一种基于机器学习方法的肝脏纤维化预测模型的构建方法、预测系统、设备和存储介质
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及一种基于机器学习方法的肝脏纤维化预测模型的构建方法、预测系统、设备和存储介质。
背景技术
传统的肝纤维化诊断需要通过穿刺针进行肝组织获取,操作过程不仅是有创,而且局部的肝组织获取并不能完全代表整个肝脏的病情发展程度。此外,部分病人会在穿刺术后承担疼痛、出血等术后并发症的风险。虽然国外已经有开发出的血清模型(比如APRI、FIB-4)和先进的肝硬度检测设备(例如超声弹性成像),但是上述方法的肝脏纤维化预测结果的准确率低,血清模型应用在国内病人数据的AUC值通常都在0.7左右。而肝硬度检测设备的准确性虽然相对较高,但很容易出现测量失误,因此也影响了其实用性。
发明内容
本发明的目的是为了解决现有的肝脏纤维化检测准确率低的问题,而提出一种基于机器学习方法的肝脏纤维化预测模型的构建方法、预测系统、设备和存储介质。
一种基于机器学习方法的肝脏纤维化预测模型的构建方法,所述预测方法通过以下步骤实现:
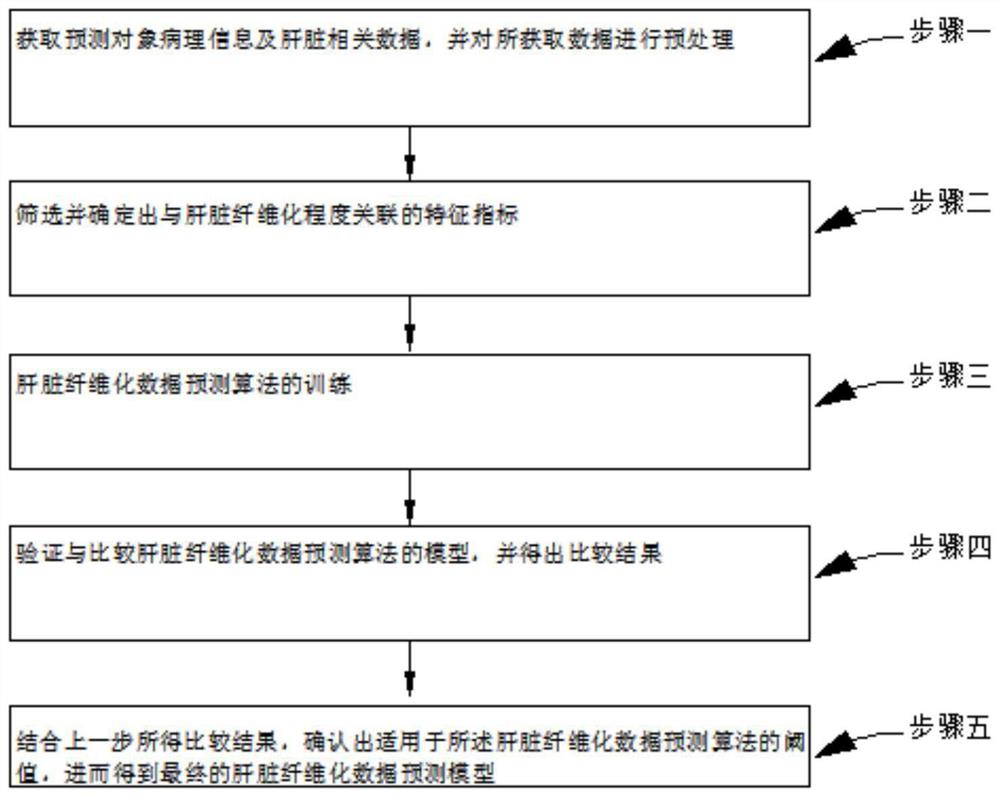
步骤一、获取预测对象病理信息及肝脏相关数据,并对所获取数据进行预处理;
步骤二、筛选并确定出与肝脏纤维化程度关联的特征指标;
步骤三、肝脏纤维化数据预测算法的训练;
步骤四、验证与比较肝脏纤维化数据预测算法的模型,并得出比较结果;
步骤五、结合上一步所得比较结果,确认出适用于所述肝脏纤维化数据预测算法的阈值,进而得到最终的肝脏纤维化数据预测模型
一种基于机器学习方法的肝脏纤维化预测系统,所述系统包括:
数据预处理模块,用于获取预测对象病理信息及肝脏相关数据,并对所获取数据进行预处理;
特征筛选模块,用于筛选并确定出与肝脏纤维化程度关联的特征;
算法训练模块,用于肝脏纤维化数据预测算法的训练;
算法验证模块,用于验证与比较肝脏纤维化数据预测算法的模型,并得出比较结果;
模型确认模块,用于结合上一步所得比较结果,确认出适用于所述肝脏纤维化数据预测算法的阈值,进而得到最终的肝脏纤维化数据预测模型。
一种用于基于机器学习方法的肝脏纤维化预测方法的预测设备,包括:
处理器;
存储器,其中存储有所述处理器的可执行指令;
其中,所述处理器配置为经由执行所述可执行指令来执行任一项所述的一种基于机器学习方法的肝脏纤维化预测模型的构建方法的步骤。
一种计算机可读存储介质,用于存储程序,所述程序被执行时实现任一项所述的一种基于机器学习方法的肝脏纤维化预测模型的构建方法的步骤。
本发明的有益效果为:
本发明是一种无创预测肝脏纤维化模型,是利用多个临床指标,包括血象检查、实验室生化全套检查、B超检查、弹性成像检查等数据来形成肝脏纤维化相关数据预测模型的。基于多个临床指标的无创诊断肝纤维化模型,不仅使得血清学和影像学之间的优劣进行互补,提高了模型的预测速度和准确性,能够为临床肝脏纤维化诊断提供参考。同时也避免了患者所需要承担的手术痛苦,能在较短的时间内得到较满意的结果,大大提高临床工作效率并减少了患者和医务人员的经济成本和时间成本。
利用本发明的肝脏纤维化预测模型来预测病毒性肝炎或者脂肪肝病人的肝纤维化程度,实现动态监测病情的效果。设定与预测结果相对应的肝纤维化级别,并按照预测结果和肝脏纤维化相适应的由低到高的严重程度设为1级、2级、3级,一般来说,肝纤维化程度达到2级就需要采取干预措施,达到3级以上就要考虑肝移植。
附图说明
图1为本发明的方法流程图;
图2为本发明涉及的针对显著肝脏纤维化(significant fibrosis)利用lasso回归筛选非0系数变量作为最终建模的输入变量的示意图;
图3为本发明涉及的肝硬化(cirrhosis)利用lasso回归筛选非0系数变量作为最终建模的输入变量的示意图;
图4为本发明涉及的针对显著肝脏纤维化(significant fibrosis)利用lasso回归筛选非0系数变量作为最终建模的输入变量的示意图;
图5为本发明涉及的肝硬化(cirrhosis)利用lasso回归筛选非0系数变量作为最终建模的输入变量的示意图;
图6为本发明涉及的训练组预测显著肝脏纤维化的受试者工作特征曲线(ROC)曲线图;
图7为本发明涉及的训练组预测肝硬化的受试者工作特征曲线(ROC)曲线图;
图8为本发明涉及的验证组预测显著肝脏纤维化的受试者工作特征曲线(ROC)曲线图;
图9为本发明涉及的验证组预测肝硬化的受试者工作特征曲线(ROC)曲线图;
图10为本发明涉及的训练组预测显著肝脏纤维化决策曲线分析(DCA)曲线图;
图11为本发明涉及的训练组预测肝硬化决策曲线分析(DCA)曲线图;
图12为本发明涉及的验证组预测显著肝脏纤维化决策曲线分析(DCA)曲线图;
图13为本发明涉及的验证组预测肝硬化决策曲线分析(DCA)曲线图。
具体实施方式
具体实施方式一:
本实施方式的一种基于机器学习方法的肝脏纤维化预测模型的构建方法,如图1所示,所述方法通过以下步骤实现:
步骤一、获取预测对象病理信息及肝脏相关数据,并对所获取数据进行预处理;
步骤二、筛选并确定出与肝脏纤维化程度关联的特征指标;
步骤三、肝脏纤维化数据预测算法的训练;
步骤四、验证与比较肝脏纤维化数据预测算法的模型,并得出比较结果;
步骤五、结合上一步所得比较结果,确认出适用于所述肝脏纤维化数据预测算法的阈值,进而得到最终的肝脏纤维化数据预测模型。
具体实施方式二:
与具体实施方式一不同的是,本实施方式的一种基于机器学习方法的肝脏纤维化预测模型的构建方法,步骤一所述的数据是从医院获取的病人病理信息,例如,淮安市第四人民医院、北京佑安医院、吉林省肝胆医院和安徽中医药大学第一附属医院等四个中心经行,包括:病人的基本信息、肝脏纤维化病理活检数据、超声弹性成像数据、B超图像测量数据和血清实验室检查数据;
步骤一所述的对数据进行预处理为,除了肝脏纤维化病理活检数据不做预处理外,其余的数值型变量统一进行两步处理:
(1)、将每个数值型变量从小到大排列,将小于第2.5%或者大于第97.5%的视为异常值并分别更改为2.5%和97.5%;
(2)、将所有数值型变量归一化,归一化公式如下:
X
X
其中,
所述的病人的基本信息包括年龄、性别、身高、体重;
所述的B超图像测量数据包括脾脏尺寸、脾静脉直径、门静脉直径、门静脉流速;
所述的血清实验室检查数据包括白细胞计数、血小板计数、谷丙转氨酶、谷草转氨酶、谷氨酰转肽酶、总胆红素、直接胆红素、凝血时间、碱性磷酸酶、白蛋白、血胆固醇、凝血国际标准化比值、透明质酸酶、III型前胶原肽、四型胶原蛋白、层粘连蛋白。
具体实施方式三:
与具体实施方式一或二不同的是,本实施方式的一种基于机器学习方法的肝脏纤维化预测模型的构建方法,步骤二所述的筛选并确定出与肝脏纤维化程度关联的特征指标的步骤具体为:
选取采集的数据中的一部分作为训练组,这里以淮安市第四人民医院和吉林省肝胆医院作为训练组,以北京佑安医院和安徽中医药大学第一附属医院另一部分数据作为两个模型的验证中心;
之后,在训练组里通过斯皮尔曼相关性分析筛选出有显著相关性的特征指标;
之后,通过lasso回归对筛选出的指标进行进一步精筛选,所述的Lasso回归的代价函数为:
其中,x
之后,筛选出与肝脏纤维化程度关联的指标包括:谷草转氨酶、谷氨酰转肽酶、血小板计数、凝血时间、透明质酸酶、III型前胶原肽、四型胶原蛋白、层粘连蛋白、超声弹性成像和门静脉直径;
图2-5中,利用lasso回归筛选非0系数变量作为最终建模的输入变量。图2和图4为针对显著肝脏纤维化(significant fibrosis);图3和图5为针对肝硬化(cirrhosis)。图2、3、4、5横坐标都为log lambda(logλ),图2、3的纵坐标为AUC值,4、5的纵坐标为系数值。图2、3为根据AUC值确定最佳输入变量的个数,从而确定最佳lambda值(λ值)。图4、5为根据图2、3确定的lambda值(λ值)而得到的在这lambda值(λ值)时候的非零系数变量。
具体实施方式四:
与具体实施方式三不同的是,本实施方式的一种基于机器学习方法的肝脏纤维化预测模型的构建方法,步骤三所述的肝脏纤维化数据预测算法的训练的步骤,具体为:
采用LightGBM算法对筛选出的指标进行训练,拟合肝脏纤维化程度;LightGBM是使用基于树的学习算法的梯度增强框架。它被设计为分布式且高效的。与其他模型相比,它具有许多优势,例如训练速度更快,效率更高,内存使用更少,准确性更高,支持并行和GPU学习,能够处理大规模数据。LightGBM使用逐叶策略来查找具有最大分配器增益的叶子,这与产生冗余计算的低效逐叶策略不同。将学习效率设定为0.1,决策树树叶的数量设定为90;为了防止过拟合和提高运行速度,将列采样技术参数(colsample_bytree)设定为0.9;其中,使用LightGBM算法构造基于多个临床数据的肝脏纤维化预测模型的步骤如下:
1)、将数据集划分成训练样本集和测试样本集;
2)、使用LightGBM方法建立肝脏纤维化预测模型,设置肝脏纤维化预测模型参数,参数包括决策树树叶叶子数目,迭代次数,学习效率;
3)、将训练样本集输入到肝脏纤维化预测模型中,完成肝脏纤维化预测模型的训练;
4)、将测试样本集输入到肝脏纤维化预测模型中,输出肝脏纤维化程度的相关数据;
5)、根据肝脏纤维化程度的相关数据建立受试者工作特征曲线ROC。
具体实施方式五:
与具体实施方式四不同的是,本实施方式的一种基于机器学习方法的肝脏纤维化预测模型的构建方法,所述的步骤四中,验证与比较肝脏纤维化数据预测算法的模型,并得出比较结果的步骤,具体为:
将上一步骤中建立的模型代入北京佑安医院和安徽中医药大学第一附属医院两个验证中心进行验证,同时将此模型与单独的超声弹性成像、APRI和FIB-4进行检验比较;
APRI的公式为:
"APRI=""(AST(IU/L)/ULN)×100"/(Platelet count(10^9/L))
FIB-4的公式为:
"FIB-4=""age(years)×AST(IU/L)"/(Platelet count(10^9/L)×ALT(IU/L)^1/2)
采用ROC曲线和DCA曲线进行效果评价与模型之间对比;
其中,APRI表示AST与PLT的比值;AST表示谷草转氨酶水平,ULN表示AST在正常值上限(即40IU/L),platelet count表示血小板计数;Age表示年龄,ALT表示谷丙转氨酶水平;APRI全名为aspartate transaminase-to-platelet ratio index,是谷草转氨酶与血小板的比值;FIB-4全称fibrosis-4,属于一种无创性评估慢性肝病患者肝脏纤维化的一种方法的专有名词;Platelet count(10^9/L)中,Platelet count为血小板计数,L表示度量单位升;
如图6-13所示。
图6-9为受试者工作特征曲线(ROC)曲线图,为本申请与APRI、FIB-4和TE(超声弹性成像)的模型分类能力评价。可以认为曲线越高能力越出色。图6-7为训练组,图8-9为验证组,图6和图8为预测显著肝脏纤维化,图7和图9为预测肝硬化。
图10-13为决策曲线分析(DCA)曲线图,为本申请与APRI,FIB-4和TE(超声弹性成像)的模型提供的获益程度比较。可以认为曲线越高获益越高。图10-11为训练组,图12-13为验证组,图10和图12为预测显著肝脏纤维化,图11和图13为预测肝硬化。
所述的步骤五中,结合上一步所得比较结果,确认出适用于所述肝脏纤维化数据预测算法的阈值,进而得到最终的肝脏纤维化数据预测模型的过程为,根据ROC曲线的最大约登指数(敏感性加特异性-1)来确认评价2级肝脏纤维化与肝硬化的模型阈值范围,根据确定出的阈值得到最终的模型的合理参数范围,从而确定最终参数固定的模型,并进行预测。
基于多个临床数据的肝脏纤维化模型,能在不做肝穿刺的情况下快速完成肝脏纤维化诊断,以此能高效率随时监测病人肝脏病变程度,制定对应的临床干预措施。不仅减少了病人的经济负担和医生的时间成本,而且也避免了病人需要有创检查带来的痛苦和并发症,减轻了医疗负担。
具体实施方式六:
本实施方式的一种基于机器学习方法的肝脏纤维化预测系统,所述系统包括:
数据预处理模块,用于获取预测对象病理信息及肝脏相关数据,并对所获取数据进行预处理;
特征筛选模块,用于筛选并确定出与肝脏纤维化程度关联的特征;
算法训练模块,用于肝脏纤维化数据预测算法的训练;
算法验证模块,用于验证与比较肝脏纤维化数据预测算法的模型,并得出比较结果;
模型确认模块,用于结合上一步所得比较结果,确认出适用于所述肝脏纤维化数据预测算法的阈值,进而得到最终的肝脏纤维化数据预测模型。
具体实施方式七:
本实施方式的一种基于机器学习方法的肝脏纤维化预测系统,所述的数据预处理模块还包括:
数据排列部,用于将每个数值型变量从小到大排列的数据排列部;
异常值更改部,与数据排列部相连,用于将小于第2.5%或者大于第97.5%的视为异常值并分别更改为2.5%和97.5%;
数值变量归一化部,与异常值更改部,用于将所有数值型变量归一化,归一化公式如下:
X
X
所述的特征筛选模块还包括:
数据分组部,用于将采集的数据中的一部分选取作为训练组,另一部分数据作为验证中心;
筛选相关性特征指标部,与数据分组部连接,用于在训练组里通过斯皮尔曼相关性分析筛选出相关性的特征指标;
精筛选部,与筛选相关性特征指标部连接,从所得相关性的特征指标中通过lasso回归对筛选出的指标进行进一步精筛选;
肝脏纤维化程度关联的指标筛选部,与精筛选部连接,从精筛选部的结果中筛选出与肝脏纤维化程度关联的指标。
具体实施方式七:
本实施方式的一种基于机器学习方法的肝脏纤维化预测系统,
所述的算法训练模块还包括:
指标筛选拟合部,用于对筛选出的指标进行训练,拟合肝脏纤维化程度;采用LightGBM算法对筛选出的指标进行训练;
肝脏纤维化预测模型构造部,用于使用LightGBM算法构造基于多个临床数据的肝脏纤维化预测模型。
所述的算法验证模块还包括:
效果评价部,用于采用ROC曲线进行效果评价;
所述的模型确认模块还包括:
确认阈值部,用于结合上一步所得比较结果,根据ROC曲线的最大约登指数敏感性加特异性-1来确认评价2级肝脏纤维化与肝硬化的模型阈值范围;
预测模型确认部,与确认阈值部连接,用于根据确定出的阈值得到最终的模型的合理参数范围,从而确定最终参数固定的模型。
具体实施方式九:
本实施方式的一种基于机器学习方法的肝脏纤维化预测设备,包括:
处理器;
存储器,其中存储有所述处理器的可执行指令;
其中,所述处理器配置为经由执行所述可执行指令来执行所述的一种基于机器学习方法的肝脏纤维化预测模型的构建方法的步骤。
具体实施方式十:
本实施方式的一种计算机可读存储介质,用于存储程序,所述程序被执行时实现权所述的一种基于机器学习方法的肝脏纤维化预测模型的构建方法的步骤。
- 一种基于机器学习方法的肝脏纤维化预测模型的构建方法、预测系统、设备和存储介质
- 一种基于机器学习的预测模型构建方法、装置和电子设备