基于共享句法表征的跨领域端到端方面级情感分析方法
文献发布时间:2024-04-18 19:44:28
技术领域
本发明涉及基于共享句法表征的跨领域端到端方面级情感分析方法,属于自然语言处理技术领域。
背景技术
端到端方面级情感分析(E2E-ABSA)通常被定义为有监督的序列标注问题。然而,基于监督学习的模型通常只能在特定的领域上才能取得好的性能,想要拓展到不同领域上使用,最直接的解决办法是在其他领域上额外收集大量数据进行模型训练,然而细粒度的任务增加了标注的难度,通常很难获取未知领域的数据。跨领域方面级情感分析的提出可以根据源域中大量的标记数据,为缺乏标记的目标域训练模型,从而降低标记数据的成本。
单一领域内的方面级情感分析模型已经获得了很好的性能。然而,在真实场景中,往往涉及来自多个领域的数据,来自不同领域的方面术语通常有很大的差异,并且之前训练好的模型可能没有其他领域中常用术语的先验知识。重新收集标记数据是昂贵的,并用这些数据重新训练模型是耗时的。为了降低实现跨领域方面级情感分析任务的成本,现有研究多采用域适应方法实现跨领域情感分析任务。特别的,基于特征的域适应旨在学习方面级情感分析任务的领域无关表征,其核心思想是结构对应学习,使用结构对应可以有效缩小领域之间的差距。
在跨领域情感分析任务中,大多现有工作集中在粗粒度层面,用于预测句子级或文档级的情感极性。相比之下,由于细粒度域适应的困难性,只有少数方法用于跨域方面级情感分析上,现有的大多数研究采用基于特征的域适应来解决跨领域方面级情感分析问题,句法关系作为跨领域细粒度任务的支点,在方面术语和观点术语之间的信息传播中起重要作用,例如Wang和Pan使用领域的句法关系来构建辅助任务,以缩小领域之间的差距。但是现有研究仅考虑了词与词之间的句法关系,忽略了在方面级情感分析任务中,与方面术语句法距离相同的单词不一定同等重要,直接使用初始句法解析结果会导致情感极性预测不够准确。针对以上问题,提出了一种简化句法依存树的方法,缩短方面术语及其对应观点术语之间的句法距离,增强对方面术语和观点术语之间的关联感知能力,获取对跨领域方面级情感分析任务更有效的域不变表征。
发明内容
为了解决上述问题,本发明提供了基于共享句法表征的跨领域端到端方面级情感分析方法,本发明能缩短方面术语及其对应观点术语之间的句法距离,增强对方面术语和观点术语之间的关联感知能力,获取对跨领域方面级情感分析任务更有效的域不变表征。
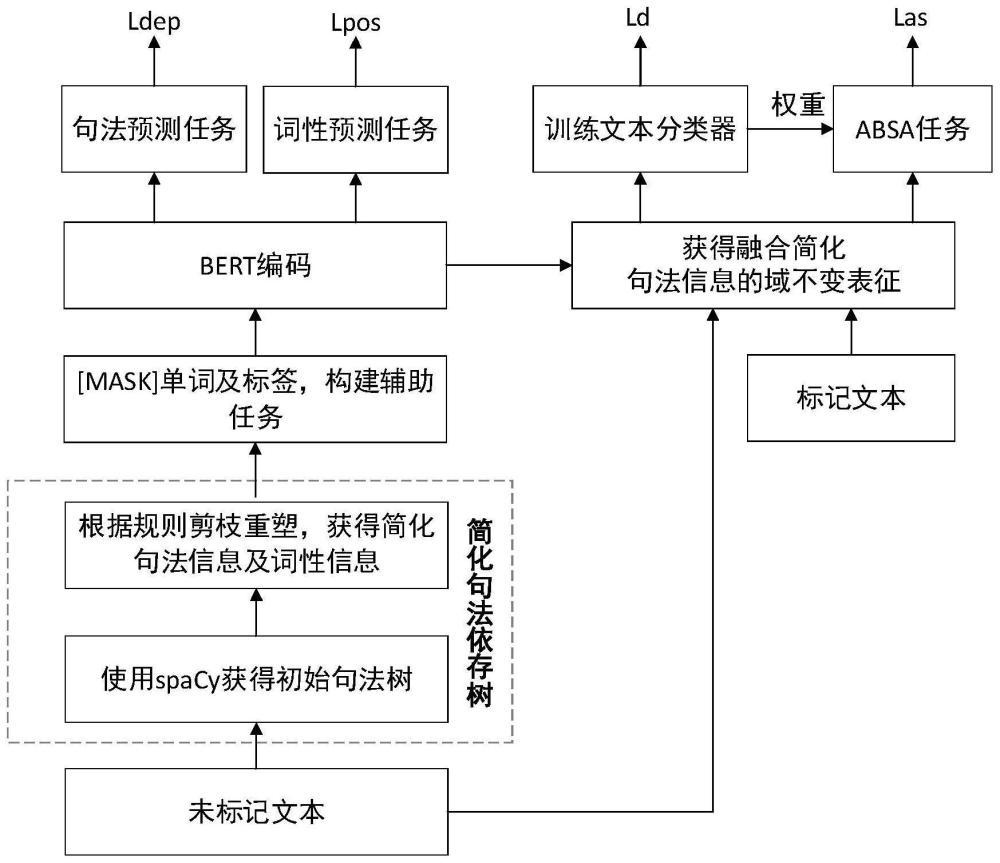
本发明的技术方案是:基于共享句法表征的跨领域端到端方面级情感分析方法,所述方法的具体步骤如下:
步骤1、在源域和目标域的无标记文本W上,使用文本处理工具spaCy获得原始句法依存树G
步骤2、将原始句法依存树G
步骤3、对文本编码,获得融合句法信息的上下文表征H;
步骤4、使用词性和简化句法信息作为自监督信号微调BERT,获得融合句法信息的域不变表征;
步骤5、训练词级分类器,获取词级权重α
步骤6、训练跨领域端到端方面级情感分析模型,利用训练好的模型进行情感分析。
作为本发明的进一步方案,所述步骤2中,将原始句法依存树,利用训练好的模型进行情感分析通过句法规则剪枝重塑,获得简化句法依存树及文本对应的简化句法标签序列和词性标签序列的具体步骤如下:
步骤2.1、对原始句法依存树G
步骤2.2、按照句法规则进行判断,如果核心词和依存词符合规则,则增加核心词父节点到依存词的句法弧,句法关系与核心词及其父节点之间的依存关系相同,同时断开核心词到依存词的句法弧,获得简化句法依存树G
步骤2.3、根据简化句法依存树,将词性标签和简化句法标签分配给句中的每个单词,获得文本对应的词性标签序列P
作为本发明的进一步方案,所述步骤3中,首先将未标记的文本序列转换为包含单词嵌入、段落嵌入、位置嵌入、词性嵌入和简化句法嵌入的连续单词嵌入e,其中单词嵌入、段落嵌入和位置嵌入采用预训练的BERT进行初始化;词性嵌入和简化句法嵌入,分别采用词性标签和简化句法标签作为嵌入矩阵被随机初始化,使用来自源域和目标域的未标记数据进行训练。然后通过多层transformer将单词嵌入转化为上下文表征H,计算公式为H=transformer(E)。
作为本发明的进一步方案,所述步骤4中,从未标记文本中选择25%的单词,使用[MASK]同时替换原句中的单词、词性标签和简化句法标签,构造基于掩码的词性预测和句法预测两个辅助任务。
假设被[MASK]的单词为w
然后使用交叉熵损失进行优化,损失函数如下:
其中I(i)是指示函数,如果[MASK]替换则等于1,否则等于0。
同样的,假设被[MASK]的单词为w
最终的句法依存表征为
句法预测任务中对应句法标签采用以下公式进行预测:
然后采用交叉熵损失进行优化,损失函数如下:
其中I(j)是指示函数,如果[MASK]替换则等于1,否则等于0。
通过句法标签预测和词性预测两个辅助任务,执行基于特征的领域适应L
作为本发明的进一步方案,所述步骤5中,训练词级分类器获得每个单词的领域分布,其损失函数为L
方面级情感分析任务的整体损失L
作为本发明的进一步方案,所述步骤6中,以多任务学习的方式对词性预测和句法预测两个辅助任务和方面级情感分析任务联合训练,L=L
所述步骤2将原始句法依存树通过句法规则将其剪枝重塑以缩短方面术语与观点术语之间的句法距离,然后将词性标签和简化句法标签分配给句中的每个单词,以便学习更有利于跨领域方面级情感分析任务的域不变表征。
本发明可以通过对数据集进行统计分析总结出句法规则,并依据句法规则对原始句法依存树进行剪枝重塑。
本发明的有益效果是:
1、本发明使用了文本处理工具,根据任务简化了句法树,捕捉方面和感知方面的观点术语之间的直接关联,消除句法距离,建立简化句法的域不变结构。
2、本发明通过构建词性预测和句法预测辅助任务获取融合句法信息的域不变表征,同时采用词级加权进一步缩短不同领域之间的差异,这有助于模型实现跨领域端到端方面级情感分析任务,为缺乏标签的目标域进行方面级情感分析提供技术支持。
附图说明
图1是本发明的总体流程图;
图2是举例说明句法依存树简化前后,句法树结构的变化及单词对应句法标签的变化的示意图。
具体实施方式
实施例1:如图1-图2所示,基于共享句法表征的跨领域端到端方面级情感分析方法,包括:
步骤1:获取原始句法依存树。在源域和目标域的无标记文本W={w
步骤2:简化句法依存树。首先,统计分析大量数据,总结句法规则;然后对原始句法依存树从根节点开始遍历,得到带有句法和词性信息的、连接核心词到依存词的句法弧;然后,按照句法规则进行判断,如果核心词和依存词符合规则,则增加从核心词父节点到依存词的句法弧,句法关系与核心词及其父节点之间的依存关系相同,同时断开核心词到依存词的句法弧,获得简化句法依存树G′
步骤3:文本编码。首先,将未标记的文本序列转换为连续单词嵌入e={e
步骤4、构建词性预测和句法预测辅助任务。从未标记文本中选择25%的单词,使用[MASK]同时替换原句中的单词、词性标签和简化句法标签,构造基于掩码的词性预测和句法预测两个辅助任务。假设被[MASK]的单词为w
其中W
然后使用交叉熵损失进行优化,损失函数如下:
其中I(i)是指示函数,如果[MASK]替换则等于1,否则等于0。
同样的,假设被[MASK]的单词为w
最终的句法依存表征为
采用softmax预测w
然后采用交叉熵损失进行优化,损失函数如下:
其中I(j)是指示函数,如果[MASK]替换则等于1,否则等于0。
通过句法标签预测和词性预测两个辅助任务,执行基于特征的领域适应L
步骤5、获取词级权重。使用源域和目标域中未标记的数据训练词级分类器,获得单词领域分布概率,分布概率及损失函数计算过程如下
使用目标域概率与源域概率的比值
方面级情感分析任务的整体损失L
步骤6、模型训练。在目标测试实例上进行预测,得到跨领域方面级情感分析的结果。首先,通过句法标签预测和词性预测两个辅助任务,执行基于特征的领域适应L
对数据集进行了大量的分析,总结句法规则,如表1所示:
表1为句法规则总结
A代表单个词构成的方面术语;O代表单个词构成的观点术语;W表示多个词构成的方面术语中的某个词。
选择Laptop、Restaurant、Device和Service四个领域的数据集构建十个从源域到目标域的转移对。对于BERT,采用了BERT-base-uncased模型,微调所有的BERT层,使用Adam进行优化,batch size设置为32,学习率设置为3·10
在现存的深度学习框架中,选择与任务相关且具有代表性的跨领域模型作为基线对比,对比结果如表2所示:
表2为跨领域端到端方面级情感分析任务的比较结果
其中包含的基线模型有Heir-Joint以及RNSCN,AD-SAL,BERT-base,BERT-DANN,BERT-UDA,AHF。显然本发明提出的方法在所有数据集下,相对于所有的基线模型,在四个数据集构成的十个转移对上,平均Micro-F1值取得了最优结果为38.58%,与AHF模型相比提升了0.92%。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以再不脱离本发明宗旨前提下做出各种措施进行改变。
- 一种结合重构句法信息的端到端方面级情感分析方法
- 一种结合重构句法信息的端到端方面级情感分析方法