一种基于跳表的分片共享内存存储系统及其方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及共享内存技术领域,特别涉及一种基于跳表的分片共享内存存储系统及其方法。
背景技术
共享内存指(shared memory)在多处理器的计算机系统中,可以被不同中央处理器(CPU)访问的大容量内存。由于多个CPU需要快速访问存储器,这样就要对存储器进行缓存(Cache)。任何一个缓存的数据被更新后,由于其他处理器也可能要存取,共享内存就需要立即更新,否则不同的处理器可能用到不同的数据。共享内存是Unix下的多进程之间的通信方法,这种方法通常用于一个程序的多进程间通信,实际上多个程序间也可以通过共享内存来传递信息。
Redis(Remote Dictionary Server,远程数据服务)是一款内存高速缓存数据库,该软件使用C语言编写,数据模型为key-value,由于Redis可支持丰富的数据类型,如String、List、Hash、Set、Sorted Set等,因此被广泛应用。
对于数据存储,一般使用redis等数据存储系统,redis采用key-value的存储方式,通过使用key作为键值,为数据存储查询的唯一索引,可以查询出对应存储的数据,但查询速度快慢,当数据存储量增大,大于redis系统的存储最大阈值时,需要增大存储数据量的最大阈值,本技术因此而研发。
发明内容
针对现有技术存在的问题,本发明提供一种基于跳表的分片共享内存存储系统及其方法。
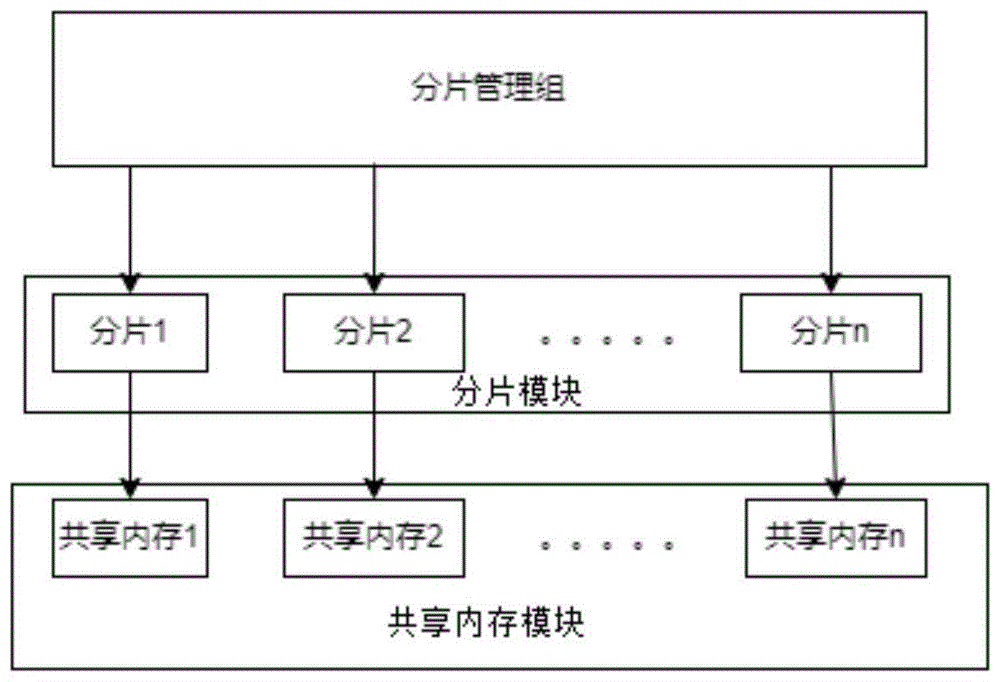
为了实现上述目的,本发明提供一种基于跳表的分片共享内存存储系统,其特征在于,包括分片管理组、分片模块、共享内存模块;
所述分片管理组用于打开或创建管理组共享内存模块,加载已存在的所有分片模块;
所述分片模块实现的是以跳表的原理,存储及访问存储到共享内存模块中的数据;
所述共享内存模块用于管理分片模块模块信息,在分片管理组件中,存储分片模块的默认最大值、存储数据数量、分片读写锁、分片列表。
优选的,所述分片模块中的跳表是多级单项链表的形式,key值按从小到大的顺序存储在跳表中,跳表中的key是有序存储。
本发明还提供一种基于跳表的分片共享内存存储方法,包括如下步骤:
步骤S1:插入数据:
步骤S101:插入数据key-value,锁分片管理组的读写锁,并检查所有分片的数据量是否已经达到或超过总容量的95%;
步骤S102:若是,则自动新增的分片模块,并检索数据插入的分片及位置,释放读写锁;
步骤S103:若否,则直接检索数据插入的分片及位置,释放读写锁;
步骤S2:数据查询:
步骤S201:锁分片管理组的读写锁,检索每个分片的跳表的key值,以待检索的key与分片的跳表头的第一个数据的key比较大小,以查询key所在分片;
步骤S202:再根据跳表中的数据key与待检索的key做比较,相等则查询到数据,释放读写锁;
步骤S3:数据删除:
步骤S301:锁分片管理组的读写锁,检索每个分片的跳表头的key值,以待删除的数据key与跳表头的key值做比较,以查询key所在分片;
步骤S302,再根据跳表中的数据key与待删除的数据做比较;若相等,则在跳表结构中删除对应的节点和释放对应的共享内存,并释放读写锁;否则,直接释放读写锁。
优选的,所述步骤S102中的新增的分片模块的大小为默认设置的分片大小。
优选的,所述步骤S102和步骤S103中检索数据插入的分片及位置的具体过程为:检索每个分片的跳表的key的值,以插入的key与分片的跳表头的第一个数据的key比较大小,如果是小于,则数据插入前一个分片模块,否则插入最后一个分片模块,释放读写锁。
优选的,所述步骤S201中的查询key所在分片具体方法为:若待检索的key小于跳表头的第一个数据的key,则数据在前一个分片,选择前一个分片在跳表链表中检索数据,否则,选择最后一个分片在跳表链表中检索数据。
优选的,所述步骤S202中的跳表中的数据key与查询的key不相等,则表示数据不存在。
优选的,所述步骤S301中的以查询key所在分片具体方法为:若待删除的数据key小于跳表头的key值,则数据在前一个分片,选择前一个分片在跳表链表中检索数据;否则选择最后一个分片检索数据。
采用本发明的技术方案,具有以下有益效果:
本发明通过创建共享内存,采用跳表的检索方式,自动根据存储数据量的大小,灵活自动增加数据存储的分片,扩大存储数据量的最大阈值。由于使用的是共享内存,访问、检索的时间达到纳秒级。支持高并发数据快速访问检索。
本发明由于是基于跳表方式进行数据存储,而且是数据存储在共享内存中,数据查询效率达到纳秒级别,数据查询速度快;支持本机的多进程同时高并发访问,灵活采用分片管理数据存储,对于前期数据量不大的数据存储,机器可以选择内存较低的服务器,服务器的价格可以更低廉,当数据量增大时,可以直接升配服务器的内存大小,不用对进行做任何操作,分片数据存在可灵活增加分片,增加数据的最大存储容量。
本发明用于本地持久化存储信息数据,灵活扩展存储系统的存储大小。
附图说明
图1为本发明分片管理组、分片模块、共享内存模块关联图;
图2为本发明跳表结构图;
图3为本发明数据插入流程;
图4为本发明数据查询流程;
图5为本发明数据删除流程。
具体实施方式
以下结合附图和具体实施例,对本发明进一步说明。
参照图1至图5,本发明提供一种基于跳表的分片共享内存存储系统,,包括分片管理组、分片模块、共享内存模块;
所述分片管理组用于打开或创建管理组共享内存模块,加载已存在的所有分片模块;所述分片模块实现的是以跳表的原理,存储及访问存储到共享内存模块中的数据;所述共享内存模块用于管理分片模块模块信息,在分片管理组件中,存储分片模块的默认最大值、存储数据数量、分片读写锁、分片列表。所述分片模块设有多个分片,所述共享内存模块设有多个共享内存,每一个分片均一个共享内存对应。
所述分片管理组实现对所有共享内存分片的管理,包含分片的创建、打开,数据检索、删除、插入功能,分片管理组创建一份具体名称的共享内存,该份共享内存用于管理分片信息,分片管理组中,存储分片的默认最大值,存储的数据数量,分片读写锁,及分片列表。分片管理组首先初始化管理分片信息的共享内存,首先打开具体名称的共享内存,如果该共享内存不存在,则创建共享内存。管理信息的共享内存中存该分片管理组的名称,及每个分片的默认大小。
所述分片实现的是以跳表的原理,存储及访问存储到共享内存中的数据。分片中的跳表是多级单项链表的形式,为了加快检索效率,key值按从小到大的顺序存储在跳表中,跳表中的key是有序存储。
本发明还提供一种基于跳表的分片共享内存存储方法,包括如下步骤:
步骤S1:插入数据:
步骤S101:插入数据key-value,锁分片管理组的读写锁,并检查所有分片的数据量是否已经达到或超过总容量的95%;所述步骤S101中的新增的分片模块的大小为默认设置的分片大小。
步骤S102:若是,则自动新增的分片模块,并检索数据插入的分片及位置,释放读写锁;
步骤S103:若否,则直接检索数据插入的分片及位置,释放读写锁;
所述步骤S102和步骤S103中检索数据插入的分片及位置的具体过程为:检索每个分片的跳表的key的值,以插入的key与分片的跳表头的第一个数据的key比较大小,如果是小于,则数据插入前一个分片模块,否则插入最后一个分片模块,释放读写锁;
步骤S2:数据查询:
步骤S201:锁分片管理组的读写锁,检索每个分片的跳表的key值,以待检索的key与分片的跳表头的第一个数据的key比较大小,以查询key所在分片;所述步骤S201中的查询key所在分片具体方法为:若待检索的key小于跳表头的第一个数据的key,则数据在前一个分片,选择前一个分片在跳表链表中检索数据,否则,选择最后一个分片在跳表链表中检索数据;
步骤S202:再根据跳表中的数据key与待检索的key做比较,相等则查询到数据,释放读写锁;不相等,则表示数据不存在。
步骤S3:数据删除:
步骤S301:锁分片管理组的读写锁,检索每个分片的跳表头的key值,以待删除的数据key与跳表头的key值做比较,以查询key所在分片,若待删除的数据key小于跳表头的key值,则数据在前一个分片,选择前一个分片在跳表链表中检索数据;否则选择最后一个分片检索数据。
步骤S302,再根据跳表中的数据key与待删除的数据做比较;若相等,则在跳表结构中删除对应的节点和释放对应的共享内存,并释放读写锁;否则,直接释放读写锁。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是在本发明的发明构思下,利用本发明说明书及附图内容所作的等效结构变换,或直接/间接运用在其他相关的技术领域均包括在本发明的专利保护范围内。
- 一种基于配置的自适应分布式存储系统的数据分片方法
- 一种基于配置的自适应分布式存储系统的数据分片方法