音频识别方法、计算机设备和计算机程序产品
文献发布时间:2024-01-17 01:15:20
技术领域
本申请涉及音频技术领域,特别是涉及一种音频识别方法、计算机设备和计算机程序产品。
背景技术
随着计算机技术发展,利用翻唱识别技术搜索翻唱歌曲或原创作品关联的原唱歌曲已日益广泛。
在相关技术中,翻唱识别技术可以基于翻唱音频的歌词或音高等信息进行匹配,将包含相似歌词内容或音高序列的歌曲作为翻唱歌曲的原唱歌曲。然而,当待识别的音频中存在说话声或其他噪音时,会错误地将话声或其他噪音作为歌曲内容,并将具有相似歌词内容或音高序列的歌曲作为该音频的原唱歌曲,影响翻唱识别过程中,原唱歌曲召回结果的准确性。
发明内容
基于此,有必要针对上述技术问题,提供一种能够提高原唱歌曲召回结果准确性的音频识别方法、计算机设备和计算机程序产品。
第一方面,本申请提供了一种音频识别方法。所述方法包括:
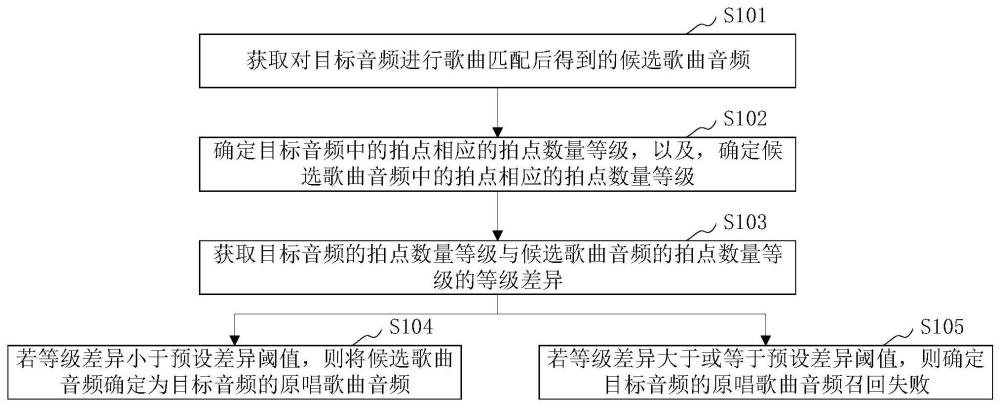
获取对目标音频进行歌曲匹配后得到的候选歌曲音频;
确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级;
获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异;
若所述等级差异小于预设差异阈值,则将所述候选歌曲音频确定为所述目标音频的原唱歌曲音频;
若所述等级差异大于或等于预设差异阈值,则确定所述目标音频的原唱歌曲音频召回失败。
在其中一个实施例中,所述确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级,包括:
将所述目标音频划分为预设时长的多个目标音频片段,并获取每个所述目标音频片段中的拍点相应的拍点数量等级;以及,
将所述候选歌曲音频划分为所述预设时长的多个候选歌曲音频片段,并获取每个所述候选歌曲音频片段中的拍点相应的拍点数量等级。
在其中一个实施例中,所述获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异,包括:
确定每个所述目标音频片段的拍点数量等级以及对应的每个所述候选歌曲音频片段的拍点数量等级的片段等级差异;
根据多个所述片段等级差异,确定所述目标音频和所述候选歌曲音频的拍点数量等级的等级差异。
在其中一个实施例中,所述确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级,包括:
将所述目标音频对应的音频特征输入到训练好的拍点信息识别模型,得到所述拍点信息识别模型输出的所述目标音频的拍点数量等级;以及,
将所述候选歌曲音频对应的音频特征输入到所述拍点信息识别模型,得到所述拍点信息识别模型输出的所述候选歌曲音频的拍点数量等级。
在其中一个实施例中,所述拍点信息识别模型通过如下步骤训练得到:
获取包含说话人语料音频和/或噪声音频的多个样本音频;
基于所述多个样本音频和每个所述样本音频的拍点数量等级标签,对待训练的拍点信息识别模型进行监督训练;
在满足训练结束条件时,得到训练好的拍点信息识别模型。
在其中一个实施例中,所述获取对目标音频进行歌曲匹配后得到的候选歌曲音频,包括:
确定目标音频的歌词,并确定所述目标音频的歌词与音频库中各个歌曲音频的歌词的歌词相似度;
若存在所述歌词相似度最大且大于第一相似度阈值的歌曲音频,则将该歌曲音频确定为所述目标音频的候选歌曲音频。
在其中一个实施例中,在所述确定所述歌词与音频库中多个歌曲音频的歌词的歌词相似度之后,还包括:
若所述目标音频的歌词与音频库中各个歌曲音频的歌词的歌词相似度均小于所述第一相似度阈值,则确定所述目标音频的旋律与所述音频库中各个歌曲音频的旋律的旋律相似度;
若存在所述旋律相似度最大且大于第二相似度阈值的歌曲音频,则将该歌曲音频确定为所述目标音频的候选歌曲音频。
在其中一个实施例中,所述确定所述目标音频的旋律与所述音频库中各个歌曲音频的旋律的旋律相似度,包括:
获取所述目标音频的旋律特征,并确定所述目标音频的旋律特征与所述音频库中各个歌曲音频的旋律特征的余弦距离;
基于所述余弦距离,确定所述目标音频的旋律与所述音频库中各个歌曲音频的旋律的旋律相似度。
第二方面,本申请还提供了一种计算机设备。所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
获取对目标音频进行歌曲匹配后得到的候选歌曲音频;
确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级;
获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异;
若所述等级差异小于预设差异阈值,则将所述候选歌曲音频确定为所述目标音频的原唱歌曲音频;
若所述等级差异大于或等于预设差异阈值,则确定所述目标音频的原唱歌曲音频召回失败。
第三方面,本申请还提供了一种计算机程序产品。所述计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
获取对目标音频进行歌曲匹配后得到的候选歌曲音频;
确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级;
获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异;
若所述等级差异小于预设差异阈值,则将所述候选歌曲音频确定为所述目标音频的原唱歌曲音频;
若所述等级差异大于或等于预设差异阈值,则确定所述目标音频的原唱歌曲音频召回失败。
上述音频识别方法、计算机设备和计算机程序产品,可以获取对目标音频进行歌曲匹配后得到的候选歌曲音频,确定目标音频中的拍点相应的拍点数量等级以及候选歌曲音频中的拍点相应的拍点数量等级,进而可以获取目标音频的拍点数量等级与候选歌曲音频的拍点数量等级的等级差异;若等级差异小于预设差异阈值,则将候选歌曲音频确定为目标音频的原唱歌曲音频,若等级差异大于或等于预设差异阈值,则确定目标音频的原唱歌曲音频召回失败。本申请中,通过比较目标音频和候选歌曲音频拍点数量等级的等级差异,并将该等级差异与差异阈值比较,一方面,可以确定目标音频的音频内容和候选歌曲音频的音频内容节奏上的差异程度,从而识别出目标音频中是否包含与候选歌曲音频无关的内容,避免将候选歌曲音频错误地作为目标音频的原唱歌曲音频,另一方面,可以避免直接检测拍点数量差异而造成的误过滤,提升原唱歌曲召回结果的准确性。
附图说明
图1为一个实施例中一种音频识别方法的流程示意图;
图2为一个实施例中一种确定拍点数量等级的等级差异的步骤的流程示意图;
图3为一个实施例中一种训练拍点信息识别模型的步骤的流程示意图;
图4为一个实施例中一种获取候选歌曲音频的步骤的流程示意图;
图5为一个实施例中另一种音频识别方法的流程示意图;
图6为一个实施例中计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
在一个实施例中,如图1所示,提供了一种音频识别方法,本实施例以该方法应用于服务器进行举例说明,可以理解的是,该方法也可以应用于终端,还可以应用于包括终端和服务器的系统,并通过终端和服务器的交互实现。其中,服务器可以用独立的服务器或者是多个服务器组成的服务器集群来实现;终端可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑等。
在本实施例中,该方法包括以下步骤:
S101,获取对目标音频进行歌曲匹配后得到的候选歌曲音频。
其中,目标音频可以是待进行翻唱识别并检索对应的原唱歌曲音频的音频。示例性地,目标音频可以包括用户上传的录音音频,如可以从用户预先录制得到的音频文件或视频文件中读取目标音频,或者实时上传的音频流;当然,也可以包括通过其他方式获取的音频,例如从网络下载的歌曲音频。
候选歌曲音频可以是具有旋律的音频,例如包含歌词的歌曲,或者,不包含歌词的纯音乐,如伴奏。
实际应用中,可以对目标音频进行歌曲匹配,歌曲匹配可以是指获取与歌曲内容与目标音频关联的歌曲音频,例如歌词或旋律与目标音频关联的歌曲音频,从而可以得到候选歌曲音频。
S102,确定目标音频中的拍点相应的拍点数量等级,以及,确定候选歌曲音频中的拍点相应的拍点数量等级。
其中,拍点也可以称为节拍点,可以是指旋律节拍中上一拍与下一拍的衔接点,本实施例中拍点数量可以理解为旋律中的拍点相应的数量。
针对不同的拍点数量,可以预先进行等级划分,将不同的拍点数量划分为不同的区间,并针对每个区间设置相应的拍点数量等级,得到多个拍点数量等级。示例性地,拍点数量等级可以与拍点数量呈正相关,即随着拍点数量增加,拍点数量等级也相应上升,例如,若拍点数量小于5,拍点数量等级可以设置为0级,拍点数量在[5,10)范围内为1级,在[10,15)范围内为2级,在[15,20)范围内为3级,若拍点数量大于20,则可以设置为4级。当然,在另外一些示例中,拍点数量等级也可以与拍点数量呈负相关。
本步骤中,在获取到目标音频相关联的候选歌曲音频后,可以分别确定目标音频中的拍点相应的拍点数量等级以及候选歌曲音频中的拍点的拍点数量等级。在一些可选的实施例中,可以通过预先训练的模型识别音频的拍点数量等级,或者,也可以在识别出音频中的拍点后,根据音频的拍点所归属的数量区间,将该数量区间对应的拍点数量等级作为音频的拍点数量等级。
S103,获取目标音频的拍点数量等级与候选歌曲音频的拍点数量等级的等级差异。
在确定目标音频和候选歌曲音频各自的拍点数量等级后,可以对两者的拍点数量等级进行对比,确定目标音频与候选歌曲音频在拍点数量等级上的等级差异,例如,可以基于目标音频的拍点数量等级与候选歌曲音频的拍点数量等级的差值,得到等级差异。
S104,若等级差异小于预设差异阈值,则将候选歌曲音频确定为目标音频的原唱歌曲音频。
S105,若等级差异大于或等于预设差异阈值,则确定目标音频的原唱歌曲音频召回失败。
作为一示例,原唱歌曲音频可以理解为未经过改编的歌曲音频,例如公开发布的初始版本的歌曲音频,用户在实际应用中可以对原唱歌曲音频进行一种或多种改编处理,如调整旋律、歌词或曲风,从而得到新的歌曲音频,新的歌曲音频也可以称为原唱歌曲音频的翻唱音频或改编音频。
具体实现中,对于目标音频中包含人声的情况,存在其内容虽然为人声但实际是与歌曲内容无关的信息,例如对于目标音频包含说话声,若说话内容与部分歌曲的歌词内容相似,如若目标音频中涉及到人声朗诵“歌唱我们亲爱的祖国,从今走向繁荣富强”,则进行歌曲匹配时存在匹配到《歌唱祖国》为候选歌曲音频的情况,但目标音频实际上可能只是诗朗诵录音,按照歌词内容进行匹配的方式容易错误地将包含相同或相似歌词内容的候选歌曲音频作为包含无关人声的目标音频的原唱歌曲音频。
又如,在基于音高序列(如旋律)进行歌曲匹配时,虽然目标音频中的多个音高可以与候选歌曲音频中的多个音高匹配上,但是目标音频中的音高有可能是噪声导致的,并不是歌曲本身的旋律,即目标音频可能不包含候选歌曲音频的旋律或者其旋律并不相似,此情况下也容易将候选歌曲音频错误地作为目标音频的原唱歌曲音频。
对于目标音频中包含与歌曲内容无关的说话声的情况,可以理解,在说话过程中说话人主要按照字词进行断句、说话,往往不具有节奏感或节奏感极微弱,而歌曲中的歌词往往会与歌曲旋律的节奏相适配,例如字词的重读位置或歌唱过程中呼吸的换气位置会与歌曲旋律的拍点位置相适配,因此,与歌曲无关的说话声的拍点疏密程度与用户演唱歌词时拍点疏密程度会存在较大差异。而对于目标音频包含噪声的情况,由于噪声的无序性更高,音频中的拍点会更加稀疏,与具有旋律的歌曲音频的拍点疏密程度也会有较大差异。
对此,本申请在得到目标音频的候选歌曲音频后,可以进一步获取目标音频和候选歌曲音频拍点数量等级的等级差异,并判断等级差异是否小于预设差异阈值。由于拍点数量等级可以表征旋律中拍点疏密程度,若等级差异小于预设差异阈值,可以确定目标音频和候选歌曲音频的拍点数量相近,在歌曲内容(如歌词或音高序列)匹配的同时,确定两者的节奏或韵律相似,从而可以将候选歌曲音频确定为目标音频的原唱歌曲音频。
若等级差异大于或等于预设差异阈值,可以确定目标音频和候选歌曲音频的拍点疏密程度差异大,两者节奏韵律存在较大区别,则可以对当前的候选歌曲音频进行过滤、剔除,不将候选歌曲音频作为目标音频的原唱歌曲音频,确定目标音频的原唱歌曲召回失败。
在一些示例中,可以展示原唱歌曲召回失败提示,以提示当前未获取到目标音频的原唱歌曲音频,目标音频中的无关人声和噪声可能是由于录音环境差、用户误触发或随意录制等因素导致,通过向用户返回原唱歌曲召回失败提示,可以引导用户正确录音,提高目标音频的录音质量。
此外,在一些实施例中,虽然也可以直接比较目标音频和候选歌曲音频中拍点的数量差异,但是该方式容错度低,容易造成候选歌曲音频的误过滤(例如,候选歌曲音频确实为目标音频的原唱歌曲音频,但用户在录制目标音频过程中由于歌词演唱节奏有误,而造成拍点数的差异);而本申请通过比较目标音频和候选歌曲音频之间拍点数量等级的等级差异,而非直接对比目标音频和候选歌曲音频中拍点的数量差异,能够避免因拍点检测误差而造成的误过滤,提高原唱歌曲音频召回的准确性。
在本实施例中,可以获取对目标音频进行歌曲匹配后得到的候选歌曲音频,确定目标音频中的拍点相应的拍点数量等级以及候选歌曲音频中的拍点相应的拍点数量等级,进而可以获取目标音频的拍点数量等级与候选歌曲音频的拍点数量等级的等级差异;若等级差异小于预设差异阈值,则将候选歌曲音频确定为目标音频的原唱歌曲音频,若等级差异大于或等于预设差异阈值,则确定目标音频的原唱歌曲音频召回失败。本申请中,通过比较目标音频和候选歌曲音频拍点数量等级的等级差异,并将该等级差异与差异阈值比较,一方面,可以确定目标音频的音频内容和候选歌曲音频的音频内容节奏上的差异程度,从而识别出目标音频中是否包含与候选歌曲音频无关的内容,避免将候选歌曲音频错误地作为目标音频的原唱歌曲音频,另一方面,可以避免直接检测拍点数量差异而造成的误过滤,提升原唱歌曲召回结果的准确性。
在一个实施例中,确定目标音频中的拍点相应的拍点数量等级,以及,确定候选歌曲音频中的拍点相应的拍点数量等级,可以包括如下步骤:
将目标音频划分为预设时长的多个目标音频片段,并确定每个目标音频片段中的拍点相应的拍点数量等级;以及,将候选歌曲音频划分为预设时长的多个候选歌曲音频片段,并确定每个候选歌曲音频片段中的拍点相应的拍点数量等级。
在具体实现中,可以按照预设的时长跨度,将目标音频和候选歌曲音频划分为多个音频片段,得到目标音频对应的多个目标音频片段以及候选歌曲音频片段。
可以理解,在音频的不同片段,拍点数量是可以变化的,本步骤中,可以确定每个目标音频片段和每个候选歌曲音频片段中的拍点相应的拍点数量等级。
对于目标音频,可以基于多个目标音频片段各自的拍点数量等级,获取到目标音频在不同播放进度下的拍点数量等级;对于候选歌曲音频,也可以基于多个候选歌曲音频片段各自的拍点数量等级,获取到候选歌曲音频片段在不同播放进度下的拍点数量等级。
在本实施例中,一方面,通过将目标音频和候选歌曲音频分别划分预设时长的多个音频片段,使得后续可以比对同一时长内拍点的拍点数量等级,提高拍点数量等级的可比性,另一方面,通过确定每个音频片段的拍点数量等级,可以精细化地度量目标音频和候选歌曲音频在不同时间片段下拍点的疏密程度,从而可以有效增加最终确定的等级差异的准确性。
相应地,在获取到每个目标音频片段和每个候选歌曲音频片段的拍点数量等级后,如图2所示,S103获取目标音频的拍点数量等级与候选歌曲音频的拍点数量等级的等级差异,可以包括如下步骤:
S201,确定每个目标音频片段的拍点数量等级以及对应的每个候选歌曲音频片段的拍点数量等级的片段等级差异。
具体地,目标音频的每个目标音频片段,可以在候选歌曲音频中确定出与该目标音频片段相对应的候选歌曲音频片段,例如可以将时间进度与一目标音频片段匹配的候选歌曲音频片段,作为该目标音频片段对应的候选歌曲音频片段。
进而在获取到每个目标音频片段的拍点数量等级和每个候选歌曲音频片段的拍点数量等级后,针对每个目标音频片段,可以获取该目标音频片段的拍点数量等级与对应的候选歌曲音频片段的拍点数量等级之间的等级差异,作为片段级别的拍点数量等级差异,该等级差异可以称为片段等级差异。
S202,根据多个片段等级差异,确定目标音频和候选歌曲音频的拍点数量等级的等级差异。
在得到多个片段等级差异后,可以综合多个片段等级差异确定目标音频和候选歌曲音频的拍点数量等级的等级差异。具体例如,可以对多个片段等级差异求和,并将求和结果作为目标音频和候选歌曲音频的拍点数量等级的等级差异。例如,对于15s的目标音频和候选歌曲音频,可以按照3s的预设时长进行划分,分别得到5个音频片段。若目标音频的各个目标音频片段的拍点数量等级依次为3、0、4、2、1,而候选歌曲音频的各个候选歌曲音频片段的拍点数量等级依次为1、0、3、1、2,则等级差异为2+0+1+1+1=5。当然,在另外一些实施例中,也可以在多个片段等级差异中,将最大的片段等级差异作为目标音频和候选歌曲音频的等级差异,当最大的片段等级差异大于预设差异阈值时,则不将候选歌曲音频作为原唱歌曲音频召回。
在本实施例中,能够精细化地确定目标音频和候选歌曲音频在不同音频片段的片段等级差异,提升目标音频和候选歌曲音频各自拍点数量等级的可比性,增加最终获取音频之间的等级差异结果的准确性。
在一个实施例中,S102确定目标音频中的拍点相应的拍点数量等级,以及,确定候选歌曲音频中的拍点相应的拍点数量等级,可以包括如下步骤:
将目标音频对应的音频特征输入到训练好的拍点信息识别模型,得到拍点信息识别模型输出的目标音频的拍点数量等级;以及,将候选歌曲音频对应的音频特征输入到拍点信息识别模型,得到拍点信息识别模型输出的候选歌曲音频的拍点数量等级。
示例性地,目标音频和/或候选歌曲音频的音频特征可以包括以下至少一种:MFCC(梅尔频率倒谱系数,Mel Frequency Cepstrum Coefficient)特征、基于CQT算法(指中心频率按指数规律分布,滤波带宽不同、但中心频率与带宽比为常量Q的滤波器组)提取的CQT特征、HPCP(声音级轮廓,Harmonic Pitch Class Profile)特征。
具体实现中,可以预先训练拍点信息识别模型,该拍点信息识别模型可以是基于具有拍点数量等级的多个音频训练得到的。
在获取到目标音频和候选歌曲音频后,针对目标音频,可以获取目标音频的音频特征并输入到拍点信息识别模型,由该模型基于输入的目标音频的音频特征确定出目标音频的拍点数量等级;相应地,针对候选歌曲音频,可以将候选歌曲音频的音频特征输入到拍点信息识别模型,获取拍点信息识别模型输出的拍点数量等级。通过将目标音频和候选歌曲音频各自的音频特征输入到拍点信息识别模型,可以快速获取到各自的拍点数量等级。
在一个实施例中,如图3所示,拍点信息识别模型可以通过如下步骤训练得到:
S301,获取包含说话人语料音频和/或噪声音频的多个样本音频。
实际应用中,可以获取用于训练拍点信息识别模型的多个样本音频,多个样本音频中除了包括歌曲音频,还包括了说话人语料音频或噪声音频,其中,说话人语料音频中包含与歌曲内容无关的说话声或对话内容,噪声音频可以包含无序的、不具有旋律节奏的噪声。
S302,基于多个样本音频和每个样本音频的拍点数量等级标签,对待训练的拍点信息识别模型进行监督训练。
作为一示例,待训练的拍点信息识别模型可以是神经网络模型,例如resnet卷积神经网络。
在得到多个样本音频后,可以预先标注每个样本音频对应的拍点数量等级,并将标注的拍点数量等级作为对应样本音频的拍点数量等级标签。进而可以利用多个样本音频和各个样本音频的拍点数量等级标签,对拍点信息识别模型进行监督训练,具体例如,在将样本音频的音频特征输入到待训练的拍点信息识别模型后,可以确定拍点信息识别模型输出的预测拍点数量等级与预设的拍点数量等级标签之间的差异值,并根据该差异值调整拍点信息识别模型的模型参数。
S303,在满足训练结束条件时,得到训练好的拍点信息识别模型。
在满足训练结束条件时,例如模型迭代次数达到预设次数或者由模型输出的预测拍点数量等级与预设的拍点数量等级标签之间的差异值小于阈值时,则可以将当前的拍点信息识别模型作为训练好的拍点信息识别模型。
在本实施例中,通过将与歌曲内容无关的说话人语料音频或噪声音频作为样本音频,对拍点信息识别模型进行监督训练,能够使模型准确识别出歌曲音频或者与歌曲无关的人声、噪声的拍点数量等级。
在一个实施例中,如图4所示,S101获取对目标音频进行歌曲匹配后得到的候选歌曲音频,可以包括如下步骤:
S401,确定目标音频的歌词,并确定目标音频的歌词与音频库中各个歌曲音频的歌词的歌词相似度。
具体实现中,在得到目标音频后,可以获取目标音频的音频特征,例如MFCC特征,进而可以将目标音频的音频特征输入到训练好的歌声识别模型,获取到歌声识别模型输出的歌词识别结果,得到目标音频的歌词。
在获取到目标音频的歌词后,可以在音频库中对识别出的歌词进行检索,确定目标音频的歌词与音频库中各个歌曲音频歌词的歌词相似度,具体地,可以获取目标音频的歌词与音频库中每首歌曲音频的歌词的编辑距离,通过该编辑距离确定出目标音频的歌词与其他歌词的歌词相似度。其中,编辑距离指的是在两个单词
S402,若存在歌词相似度最大且大于第一相似度阈值的歌曲音频,则将该歌曲音频确定为目标音频的候选歌曲音频。
在得到多个歌词相似度后,可以确定最大的歌词相似度,并判断最大的歌词相似度是否也大于预设的第一相似度阈值;示例性地,若以编辑距离作为歌词相似度,则可以判断编辑距离是否小于预设的编辑距离阈值。若是,则可以将该歌曲音频确定为目标音频的候选歌曲音频。
在本实施例中,在获取到目标音频后,可以通过匹配难度低且精度高的歌词匹配,获取歌词内容与目标音频关联的候选歌曲音频,后续可以结合拍点数量等级差异识别的兜底策略,对歌词匹配的候选歌曲音频作进一步识别,在确保原唱歌曲查找速度的同时,能够剔除目标音频中无关人声带来的干扰,确保召回结果的准确性。
在一个实施例中,在确定歌词信息与音频库中多个歌曲音频的歌词的歌词相似度之后,还可以包括如下步骤:
若目标音频的歌词与音频库中各个歌曲音频的歌词的歌词相似度均小于第一相似度阈值,则确定目标音频的旋律与音频库中各个歌曲音频的旋律的旋律相似度;若存在旋律相似度最大且大于第二相似度阈值的歌曲音频,则将该歌曲音频确定为目标音频的候选歌曲音频。
在获取到目标音频的歌词与各个歌曲音频的歌词的歌词相似度后,若各个歌词相似度均小于第一相似度阈值,则可以确定歌词匹配的置信度低,目标音频的歌词与各个歌曲音频的歌词未能匹配上,进而可以获取目标音频的旋律与音频库中各个歌曲音频的旋律的旋律相似度。
在得到多个旋律相似度后,可以确定最大的旋律相似度,并判断最大的旋律相似度是否大于第二相似度阈值,若是,则可以将该歌曲音频确定为目标音频的候选歌曲音频,若否,则可以确定音频库中的各个歌曲音频均不能与目标音频匹配上,可以返回原唱歌曲召回失败提示。
在本实施例中,可以在歌词匹配失败后进一步利用目标音频的旋律进行歌曲匹配,针对旋律相关的候选歌曲音频,可以结合拍点数量等级差异识别的兜底策略,对旋律匹配的候选歌曲音频作进一步识别,剔除目标音频中的噪声干扰而导致的误召回,确保召回结果的准确性。
在一个实施例中,所述确定目标音频的旋律与所述音频库中各个歌曲音频的旋律的相似度,包括:
获取目标音频的旋律特征,并确定目标音频的旋律特征与音频库中各个歌曲音频的旋律特征的余弦距离;基于余弦距离,确定目标音频的旋律与音频库中各个歌曲音频的旋律的相似度。
实际应用中,可以将目标音频的音频特征输入到旋律特征提取模型,提取到k维的旋律特征(如embedding特征)。
然后,可以将目标音频的旋律特征输入到旋律特征检索库中进行检索,该检索库中可以存储有音频库中各个歌曲音频对应的旋律特征,在检索过程中,可以计算目标音频的旋律特征与检索库中各个旋律特征之间的余弦距离,并基于余弦距离,得到目标音频的旋律与歌曲音频的旋律的旋律相似度,其中,余弦距离与旋律相似度呈负相关。通过计算旋律特征之间的余弦距离,可以快速获取到目标音频与音频库中各个歌曲音频的旋律相似度。
为了使本领域技术人员能够更好地理解上述步骤,以下通过一个例子对本申请实施例加以示例性说明,但应当理解的是,本申请实施例并不限于此。
具体实现中,终端可以向服务器发送针对目标音频的原唱歌曲识别请求,如图5所示,响应于该请求,服务器可以对目标音频进行歌曲匹配,获取目标音频的候选歌曲音频。在歌曲匹配过程中,服务器可以获取目标音频的音频特征,例如可以将目标音频划分为多个目标音频片段,以片段为单位提取MFCC特征,然后,可以将音频特征输入到歌声识别模型,得到模型识别出的目标音频的歌词,并在音频库中检索具有相似或相同歌词的歌曲音频(即图5中的匹配结果1),然后可以在置信度高于阈值的情况下,将该歌曲音频作为候选歌曲音频。若基于歌词匹配得到的歌曲音频的置信度低于阈值,则可以将提取到的音频特征输入到旋律特征提取模型,基于该模型的输出结果得到目标音频的各个目标音频片段的旋律特征(如embedding特征),并基于该旋律特征检索具有相同或相似旋律的歌曲音频(即图5中的匹配结果2),若置信度高于阈值,则可以将该歌曲音频作为候选歌曲音频,否则,可以确定目标音频的原唱歌曲召回失败。
在得到候选歌曲音频后,可以进行切片、音频特征提取后,基于候选歌曲音频的音频特征,确定候选歌曲音频各个候选歌曲音频片段的拍点数量等级(也可以称为拍点级数)。并且,对于目标音频,也可以对目标音频进行切片、音频特征提取处理,得到各个目标音频片段的拍点数量等级,然后可以根据各个候选歌曲音频片段的拍点数量等级和各个目标音频片段的拍点数量等级,确定目标音频和候选歌曲音频的等级差异。
在等级差异小于差异阈值时,可以确定候选歌曲音频为原唱歌曲音频的置信度高于阈值,则可以得到对应的召回结果,其中,基于歌词匹配得到的候选歌曲音频为召回结果1;若基于歌词匹配的候选歌曲音频不为原唱歌曲音频,则可以对基于旋律匹配得到的候选歌曲音频进行相同处理,得到召回结果2,若该候选歌曲音频的置信度仍然低于阈值,则原唱歌曲音频召回失败。
应该理解的是,虽然如上所述的各实施例所涉及的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,如上所述的各实施例所涉及的流程图中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图6所示。该计算机设备包括处理器、存储器、输入/输出接口(Input/Output,简称I/O)和通信接口。其中,处理器、存储器和输入/输出接口通过系统总线连接,通信接口通过输入/输出接口连接到系统总线。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质和内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于存储歌曲音频的音频数据。该计算机设备的输入/输出接口用于处理器与外部设备之间交换信息。该计算机设备的通信接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种音频识别方法。
本领域技术人员可以理解,图6中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现以下步骤:
获取对目标音频进行歌曲匹配后得到的候选歌曲音频;
确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级;
获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异;
若所述等级差异小于预设差异阈值,则将所述候选歌曲音频确定为所述目标音频的原唱歌曲音频;
若所述等级差异大于或等于预设差异阈值,则确定所述目标音频的原唱歌曲音频召回失败。
在一个实施例中,处理器执行计算机程序时还实现上述其他实施例中的步骤。
在一个实施例中,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现以下步骤:
获取对目标音频进行歌曲匹配后得到的候选歌曲音频;
确定所述目标音频中的拍点相应的拍点数量等级,以及,确定所述候选歌曲音频中的拍点相应的拍点数量等级;
获取所述目标音频的拍点数量等级与所述候选歌曲音频的拍点数量等级的等级差异;
若所述等级差异小于预设差异阈值,则将所述候选歌曲音频确定为所述目标音频的原唱歌曲音频;
若所述等级差异大于或等于预设差异阈值,则确定所述目标音频的原唱歌曲音频召回失败。
在一个实施例中,计算机程序被处理器执行时还实现上述其他实施例中的步骤。
需要说明的是,本申请所涉及的用户信息(包括但不限于用户设备信息、用户个人信息等)和数据(包括但不限于用于分析的数据、存储的数据、展示的数据等),均为经用户授权或者经过各方充分授权的信息和数据,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(Read-OnlyMemory,ROM)、磁带、软盘、闪存、光存储器、高密度嵌入式非易失性存储器、阻变存储器(ReRAM)、磁变存储器(Magnetoresistive Random Access Memory,MRAM)、铁电存储器(Ferroelectric Random Access Memory,FRAM)、相变存储器(Phase Change Memory,PCM)、石墨烯存储器等。易失性存储器可包括随机存取存储器(Random Access Memory,RAM)或外部高速缓冲存储器等。作为说明而非局限,RAM可以是多种形式,比如静态随机存取存储器(Static Random Access Memory,SRAM)或动态随机存取存储器(Dynamic RandomAccess Memory,DRAM)等。本申请所提供的各实施例中所涉及的数据库可包括关系型数据库和非关系型数据库中至少一种。非关系型数据库可包括基于区块链的分布式数据库等,不限于此。本申请所提供的各实施例中所涉及的处理器可为通用处理器、中央处理器、图形处理器、数字信号处理器、可编程逻辑器、基于量子计算的数据处理逻辑器等,不限于此。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请的保护范围应以所附权利要求为准。
- 用于管理存储系统的方法、设备和计算机程序产品
- 溯源分析方法、电子设备及计算机程序产品
- 文本分类方法、电子设备及计算机程序产品
- 用于管理存储系统的方法、设备和计算机程序产品
- 用于对象检测的方法、设备和计算机程序产品
- 音频识别方法、计算机设备和计算机程序产品
- 音频敏感内容的识别方法、设备和计算机程序产品