一种数据库间的数据一致性比对方法及装置
文献发布时间:2023-06-19 19:38:38
技术领域
本申请涉及数据库中数据一致性比对领域,尤其涉及一种数据库间的数据一致性比对方法。本申请还涉及一种数据库间的数据一致性比对装置。
背景技术
随着大数据的发展,很多业务场景中会涉及到数据同步的操作。
现有技术中,一般需要将主节点数据同步到备节点数据,或者将某一类型数据库表的数据同步到其他类型数据库表中。同步中如果出现数据不一致,通常采用人工方法将差异数据比对出来。
现有技术中存在的缺陷是,采用人工方法很难将差异数据比对出来,特别是异构数据库间本身不互通,更难于操作。
发明内容
本申请的目的在于克服现有技术中人工方法很难将差异数据比对出来的缺陷,提供一种数据库间的数据一致性比对方法。本申请还涉及一种数据库间的数据一致性比对装置。
本申请提供的一种数据库间的数据一致性比对方法,包括:
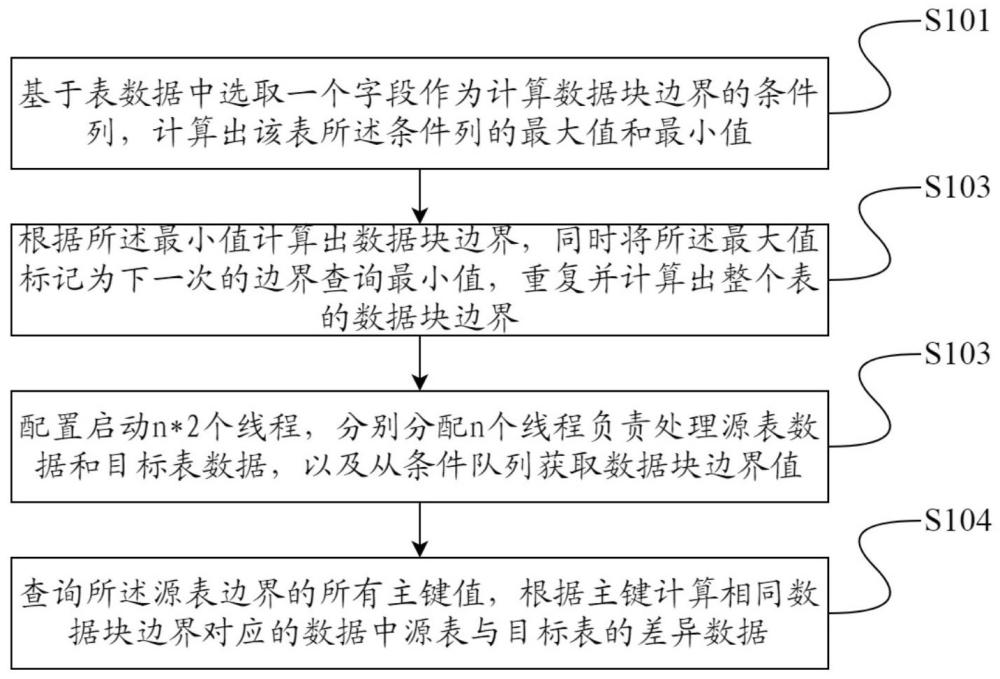
基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值;
根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界;
配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值;
查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
可选的,所述条件列有索引。
可选的,所述计算出该表所述条件列的最大值和最小值,包括:
通过【select min(c1),max(c1)from t】计算出该表所述条件列的最大值和最小值;
其中,所述c1表示条件列。
可选的,所述计算出数据块边界,包括:
通过 【select max(c1) from t where c1 >= 边界查询最小值 order by c1limit 1000 】 计算出数据块边界为【max(c1)值-该sql的查询条件列的值】;
其中,所述c1表示条件列。
可选的,所述查询所述源表边界值范围内的所有主键值形式如下:
select 主键列1,...,主键列n from t where 比较列 >= 边界最小值 and 比较列 <= 边界最大值 order by 比较列 desc。
可选的,还包括:查询源表该边界的所有主键值,记录到源表块数据容器中。
可选的,所述记录到源表块数据容器中,包括:
通过配置控制块数据容器的使用大小。
可选的,所述计算相同数据块边界对应的数据中源表与目标表的差异数据:包括:
将相同数据块边界的源表数据块与目标表数据块标记为同一组;
读取标记为同一组的数据进行双向比较,计算出差异主键数据后落地成文件。
可选的,所述落地成文件,包括:
源表存在的主键,如果目标表不存在,将该主键数据记录到文件1中;
目标表存在的主键,如果源表不存在,将该主键数据记录到文件2中。
本申请还提供一种数据库间的数据一致性比对装置,包括:
第一计算模块,基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值;
第二计算模块,根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界;
配置查询模块,配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值;
比对模块,查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
本申请的优点和有益效果:
本申请提供的一种数据库间的数据一致性比对方法,包括:基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值;根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界;配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值;查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。本申请通过算法快速将数据分解成多个数据块边界,每个数据块边界可以独立进行数据查询比对,多个数据块边界间可以并行比对从而提升性能,提高比对速度,降低比对难度。
附图说明
图1是本申请中数据库间的数据一致性比对流程示意图。
图2是本申请中数据库间的数据一致性比对逻辑示意图。
图3是本申请中数据库间的数据一致性比对装置示意图。
具体实施方式
下面结合附图和具体实施例对本申请作进一步说明,以使本领域的技术人员可以更好地理解本申请并能予以实施。
以下内容均是为了详细说明本申请要保护的技术方案所提供的具体实施过程的示例,但是本申请还可以采用不同于此的描述的其他方式实施,本领域技术人员可以在本申请构思的指引下,采用不同的技术手段实现本申请,因此本申请不受下面具体实施例的限制。
本申请提供的一种数据库间的数据一致性比对方法,包括:基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值;根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界;配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值;查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。本申请通过算法快速将数据分解成多个数据块边界,每个数据块边界可以独立进行数据查询比对,多个数据块边界间可以并行比对从而提升性能,提高比对速度,降低比对难度。
请参照图1所示,本申请目的是解决传统数据比对方式慢的问题。通过算法快速将数据分解成多个数据块边界,每个数据块(chunk)边界可以独立进行数据查询比对,多个数据块边界间可以并行比对从而提升性能。比对过程中仅进行主键比对,且进行双向比对。
对于源表存在的主键,如果目标表不存在,将该主键数据记录到文件1中。
对于目标表存在的主键,如果源表不存在,将该主键数据记录到文件2中。
本申请涉及的技术方案中不要求切分数据块边界的条件必须为主键,所以即使存在联合主键的情况下也不影响使用及效率,同时在综合考虑内存,cpu的资源占用基础上,通过合理配置实现了比对任务的最优性能。
如图1所示,S101基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值。
计算表的数据块边界,所述表包括:源表和目标表。
本申请中,计算表的数据块边界是最重要的一步,通过快速计算边界后才能通过多线程并行查询数据块边界的数据进行比较提升性能。
具体的,首先需要选取一个字段作为计算数据块边界的条件列,一般该列要求有索引,且数据尽可能不重复。在本申请中,该条件列记为c1。
通过【select min(c1),max(c1)from t】计算出该表所述条件列的最大值最小值。其中min(c1)记为初始化的边界查询最小值。
如图1所示,S102根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界。
通过 【select max(c1) from t where c1 >= 边界查询最小值 order by c1limit 1000 】 计算出数据块边界为【max(c1)值-该sql的查询条件列的值】,同时标记max(c1)值为下一次的边界查询最小值。
最后,重复并计算出整个表的数据块边界。
一个具体的例子说明以上步骤计算后的结果如下:
假设t表有c1,c2,c3列,共1000条数据,为了方便演示,假设c1列数据内容为data1-data1000共计1000条,计算边界时limit条件为100,经过上述规则计算后拆分的数据块记录如下:
计算获取如上结构的数据块边界并放入条件队列,供后续步骤处理。
如图1所示,S103配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值。
该步骤为多线程,每个线程负责从条件队列获取数据块边界后,从表中读取需要比较的主键数据,并存入内存,用于后续比较。
上文说过数据块边界为条件列,并不强制要求条件列必须为主键,因为主键理论上可能为联合主键,如果多列作为条件列会加大计算边界的难度并影响性能。其基本算法过程如下:
如图2所示,S201边界查询线程。
S202准备已确定的源表条件列和目标条件列。
S203通过配置启动2n个线程,针对源表n个线程负责处理源表数据,n个线程负责处理目标表数据。
S204针对源表的每个线程负责从条件队列获取数据块边界值,然后查询源表该边界的所有主键值,记录到源表块数据容器中。其sql如下形式:
select 主键列1,...,主键列n from t where 比较列 >= 边界最小值 and 比较列 <= 边界最大值 order by 比较列 desc。
针对目标表的每个线程负责从条件队列获取数据块边界值,然后查询目标表该边界的所有主键值,记录到目标表块数据容器中。其sql如下形式:
select 主键列1,...,主键列n from t where 比较列 >= 边界最小值 and 比较列 <= 边界最大值 order by 比较列 desc。
超过指定大小后,向块数据容器中放入数据时会被阻塞,只有数据被后续线程比较处理销毁后被阻塞的数据才能放进去。为了控制内存的使用,通过配置可以控制块数据容器的使用大小。
如图1所示,S104查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
请继续参考图2所示,S205相同数据块边界的源表数据块与目标表数据块会被标记为同一组,该线程负责获取已经读取完成的被标记为同一组的数据进行双向比较。
S206计算出差异主键数据后落地成文件,该组数据被比对完成后销毁数据块,释放空间。
最后,差异数据落地生成文件。
对于比较结果,按如下规则落地文件:
对于源表存在的主键,如果目标表不存在,将该主键数据记录到文件1中。
对于目标表存在的主键,如果源表不存在,将该主键数据记录到文件2中。
如图3所示,本申请还提供一种数据库间的数据一致性比对装置,该装置用于执行上述方法。
第一计算模块301,基于表数据中选取一个字段作为计算数据块边界的条件列,计算出该表所述条件列的最大值和最小值。
计算表的数据块边界,所述表包括:源表和目标表。
本申请中,计算表的数据块边界是最重要的一步,通过快速计算边界后才能通过多线程并行查询数据块边界的数据进行比较提升性能。
具体的,选取一个字段作为计算数据块边界的条件列,一般该列要求有索引,且数据尽可能不重复。在本申请中,该条件列记为c1。
通过【select min(c1),max(c1)from t】计算出该表所述条件列的最大值最小值。其中min(c1)记为初始化的边界查询最小值。
第二计算模块302,根据所述最小值计算出数据块边界,同时将所述最大值标记为下一次的边界查询最小值,重复并计算出整个表的数据块边界。
通过 【select max(c1) from t where c1 >= 边界查询最小值 order by limit1000 】 计算出数据块边界为【max(c1)值-该sql的查询条件列的值】,同时标记max(c1)值为下一次的边界查询最小值。
最后,重复并计算出整个表的数据块边界。
配置查询模块303,配置启动2n个线程,分别分配n个线程负责处理源表数据和目标表数据,以及从条件队列获取数据块边界值。
该步骤为多线程,每个线程负责从条件队列获取数据块边界后,从表中读取需要比较的主键数据,并存入内存,用于后续比较。
上文所述条件列,并不强制要求条件列必须为主键,因为主键理论上可能为联合主键,如果多列作为条件列会加大计算边界的难度并影响性能。其基本算法如下:
通过配置启动2n个线程,针对源表n个线程负责处理源表数据,n个线程负责处理目标表数据
针对源表的每个线程负责从条件队列获取数据块边界值,然后查询源表该边界的所有主键值,记录到源表块数据容器中。其sql如下形式:
select 主键列1,...,主键列n from t where 比较列 >= 边界最小值 and 比较列 <= 边界最大值 order by 比较列 desc。
针对目标表的每个线程负责从条件队列获取数据块边界值,然后查询目标表该边界的所有主键值,记录到目标表块数据容器中。其sql如下形式:
select 主键列1,...,主键列n from t where 比较列 >= 边界最小值 and 比较列 <= 边界最大值 order by 比较列 desc。
超高指定大小后,向块数据容器中放入数据时会被阻塞,只用块数被后续线程比较处理被销毁后被阻塞的数据才能放进去。为了控制内存的使用,通过配置可以控制块数据容器的使用大小。
比对模块304,查询所述源表边界值范围内的所有主键值,根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
根据主键计算相同数据块边界对应的数据中源表与目标表的差异数据。
具体的,相同数据块边界的源表数据块与目标表数据块会被标记为同一组,该线程负责获取已经读取完成的被标记为同一组的数据进行双向比较,计算出差异主键数据后落地成文件,该组数据被比对完成后销毁数据块,释放空间。
最后,差异数据落地生成文件。
对于比较结果,按如下规则落地文件:
对于源表存在的主键,如果目标表不存在,将该主键数据记录到文件1中。
对于目标表存在的主键,如果源表不存在,将该主键数据记录到文件2中。
最后应说明的是:以上实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的精神和范围。
- 一种检测数据库数据一致性的方法、装置及数据库系统
- 一种检测数据库数据一致性的方法、装置及数据库系统