基于骨架和语义信息混合的驾驶员行为识别方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及驾驶员行为识别技术领域,尤其涉及一种基于骨架和语义信息混合的驾驶员行为识别方法及系统。
背景技术
本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
驾驶员在驾驶过程中的行为是否规范,严重影响到驾驶安全以及道路安全。驾驶员行为识别是指识别车舱内驾驶员在驾驶过程中的各种行为,如打电话、喝水、调收音机等,广泛应用于辅助驾驶和自动驾驶系统,对驾驶安全具有重要意义。现有驾驶员行为识别方法多基于语义信息或骨架信息。基于语义信息的方法多采用图片或视频数据作为输入,前者缺乏时间信息及运动模式,后者存在大量冗余信息、计算量大;基于骨架信息的驾驶员行为识别方法以驾驶员骨架关键点序列作为输入,计算量小、推理速度快,但缺乏场景语义信息和目标交互信息,识别准确率低。注意力机制也广泛应用于驾驶员行为识别方法中,但往往没有针对驾驶员行为识别任务做相应优化,无法精确定位到驾驶员行为最相关的部分。另外,在夜间环境中,会由于驾驶数据亮度低,可用数据少的问题,导致模型训练困难,识别结果不准确,大大增加了行车安全隐患。
发明内容
针对现有技术存在的不足,本发明的目的是提供基于骨架和语义信息混合的驾驶员行为识别方法及系统,本发明扩展了用于驾驶员行为识别的数据模态,以语义信息和骨架信息作为模型输入分别在语义流和骨架流提取驾驶行为时空特征,借助基于驾驶员骨架关键点信息的空间软注意力机制在语义流高效提取驾驶行为相关的细节语义信息,并利用线性融合策略,融合语义流和骨架流的结果,输出最终驾驶员行为识别结果。
为了实现上述目的,本发明采用的技术方案为:提供了一种利用语义信息和骨架信息,借助基于驾驶员骨架关键点信息的空间软注意力机制和线性融合策略的驾驶员行为识别方法,包括:基于驾驶员骨架关键点信息的空间软注意力模块,基于驾驶员骨架和语义信息的混合网络,以及针对夜间驾驶数据亮度低和数量少问题的自适应直方图均衡化和迁移学习方法。
本发明第一方面提供了一种基于骨架和语义信息混合的驾驶员行为识别方法,包括以下步骤:
输入视频帧序列,利用姿态估计算法获取驾驶员骨架关键点序列,并从中提取驾驶员手部和头部关键点坐标;
在输入视频帧中,根据驾驶员2个手部和头部关键点为区域中心,设定值为半径的圆形区域的组合初步确定驾驶员行为相关感兴趣区域;
生成与输入视频帧大小相同的注意力掩膜,将注意力掩膜与相应输入视频帧叠加,获得带有注意力掩膜的视频帧序列;
利用骨架关键点序列和自适应图卷积神经网络得到骨架流预测结果;利用带有注意力掩膜的视频帧序列和慢速语义网络得到语义流预测结果;
以骨架流预测结果和语义流预测结果为输入,利用线性融合策略进行行为预测结果融合,获取最终的驾驶员行为识别结果。
进一步的,确定驾驶员行为相关感兴趣区域后,根据驾驶员行为特点,调整初步结果以得到最终驾驶员行为感兴趣区域。
进一步的,注意力掩膜中感兴趣区域设置高灰度值,背景区域设置低灰度值。
进一步的,获取骨架流预测结果的具体步骤为:以骨架关键点序列为输入,构建以驾驶员骨架关键点为顶点,以骨架关键点自然连接关系为边的骨架图序列,利用自适应图卷积神经网络提取驾驶员行为时空特征,得到骨架流预测结果。
更进一步的,首先对输入的骨架关键点序列进行数据扩增和批量归一化,然后利用自适应图卷积网络进行时空特征提取,自适应图卷积网络由9个自适应图卷积模块组成,在骨架流的末端为全局平均池化层和softmax层,输出骨架流预测结果。
进一步的,获取语义流预测结果的具体步骤为:以带有注意力掩膜的视频帧序列为输入,提取稀疏视频帧序列,利用慢速语义网络高效提取驾驶员行为时空特征,得到语义流预测结果。
更进一步的,以带有注意力掩膜的视频帧序列为输入后,对输入帧稀疏采样,借助调整后的3D ResNet网络进行特征提取,将语义流看作慢速语义特征提取网络,在慢速语义特征提取网络的末端引入全局平均池化、全连接层和softmax层,输出语义流预测结果。
进一步的,利用自适应直方图均衡化和迁移学习方法对夜间驾驶数据进行处理,从而实现夜间驾驶员行为识别。
更进一步的,以夜间驾驶员视频帧序列为输入,利用直方图均衡化操作调整图像的灰度值,将图像划分成若干个的小块区域,以自适应调整各区域的局部特征和边界,并限制图像对比度以降低噪声,获取灰度对比更强的夜间驾驶员视频帧序列;
以经过处理的夜间驾驶员视频帧序列为输入,迁移在日间驾驶员视频帧序列上训练得到的驾驶员行为识别模型到基于语义骨架空间注意力混合网络的驾驶员行为识别网络,训练针对夜间环境的驾驶员行为识别模型。
本发明第二方面提供了一种基于骨架和语义信息混合的驾驶员行为识别系统,包括:
骨架关键点获取模块,被配置为输入视频帧序列,利用姿态估计算法获取驾驶员骨架关键点序列,并从中提取驾驶员手部和头部关键点坐标;
感兴趣区域模块,被配置为在输入视频帧中,根据驾驶员2个手部和头部关键点为区域中心,设定值为半径的圆形区域的组合初步确定驾驶员行为相关感兴趣区域;
注意力掩膜模块,被配置为生成与输入视频帧大小相同的注意力掩膜,将注意力掩膜与相应输入视频帧叠加,获得带有注意力掩膜的视频帧序列;
结果预测模块,被配置为利用骨架关键点序列和自适应图卷积神经网络得到骨架流预测结果;利用带有注意力掩膜的视频帧序列和慢速语义网络得到语义流预测结果;
行为识别结果模块,被配置为以骨架流预测结果和语义流预测结果为输入,利用线性融合策略进行行为预测结果融合,获取最终的驾驶员行为识别结果。
以上一个或多个技术方案存在以下有益效果:
(1)本发明设计基于骨架关键点信息的空间软注意力模块,精确定位驾驶员行为相关感兴趣区域,有利于高效提取驾驶员行为相关区域特征。
(2)本发明设计基于驾驶员骨架和语义信息的混合网络,有效融合驾驶员行为相关的语义和骨架信息,两种信息优势互补,有效提升驾驶员行为识别准确性。
(3)本发明在夜间驾驶员行为识别任务中引入限制对比度的直方图均衡化操作和迁移学习方法,有利于解决夜间驾驶员行为数据亮度和对比度低、数量少的问题,提高夜间驾驶员行为识别方法的性能。
本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
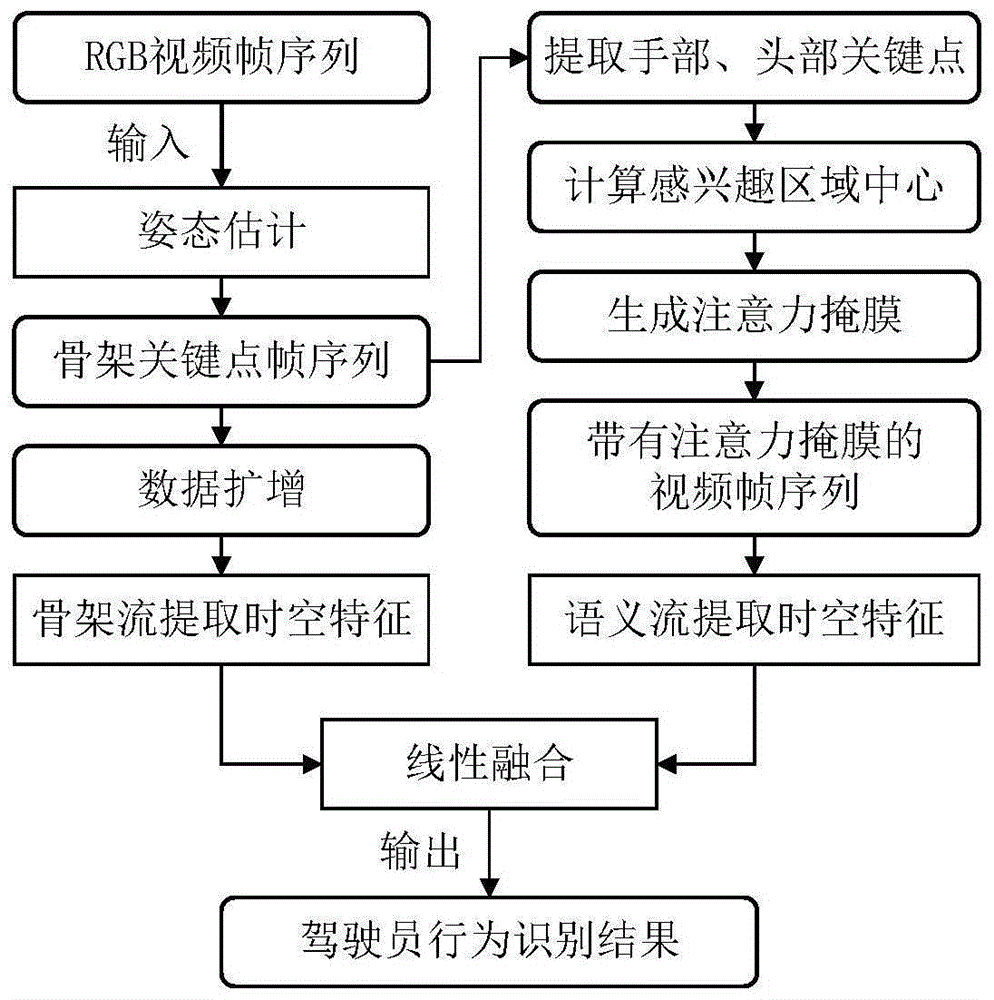
图1:本发明实施例一基于骨架和语义信息混合的驾驶员行为识别方法的流程图;
图2:本发明实施例一驾驶员行为识别中骨架关键点定义的示意图;
图3:本发明实施例一基于骨架和语义信息以及空间注意力混合模型的驾驶员行为识别网络的结构图;
图4:本发明实施例一针对夜间驾驶员行为数据的自适应直方图均衡化和迁移学习方法框架结构图;
图5:3MDAD驾驶员行为识别数据集样例图。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合;
实施例一:
本发明实施例一提供了一种基于骨架和语义信息混合的驾驶员行为识别方法,其流程图如图1所示,具体包括以下步骤:
步骤1:输入视频帧序列,利用姿态估计算法获取驾驶员骨架关键点序列,并从中提取驾驶员手部和头部关键点坐标,其中,关键点的定义遵从行为识别中普遍使用的两种定义之一:18点或25点,25个关键点与18个关键点定义的区别主要在足部,而驾驶员行为识别任务主要与驾驶员上半身动作相关,18个关键点即可较好的表征驾驶员行为。具体关键点如图2所示,其中,0为鼻子、1为脖子、2为右肩部、3为右肘部、4为右腕部、5为左肩部、6为左肘部、7为左腕部、8为右臀部、9为右膝部、10为右脚踝、11为左臀部、12为左膝部、13为左脚踝、14为右眼部、15为左眼部、16为右耳、17为左耳。
步骤1.1:输入驾驶员行为RGB视频帧序列I
步骤2:在输入视频帧中根据驾驶员2个手部和头部关键点为区域中心,设定值为半径的圆形区域的组合初步确定驾驶员行为相关感兴趣区域;本实施例中,根据驾驶员在图像中所占区域大小,设定半径为a、a、e,3个半径均约为驾驶员头部所占区域半径的2倍,因驾驶员行为多与手持物体相关,所以手部半径可适当增大。
步骤2.1:从步骤1获取的驾驶员骨架关键点序列中提取驾驶员手部和头部关键点序列H
步骤2.2:初步确定以手部和头部关键点为中心的圆形区域为感兴趣区域,因为驾驶员行为多与手部和头部区域相关(如:打电话),为尽量多覆盖目标区域而尽量少覆盖背景区域,设置以左、右手为中心的区域半径为a、a,以头部为中心的区域半径为e。
步骤2.3:确定驾驶员行为相关感兴趣区域后,根据驾驶员行为特点,调整初步结果以得到最终驾驶员行为感兴趣区域。具体的,结合驾驶行为特点,驾驶行为相关区域多位于肘部至手部的延申处和面部前方(如调收音机时,肘部至手部的延申处为驾驶行为高度相关的收音机;喝水时,驾驶行为高度相关的水杯位于驾驶员面部前方),所以进一步调整上述初步感兴趣区域,公式表示如下:
sgn(H'
其中(H
步骤3:如图3所示,基于骨架关键点的空间软注意力模块以及驾驶员骨架和语义信息混合网络,建立基于骨架和语义信息的空间注意力混合网络模型,基于骨架和语义信息的空间注意力混合网络模型用于生成骨架流预测结果和语义流预测结果。驾驶员骨架和语义信息混合网络包括语义流和骨架流,语义流为调整后的3D ResNet结构,用于提取视频帧序列时空特征,重点关注语义特征;骨架流为自适应图卷积神经网络结构,它主要由9个自适应图卷积块组成,用于提取骨架关键点序列时空特征,重点关注驾驶员行为动态变化特征。
步骤3.1:基于骨架关键点的空间软注意力模块生成与输入视频帧大小相同的注意力掩膜,将注意力掩膜与相应输入视频帧叠加,获得带有注意力掩膜的视频帧序列。
具体的,生成与输入视频帧大小相同的注意力掩膜M
λ为控制原始视频帧亮度的权值,λ>0。
步骤:3.2:利用骨架关键点序列和自适应图卷积神经网络得到骨架流预测结果;利用带有注意力掩膜的视频帧序列和慢速语义网络得到语义流预测结果;
步骤3.2.1:获取骨架流预测结果的具体步骤为:以骨架关键点序列为输入,构建以驾驶员骨架关键点为顶点,以骨架关键点自然连接关系为边的骨架图序列,利用自适应图卷积神经网络提取驾驶员行为时空特征,得到骨架流预测结果。其中特别关注驾驶员行为相关的动态变化特征,经过softmax网络层将结果映射到(0,1)区间。
具体的,骨架流以骨架关键点序列V
其中,f和v表示特征图和图节点,l
步骤3.3:获取语义流预测结果的具体步骤为:以带有注意力掩膜的视频帧序列为输入,提取稀疏视频帧序列,利用慢速语义网络高效提取驾驶员行为时空特征,得到语义流预测结果。其中特别关注驾驶员行为相关的空间语义特征,经过softmax网络层将结果映射到(0,1)区间。
具体的,语义流以步骤3中获取的带有注意力掩膜的视频帧序列A
更为具体的,骨架流和语义流分别是提取骨架序列和视频帧序列特征的两种网络模型。
骨架流为自适应图卷积网络,主要由9个自适应图卷积块组成,每个自适应图卷积块的组成为{自适应图卷积层,batch normalization层,Relu层,dropout层,时间卷积层,batch normalization层,Relu层},自适应图卷积层提取空间特征,时间卷积层(K
由于稀疏采样后,输入序列的时间跨度较大,早期层中使用时间卷积会降低精度,因此将语义流为调整的3D ResNet结构:仅在res4、res5上使用时间卷积,conv1,res2和res3不使用时间卷积,即可得到语义流结构,具体结构如表1所示。
表1:语义流各网络层细节
表1中,{T×S
步骤4:以骨架流预测结果和语义流预测结果为输入,利用线性融合策略进行行为预测结果融合,获取最终的驾驶员行为识别结果。
具体的,以步骤3中获取的骨架流和语义流的预测结果(O
O
其中α为骨架流预测结果的权重,若骨架流预测结果更好,则α>1,反之0<α<1。
步骤5:利用自适应直方图均衡化和迁移学习方法对夜间驾驶数据进行处理,从而实现夜间驾驶员行为识别。
具体的,夜间驾驶员行为数据存在收集难度大、数量少、亮度和对比度低的问题,导致夜间驾驶员行为识别难度更大。
以夜间驾驶员视频帧序列为输入,利用直方图均衡化操作调整图像的灰度值,直方图均衡化操作可用下式表示:
其中,cdf表示累积分布函数,归一化区间为[0,255],cdf
以经过处理的夜间驾驶员视频帧序列为输入,迁移在日间驾驶员视频帧序列上训练得到的驾驶员行为识别模型到基于语义骨架空间注意力混合网络的驾驶员行为识别网络,训练针对夜间环境的驾驶员行为识别模型。
作为进一步的技术方案,基于骨架和语义信息的空间注意力混合网络的训练,具体过程为:输入驾驶员行为视频帧序列,骨架流以视频帧序列经姿态估计算法得到的骨架关键点序列为输入,选择带有momentum的SGD作为网络的优化器,训练周期设置为55个epoch,初始学习率设置为0.1,分别在周期10和45变化为0.01和0.001,momentum设置为0.9。语义流以经过基于骨架关键点的空间软注意力模块处理的视频帧序列为输入,以步长16对带有骨架空间软注意力的视频帧序列进行稀疏采样,与骨架流类似,选择带有momentum的SGD作为网络的优化器,训练周期设置为600个epoch,学习率设置为0.1,momentum设置为0.9。线性融合策略使用的权值设置为0.7。
如图4所示,夜间驾驶员行为识别方法以经过对比度限制的自适应直方图均衡化操作后的视频帧序列为输入,输入帧图像大小为640×480,被分割成8×8大小的小块进行自适应直方图均衡化,对比度延伸值限制为5,其网络参数由在白天环境中的驾驶员行为识别模型进行初始化,在骨架流设置初始学习率为0.01,在语义流调整训练周期为300个epoch,其他超参数与白天环境中的驾驶员行为识别网络一致。
本发明对上述方案的技术效果进行了实验验证:
1.实验条件
本发明的所有验证实验的硬件条件为:CPU:intel Xeon 4114,RAM:256G,显卡:1块TITAN RTX。
实验所用软件环境为:ubuntu16.04,python3.7,pytorch=1.8.0,torchvision=0.9.0。
实验数据来自于3MDAD公开数据集,该数据集包含16类驾驶动作,如图5所示,表示的驾驶行为类别:
第一行分别表示为:A1安全驾驶,A2整理仪容,A3调收音机,A4调节GPS,A5左手使用手机;
第二行分别表示为:A6右手使用手机,A7左手打电话,A8右手打电话,A9自拍,A10与乘客交谈;
第三行分别表示为:A11手舞足蹈,A12疲劳或瞌睡,A13使用左手喝水,A14使用右手喝水,A15从后面拿东西,A16吸烟。
白天环境中采集了50人的数据,夜间环境中采集了19人的数据,本发明仅使用数据集中侧面摄像头采集到的RGB视频帧序列。
2.实验内容及结果
本发明在3MDAD数据集上进行了白天和夜间环境下的驾驶员行为识别实验,其中夜间环境下的驾驶员行为识别难度更大。表2为本发明所设计的方法与以往的算法之间的比较,其中评判指标采用识别准确率,数值越大表明效果越好。
表2不同算法在3MDAD驾驶员行为识别数据集上的性能比较
表2显示本发明在性能上优于以往的算法(表2中给出的实验结果来自于10次独立实验结果中位数的均值,以往算法的实验结果来自于相关论文)。除此之外,本发明还进行了消融实验,表3证明了基于驾驶员骨架关键点的空间软注意力模块、基于驾驶员骨架和语义信息的混合网络的有效性(表3中给出的实验结果来自于10次独立实验)。
表3基于语义骨架空间注意力混合网络的驾驶员行为识别消融实验结果
注:(-SSSA-M)和(+SSSA-M)分别表示语义流未使用和使用基于骨架关键点的空间软注意力机制。
此外表4证明了夜间驾驶员行为识别方法中,自适应直方图均衡化和基于骨架关键点的空间软注意力模块的有效性。
表4夜间驾驶员行为识别结果
注:(+equalization)表示在训练时使用限制对比度的自适应直方图均衡化结果,(+SSSA-M)表示使用基于骨架关键点的空间软注意力机制。
实施例二:
本发明实施例二提供了一种基于骨架和语义信息混合的驾驶员行为识别系统,包括:
骨架关键点获取模块,被配置为输入视频帧序列,利用姿态估计算法获取驾驶员骨架关键点序列,并从中提取驾驶员手部和头部关键点坐标;
感兴趣区域模块,被配置为在输入视频帧中,根据驾驶员2个手部和头部关键点为区域中心,设定值为半径的圆形区域的组合初步确定驾驶员行为相关感兴趣区域;
注意力掩膜模块,被配置为生成与输入视频帧大小相同的注意力掩膜,将注意力掩膜与相应输入视频帧叠加,获得带有注意力掩膜的视频帧序列;
结果预测模块,被配置为利用骨架关键点序列和自适应图卷积神经网络得到骨架流预测结果;利用带有注意力掩膜的视频帧序列和慢速语义网络得到语义流预测结果;
行为识别结果模块,被配置为以骨架流预测结果和语义流预测结果为输入,利用线性融合策略进行行为预测结果融合,获取最终的驾驶员行为识别结果。
夜间数据处理模块,被配置为利用自适应直方图均衡化和迁移学习方法对夜间驾驶数据进行处理,从而实现夜间驾驶员行为识别。
具体的,以夜间驾驶员视频帧序列为输入,利用直方图均衡化操作调整图像的灰度值,将图像划分成若干个的小块区域,以自适应调整各区域的局部特征和边界,并限制图像对比度以降低噪声,获取灰度对比更强的夜间驾驶员视频帧序列;
以经过处理的夜间驾驶员视频帧序列为输入,迁移在日间驾驶员视频帧序列上训练得到的驾驶员行为识别模型到基于语义骨架空间注意力混合网络的驾驶员行为识别网络,训练针对夜间环境的驾驶员行为识别模型。
网络训练模块,被配置为基于骨架和语义信息的空间注意力混合网络的训练。
具体的,输入驾驶员行为视频帧序列,骨架流以视频帧序列经姿态估计算法得到的骨架关键点序列为输入,选择带有momentum的SGD作为网络的优化器,训练周期设置为55个epoch,初始学习率设置为0.1,分别在周期10和45变化为0.01和0.001,momentum设置为0.9。语义流以经过基于骨架关键点的空间软注意力模块处理的视频帧序列为输入,以步长16对带有骨架空间软注意力的视频帧序列进行稀疏采样,与骨架流类似,选择带有momentum的SGD作为网络的优化器,训练周期设置为600个epoch,学习率设置为0.1,momentum设置为0.9。线性融合策略使用的权值设置为0.7。
夜间驾驶员行为识别方法以经过对比度限制的自适应直方图均衡化操作后的视频帧序列为输入,输入帧图像大小为640×480,被分割成8×8大小的小块进行自适应直方图均衡化,对比度延伸值限制为5,其网络参数由在白天环境中的驾驶员行为识别模型进行初始化,在骨架流设置初始学习率为0.01,在语义流调整训练周期为300个epoch,其他超参数与白天环境中的驾驶员行为识别网络一致。
以上实施例二中涉及的各步骤与方法实施例一相对应,具体实施方式可参见实施例一的相关说明部分。术语“计算机可读存储介质”应该理解为包括一个或多个指令集的单个介质或多个介质;还应当被理解为包括任何介质,所述任何介质能够存储、编码或承载用于由处理器执行的指令集并使处理器执行本发明中的任一方法。
本领域技术人员应该明白,上述本发明的各模块或各步骤可以用通用的计算机装置来实现,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。本发明不限制于任何特定的硬件和软件的结合。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。