一种基于人工智能的数字图像识别方法及相关设备
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及图像识别技术领域,具体为一种基于人工智能的数字图像识别方法及相关设备。
背景技术
图像识别技术是人工智能的一个重要领域。它是指对图像进行对象识别,以识别各种不同模式的目标和对像的技术,图像识别技术可能是以图像的主要特征为基础的,而这些图像一般通过扫描仪等图像扫描设备将图像扫描,将图片信息转换为文本的信息。
而现有的基于人工智能的数字图像识别设备在使用的过程中,由于图像不仅有由打印机等设备打印出的图像文件,也有使用人员手写出的图像文件,导致数字图像设备在扫描完成后容易发生识别错误的现象,且目前的数字图像识别设备的扫描设备往往为固定位置,当扫描的文件或书本较大时,无法较好的完整的将其进行一次性扫描完成,影响使用。
为此,提出一种基于人工智能的数字图像识别方法及相关设备。
发明内容
本发明的目的在于提供一种基于人工智能的数字图像识别方法及相关设备,通过控制机构控制传动环和方形框的固定与放松,并由传动环上缠绕的传动带带动一号转动轴和二号转动轴,使识别设备可以便捷的进行纵向和横向位置的调整的同时,还可以保证其上扫描设备在调整的过程中保持水平,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于人工智能的数字图像识别设备,包括机底座,所述机底座的顶部固定安装有支撑板,所述支撑板的一侧安装有控制机构,所述控制机构包括固定安装在支撑板一侧的支撑环,所述支撑环的外表面安装有调节机构,所述调节机构的一侧安装有扫描设备,所述调节机构包括活动安装在支撑环外表面的支撑框,所述支撑框的一侧贯穿开设有限位槽,所述支撑环的外表面且位于支撑框的内部转动安装有传动环,所述支撑框内部的顶部转动安装有一号转动轴,所述支撑框内部的底部转动安装有二号转动轴,所述一号转动轴的外表面固定安装有支撑块,所述支撑块的一侧延伸至支撑框的外部,所述支撑块的一侧与扫描设备固定连接,所述传动环的外表面缠绕有传动带,所述一号转动轴和二号转动轴的外表面均通过传动轮与传动带的内表面传动连接。
优选的,所述控制机构包括滑动安装在支撑环内部的圆台柱,所述圆台柱远离支撑板的一侧固定安装有方形框,所述方形框和圆台柱的一侧均贯穿开设有圆形孔。
优选的,两个所述圆形孔之间转动安装有同一个螺纹柱,所述螺纹柱的一侧延伸至支撑板的内部,所述螺纹柱的外表面与支撑板的内表面螺纹连接。
优选的,所述支撑环远离支撑板的一端等距固定安装有若干挤压块,所述挤压块的内表面与圆台柱的外表面滑动连接,所述挤压块的外表面与传动环的内表面活动连接。
优选的,所述方形框的外表面与限位槽的内表面滑动连接,所述支撑板的一侧开设有环形齿槽。
优选的,所述方形框内部的两侧均滑动安装有齿块,所述齿块的一侧延伸至方形框的外部。
优选的,所述齿块的另一侧固定安装有弹簧,所述弹簧的一侧与方形框的内壁固定连接,所述齿块的外表面与环形齿槽的内表面活动连接。
一种基于人工智能的数字图像识别方法,其具有上述所述的基于人工智能的数字图像识别设备,包括以下步骤:
S1、通过数字图像识别设备将文件图像进行扫描,将扫描出的所述文件图像信息通过小波变换的方法将光学信号转换为数字信号,并对文件图像信息进行预处理,得到整体数字图像;
S2、将预处理后的文件图像信息的数字信号进行图像切割,将图像中文字特征部分提取出来,得到分散数字图像;
S3、将提取出的分散数字图像和整体数字图像文本输入模板匹配模型内部,将每个数字像中文本依次识别,分别形成分散数字文本和整体数字文本;
S4、将分散数字文本根据整体数字文本进行排列,形成新的整合数字文本,将整合数字文本与整体数字文本进行对比,保留整合数字文本中与整体数字文本相同的的部分,将不同部分的数字文本前后的数字文本输入数据库中,通过使用Word2Vec模型和LDA主题模型共同进行候选词推荐,联想出可能性较高的数字文本并进行替换,得到目标数字文本。
优选的,所述步骤S1中对图形进行二值化处理是指,将图像用一个二维函数f(x,y)表示,其中x.y是图像中像素坐标,f为图像像素在坐标点(x.y)处的灰度值,图像的数据矩阵表示如下:
数据矩阵中的数值在[0,255]范围中取值,坐标点的颜色越深其灰度值越大,在数字编码图像中,数字字符的颜色一般较背景颜色深,设定某一个阈值b,b值小于字符颜色灰度,且大于背景颜色灰度.将b值与数据矩阵f(x,y)中数值相比较,把小于b值的数值改成0,大于b的数值改成1,即可滤去背景颜色保留数字字符,得到数字编码图像的二值化图像。
优选的,所述Word2Vec模型用于将数值化处理结果作为训练样本导入其中进行训练,得到各个词语的词向量,然后根据所述词向量获取各个词语的相关词语集合,所述LDA主题模型用于将数值化处理结果作为训练样本导入其中进行训练,得到主题-词语矩阵,然后根据所述主题-词语矩阵获取各个主题的特征词语集合。
与现有技术相比,本发明的有益效果为:
1、通过控制机构控制传动环和方形框的固定与放松,并由传动环上缠绕的传动带带动一号转动轴和二号转动轴,使识别设备可以便捷的进行纵向和横向位置的调整的同时,还可以保证其上扫描设备在调整的过程中保持水平,提高了识别设备使用时的便捷性和适用范围。
2、通过控制机构的设置,使调节设备在进行调节完成后进行有效的固定,保证识别设备在使用的过程中的稳定性,防止识别设备在使用的过程中其上的扫描设备发生偏移的现象。
3、通过将扫描的数字图像进行图像切割,将分散数字文本根据整体数字文本进行排列,形成新的整合数字文本,并将整合数字文本与整体数字文本进行对比,并通过将不同部分的数字文本前后的数字文本输入数据库中,联想出可能性较高的数字文本并进行替换,进而得到目标数字文本,减少扫描出的数字文本发生误差的现象。
附图说明
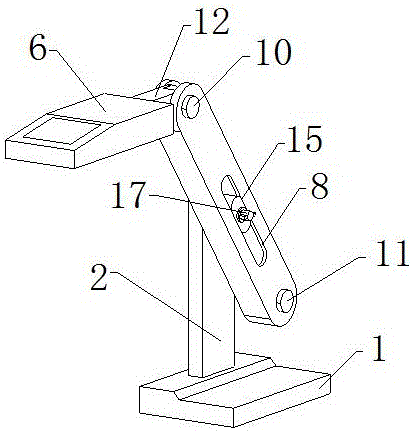
图1为本发明的整体结构示意图;
图2为本发明的内部结构纵剖示意图;
图3为图2中A处结构放大图;
图4为本发明的方形框和圆台柱内部结构横剖示意图;
图5为本发明的支撑板外部结构局部示意图;
图6为本发明的步骤框图。
图中:1、机底座;2、支撑板;3、控制机构;4、支撑环;5、调节机构;6、扫描设备;7、支撑框;8、限位槽;9、传动环;10、一号转动轴;11、二号转动轴;12、支撑块;13、传动带;14、圆台柱;15、方形框;16、圆形孔;17、螺纹柱;18、挤压块;19、环形齿槽;20、齿块;21、弹簧。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语"中心"、"纵向"、"横向"、"长度"、"宽度"、"厚度"、"上"、"下"、"前"、"后"、"左"、"右"、"坚直"、"水平"、"顶"、"底"、"内"、"外"、"顺时针"、"逆时针"等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
此外,术语"第一"、"第二"仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有"第一"、"第二"的特征可以明示或者隐含地包括一个或者更多个所述特征。在本发明的描述中,"多个"的含义是两个或两个以上,除非另有明确具体的限定。此外,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
请参阅图1至图2,本发明提供一种基于人工智能的数字图像识别设备,包括机底座1,机底座1的顶部固定安装有支撑板2,支撑板2的一侧安装有控制机构3,控制机构3包括固定安装在支撑板2一侧的支撑环4,支撑环4的外表面安装有调节机构5,调节机构5的一侧安装有扫描设备6,扫描设备6具有扫描图像的功能,与外部电源电性连接,并受外部PLC编程程序控制,调节机构5包括活动安装在支撑环4外表面的支撑框7,支撑框7的一侧贯穿开设有限位槽8,支撑环4的外表面且位于支撑框7的内部转动安装有传动环9,支撑框7内部的顶部转动安装有一号转动轴10,支撑框7内部的底部转动安装有二号转动轴11,一号转动轴10的外表面固定安装有支撑块12,支撑块12的一侧延伸至支撑框7的外部,支撑块12的一侧与扫描设备6固定连接,传动环9的外表面缠绕有传动带13,一号转动轴10和二号转动轴11的外表面均通过传动轮与传动带13的内表面传动连接,通过控制机构3使支撑框7可以进行转动,然后转动支撑框7,支撑框7会带着一号转动轴10和二号转动轴11跟随支撑框7一起进行移动,但由于传动环9不会进行转动,在传动带13的带动下,一号转动轴10和二号转动轴11会在支撑框7进行转动的同时自转,并由于一号转动轴10上支撑块12上固定的扫描设备6在初始状态下就处于水平,所以在支撑框7进行转动时扫描设备6会始终保持水平状态。
作为本发明的一种实施方式,参照图3至图5,控制机构3包括滑动安装在支撑环4内部的圆台柱14,圆台柱14远离支撑板2的一侧固定安装有方形框15,方形框15和圆台柱14的一侧均贯穿开设有圆形孔16,两个圆形孔16之间转动安装有同一个螺纹柱17,螺纹柱17的一侧延伸至支撑板2的内部,螺纹柱17的外表面与支撑板2的内表面螺纹连接,支撑环4远离支撑板2的一端等距固定安装有若干挤压块18,挤压块18的内表面与圆台柱14的外表面滑动连接,挤压块18的外表面与传动环9的内表面活动连接,方形框15的外表面与限位槽8的内表面滑动连接,支撑板2的一侧开设有环形齿槽19,方形框15内部的两侧均滑动安装有齿块20,齿块20的一侧延伸至方形框15的外部,齿块20的另一侧固定安装有弹簧21,弹簧21的一侧与方形框15的内壁固定连接,齿块20的外表面与环形齿槽19的内表面活动连接,转动螺纹柱17,螺纹柱17向着远离支撑板2的方向移动,螺纹柱17会同时带着方形框15和圆台柱14同时移动,方形框15在移动的过程中,齿块20被弹簧21抵在环形齿槽19上,弹簧21的状态会从压缩状态变为放松状态,使方形框15可以进行转动,此时圆台柱14较大半径处还抵着挤压块18,所以传动环9无法进行转动,继续转动螺纹柱17,圆台柱14从支撑环4上挤压块18之间抽出后,传动环9可以进行转动,移动支撑框7,在方形框15和限位槽8的限位下,前后移动支撑框7,传动环9会在传动带13的带动下进行转动,控制支撑框7的圆心位置。
请参阅图6,一种基于人工智能的数字图像识别方法,其具有上述的基于人工智能的数字图像识别设备,包括以下步骤:
S1、通过数字图像识别设备将文件图像进行扫描,将扫描出的所述文件图像信息通过小波变换的方法将光学信号转换为数字信号,并对文件图像信息进行预处理,得到整体数字图像;
S2、将预处理后的文件图像信息的数字信号进行图像切割,将图像中文字特征部分提取出来,得到分散数字图像;
S3、将提取出的分散数字图像和整体数字图像文本输入模板匹配模型内部,将每个数字像中文本依次识别,分别形成分散数字文本和整体数字文本;
S4、将分散数字文本根据整体数字文本进行排列,形成新的整合数字文本,将整合数字文本与整体数字文本进行对比,保留整合数字文本中与整体数字文本相同的的部分,将不同部分的数字文本前后的数字文本输入数据库中,通过使用Word2Vec模型和LDA主题模型共同进行候选词推荐,联想出可能性较高的数字文本并进行替换,得到目标数字文本,将数。
步骤S1中对图形进行二值化处理是指,将图像用一个二维函数f(x,y)表示,其中x.y是图像中像素坐标,f为图像像素在坐标点(x.y)处的灰度值,图像的数据矩阵表示如下:
数据矩阵中的数值在[0,255]范围中取值,坐标点的颜色越深其灰度值越大,在数字编码图像中,数字字符的颜色一般较背景颜色深,设定某一个阈值b,b值小于字符颜色灰度,且大于背景颜色灰度.将b值与数据矩阵f(x,y)中数值相比较,把小于b值的数值改成0,大于b的数值改成1,即可滤去背景颜色保留数字字符,得到数字编码图像的二值化图像,Word2Vec模型用于将数值化处理结果作为训练样本导入其中进行训练,得到各个词语的词向量,然后根据词向量获取各个词语的相关词语集合,LDA主题模型用于将数值化处理结果作为训练样本导入其中进行训练,得到主题-词语矩阵,然后根据主题-词语矩阵获取各个主题的特征词语集合。
工作原理:首先转动螺纹柱17,螺纹柱17向着远离支撑板2的方向移动,螺纹柱17会同时带着方形框15和圆台柱14同时移动,方形框15在移动的过程中,齿块20被弹簧21抵在环形齿槽19上,弹簧21的状态会从压缩状态变为放松状态,使方形框15可以进行转动,从而使支撑框7可以进行转动,此时圆台柱14较大半径处还抵着挤压块18,所以传动环9无法进行转动,然后转动支撑框7,支撑框7会带着一号转动轴10和二号转动轴11跟随支撑框7一起进行移动,但由于传动环9不会进行转动,在传动带13的带动下,一号转动轴10和二号转动轴11会在支撑框7进行转动的同时自转,并由于一号转动轴10上支撑块12上固定的扫描设备6在初始状态下就处于水平,所以在支撑框7进行转动时扫描设备6会始终保持水平状态,然后继续转动螺纹柱17,圆台柱14从支撑环4上挤压块18之间抽出后,传动环9可以进行转动,移动支撑框7,在方形框15和限位槽8的限位下,前后移动支撑框7,传动环9会在传动带13的带动下进行转动,控制支撑框7的圆心位置。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种应用程序下载渠道的识别方法及相关设备
- 基于人工智能的数字图像识别方法及相关设备
- 一种基于硬件指纹相关性的数字图像源拍摄设备识别方法