一种科技大数据智能决策分析方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于决策分析方法技术领域,具体涉及一种科技大数据智能决策分析方法。
背景技术
目前,云计算平台也称为云平台,其中,以数据存储为主的存储型云平台、以数据处理为主的计算型云平台以及计算和数据存储处理兼顾的综合云计算平台都属于云计算平台的范畴,云计算服务平台利用大数据的处理功能来满足人们不同的请求,给人们提供服务。
现今市场上的此类云计算服务平台种类繁多,基本可以满足人们的使用需求,但是依然存在一定的不足之处。
通过上述分析,现有技术存在的问题及缺陷为:
(1)在统一运维上的缺陷:科技政务大数据是一个体系化工程,涉及到大量的系统建设和持续运维,随着政务应用的多样化发展,应用的规模也越来越庞大、应用的结构也越来越复杂,需要更加精细的运维工作来保障系统安全稳定地运行。传统政务系统建设后的运维工作,往往由承建厂商各自承担,运维管理工作复杂效率低、机制不健全、出现问题推诿扯皮的现象严重。
(2)数据互通上的缺陷:当前政务大数据建设仍然存在信息共享的难题,信息孤岛问题仍然广泛存在。过去的项目制建设模式导致数据分散在各个部门,受到条线分割、各自为政的束缚,垂直管理部门的数据集中在国家、省级数据中心,需要协调上级机关;部分单位将数据看成私有财产,以安全为理由,不提供或少提供、晚提供;有些单位的数据质量不高,因为是“谁提供谁负责”,所以不太敢提供,各委办局从自身利益和风险出发,不太愿意主动提供数据,不要不给,要了不一定给;由于数据的提供方和使用方之间可能存在的多次数据中转,数据的实时性、鲜活性和权威性也无法得到保障。
(3)在数据标准化上的缺陷:通过多年来各种政务系统的建设,政府部门已经沉淀了大量的数据,但数据应用、数据服务、数据资产的管理基本处于空白状态,大量数据存储于excel/word等电子文档中,还有部分数据是纸质版数据。这些数据并不能够直接被程序所使用,部门之间调用数据往往需要重复采集、重复录入等问题,严重浪费人力物力。业务系统使用数据时需要统一采集、加工、清洗、治理,通过一系列标准化的数据治理后方可使用,由于数据格式、数据结构不同,治理后的数据依旧无法实现共享。
(4)在快速构建应用上的缺陷:传统的应用系统开发包括前端、后端、数据库、中间件及服务器的开发,都需要大量的产品研发人员写代码实现,普遍存在人员成本高、研发效率低下、扩展能力弱、运维成本高等缺点,基本无法及时响应客户需求。
(5)在标准体系上的缺陷:在政务大数据建设过程中,各厂商都有自己的架构规范和设计标准,各厂商之间在技术标准规范、架构标准规范、数据标准规范、平台工具技术标准、数据安全标准互不相同,这种情况会对后期系统建设中各系统的数据对接、接口调用、工具标准、安全建设等方面造成巨大隐患,普遍存在“对不上、接不了、用不好”等问题,是间接造成信息孤岛的元凶。
发明内容
针对上述的技术问题,本发明提供了一种效率高、适用范围广、误差小的科技大数据智能决策分析方法。
为了解决上述技术问题,本发明采用的技术方案为:
一种科技大数据智能决策分析方法,包括下列步骤:
S1、对整体平台的数据进行采集;
S2、对整体平台的采集的数据进行治理;
S3、对数据进行整合处理。
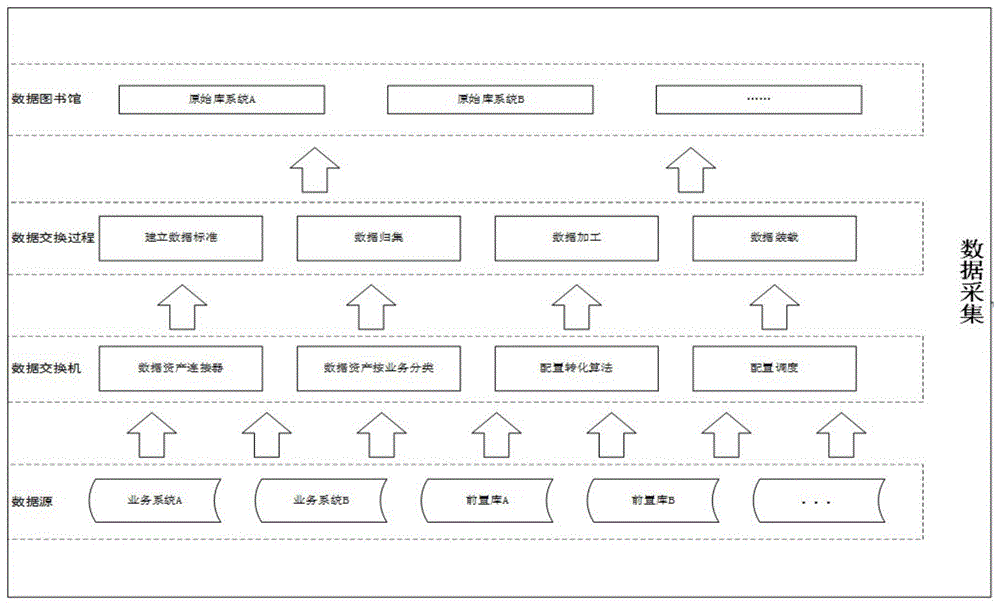
所述S1中对整体平台的数据进行采集的方法为:从中间库或前置机数据库中采集数据,按照定义好的数据交换方式生成数据包,由定制好的发送路由发送给接收方;接收方接收到数据包后自动进行解包处理,并将数据存储到接收方的前置机交换数据库中;采集内容主要分为:全量采集、增量采集。采集方式主要分为:触发器方式、时间戳方式、全表删除插入方式、全表比对方式。采集工具主要分为:ftp文件传输、数据导入工具、WebService接口;通过建立数据标准、数据归集、数据加工、数据装载,依据不同的业务场景,将采集的数据进行分类,包括结构化数据、非结构化数据、半结构化数据,存储于原始库中。
所述S2中对整体平台的采集的数据进行治理的方法为:通过数据采集装置进行源数据的采集,利用大数据处理技术对原始库数据中的脏数据、重复数据、错误数据进行治理优化,治理完成后,利用大数据算法技术实现数据的标准化,进而快速实现数据治理。
所述利用大数据处理技术对原始库数据中的脏数据、重复数据、错误数据进行治理优化的方法为:对业务数据中不符合标准规范或者无效的数据进行过滤操作,根据采集数据的来源不同,配置不同的数据清洗流程,包括数据过滤和数据去重。
所述数据过滤的方法为:选择数据过滤,选择相应的字段配置对应的过滤规则进行过滤,并通过打标签的方式进行标记识别:手机号的标准规则及过滤;统一社会信用代码的标准规则及过滤;身份证的标准规则及过滤;姓名过滤的标准规则及过滤。
所述数据去重的方法为:去掉重复数据,保证唯一性,根据相关业务属性通过时间/自增主键确定数据更新顺序的字段排序后配置剔重,选择相应的字段做为去重的条件;排序规则为:自增主键顺序;数据更新时间戳顺序;业务流水号顺序;其他可确定重复数据更新顺序;判断去重的依据;然后判断每一个字段是否可以出现重复情况,否则需要去重。
所述利用大数据算法技术实现数据的标准化的方法为:包括下列步骤:
S2.1、标准化处理阶段,结合数据标准管理,整理已定义的数据元素、数据字典、相关标准规范和业务流程,在元数据管理模块中进行先期维护,对数据内容、使用范围、使用方式、质量、更新方式、更新周期、数据来源、负责单位、数据提供方、存储位置、处理逻辑、数据格式等内容进行统一管理,用以管理汇聚接入的数据资源;
S2.2、与标准数据元库的对接,同时按照标准数据元同步更新机制,可通过手动或系统自动导入的方式,将标准数据元同步至本地数据元库中。本地数据元库存放本地数据元和标准数据元;
S2.3、依托数据元标准校验规则,对本地数据元进行数据标准化的规范校验,即把本地数据元所有真实数据字段与标准数据元进行比对并形成相关的结果报告。
所述S3中对数据进行整合处理的方法为:包括下列步骤:
S3.1、数据清洗转化,数据清洗过程主要是对业务数据中不符合标准规范或者无效的数据进行过滤操作,根据采集数据的来源不同,进行不同的数据清洗;在进行数据整合之前先定义数据的清洗规则,并对符合清洗规则的数据设置数据的错误级别;当进行数据整合过程中遇到符合清洗规则的数据时,系统将把这些业务数据置为问题数据,并根据错误的严重程度进行归类,并与数据质量管理相结合,完善数据治理流程,拓展数据分析范围,建立异常数据查找分析模型;
S3.2、数据装载,数据装载是根据大数据标准库结构,将经过整合后的数据插入到相应的数据表中;数据装载过程进行的主要操作是插入操作和修改操作;数据装载在系统完成了更新之后进行,在数据库中的数据来自多个相互关联的操作系统,则将保证在这些系统同步工作时移动数据;
S3.3、数据校验,数据校验过程是基于整合完成后的业务数据进行数据校验,数据校验是通过数据质量分析工具对已经建成的标准库的数据进行的校验操作。
所述S3.2中数据装载的方法包括:基本装载、追加装载、破坏性合并和建设性合并;
所述基本装载为:按照装载的目标表,将转换的过的数据输入到目标表中去;若目标表中已有数据,装载时会先删除这些数据,再装入新数据;
所述追加装载为:如果目标表中已经存在数据,在保存已有的数据的基础上增加新的数据;当一个输入的数据记录与已经存在的记录重复时,输入记录可能会作为副本增加进去,或者丢弃新输入的数据;
所述破坏性合并为:如果输入数据记录的主键与一条已经存在的记录的主键相匹配,则用新输入数据更新目标记录数据;如果输入记录是一条新的记录,没有任何与之匹配的现存记录,那么就将这条输入的记录添加到目标表中;
所述建设性合并为:输入的记录主键与已有的记录的主键相匹配,则保留已有的记录,增加输入的记录,并标记为旧记录的替代。
所述S3.3中数据校验的方法为:
S3.3.1、数据从业务系统数据库采集到大数据过程数据库时,都要进行相应的数据标准校验;在实时数据核验方面,需要支持接入数据的关键信息、唯一性信息的日志存储和查询统计;
S3.3.2、对于接入要求可靠性、一致性要求高的数据,将提供数据同步检查和校验功能,并输出详细日志;
S3.3.3、支持一定时间范围的接入状态统计,包括对数据更新、联通状态、数据量、校验情况的统计。
本发明与现有技术相比,具有的有益效果是:
1、本发明从中间库或前置机数据库中采集数据,按照定义好的数据交换方式生成数据包,由定制好的发送路由发送给接收方。接收方接收到数据包后自动进行解包处理,并将数据存储到接收方的前置机交换数据库中。采集内容主要分为:全量采集、增量采集。采集方式主要分为:触发器方式、时间戳方式、全表删除插入方式、全表比对方式。依据不同的业务场景,将采集的数据进行分类,包括结构化数据、非结构化数据、半结构化数据。为数据治理装置提供接入、处理和驱动各种类型数据的能力,通过多引擎共同协作,实现对接入的结构化数据、非结构化数据、半结构化数据进行快速融合的能力。
2、本发明建立规范的数据管理体系、数据应用体系,将流程、策略、标准通过业务和技术相结合的方式进行有效组合,实现对平台数据有效管理,挖掘和提升数据价值。其中,数据管理体系以源数据和数据资产为核心管理对象,构建数据处理框架和数据管理机制,并通过数据管理流程和数据管理团队予以支撑和规范,面向应用体系提供标准的、可靠的、及时的对外数据服务能力;数据应用体系通过构建数据应用体系,融合数据资产和数据服务,打造典型数据应用场景,实现各应用领域的全面化支撑。
3、本发明通过接入数据治理装置治理后的标准化数据,对数据进行多维度的统计分析,最终形成分析报表。本发明在使用时不需要代码开发,仅需要通过拖拉拽的方式即可构建,简单易用,可扩展性好。
附图说明
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引申获得其它的实施附图。
本说明书所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容能涵盖的范围内。
图1为本发明数据采集的流程框图;
图2为本发明数据治理的流程框图;
图3为本发明数据整合的流程框图;
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例,这些描述只是为进一步说明本发明的特征和优点,而不是对本发明权利要求的限制;基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
下面结合附图和实施例,对本发明的具体实施方式做进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
在本实施例中,如图1-3所示,包括下列步骤:
步骤一、对整体平台的数据进行采集。从中间库或前置机数据库中采集数据,按照定义好的数据交换方式生成数据包,由定制好的发送路由发送给接收方;接收方接收到数据包后自动进行解包处理,并将数据存储到接收方的前置机交换数据库中;采集内容主要分为:全量采集、增量采集。采集方式主要分为:触发器方式、时间戳方式、全表删除插入方式、全表比对方式。采集工具主要分为:ftp文件传输、数据导入工具、WebService接口;通过建立数据标准、数据归集、数据加工、数据装载,依据不同的业务场景,将采集的数据进行分类,包括结构化数据、非结构化数据、半结构化数据,存储于原始库中。
步骤二、对整体平台的采集的数据进行治理。通过数据采集装置进行源数据的采集,利用大数据处理技术对原始库数据中的脏数据、重复数据、错误数据进行治理优化,治理完成后,利用大数据算法技术实现数据的标准化,进而快速实现数据治理。
利用大数据处理技术对原始库数据中的脏数据、重复数据、错误数据进行治理优化的方法为:对业务数据中不符合标准规范或者无效的数据进行过滤操作,根据采集数据的来源不同,配置不同的数据清洗流程,包括数据过滤和数据去重。
数据过滤的方法为:选择数据过滤,选择相应的字段配置对应的过滤规则进行过滤,并通过打标签的方式进行标记识别:手机号的标准规则及过滤;统一社会信用代码的标准规则及过滤;身份证的标准规则及过滤;姓名过滤的标准规则及过滤,具体数据过滤方式如表1所示。
表1
数据去重的方法为:去掉重复数据,保证唯一性,根据相关业务属性通过时间/自增主键确定数据更新顺序的字段排序后配置剔重,选择相应的字段做为去重的条件;排序规则为:自增主键顺序;数据更新时间戳顺序;业务流水号顺序;其他可确定重复数据更新顺序;判断去重的依据;然后判断每一个字段是否可以出现重复情况,否则需要去重。
利用大数据算法技术实现数据的标准化的方法为:包括下列步骤:
标准化处理阶段,结合数据标准管理,整理已定义的数据元素、数据字典、相关标准规范和业务流程,在元数据管理模块中进行先期维护,对数据内容、使用范围、使用方式、质量、更新方式、更新周期、数据来源、负责单位、数据提供方、存储位置、处理逻辑、数据格式等内容进行统一管理,用以管理汇聚接入的数据资源;
与标准数据元库的对接,同时按照标准数据元同步更新机制,可通过手动或系统自动导入的方式,将标准数据元同步至本地数据元库中。本地数据元库存放本地数据元和标准数据元;
依托数据元标准校验规则,对本地数据元进行数据标准化的规范校验,即把本地数据元所有真实数据字段与标准数据元进行比对并形成相关的结果报告。
步骤三、对数据进行整合处理。
数据清洗转化,数据清洗过程主要是对业务数据中不符合标准规范或者无效的数据进行过滤操作,根据采集数据的来源不同,进行不同的数据清洗;在进行数据整合之前先定义数据的清洗规则,并对符合清洗规则的数据设置数据的错误级别;当进行数据整合过程中遇到符合清洗规则的数据时,系统将把这些业务数据置为问题数据,并根据错误的严重程度进行归类,并与数据质量管理相结合,完善数据治理流程,拓展数据分析范围,建立异常数据查找分析模型。
数据转换的过程包括数据格式转换、代码转换和值转换等数据转换方式,满足采购人数据中心数据转换要求。数据源多样,这些数据库当初在建立的过程中并没有考虑到统一数据格式或者代码规范,为了保证标准库数据的规范和一致,有必要在数据整合过程中对数据进行相应的转换,具体数据转换方式如表2所示。例如,将人员的出生日期统一为八位的字符日期的转换属于格式转换,将人员的性别数据统一转换为国标性别代码为代码转换,将人的身份证号统一转换为18位的身份证号为值转换。
/>
表2
数据装载,数据装载是根据大数据标准库结构,将经过整合后的数据插入到相应的数据表中;数据装载过程进行的主要操作是插入操作和修改操作;数据装载在系统完成了更新之后进行,在数据库中的数据来自多个相互关联的操作系统,则将保证在这些系统同步工作时移动数据。
数据装载的方法包括:基本装载、追加装载、破坏性合并和建设性合并;
基本装载为:按照装载的目标表,将转换的过的数据输入到目标表中去;若目标表中已有数据,装载时会先删除这些数据,再装入新数据;
追加装载为:如果目标表中已经存在数据,在保存已有的数据的基础上增加新的数据;当一个输入的数据记录与已经存在的记录重复时,输入记录可能会作为副本增加进去,或者丢弃新输入的数据;
破坏性合并为:如果输入数据记录的主键与一条已经存在的记录的主键相匹配,则用新输入数据更新目标记录数据;如果输入记录是一条新的记录,没有任何与之匹配的现存记录,那么就将这条输入的记录添加到目标表中;
建设性合并为:输入的记录主键与已有的记录的主键相匹配,则保留已有的记录,增加输入的记录,并标记为旧记录的替代。
数据校验,数据校验过程是基于整合完成后的业务数据进行数据校验,数据校验是通过数据质量分析工具对已经建成的标准库的数据进行的校验操作。
数据校验的方法为:
数据从业务系统数据库采集到大数据过程数据库时,都要进行相应的数据标准校验;在实时数据核验方面,需要支持接入数据的关键信息、唯一性信息的日志存储和查询统计。
对于接入要求可靠性、一致性要求高的数据,将提供数据同步检查和校验功能,并输出详细日志。
支持一定时间范围的接入状态统计,包括对数据更新、联通状态、数据量、校验情况的统计。
上面仅对本发明的较佳实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化,各种变化均应包含在本发明的保护范围之内。
- 一种基于大数据的农业科技服务智能分拣方法
- 一种基于大数据和人工智能的个体亚健康状态评估方法
- 一种基于大数据的农业科技服务智能分拣方法
- 一种基于大数据的科技服务智能匹配、推荐的方法