一种图像检测的方法及装置
文献发布时间:2023-06-19 10:16:30
技术领域
本公开涉及计算机视觉技术领域,特别涉及一种图像检测的方法及装置。
背景技术
随着人们生活水平的提高,汽车、摩托车、电动车的数量越来越多,随之出现了较多的交通事故。经过对交通事故的研究发现,佩戴头盔可以有效降低伤亡率。
因此,为了有效保护摩托车、电动车骑乘人员和汽车驾乘人员的生命安全、减少交通事故死亡率,公安部交通管理局发文提倡,全国开展“一盔一带”安全守护行动。但在行动开展中,由于部分人们的安全意识淡薄,仍然存在大量不佩戴头盔的现象。
相关技术下,检测摩托车、电动车骑乘人员佩戴头盔的方法为人力巡查,也就是在每一个路口安排人员进行定点排查。由于目前车流量大,存在检测效率低、人力成本高、不能做到全覆盖的缺点。
由此可见,需要设计一种新的方法,以克服上述缺陷。
发明内容
本公开实施例提供一种图像检测的方法及装置,用以解决相关技术下对头盔佩戴情况进行检测存在着效率低、人力成本高以及不能全覆盖的问题。
本公开实施例提供的具体技术方案如下:
第一方面,一种图像检测的方法,包括:
获取待处理的视频数据,提取出目标帧图像;
对所述目标帧图像进行检测,获得第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;
基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型;
若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出所述目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况。
可选的,所述对目标帧图像进行检测,获得第一检测结果,包括:
基于所述目标帧图像,采用图像检测算法,对所述目标车辆和所述目标人体进行定位,确定包含所述目标车辆和所述目标人体的第一检测框,并将所述第一检测框作为所述第一检测结果;
所述对目标帧图像进行检测,获得第二检测结果,包括:
基于所述目标帧图像,采用图像检测算法,对所述目标人体进行定位,确定包含所述目标人体的第二检测框,并将所述第二检测框作为所述第二检测结果。
可选的,所述基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型,包括:
基于所述第一检测结果,采用特征提取算法,提取出所述目标车辆的车辆特征,其中,所述车辆特征至少包含以下特征中的任意一种或组合:车辆外形特征、所述目标车辆与所述目标人体的占比特征、所述目标人体的腿部运动特征、轮胎形状特征、轮胎与车身的占比特征、行驶车道特征、骑行姿势特征;
基于所述车辆特征,采用超分辨率检测序列网络VGG,确定所述目标车辆的车辆类型。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征之前,进一步包括:
若所述车辆类型为指定的非机动车类型,则将所述第二检测结果包含的像素值与预设门限值进行比较;
确定所述像素值不小于所述预设门限值时,对所述第二检测结果中包含的目标人体的头部区域进行剪裁。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况,包括:
基于所述第二检测结果,提取所述目标人体的头部特征,其中,所述头部特征至少包含以下特征中的任意一种或组合:面部皮肤特征、反光特征、反光面积占比特征、纹理特征、外形特征、颜色特征;
基于所述头部特征,采用深度残差网络,确定所述目标人体的头盔佩戴情况;
确定所述目标人体未佩戴头盔时,触发告警机制。
第二方面,一种图像检测的装置,包括:
提取单元,用于获取待处理的视频数据,提取出目标帧图像;
获得单元,用于对所述目标帧图像进行检测,获得第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;
第一确定单元,用于基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型;
第二确定单元,用于若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出所述目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况。
可选的,所述对目标帧图像进行检测,获得第一检测结果,所述获取单元用于:
基于所述目标帧图像,采用图像检测算法,对所述目标车辆和所述目标人体进行定位,确定包含所述目标车辆和所述目标人体的第一检测框,并将所述第一检测框作为所述第一检测结果;
所述对目标帧图像进行检测,获得第二检测结果,所述获取单元用于:
基于所述目标帧图像,采用图像检测算法,对所述目标人体进行定位,确定包含所述目标人体的第二检测框,并将所述第二检测框作为所述第二检测结果。
可选的,所述基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型,所述第一确定单元用于:
基于所述第一检测结果,采用特征提取算法,提取出所述目标车辆的车辆特征,其中,所述车辆特征至少包含以下特征中的任意一种或组合:车辆外形特征、所述目标车辆与所述目标人体的占比特征、所述目标人体的腿部运动特征、轮胎形状特征、轮胎与车身的占比特征、行驶车道特征、骑行姿势特征;
基于所述车辆特征,采用超分辨率检测序列网络VGG,确定所述目标车辆的车辆类型。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征之前,所述第二确定单元进一步用于:
若所述车辆类型为指定的非机动车类型,则将所述第二检测结果包含的像素值与预设门限值进行比较;
确定所述像素值不小于所述预设门限值时,对所述第二检测结果中包含的目标人体的头部区域进行剪裁。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况,所述第二确定单元用于:
基于所述第二检测结果,提取所述目标人体的头部特征,其中,所述头部特征至少包含以下特征中的任意一种或组合:面部皮肤特征、反光特征、反光面积占比特征、纹理特征、外形特征、颜色特征;
基于所述头部特征,采用深度残差网络,确定所述目标人体的头盔佩戴情况;
确定所述目标人体未佩戴头盔时,触发告警机制。
第三方面,一种计算机设备,包括:
存储器,用于存储可执行指令;
处理器,用于读取并执行存储器中存储的可执行指令,以实现如上述第一方面中任一项所述的方法。
第四方面,一种计算机可读存储介质,当所述计算机可读存储介质中的指令由处理器执行时,使得所述处理器能够执行如上述第一方面中任一项所述的方法。
本公开实施例中,智能设备基于获取的待处理的视频数据提取目标帧图像,并获得对应的第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;再基于所述第一检测结果提取的车辆特征确定目标车辆的车辆类型;若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果提取的目标人体的头部特征,确定相应的头盔佩戴情况,这样,可以基于道路交通监控系统的视频数据,准确、高效地确定目标车辆的车辆类型,并能通过有效的筛选确定指定的车辆类型,以及确定所述指定车辆类型对应的目标人体的头盔佩戴情况,从而在降低人力成本的基础上,大大提高了对指定车辆类型的目标人体的头盔佩戴情况检测的效率,进而利用现有的道路交通监控系统的视频数据,也能够使该项检测工作做到全覆盖。
附图说明
图1为本公开实施例中检测头盔佩戴情况的具体流程图;
图2为本公开实施例中基于视频数据获得帧图像的示意图;
图3为本公开实施例中应用场景一的示意图;
图4A、图4B、图4C、图4D、图4E、图4F、图5、图6、图7、图8、图9、图10为本公开实施例中车辆特征的示意图;
图11为本公开实施例中应用场景二的示意图;
图12、图13、图14为本公开实施例中头部特征的示意图;
图15为本公开实施例中应用场景三的示意图;
图16为本公开实施例中装置逻辑结构示意图;
图17为本公开实施例中计算机设备实体结构示意图。
具体实施方式
为了解决相关技术下对头盔佩戴情况进行检测存在着效率低、人力成本高以及不能全覆盖的问题,本公开实施例中,智能设备基于获取的待处理的视频数据提取目标帧图像,并对所述目标帧图像进行检测,获得第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;再基于所述第一检测结果提取的车辆特征确定所述目标车辆的车辆类型;若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果提取的所述目标人体的头部特征,确定相应的头盔佩戴情况,这样,可以准确地从待处理的视频数据中确定所述目标车辆对应的目标人体的头盔佩戴情况。
下面结合附图对本公开优选的实施方式作出进一步详细说明。
本公开实施例中,智能设备需要预先建立一个训练集,所述训练集中包含有海量的各种类型的非机动车以及人体佩戴头盔的视频数据,如电动车、自行车等,所述视频数据可以作为样本数据用于训练各类模型。
可选的,本公开实施例中,可以基于所述训练集中的样本数据,生成三个训练样本集,分别记为训练样本集1、训练样本集2、训练样本集3;这三个训练样本集分别用于训练检测框标注模型、车辆类型分类模型和头盔佩戴分类模型,其中,所述检测框标注模型可以用于基于所述样本数据包含的帧图像,获得第一检测结果和第二检测结果。
可选的,在进行模型训练之前,智能设备需对各个训练样本集中包含的每一个样本数据进行解帧,从而获得对应的样本帧图像。
具体的模型训练过程如下:
1)基于训练样本集1对检测框标注模型进行训练。
本公开实施例中,将训练样本集1中包含的各个训练样本对应的样本帧图像,输入检测框标注模型进行训练,对各个样本帧图像中包含的车辆和人体进行定位,并确定包含所述车辆和所述人体的第一检测框,当检测框标注模型的训练结果满足预设的收敛条件时,输出训练完毕的针对于车辆和人体的检测框标注模型。
本公开实施例中,将训练样本集1中包含的各个训练样本对应的样本帧图像,输入检测框标注模型进行训练,对各个样本帧图像中包含的人体进行定位,并确定包含所述人体的第二检测框,当检测框标注模型的训练结果满足预设的收敛条件时,输出训练完毕的针对于人体的检测框标注模型。
可选的,针对于车辆和人体的检测框标注模型和针对于人体的检测框标注模型可以是同一个检测框标注模型,也可以两个不同的检测框检测模型。
可选的,所述检测框标注模型可以采用卷积神经网络,也可以采用循环神经网络,还可以采用智能实时目标检测网络(You Only Look Once,YOLO)。
2)基于训练样本集1对车辆类型分类模型进行训练。
本公开实施例中,将训练样本集2中包含的各个训练样本对应的样本帧图像按照车辆类型不同进行分类,获得对应的各个子训练样本集,再分别将各个子训练样本集输入车辆类型分类模型进行训练,对各个样本帧图像包含的车辆对应的图像区域进行定位,并提取所述车辆的车辆特征,再基于所述车辆特征,确定对应车辆的车辆类型,当车辆类型分类模型的训练结果满足预设的收敛条件时,输出训练完毕的车辆类型分类模型。
可选的,所述车辆类型分类模型可以采用超分辨率检测序列网络(VisualGeometry Group,VGG),也可以采用深度残差网络(Residual Neural Network,RESET),其中,所述车辆类型分类模型为多分类模型,可以根据实际使用情况进行预设,对应的,可以获得二分类模型,也可以获得三分类模型,还可以为四分类模型等等。
3)基于训练样本集3对头盔佩戴分类模型进行训练。
本公开实施例中,将训练样本集3中包含的各个训练样本对应的样本帧图像,输入头盔佩戴分类模型进行训练,对各个样本帧图像包含的人体的头部区域进行定位,并提取所述人体的头部特征,再基于所述头部特征,确定所述人体的头盔佩戴情况,当头盔佩戴分类模型的训练结果满足预设的收敛条件时,输出训练完毕的头盔佩戴分类模型。
本公开实施例中,智能设备对视频数据中提取的帧图像进行检测,可以实现对任意一段视频数据中包含的车辆和人体进行准确标注、分类,从而对所述人体的头盔佩戴情况做出准确判断。
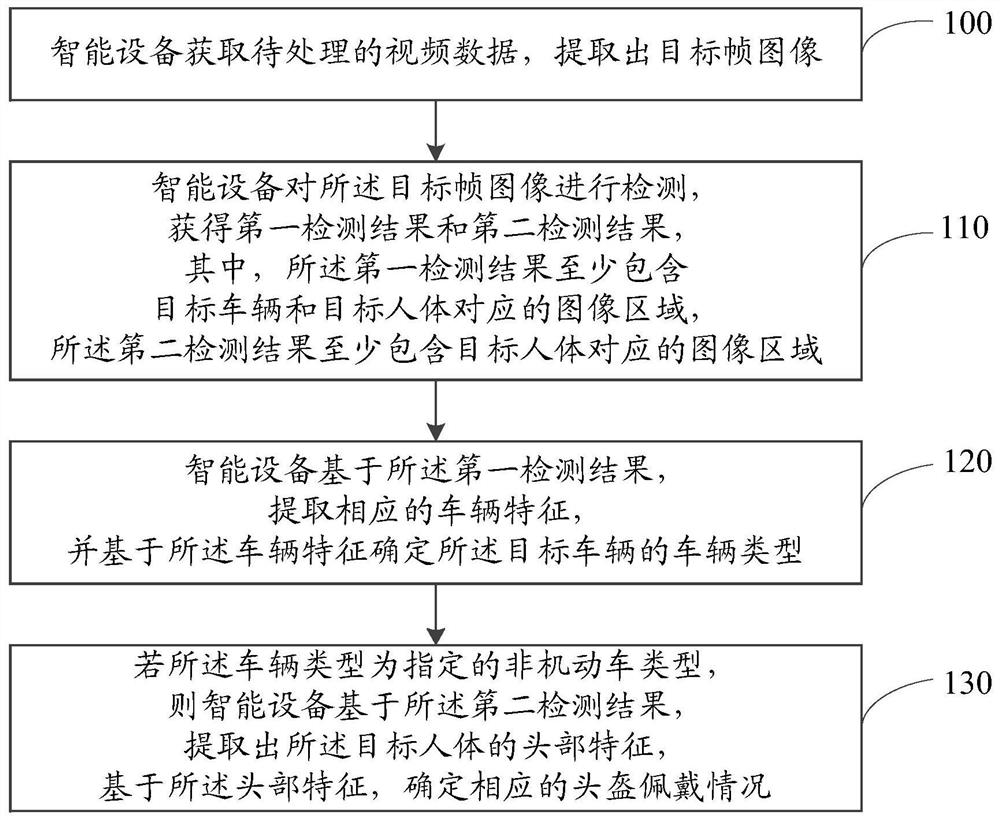
参阅图1所示,本公开实施例中,智能设备对头盔佩戴情况进行检测的具体流程如下:
步骤100:智能设备获取待处理的视频数据,提取出目标帧图像。
本公开实施例中,智能设备从道路交通监控系统获得待处理的视频数据,再对所述视频数据进行解帧处理,将所述视频数据分为一帧一帧的帧图像,从中提取出目标帧图像。
例如,参阅图2所示,以路口A为例。
智能设备从道理交通监控系统获得路口A的监控视频数据,记为视频A。那么,智能设备对视频A进行解帧处理,从而提取出目标帧图像,记为帧图像A。
步骤110:智能设备对所述目标帧图像进行检测,获得第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域。
本公开实施例中,智能设备基于所述目标帧图像,采用图像检测算法,对所述目标车辆和所述目标人体进行定位,确定包含所述目标车辆和所述目标人体的第一检测框,并将所述第一检测框作为所述第一检测结果。
本公开实施例中,智能设备基于所述目标帧图像,采用图像检测算法,对所述目标人体进行定位,确定包含所述目标人体的第二检测框,并将所述第二检测框作为所述第二检测结果。
可选的,所述图像检测算法可以为尺度不变特征变换(Scale-invariant featuretransform,SIFT)算法,也可以为实时循环学习算法,还可以为长短时间记忆算法。
例如,仍以路口A为例。
参阅图3所示,假设智能设备提取的目标帧图像为帧图像A。
智能设备基于帧图像A,采用SIFT算法,对所述目标车辆和所述目标人体进行定位,确定的包含目标车辆和所述目标人体的第一检测框为检测框A1。
那么,智能设备将所述第一检测框作为第一检测结果,即所述第一检测结果为检测框A1。
同时,智能设备基于帧图像A,采用实时循环学习算法,对所述目标人体进行定位,确定的包含所述目标人体的第二检测框为检测框A2。
那么,智能设备将所述第二检测框作为第二检测结果,即所述第二检测结果为检测框A2。
这样,智能设备可以基于所述目标帧图像,准确地获得对应的第一检测结果和第二检测结果。
步骤120:智能设备基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型。
本公开实施例中,智能设备基于所述第一检测结果,提取相应的车辆特征,并基于车辆特征确定所述目标车辆的车辆类型,具体的,智能设备通过以下两个步骤确定所述目标车辆的车辆类型:
1)智能设备基于所述第一检测结果,采用特征提取算法,提取所述目标车辆的车辆特征,其中,所述车辆特征包含但不限于如下特征中的任意一种或组合:
A、车辆外形特征。
具体实施中,不同类型车辆具有不同的车辆外形特征。
例如,参阅图4A所示,以电动车和自行车为例。
电动车与自行车相比,电动车车体较大、结实,在车体的前面和后面均安装有车灯;而自行车的车体较小、单薄,一般由圆柱形结构组成,且自行车一般不安装车灯等照明设施。
又例如,参阅图4B所示,以电动车和摩托车为例。
电动车与摩托车相比,电动车的车体小巧,通常为曲面结构拼接而成,而摩托车的车体较大,车体较圆润,通常为角度的圆形或者圆柱形结构组成。
可选的,所述车辆外形特征可以包含但不限于如下特征中的任意一个或组合:
a1、外轮廓特征。
具体实施中,不同类型车辆具有不同的外轮廓特征。
例如,参阅图4C所示,以电动车、摩托车和自行车为例。
电动车的外轮廓特征为小巧,车座与车把之间设有凹陷空间,用于容纳目标人体部分躯体,如腿部;
摩托车的外轮廓特征为流线型,车座和车把之间不存在凹陷空间,目标人体直接骑在摩托车车身上;
而自行车的外轮廓特征为单薄,车座和车把之间因款式不同,可以存在凹陷空间,也可以不存在凹陷空间,但目标人体均直接骑在自行车车身上。
a2、车体特征。
例如,参阅图4D所示,仍以电动车、自行车和摩托车为例。
电动车与自行车相比,电动车车体较大,通常为片、罩、盖等曲面结构拼接而成;而自行车的车体较小、单薄,一般由圆柱形结构组成。
电动车与摩托车相比,电动车车体较小,通常为曲面结构拼接而成,而摩托车的车体较大,车体较圆润,通常为角度的圆形或者圆柱形结构组成。
a3、动力特征。
具体实施中,不同类型车辆具有不同的动力特征。
例如,参阅图4E所示,仍以电动车、自行车和摩托车为例。
电动车的动力来源于蓄电池,通常蓄电池被安装在车座下部,或者电动车的踏板下部;而自行车的动力来源于目标人体对自行车的脚踏板施加的外力,因此,自行车不具有蓄电池等设施;摩托车的动力来源于液体燃料,通常油箱被安装在车身中部。
a4、车灯位置特征。
具体实施中,不同类型车辆具有不同的车灯位置特征。
例如,参阅图4F所示,仍以电动车、摩托车以及自行车为例。
电动车的车灯位置特征为通常安装在电动车车身的前面和后面;而摩托车的车灯位置特征为通常安装在摩托车车身的前面、后面、车身两侧;自行车则一般不安装车灯等照明设施。
…………。
因此,基于不同车辆具有的不同的车辆外形特征,可以将不同类型的车辆进行准确分类。
B、目标车辆与目标人体的占比特征。
具体实施中,由于目标车辆的车辆类型不同,对应的目标车辆的设计外形不同,从而就造成目标人体在目标车辆上的占比特征不同。
例如,参阅图5所示,仍以电动车、自行车和摩托车为例。
由于电动车的设计外形特征,目标人体会蜷缩着位于车身中,那么,针对于电动车,电动车与目标人体的占比约为2:1;
而自行车是目标人体骑在车身上,利用目标人体踏脚踏板,使自行车前行,那么,自行车与目标人体的占比约为3:1;
而摩托车通常是目标人体骑在车身上,利用液体燃料作为动力进行前行,那么,摩托车与目标人体的占比约为5:1。
因此,基于目标车辆和目标人体的占比特征,可以将不同的车辆进行分类。
C、目标人体的腿部运动特征。
具体实施中,由于不同的车辆的驱动方式不同,造成了不同的目标人体的腿部运动特征不同。
例如,参阅如图6所示,仍以电动车、自行车和摩托车为例。
在目标帧图像中,若目标人体是蜷缩着,通常为电动车;若目标人体的腿部存在伸展的动作,或者,目标人体的小腿和大腿有紧贴的状态,通常为自行车;若目标人体腿部一直保持伸展状态,通常为摩托车。
因此,基于目标人体的腿部运动特征,可以将不同的车辆进行分类。
D、轮胎形状特征。
具体实施中,不同类型的车辆具有不同的轮胎形状。
例如,参阅图7所示,仍以电动车、自行车和摩托车为例。
自行车的轮胎由圆环形的胎体、车轴以及连接所述胎体和所述车轴的钢丝圈组成,且钢丝圈具有交织网状结构;
而电动车的轮胎与自行车的轮胎相比,圆环形的胎体与车轴间不存在钢丝圈;
摩托车的轮胎要大于电动车的轮胎,但要小于自行车的轮胎,且摩托车的轮胎较宽、结实,表面花纹较明显,胎体与车轴间存在较粗的支撑件。
因此,基于所述轮胎形状特征,可以将不同的车辆进行分类。
E、轮胎与车身的占比特征。
具体实施中,不同的车辆具有不同的轮胎和车身占比,从而就存在着轮胎与车身的占比特征。
例如,参阅图8所示,仍以电动车、自行车和摩托车为例。
电动车用电力作为动力进行前行,为了安全考虑,电动车的重心越低越稳,从而就造成了电动车的轮胎与电动车的车身占比较小,通常为0.5;
而自行车借助人力作为动力进行前行,自行车通过脚踏板、链盘、齿轮构成的机械结构实现自行车的前行,基于力学知识,使人力最大限度的得到利用,一般采用增加自行车的轮胎与车身的占比的方式,相应的,自行车就具有了轮胎与车身的占比较大的特征,通常为0.8;
摩托车利用燃烧液体燃料作为前行动力,因此,摩托车的重心较低,对应的,摩托车的轮胎与车身占比也较小,通常为0.3。
因此,基于所述轮胎与车身的占比特征,可以将不同的车辆进行分类。
F、行驶车道特征。
具体实施中,不同的车辆在道路上行驶,占据不同的车道。
例如,参阅图9所示,仍以电动车、自行车和摩托车为例。
摩托车的车辆类型属于机动车,通常在道路上行驶时,占据机动车道;而电动车和自行车的车辆类型均属于非机动车,通常在道路上行驶时,占据非机动车道。
因此,智能设备可以根据车辆所占据的车道不同,将不同的车辆进行分类。
G、骑行姿势特征。
具体实施中,不同的车辆类型具有不同的骑行姿势。
例如,参阅图10所示,仍以电动车、自行车和摩托车为例。
摩托车和电动车相比,部分摩托车和电动车的车辆外形相似,但目标人体的骑行姿势不同,通常骑在摩托车上的目标人体的上半身(如胸部、上臂等)贴近车体,而骑电动车的目标人体的上半身往往是竖直的,骑自行车的目标人体的上半身稍向车身侧倾斜。
因此,智能设备可以基于目标人体的骑行姿态,将不同的车辆进行分类。
2)智能设备基于所述车辆特征,采用超分辨率检测序列网络,确定所述目标车辆的车辆类型。其中,所述车辆类型包含但不限于如下类型:
电动车;
电瓶车;
自行车;
摩托车;
三轮车;
蓄力车。
可选的,智能设备基于所述车辆特征,可以采用深度残差网络,确定所述目标车辆的车辆类型。
步骤130:若所述车辆类型为指定的非机动车类型,则智能设备基于所述第二检测结果,提取出所述目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况。
具体实施中,智能设备在执行步骤120之后,就可以确定出目标车辆的车辆类型。
可选的,智能设备在执行步骤130之前,进一步地,为了保证后续对目标人体的头部特征进行准确提取,可以先基于所述第二检测结果对目标人体的头部区域进行局部截取。具体的,智能设备可以按照以下步骤进行截取操作:
a、若所述车辆类型为指定的非机动车类型,则智能设备将所述第二检测结果包含的像素值与预设门限值进行比较。
具体实施中,智能设备按照步骤120确定的目标车辆的车辆类型,分别与指定的非机动车类型进行比对,当所述车辆类型为指定的非机动车类型时,则将所述帧图像对应的第二检测结果包含的像素值与预设门限值进行比较,其中,所述预设门限值用来表征对应的帧图像的分辨率,所述指定的非机动车类型包含但不限于如下类型中的任意一种或任意组合:
电动车;
电动三轮车等等。
b、智能设备确定所述像素值不小于所述预设门限值时,对所述第二检测结果中包含的目标人体的头部区域进行剪裁。
具体实施中,智能设备确定所述像素值不小于所述预设门限值时,对所述第二检测结果汇总包含的目标人体的头部区域进行剪裁,从而获得对应的目标人体的头部区域。
例如,参阅图11所示,仍以电动车和自行车为例。
假设智能设备按照步骤120确定的目标车辆的车辆类型为电动车和自行车,且指定的非机动车类型为电动车,以及确定的目标车辆的车辆类型为电动车的对应的帧图像为帧图像A。
那么,智能设备将帧图像A对应的第二检测结果包含的像素值与所述预设门限值进行比较。
又假设智能设备电动车对应的第二检测结果的像素为260,以及预设门限值为200像素。
那么,由于所述第二检测结果的像素260>200(预设门限值),则智能设备对所述第二检测结果中包含的目标人体的头部区域进行剪裁,从而,得到目标人体的头部区域,记为检测框A3。
另一方面,如果智能设备确定的所述像素值小于所述预设门限值,也可以不进行截取,对应的,也不启动告警机制。
基于上述流程,相应的,以对目标人体的头部区域进行截取操作获得的对应的子帧图像为例,若已确定的车辆类型为指定的非机动车类型(如电动车),则智能设备可以执行以下操作:
(1)智能设备基于所述第二检测结果,提取所述目标人体的头部特征,其中,所述头部特征包含但不限于以下特征中的任意一种和组合:
1)面部皮肤特征。
具体实施中,在所述第二检测结果中,由于目标人体的头部佩戴不同的头部配饰,可以呈现出不同的面部皮肤特征,其中,所述头部配饰可以是帽子,也可以是头盔,还可以是任意一种可以遮盖头部的物品。
例如,参阅图12所示,以电动车为例。
假设智能设备确定存在三张帧图像中的目标车辆均为指定的非机动车类型(即电动车),对应的三张帧图像记为帧图像A、帧图像B、帧图像C,那么,对应的第二检测结果分别记为检测框A2、检测框B2、检测框C2。
又假设检测框A2中目标人体的头部佩戴有头盔,检测框B2中目标人体的头部未佩戴任何头部配饰,检测框C2中目标人体的头部佩戴有帽子。
则,由于检测框A2中目标人体的头部佩戴有头盔,面部皮肤被遮挡,那么,智能设备基于检测框A2,提取出的面部皮肤特征为未检测到面部皮肤,或者,仅检测到较少的面部皮肤,通常所述面部皮肤与所述目标人体的头部区域的面积占比较小,通常约为0.1;
由于检测框B2中目标人体的头部未佩戴任何头部配饰,面部皮肤无遮挡,那么,智能设备基于检测框B2,提取出的面部皮肤特征为检测到的面部皮肤与所述目标人体的头部区域的面积占比较大,通常约为0.8;
由于所述检测框C2中目标人体的头部佩戴有帽子,面部皮肤存在部分遮挡,那么,智能设备基于检测框C2,提取出的面部皮肤特征为检测到的面部皮肤与所述目标人体的头部区域的面积占比,通常约为0.6。
因此,智能设备基于所述目标人体的面部皮肤特征,可以准确提取出对应的头部特征。
2)反光特征。
具体实施中,由于头盔由壳体,以及与壳体连接的透明塑料面罩组成,而透明塑料面罩以及壳体本身均具有反光特征,那么,在所述第二检测结果中,可以通过提取目标人体的头部区域的反光特征,准确地提取出对应的头部特征。
3)反光面积占比特征。
具体实施中,智能设备基于所述反光面积与所述目标人体的头部区域的面积占比,可以区分目标人体佩戴的反光物品类型。
例如,参阅图13所示,仍以电动车为例。
假设目标人体佩戴有墨镜,那么,墨镜的反光面积与所述目标人体的头部区域面积的占比较小,如0.2;
又假设目标人体佩戴有头盔,那么,头盔的反光面积与所述目标人体的头部区域面积的占比较大,如0.7。
因此,智能设备可以基于反光面积占比特征,准确地提取出对应的头部特征。
4)纹理特征。
具体实施中,不同的头部配饰具有不同的纹理特征。
例如,参阅图14所示,仍以电动车为例。
假设目标人体佩戴有头盔,由于头盔的材质特点,如塑料不具有明显的纹理特征,那么,在所述第二检测结果中,目标人体的头部区域呈现的头部特征不具有纹理特征;
又假设目标人体佩戴有头部配饰,如棉质帽子、毛织类帽子等,由于棉质以及毛织类帽子本身具有明显的线条纹理特征,那么,在所述第二检测结果中,目标人体的头部区域会呈现所述头部配饰所具有的明显的纹理特征;
又假设目标人体未佩戴头部配饰,那么,在所述第二检测结果中,目标人体的头部区域会呈现头发丝的纹理特征。
因此,智能设备基于纹理特征,可以准确地提取出对应的头部特征。
5)外形特征。
具体实施中,不同的头部配饰对应着不同的外形特征。通常佩戴有头盔的头部区域较圆润,而未佩戴头盔的头部区域不会呈现标准的圆形的外形特征,或者,佩戴有其他头部配饰的头部区域会呈现出不规则的外形特征,因此,智能设备基于不同的外形特征,可以准确提取出对应的头部特征。
6)颜色特征。
具体实施中,不同的头部特征对应着不同的颜色特征。由于头盔有多种颜色,那么,对应着佩戴有头盔的头部特征具有不同的颜色特征,而目标人体的头部颜色通常为头发以及皮肤的颜色,如黑色、肤色、茶色等,因此,基于不同的颜色特征,准确提取出对应的头部特征。
(2)智能设备基于所述头部特征,采用深度残差网络,确定所述目标人体的头盔佩戴情况。
具体实施中,智能设备基于所述头部特征,采用深度残差网络,可以确定所述目标人体的头盔佩戴情况。
可选的,智能设备基于所述头部特征,也可以采用超分辨率检测序列网络,确定所述目标人体的头盔佩戴情况。
(3)智能设备确定所述目标人体未佩戴头盔时,触发告警机制。
具体实施中,当智能设备确定所述目标车辆上所载乘的至少一个目标人体未佩戴头盔时,则触发告警机制,其中,所述告警机制可以是报警滴滴声,也可以是语音提示音。
例如,参阅图15所示,仍以电动车为例。
假设电动车上一共载乘两个目标人体,分别记为驾驶员和乘客。
假设智能设备基于第二检测结果(即,检测框A3),提取出对应的头部特征后,采用深度残差网络,确定的驾驶员头部佩戴有头盔,以及确定的乘客的头部未佩戴头盔,头部仅佩戴有帽子。
那么,由于智能设备确定的乘客未佩戴头盔,即,所述目标车辆上所载乘的至少一个目标人体未佩戴头盔,则触发告警机制,即发出报警滴滴声。
可选的,电动三轮车对应的目标人体的头盔佩戴情况的检测过程与上述检测过程类似,由于电动三轮车的车辆外形特征更具有辨识度,即电动三轮车具有三个轮胎,因此,相关检测过程在此不再赘述。
基于同一发明构思,参阅图16所示,本公开实施例提供一种图像检测的装置,包括:
提取单元1601,用于获取待处理的视频数据,提取出目标帧图像;
获得单元1602,用于对所述目标帧图像进行检测,获得第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;
第一确定单元1603,用于基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型;
第二确定单元1604,用于若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出所述目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况。
可选的,所述对目标帧图像进行检测,获得第一检测结果,所述获取单元1602用于:
基于所述目标帧图像,采用图像检测算法,对所述目标车辆和所述目标人体进行定位,确定包含所述目标车辆和所述目标人体的第一检测框,并将所述第一检测框作为所述第一检测结果;
所述对目标帧图像进行检测,获得第二检测结果,所述获取单元用于:
基于所述目标帧图像,采用图像检测算法,对所述目标人体进行定位,确定包含所述目标人体的第二检测框,并将所述第二检测框作为所述第二检测结果。
可选的,所述基于所述第一检测结果,提取相应的车辆特征,并基于所述车辆特征确定所述目标车辆的车辆类型,所述第一确定单元1603用于:
基于所述第一检测结果,采用特征提取算法,提取出所述目标车辆的车辆特征,其中,所述车辆特征至少包含以下特征中的任意一种或组合:车辆外形特征、所述目标车辆与所述目标人体的占比特征、所述目标人体的腿部运动特征、轮胎形状特征、轮胎与车身的占比特征、行驶车道特征、骑行姿势特征;
基于所述车辆特征,采用超分辨率检测序列网络VGG,确定所述目标车辆的车辆类型。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征之前,所述第二确定单元1604进一步用于:
若所述车辆类型为指定的非机动车类型,则将所述第二检测结果包含的像素值与预设门限值进行比较;
确定所述像素值不小于所述预设门限值时,对所述第二检测结果中包含的目标人体的头部区域进行剪裁。
可选的,所述若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果,提取出目标人体的头部特征,基于所述头部特征,确定相应的头盔佩戴情况,所述第二确定单元1604用于:
基于所述第二检测结果,提取所述目标人体的头部特征,其中,所述头部特征至少包含以下特征中的任意一种或组合:面部皮肤特征、反光特征、反光面积占比特征、纹理特征、外形特征、颜色特征;
基于所述头部特征,采用深度残差网络,确定所述目标人体的头盔佩戴情况;
确定所述目标人体未佩戴头盔时,触发告警机制。
基于同一发明构思,参阅图17所示,本公开实施例提供一种计算机设备,包括:
存储器1701,用于存储可执行指令;
处理器1702,用于读取并执行存储器1701中存储的可执行指令,以实现上述各个实施例中介绍的任意一种方法。
基于同一发明构思,本公开实施例提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由处理器执行时,使得所述处理器能够执行上述各个实施例中介绍的任意一种方法。
综上所述,本公开实施例中,智能设备基于获取的待处理的视频数据提取目标帧图像,并获得对应的第一检测结果和第二检测结果,其中,所述第一检测结果至少包含目标车辆和目标人体对应的图像区域,所述第二检测结果至少包含目标人体对应的图像区域;再基于所述第一检测结果提取的车辆特征确定目标车辆的车辆类型;若所述车辆类型为指定的非机动车类型,则基于所述第二检测结果提取的目标人体的头部特征,确定相应的头盔佩戴情况,这样,可以基于道路交通监控系统的视频数据,准确、高效地确定目标车辆的车辆类型,并能通过有效的筛选确定指定的车辆类型,以及确定所述指定车辆类型对应的目标人体的头盔佩戴情况,从而在降低人力成本的基础上,大大提高了对指定车辆类型的目标人体的头盔佩戴情况检测的效率,进而利用现有的道路交通监控系统的视频数据,也能够使该项检测工作做到全覆盖。
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本公开的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本公开范围的所有变更和修改。
显然,本领域的技术人员可以对本公开实施例进行各种改动和变型而不脱离本公开实施例的精神和范围。这样,倘若本公开实施例的这些修改和变型属于本公开权利要求及其等同技术的范围之内,则本公开也意图包含这些改动和变型在内。
- 脏污图像检测方法、脏污图像检测装置及脏污图像检测机构
- 图像检测方法、图像检测装置、图像检测设备及介质