音响处理方法、音响处理系统及程序
文献发布时间:2023-06-19 18:32:25
技术领域
本发明涉及一种音响处理。
背景技术
以往提出有对语音或乐音等声音进行合成的各种技术。例如,在非专利文献1或非专利文献2中,公开了通过利用了深度神经网络(DNN:Deep Neural Network)的每个时间步(Time step)的合成处理,生成音响信号的样本的技术。
非专利文献1:Van Den Oord,Aaron,et al."WAVENET:AGENERATIVE MODEL FORRAW AUDIO."arXiv:1609.03499v2(2016)
非专利文献2:Blaauw,Merlijn,and Jordi Bonada."A NEURALPARAMETRICSINGING SYNTHESIZER."arXiv preprint arXiv:1704.03809v3(2017)
发明内容
根据非专利文献1或非专利文献2的技术,能够考虑到乐曲中的处于当前的时间步的后方的特征,生成音响信号的各样本。但是,难以与各样本的生成并行地生成与由利用者实时发出的指示相对应的合成音。考虑到以上情况,本发明的一个方式的目的在于,生成与乐曲内的处于后方的特征和来自利用者的实时指示相对应的合成音。
为了解决以上的课题,本发明的一个方式涉及的音响处理方法,在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据,取得与来自利用者的实时的指示相对应的控制数据,与包含所述取得的控制数据和所述取得的编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。
本发明的一个方式涉及的音响处理系统具有:编码化数据取得部,其在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据;控制数据取得部,其在所述多个时间步的每一者,取得与来自利用者的实时的指示相对应的控制数据;以及音响特征数据生成部,其在所述多个时间步的每一者,与包含所述取得的控制数据和所述取得的编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。
本发明的一个方式涉及的程序使计算机作为如下各部起作用:编码化数据取得部,其在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据;控制数据取得部,其在所述多个时间步的每一者,取得与来自利用者的实时的指示相对应的控制数据;以及音响特征数据生成部,其在所述多个时间步的每一者,与包含所述取得的控制数据和所述取得的编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。
附图说明
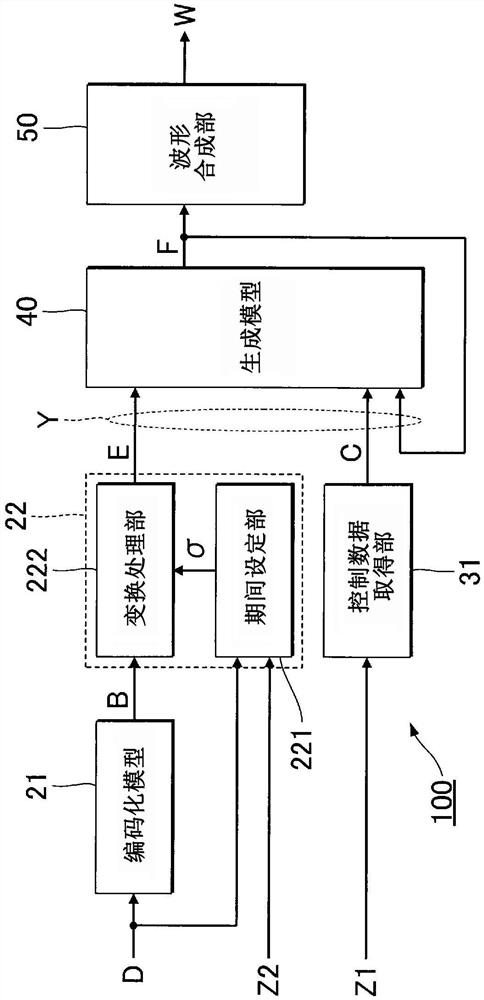
图1是例示出第1实施方式涉及的音响处理系统的结构的框图。
图2是音响处理系统的动作(乐器音的合成)的说明图。
图3是音响处理系统的动作(歌唱音的合成)的说明图。
图4是例示出音响处理系统的功能性结构的框图。
图5是例示出准备处理的具体流程的流程图。
图6是例示出合成处理的具体流程的流程图。
图7是学习处理的说明图。
图8是例示出学习处理的具体流程的流程图。
图9是第2实施方式涉及的音响处理系统的动作的说明图。
图10是例示出音响处理系统的功能性结构的框图。
图11是例示出准备处理的具体流程的流程图。
图12是例示出合成处理的具体流程的流程图。
图13是学习处理的说明图。
图14是例示出学习处理的具体流程的流程图。
具体实施方式
A:第1实施方式
图1是例示出本发明的第1实施方式涉及的音响处理系统100的结构的框图。音响处理系统100是生成音响信号W的计算机系统,该音响信号W表示合成音的波形。合成音是通过例如虚拟的演奏者演奏乐器而发音的乐器音、或通过例如虚拟的歌唱者歌唱乐曲而发音的歌唱音。音响信号W由多个样本(Sample)的时间序列构成。
音响处理系统100具有控制装置11、存储装置12、放音装置13和操作装置14。音响处理系统100例如通过智能手机、笔记本终端或个人计算机等信息设备而实现。此外,音响处理系统100除了由单体的装置实现以外,还可以由相互分体地构成的多个装置(例如客户端服务器系统)实现。
存储装置12是对控制装置11执行的程序和控制装置11使用的各种数据进行存储的单个或多个存储器。存储装置12例如由磁记录介质或半导体记录介质等公知的记录介质、或多种记录介质的组合构成。另外,可以将相对于音响处理系统100能够拆装的可移动型的记录介质、或能够进行经由通信网络的写入或读出的记录介质(例如云存储)作为存储装置12而利用。
存储装置12对表示乐曲的内容的乐曲数据D进行存储。在图2例示出在乐器音的合成中利用的乐曲数据D,在图3例示出在歌唱音的合成中利用的乐曲数据D。乐曲数据D表示构成乐曲的多个符号(symbols)的时间序列。各符号是音符或音素。在乐器音的合成中利用的乐曲数据D针对构成乐曲的多个符号(具体而言,音符)的每一者而指定持续长度d1和音高d2。在歌唱音的合成中利用的乐曲数据D针对构成乐曲的多个符号(具体而言,音素)的每一者而指定持续长度d1、音高d2和音素编码d3。持续长度d1是符号持续的拍数。例如,通过不依赖于乐曲的节奏的最小变动(tick)值而指定持续长度d1。音高d2例如由节点编号进行指定。音素编码d3是用于对音素进行识别的编码。图3的音素/sil/是指静音。乐曲数据D还可称为表示乐曲的乐谱的数据。
图1的控制装置11是对音响处理系统100的各要素进行控制的单个或多个处理器。具体而言,例如控制装置11由CPU(Central Processing Unit)、SPU(Sound ProcessingUnit)、DSP(Digital Signal Processor)、FPGA(Field Programmable Gate Array)、或ASIC(Application Specific Integrated Circuit)等1种以上的处理器构成。控制装置11根据存储装置12所存储的乐曲数据D,生成音响信号W。
放音装置13对由控制装置11生成的音响信号W表示的合成音进行播放。放音装置13例如是扬声器或耳机。此外,对于将音响信号W从数字变换为模拟的D/A变换器和对音响信号W进行放大的放大器,为了方便而省略了图示。另外,在图1中,例示出放音装置13搭载于音响处理系统100的结构,但也可以是与音响处理系统100分体的放音装置13通过有线或无线的方式与音响处理系统100连接。
操作装置14是接受来自利用者的指示的输入设备。操作装置14例如是利用者操作的多个操作件、或对利用者的接触进行检测的触摸面板。可以将包含操作钮或操作踏板等操作件的MIDI(Musical Instrument Digital Interface)控制器等的输入设备作为操作装置14而利用。
利用者通过对操作装置14进行操作而能够将合成音的条件指示给音响处理系统100。具体而言,利用者能够对指示值Z1和乐曲的节奏Z2进行指示。第1实施方式的指示值Z1是表示合成音的强弱(动感)的数值。指示值Z1及节奏Z2与音响信号W的生成并行地被实时指示。指示值Z1及节奏Z2与来自利用者的指示相对应地在时间轴上连续变化。利用者对节奏Z2进行指示的方法是任意的。例如,可以根据利用者反复对操作装置14的操作件进行操作的周期而确定节奏Z2。另外,也可以根据由利用者进行的乐器演奏或歌唱语音而确定节奏Z2。
图4是例示出音响处理系统100的功能性结构的框图。控制装置11通过执行存储装置12所存储的程序,从而实现用于根据乐曲数据D而生成音响信号W的多个功能(编码化模型21、编码化数据取得部22、控制数据取得部31、生成模型40及波形合成部50)。
编码化模型21是根据乐曲数据D而生成符号数据B的时间序列的统计性推定模型。如图2及图3中作为步骤Sa12而图示的那样,编码化模型21针对构成乐曲的多个符号的每一者而生成符号数据B。即,根据乐曲数据D的1个符号(1音符或1音素),生成1个符号数据B。具体而言,关于各符号的符号数据B,编码化模型21根据该符号和前后的符号,生成各符号的符号数据B。乐曲的整个范围的符号数据B的时间序列是根据乐曲数据D而生成的。具体而言,编码化模型21是对乐曲数据D和符号数据B的时间序列之间的关系进行了学习的训练好的模型。
与乐曲数据D的1个符号(音符或音素)对应的1个符号数据B除了该符号自身的音乐特征(持续长度d1、音高d2及音素编码d3)以外,还与乐曲中的该符号的前方(过去)的各符号的音乐特征和该符号的后方(未来)的各符号的音乐特征相对应地变化。编码化模型21生成的符号数据B的时间序列储存于存储装置12。
编码化模型21例如由深度神经网络(DNN:Deep Neural Network)构成。例如,卷积神经网络(CNN:Convolutional Neural Network)或递归神经网络(RNN:Recurrent NeuralNetwork)等任意形式的深度神经网络作为编码化模型21而利用。作为递归神经网络而例示出双向性的递归神经网络(Bi-directional RNN)。此外,长短期记忆(LSTM:Long Short-Term Memory)或Self-Attention等附加性要素可以搭载于编码化模型21。以上例示出的编码化模型21通过使控制装置11执行根据乐曲数据D而生成多个符号数据B的运算的程序和应用于该运算的多个变量(具体而言,加权值及偏差)的组合而实现。对编码化模型21进行规定的多个变量通过利用多个训练数据的机器学习而事先设定,存储于存储装置12。
编码化数据取得部22如图2或图3所例示的那样,在时间轴上的多个时间步τ的每一者依次取得编码化数据E。多个时间步τ的每一者是在时间轴上以等间隔(例如5毫秒间隔)离散地设定的时间点。如图4所例示的那样,编码化数据取得部22具有期间设定部221和变换处理部222。
期间设定部221根据乐曲数据D和节奏Z2对乐曲内的各符号发音的期间(以下,称为“单位期间”)σ进行设定。具体而言,期间设定部221针对乐曲内的多个符号的每一者而对单位期间σ的开始时刻和结束时刻进行设定。例如,与由乐曲数据D针对每个符号而指定的持续长度d1和利用者通过操作装置14而指示的节奏Z2相对应地设定各单位期间σ。如图2或图3所例示的那样,各单位期间σ包含有时间轴上的1个以上的时间步τ。
各单位期间σ的设定可任意地采用公知的解析技术。将利用例如隐马尔可夫模型(HMM:Hidden Markov Model)等统计性推定模型而推定每个音素的持续长度的功能(G2P:Grapheme-to-Phonemes)、或利用例如深度神经网络等机器学习完毕(well-trained)的统计性推定模型而推定持续长度的功能,作为期间设定部221而利用。期间设定部221生成表示各单位期间σ和每个时间步τ的编码化数据E之间的对应关系的信息(以下,称为“映射信息”)。
变换处理部222如图2或图3中作为步骤Sb14而图示出的那样,在时间轴上的多个时间步τ的每一者取得编码化数据E。即,变换处理部222按照时间序列的顺序将多个时间步τ的每一者作为当前步τc而依次选择,针对该当前步τc而生成编码化数据E。具体而言,变换处理部222利用期间设定部221设定了各单位期间σ的结果(即,映射信息),将存储装置12所存储的每个符号的符号数据B变换为时间轴上的每个时间步τ的编码化数据E。即,变换处理部222利用编码化模型21生成的符号数据B和期间设定部221生成的映射信息,针对时间轴上的每个时间步τ而生成编码化数据E。与1个符号对应的1个符号数据B向多个时间步τ范围的编码化数据E展开。但是,例如在持续长度d1极端短的情况下,也有时将1个符号数据B变换为1个编码化数据E。
从每个符号的符号数据B向每个时间步τ的编码化数据E的变换例如利用深度神经网络。例如,利用卷积神经网络或递归神经网络等任意形式的深度神经网络,变换处理部222生成编码化数据E。
如根据以上的说明所理解的那样,编码化数据取得部22在多个时间步τ的每一者取得编码化数据E。如前述那样,与乐曲内的1个符号对应的符号数据B除了该符号自身的特征以外,与该符号的前方及后方的各符号的特征相对应地变化。因此,当前步τc的编码化数据E与乐曲数据D所指定的多个符号(音符或音素)中的对应于当前步τc的符号的特征(d1-d3)和该符号的前后的符号的特征(d1-d3)相对应地变化。
图4的控制数据取得部31在多个时间步τ的每一者取得控制数据C。控制数据C是与由利用者通过针对操作装置14的操作而实时赋予的指示相对应的数据。具体而言,控制数据取得部31针对每个时间步τ而依次生成表示由利用者发出的指示值Z1的控制数据C。此外,可以将节奏Z2作为控制数据C而利用。
生成模型40在多个时间步τ的每一者生成音响特征数据F。音响特征数据F是表示合成音的音响性特征的数据。具体而言,音响特征数据F例如表示合成音的梅尔频谱(mel-spectrum)或振幅谱等频率特性。即,生成与不同的时间步τ对应的音响特征数据F的时间序列。具体而言,生成模型40是根据当前步τc的输入数据Y,生成该当前步τc的音响特征数据F的统计性推定模型。即,生成模型40是对输入数据Y和音响特征数据F之间的关系进行了学习的训练好的模型。此外,生成模型40是“第1生成模型”的一个例子。
当前步τc的输入数据Y包含有在当前步τc由编码化数据取得部22取得的编码化数据E、和在当前步τc由控制数据取得部31取得的控制数据C。另外,当前步τc的输入数据Y包含有在相对于当前步τc而位于过去的多个时间步τ的每一者由生成模型40生成的音响特征数据F。即,由生成模型40生成完毕的音响特征数据F回归到该生成模型40的输入。
如根据以上的说明所理解的那样,生成模型40根据当前步τc的编码化数据E及控制数据C、和过去的时间步τ的音响特征数据F,生成当前步τc的音响特征数据F(图2及图3的步骤Sb16)。在第1实施方式,编码化模型21作为根据乐曲数据D而生成符号数据B的编码器起作用,生成模型40作为根据编码化数据E及控制数据C而生成音响特征数据F的解码器起作用。此外,输入数据Y是“第1输入数据”的一个例子。
生成模型40例如由深度神经网络构成。例如将因果论的卷积神经网络或递归神经网络等任意形式的深度神经网络作为生成模型40而利用。作为递归神经网络,例示出单向性的递归神经网络。此外,也可以将长短期记忆或Self-Attention等附加性要素搭载于生成模型40。以上例示出的生成模型40通过使控制装置11执行根据输入数据Y而生成音响特征数据F的运算的程序和应用于该运算的多个变量(具体而言,加权值及偏差)的组合而实现。对生成模型40进行规定的多个变量通过利用多个训练数据的机器学习而事先设定,存储于存储装置12。
如以上所说明的那样,在第1实施方式,通过将输入数据Y供给至机器学习完毕的生成模型40而生成音响特征数据F。因此,能够基于在机器学习中使用的多个训练数据潜在的倾向,生成统计上合理的音响特征数据F。
图4的波形合成部50根据音响特征数据F的时间序列,生成合成音的音响信号W。波形合成部50通过例如包含离散逆傅里叶变换的运算,将音响特征数据F表示的频率特性变换为时间区域的波形,针对相前后的时间步τ将该波形连结,由此生成音响信号W。此外,可以将对音响特征数据F和音响信号W的样本的时间序列之间的关系进行了学习的深度神经网络(所谓的神经声码器)作为波形合成部50而利用。通过将由波形合成部50生成的音响信号W供给至放音装置13,从而从放音装置13播放合成音。
图5是例示出控制装置11根据乐曲数据D而生成符号数据B的时间序列的处理(以下,称为“准备处理”)Sa的具体流程的流程图。在每次更新乐曲数据D时执行准备处理Sa。例如,在与来自利用者的编辑的指示相对应地更新乐曲数据D时,控制装置11针对更新后的乐曲数据D而执行准备处理Sa。
如果准备处理Sa开始,则控制装置11从存储装置12取得乐曲数据D(Sa11)。控制装置11如图2及图3所例示的那样,通过将表示多个符号的时间序列(音符列或音素列)的乐曲数据D供给至编码化模型21,从而生成与乐曲内的不同的符号对应的多个符号数据B(Sa12)。具体而言,生成乐曲的整个范围的符号数据B的时间序列。控制装置11将由编码化模型21生成的符号数据B的时间序列储存于存储装置12(Sa13)。
图6是例示出控制装置11生成音响信号W的处理(以下,称为“合成处理”)Sb的具体流程的流程图。在通过准备处理Sa生成符号数据B之后,在时间轴上的多个时间步τ的每一者执行合成处理Sb。即,按照时间序列的顺序依次选择多个时间步τ的每一者作为当前步τc,针对该当前步τc执行以下的合成处理Sb。利用者能够通过对操作装置14进行操作,从而与合成处理Sb的反复并行地在任意的时间点对指示值Z1进行指示。
如果开始合成处理Sb,则控制装置11取得利用者所指示的节奏Z2(Sb11)。然后,控制装置11对在乐曲内与当前步τc对应的位置(以下,称为“读出位置”)进行计算(Sb12)。读出位置与步骤Sb11中取得的节奏Z2相对应地决定。例如,节奏Z2越快,则读出位置针对每个合成处理Sb在乐曲内越快速推进。控制装置11对读出位置是否已到达乐曲的结束位置进行判定(Sb13)。
在读出位置已到达结束位置的情况下(Sb13:YES),控制装置11将合成处理Sb结束。另一方面,在读出位置未到达结束位置的情况下(Sb13:NO),控制装置11(编码化数据取得部22)根据存储装置12所存储的多个符号数据B中的与读出位置对应的1个符号数据B,生成与当前步τc对应的编码化数据E(Sb14)。另外,控制装置11(控制数据取得部31)取得表示当前步τc的指示值Z1的控制数据C(Sb15)。
控制装置11通过将当前步τc的输入数据Y供给至生成模型40,从而生成当前步τc的音响特征数据F(Sb16)。当前步τc的输入数据Y如前述那样,包含针对当前步τc而取得的符号数据B及控制数据C、和针对过去的多个时间步τ的每一者而由生成模型40生成的音响特征数据F。控制装置11将针对当前步τc而生成的音响特征数据F储存于存储装置12(Sb17)。存储装置12所存储的音响特征数据F在下一次及其以后的合成处理Sb的输入数据Y中利用。
控制装置11(波形合成部50)根据当前步τc的音响特征数据F,生成音响信号W的样本的时间序列(Sb18)。然后,控制装置11将当前步τc的音响信号W接着紧邻其前的时间步τ的音响信号W而供给至放音装置13(Sb19)。通过以上例示出的合成处理Sb针对每个时间步τ而反复,从而乐曲整个范围的合成音从放音装置13进行播放。
如以上所说明的那样,在第1实施方式,利用与当前步τc的后方的乐曲的特征相对应的编码化数据E、和当前步τc的来自利用者的指示相对应的控制数据C,生成音响特征数据F。因此,能够生成与当前步τc的后方(未来)的乐曲的特征、和来自利用者的实时的指示相对应的合成音的音响特征数据F。
另外,在音响特征数据F的生成中利用的输入数据Y除了当前步τc的控制数据C及编码化数据E以外,还包含过去的时间步τ的音响特征数据F。因此,能够生成音响特征时间上的变迁在听觉上自然的合成音的音响特征数据F。
但是,在仅根据乐曲数据D而生成音响信号W的结构中,难以以高的时间分辨率对合成音的音响特性精密地进行控制。在第1实施方式,能生成与来自利用者的指示相对应的音响信号W。即,具有能够将音响信号W的音响特性与来自利用者的指示相对应地以高的时间分辨率精密地进行控制的优点。此外,作为与来自利用者的指示相对应地对音响信号W的音响特性进行控制的结构,还设想到将音响处理系统100生成的音响信号W的音响特性与来自利用者的指示相对应地直接进行控制的结构。在第1实施方式,通过将与来自利用者的指示相对应的控制数据C供给至生成模型40而控制合成音的音响特性。因此,具有能够基于在机器学习所利用的多个训练数据潜在的倾向(与来自利用者的指示相对应的音响特性的倾向),相对于来自利用者的指示而对合成音的音响特性进行控制的优点。
图7是创建编码化模型21及生成模型40的处理(以下,称为“学习处理”)Sc的说明图。学习处理Sc是利用事先准备的多个训练数据T的有教师机器学习。多个训练数据T的每一者包含乐曲数据D、控制数据C的时间序列和音响特征数据F的时间序列。各训练数据T的音响特征数据F是表示根据该训练数据T的乐曲数据D及控制数据C应当生成的合成音的音响特征(例如频率特性)的正确数据。
控制装置11通过执行存储装置12所存储的程序,在图4例示出的各要素的基础上,还作为准备处理部61及学习处理部62起作用。准备处理部61根据存储装置12所存储的参照数据T0,生成训练数据T。根据不同的参照数据T0而生成多个训练数据T。各参照数据T0是包含乐曲数据D和音响信号W的数据。各参照数据T0的音响信号W是表示与该参照数据T0的乐曲数据D对应的乐曲(以下,称为“参照音”)的波形的信号。例如,通过乐曲数据D表示的乐曲的演奏、或以歌唱的方式发音的参照音的收录而生成音响信号W。根据多个乐曲而准备多个参照数据T0。因此,多个训练数据T包含与不同的乐曲对应的2个以上的训练数据T。
准备处理部61通过对各参照数据T0的音响信号W进行解析,从而生成训练数据T的控制数据C的时间序列和音响特征数据F的时间序列。例如,准备处理部61对表示音响信号W的信号强度(参照音的强弱)的指示值Z1的时间序列进行计算,针对每个时间步τ而生成表示该指示值Z1的控制数据C。此外,也可以根据音响信号W对节奏Z2进行计算,生成表示该节奏Z2的控制数据C。
另外,准备处理部61对音响信号W的频率特性(例如梅尔频谱或振幅谱)的时间序列进行计算,针对每个时间步τ而生成表示该频率特性的音响特征数据F。对于音响信号W的频率特性的计算可以任意采用例如离散傅里叶变换等公知的频率解析。准备处理部61通过使在以上的流程中生成的控制数据C的时间序列和音响特征数据F的时间序列与乐曲数据D对应,从而生成训练数据T。准备处理部61生成的多个训练数据T存储于存储装置12。
学习处理部62通过利用多个训练数据T的学习处理Sc而创建编码化模型21和生成模型40。图8是例示出学习处理Sc的具体流程的流程图。例如,将针对操作装置14的指示作为契机而开始学习处理Sc。
如果开始学习处理Sc,则学习处理部62选择存储装置12所存储的多个训练数据T中的规定个数的训练数据T(以下,称为“选择训练数据T”)(Sc11)。规定个数的选择训练数据T构成1个批次(batch)。学习处理部62将选择训练数据T的乐曲数据D供给至临时性的编码化模型21(Sc12)。编码化模型21根据由学习处理部62供给的乐曲数据D,生成每个符号的符号数据B。编码化数据取得部22根据每个符号的符号数据B,生成每个时间步τ的编码化数据E。将由编码化数据取得部22应用于编码化数据E的取得的节奏Z2设定为规定的基准值。另外,学习处理部62将选择训练数据T的各控制数据C依次供给至临时性的生成模型40(Sc13)。通过以上的处理,将包含编码化数据E及控制数据C和过去的音响特征数据F在内的输入数据Y针对每个时间步τ而供给至生成模型40。生成模型40针对每个时间步τ而生成与输入数据Y相对应的音响特征数据F。此外,可以将在由生成模型40生成之后附加了杂音成分的过去的音响特征数据F包含于输入数据Y。通过利用附加了杂音成分的音响特征数据F而抑制过度学习。
学习处理部62对损失函数进行计算,该损失函数表示由临时性的生成模型40生成的音响特征数据F的时间序列和在选择训练数据T中包含的音响特征数据F的时间序列(即,正确值)之间的差异(Sc14)。学习处理部62反复对编码化模型21的多个变量和生成模型40的多个变量进行更新,以使得损失函数减小(Sc15)。对于与损失函数相对应的变量的更新,例如利用误差逆传播法。
此外,多个变量的更新针对生成模型40按照每个时间步τ而执行,针对编码化模型21按照每个符号而执行。具体而言,多个变量的更新通过以下的流程1至流程3而实现。
[流程1]学习处理部62通过与每个时间步τ的编码化数据E对应的损失函数的误差逆传播,对生成模型40的多个变量进行更新。通过流程1得到与生成模型40相关的损失函数。
[流程2]学习处理部62将与每个时间步的编码化数据E对应的损失函数变换为与每个符号的符号数据B对应的损失函数。对于损失函数的变换,利用映射信息。
[流程3]学习处理部62通过与每个符号的符号数据B对应的损失函数的误差逆传播,对编码化模型21的多个变量进行更新。
学习处理部62对与学习处理Sc相关的结束条件是否成立进行判定(Sc16)。结束条件例如是损失函数小于规定的阈值、或者损失函数的变化量小于规定的阈值。此外,实际上在利用多个训练数据T的多个变量的更新被反复的次数已达到规定值的情况下(即,针对每1轮数(Epoch)),判定结束条件的成立与否。另外,也可以将利用训练数据T计算出的损失函数用于结束条件的成立与否的判断,但也可以将根据与训练数据T分别准备的测试数据计算出的损失函数利用于结束条件的成立与否的判断。
在结束条件不成立的情况(Sc16:NO),学习处理部62从存储装置12所存储的多个训练数据T选择未选择的规定个数的训练数据T作为新的选择训练数据T(Sc11)。即,直至结束条件的成立(Sc16:YES)为止,反复进行规定个数的训练数据T的选择(Sc11)、损失函数的计算(Sc12-Sc14)和多个变量的更新(Sc15)。在结束条件成立的情况下(Sc16:YES),学习处理部62将学习处理Sc结束。通过学习处理Sc的结束而创建编码化模型21及生成模型40。
根据通过以上的学习处理Sc而创建出的编码化模型21,能够生成适当的符号数据B,以针对未知的乐曲数据D生成统计上合理的音响特征数据F。另外,根据生成模型40,能够针对编码化数据E生成统计上合理的音响特征数据F。
此外,在以上例示出的学习处理Sc使用的训练数据T中可以利用与控制数据C的时间序列不同的控制数据C的时间序列,执行训练好(学习完毕)的生成模型40的重新训练。在生成模型40的重新训练中,不需要对规定编码化模型21的多个变量进行更新。
B:第2实施方式
以下对第2实施方式进行说明。此外,在以下所例示的各方式中对于功能与第1实施方式相同的要素,沿用与第1实施方式相同的标号而适当地省略各自的详细说明。
第2实施方式的音响处理系统100与图1例示出的第1实施方式相同地,具有控制装置11、存储装置12、放音装置13和操作装置14。乐曲数据D存储于存储装置12这一点也与第1实施方式相同。图9是第2实施方式的音响处理系统100的动作的说明图。在第2实施方式,例示出利用第1实施方式的歌唱音的合成用的乐曲数据D而合成歌唱音的情况。乐曲数据D针对乐曲内的每个因素而对持续长度d1、音高d2和音素编码d3进行指定。此外,对于乐器音的合成也能够应用第2实施方式。
图10是例示出第2实施方式涉及的音响处理系统100的功能性结构的框图。第2实施方式的控制装置11通过执行存储装置12所存储的程序,实现用于根据乐曲数据D而生成音响信号W的多个功能(编码化模型21、编码化数据取得部22、生成模型32、生成模型40及波形合成部50)。
编码化模型21与第1实施方式相同地,是根据乐曲数据D而生成符号数据B的时间序列的统计性推定模型。具体而言,编码化模型21是对乐曲数据D和符号数据B之间的关系进行了学习(训练)的训练好的模型。如图9中作为步骤Sa22而图示出的那样,编码化模型21针对构成乐曲的歌词的多个音素的每一者而生成符号数据B。即,与乐曲内的不同的符号对应的多个符号数据B由编码化模型21生成。编码化模型21与第1实施方式相同地,由任意的形式的深度神经网络构成。
与第1实施方式的符号数据B相同地,与任意的1个音素对应的符号数据B除了该音素自身的特征(持续长度d1、音高d2及音素编码d3)以外,还会受到乐曲中的该音素的前方(过去)的各音素的特征和该音素的后方(未来)的各音素的特征的影响。乐曲整个范围的符号数据B的时间序列是根据乐曲数据D而生成的。由编码化模型21生成的符号数据B的时间序列储存于存储装置12。
编码化数据取得部22与第1实施方式相同地,在时间轴上的多个时间步τ的每一者依次取得编码化数据E。第2实施方式的编码化数据取得部22具有期间设定部221、变换处理部222、音高推定部223和生成模型224。图10的期间设定部221与第1实施方式相同地,根据乐曲数据D和节奏Z2而设定乐曲内的各音素进行发音的单位期间σ。
变换处理部222如图9所例示的那样,在时间轴上的多个时间步τ的每一者取得中间数据Q。中间数据Q相当于第1实施方式的编码化数据E。具体而言,变换处理部222按照时间序列的顺序依次选择多个时间步τ的每一者作为当前步τc,针对该当前步τc而生成中间数据Q。即,变换处理部222利用由期间设定部221设定出各单位期间σ的结果(即,映射信息),将存储装置12所存储的每个符号的符号数据B变换为时间轴上的每个时间步τ的中间数据Q。即,编码化数据取得部22利用由编码化模型21生成的符号数据B和由期间设定部221生成的映射信息,针对时间轴上的每个时间步τ而生成中间数据Q。与1个符号对应的1个符号数据B向1个以上的时间步τ范围的中间数据Q展开。例如,在图9中,与音素/w/对应的符号数据B变换为由期间设定部221针对该音素/w/而设定的单位期间σ内的1个时间步τ的中间数据Q。另外,与音素/ah/对应的符号数据B变换为由期间设定部221针对该音素/ah/而设定的单位期间σ内的与5个时间步τ对应的5个中间数据Q。
另外,变换处理部222针对多个时间步τ的每一者而生成位置数据G。任意的1个时间步τ的位置数据G是以相对于单位期间σ的比例表示与该时间步τ对应的中间数据Q对应于单位期间σ内的哪个位置的数据。例如,在与中间数据Q对应的位置是单位期间σ的开头的情况下,位置数据G设定为“0”,在该位置是单位期间σ的末尾的情况下,位置数据G设定为“1”。例如,在图9中,如果着眼于音素/ah/的单位期间σ所含有的5个时间步τ中的任意的2个时间步τ,则后方的时间步τ的位置数据G与前方的时间步τ的位置数据G相比而对单位期间σ内的后方的时间点进行指定。例如,针对1个单位期间σ内的最后的时间步τ,生成表示该单位期间σ的终点的位置数据G。
图10的音高推定部223针对多个时间步τ的每一者,生成音高数据P。与任意的1个时间步τ对应的音高数据P是表示该时间步τ的合成音的音高的数据。由乐曲数据D指定的音高d2表示每个符号(例如音素)的音高,与此相对,音高数据P表示包含例如1个时间步τ的规定长度的期间内的音高的时间性变化。此外,音高数据P也可以是表示例如1个时间步τ的音高的数据。此外,音高推定部223可以省略。
具体而言,音高推定部223根据存储装置12所存储的乐曲数据D的各符号的音高d2等和由期间设定部221针对每个音素而设定的单位期间σ,生成多个时间步τ的每一者的音高数据P。对于音高数据P的生成(即,音高的时间性变化的推定)可任意地采用公知的解析技术。例如,利用例如深度神经网络或隐马尔可夫模型等统计性推定模型对音高的时间上的变迁(所谓的音高曲线)进行推定的功能,作为音高推定部223而利用。
图10的生成模型224如图9中作为步骤Sb21而图示出的那样,在多个时间步τ的每一者生成编码化数据E。生成模型224是根据输入数据X而生成编码化数据E的统计性推定模型。具体而言,生成模型224是对输入数据X和编码化数据E之间的关系进行了学习(训练)的训练好的模型。此外,生成模型224是“第2生成模型”的一个例子。
当前步τc的输入数据X包含与时间轴上的规定长度的期间(以下,称为“参照期间”)Ra内的各时间步τ对应的中间数据Q、位置数据G和音高数据P。参照期间Ra是包含当前步τc的期间。具体而言,参照期间Ra包含当前步τc、位于当前步τc的前方的多个时间步τ和位于当前步τc的后方的多个时间步τ。与参照期间Ra内的各时间步τ相关联的中间数据Q、针对参照期间Ra内的各时间步τ而生成的位置数据G及音高数据P包含于当前步τc的输入数据X。此外,输入数据X是“第2输入数据”的一个例子。此外,位置数据G及音高数据P的一者或两者可以从输入数据X省略。另外,在第1实施方式,也与第2实施方式相同地,可以使由变换处理部222生成的位置数据G包含于输入数据Y。
如前述那样,当前步τc的中间数据Q会被当前步τc的乐曲的特征和该当前步τc的前方及后方的乐曲的特征影响。因此,根据包含中间数据Q的输入数据X而生成的编码化数据E会被当前步τc的该乐曲的特征(持续长度d1、音高d2及音素编码d3)、和当前步τc的前方及后方的该乐曲的特征(持续长度d1、音高d2及音素编码d3)影响。而且,在第2实施方式,参照期间Ra包含当前步τc的后方(未来)的时间步τ。因此,与参照期间Ra仅包含当前步τc的结构相比,能够使当前步τc的后方的该乐曲的特征有效地影响编码化数据E。
生成模型224例如由深度神经网络构成。例如将非因果论的卷积神经网络等任意形式的深度神经网络作为生成模型224而利用。另外,可以将递归神经网络作为生成模型224而利用,也可以将长短期记忆或Self-Attention等附加性要素搭载于生成模型224。以上例示出的生成模型224通过使控制装置11执行根据输入数据X而生成编码化数据E的运算的程序和应用于该运算的多个变量(具体而言,加权值及偏差)的组合而实现。对生成模型224进行规定的多个变量通过利用多个训练数据的机器学习而事先设定,存储于存储装置12。
如以上所说明的那样,在第2实施方式,通过将输入数据X供给至机器学习完毕(训练好)的生成模型224而生成编码化数据E。因此,能够基于在机器学习使用的多个训练数据中潜在的关系,生成统计上合理的编码化数据E。
图10的生成模型32在多个时间步τ的每一者生成控制数据C。控制数据C与第1实施方式相同地,是与由利用者通过针对操作装置14操作而实时赋予的指示(具体而言,合成音的指示值Z1)相对应的数据。即,生成模型32作为在多个时间步τ的每一者取得控制数据C的要素(控制数据取得部)起作用。此外,可以将第2实施方式的生成模型32置换为第1实施方式的控制数据取得部31。
生成模型32根据时间轴上的规定的期间(以下,称为“参照期间”)Rb内的多个时间步τ的指示值Z1的时间序列,生成控制数据C。参照期间Rb是包含当前步τc的期间。具体而言,参照期间Rb包含当前步τc、和位于当前步τc的前方的多个时间步τ。即,前述的对输入数据X产生影响的参照期间Ra包含当前步τc的后方的时间步τ,相对与此,对控制数据C产生影响的参照期间Rb不包含当前步τc的后方的时间步τ。
生成模型32例如由深度神经网络构成。例如,将因果论的卷积神经网络或递归神经网络等任意形式的深度神经网络作为生成模型32而利用。作为递归神经网络,例示出单向性的递归神经网络。此外,也可以将长短期记忆或Self-Attention等附加性要素搭载于生成模型32。以上例示出的生成模型32通过使控制装置11执行根据参照期间Rb内的指示值Z1的时间序列而生成控制数据C的运算的程序和应用于该运算的多个变量(具体而言,加权值及偏差)的组合而实现。对生成模型32进行规定的多个变量通过利用多个训练数据的机器学习而事先设定,存储于存储装置12。
如以上所例示的那样,在第2实施方式,根据与来自利用者的指示相对应的指示值Z1的时间序列,生成控制数据C。因此,能够生成与对应于来自利用者的指示的指示值Z1的时间性变化相对应地适当地变化的控制数据C。此外,生成模型32可以省略。即,指示值Z1可以直接作为控制数据C而供给至生成模型32。另外,生成模型32可以置换为低通滤波器。即,通过时间轴上的指示值Z1的平滑化而生成的数值也可以作为控制数据C而供给至生成模型32。
生成模型40与第1实施方式相同地,在多个时间步τ的每一者生成音响特征数据F。即,生成与不同的时间步τ对应的音响特征数据F的时间序列。生成模型40是根据输入数据Y而生成音响特征数据F的统计性推定模型。具体而言,生成模型40是对输入数据Y和音响特征数据F之间的关系进行了学习(训练)的训练好的模型。
当前步τc的输入数据Y包含有在当前步τc由编码化数据取得部22取得的编码化数据E、和在当前步τc由生成模型32生成的控制数据C。另外,当前步τc的输入数据Y如图9所例示的那样,包含有在位于当前步τc的过去的多个时间步τ由生成模型40生成的音响特征数据F、和该多个时间步τ的每一者的编码化数据E及控制数据C。
如根据以上的说明所理解的那样,生成模型40根据当前步τc的编码化数据E及控制数据C、和过去的时间步τ的音响特征数据F,生成当前步τc的音响特征数据F。在第2实施方式,生成模型224作为生成编码化数据E的编码器起作用,生成模型32作为生成控制数据C的编码器起作用。另外,生成模型40作为根据编码化数据E及控制数据C而生成音响特征数据F的解码器起作用。此外,输入数据Y是“第1输入数据”的一个例子。
生成模型40与第1实施方式相同地,例如由深度神经网络构成。例如,将因果论的卷积神经网络或递归神经网络等任意形式的深度神经网络作为生成模型40而利用。作为递归神经网络而例示出单向性的递归神经网络。此外,也可以将长短期记忆或Self-Attention等附加性要素搭载于生成模型40。以上例示出的生成模型40通过使控制装置11执行根据输入数据Y而生成音响特征数据F的运算的程序和应用于该运算的多个变量(具体而言,加权值及偏差)的组合而实现。利用对生成模型40进行规定的多个变量通过利用多个训练数据的机器学习而事先设定,存储于存储装置12。此外,在生成模型40是递归型模型(自回归模型)的结构中,生成模型32可以省略。另外,如果是具有生成模型32的结构,则针对生成模型40可以省略递归性。
波形合成部50与第1实施方式相同地,根据音响特征数据F的时间序列,生成合成音的音响信号W。通过将波形合成部50生成的音响信号W供给至放音装置13,从而合成音从放音装置13进行播放。
图11是例示出第2实施方式的准备处理Sa的具体流程的流程图。与第1实施方式相同地,在每次更新乐曲数据D时执行准备处理Sa。例如,在与来自利用者的编辑的指示相对应地更新乐曲数据D时,控制装置11针对更新后的乐曲数据D而执行准备处理Sa。
如果开始准备处理Sa,控制装置11从存储装置12取得乐曲数据D(Sa21)。控制装置11通过将乐曲数据D供给至编码化模型21,从而生成与乐曲内的不同的音素对应的多个符号数据B(Sa22)。具体而言,生成乐曲整个范围的符号数据B的时间序列。控制装置11将由编码化模型21生成的符号数据B的时间序列储存于存储装置12(Sa23)。
控制装置11(期间设定部221)根据乐曲数据D和节奏Z2而设定乐曲内的各音素的单位期间σ(Sa24)。控制装置11(变换处理部222)如图9所例示的那样,根据针对多个音素的每一者而由存储装置12存储的符号数据B,生成与对应于该音素的单位期间σ内的1个以上的时间步τ相关的1个以上的中间数据Q(Sa25)。另外,控制装置11(变换处理部222)针对多个时间步τ的每一者,生成位置数据G(Sa26)。控制装置11(音高推定部223)针对多个时间步τ的每一者,生成音高数据P(Sa27)。如根据以上的说明所理解的那样,在执行合成处理Sb之前,在乐曲整个范围,针对每个时间步τ,生成中间数据Q、位置数据G和音高数据P的组。
此外,构成准备处理Sa的各处理的顺序不限定于以上的例示。例如,可以在执行针对各时间步τ的中间数据Q的生成(Sa25)及位置数据G的生成(Sa26)之前,执行音高数据P的生成(Sa27)。
图12是例示出第2实施方式的合成处理Sb的具体流程的流程图。在执行准备处理Sa之后,针对多个时间步τ的每一者而执行合成处理Sb。即,按照时间序列的顺序选择多个时间步τ的每一者作为当前步τc,针对该当前步τc而执行以下的合成处理Sb。
如果开始合成处理Sb,则控制装置11(编码化数据取得部22)如图9所例示的那样,将当前步τc的输入数据X供给至生成模型224,由此生成当前步τc的编码化数据E(Sb21)。当前步τc的输入数据X包含参照期间Ra内的多个时间步τ的每一者的中间数据Q、位置数据G和音高数据P。另外,控制装置11生成当前步τc的控制数据C(Sb22)。具体而言,控制装置11将参照期间Rb内的指示值Z1的时间序列供给至生成模型32,由此生成当前步τc的控制数据C。
控制装置11将当前步τc的输入数据Y供给至生成模型40,由此生成当前步τc的音响特征数据F(Sb23)。当前步τc的输入数据Y如前述那样,包含针对当前步τc而取得的编码化数据E及控制数据C、针对过去的多个时间步τ的每一者而生成的音响特征数据F、编码化数据E和控制数据C。控制装置11将针对当前步τc而生成的音响特征数据F与该当前步τc的编码化数据E及控制数据C一起储存于存储装置12(Sb24)。存储装置12所存储的音响特征数据F、编码化数据E和控制数据C利用于下次及其以后的合成处理Sb的输入数据Y。
控制装置11(波形合成部50)根据当前步τc的音响特征数据F,生成音响信号W的样本的时间序列(Sb25)。然后,控制装置11将针对当前步τc而生成的音响信号W供给至放音装置13(Sb26)。将以上例示出的合成处理Sb针对每个时间步τ而反复,由此与第1实施方式相同地,乐曲整个范围的合成音从放音装置13进行播放。
如以上所说明的那样,在第2实施方式,也与第1实施方式相同地,利用在乐曲内与当前步τc的后方的音素的特征相对应的编码化数据E、和与当前步τc的来自利用者的指示相对应的控制数据C,生成音响特征数据F。因此,能够生成与当前步τc的后方(未来)的乐曲的特征、和来自利用者的实时的指示相对应的合成音的音响特征数据F。
另外,在音响特征数据F的生成中利用的输入数据Y除了当前步τc的控制数据C及编码化数据E以外,还包含过去的时间步τ的音响特征数据F。因此,与第1实施方式相同地,能够生成音响特征的时间上的变迁在听觉上自然的合成音的音响特征数据F。
在第2实施方式,根据包含与多个时间步τ分别对应的2个以上的中间数据Q在内的输入数据X,生成当前步τc的编码化数据E,该多个时间步τ包含当前步τc和后方的时间步τ。因此,与根据1个中间数据Q而生成编码化数据E的结构相比,能够生成音响特征的时间上的变迁在听觉上自然的音响特征数据F的时间序列。
另外,在第2实施方式,根据输入数据X而生成编码化数据E,该输入数据X包含有表示在单位期间σ内与中间数据Q对应的位置的位置数据G、和表示每个时间步τ的音高的音高数据P。因此,能够生成适当地表现出音素及音高的时间上的变迁的编码化数据E的时间序列。
图13是第2实施方式的学习处理Sc的说明图。第2实施方式的学习处理Sc是利用多个训练数据T而创建编码化模型21、生成模型224、生成模型32和生成模型40的有教师机器学习。多个训练数据T的每一者包含乐曲数据D、指示值Z1的时间序列和音响特征数据F的时间序列。各训练数据T的音响特征数据F是表示根据该训练数据T的乐曲数据D及指示值Z1应当生成的合成音的音响特征(例如频率特性)的正确数据。
控制装置11通过执行存储装置12所存储的程序,从而除了图10例示出的各要素以外,还作为准备处理部61及学习处理部62起作用。准备处理部61与第1实施方式相同地,根据存储装置12所存储的参照数据T0而生成训练数据T。各参照数据T0是包含乐曲数据D和音响信号W的数据。各参照数据T0的音响信号W是表示与该参照数据T0的乐曲数据D对应的参照音(例如歌唱音)的波形的信号。
准备处理部61通过对各参照数据T0的音响信号W进行解析,从而生成训练数据T的指示值Z1的时间序列和音响特征数据F的时间序列。例如,准备处理部61通过对音响信号W进行解析而对表示参照音的强弱的指示值Z1进行计算。另外,准备处理部61与第1实施方式相同地,对音响信号W的频率特性的时间序列进行计算,针对每个时间步τ而生成表示该频率特性的音响特征数据F。准备处理部61利用映射信息使按照以上的流程生成的指示值Z1的时间序列和音响特征数据F的时间序列与乐曲数据D对应,由此生成训练数据T。
学习处理部62通过利用多个训练数据T的学习处理Sc,创建编码化模型21、生成模型224、生成模型32和生成模型40。图14是例示出第2实施方式的学习处理Sc的具体流程的流程图。例如,将针对操作装置14的指示作为契机而开始学习处理Sc。
如果开始学习处理Sc,则学习处理部62选择存储装置12所存储的多个训练数据T中的规定个数的训练数据T作为选择训练数据T(Sc21)。学习处理部62将选择训练数据T的乐曲数据D供给至临时性的编码化模型21(Sc22)。编码化模型21、期间设定部221、变换处理部222和音高推定部223针对乐曲数据D而动作,由此生成每个时间步τ的输入数据X。临时性的生成模型224针对每个时间步τ而生成与各输入数据X相对应的编码化数据E。此外,由期间设定部221应用于单位期间σ的设定的节奏Z2被设定为规定的基准值。
另外,学习处理部62将选择训练数据T的各指示值Z1供给至临时性的生成模型32(Sc23)。生成模型32针对每个时间步τ,生成与指示值Z1的时间序列相对应的控制数据C。通过以上的处理,包含编码化数据E及控制数据C和过去的音响特征数据F在内的输入数据Y以时间步τ为单位被供给至生成模型40。生成模型40针对每个时间步τ,生成与输入数据Y相对应的音响特征数据F。
学习处理部62对损失函数进行计算,该损失函数表示由临时性的生成模型40生成的音响特征数据F的时间序列和在选择训练数据T中包含的音响特征数据F的时间序列(即,正确值)之间的差异(Sc24)。学习处理部62反复对编码化模型21、生成模型224、生成模型32和生成模型40的每一者的多个变量进行更新,以使得损失函数减小(Sc25)。对于与损失函数相对应的变量的更新,例如利用误差逆传播法。
学习处理部62与第1实施方式相同地,对与学习处理Sc相关的结束条件是否成立进行判定(Sc26)。在结束条件不成立的情况(Sc26:NO),学习处理部62从存储装置12所存储的多个训练数据T选择未选择的规定个数的训练数据T作为新的选择训练数据T(Sc21)。即,直至结束条件的成立(Sc26:YES)为止,反复进行规定个数的训练数据T的选择(Sc21)、损失函数的计算(Sc22-Sc24)和多个变量的更新(Sc25)。在结束条件成立的情况下(Sc26:YES),学习处理部62将学习处理Sc结束。通过学习处理Sc的结束而创建编码化模型21、生成模型224、生成模型32和生成模型40。
根据通过以上例示出的学习处理Sc而创建出的编码化模型21,能够生成适当的符号数据B而用于针对未知的乐曲数据D生成统计上合理的音响特征数据F。另外,根据生成模型224,能够生成适当的编码化数据E而用于针对乐曲数据D生成统计上合理的音响特征数据F。相同地,根据生成模型32,能够生成适当的控制数据C而用于针对乐曲数据D生成统计上合理的音响特征数据F。
C:变形例
以下,例示对以上例示出的各方式附加的具体的变形方式。可以将从以下的例示中任意地选择出的2个以上的方式在不相互矛盾的范围适当地合并
(1)在第2实施方式,例示出生成歌唱音的音响信号W的结构,在生成乐器音的音响信号W时也可以相同地应用第2实施方式。在对乐器音进行合成的结构中,乐曲数据D如在第1实施方式中前述的那样,针对构成乐曲的多个音符的每一者而对持续长度d1和音高d2进行指定。即,从乐曲数据D省略音素编码d3。
(2)也可以选择性地使用利用不同的训练数据T构建出的多个生成模型40,生成音响特征数据F。例如,在多个生成模型40的每一者的学习处理Sc中利用的训练数据T是根据由不同的歌唱者或乐器发出的参照音的音响信号W而生成的。控制装置11利用多个生成模型40中的与利用者选择出的歌唱者或乐器对应的1个生成模型40,生成音响特征数据F。
(3)在前述的各方式,例示出表示合成音的强弱的指示值Z1,但指示值Z1不限定于强弱。例如,作为指示值Z1,可例示出附加于合成音的颤音(vibrato)的深度(振幅)、颤音的周期、合成音中的紧邻发音之后的起音(attack)部的强度的时间变化(即,合成音的上升沿的速度)、合成音的音色(例如清晰度)、合成音的节奏、合成音的歌唱者或演奏乐器的标识符等与合成音的条件相关的各种数值。
此外,准备处理部61在训练数据T的生成中对参照数据T0所包含的参照音的音响信号W进行解析,由此能够对以上例示出的各种指示值Z1的时间序列进行计算。例如,表示参照音的颤音的深度或周期的指示值Z1是根据音响信号W的频率特性的时间性变化进行计算的。表示参照音中的起音部的强度的时间变化的指示值Z1是根据音响信号W的信号强度的时间微分值或基本频率的时间微分值进行计算的。表示合成音的音色的指示值Z1是根据音响信号W的每个频域的强度比进行计算的。表示合成音的节奏的指示值Z1是通过公知的节拍检测技术或节奏检测技术进行计算的。也可以通过对制作者的周期性指示(例如,打拍子(Tap)操作)进行解析而对表示合成音的节奏的指示值Z1进行计算。另外,表示合成音的歌唱者或演奏乐器的标识符的指示值Z1例如与制作者的手动操作相对应地设定。另外,也可以根据乐曲数据D所包含的演奏信息而对训练数据T内的指示值Z1进行设定。例如,根据依照MIDI标准的各种演奏信息(强弱、调制轮、颤音参数或脚踏板等)对指示值Z1进行计算。
(4)在第2实施方式,例示出被加入至输入数据X的参照期间Ra包含位于当前步τc的前方的多个时间步τ和位于后方的多个时间步τ的结构。但是,还能想到参照期间Ra包含位于紧邻当前步τc之前的1个时间步τ的结构、或者包含位于紧邻当前步τc之后的1个时间步τ的结构。另外,还可采用参照期间Ra仅包含当前步τc的结构。即,也可以通过将当前步τc的中间数据Q、位置数据G和音高数据P的组作为输入数据X供给至生成模型224,从而生成该当前步τc的编码化数据E。
(5)在第2实施方式,例示出参照期间Rb包含多个时间步τ的结构,但还能设想到参照期间Rb仅包含当前步τc的结构。即,生成模型32仅根据当前步τc的指示值Z1生成控制数据C。
(6)在第2实施方式,例示出参照期间Ra包含位于当前步τc的前方及后方的多个时间步τ的结构。在以上的结构中,针对根据包含当前步τc的中间数据Q的输入数据X而生成的编码化数据E,通过生成模型224而反映出乐曲中的该当前步τc的前方及后方的特征。因此,各时间步τ的中间数据Q自身可以是仅反映出与乐曲的该时间步τ对应的特征的数据。即,对于当前步τc的中间数据Q,也可以不反映出当前步τc的前方或后方的乐曲的特征。
例如,在当前步τc的中间数据Q反映出与该当前步τc对应的1个符号的特征,但是没有反映当前步τc的前方或后方的符号的特征。中间数据Q是根据每个符号的符号数据B而生成的。符号数据B如前述那样,是表示1个符号的特征(例如,持续长度d1、音高d2及音素编码d3)的数据。
在本变形例,能够仅根据1个符号数据B而直接生成中间数据Q。例如,变换处理部222根据各符号的符号数据B,利用前述的映射信息而生成各时间步τ的中间数据Q。即,在本变形例,在生成中间数据Q时不利用编码化模型21。具体而言,在图11的步骤Sa22中,控制装置11将与乐曲内的不同的音素对应的符号数据B根据乐曲数据D的该音素的信息(例如音素编码d3)直接生成。即,在生成符号数据B时不利用编码化模型21。但是,在生成本变形例的符号数据B时可以利用编码化模型21。
此外,在本变形例,为了将位于与当前步τc对应的符号的前方或后方的1个以上的符号的特征反映至编码化数据E,与第2实施方式相比需要使参照期间Ra扩大。例如,需要将参照期间Ra确保为相对于当前步τc向前方3秒以上、或向后方3秒以上范围的程度。另一方面,根据本变形例,具有能够省略编码化模型21这一优点。
(7)在前述的各方式,例示出向生成模型40供给的输入数据Y包含过去的多个时间步τ的音响特征数据F的结构,但还能想到当前步τc的输入数据Y包含紧邻其前的1个时间步τ的音响特征数据F的结构。另外,使过去的音响特征数据F回归至生成模型40的输入的结构不是必须的。即,可以将不包含过去的音响特征数据F的输入数据Y供给至生成模型40。但是,在不使过去的音响特征数据F回归的结构中,合成音的音响特征有可能不连续地变化。因此,从生成音响特征连续地变迁的听觉上自然的合成音的观点出发,优选使过去的音响特征数据F回归至生成模型40的输入的结构。
(8)在前述的各方式,例示出音响处理系统100具有编码化模型21的结构,但编码化模型21可以省略。例如,利用音响处理系统100以外的外部装置的编码化模型21而根据乐曲数据D生成的符号数据B的时间序列可以存储于音响处理系统100的存储装置12。
(9)在前述的各方式,编码化数据取得部22生成了编码化数据E,但编码化数据取得部22也可以是从外部装置接收由该外部装置取得的编码化数据E的要素。即,编码化数据E的取得包含编码化数据E的生成和编码化数据E的接收这两者。
(10)在前述的各方式,针对乐曲的整体而执行了准备处理Sa,但也可以针对将乐曲进行了划分的多个区间的每一者而执行准备处理Sa。例如,也可以针对与音乐含义相对应地将乐曲进行了划分的多个构造区间(例如,序曲、A段、B段或副歌等)的每一者而执行准备处理Sa。
(11)可以通过在与移动电话机或智能手机等终端装置之间进行通信的服务器装置而实现音响处理系统100。例如,音响处理系统100根据从终端装置接收到的来自利用者的指示(指示值Z1及节奏Z2)和存储装置12所存储的乐曲数据D而生成音响信号W,将该音响信号W发送至终端装置。此外,在波形合成部50搭载于终端装置的结构中,由生成模型40生成的音响特征数据F的时间序列从音响处理系统100发送至终端装置。即,从音响处理系统100省略波形合成部50。
(12)以上例示出的音响处理系统100的功能如前述的那样,通过构成控制装置11的单个或多个处理器、和存储于存储装置12的程序的协同动作而实现。本发明涉及的程序可以以储存于计算机可读取的记录介质的方式提供而安装于计算机。记录介质例如是非临时性(non-transitory)的记录介质,优选是CD-ROM等光学式记录介质(光盘),还包含半导体记录介质或磁记录介质等公知的任意形式的记录介质。此外,作为非临时性的记录介质,包含除了临时性的传输信号(transitory,propagating signal)以外的任意的记录介质,也可以不将易失性的记录介质除外。另外,在传送装置经由通信网而传送程序的结构中,在该传送装置,对程序进行存储的存储装置相当于前述的非临时性的记录介质。
D:附录
根据以上例示出的方式,例如掌握以下的结构。
本发明的一个方式(方式1)涉及的音响处理方法,在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据,取得与来自利用者的实时的指示相对应的控制数据,与包含所取得的所述控制数据和所取得的所述编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。在以上的方式中,与乐曲中的当前的时间步的后方的乐曲的特征和对应于当前的时间步的来自利用者的指示的控制数据相对应地,生成音响特征数据。因此,能够生成与乐曲内的后方(未来)的特征、和来自利用者的实时的指示相对应的合成音的音响特征数据。
此外,“乐曲”通过多个符号的时间序列进行表现。构成乐曲的各符号例如是音符或音素。针对各符号,指定音高、发音时间点及音量等多种的音乐要素中的的1种以上的要素。即,各符号的音高的指定不是必须的。另外,编码化数据的取得例如包含利用映射信息的编码化数据的变换。
在方式1的具体例(方式2)中,所述多个时间步的每一时间步的所述第1输入数据包含有在过去的1个以上的时间步中生成的1个以上的所述音响特征数据。在以上的方式中,在生成音响特征数据时利用的第1输入数据除了当前的时间步的控制数据及编码化数据以外,还包含在过去的1个以上的时间步中生成的音响特征数据。因此,能够生成音响特征的时间上的变迁在听觉上自然的合成音的音响特征数据。
在方式1或2的具体例(方式3)中,在所述音响特征数据的生成中,通过将所述第1输入数据供给至机器学习完毕(训练好)的第1生成模型,生成所述音响特征数据。在以上的方式中,在生成音响特征数据时,使用机器学习完毕的第1生成模型。因此,能够基于在第1生成模型的机器学习使用的多个训练数据中潜在的倾向,生成统计上合理的音响特征数据。
在方式1至3中任一项所述的具体例(方式4)中,进一步地根据所述音响特征数据的时间序列,生成音响信号,该音响信号表示所述合成音的波形。在以上的方式中,根据音响特征数据的时间序列,生成合成音的音响信号,因此能够通过将音响信号供给至放音装置而对合成音进行播放。
在方式1至4中任一项所述的具体例(方式5)中,根据表示构成所述乐曲的符号的时间序列的乐曲数据,生成与该乐曲内的不同的符号对应的多个符号数据,所述多个符号数据的每一者是与所述乐曲中的对应于该符号数据的符号的特征和该符号的后方的符号的特征相对应的数据,在所述编码化数据的取得中,根据所述多个符号数据而取得与所述时间步对应的所述编码化数据。
在方式1至4中任一项所述的具体例(方式6)中,进一步地,根据表示构成所述乐曲的符号的时间序列的乐曲数据,生成与该乐曲内的不同的符号对应的多个符号数据,所述多个符号数据的每一者是与所述乐曲中的对应于该符号数据的符号的特征和该符号的后方的符号的特征相对应的数据,根据所述多个符号数据,生成与所述多个时间步的每一者对应的中间数据,在所述编码化数据的取得中,根据包含2个以上的中间数据的第2输入数据,生成所述编码化数据,该2个以上的中间数据与所述多个时间步中的包含当前的时间步和该时间步的后方的时间步在内的2个以上的时间步分别对应。在以上的结构中,根据包含2个以上的中间数据的第2输入数据,生成当前的时间步的编码化数据,该第2输入数据与包含当前的时间步和后方的时间步在内的2个以上的时间步分别对应。因此,与根据1个中间数据而生成编码化数据的结构相比,能够生成音响特征的时间上的变迁在听觉上自然的音响特征数据的时间序列。
在方式6的具体例(方式7)中,在所述编码化数据的取得中,通过将所述第2输入数据供给至机器学习完毕的第2生成模型,生成所述编码化数据。在以上的方式中,通过将第2输入数据供给至机器学习完毕的第2生成模型,生成编码化数据。因此,能够基于在机器学习使用的多个训练数据中潜在的倾向,生成统计上合理的编码化数据。
在方式6或7的具体例(方式8)中,在所述中间数据的生成中,利用所述符号数据而生成与该符号数据对应的符号进行发音的单位期间内的1个以上的时间步的中间数据,所述第2输入数据包含:位置数据,其表示所述2个以上的中间数据的每一者与所述单位期间内的哪个位置对应;以及音高数据,其表示所述2以上的时间步的每一者的音高。在以上的方式中,根据包含有表示在符号进行发音的单位期间内与中间数据对应的位置的位置数据、和表示每个时间步的音高的音高数据在内的第2输入数据,生成编码化数据。因此,能够生成适当地表现出符号及音高的时间上的变迁的编码化数据的时间序列。
在方式1至4中任一项所述的具体例(方式9)中,进一步地生成与所述多个时间步的每一者对应的中间数据,与所述多个时间步的每一者对应的所述中间数据是与构成所述乐曲的符号的时间序列中的对应于该时间步的符号的特征相对应的数据,在所述编码化数据的取得中,根据包含2个以上的中间数据的第2输入数据,生成所述编码化数据,该2个以上的中间数据与所述多个时间步中的包含当前的时间步和该时间步的后方的时间步在内的2个以上的时间步分别对应。
在方式6至9中任一项所述的具体例(方式10)中,在所述控制数据的取得中,根据与来自所述利用者的指示相对应的指示值的时间序列,生成所述控制数据。在以上的方式中,根据与来自利用者的指示相对应的指示值的时间序列,生成控制数据,因此能够生成与指示值的时间上的变迁相对应地适当地变化的控制数据,该指示值与来自利用者的指示相对应。
本发明的一个方式(方式11)涉及的音响处理系统具有:编码化数据取得部,其在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据;控制数据取得部,其在所述多个时间步的每一者,取得与来自利用者的实时的指示相对应的控制数据;以及音响特征数据生成部,其在所述多个时间步的每一者,与包含所取得的所述控制数据和所取得的所述编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。
本发明的一个方式(方式12)涉及的程序使计算机作为如下各部起作用:编码化数据取得部,其在时间轴上的多个时间步的每一者,取得与乐曲中的该时间步的该乐曲的特征和该时间步的后方的该乐曲的特征相对应的编码化数据;控制数据取得部,其在所述多个时间步的每一者,取得与来自利用者的实时的指示相对应的控制数据;以及音响特征数据生成部,其在所述多个时间步的每一者,与包含所取得的所述控制数据和所取得的所述编码化数据在内的第1输入数据相对应地,生成音响特征数据,该音响特征数据表示合成音的音响性特征。
标号的说明
100…音响处理系统,11…控制装置,12…存储装置,13…放音装置,14…操作装置,21…编码化模型,22…编码化数据取得部,221…期间设定部,222…变换处理部,223…音高推定部,224…生成模型,31…控制数据取得部,32…生成模型,40…生成模型,50…波形合成部,61…准备处理部,62…学习处理部。
- 音响处理系统、音响处理方法及程序
- 音响处理方法、推定模型的训练方法、音响处理系统及程序