.5%的基于高斯核支持向量机的埃达克质岩构造背景判别模型,可用来区分汇聚板块边缘、板内火山活动和太古代克拉通(包括绿岩带)三种埃达克质岩构造背景类型。
(2)本发明在二维可视化的基础上运用机器学习方法,高维度的研究目标特征,进行穷举端元和PCA分析,得出Ba vs.Sr/Nd端元图解,此图解具有约82.3%的准确率,能有效区分构造背景类型,为可视化研究埃达克质岩主微量元素提供借鉴。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
图1为本发明的实施例一种融合机器学习的埃达克质岩构造背景判别图解方法的流程图;
图2为本发明的实施例的PCA载荷图;
图3为本发明的实施例的t-SNE图;
图4为本发明的实施例的四种机器学习分类算法在不同埃达克质岩构造背景判别的决策边界问题上的比较结果图;
图5为本发明的实施例的埃达克质岩构造背景判别图解图。
具体实施方式
为了使本发明实施例公开的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明实施例进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本发明实施例,并不用于限定本发明实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。
需要说明的是,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或服务器不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
如图1所示,一种融合机器学习的埃达克质岩构造背景判别图解方法,包括以下步骤:
S1、收集埃达克质岩主微量元素数据,建立埃达克质岩主微量元素数据集;
优选的,步骤S1中所述的埃达克质岩主微量元素数据为由9个主量元素和22个微量元素组成的31个特征元素(主量元素单位为%,微量元素单位为ppm);主量元素包括SiO
需要说明的是,采集数据时由于埃达克质岩中主量元素中的Fe2O3以及微量元素中的Co空缺率均大于50%,为避免过度填充空缺值而导致结果不确定性增大,故将其数据删除。
且数据预处理在数据挖掘过程中占有重要地位,在收集到的各种数据中,数据缺失是非常常见的现象。如果对于数据空缺值,采用KNN填充使用缺失点附近的数据点对缺失值进行估计并填充,经实验得到填充后准确率最高的机器学习算法为人工神经网络,准确率为91.0%。为进一步提高准确率,删除数据空缺值,对于无空缺值特征元素数据进行机器学习训练,得到了高斯核支持向量机98.5%的准确率,较KNN填充处理的准确率提升了7.5%,说明采集到的数据较填充的数据更具有真实性,因此本实施例使用31个特征元素无空缺值的数据进行下一步分析。
同时,对埃达克质岩主微量元素数据进行PCA和t-SNE分析,PCA载荷图(如图2所示)结果显示,主成分1(PC1)和主成分2(PC2)分别占数据集的47.1%和17%的方差,能解释数据集64.1%的信息,因此采用PC1和PC2的载荷图来进一步分析元素数据。从图2载荷图中可看出,第三象限中无元素分布,即这31种元素在PC1或者PC2上都具有一定的贡献率。同时,尝试删除Na2O、Al2O3、Ni、Ba、Lu、Zr、MnO、Nb、K2O、U和Hf等多种元素组合,但是删除元素后的机器学习判别模型准确率都较现在的98.5%有所降低,因此,本发明保留31个特征元素进行机器学习模型训练。t-SNE图(如图3所示)显示,埃达克质岩三种构造背景类型的数据分布交集极少且存在聚类现象,表明可以尝试通过机器学习方法对其进行分类,进一步表明此方法的可行性及有效性。
S2、数据预处理:异常数据清洗、删除空缺值和零-均值规范化预处理;
优选的,步骤S2所述的异常数据清洗具体为:首先删除负值和异常值,而后采用数据插补的方式对空白值进行插值处理,获得利于机器学习训练分布相对集中的数据集。
S3、使用无监督机器学习方法对数据集进行特征分析;
优选的,在步骤S3使用PCA与t-SNE相结合的方式进行特征分析和数据深层次关系分析,其具体包括以下步骤:
S31、利用PCA输出载荷图,展示原始数据和主成分之间的关系;
PCA是一种线性降维方法,PCA的载荷图(Loading Plot)是分析PCA结果的重要工具。载荷图中的向量可以用三种方式解释:长度、方向和向量之间的角度,展示了原始数据和主成分之间的关系,其中每个数据点代表一个变量,每个主成分的方向代表了该主成分与原始变量之间的线性关系。主成分分析结果为变量的线性组合,它可以影响元素特征选择决策。
S32、利用t-SNE将高维数据映射到二维或三维空间,降低数据的维度。
主成分分析结果为变量的线性组合,它可以影响后续的元素选择决策。而t-SNE是一种非线性无监督的降维算法,通过保留数据之间的相对距离,从而降低数据的维度,将高维数据映射到二维或三维空间中,以便于可视化。由于t-SNE本身是不同维度空间下条件概率的映射,其结果没有任何明确的表达式,但在可视化的应用中,t-SNE比PCA效果要好。因此拟使用PCA与t-SNE相结合的方式进行数据深层次关系分析。
S4、机器学习算法训练、调参及评估,构建埃达克质岩构造背景机器学习判别模型;
优选的,步骤S4具体包括以下步骤:
S41、分别使用随机森林、高斯核支持向量机、人工神经网络或者K近邻方法进行机器学习算法训练;
随机森林RF(Random Forest)是一种基于决策树的集成学习方法,通过对多棵决策树的投票来进行分类或回归预测,比传统决策树具有更强的泛化能力和更好的分类效果。支持向量机SVM(Support Vector Machine)是一种通过找到最大化间隔的超平面来进行分类或回归预测的模型。除了典型线性分类预测,可以使用不同的核函数来实现非线性分类,例如多项式核、高斯核等。人工神经网络ANN(Artificial Neural Network)是一种模拟人脑神经元之间的连接关系来进行学习和预测的模型。它由多个神经元层组成,每层神经元将输入数据进行加权和激活函数的处理,输出给下一层神经元。通过对神经元之间的权重和偏置不断调整来实现模型的优化,使其能够对数据进行更精确的分类或回归预测。K近邻KNN(k-Nearest Neighbor)是以实例为基础的学习方法,它通过计算未知样本与训练数据集中距离最近的K个样本的类别来预测此样本的类别。K值的选择和距离度量方法是影响模型性能的重要参数,需要根据具体问题进行调整。可知上述机器学习算法在不同的数据集和任务中具有不同的优势和适用性,故在实际应用中,需要针对特定问题和数据特点选择恰当的模型。
S42、使用网格搜索结合K折交叉验证的方式进行调参:
通过网格搜索5折交叉验证,以设定分数作为评价模型的标准,针对每个特征元素的机器学习模型,寻找上述四种机器学习方法埃达克质岩构造背景类型分类最优的超参数;
其中,网格搜索(Grid Search)是一种常用的机器学习超参数优化方法,它通过穷举所有可能的超参数组合进行训练和评估,从而找到最优的超参数组合。在网格搜索中,需要预先设定每个超参数的取值范围,并针对特定问题和数据特点选择恰当的超参数。此外,为了避免过拟合,提高模型性能。
K折交叉验证(K-fold Cross Validation)是一种常用的机器学习模型评估方法,它将数据集分成K个子集,将其中一个子集作为验证集,其余K-1个子集作为训练集,然后重复这个过程K次,每次将不同的子集作为验证集,最终将K次评估结果的平均值作为模型的评估结果。
如图4所示,本实施例中使用测试集对网格搜索后所拟合的模型进行评测的结果为:支持向量机准确率为0.985;K近邻准确率为0.983;人工神经网络准确率为0.951;随机森林准确率为0.924。根据混淆矩阵和准确率的综合评判,最优的分类器模型为“参数C=10,gamma=0.1”的高斯核支持向量机模型,准确率为0.985,97%的汇聚板块边缘、100%的板内火山活动和100%的太古代克拉通得到正确分类。
S43、使用数据集中未用过的测试数据利用混淆矩阵或者学习曲线进行预测评估;
其中混淆矩阵预测评估包括以下步骤:首先将预测结果分类:真正类、真负类、假正类和假负类,其中真正类表示模型正确预测为正例的样本数;真负类表示模型正确预测为负例的样本数;假正类表示模型错误地将负例预测为正例的样本数;假负类表示模型错误地将正例预测为负例的样本数;然后计算出模型的各种性能指标:准确率、召回率、精确率、F1-score;
学习曲线预测评估可将训练集大小与模型性能之间关系表示出来的图像。通常情况下,学习曲线包括两条曲线,分别表示训练集和验证集的性能随着数据量增加而变化的趋势。当模型过于简单或数据量不足时,学习曲线会呈现欠拟合的趋势,也就是训练集和验证集的误差都较高且相似。而当模型复杂度过高或数据量过多时,学习曲线会呈现过拟合的趋势,也就是训练集误差非常低,但验证集误差非常高。通过学习曲线,故可根据训练集和验证集的性能趋势,判断模型是否欠拟合或过拟合,并且可以根据需要增加或减少训练集样本数量。
S44、选出准确率最高的机器学习方法:高斯核支持向量机作为埃达克质岩构造背景判别模型,埃达克质岩构造背景判别模型用于区分汇聚板块边缘、板内火山活动和太古代克拉通。
S5、穷举并筛选特征元素端元;
优选的,步骤S5具体包括以下步骤:
S51、将31特征元素与计算后的特征元素含量比值联合,进行对数转换,得到图解的端元;
优选的,步骤S51具体包括以下步骤:
S511、使用穷举端元法计算31个特征元素中任意两个特征元素的比值,得到465个元素比值;
S512、将31个特征元素与计算后的465个元素比值联合,进行对数转换,得到496个构建图解的端元。
其中穷举端元图解(Pictorial Representation of Exhaustive Enumeration)通过列举所有可能的情况,从而得出结论。在穷举端元图解中,将所有可能的情况用图形化的方式表示出来,并对每种情况进行分类和统计,最终得出结论。
本实施例中,为确定组合特征的重要性,对9个图解中的端元元素进行主成分分析,即Sr/Nd、Ba、Ce、SiO
S52、为量化且准确地筛选有效的埃达克质岩构造背景二元分类图解,引入轮廓系数,对二维图解的轮廓系数进行计算,并将其降序排列。
其中轮廓系数是无监督学习中常用来衡量聚类算法效果的指标,取值范围在-1到1之间,越接近1表示聚类效果越好,即表示各类型构造背景的区分度越好。
优选的,步骤S52具体包括以下步骤:
S521、利用正态化的数据,穷举投图得到122760幅二维图解;
S522、计算二维图解的轮廓系数并降序,为使得二维图解显示更多元素信息,取出横纵坐标无重复元素的端元组合,得到埃达克质岩判别效果最好的前9个二维图解分别为Ba vs.Sr/Nd图解,轮廓系数为0.505;
S523、结合PCA输出结果,使用Ba和Sr/Nd组合作为判别图解的端元元素。
S6、机器学习算法训练并绘制决策边界;决策边界是机器学习模型中的一个关键概念,它是将数据分为不同类别的“分界线”。所呈现的决策边界即为图解中埃达克质岩不同构造背景的边界,即可得到埃达克质岩构造背景的二元判别图解。
优选的,步骤S6具体包括以下步骤:
S61、将数据集分为训练集和测试集;
S62、利用高斯核支持向量机对Ba和Sr/Nd特征元素的训练集进行训练,然后使用测试集对所拟合的模型进行评测,得到最佳图解端元的特征数据训练机器学习分类器;
S63、以最佳图解端元的特征数据训练机器学习分类器,再利用所得分类模型对二维平面中的所有点数据进行预测计算,推断出决策边界。
S7、综合模型评估及视觉审查结果得出可视化判别图解。
优选的,步骤S7具体包括以下步骤:
本实施例中的模型预测结果为:随机森林准确率为0.823;K近邻准确率为0.792;线性内核支持向量机准确率为0.775;人工神经网络准确率为0.765。虽然在Ba和Sr/Nd特征元素可视化图解端元的机器学习模型中,随机森林算法的准确率最高,即0.823。但是综合决策边界图的视觉审查可看出(图4),K近邻和随机森林可视化决策边界图的边界线不规整较嘈杂,线性支持向量机和人工神经网络的边界线较清晰明了。因此,不宜使用上述决策边界图直接作为判别图解。为了使得判别图解判别更有效,所以将随机森林、高斯核支持向量机、人工神经网络或者K近邻方法的预测准确率作为权重,按照随机森林、K近邻、高斯核支持向量机和人工神经网络的决策边界线的顺序,选择符合要求(线条规整清晰)的线条进行边界拟合,得到最终的判别图解图。
在本实施例中收集了1075条全球埃达克质岩主微量地球化学数据。并借助sklearn库进行机器学习;pandas和numpy库进行数据分析和操作;geopandas库进行地理空间数据分析;itertools库进行端元穷举;matplotlib库进行图表绘制;mlxtend库进行决策边界绘制。
在Ba和Sr/Nd特征元素可视化图解端元的机器学习模型中,随机森林算法的准确率最高,即0.823。但是由图4所示的综合决策边界图的视觉审查可看出,K近邻和随机森林可视化决策边界图的边界线不规整较嘈杂,线性支持向量机和人工神经网络的边界线较清晰明了。因此,不宜使用上述决策边界图直接作为判别图解。同时,为了使得判别图解判别更有效,将根据四种机器学习算法的准确率作为权重,按照随机森林、K近邻、线性内核支持向量机和人工神经网络决策边界线的顺序,优先选择规整清晰的线条进行边界拟合,从而得到如图5所示的最终的判别图解图。
因此,本发明采用上述结构的融合机器学习的埃达克质岩构造背景判别图解方法,使用主成分分析和t分布-随机近邻嵌入等无监督学习方法进行高维数据降维,采用随机森林、高斯核支持向量机、人工神经网络和K近邻的机器学习方法训练,得出准确率为98.5%的高斯核支持向量机作为埃达克质岩构造背景判别器,并提出Ba vs.Sr/Nd图解,为汇聚板块边缘、板内火山活动和太古代克拉通(包括绿岩带)三种构造背景判别提供依据,拓展了机器学习在埃达克质岩构造背景研究中的应用,为构造-岩浆作用研究带来新的思路。
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。
- 一种沉积岩构造背景判别方法
- 埃克替尼和盐酸埃克替尼的制备方法及其中间体