一种云计算数据中心能耗优化方法及系统
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及电子数字数据处理技术领域,具体涉及一种云计算数据中心能耗优化方法及系统。
背景技术
数据中心的能源消耗量较大,其能源成本占据了其运营成本的重要部分,通过优化能耗可以降低能源成本进而提高运营效率。有效的管理和规划数据中心的能源需求,可以满足不断增长的计算需求,推动数据中心的可扩展性和业务发展。而对于数据中心的诸多服务器,不同服务器的功耗有所差异,为了避免部分服务器过载而导致的能耗较高的问题,需要将负载较高的服务器进行负载均衡化处理,以节约资源消耗。
对于数据中心的诸多服务器,采用孤立森林算法,对于负载较高或较低的服务器进行检测。而在传统的孤立森林算法中,将每个非叶子节点分割成两个子节点的过程中,采用的是随机超平面的方式进行划分的,但这样的划分方式会由于各点对应的特征取值范围的不同、不同特征的重要性或权重的差异,而导致选取的特征不能很好地划分出异常样本,进而造成算法检测效果较差的问题。
发明内容
本发明提供一种云计算数据中心能耗优化方法及系统,以解决现有的问题。
本发明的一种云计算数据中心能耗优化方法及系统采用如下技术方案:
本发明一个实施例提供了一种云计算数据中心能耗优化方法,该方法包括以下步骤:
获取数据中心中各服务器的多种运行数据所形成的多维数据集,一个服务器对应一个多维数据集;
对任意多维数据集进行降维获得若干个主成分数据,将若干个相同层的主成分数据所形成的集合记为对应层下的一个样本簇类;将任意主成分数据的一阶差分结果记为主成分数据对应的差分数据;根据样本簇类中所有差分数据和主成分数据中数据点的平均值获得样本簇类的离散程度;对样本簇类进行随机划分获得子簇类,根据子簇类之间的差异获得划分优度,根据划分优度的大小获得新子簇类;
利用样本簇类的划分方法对其他层的样本簇类进行划分,获取不同层的新子簇类之间的差异获得余-主成分数据,将余-主成分数据重新划分获得最终的孤立森林;
利用孤立森林对所有服务器进行能耗优化。
进一步的,所述对任意多维数据集进行降维获得若干个主成分数据,包括的具体方法为:
利用主成分分析算法将所有服务器对应的多维数据集进行降维,获得若干个主成分数据,一个服务器对应若干层的主成分数据;
获取各主成分数据的方差贡献率,选取服务器对应若干层的主成分数据中方差贡献率大于预设超参数
进一步的,所述根据样本簇类中所有差分数据和主成分数据中数据点的平均值获得样本簇类的离散程度,包括的具体方法为:
首先,将任意主成分数据中所有数据点的平均值记为主成分数据的均值参数;获取任意主成分数据的一阶差分结果记为主成分数据对应的差分数据;
然后,任意样本簇类的离散程度的具体计算方法为:
其中,
进一步的,所述对样本簇类进行随机划分获得子簇类,根据子簇类之间的差异获得划分优度,根据划分优度的大小获得新子簇类,包括的具体方法为:
首先,构建随机树,将一个样本簇类作为随机树中的一个节点,将样本簇类中的主成分数据随机划分为两个含有若干主成分数据的集合,记为样本簇类的子簇类;将子簇类在随机树中对应的节点作为样本簇类对应节点的子节点;
然后,根据子簇类中所有主成分数据的所有数据点的平均值以及差分数据中数据点的数值,获得子簇类的差异因子,将两个子簇类的差异因子的差值记为两个子簇类之间的差异性;
最后,将子类簇包含的主成分数据的数量与子类簇的离散程度的乘积记为子簇类的第一数值,将两个子簇类的第一数值的和值记为两个子簇类的第二数值,将两个子簇类的差异性与第二数值的比值记为两个子簇类时对应的划分优度,划分优度最大时,将样本簇类划分的两个子簇类记为样本簇类的新子簇类。
进一步的,所述差异因子的具体获取方法为:
其中,
进一步的,所述获取不同层的新子簇类之间的差异获得余-主成分数据,包括的具体方法为:
获取第
进一步的,所述将余-主成分数据重新划分获得最终的孤立森林,包括的具体方法为:
首先,判断第
然后,当余-主成分数据的划分系数大于等于0时,将余-主成分数据划分至第一个新子簇类中,当余-主成分数据的划分系数小于0时,将余-主成分数据划分至第二个新子簇类中;通过孤立森林算法,并结合划分优度和划分系数将所有服务器的所有主成分数据进行划分,获得若干个随机树形成的孤立森林,所述最终的孤立森林中每一个叶节点对应一个服务器。
进一步的,所述判断第
首先,当第
然后,对于第
其中,
进一步的,所述利用孤立森林对所有服务器进行能耗优化,包括的具体方法为:
利用孤立森林算法对孤立森林进行异常检测,获取各个节点的异常评分,当节点的异常评分大于预设的评分标准时,将节点对应的服务器标记为负载异常的服务器,通过数据中心降低负载异常的服务器的任务量,降低负载异常的服务器的能耗。
进一步的,一种云计算数据中心能耗优化系统包括以下模块:
数据采集模块:用于获取数据中心中各服务器的多种运行数据所形成的多维数据集,一个服务器对应一个多维数据集;
划分优度模块:用于对任意多维数据集进行降维获得若干个主成分数据,将若干个相同层的主成分数据所形成的集合记为对应层下的一个样本簇类;将任意主成分数据的一阶差分结果记为主成分数据对应的差分数据;根据样本簇类中所有差分数据和主成分数据中数据点的平均值获得样本簇类的离散程度;对样本簇类进行随机划分获得子簇类,根据子簇类之间的差异获得划分优度,根据划分优度的大小获得新子簇类;
孤立森林模块:用于利用样本簇类的划分方法对其他层的样本簇类进行划分,获取不同层的新子簇类之间的差异获得余-主成分数据,将余-主成分数据重新划分获得最终的孤立森林;
能耗优化模块:用于利用孤立森林对所有服务器进行能耗优化。
本发明的技术方案的有益效果是:通过将多维数据集降维获取若干个主成分数据在一定程度上降低了数据量,将样本簇类进行划分获得子簇类后,根据子簇类之间的差异获得随机树中各节点对应的子节点,使多个随机树形成的孤立森林中样本簇类对应节点的两个子节点差异最大,提高异常检测的准确性,进一步提高了对服务器的能耗优化效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
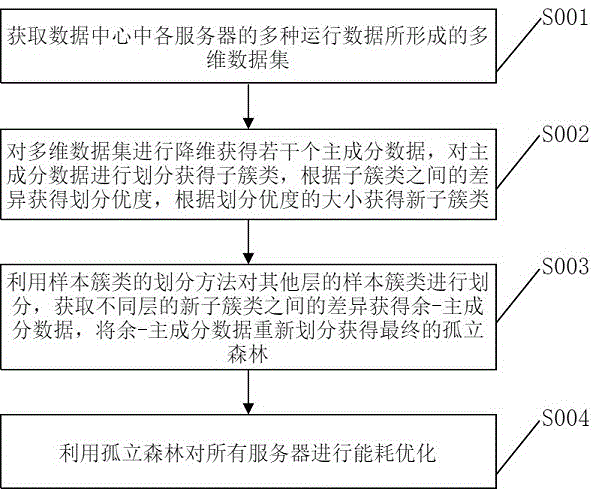
图1为本发明的一种云计算数据中心能耗优化方法的步骤流程图;
图2为本发明的一种云计算数据中心能耗优化系统的结构框图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种云计算数据中心能耗优化方法及系统,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的一种云计算数据中心能耗优化方法及系统的具体方案。
请参阅图1,其示出了本发明一个实施例提供的一种云计算数据中心能耗优化方法的步骤流程图,该方法包括以下步骤:
步骤S001:获取数据中心中各服务器的多种运行数据所形成的多维数据集。
需要说明的是,本实施例针对数据中心运行过程中的各服务器,对其进行实时的异常检测,避免某些服务器过载而其他服务器处于低负载状态,通过负载均衡技术提高服务器的利用率并减少能耗。
具体的,为了实现本实施例提出的一种云计算数据中心能耗优化方法,首先需要采集数据中心的多维数据集,具体过程为:
通过数据中心获取多个服务器的运行数据,对于单个服务器所对应的运行数据包括CPU利用率、内存利用率、磁盘I/O、网络流量、功耗数据以及温度数据,将CPU利用率、内存利用率、磁盘I/O、网络流量、功耗数据以及温度数据形成的集合记为服务器的多维数据集,多维数据集中的元素称为服务器的运行数据。
至此,通过上述方法得到各个服务器对应多个运行数据形成的多维数据集。
步骤S002:对多维数据集进行降维获得若干个主成分数据,对主成分数据进行划分获得子簇类,根据子簇类之间的差异获得划分优度,根据划分优度的大小获得新子簇类。
需要说明的是,对于任意一个节点,其代表着诸多样本的集合,一个样本代表着一个服务器的多维度数据,利用不同的主成分进行划分即代表利用不同的数据来对各样本进行划分,而划分后结果的优劣需要里利用其划分结果中各簇类的离散程度来度量;传统的度量数据离散程度的方式无法直接利用到时间序列离散性的度量上,故对于同一主成分对应的数据序列簇而言,不仅需要考虑各样本序列的平均差异(表示各服务器的平均负载的离散),还应当考虑各个序列自身的波动变化情况,进而得到更加精确的离散性度量以进行划分优度的判断。
具体的,步骤(1),首先,利用主成分分析算法将所有服务器对应的多维数据集进行降维,获得若干个主成分数据,一个服务器对应若干层的主成分数据。
需要说明的是,主成分分析算法为现有算法,因此本实施例不进行过多赘述。
然后,获取各主成分数据的方差贡献率;选取方差贡献率大于
需要说明的是,根据经验预设超参数
步骤(2),将若干个相同层的主成分数据所形成的集合,记为对应层下的一个样本簇类;将任意主成分数据中所有数据点的平均值记为主成分数据的均值参数;获取任意主成分数据的一阶差分结果记为主成分数据对应的差分数据;根据样本簇类中各主成分数据获取任意样本簇类的离散程度,具体计算方法为:
其中,
需要说明的是,获取样本簇类中各主成分数据中所有数据点的均值,对于两个均值参数相同的主成分数据而言,若仅仅采用均值参数评估主成分数据的离散程度,这两个均值参数对于离散程度的贡献是相同的,但实际上应当是不同的;故在计算各均值的方差时,应当对不同的离差平方进行加权平均,将主成分数据的一阶差分的绝对值之和在归一化之后作为离差平方的权重系数,以得到更加精确的离散程度的度量。
步骤(3),需要说明的是,对于孤立森林中任意一个节点,当其包含的主成分数据个数超过2时,可以对其进行进一步划分,而对于不同的划分,其对应两类的差异性会有所不同;为了使得孤立主成分数据更好的被分离开来,即对于负载异常的服务器需要尽可能缩短其对应主成分数据在二叉树中的路径长度,进而保证其受到随机性的干扰较小,而上述步骤可以得到单个样本簇类的离散程度,但对于分类结果,应当在保证类内的离散程度小的同时,尽可能放大两个类别之间的差异性,进而得到划分优度的度量。
首先,构建随机树,将一个样本簇类作为随机树中的一个节点,将样本簇类中的主成分数据随机划分为两个含有若干主成分数据的集合,记为样本簇类的子簇类;将子簇类在随机树中对应的节点作为样本簇类对应节点的子节点;两个子簇类之间的差异性的具体计算方法为:
其中,
需要说明的是,本实施例选择在10分钟内,每30秒采样一次,获得服务器的运行数据,因此预设差分数据中数据点的权重系数
需要说明的是,将样本簇类划分为两个子簇类时,应使第一个子簇类中所有主成分数据的所有数据点的平均值,大于等于第二个子簇类中所有主成分数据的所有数据点的平均值。
需要说明的是,利用子簇类中所有主成分数据的所有数据点的平均值,来表示各子簇类中所有主成分数据的所有数据点的平均大小,但考虑到对于各服务器进行检测时,所有主成分数据的所有数据点的平均大小反映了各服务器在当前时刻邻域内的平均负载情况,而未考虑后续可能的变化情况,故在
步骤(4),首先,根据差异性和离散程度获得样本簇类划分为两个子簇类时对应的划分优度
其中,
需要说明的是,所述子簇类的离散程度与样本簇类的离散程度的获取方法相同。
需要说明的是,划分优度的计算方法中,
需要说明的是,当两子簇类的离散程度小且子簇类之间的差异性达到最大时,得到样本簇类的最优划分结果。
然后,划分优度最大时,将样本簇类划分的两个子簇类记为样本簇类的新子簇类。
需要说明的是,在获取的多维度数据中,可能存在一些冗余的维度或变量,这些变量可能显的在分析中不具有明区分能力。本实施例通过PCA主成分分析,可以识别和去除这些冗余信息,从而提高数据的效率和清晰度。
至此,通过上述方法得到样本簇类的新子簇类。
步骤S003:利用样本簇类的划分方法对其他层的样本簇类进行划分,获取不同层的新子簇类之间的差异获得余-主成分数据,将余-主成分数据重新划分获得最终的孤立森林。
需要说明的是,在对各主成分数据进行划分时,各主成分数据的划分结果会有所差异,需要对不同的划分结果与同类型的服务器进行匹配,例如当服务器的散热功率较高时,可能会对应较低的温度数据,需要利用不同分类对应的相似度进行类别的匹配,对于部分样本在不同的主成分中划分结果不同的情况,利用其不同主成分之间的相关性,结合各主成分的方差贡献率,判断给点最终属于的类别。
具体的,首先,获取第
需要说明的是,不采用数据大小进行匹配的原因是,主成分数据之间并不一定是正相关的。
需要说明的是,得到各主成分数据在划分后子簇类的匹配关系,而对于同一个服务器,其在不同层的主成分数据下产生的划分结果可能不同,即产生了余-主成分数据,因此需要判断余-主成分数据最终应当划分在哪一个子簇类中。
然后,当第
其中,
最后,当余-主成分数据的划分系数大于等于0时,将余-主成分数据划分至第一个新子簇类中,当余-主成分数据的划分系数小于0时,将余-主成分数据划分至第二个新子簇类中;通过孤立森林算法,并结合划分优度和划分系数将所有服务器的所有主成分数据进行划分,获得若干个随机树形成的孤立森林,所述最终的孤立森林中每一个叶节点对应一个服务器。
需要说明的是,服务器对应的主成分数据在不同层的样本簇类产生了不同的划分结果,即产生的新子簇类不相同,因此需要判断哪个划分结果更加可靠,故本实施例通过余-主成分数据与其他主成分数据之间的相关系数,说明主成分数据之间的相似程度,相似程度较高说明样本簇类产生的划分结果更加可靠,而不同的主成分数据对原始数据的贡献不同,故利用各主成分的方差贡献率作为权重系数,在进行归一化之后,对分类结果进行加权平均,以得到最终的划分结果。
需要说明的是,本实施例中,由于多维数据中可能会存在诸多冗余的数据,因此需要进行降维处理。在获取二叉树的过程中,即需要对每次分类进行自适应,而非传统的随机划分,划分的目的是为了使得遗产样本更早的被分离,即每次划分需要保证结果的两类之间差异尽可能大,而一类中各样本的差异尽可能小,即对于多个服务器而言,需要尽可能将负载差异较大服务器分为不同的簇类;故对需要针对不同样本间各主成分之间的关系进行分析,对同一主成分下进行簇类内以及簇类间的差异性进行度量,以对不同样本在该主成分上的划分效果进行评价,最后结合各主成分之间的相关性,对分类结果进行综合,进而获取样本簇类对应的子簇类。
至此,通过上述方法得到最终的孤立森林。
步骤S004:利用孤立森林对所有服务器进行能耗优化。
具体的,利用孤立森林算法对孤立森林进行异常检测,获取各个节点的异常评分,当节点的异常评分大于预设的评分标准时,将节点对应的服务器标记为负载异常的服务器,通过数据中心降低负载异常的服务器的任务量,降低负载异常的服务器的能耗,从而对各服务器的能耗进行优化。
需要说明的是,根据经验预设评分标准为0.8,可根据实际情况进行调整,本实施例不进行具体限定。
需要说明的是,孤立森林算法为现有的异常检测算法,因此本实施例不进行过多赘述。
通过以上步骤,完成对所有服务器的能耗优化。
请参阅图2,其示出了本发明一个实施例提供的一种云计算数据中心能耗优化系统的结构框图,该系统包括以下模块:
数据采集模块:用于获取数据中心中各服务器的多种运行数据所形成的多维数据集,一个服务器对应一个多维数据集;
划分优度模块:用于对任意多维数据集进行降维获得若干个主成分数据,将若干个相同层的主成分数据所形成的集合记为对应层下的一个样本簇类;将任意主成分数据的一阶差分结果记为主成分数据对应的差分数据;根据样本簇类中所有差分数据和主成分数据中数据点的平均值获得样本簇类的离散程度;对样本簇类进行随机划分获得子簇类,根据子簇类之间的差异获得划分优度,根据划分优度的大小获得新子簇类;
孤立森林模块:用于利用样本簇类的划分方法对其他层的样本簇类进行划分,获取不同层的新子簇类之间的差异获得余-主成分数据,将余-主成分数据重新划分获得最终的孤立森林;
能耗优化模块:用于利用孤立森林对所有服务器进行能耗优化。
本实施例通过将多维数据集降维获取若干个主成分数据在一定程度上降低了数据量,将样本簇类进行划分获得子簇类后,根据子簇类之间的差异获得随机树中各节点对应的子节点,使多个随机树形成的孤立森林中样本簇类对应节点的两个子节点差异最大,提高异常检测的准确性,进一步提高了对服务器的能耗优化效果。
需要说明的是,本实施例中所用的
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种电力云计算数据中心的能耗优化方法
- 一种基于多区域划分的云计算数据中心能耗优化方法