一种结构化数据的自适应关系建模方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及一种数据处理方法,特别涉及一种结构化数据的自适应关系建模方法,属于人工智能学习预测技术领域。
背景技术
迄今为止,大多数企业都依赖结构化数据进行数据存储和预测分析。关系数据库管理系统(RDBMS)已经成为业界采用的主流数据库系统,关系数据库已经成为实际上存储和查询结构化数据的标准,而结构化数据对大多数业务的操作都是至关重要的。结构化数据中往往包含着大量的信息,这些信息往往可以用于进行数据驱动的决策或是识别风险和机会。从数据中提取见解用于决策需要高级分析,尤其是深度学习,它比统计聚合要复杂得多。
深度神经网络(DNNs)在图像、音频和文本数据方面都取得了突破,像CNNs[Kaiming He,Xiangyu Zhang,Shaoqing Ren,and Jian Sun.2016.Deep residuallearning for image recognition.In Proceedings of the IEEE conference oncomputer vision and pattern recognition.770–778.]和LSTM[Siwei Lai,Liheng Xu,Kang Liu,and Jun Zhao.2015.Recurrent Convolutional Neural Networks for TextClassification.In Proceedings of the Twenty-Ninth AAAI Conference onArtificial Intelligence,.AAAI,2267–2273.]这样的DNNs非常适合于一些特定数据类型,例如,CNNs在图像领域的应用,以及LSTM在序列数据上的应用。使用DNNs的一个主要优势是,DNNs的使用消除了手工特性工程的需要,然而,把DNNs应用到关系表中的结构化数据时,可能不会产生有意义的结果。具体来说,结构化数据的属性值之间存在内在的相关性和依赖性,而这种特性之间的相互作用关系对于预测分析是必不可少的。虽然理论上,只要有足够的数据和容量,DNN可以近似任何目标函数,但传统DNN网络层善于捕获的相互作用是可加性的,因此,要为这样相乘的相互作用建模,就需要过分庞大并且越来越难以理解的模型,这些模型往往由多层叠加而成,层之间还有非线性的激活函数。先前的研究也提出,用DNNs隐式建模这样的交叉特征可能需要大量的隐藏单元,这大大增加了计算成本,并且也使DNNs更加难以解释;如文献Alexandr Andoni,Rina Panigrahy,Gregory Valiant,andLi Zhang.2014.Learning Polynomials with Neural Networks.In Proceedings of the31th International Conference on Machine Learning,ICML.所述。
形式上,结构化数据指的是可以用表格来表示的数据类型。可以看作是一个由n行(元组/样本)m列(属性/特征)组成的逻辑表,它是通过选择、投影和连接等核心关系操作从关系数据库中提取出来的。预测建模是学习依赖属性y对决定属性x的函数依赖性(预测函数),即,f∶x→y。其中x通常称为特征向量,y为预测目标。针对结构化数据进行预测建模的主要挑战实际上是如何通过交叉特征来建模这些属性之间的依赖关系和相关性,即所谓的特征相互作用。这些交叉特征通过捕获原始输入特征的相互作用来创建新特征。具体来说,一个交叉特征可以定义为
在关系分析中,DNNs的首选替代方案是明确地对特征交互进行建模,从而在特征归因方面获得更好的性能和可解释性。然而,可能的特征交互的数量在组合上是很大的。因此,显式交叉特征建模的核心问题是如何识别正确的特征集,同时确定相应的交互权值。大多数现有的研究通过捕获交互阶数限制在预定义的个数范围内的交叉特征来回避这一问题。然而,随着最大阶数的增加,交叉特征的数量仍然接近指数增长。AFN(Weiyu Cheng,Yanyan Shen,and Linpeng Huang.2020.Adaptive Factorization Network:LearningAdaptive-Order Feature Interactions.In 34th AAAI Conference on ArtificialIntelligence.)则更进一步,它利用对数神经元对交叉特征进行建模(J.WesleyHines.1996.A logarithmic neural network architecture for unbounded non-linearfunction approximation.In Proceedings of International Conference on NeuralNetworks(ICNN’96).IEEE,1245–1250.),每个神经元将特征转化为对数空间,从而将多个特征的幂转化为可学习的系数,具体来说,即
我们认为交叉特征应该只考虑某些输入特征,并且,特征相互作用应该动态地对单个输入建模。其基本原理是,并非所有的输入特征对交叉项都是建设性的,使用不相关的特征进行建模可能会引入噪声,从而降低有效性和可解释性。特别是,在实际应用中学习模型的部署不仅强调了准确性,同时还强调了效率和可解释性。值得注意的是,理解学习模型的一般行为和整个逻辑(全局可解释性),并为所做出的特定决策提供理由(局部可解释性)对于高风险应用中的关键决策制定至关重要,如医疗保健或金融行业。尽管许多黑盒模型(如DNNs)具有强大的预测能力,但它们以隐式的方式对输入进行建模,这种方式令人费解,有时还可能学习到一些令人意想不到的模式。就此而言,明确地用最小组成特征集自适应地建模特征关系,会在有效性、效率和可解释性方面提供合理的先验知识。
发明内容
本发明的目的在于针对现有技术的上述部分或全部不足,提供一种结构化数据的自适应关系建模方法,包括以下内容:
使用指数神经元建模所述结构化数据属性间的交叉特征,所述指数神经元为K×o个,其中,K表示注意头的个数,o表示每个注意头的所述指数神经元的数目,K和o都是自然数;每个注意头的所有所述指数神经元共享双线性注意函数的权重矩阵W
每个注意头的第i个所述指数神经元y
其中,i,⊙表示哈达玛积,exp(·)函数和相应的指数w
w
其中,
其中,
作为优选,所述α的取值范围在[1.7,2.0]范围内。。
作为优选,所述n
作为优选,所述K和o均为2
作为优选,将所述K×o个指数神经元的v
作为优选,将所述多个指数神经元的w
另一方面,本发明还提供了一种电子设备,所述电子设备包括:
至少一个处理器;以及,
与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行前述的一种医疗时序数据综合信息提取方法。
另一方面,本发明还提供了一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质存储计算机指令,该计算机指令用于使该计算机执行前述的一种医疗时序数据综合信息提取方法。
另一方面,本发明还提供了一种计算机程序产品,包括存储在非暂态计算机可读存储介质上的计算程序,该计算机程序包括程序指令,当该程序指令被计算机执行时,使该计算机执行前述的一种医疗时序数据综合信息提取方法。
有益效果
与现有技术相比,本发明提出的一种结构化数据的自适应关系建模方法,具有如下特点:
1、本发明提出的指数神经元能够建模任意阶的交叉特征(或称特征相互作用);克服了对数神经元输入必须为正的限制,扩大了输入的取值范围,提升了交叉特征建模的有效性。
2、通过指数神经元以及多头门控注意力机制能够根据输入数据动态并有选择性地建模任意阶的交叉特征,提升特征建模的准确性和效率。
3、本发明的交叉特征建模方法遵循白盒设计,建模过程更加透明,因而在关系分析处理中更具解释性。
4、通过注意重校准权重的门控机制能够动态捕捉对应于输入样本的交互项,提供模型决策的可解释性,从而得到人们的信任并提供新的见解,促进人们对某些领域的理解。
5、通过注意权值向量对训练数据的学习,提供模型决策全局范围的可解释性。
6、通过动态特征交互权重提供模型当前输入决策局部范围的可解释性。
附图说明
图1为本发明实施例一所述方法的流程图。
具体实施方式
下面结合附图,具体说明本发明的优选实施方式。
为了后续描述的方便,将结构化数据表示为一个逻辑表T,其中包含n行和m列,具体来说,每一行可以表示为一个元组(x,y)=(x
本发明的思想在于属性值分布具有“结构”,同时,特征交互也具有“结构”。这种结构可以在每个输入样本的基础上学习,以便进行更有效并且可解释地交互建模。并且,并不是所有的特征在交互建模中都是有用的,通过简单地引入更多成分特征来捕获交叉特征既没效率也不有效。相反,以有选择性并且动态的方式捕获交叉特征更为有效。
具体来说,给定输入特征x,首先将每个输入特征转换到指数空间。接下来,采用多头门控注意机制,用本发明提出的指数神经元自适应地对特征交互项建模。每个指数神经元显式地对任意阶的特定交叉特征进行建模,这更有效,并且更容易被人类理解;门控注意机制动态生成交互权重,选择性地过滤噪声特征,这使得建模过程更高效,更有效,更具解释性。后续,使用这种自适应关系建模方法获得的关系表示(即为交互建模所捕获的交叉特征)提供给后续的预测模型即可完成预测任务。
实施例一实现了本发明所述的一种结构化数据的自适应关系建模方法,可以捕捉输入元组不同属性之间的交叉特征,具体包括以下内容:
使用指数神经元建模所述结构化数据属性间的交叉特征,所述指数神经元为K×o个,其中,K表示注意头的个数,o表示每个注意头的所述指数神经元的数目,K和o都是自然数;每个注意头的所有所述指数神经元共享其双线性注意函数φ
每个注意头的第i个所述指数神经元y
其中,i,⊙表示哈达玛积,exp(·)函数和相应的指数w
w
其中,
其中,
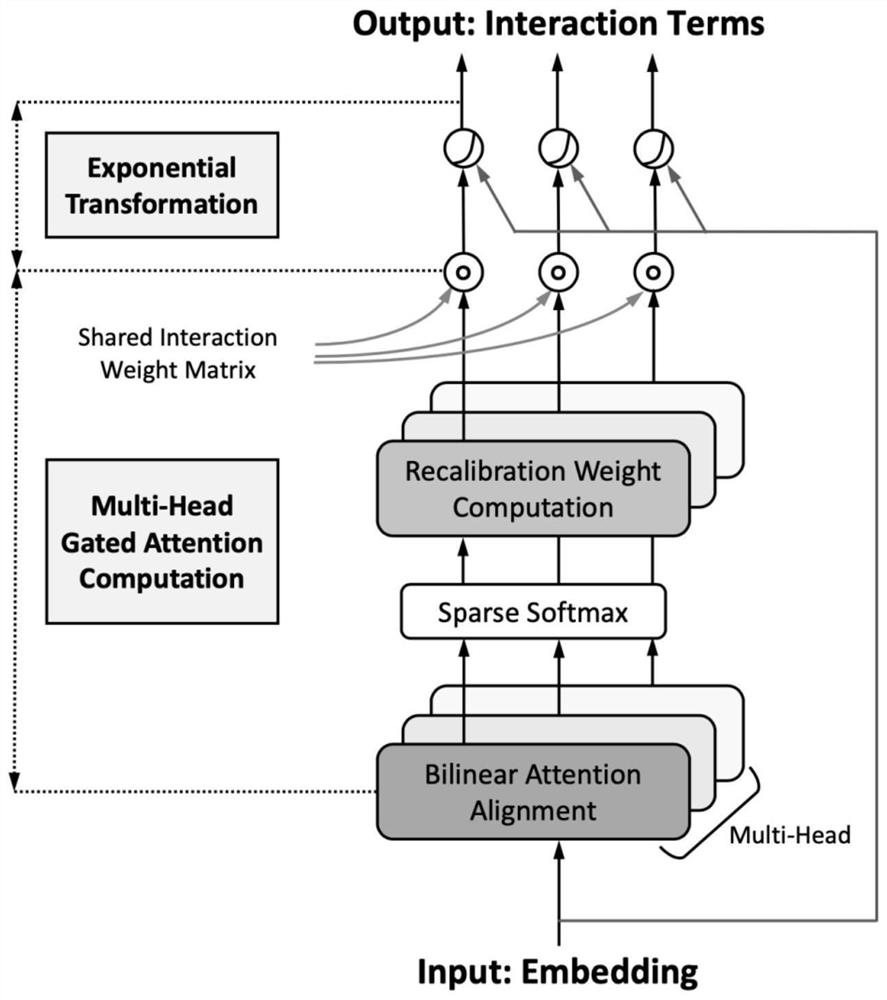
上述内容可以由附图1所示的流程图进行形象的描述,将输入Input(嵌入向量Embedding)一方面通过指数变换(Exponential Transformation)转换到指数空间得到若干指数神经元;另一方面,采用多头门控注意机制(Multi-Head Gated AttentionComputation)根据输入Input自适应地对特征交互项建模生成动态特征交互权重;而后将动态特征交互权重作用于指数神经元得到输出Output(交互作用项Interaction Terms)。具体的,多头门控注意机制是对多头(Multi-Head)的每一头基于输入Input分别进行双线性注意对齐(Bilinear Attention Alignment)、稀疏Softmax(Sparse Softmax)、重校准权重(Recalibration Weight Computation)、共享交互权重矩阵(Shared InteractionWeight Matrix)后生成动态特征交互权重。
下面对本发明的指数神经元与多头门控注意力进行详细介绍。
指数神经元:
首先,本发明提出在指数空间而不是对数空间中处理输入,即将每个输入特征视为自然指数函数的指数,解决了现有对数神经元输入必须保持为正的限制,提高了神经元的灵活性,扩大了输入的适用范围。然后,提出指数变换的指数神经元y
因此,在指数神经元中建模的特征交互基于在指数空间中变换的特征嵌入,即
多头门控注意力:
对于第i个指数神经元y
为此,本发明将每个指数神经元与一个可学习的注意权值向量v
α-entmax(·)为稀疏softmax,通过给一些输出分配零概率来产生稀疏分布,如(AndréF.T.Martins and Ramón Fernández Astudillo.2016.From Softmax toSparsemax:A Sparse Model of Attention and Multi-Label Classification.InProceedings of the 33nd International Conference on Machine Learning,ICML2016,Vol.48.1614–1623.)、(Ben Peters,Vlad Niculae,and AndréF.T.Martins.2019.Sparse Sequence-toSequence Models.In Proceedings of the 57thConference of the Association for Computational Linguistics,ACL 2019.1504–1519.)等。本实施例使用Constantino Tsallis.1988.Possible generalization ofBoltzmann-Gibbs statistics.In Journal of Statistical Physics.52:479–487.,对于较大的α,α-entmax倾向于产生较稀疏的概率分布,因而较大比例的输入特征将被过滤掉,即稀疏性随α的增大而增大。双线性注意首先将第j个属性域的嵌入向量e
w
其中,再校准权重z
此外,为了支持来自不同表示空间的交互建模,本发明采用了多头注意机制,而不是用单个双线性注意函数φ
进一步的,K、o和α是本发明方法的关键超参数。具体来说,K和o分别是注意头数和每个头所对应的指数神经元数目,α则控制了多头部注意对齐中稀疏特征选择的α-entmax的稀疏性。试验结果表明:①仅仅增加K或o并不一定会得到更高的预测性能。这表明,利用多头注意机制在中等数量的表征空间建模是有益的,在每个注意头内共享线性注意对齐权重也有利于学习,同时大大减小了参数的大小。②适当的稀疏度α始终能获得更好的预测性能,将稀疏度α的取值范围设置在[1.7,2.0]范围内效果更好。这表明稀疏注意机制可以帮助过滤噪声特征,以实现更有效的动态特征交互建模。
进一步的,当采用较大的嵌入尺寸时,预测效果相较于小的嵌入尺寸更好,尤其是当嵌入尺寸n
进一步的,所述K和o的个数最好为2
进一步的,将上述方法用于某一场景,使用对应的结构化训练数据对网络进行训练后,所有指数神经元的全局权值v
进一步的,使用训练后的网络进行预测时,由于门控机制,针对输入数据作噪声滤除,可以获得每一交互关注的属性(z
通过上述本发明自适应建模方法提高了结构化数据关系建模的有效性、可解释性和效率:
1、有效性
大多数现有的特征交互建模研究要么以预定义的最大交互阶数静态捕获可能的交叉特征,要么以隐式的方式建模交叉特征。然而,在不同的输入实例中,不同的关系应该具有不同的组成属性。有些关系是有信息的,而另一些可能只是噪音。因此,以静态方式建模交叉特征不仅参数和计算效率低,而且可能是无效的。特别地,每个指数神经元的输出y
2、可解释性
可解释性度量了模型所做的决策可以被人类理解的程度,从而得到用户的信任并提供新的见解。目前已经存在解释黑盒模型如何工作的事后解释方法,包括基于扰动的方法、基于梯度的方法和基于注意的方法。然而,另一个模型给出的解释往往不可靠,这可能会产生误导。另外,本发明遵循白盒设计,并且建模过程更加透明,因而在关系分析处理中更具解释性。
具体地说,每个特征交互项y
3、效率
除了有效性和可解释性之外,模型复杂性是实际应用中模型部署的另一个重要标准。本发明中,K·o个指数神经元可在复杂度O(Komn
试验结果
将特征交互方法与现有的FM嵌入方法以及多层感知器(MLP)预测相结合,得到预测模型,以评估本发明。
试验中使用的数据集为app推荐(Frappe)、电影推荐(MovieLens)、分类点击率预测(Avazu、Criteo)和医疗健康(Diabetes130)。
将本发明ARM-Net与如下五类特征交互建模基线模型进比较:
(1)线性回归(LR),在不考虑特征交互的情况下,将输入属性与其各自的重要性权重进行线性聚合;
(2)对二阶特征交互作用进行建模的方法,即FM(SteffenRendle.2010.Factorization Machines.In ICDM 2010,The 10th IEEE InternationalConference on Data Mining,Sydney,Australia,14-17December 2010.),AFM(Jun Xiao,Hao Ye,Xiangnan He,Hanwang Zhang,Fei Wu,and Tat-Seng Chua.2017.AttentionalFactorization Machines:Learning the Weight of Feature Interactions viaAttention Networks.In Proceedings of the Twenty-Sixth International JointConference on Artificial Intelligence,IJCAI.);
(3)捕捉高阶特征交互作用的方法,即HOFM(Mathieu Blondel,Akinori Fujino,Naonori Ueda,and Masakazu Ishihata.2016.Higher-order factorizationmachines.In Advances in Neural Information Processing Systems.3351–3359.),DCN(Ruoxi Wang,Bin Fu,Gang Fu,and Mingliang Wang.2017.Deep&Cross Network for AdClick Predictions.In Proceedings of the SIGKDD’17.ACM.),CIN(Jianxun Lian,Xiaohuan Zhou,Fuzheng Zhang,Zhongxia Chen,Xing Xie,and GuangzhongSun.2018.xDeepFM:Combining explicit and implicit feature interactions forrecommender systems.In Proceedings of the 24th ACM SIGKDD InternationalConference on Knowledge Discovery&Data Mining.1754–1763.)和AFN(Weiyu Cheng,Yanyan Shen,and Linpeng Huang.2020.Adaptive Factorization Network:LearningAdaptive-Order Feature Interactions.In 34th AAAI Conference on ArtificialIntelligence.);
(4)基于神经网络的方法,即DNN,以及图神经网络GCN(Thomas N.Kipf and MaxWelling.2017.Semi-Supervised Classification with Graph ConvolutionalNetworks.In 5th International Conference on Learning Representations,ICLR.OpenReview.net.)和GAT(Petar Velickovic,Guillem Cucurull,ArantxaCasanova,Adriana Romero,Pietro Liò,and Yoshua Bengio.2018.Graph AttentionNetworks.In 6th International Conference on Learning Representations,ICLR.)。
(5)通过DNNs集成了显式交叉特征建模和隐式特征交互建模的模型,即Wide&Deep(Heng-Tze Cheng,Levent Koc,Jeremiah Harmsen,Tal Shaked,Tushar Chandra,HrishiAradhye,Glen Anderson,Greg Corrado,Wei Chai,Mustafa Ispir,Rohan Anil,ZakariaHaque,Lichan Hong,Vihan Jain,Xiaobing Liu,and Hemal Shah.2016.Wide&DeepLearning for Recommender Systems.In Proceedings of the 1st Workshop on DeepLearning for Recommender Systems.ACM,7–10.)、KPNN(Yanru Qu,Bohui Fang,WeinanZhang,Ruiming Tang,Minzhe Niu,Huifeng Guo,Yong Yu,and XiuqiangHe.2018.Product-based neural networks for user response prediction overmulti-field categorical data.ACM Transactions on Information Systems(TOIS)37,1(2018),1–35.)、NFM(Xiangnan He and Tat-Seng Chua.2017.Neural FactorizationMachines for Sparse Predictive Analytics.In Proceedings of the 40thInternational ACM SIGIR Conference on Research and Development in InformationRetrieval.ACM,355–364.)、DeepFM(Huifeng Guo,Ruiming Tang,Yunming Ye,ZhenguoLi,and Xiuqiang He.2017.DeepFM:A Factorization-Machine based Neural Networkfor CTR Prediction.In Proceedings of the Twenty-Sixth International JointConference on Artificial Intelligence,IJCAI.1725–1731.)、DCN+(Ruoxi Wang,BinFu,Gang Fu,and Mingliang Wang.2017.Deep&Cross Network for Ad ClickPredictions.In Proceedings of the SIGKDD’17.ACM.)、xDeepFM(Jianxun Lian,Xiaohuan Zhou,Fuzheng Zhang,Zhongxia Chen,Xing Xie,and GuangzhongSun.2018.xDeepFM:Combining explicit and implicit feature interactions forrecommender systems.In Proceedings of the 24th ACM SIGKDD InternationalConference on Knowledge Discovery&Data Mining.1754–1763.)和AFN+(Weiyu Cheng,Yanyan Shen,and Linpeng Huang.2020.Adaptive Factorization Network:LearningAdaptive-Order Feature Interactions.In 34th AAAI Conference on ArtificialIntelligence.)。
使用AUC(ROC曲线下的面积,越大越好)和Logloss(交叉熵,越小越好)作为评价指标。对于AUC和Logloss,在采用的基准数据集上,0.001水平的改近被认为是显著的。我们将数据集分成8:1:1,分别用于训练、验证和测试,报告五次独立运行的评估指标的平均值,并在验证集上采取了提前停止的策略。
试验中采用Adam优化器,学习率搜索范围为0.1~1e-3,所有模型的batch size定为4096。特别地,我们对较小的数据集Diabetes130采用1024的batch size,对于较大的数据集Avazu,则每1000个训练步骤进行一次评估。实验是在Xeon(R)Silver 4114CPU@2.2GHz(10核)、256G内存和GeForce RTX 2080Ti的服务器上进行的。模型在PyTorch 1.6.0和cuda10.2中实现。
为了进行公平的比较,我们通过在数据集中一致地将嵌入大小固定为10,并在所有的集成模型中共享了DNN的最佳搜索配置,来评估这些具有相同训练设置的模型的有效性。特别地,我们从1~8和100~800获得了最佳DNN深度。GCN/GAT层数是{1,2,…,8}中最好的;HOFM、DCN、CIN、DCN+和xDeepFM的相互作用阶数在1~8中搜索,GCN、GAT、CIN、xDeepFM和AFN的特征/神经元数在{10,25,50,100,…,1600}。对于ARM-Net,稀疏度α在1.0~4.0中搜索;注意头数K和每个注意头的指数神经元数o在约束K·o≤1024的情况下进行网格搜索。不同数据集下的数据统计和最佳超参数见表1:数据集统计和ARM-Net最佳参数配置(Table1:Dataset statistics and best ARM-Net configurations),表中给出了不同数据集(Dataset)的元组(实例)数(Tuples)、属性域数目(Fields)和不同特征数(Features),以及对应数据集的本发明网络的最佳超参数(ARM-Net Hyperparameters)。比较结果见表2:相同训练数据集下的总体预测性能(Table2:Overall prediction performance withthe same training settings)。其中的ARM-Net+为ARM-Net和DNN的集成模型。
Table 1:Dataset statistics and best ARM-Net configurations.
Table 2:Overall prediction performance with the same trainingsettings
从表2中可以看出:
1.使用单个模型的显式交互建模。
将ARM网络与单一结构的基线模型进行比较,这类基线模型可以显式地捕获一阶、二阶和高阶交叉特征。基于表2结果,我们有以下发现:
首先,ARM-Net在AUC上始终优于显式建模相互作用的基线模型。更好的预测性能证实了ARM-Net跨数据集和领域的有效性,包括应用推荐(Frappe)、电影标签推荐(MovieLens)、点击率预测(Avazu和Criteo)和医疗再入院预测(Diabetes130)。
其次,高阶模型(例如HOFM和CIN)通常比低阶模型(例如LR和FM)有更好的预测性能,这验证了高阶交叉特征对预测的重要性,高阶交叉特征的缺失会大大降低模型的建模能力。
第三,AFN和ARM-Net都显著优于固定阶的基线模型,这验证了以自适应和数据驱动的方式建模任意阶特征交互的有效性。
最后,ARM-Net的AUC明显高于一般表现最好的基线模型AFN。
ARM网络的良好性能主要归功于指数神经元和门控注意机制。具体来说,AFN中对数变换正输入的限制限制了它的表示,而ARM-Net则通过在指数空间中建模特征交互来避免这个问题。此外,ARM-Net的多头门控注意力不像AFN那样静态地建模交互,而是选择性地过滤噪声特征,并动态地生成交互权重,以反映每个输入实例的特征。因此,ARM-Net可以捕获更有效的交叉特征,以便在每个输入的基础上获得更好的预测性能,并且由于这种运行时灵活性,ARM-Net的参数效率更高。如表1所示,对于不同规模的数据集,最好的ARM-Net只需要几十到几百个指数神经元,而最好的AFN一般需要一千多个神经元才能获得最佳结果,例如,在大型数据集Avazu上,ARM网络和AFN分别需要32个和1600个神经元。
2.基于神经网络的模型和集成模型。
基于表2结果,我们有以下发现:
(1)尽管没有显式地对特征交互进行建模,但是相对于其他单一结构的基线模型,最佳的基于神经网络的模型通常具有更强的预测性能。特别是,基于注意力机制的图网络GAT在Avazu和Diabetes130上获得了明显高于其他单一结构模型的AUC。然而,它的性能并不像ARM-Net那样稳定,不同的数据集之间差异很大,例如,GAT在Frappe和MovieLens上的性能比DNN和ARM-Net差得多。
(2)DNN的模型集成显著提高了它们各自的预测性能。这可以在整个基线模型中一致地观察到,例如DCN+、xDeepFM和AFN+,这表明DNNs捕获的非线性相互作用是对显式捕获的相互作用的补充。
(3)ARM-Net实现了与DNN相当的性能,ARM-Net+进一步提高了性能,在所有的基准数据集上都获得了最好的整体性能。
总之,这些结果进一步证实了ARM-Net对任意阶特征交互的有选择地、动态地建模的有效性。
描述于本公开实施例中所涉及到的单元可以通过软件的方式实现,也可以通过硬件的方式来实现。其中,单元的名称并不构成对该单元本身的限定。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 一种结构化数据的自适应关系建模方法
- 一种非结构化数据中的特定实体关系的提取方法