迭代式数据获取方法
文献发布时间:2023-06-19 10:32:14
技术领域
本发明属于数据处理技术领域,具体涉及一种迭代式数据获取方法。
背景技术
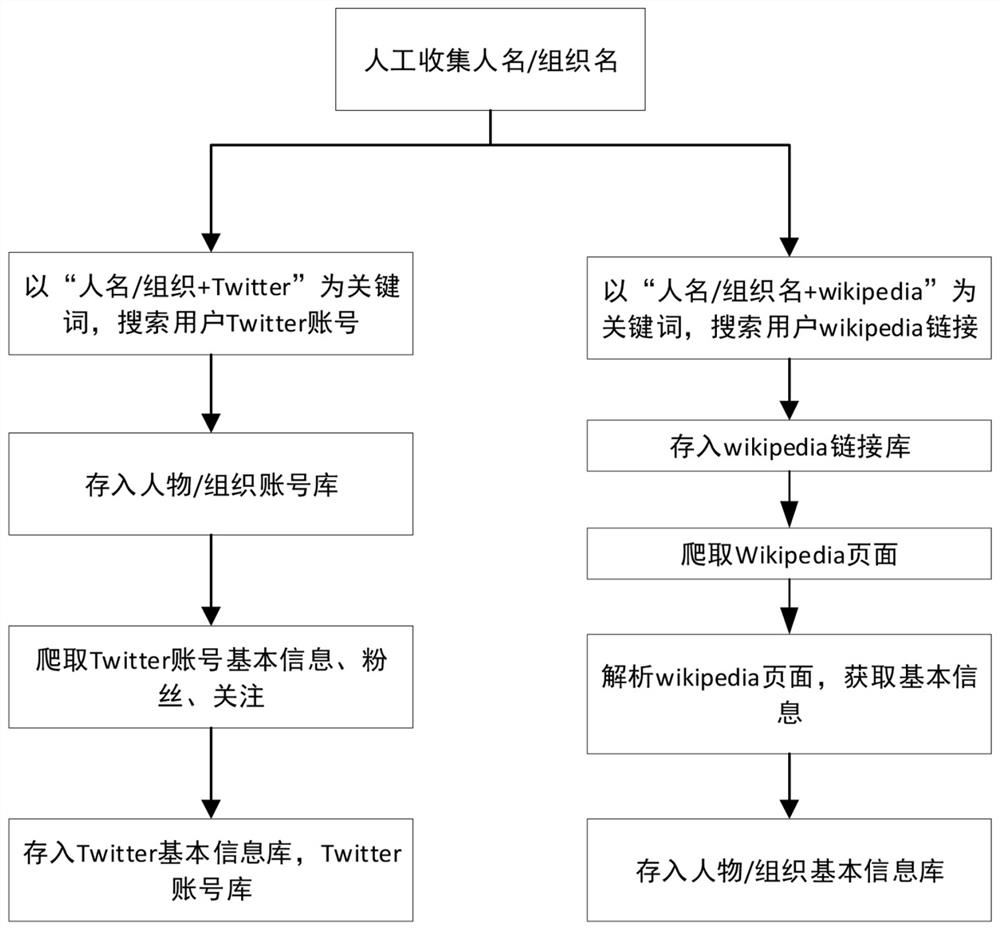
构建以人物、组织、社交账号为核心的知识图谱需要收集大量的人物/组织基本信息、人物/组织对应的社交账号以及这些社交账号之间的关系数据。目前这项工作主要靠人工找到一批人名/组织名,然后以”人名/组织名+Twitter”为关键字,输入搜索引擎搜索框中,找到人物/组织对应的Twitter账号,再使用爬虫技术获取Twitter账号的基本信息以及Twitter账号的粉丝与关注。同时,以“人名/组织名+Wikipedia”为关键字,输入搜索引擎搜索框中,找到人物/组织对应的Wikipedia页面链接,通过爬虫获取Wikipedia页面信息,再对Wikipedia页面的Infobox信息进行解析,得到人物/组织基本信息。整体流程如图1所示:
面向人物/组织以及社交账号信息的收集,现有技术方案主要利用人物/组织名来检索Twitter账号以及人物基本信息。而构建以人物、组织、社交账号为核心的知识图谱,需要百万级别的人物、组织,这就需要人工搜集大量人名/组织名。现有方案不仅耗费人工且收集的速度较慢。
发明内容
针对面向人物/组织以及社交账号信息的收集过程存在的耗费人工且收集的速度较慢问题,本发明提供一种“由人找社交账号”和“由社交账号找人”两种方式结合,迭代式收集人物、组织、社交账号信息的方法。
本发明解决其技术问题所采用的方案是:一种迭代式数据获取方法,该方法包括以下步骤:
第一步:获取种子人物、组织。
从官方网站,人工收集一些人物姓名、组织名称等,作为种子数据,存入种子数据库表。种子数据库表字段包括:人物/组织ID,人物/组织名称。
第二步:通过爬取网页获取人物、组织的社交账号。
通过Senlenium调用谷歌搜索引擎驱动,模拟谷歌搜索。以种子数据库表中的人名姓名/组织名称+“Twitter”为搜索词,爬取搜索页面。由于Google已经对搜索的结果进行排序,搜索结果靠前的匹配的可能性较大,为保障正确率,只取第一条结果进行匹配。使用正则表达式匹配爬取数据的第一条信息,获取到人物/组织的Twitter账号。若匹配到结果,则存入人物组织社交账号表,没有匹配到则爬取下一个人物/组织。人物组织社交账号表包含字段:ID、人物/组织名称、社交账号ID、社交账号名称。
第三步:通过Twitter爬取程序,获取社交账号的基本信息,以及社交账号的粉丝和关注。
调用Twitter开放的爬取API,获取Twitter账号的基本信息,存入Twitter信息表。Twitter信息表的字段包括:Twitter ID,Twitter昵称,Twitter用户名称,Twitter用户注册时间,Twitter用户简介,Twitter用户位置,Twitter用户发文数,Twitter用户关注数,Twitter用户粉丝数。
通过Twitter开放的爬取API,获取Twitter账号的关注与粉丝,存入Twitter关系表。Twitter关系表的字段包括:Twitter用户ID,Twitter用户关注ID。
第四步:从Twitter信息表中筛选Twitter用户粉丝数大于nk的用户,存入重点账号库表。重点账号库表字段包括:重点账号ID,重点账号Twitter ID。
第五步:通过爬取网页,获取人物、组织的Wikipedia页面URL。
从重点账号库表,获取一条数据。以人物/组织Twitter账号名称+“Wikipedia”为搜索词,爬取搜索页面。通过正则表达式匹配爬取页面的第一条信息,获取人物组织或者账号对应的人物组织的Wikipedia页面链接。若匹配结果不为空,则将结果存入人物/组织Wikipedia链接库表,否则爬取下一个。Wikipedia链接库表字段包括:人物/组织/账号ID,人物/组织/账号名称,Wikipedia链接URL。
同时,若匹配到Twitter账号对应的Wikipedia页面链接,则继续爬取该Twitter账号对应的粉丝与关注,存入Twitter账号基本信息库以及Twitter账号关系库。
第六步:从Wikipedia链接库中读取Wikipedia链接URL。再根据获取的URL,爬取wikipedia页面,得到人物、组织的详细信息。
根据Wikipedia页面链接爬取该人物/组织的Wikipedia页面,解析Wikipedia页面Infobox里面的信息,得到该人物组织的详细信息。存入人物组织基本信息库。人物/组织基本信息库字段包括:人物/组织ID、英文名称、中文名称、人物简介、住址、学历、职位、国籍、邮箱、官方网站。
循环迭代以上步骤,直至重点账号库中无新增的社交账号。
本发明的有益效果:
本发明提出的迭代式的信息收集方法,首先人工收集少量的人名/组织名,找到这些人物/组织的基本信息、Twitter账号以及Twitter账号的粉丝与关注,再将爬取到的Twitter账号中粉丝数较多的用户,通过社交账号来的检索人的基本信息,迭代以上步骤。本发明迭代式数据获取方法通过将“由人找社交账号”和“由社交账号找人”两种方式结合,迭代式收集人物、组织、社交账号信息,提高了收集速度,减少了人力,该方法可以在较短时间内收集大量的数据,满足构建知识图谱的数据需要。
附图说明
图1现有信息搜集方案。
图2本发明的迭代式信息收集整体流程。
图3以“名称+Twitter”为关键词爬取用户账号页面示例。
图4以“名称+Wikipedia”获取Wikipedia页面URL示例。
具体实施方式
发明技术方案中中涉及的技术词如下。
Selenium:Selenium是一个用于Web应用程序测试的工具。Selenium可以通过程序调用浏览器的驱动,来模拟用户在浏览器的操作操作。
Wikipedia:维基百科,是一种用多种语言编写的网络百科全书。
Wikipedia infobox:维基百科页面中的信息框,内含丰富的结构化信息。
实施例1:本实施例的整体流程如图2所示,包括以下过程。
首先,获取种子人物、组织名称。
从官方网站如企业官网、学校官网,人工收集一些人物姓名、组织名称等,作为种子数据,存入种子数据库表。种子数据库表字段包括:人物/组织ID,人物/组织名称。例如,进入苹果官网
其次:通过爬取网页获取人物、组织的社交账号。
通过Senlenium调用谷歌搜索引擎驱动,模拟谷歌搜索。以种子数据库表重中的人名姓名/组织名称+“Twitter”为搜索词,如“Tim Cook Twitter”,爬取搜索页面。由于Google已经对搜索的结果进行排序,搜索结果靠前的匹配的可能性较大,为保障正确率,只取第一条结果进行匹配。使用正则表达式(re= 然后:通过Twitter爬取程序,获取社交账号的基本信息,以及社交账号的粉丝和关注。 调用Twitter开放的爬取API,获取Twitter账号的基本信息,存入Twitter信息表。Twitter信息表的字段包括:Twitter ID,Twitter昵称,Twitter用户名称,Twitter用户注册时间,Twitter用户简介,Twitter用户位置,Twitter用户发文数,Twitter用户关注数,Twitter用户粉丝数。 通过Twitter开放的爬取API,获取Twitter账号的关注与粉丝,存入Twitter关系表。Twitter关系表的字段包括:Twitter用户ID,Twitter用户关注ID。 继续:从Twitter信息表中筛选Twitter用户粉丝数大于2000的用户,存入重点账号库表。重点账号库表字段包括:重点账号ID,重点账号Twitter ID。 然后,通过爬取网页,获取人物、组织的Wikipedia页面URL。 从重点账号库表,获取一条数据。以人物/组织Twitter账号名称+“Wikipedia”为搜索词,如“Kobe Bryant Wikipedia”,爬取搜索页面。通过正则表达式(re=(
同时,若匹配到Twitter账号对应的Wikipedia页面链接,则继续爬取该Twitter账号对应的粉丝与关注,存入Twitter账号基本信息库以及Twitter账号关系库。
然后,从Wikipedia链接库中读取Wikipedia链接URL。
根据Wikipedia页面链接爬取该人物/组织的Wikipedia页面,解析Wikipedia页面Infobox里面的信息,得到该人物组织的详细信息。存入人物组织基本信息库。人物/组织基本信息库字段包括:人物/组织ID、英文名称、中文名称、人物简介、住址、学历、职位、国籍、邮箱、官方网站。
循环迭代以上步骤,直至重点账号库中无新增的社交账号。从而将“由人找社交账号”和“由社交账号找人”两种方式结合,迭代式收集人物、组织、社交账号信息,提高收集速度,减少人力。
实施例2:迭代式数据获取方法,首先建立种子数据库,并读取种子数据名称,根据读取的种子数据名称通过爬取谷歌:名称+“”+Twitter,使用正则表达式匹配爬取数据的第一条信息,获取到人物/组织的Twitter账号。若没匹配到结果,重复爬取谷歌至到匹配到结果后存入人物组织社交账号库,多次匹配后若始终没有匹配到结果,则爬取下一个人物/组织。
读取已经存入人物/组织账号库的人物/组织账号,并爬取账号基本信息、粉丝和关注。存入Twitter基本信息库,Twitter关系库,若账号粉丝数大于2000,同时存入Twitter重点账号库。
基于以上过程,若重点账号库有新增数据时,则读取重点账号名称,然后爬取谷歌:名称+“”+wikipedia,使用正则表达式匹配爬取数据的第一条信息,获取人物组织或者账号对应的人物组织的Wikipedia页面链接。若没匹配到结果,重复爬取谷歌至到匹配到结果后存入wikipedia链接库,多次匹配后若始终没有匹配到结果则爬取下一个人物组织的Wikipedia页面链接。
然后从Wikipedia链接库中读取Wikipedia链接URL,爬取wikipedia页面,进而解析wikipedia infobox内信息,存入人物/组织基本信息库。
上述使用正则表达式匹配爬取数据的第一条信息,获取人物组织或者账号对应的人物组织的Wikipedia页面链接后,爬取账号基本信息、粉丝和关注。存入Twitter基本信息库,Twitter关系库,若账号粉丝数大于2000,同时存入Twitter重点账号库。
- 迭代式数据获取方法
- 一种植入式控制系统数据获取装置及数据获取方法