面向中文金融文本的嵌套和不连续实体的命名实体识别系统
文献发布时间:2023-06-19 18:34:06
技术领域
本发明属于金融文本的自然语言处理技术领域,具体涉及针对中文金融文本中的深层嵌套实体和不连续实体的识别技术。
背景技术
命名实体识别主要指从非结构自然语言文本中识别出文本语料中的人名、地名等领域专有名词,常被视作序列化标注问题,可以分为实体边界识别与实体分类两个步骤。金融领域不同于一般领域,文本本身便存在语义信息复杂等问题,而命名实体识别作为NLP(自然语言处理)领域的基础任务,识别结果又严重影响着下游任务的效果。金融领域中文命名实体识别存在以下特点:文本结构复杂,形式多样;高频存在不规则实体缩写,专业词典匮乏;金融实体长度较长且往往存在深层嵌套的问题使得边界不容易识别。比如“中国银行北京分行”,其中嵌套着“中国银行”、“北京分行”等同类型实体或“中国”、“北京”不同类型的名词实体。
目前多采用深度学习神经网络对文本实体进行识别,如下所述:
(1)基于Embedding模型的方式。词向量模型旨在将金融领域自然语言文本中的词转换为稠密的词向量,Word2vec模型通过词的上下文得到向量化表达,然而由于其只考虑了词语的局部信息,GloVe(Global Vectors)在此基础上同时考虑全局信息,利用全局词频统计进行词表征。2018年Google提出的BERT模型具有里程碑意义,它同GPT(Gererate Pre-Training Model,生成式预训练语言模型)一样采取两阶段训练过程,其输入包括三部分——token embedding(分词编码)、position embedding(位置编码)、segmentembedding(段落编码)。后续通过Masked Language Model(掩码语言模型)任务让网络预测被隐藏掩盖的信息;Next Sentence Prediction(下一句预测)任务预测第二句是否是下一句的任务进而获得句子级表征的能力。
(2)基于LSTM(长短时记忆神经网络)模型的方式。长短时记忆神经网络作为一种经典的RNN(循环神经网络)模型以捕获上下文语义信息,在NLP序列任务中始终展现着优越性能。其关键就是单元状态(cell state),利用门控机制控制信息流从上一个cell传递给下一个cell。一个LSTM cell有三个门—遗忘门(forget gate)、输入门(input gate)、输出门(output gate),实现遗忘或增加信息,具体通过一个sigmoid函数和一个点乘操作实现。在金字塔层叠式模型中使用LSTM神经网络能学习并长期保存上下文语义信息,有效捕捉不同长度的嵌套实体。
目前所采用的深度学习神经网络对识别金融文本中的复杂嵌套实体和不连续实体的效果不佳,采用分层识别模型识别时存在层与层之间的错误传播问题,前面的层识别出的错误实体会继续影响后续层的识别,如由内而外识别实体,但先识别出最外层的实体,则内部实体将不再被识别出。除此之外,目前的方法普遍未考虑到复杂实体的划分粒度更细,会造成数据稀疏的问题,加大了命名实体识别的难度。
发明内容
针对金融文本中的复杂嵌套实体和不连续实体的识别问题,本发明提出了一种面向中文金融文本的嵌套和不连续实体的命名实体识别系统,采用一种金字塔层叠式模型,解决中文金融文本的命名实体识别问题,同时实现对复杂嵌套实体和不连续实体的识别,对于语法不规范、出现频率较低的实体,还利用语义增强表示增强识别结果,缓解数据稀疏和表达不规范所造成的实体识别不准确的问题。
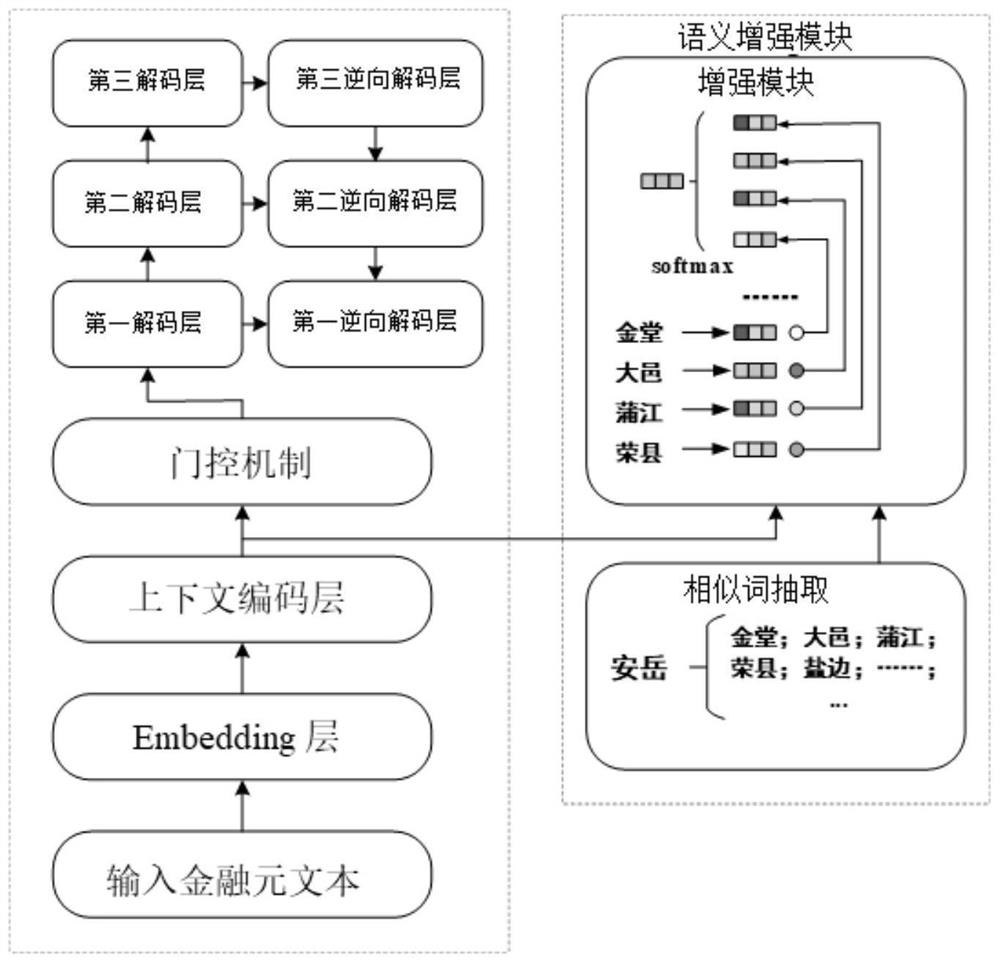
具体地,本发明提供了一种面向中文金融文本的嵌套和不连续实体的识别系统,包括如下三个模块:词嵌入编码模块、语义增强模块、金字塔层叠式解码模块。将采集的中文金融文本进行清洗和分词后输入所述识别系统。
所述词嵌入编码模块对输入的金融元文本中的字进行编码,利用上下文编码层获取上下文特征,获取词向量,最后输出金融元文本的词嵌入向量给语义增强模块。
所述语义增强模块包含增强模块与门控机制;针对输入的金融元文本的词嵌入向量,增强模块基于余弦相似度计算与当前词语义最相似的前m个词,将相似词映射到另一个嵌入矩阵中,m为正整数。同时,基于上下文引入注意力机制获取每个相似词对当前词语义信息的贡献度,对m个相似词嵌入向量加权求和。将各词扩充语义后得到的加权求和的相似词嵌入向量与当前词嵌入向量利用门控机制进行加权拼接,最终得到当前词语义增强后的嵌入向量,输入金字塔层叠式解码模块中。
所述金字塔层叠式解码模块包括L层内部连接的解码层,每一解码层预测长度为l的实体,第L层识别长度为L的嵌套实体,L为正整数;每一解码层都由LSTM和CNN(卷积神经网络)两个组件组成,LSTM用于识别实体,CNN用于聚合两个相邻分词的隐层状态,然后将当前聚合得到的嵌套实体的语义信息送入更高的解码层。同时,为了避免高层识别长实体时对底层信息的遗漏,所述金字塔层叠式解码模块还将逆向的金字塔模型与正向的金字塔模型进行拟合。标记逆向金字塔模型中解码层为逆向解码层,正向金字塔模型中解码层为正向解码层,通过连接正向解码层与逆向解码层的状态,利用前馈神经网络预测实体最终的分类。
相对于现有技术,本发明的优点与积极效果在于:
(1)由于金融数据集的多源性,不同来源数据的结构大相径庭,甚至相当部分的文本存在不规范的表达方式。除此之外,还有一些词语出现的频率较低,不能准确地给出词向量表示。因此本发明系统设计了语义增强模块,进行语义信息的深层编码和聚合,改善表达不准确实体的抽取结果。
(2)金融领域中复杂嵌套实体的识别在之前虽已有工作通过堆叠传统的NER层解决嵌套问题,但是容易在错误的嵌套层识别出嵌套实体,虽然span和分类可能正确,但是会致使模型逐渐趋向不预测正确的实体,最终严重破坏召回率。本发明系统设计了金字塔层叠式模型,改善了对嵌套实体识别的准确性,以及对不连续实体识别的问题,还采用逆向的金字塔模型实现信息流的反向流动,有效改善了金融领域嵌套实体和不连续实体识别的困境,提升了对中文金融领域实体识别的准确率。
(3)经试验证明,本发明识别系统相较于现有技术,在识别中文金融文本中嵌套实体和不连续实体方面展现出优越性能,采用本发明识别系统能提升对中文金融领域实体识别的准确率。
附图说明
图1是本发明系统识别不连续实体和嵌套实体的一个整体流程示意图;
图2是本发明实施例的面向中文金融文本的嵌套和不连续实体的识别系统的结构图;
图3是本发明识别嵌套实体与不连续实体的一个示例图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明实施例从数据的采集与预处理,设计构建面向中文金融文本的嵌套和不连续实体的识别系统,使用本发明系统进行实体识别的结果分析,这三方面来进行说明。采用本发明识别系统进行实体识别的一个流程如图1所示,对金融数据预处理后输入本发明识别系统,通过词嵌入编码模块、语义增强模块和金字塔层叠式解码模块处理后,识别嵌套和不连续实体,对本发明识别系统的识别结果还可以进一步融合人工设计的规则提升精确率。
国内金融市场的非结构化文本大量存在于公司公告、新闻、股评中等等,形式结构往往多样复杂。针对金融领域实体抽取数据集匮乏的问题,本发明实施例所采集到的数据来源于同花顺网站的金融资讯,数据集涵盖公司以及实体人之间的股权关系如质押、持股、股份股权转让等信息,数据较为全面,对于将本发明实体关系识别模型迁移到更大领域具有借鉴意义。在采集到数据后,为了下一步的嵌入表示,需要先进行数据清洗,再利用专业的分词工具进行数据的初步处理。本发明采集的大量金融文本数据,涵盖了公司、实体人、股份等多种类型实体。
利用上面的分词工具分词后,得到词向量表示的金融元文本,然后将金融元文本输入识别系统中。本发明的面向中文金融文本的嵌套和不连续实体的识别系统包括词嵌入编码模块、语义增强模块和金字塔层叠式解码模块,识别系统的一个实现示例如图2所示,下面说明各模块的实现。
词嵌入(embedding)编码模块对输入的每条金融元文本,充分考虑字和词的上下文语义信息,将拼接后的字嵌入向量与词向量共同表示金融元文本。首先通过预训练词嵌入,本发明实施例采用Tencent Embedding,找到每个字符所对应的预训练向量,原始文本将会初始化为分布式的向量。然后将得到的分布式向量输入到上下文编码层LSTM以学习到文本的上下文特征;针对词向量,通过预训练好的词向量矩阵进行表示;最后通过一个线性层降低词嵌入编码模块的嵌入向量维度。
由于金融数据集的多源性,不同来源数据的结构大相径庭,甚至相当部分的文本存在不规范的表达方式。除此之外,还有一些词语出现的频率较低,不能准确地给出词向量表示,因此本发明设计利用语义增强模块进行语义信息的深层编码和聚合,改善表达不准确实体的抽取结果。以往的自然语言文本通常经过单一的预训练语言模型进行向量的表示,虽然能捕捉有效的上下文语义信息,但无法识别表达不合规范的金融实体。而预训练语言模型表示的词嵌入向量是NER任务取得良好性能的重要前提,也是语义增强表示的关键资源。
本发明的语义增强模块,也叫语义扩充模块,包含增强模块与门控机制。针对上一模块输出的每个词嵌入表示,增强模块基于余弦相似度计算与当前词语义最相似的前m个词,将相似词映射到另一个嵌入矩阵中,同时,基于上下文引入注意力机制区分每个词对当前词语义信息贡献的重要程度,最终得到当前词扩充语义后的表示。进一步,语义增强模块采用复位门控制通过的信息,再通过两个可训练矩阵平衡相似向量和原向量的权重,最终得到语义增强后的向量。
本发明实施例中,语义增强模块首先针对金融元文本词序列里的每个词,在大型语料库腾讯词向量Tencent embedding里找到与当前词相似度最高的前m个词语,并利用另一个嵌入矩阵进行映射。m为正整数。
针对一段由n个词组成的金融元文本w={w
其中,h
获得词w
之后通过门控机制控制加权后的信息流输入到后续的金字塔层叠式解码模块中。设门控机制中W
g=σ(W
其中,1表示元素为1的矩阵。
金融领域中复杂嵌套实体的识别在之前虽已有工作通过堆叠传统的NER(NamedEntity Recognition,命名实体识别)层解决嵌套问题,但是容易在错误的嵌套层识别出嵌套实体,虽然实体对应的位置标签span和分类可能正确,但是会致使模型逐渐趋向不预测正确的实体,最终严重破坏召回率。因此,本发明设计了金字塔层叠式解码模块,该模块的模型中共由L层内部连接层(即解码层)构成,每一解码层预测长度为l的实体,由于l的限制,识别模型便不会在错误层生成不对应的实体。每一层的命名实体识别组件都由两个组件——LSTM和CNN(卷积神经网络)组成,LSTM负责识别实体,CNN则聚合两个相邻分词的隐层状态,然后将丰富的语义信息送入更高层的解码层,由此还改善了不连续实体识别的问题。层数越高,识别的实体长度越长,为了使实体能接受更高层的信息反馈,金字塔层叠式解码模块还拟采用逆向的金字塔模型实现信息流的反向流动,有效改善了金融领域嵌套实体和不连续实体识别的困境,提升识别准确率。
如图3所示,最底层负责识别长度为1的token,如“中国”、“北京”、“重庆市”等。第L层负责识别长度为L的嵌套实体,由于L的限制,金字塔模型不会在错误的层输出不对应的实体。LSTM模型能充分捕捉前后文语义信息,根据上下文识别出不连续实体如“中国银行重庆市分行”。除此之外借助底层聚合隐层状态的CNN网络,还能捕获全部重叠的嵌套实体。层数越高,识别的实体长度越长,考虑到信息流经过多层传递易造成高层识别长实体时信息的遗漏,因此,本发明的金字塔层叠式解码模块最后融合正向与逆向的金字塔模型,充分利用高层的span对下层的反馈信息。
在金字塔层叠式解码模块中,语义增强模块输出的嵌入向量先进入自底向上的金字塔层叠解码模块的底层。每个解码层的命名实体识别组件由一个LSTM和一个CNN组成。在第l层需要LSTM进行长度l的实体识别,如在第2层识别跨度为2的实体,如图3中的“中国银行”、“杭州分行”、“重庆市分行”等等。这样保证目标解码层每一层任务清晰,不会识别出错误跨度的实体。卷积神经网络CNN包含两个卷积核,负责将相邻实体隐藏状态进行聚合,输入更高一层,即第(l+1)层。
其中,h
由于第一层解码层输入来源是语义增强模块,相比其他输入上下层间的输出,维度不一致。因此为了解决该问题,本发明对语义增强模块输出的嵌入向量先进行归一化,再进入第一解码层的LSTM。
自底向上的金字塔模型中每个解码层都考虑了来自下层的信息,但是高层的长实体识别嵌入的识别往往需要经过较多底层信息,在这个传递过程会丢失许多重要的信息。为了捕获高层的信息流对下边的反馈,加强相邻解码层交互性的同时保留长实体信息,本发明在模型中加入逆向的金字塔模型。具体地,针对第l-1层的文本嵌入的重构,将第l层的正解码层和反解码层的隐藏状态连接起来,并将其输入反向CNN,如下表示:
其中,h′
最终通过连接正向解码层(decoding layer)与逆向解码层(inverse decodinglayer)的状态,利用前馈神经网络预测实体最终的分类,有效解决了实体深层嵌套与不连续的问题。
logits
其中,logits
针对金融复杂场景下的金融命名实体识别任务,对本发明的层叠式模型进行实验,结果如下表1所示。
表1对本发明进行试验结果对比
如表1所示,使用ACE2005中文数据集和人民日报数据集,分别对本发明模型和对比模型进行试验,对比模型包括:Pyramid模型和Jin模型。Pyramid模型、Pyramid+Bert模型在参考文献1(Wang J,Shou L,Chen K,et al.Pyramid:A Layered Model for NestedNamed Entity Recognition[C]//Proceedings of the 58th Annual Meeting of theAssociation for Computational Linguistics.2020.)中记载。Jin模型、baseline+Bert模型在参考文献2(Liao Z,Zhang Z,Yang L.Chinese Named Entity Recognition Basedon Hierarchical Hybrid Model[C]//Pacific Rim International Conference onTrends in Artificial Intelligence.Springer-Verlag,2010.)中记载。BERT为预训练语言模型,用来分词表示。
计算精确率(precision)、召回率(recall)以及F1分数三个评价指标,其中,F1值越大表示算法性能越好,精确率越大表示算法性能越好,召回率越大表示算法性能越好。由表1可以看出,采用本发明识别系统相较于现有技术,在这些评价指标上能取得更好的效果,相较其他模型在识别嵌套实体和不连续实体方面展现出优越性能,提升了对中文金融领域实体识别的准确率。
除说明书所述的技术特征外,均为本专业技术人员的已知技术。本发明省略了对公知组件和公知技术的描述,以避免赘述和不必要地限制本发明。上述实施例中所描述的实施方式也并不代表与本申请相一致的所有实施方式,在本发明技术方案的基础上,本领域技术人员不需要付出创造性的劳动即可做出的各种修改或变形仍在本发明的保护范围内。
- 面向大规模医疗文本挖掘的中文分词和命名实体识别系统
- 面向大规模医疗文本挖掘的中文分词和命名实体识别系统