基于模型融合的件量预测方法、装置、设备及存储介质
文献发布时间:2023-06-19 10:58:46
技术领域
本发明涉及快递技术领域,具体涉及一种基于模型融合的件量预测方法、装置、设备及存储介质。
背景技术
随着物流行业的快速发展,业务量(快递件量)的管控关系着物流公司的业务能否正常进行。因此,对件量进行预测就显得尤为重要。
目前,快递行业内对件量的预测仍存在以下缺陷:
1、快递行业件量波动较大,难以预测,误差较大,会影响工作人员、车辆等资源的不足与浪费;
2、快递行业件量预测需求较多,件量预测影响快递各环节的效率;
3、快递行业的件量预测不仅受近期、同期、周期、天气、经济环境等影响,还受各预测模型影响,件量预测准确性较低。
发明内容
为解决快递技术领域中快递件量准确预测的问题,本申请提供一种基于模型融合的件量预测方法、装置、设备及存储介质,通过将各预测模型进行融合以对快递件量进行预测,提高预测准确率。
本发明技术方案如下:
本发明提供一种件量预测融合模型生成方法,包括步骤:
获取件量的历史数据,对所述历史数据进行预处理并筛选出目标件量数据信息;
根据所述目标件量数据信息构建多种预测模型,并使用多种模型融合方法中的任一种模型融合方法融合各种预测模型,从而构成用于预测快递件量的多种件量预测融合模型;
采用各种件量预测融合模型分别进行件量预测,并根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,筛选误差最小的件量预测融合模型作为目标件量预测融合模型;
根据筛选的所述目标件量预测融合模型进行件量预测。
进一步优选的,所述预测模型包括定性预测模型、时间序列预测模型、面板数据预测模型、小波分析预测模型、LSTM预测模型中的多种,所述模型融合方法包括投票方法、平均方法、Bagging方法和Boosting方法中的多种。
进一步优选的,所述采用各种件量预测融合模型进行件量预测包括件量的数量的预测及件量的预测指标的预测。
进一步优选的,所述预测指标包括近期因素、同期因素和周期因素,其中,所述近期因素包括近期件量、近期件量平滑值、近期周平均值,所述同期因素包括历史年度中同期件量指标,所述周期因素包括历史周中同一天的件量、历史月中同一天的件量、历史季度中同一天的件量、历史年度中同一天的件量。
进一步优选的,所述根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,具体包括计算件量预测误差值、件量预测误差率、模型误差、测量误差、截断误差和舍入误差中的任一种或多种误差信息。
进一步优选的,所述件量预测误差值和件量预测误差率的计算过程是:
根据实际件量的数量和预测件量的数量计算件量预测误差值;
利用件量预测融合模型进行多次件量预测,根据多次件量预测的数值计算件量预测误差率。
进一步优选的,所述对所述历史数据进行预处理包括:清洗历史数据、替换空数据及处理异常数据。
本发明还提供一种基于模型融合的件量预测装置,包括:
数据处理模块,用于获取件量的历史数据,对所述历史数据进行预处理并筛选出目标件量数据信息;
模型融合创建模块,用于根据所述目标件量数据信息构建多种预测模型,并使用多种模型融合方法中的任一种模型融合方法融合各种预测模型,从而构成用于预测快递件量的多种件量预测融合模型;
模型融合筛选模块,用于采用各种件量预测融合模型分别进行件量预测,并根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,筛选误差最小的件量预测融合模型作为目标件量预测融合模型;
件量预测模块,用于基于所述目标件量预测融合模型进行件量预测。
本发明还提供一种基于模型融合的件量预测设备,包括处理器和存储器,所述存储器中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或所述指令集由所述处理器加载并执行以实现上所述的件量预测方法。
本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述的件量预测方法。
依据上述实施例的件量预测方法、装置、终端设备及存储介质,通过采用模型融合方法将各种预测模型融合后形成件量预测融合模型,并通过筛选获取最佳的件量预测融合模型对快递的件量进行最佳预测,与当前物流行业主要采用人工预测或粗略的方法来预测快递的件量相比,本申请提供的件量预测融合模型可以极大地提高件量的预测准确率,进一步,为物流工作的有序开展提供有力的数据基础,例如,基于预测的件量可以提前做好工作人员、车辆的准备,从而达到降低成本,减少损失的效果。
附图说明
图1为件量预测方法流程图;
图2为件量预测装置原理图;
图3为件量预测设备原理图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。
实施例一:
本实施例提供一种基于模型融合的件量预测方法,其流程图如图1所示,具体包括如下步骤。
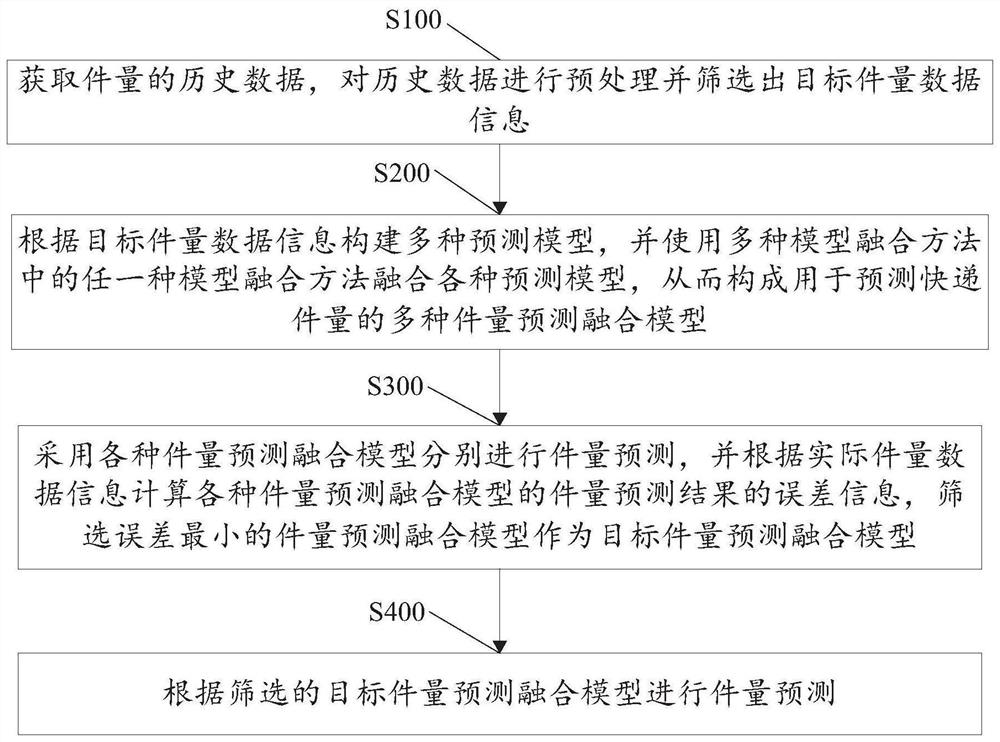
S100:获取件量的历史数据,对历史数据进行预处理并筛选出目标件量数据信息。
S200:根据目标件量数据信息构建多种预测模型,并使用多种模型融合方法中的任一种模型融合方法融合各种预测模型,从而构成用于预测快递件量的多种件量预测融合模型。
S300:采用各种件量预测融合模型分别进行件量预测,并根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,筛选误差最小的件量预测融合模型作为目标件量预测融合模型。
S400:根据筛选的目标件量预测融合模型进行件量预测。
下面对上述步骤S100-S400进行具体说明。
在步骤S100中,获取件量的历史数据,对历史数据进行预处理并筛选出目标件量数据信息,其中,件量的历史数据是指物流行业中存储的件量数据,也可以是某统计机构公布的某段时间内物流行业中件量的数据。件量包含收件量,也可以包含发件量,还可以包含收件量和发件量。在数据库中,无论是线上还是线下,均会存储派件量、收件量的信息。该些信息可以但不限于包含:件量的类型、时间。时间可以是按天存储,也可以是按照周存储,也可以按照录入系统的具体时间存储。
对获取的历史数据进行预处理,包括:清洗历史数据,替换空数据及处理异常数据;其中,清洗历史数据,去除获取的历史数据中不需要的信息及替换异常数据。通常在对数据进行统计分析之前,需要将一些不规则数据滤除掉,以确保分析的准确性。数据清洗是一个减少数据错误与不一致性的过程,主要是检测并删除或改正不规则数据。
在本实施例中,主要是针对件量进行预测,因此可以去除历史数据中包含的单号信息及地址信息。在这些历史数据中,可能会出现空数据或数值异常(如非数值表示)的数据,将这些空数据或数值异常的数据用其相邻的数据替换。
具体地,历史数据包含收件量和/或发件量,可以根据不同的业务场景从数据库中调取各网点收件量(有订单、无订单)和派件量的信息,下面将以某网点的收件量为测试数据,历史数据所在日期为2017年-2020年期间的揽件量,获得的历史数据经过数据清洗后可以如下表1所示。
表1
异常数据处理的方式可以是删除法、替代法(连续变量均值替代、离散变量用众数以及及中位数替代)、插补法(回归插补、多重插补),除了直接删除,还可以先将异常值变成缺失值,然后进行缺失值的补齐操作。实际应用中,对于异常值处理,一般划分为NA缺失值或者进行数据修整。
在步骤S200中,根据目标件量数据信息构建多种预测模型,并使用多种模型融合方法中的任一种模型融合方法融合各种预测模型,从而构成用于预测快递件量的多种件量预测融合模型。
其中,预测模型包括定性预测模型、时间序列预测模型、面板数据预测模型、小波分析预测模型、LSTM预测模型中的多种,模型融合方法包括投票方法、平均方法、Bagging方法和Boosting方法、回归方法中的多种。
各预测模型具体描述如下:
定性预测模型是指,所谓的定性预测就是相关人员根据过去的经验、知识和直觉等对件量做出侧预测,无需连续的数据作为支撑,且时效性更强,受主观因素影响较大,所以业务敏感度的提升很有必要。
时间序列预测模型是指,时间序列大量的用于传统的预测中,一般需观察时间序列数据是否具有平稳性与季节性,若数据具有平稳非季节性,一般使用平滑法预测,如简单平均法、移动平均法、指数平滑法。对于季节性数据则使用季节性预测,如季节多元回归模型、季节自回归模型、时间序列分解。而数据是非平稳非季节性的,可以使用趋势预测法,包括线性趋势推测,非线性趋势推测,自回归预测模型。
面板数据预测模型是指,面板数据有时间序列和截面两个,可以克服时间序列分析受多重共线性的困扰,能够提供更多的信息、更多的变化、更少共线性、更多的自由度和更高的估计效率,而面板数据的单位根检验和协整分析是当前最前沿的领域之一。
小波分析预测模型是指,小波分析适用于具有非平稳、非线性和信噪比高的特点时间序列,若采用传统的去噪处理方法往往存在诸多缺陷。而小波理论是根据时频局部化的要求而发展起来的,具有自适应和数学显微镜性质,特别适合非平稳、非线性信号的处理。
LSTM预测模型是指,最近很火的LSTM(长短期记忆网络),是一种时间递归神经网络,能够在更长的序列中有更好的表现,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM准确率较高,内部参数较多,训练难度加大,通常需要的数据较多。而因GRU效果和LSTM相当,参数比LSTM更少,在构建大训练的模型时,也是个不错的选择。
进一步,可以采用不同次指数平滑对上述各预测模型进行指数平滑处理,使处理后的预测模型更平稳,波动更小。
各模型融合方法具体描述如下:
投票方法是一种简单的模型融合方法,假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
平均方法是指,对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6。
Bagging方法是指,Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。Bagging方法大概分为以下过程:
重复K次;
有放回地重复抽样建模;
训练子模型。
Boosting方法是指,Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
回归方法是指,回归分析是一种数学模型。当因变量和自变量为线性关系时,它是一种特殊的线性模型。
最简单的情形是一元线性回归,由大体上有线性关系的一个自变量和一个因变量组成;模型是Y=a+bX+ε(X是自变量,Y是因变量,ε是随机误差)。
通常假定随机误差的均值为0,方差为σ^2(σ^2>0,σ^2与X的值无关)。若进一步假定随机误差遵从正态分布,就叫做正态线性模型。一般的,若有k个自变量和1个因变量,则因变量的值分为两部分:一部分由自变量影响,即表示为它的函数,函数形式已知且含有未知参数;另一部分由其他的未考虑因素和随机性影响,即随机误差。
当函数为参数未知的线性函数时,称为线性回归分析模型;当函数为参数未知的非线性函数时,称为非线性回归分析模型。当自变量个数大于1时称为多元回归,当因变量个数大于1时称为多重回归。
可以将多个模型的预测结果作为自变量,将实际件量作为因变量,建立回归模型。
在步骤S300中,采用各种件量预测融合模型分别进行件量预测,并根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,筛选误差最小的件量预测融合模型作为目标件量预测融合模型。
具体的,采用各种件量预测融合模型进行件量预测包括件量的数量的预测及件量的预测指标的预测,其中,预测指标包括近期因素、同期因素和周期因素。
进一步,近期因素包括近期件量、近期件量平滑值、近期周平均值,同期因素包括历史年度中同期件量指标,周期因素包括历史周中同一天的件量、历史月中同一天的件量、历史季度中同一天的件量、历史年度中同一天的件量。
以指数平滑方法对快递件量的预测指标进行预测为例进行说明。
假设要预测第t天的揽件量为xt,第t-1天的揽件量为xt-1,依次类推,设计预测指标:
进期因素包括以下内容:
1)近期件量:xt-1,xt-2,…,xt-14分别表示前1,2,…,14天件量。
2)近期件量平滑:近3天平均,近5天平均,近7天平均,近10天平均,近14天平均。其中(xt-1+xt-2+xt-3)/3表示近3天平均,依次类推
3)近期周平均:近2-8天平均,近7-14天平均。
同期因素包括以下内容:
同期因素包括历史年度中同期件量指标,例如,计算去年同期指标,如去年的今天lxt。只要将今年时间段的揽件量换成去年同一时间段的揽件量,即可计算近期因素中的所有指标的去年同期指标。
周期因素包括以下内容:
周期因素包括历史周中同一天的件量、历史月中同一天的件量、历史季度中同一天的件量、历史年度中同一天的件量,例如,计算上周同一天,上个月同一天,上个季度同一天,上年同一天件量。
进一步,根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,具体包括计算件量预测误差值、件量预测误差率、模型误差、测量误差、截断误差和舍入误差中的任一种或多种误差信息;其中,件量预测误差值和件量预测误差率的计算过程如下:
预测误差值公式:超出为正,过少为负,其中A表示测量值,E表示正常值。
预测误差率计算方法:
a为第一次测量数据,b为第二次测量数据,c为第三次测量数,d为第四次测量数据,e为第五次测量数据
(a+b+c+d+e)/5=平均值
平均值/100=平均值的百分比。
上述的模型误差是指:在建立数学模型过程中,要将复杂的现象抽象归结为数学模型,往往要忽略一些次要因素的影响,对问题作一些简化。因此数学模型和实际问题有一定的误差,这种误差称为模型误差。
上述的测量误差是指:在建模和具体运算过程中所用的数据往往是通过观察和测量得到的,由于精度的限制,这些数据一般是近似的,即有误差,这种误差称为测量误差。
上述的截断误差是指:由于实际运算只能完成有限项或有限步运算,因此要将有些需用极限或无穷过程进行的运算有限化,对无穷过程进行截断,这样产生的误差成为截断误差。
上述的舍入误差是指:在数值计算过程中,由于计算工具的限制,往往对一些数进行四舍五入,只保留前几位数作为该数的近似值,这种由舍入产生的误差成为舍入误差。
通过上述计算的任一种或多各误差,筛选误差最小的件量预测融合模型作为目标件量预测融合模型,例如,可以根据件量预测误差值和件量预测误差率筛选对应的件量预测融合模型,该件量预测融合模型对应的预测模型为小波分析预测模型,对应的模型融合方法为平均方法,再例如,还可以根据模型误差筛选对应的件量预测融合模型,该件量预测融合模型对应的预测模型是面板数据预测模型,对应的模型融合方法为Bagging方法,所以,实际应用中,可根据设计的目标误差筛选出最佳的预测指标、预测模型、模型融合方法,在步骤S400中,根据筛选的预测指标、预测模型、模型融合方法进行件量预测,以提高件量的预测准确率。
通过本实施例提供的件量预测方法,采用模型融合方法将各种预测模型融合后形成件量预测融合模型,并通过筛选获取最佳的件量预测融合模型对快递的件量进行最佳预测,可以极大地提高件量的预测准确率,进一步,为物流工作的有序开展提供有力的数据基础,例如,基于预测的件量可以提前做好工作人员、车辆的准备,从而达到降低成本,减少损失的效果。
实施例二:
基于实施例一,本实施例提供一种件量预测融合模型生成装置,其原理图如图2所示,具体包括数据处理模块100、模型融合创建模块200、模型融合筛选模块300和件量预测模块400。
具体的,数据处理模块100用于获取件量的历史数据,对历史数据进行预处理并筛选出目标件量数据信息。件量的历史数据是指物流行业中存储的件量数据,也可以是某统计机构公布的某段时间内物流行业中件量的数据。件量包含收件量,也可以包含发件量,还可以包含收件量和发件量。
对获取的历史数据进行预处理,包括:清洗历史数据,替换空数据及处理异常数据;其中,清洗历史数据,去除获取的历史数据中不需要的信息及替换异常数据。通常在对数据进行统计分析之前,需要将一些不规则数据滤除掉,以确保分析的准确性。数据清洗是一个减少数据错误与不一致性的过程,主要是检测并删除或改正不规则数据。
在本实施例中,主要是针对件量进行预测,因此可以去除历史数据中包含的单号信息及地址信息。在这些历史数据中,可能会出现空数据或数值异常(如非数值表示)的数据,将这些空数据或数值异常的数据用其相邻的数据替换。
异常数据处理的方式可以是删除法、替代法(连续变量均值替代、离散变量用众数以及中位数替代)、插补法(回归插补、多重插补),除了直接删除,还可以先将异常值变成缺失值,然后进行缺失值的补齐操作。
模型融合创建模块200用于根据目标件量数据信息构建多种预测模型,并使用多种模型融合方法中的任一种模型融合方法融合各种预测模型,从而构成用于预测快递件量的多种件量预测融合模型。
其中,预测模型包括定性预测模型、时间序列预测模型、面板数据预测模型、小波分析预测模型、LSTM预测模型中的多种,模型融合方法包括投票方法、平均方法、Bagging方法和Boosting方法中的多种。各预测模型及融合方法具体请参考实施例一,本实施例不作赘述。
模型融合筛选模块300用于采用各种件量预测融合模型分别进行件量预测,并根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,筛选误差最小的件量预测融合模型作为目标件量预测融合模型。
具体的,采用各种件量预测融合模型进行件量预测包括件量的数量的预测及件量的预测指标的预测,其中,预测指标包括近期因素、同期因素和周期因素。关于近期因素、同期因素和周期因素的描述请参考实施例一,本实施例不作赘述。
进一步,根据实际件量数据信息计算各种件量预测融合模型的件量预测结果的误差信息,具体包括计算件量预测误差值、件量预测误差率、模型误差、测量误差、截断误差和舍入误差中的任一种或多种误差信息;关于件量预测误差值、件量预测误差率、模型误差、测量误差、截断误差和舍入误差的描述请参考实施例一,本实施例不作赘述。
模型融合筛选模块300通过计算的任一种或多各误差,筛选误差最小的件量预测融合模型作为目标件量预测融合模型,例如,可以根据件量预测误差值和件量预测误差率筛选对应的件量预测融合模型,该件量预测融合模型对应的预测模型为小波分析预测模型,对应的模型融合方法为平均方法,再例如,还可以根据模型误差筛选对应的件量预测融合模型,该件量预测融合模型对应的预测模型是面板数据预测模型,对应的模型融合方法为Bagging方法,所以,实际应用中,可根据设计的目标误差筛选出最佳的预测指标、预测模型、模型融合方法。
件量预测模块400用于根据筛选的目标件量预测融合模型进行件量预测,具体的,件量预测模块400根据筛选出最佳的预测指标、预测模型、模型融合方法进行件量预测,以提高件量的预测准确率。
通过本实施例提供的件量预测融合模型生成装置,采用模型融合方法将各种预测模型融合后形成件量预测融合模型,并通过筛选获取最佳的件量预测融合模型对快递的件量进行最佳预测,可以极大地提高件量的预测准确率,进一步,为物流工作的有序开展提供有力的数据基础,例如,基于预测的件量可以提前做好工作人员、车辆的准备,从而达到降低成本,减少损失的效果。
实施例三:
基于实施例一和实施例二,本实施例提供一种基于模型融合的件量预测设备,该设备的原理图如图3所示,该设备500可以是平板电脑、笔记本电脑或台式电脑。设备500还可能被称为便携式终端、膝上型终端、台式终端等其他名称。
通常,设备500包括有处理器5001和存储器5002,处理器5001可以包括一个或多个处理核心,比如4核心处理器、8核心处理器等。处理器5001可以采用DSP(Digital SignalProcessing,数字信号处理)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)、PLA(Programmable Logic Array,可编程逻辑阵列)中的至少一种硬件形式来实现。处理器3001也可以包括主处理器和协处理器,主处理器是用于对在唤醒状态下的数据进行处理的处理器,也称CPU(Central Processing Unit,中央处理器);协处理器是用于对在待机状态下的数据进行处理的低功耗处理器。
在一些实施例中,处理器5001可以在集成有GPU(Graphics Processing Unit,图像处理器),GPU用于负责显示屏所需要显示的内容的渲染和绘制。一些实施例中,处理器5001还可以包括AI(Artificial Intelligence,人工智能)处理器,该AI处理器用于处理有关机器学习的计算操作。
存储器5002可以包括一个或多个计算机可读存储介质,该计算机可读存储介质可以是非暂态的。存储器5002还可包括高速随机存取存储器,以及非易失性存储器,比如一个或多个磁盘存储设备、闪存存储设备。在一些实施例中,存储器5002中的非暂态的计算机可读存储介质用于存储至少一个指令、至少一段程序、代码集或指令集,该至少一条指令、至少一段程序、代码集或指令集用于被处理器5001所执行以实现本申请中实施例一提供的件量预测方法。
因此,本申请的设备500通过至少一条指令、至少一段程序、代码集或指令集执行实施例一提供的件量预测方法,具有的优点是:采用模型融合方法将各种预测模型融合后形成件量预测融合模型,并通过筛选获取最佳的件量预测融合模型对快递的件量进行最佳预测,可以极大地提高件量的预测准确率。
在一些实施例中,设备500还可选包括有:外围设备接口5003和至少一个外围设备。处理器5001、存储器5002和外围设备接口5003之间可以通过总线或信号线相连。各个外围设备可以通过总线、信号线或电路板与外围设备接口5003相连。
具体到本实施例中,为了实现件量预测方法,相应的外围设备包括数据库5004,进一步,处理器5001通过数据库5004可以获取件量历史数据信息,处理器5001根据件量历史数据信息进行相应的预测模型构建、模型融合、件量预测操作。
本发明还提供一种计算机可读存储介质,该计算机可读存储介质可以为非易失性计算机可读存储介质,该计算机可读存储介质也可以为易失性计算机可读存储介质。该计算机可读存储介质中存储有指令,当该指令在计算机上运行时,使得计算机执行实施例一中的件量预测方法。
实施例二中的系统如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-only memory,ROM)、随机存取存储器(Random access memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 基于模型融合的件量预测方法、装置、设备及存储介质
- 基于指数平滑的件量预测方法、装置、设备及存储介质