无缝集成的微控制器芯片
文献发布时间:2024-04-18 19:52:40
技术领域
描述了无缝集成的微控制器芯片中管芯间信号的通信,该芯片包括驻留在单独的处理节点上的微控制器CPU、存储器和模拟器件。这种集成系统提供降低的成本或复杂性、更高的效率、更短的上市时间,同时保持无缝集成而不会造成明显的性能损失。
背景技术
除非明确识别为公开或众所周知,否则本文提及的技术和概念,包括出于上下文、定义或比较目的,不应当被解释为承认此类技术和概念是先前公知的或现有技术的一部分。本文引用的参考文献(如果有的话),包括专利、专利申请和出版物,无论是否明确并入,都出于所有目的通过引用整体并入本文。
在微控制器和微型计算机领域,我们面临着有效开发和集成适应各种环境和功能的I/O外设和系统的挑战。适用于一个行业的解决方案并不适用于所有行业,并且需要进行修改。这一挑战进而又产生了巨大的扩展问题,其中ASIC器件需要针对几乎所有控制功能进行修改。
现有解决方案将CPU、存储器和外设访问集成到单个管芯(die)上。I/O外设与CPU、时钟和存储器访问之间的接口被紧密耦合和管理,以实现期望的性能。
I/O或管芯内任何其它元件的改变可以涉及新的硬件和软件设计,以便维持管芯的性能和外部接口。CPU的改变将导致相同的结果。
此外,一些部件(诸如CPU逻辑和存储器)可以在一个制造过程中更好地实现,而其它部件(诸如高电压和精密模拟)可以在不同的制造过程中更好地实现。与在更适合其需求的制造过程中实现每个部件所能实现的效果相比,在同一管芯上实现所有部件会增加成本并降低性能。
由于总线、中断、直接存储器存取(DMA)与时钟之间的紧密关系和相关联的交互,CPU与I/O之间的解耦具有挑战性。
为了克服这个问题,现有的解决方案在管芯中提供了大量的导线(输入/输出),以启用外部接口来管理系统。或者一些解决方案将CPU与外设分开作为独立ASIC(有时是模拟ASIC),这给系统设计人员和程序员带来了复杂的接口问题。CPU与ASIC的分离没有解决将两者堆叠(或并排)在一起时的编程挑战。
用于管芯到管芯接口的编程复杂性包括必须使用大量CPU指令来对远程管芯上的外设执行逻辑操作。此外,对常用接口(诸如中断服务请求和直接存储器存取请求)的改变会导致软件必须使用轮询机制来管理此类功能或提供单独的通用输入/输出以与这些特征互连。某些特征(诸如总线事务的安全性管理、总线事务的外设数据流控制、事务错误报告和数据块传送)可能需要由软件直接管理,而在单管芯方法中,这些可以在硬件中处置。其它特征,如在CPU和电力管理之间提供自动PMU状态传播(其可以位于远程管芯上)也必须由软件管理,或者提供专用互连来直接传送标准信号。
因此,需要一种管芯间硬件架构,该架构允许桥接整个总线加上中断加上DMA和其它期望的结构,同时用逻辑结构取代大量的导线,这导致最小化管芯间通信接口,并且同时为每个管芯的部件提供在逻辑上与如果使用通常的完全并行信号集在同一管芯上实现它们所发生的情况等效的行为。允许位于与CPU不同的管芯上的外设通过全功能标准总线接口来实现的接口,允许外设被设计为与它们最终是位于与CPU相同的管芯上还是不同的管芯上无关。另外,在ASIC部分上添加/从其去除外设或在CPU与ASIC管芯之间移动部件不影响接口,从而启用与不同系统及其特定需求相关联的设计的快速改变。并且如果接口本身是通用格式,那么包含CPU的任何管芯都可以耦合到包含外设的任何管芯,即使这两个管芯并非都是针对这种特定布置而设计的。CPU管芯可以跨多种设计(包括当CPU管芯设计完成时最初未设想的设计)被使用。或者,非CPU管芯可以与多个不同的CPU管芯配对,以使用用于共用外设的共用设计高效地实现处理能力的变化。
发明内容
描述了一种系统。该系统可以包括:第一管芯,具有中央处理单元(CPU)和第一桥;第二管芯,具有第二桥,其中第二管芯不包括第二CPU或者具有与第一桥和第二桥不相关的第三CPU。而且,该系统包括电耦合到第一桥和第二桥的管芯到管芯互连,其中管芯到管芯互连包括比第一管芯中的第一总线和第二管芯中的第二总线更少的信号线。此外,第一桥和第二桥掩蔽管芯到管芯互连的存在,使得第二管芯的功能对于第一管芯上的主设备(例如,CPU)来说看起来好像是在第一管芯上实现的。
注意的是,第一管芯可以包括多个设备,其中的一个或多个设备可以充当总线主设备,其经由管芯到管芯互连参与到第二管芯上的总线从设备的总线事务。
而且,第二桥可以在由第一总线主设备最终决定暂停的事务之前暂停第一管芯上的总线主设备的事务,以允许第一管芯或第二管芯上的第二总线主设备对事务的服务经由管芯到管芯互连发生。
此外,第二管芯可以包括多个设备,其中的一个或多个设备可以充当相对于第一桥和第二桥的总线从设备。
此外,当仅实现第二管芯的单个实例时,第一管芯可以提供单个较宽带宽互连,同时对于存在第二管芯的两个实例的实施方式允许两个较低带宽连接。
在一些实施例中,在第一管芯上实现的软件模型与好像在单管芯系统上实现的软件模型相同。
注意的是,第一总线和第二总线可以具有共同的格式。例如,该格式可以包括:ARM高级微控制器总线架构(AHB)、AHBLite或AHB5。可替代地或附加地,该格式可以包括Wishbone架构。
而且,该系统可以包括:第二管芯上电耦合到第二管芯上的第三总线的第二总线主设备以及作为总线从设备电耦合到第三总线的第三桥;第一管芯上电耦合到第一管芯上的第四总线的第二总线从设备,以及作为总线主设备电耦合到第四总线的第四桥;以及在第三桥与第四桥之间传达第二信号的第二管芯到管芯互连,其中第二管芯到管芯互连的数量小于第二总线主设备与第三桥之间的信号线的数量。第一桥、第二桥和管芯到管芯互连可以使总线主设备能够以与总线事务好像发生在单管芯系统中相同的方式参与与总线从设备的总线事务。
此外,用于访问第二管芯上的总线从设备的CPU指令可以与好像总线从设备在第一管芯上实现时相同。
此外,第一桥和第二桥可以顺序地使用管芯到管芯互连来进行命令运输,然后进行选择性数据运输。在一些实施例中,命令运输在单个时钟周期中传送。可替代地,命令运输可以在多个时钟周期上序列化,同时对第一管芯透明或者同时对第一管芯上的软件模型透明。而且,用于序列化的序列化长度可以至少部分地基于命令内容而可变。
注意的是,命令运输可以保持相同的时钟周期,就好像系统是在没有第一桥或第二桥的单个管芯上实现的一样。
此外,对于管芯到管芯互连中的一个或多个,数据阶段可以具有不同的数据方向。例如,可以从命令内容解码出数据方向。此外,数据运输可以在单个时钟周期中被传送或者可以在多个时钟周期上被序列化。数据运输序列化长度可以从先前的命令内容解码。
在一些实施例中,管芯到管芯互连可以提供从第一管芯到第二管芯的关于后续阶段是命令阶段还是数据阶段的阶段指示。例如,阶段指示可以被用于为单个命令传送提供多于一个数据传送。
而且,可以根据在前一命令阶段期间提供的指令针对每个数据阶段更新第二管芯上的总线地址。
此外,第一桥可以响应于第一总线上的突发指示来执行多个数据阶段。
在一些实施例中,第一桥可以响应于第一总线上的顺序存取地址的检测而执行多个数据阶段。可替代地或附加地,第一桥可以响应于直接存储器存取(DMA)控制器指示而执行多个数据阶段。
注意的是,管芯到管芯互连可以实现与第一总线或第二总线不相关的事务。
而且,不相关的命令可以通过命令阶段期间的编码来指示。
另一个实施例提供了第一管芯。
另一个实施例提供了第二管芯。
另一个实施例提供了一种包括第一管芯、第二管芯和管芯到管芯互连的电子设备。
另一个实施例提供了一种用于在具有第一桥的第一管芯与具有第二桥的第二管芯之间进行通信的方法。这种方法包括由第一管芯和第二管芯执行的操作中的至少一些。
提供本发明内容是为了说明一些示例性实施例,以提供对本文描述的主题的一些方面的基本理解。因而,将认识到的是,上述特征是示例并且不应当被解释为以任何方式缩小本文描述的主题的范围或精神。从以下具体实施方式、附图和权利要求中,本文描述的主题的其它特征、方面和优点将变得明显。
附图说明
图1是图示单管芯系统的框图。
图2A是图示单管芯系统的实施例的选择的细节的框图。
图2B是图示包括CPU管芯、ASIC芯片和选择的内部架构的双管芯系统的实施例的选择的细节的框图。
图3是图示双管芯系统的实施例的所选择的细节的框图。
图4是图示具有减少的导线集合的双管芯系统之间的接口的实施例的所选择的细节的框图。
图5是图示总线事务的实施例的所选择的细节的图。
图6是图示总线错误传播和受保护的总线访问的实施例的所选择的细节的图。
图7是图示处置各种突发的实施例的所选择的细节的图。
图8是图示ASIC管芯上的中断源与CPU管芯上的中断控制器之间的中断桥接的实施例的所选择的细节的图。
图9是图示序列图的实施例的所选择的细节的图,该序列图示出了ASIC管芯DMA使能的总线从设备与CPU管芯DMA控制器之间的DMA请求同步。
图10A是图示用于双管芯系统的配置和发现过程的实施例的流程图。
图10B是图示用于具有固定ASIC管芯能力的双管芯系统的配置和发现过程的实施例的流程图。
注意的是,相同的附图标记贯穿所有附图指代对应的部分。而且,同一部分的多个实例由通过破折号与实例编号分开的共用前缀指定。
具体实施方式
所公开的通信技术可以以多种方式实现,例如,作为过程、制品、装置、系统、物质组合物以及诸如计算机可读存储介质之类的计算机可读介质(例如,光和/或磁大容量存储设备(诸如盘)、具有非易失性存储装置(诸如闪存存储装置)的集成电路中的介质),或者其中通过光或电子通信链路发送程序指令的计算机网络。如下文更详细地讨论的,本公开提供了所公开的通信技术的一个或多个实施例的阐述,其可以实现诸如安全性、成本、盈利能力、性能、效率和/或上述领域中的效用中的一项或多项的因素的改进。具体实施方式包括有助于理解具体实施方式的其余部分的介绍。介绍包括根据本文描述的概念的系统、方法、制品和计算机可读介质中的一个或多个的示例实施例。如下文更详细讨论的,所公开的通信技术涵盖所发布的权利要求的范围内的多种可能的修改和变化。
所公开的通信技术提供了管芯到管芯接口/桥,其允许以对最终用户透明的方式的多管芯微控制器实现。通过在两个管芯之间桥接几个标准微控制器接口,外设可以被实现为在很大程度上与它们是在两个管芯中的哪一个中实现的无关。事实上,用户将体验到单个微控制器单元。桥接不是微不足道的并且可以为现有技术中缺失的元素提供解决方案。
现有的总线扩展不支持单管芯微控制器中常见的特征和行为。人们会天真地认为,当我们将单个管芯拆分成多个管芯时,原则上我们可以连接所有导线。通常,这仅在理论上有效,并且常常要求用于每个内部接口的物理线路连接。
“连接所有导线”的方法没有任何意义,因为简单地将它都放在同一个管芯上会更容易。我们正在寻找的是最小化互连计数的数量,同时实现与多个远程管芯的合理地复杂的交互。所公开的通信技术可以优于传统的外部总线扩展(例如,I2C、SPI、并行存储器总线等)。值得注意的是,通信技术可以提供优势,诸如:
与用于单管芯集成的相同的软件编程模型。远程管芯上的总线外设直接对CPU总线存储器映射的存取做出响应。
虽然互连计数较少,但访问远程管芯上的外设的时延较低。在一些实施例中,这可以有效地使实际配置的附加时延为零。
减少由软件为每个远程外设访问操作执行的操作码(opcode)的数量,此外,操作码的数量与针对单个管芯的相同,但少于如果像其它外部总线扩展的东西被使用时的操作码的数量。
提供常用的总线特征,对CPU管芯上的主设备和远程管芯上的从设备使用常用的标准化接口,包括:当远程从设备未准备好数据递送(读或写)时,透明从设备停顿(stalling)(流控制);事务错误报告;支持安全性特征,例如访问特权/安全性;多个总线主设备(例如,CPU和DMA)之间远程从设备的自动仲裁;和/或突发模式传送。
以通常的方式,例如以对端点透明的方式,提供来自潜在大量外设的个性化中断请求能力。
以通常的方式提供来自外设的个性化DMA请求能力。例如,在与总线传送数据阶段同步的DMA数据传送期间的DMA请求解除断言(de-assertion)。
以透明的方式启用用于电力管理特征的管芯间同步。
除了总线访问特权(诸如调试端口访问)以外,还可以在CPU管芯与ASIC管芯之间启用透明的安全性特征配置。
独立于CPU管芯的远程管芯设计和制造-还可以在最后一刻添加或重新设计远程管芯上的接口/外设,而不影响CPU管芯或软件模型。
启用多管芯产品,其中不可能或不切实际集成在CPU管芯上的部件(例如,由于工艺技术不兼容)可以与实现这些部件的远程管芯配对,同时对两个管芯上的部件接口规范和编程者模型透明。
启用外设管芯的启动时间发现/映射。
启用运行时可调的互连计数,以将单个CPU管芯与具有不同互连计数的多个不同ASIC管芯配对,而无需改变远程管芯上的软件模型或外围部件设计。
连同图示所公开的通信技术的所选择的细节的附图,下面提供了所公开的通信技术的一个或多个实施例的详细描述。下面结合实施例对所公开的通信技术进行描述。本文的实施例应理解为仅仅是示例性的。所公开的通信技术明确地不限于本文的任何或所有实施例或受其限制,并且所公开的通信技术涵盖多种组合、替代、修改和等同形式。为了避免说明中的单调,可以将各种词语标签(诸如:第一、最后一个、某些、各种、另外的、其它、特定、选择、一些和值得注意)应用于单独的实施例集合;如本文所使用的,此类标签明确地不意味着传达质量或任何形式的偏好或偏见,而仅仅是为了方便地区分单独的集合。所公开的过程的一些操作的次序在所公开的通信技术的范围内是可更改的。无论在什么地方多个实施例用于描述过程、系统和/或程序指令特征的变化,都可以设想根据预定或动态确定的准则执行多种操作模式之一的静态和/或动态选择的其它实施例分别与多个实施例中的多个对应。在下面的描述中阐述了许多具体细节以提供对所公开的通信技术的透彻理解。提供这些细节是为了示例的目的,并且本发明可以在没有一些或全部细节的情况下根据权利要求来实践。为了清楚起见,没有详细描述与所公开的通信技术相关的技术领域中已知的技术材料,使得所公开的通信技术不会被不必要地模糊。
微控制器广泛用于各种系统和设备。设备常常利用多个微控制器在设备内一起工作以处置各自的任务。
微控制器是一种嵌入式实时设备,用于控制设备或更大系统中的单个功能或有限数量的功能。它通过使用它的中央处理器(CPU)和存储器解释从其外设接收的数据来做到这一点。外设可以是集成的(例如,集成到微控制器中的温度传感器或无线电通信接口)、模拟I/O接口(例如,模数转换器或LCD驱动器)或数字接口(例如,通用的单独输入/输出信号驱动器或SPI通信接口)。微控制器接收的临时信息存储在其数据存储器中,处理器在其中访问该信息并使用存储在其程序存储器中的指令来解密和应用传入的数据。然后,它使用其I/O外设进行通信和/或执行适当的动作。
例如,汽车可能有许多微控制器,用于控制内部的各种单独系统,诸如防抱死制动系统、牵引力控制、燃油喷射或悬架控制。此类微控制器可以负责与实现这些系统的硬件交互,诸如感测和控制模拟或数字部件。此外,这些微控制器常常使用通信接口彼此通信以协调它们的动作。有些可能与汽车内更复杂的中央计算机通信,而其他可能仅与其它微控制器通信。
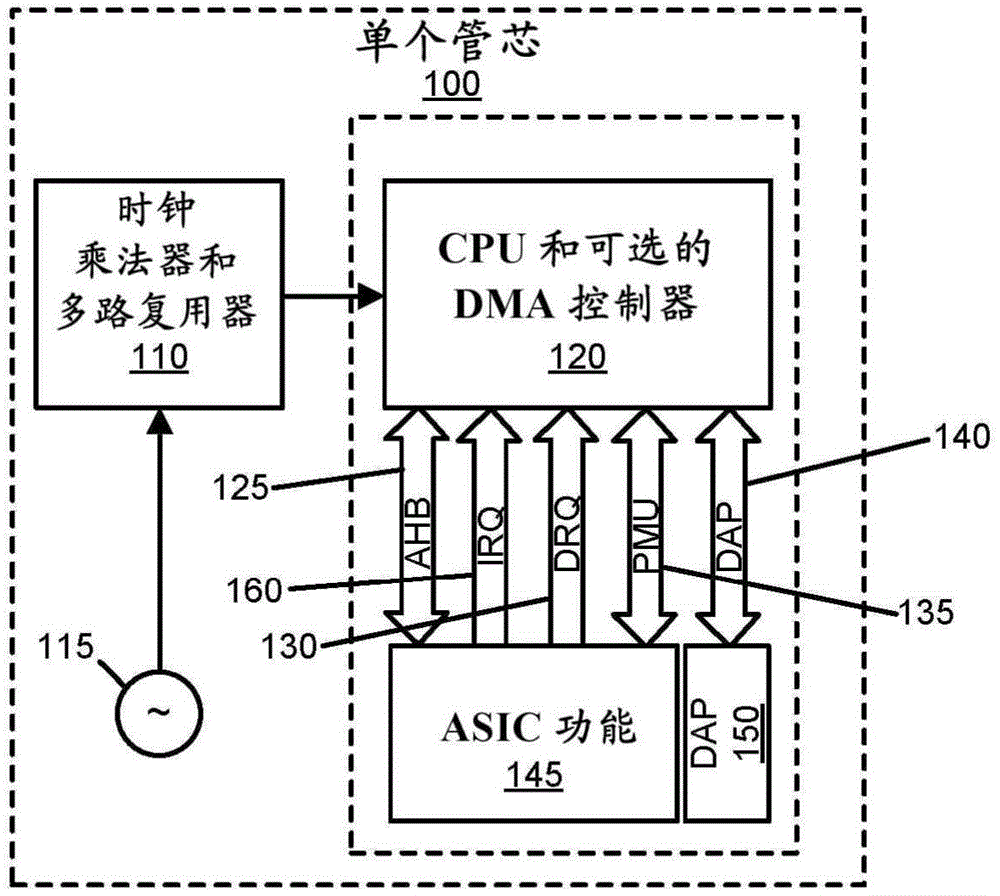
图1在高级别图示了单管芯微控制器100架构,包括时钟乘法器和多路复用器(mux)110及其源115、多个CPU和可选的DMA控制器120、与AHB总线125对接的基本ASIC功能145、用于管理中断的多个中断请求信号(IRQ)160、用于自动化DMA服务的多个DMA请求信号(DRQ)130、电力管理单元(PMU)接口135、以及通过调试访问端口接口140与CPU或其它内部部件中的一个或多个交互的调试访问端口(DAP)150。(注意的是,高级高性能总线或AHB是ARM高级微控制器总线架构(AMBA)中定义的总线架构,其是一种开放标准片上互连规范,用于片上系统(SoC)设计中的功能块的连接和管理。AMBA中的其它总线格式包括APB和AXI。)图1描绘了功能性和内部接口中的一些,当我们从单管芯设计转向所公开的通信技术的多管芯设计时,我们将更详细地讨论这些功能性和内部接口。贯穿本公开,我们可以如在一个实施例中那样使用AHB 125。所公开的通信技术不限于AHB总线设计的具体特点并且使用这种已知技术作为实施方式示例。此外,AHB接口125可以包括ASIC功能145内部的另外的总线层,诸如一个或多个APB总线,使得ASIC功能145内部的总线从设备可以通过AHB接口125附接,但不直接附接至其。
微控制器通常被提供为计算能力换取低成本。由于感测/反应序列的实时方面,微控制器中的计算性能通常经过优化,以通过界定感测/反应序列来界定系统的组合时延。执行这整个序列的时间常常可以以毫秒的分数来测量。这与计算处理器不同,计算处理器可以接受高得多且更可变的时延,但同时可能处置更大量不相关的任务并且针对更大时间尺度的平均性能进行优化。因此,将CPU连接到其外设资源的架构更加紧密地耦合。通常,微控制器CPU以与外设和主存储器相同的频率(或某个小倍数)运行,并预期CPU在CPU自己的主总线上(或桥接到某个不同格式的总线)以字(该特定系统的本机字位尺寸)级别与这些部件交互。目标施加访问延迟的每个字访问都导致处理器执行在该延迟期间停顿。计算处理器经过优化,通常与本地高速缓存存储器交互并具有各种缓解策略,以在高速缓存不包含期望数据时继续执行有用的工作。在这些处理器中,处理器主要通过高速缓存连接到非高速缓存部件。另外,在这种情况下,缓慢的外设访问通常会被变换成填充有缺失数据传输时的初始CPU执行停顿的高速缓存页面或块事务。通常,CPU将在其各个线程上测量到一些停顿,因为等待数据时停顿的线程只是总体工作负载的一部分,并且该线程常常可以在传输数据块时将其执行让给其它线程。此后,计算处理器可以高效地对整个数据块工作,而不会因访问时延而中断。由于微控制器更频繁地访问外设存储器并且通常以字为基础,因此慢外设将在每次访问字时再次使CPU停顿。出于性能原因,微控制器通常直接附接外设或直接桥接到CPU自己的总线结构。
CPU总线的名义目的是处置存储器(或存储器映射的)数据传送。但通常要求其它功能,因此在这同一总线上执行。这些任务包括:来自总线从设备的数据停顿;来自从设备的指示事务结果的响应(例如,ok或非法访问);和/或传送目的/特权的总线主设备指示,诸如:访问目的是代码或数据;访问来自内核或用户访问特权;事务是否是针对安全数据;和/或是否可以缓冲写访问(如果从设备慢,那么不必在继续下一个事务之前等待从设备响应)。
中断通常被微控制器用来允许外设指示时间关键事件的发生。外设可以驱动中断请求(IRQ)信号来指示可能要求CPU动作的状况。微控制器CPU通常与中断控制器配对,例如,嵌套向量中断控制器(NVIC),该控制器将各种IRQ线上的事件在它们发生时注册到中断待决寄存器中。(注意的是,嵌套向量中断控制(NVIC)是一种对中断进行优先级排序、提高CPU性能并减少中断时延的方法。NVIC还提供了处置当其它中断正在执行时或当CPU正在恢复(restore)其先前状态并重新开始(resume)其挂起进程时发生的中断的实现方案。)当用于该IRQ线的待决寄存器已被设置时,那个IRQ线上的后续改变将被忽略。此外,可以制定策略来为IRQ活动提供硬件响应,诸如自动开始执行与那个IRQ线相关联的代码块(中断处理程序)。如果被编程为自动执行中断处理程序,那么处理程序的执行通常自动清除相关联的中断事件寄存器。如果CPU选择不启用自动处理程序,那么CPU可以检查待决寄存器本身并将其清除以重新启用IRQ捕获。微控制器外设通常将其IRQ指示实现为到中断控制器的个性化信号,中断控制器具有多个输入端以接收此类信号。在一些情况下,微控制器外设可以预期提供多个IRQ信号,诸如在不同IRQ信号指示不同事件。
IRQ信号通常被称为基于电平或基于边沿。基于电平的中断通常用于预期解释是外设有一个或多个未处置的事件的情况。当外设可以发信号通知多种不同类型的事件并且多个此类事件可以同时发生时,这尤其合适。外设通常会在微控制器可通过总线访问的寄存器中标记未处置的事件(中断标志)。只要这个寄存器中标记了任何事件,外设就会断言IRQ线。一旦它处置了该事件(诸如执行响应动作或改变存储器状态以标记某个后续动作),CPU就可以通过总线访问将一个或多个事件从这个寄存器中清除。如果中断处理程序退出并且标志寄存器中存在未处置的事件,那么IRQ线仍将被断言,并且待决寄存器将被再次设置以进行进一步处理。
基于边沿的中断作为事件从外设传送到中断控制器,通常作为IRQ信号上的数据改变,诸如数据0后跟数据1(上升沿)。在这种情况下,中断控制器可以被配置为仅响应于这个序列而设置待决寄存器,并且外设可以确保每个外设事件仅递送这个序列一次。当来自外设的消息应当被解释为单个事件时,基于边沿的中断更常用(例如,如果需要准确计数事件的数量,或者如果由于IRQ线的停用在某个延迟之后被递送到中断控制器而使得意外重新进入中断处理程序会损害行为)。
微控制器可以通过直接存储器存取控制器来实现,以帮助自动化数据传送。微控制器通常实现第3方DMA,而不是第1方DMA,因此具有要移至另一个位置(诸如主存储器)/从另一个位置移动来的数据的外设可以警告DMA控制器要求进行操作,以便这个控制器可以实现作为总线主设备所需的操作,而外设作为总线从设备。第3方DMA的实施成本较低,但性能也较低。DMA事务可以或者由CPU发起,或者由外设发起。为了让外设警告DMA控制器存在期望的外设发起的事务,通常使用由外设驱动到控制器的DMA(DRQ)请求信号。然后,控制器可以根据CPU指派给该请求的策略来响应该请求。当尚未参与针对该策略的事务时,控制器将DRQ线上的活动电平解释为期望传送发生。除了某些异常情况(诸如CPU干预以取消待决的传送)之外,预期外设将继续进行请求,直到发生响应性传送。这可以是为了进行足够的传送以将数据缓冲器置于期望的充满级别、提供数据缓冲器可以被退出(retire)的指示,或者特定于发出请求的外设的操作的其它条件。微控制器外设通常将其DRQ指示作为单独的信号指示给DMA控制器,DMA控制器具有多个输入端来接收此类信号。在一些情况下,微控制器外设可以预期提供多个DRQ信号,诸如在不同DRQ信号上指示不同类型的所需传送。
DMA事务可以是固定长度或可变长度,DMA控制器可以使用合适的总线事务来实现,诸如一个或多个AHB总线访问或突发访问。例如,给定外设可能始终为每个请求传送固定长度的32字节数据。在其它情况下,每次传送的长度可以取决于具体情况,以便外设(但不是控制器)知道要传送的期望数据。允许第3方主设备处置这种情况的典型策略是让实现的外围逻辑在事务中仍有更多数据时将DRQ线保持在活动电平。然后,控制器可以在传送的每个字之后检查DRQ线,并在第一总线周期上断开传送,在该总线周期中,外设在数据被递送的同时对DRQ解除断言。由于这个原因,在与总线数据完全相同的周期将DRQ的解除断言递送到DMA控制器是有用的。否则,DMA控制器可能传送不正确数量的字。类似的考虑可以用于固定长度的DMA事务。如果外设在固定长度DMA事务接近结束时对其DMA请求解除断言,那么DMA控制器完成总线事务与DRQ解除断言到达之间的差异延迟会使得DMA控制器错误地感知到DRQ信号在前一个DMA事务完成后仍被断言,导致其不正确地发起后续事务。
图2A是现有单管芯架构的部件级描绘,具有附加的细节以帮助映射系统的一些复杂性。在图2A中,微控制器管芯200实现了与其外围部件220的多个互连,外围部件220表示可能的数据和事件总线线路,包括多条数据总线125、IRQ信号160、DRQ信号130、PMU接口135指示以及表示事件和状态的其它信号。这个总线和线路被用于与微控制器的其它子系统对接,诸如:具有互连220接口229的定制DSP逻辑211、具有互连220接口230的DMA控制器212、具有互连220接口231的RAM 216、闪存存储器213和具有互连220接口236的CPU 217以及其它ASIC逻辑,诸如具有互连220接口237的LV通信221、具有互连220接口238的LV传感器222、具有互连220接口239的LV致动器223、具有互连220接口240的通信接口(诸如CAN/LIN224)、具有互连220接口241的HV传感器225、以及具有互连220接口242的HV致动器226。请注意,这些只是实施例的示例并且可以包括其它元件。此外,我们添加了电力管理单元-PMU205、具有CPU接口234的调试器218、经由接口235提供时钟输入的振荡器219以及经由接口227与定制DSP逻辑211对接的复杂通信/传感器/致动器210。
互连220提供各种部件之间的通信。这些通信通常包括数据总线事务(例如,AHB)、IRQ信令、DRQ信令以及PMU控制和指示。这些互连通常由使用标准化接口(诸如CPU互连接口)的各种部件来访问。
注意的是,互连220包括某种嵌入式逻辑来辅助对于这些接口的低级需求并不罕见。例如,数据事务互连125可以频繁地包括块地址解码和数据多路复用功能,以辅助针对由总线主设备呈现的地址的正确总线从设备的数据总线事务的路由。在其它协议中,地址解码函数可以由每个总线从设备独立地计算,并且互连220中包括的逻辑利用来自各个总线从设备的地址匹配指示来辅助数据路由。为了提供多个数据总线主设备同时参与总线事务的能力,多道(lane)总线结构(例如,多层AHB)常常通过嵌入到互连220中的路由和争用解决逻辑来实现。此外,在存在时钟域交叉或时钟速率差异的情况下,将重定时或同步逻辑放置到互连220中也是常见的。
使用互连220的示例是CPU 217与LV传感器222之间的AHB数据总线125事务。这种事务可以由CPU 217在接口236中的AHB主信号上发出用于AHB事务的AHB地址阶段来发起。存在于互连220中的块地址解码逻辑解码出在用于这个事务的地址阶段中指示的地址是在分配给LV传感器222的地址块中。互连220然后将这个AHB地址阶段呈现给接口238中的AHB从信号。随后的AHB数据阶段通过接口236和238以及互连220在CPU 217与LV传感器222之间执行所请求的事务。数据阶段可以导致总线从设备立即传送的数据、在停顿之后传送的数据或不传送数据(这指示事务错误)。可以响应于格式错误的事务(诸如不正确的地址或数据尺寸),对于不允许的事务(诸如未经适当授权的事务)或出于其它原因,来指示事务错误。其它数据总线格式可以有其它事务结果。其它总线主设备可以类似地利用互连220来使用它们到互连220的接口中的AHB主信号来发起事务,诸如DMA控制器212使用接口230中的AHB主信号。其它总线从设备也可以使用其接口中的AHB从信号通过互连220进行事务,诸如定制DSP逻辑211使用接口229中的AHB从信号或RAM 216使用接口231中的AHB从信号。
使用互连220的另一个示例是HV致动器226发出中断请求,导致位于CPU 217中的中断控制器。HV致动器226可以在其接口242中的一个或多个中断请求源信号上指示中断请求。这个信号可以经由互连220被提供给接口236中的中断请求接收信号。实现这一点的一种方式是通过在接口236中提供多个编号的中断请求接收信号并将接口242中的中断请求源信号路由到这些编号的接收信号之一。然后,通过其它接口上的互连220连接的其它中断源信号可以被路由到接口236中的不同编号的中断请求接收信号。其它中断请求源可以通过其接口中的中断请求源信号的指示来指示通过互连220的中断请求,诸如使用接口229中的信号的定制DSP逻辑211。其它中断控制器可以通过其接口中的中断请求接收信号通过互连220接收中断请求,诸如DMA控制器212使用接口230中的信号。
使用互连220的另一个示例是经由DMA控制器212在LV通信221和RAM 216之间传输数据的DMA事务。LV通信221可以指示需要使用接口237中的一个或多个DMA请求源信号来执行该事务。互连220可以将该信号路由到接口230中的DMA请求接收信号,向DMA控制器212指示需要传输。实现这一点的一种方式是通过在接口230中提供多个编号的DMA请求接收信号并将接口237中的DMA请求源信号路由到这些编号的接收信号之一。然后,通过其它接口上的互连220连接的其它DMA请求源信号可以被路由到不同编号的DMA请求,这些不同编号的DMA请求作为接口230上的信号被接收。当接收到DMA请求时,DMA控制器212然后可以采取响应动作,例如经由接口230中的AHB主信号、经由互连220经由接口237和231中的AHB从信号,与LV通信221和RAM 216进行AHB事务。
在一些实施方式中,CPU 217可以具有用于与部件直接通信的附加连接。CPU 217可以通过专用接口232直接访问闪存存储器213,并且可以通过专用接口233访问RAM 216。这可以允许诸如更低的时延、更快的传送速率以及使用接口236在专用接口上并通过互连220同时进行传送的能力之类的益处。
许多微控制器系统包括电力管理功能,诸如电力排序和一种或多种睡眠模式以在不要求活动时节省电力。微控制器的CPU可以执行命令以进入这种睡眠模式,这会导致各种省电操作,诸如禁用时钟、禁用到逻辑块的电力、禁用到存储器的电力、禁用到模拟部件的电力、禁用提供给端口的给电源的电力,等等。CPU可以采取其所需的任何动作来使自身为这种睡眠模式做好准备,然后(参见图1)在PMU接口135上向PMU 205指示以指示应当执行睡眠。PMU 205可以实现逻辑来采取执行这个睡眠所必需的步骤。在许多情况下,PMU 205和CPU 217可以执行操作序列来执行电力模式改变,常常交换确认以指示序列中操作的完成。CPU 217通常具有专用接口256(其可以是PMU接口135的一部分)以使得能够与PMU 205进行这些交互。PMU 205还典型地具有到互连220的更通用接口283(其可以实现PMU接口135的至少一部分),诸如用于参数配置的数据总线信号、用于软件通知的中断请求等。
在执行睡眠之前,软件可以设置策略,诸如哪些资源在睡眠期间被禁用,以及什么条件会将处理器从睡眠状况唤醒。用于检测唤醒事件的一种常见技术是选择中断中的一个或多个以便一检测到就发起这种唤醒。由于中断控制器本身通常可以是睡眠电路系统的一部分,因此中断控制器的内部状态的一部分可以被传送到域的外部的逻辑以睡眠到唤醒中断控制器(WIC)中。WIC是PMU 205的逻辑的一部分。然后,这个WIC可以在睡眠期间保持活动,以检测适当的中断活动以发起唤醒。WIC然后可以指示PMU 205采取任何必要的步骤来重新启用睡眠禁用的资源。这一旦完成,就可以向CPU提供重新开始活动的指示。活动的这种重新开始的一部分可以是将WIC状态的相关部分传送回NVIC。这可以向CPU提供关于各种可能事件中的哪一个造成唤醒的指示,诸如通过在中断控制器中将那些中断置于待决状态。
为了促进软件开发和故障分析,微控制器管芯200可以通过用调试器逻辑218实现的调试端口来实现。这可以允许附接通信接口,该通信接口然后可以控制和/或检查微控制器管芯200的状态,诸如通过控制代码执行、检查寄存器内容、主控(mastering)数据总线上的事务、控制PMU状态等。CPU 217可以实现专用接口234以启用这些调试操作。
图2B描绘了将单管芯微控制器200拆分成双管芯系统、同时保留全部功能性并且无需对软件模型进行改变的实施例。所公开的通信技术实现了“保留全部功能性并且无需对软件模型进行改变”的原则。现有方法无法满足这些准则。原本在单管芯微控制器200上实现的部件改为在具有CPU管芯246和ASIC管芯271的多管芯系统中实现。CPU管芯246实现CPU 217、RAM 216、闪存存储器213和DMA控制器212。ASIC管芯271实现振荡器265、低压通信外设221、低压传感器外设222、低压致动器外设223、CAN/LIN通信外设224、高压传感器225、高压致动器226、定制DSP逻辑211及其相关联的模拟块210。PMU 205被分解成在CPU管芯246上实现的PMU控制器244和在ASIC管芯271上实现的PMU 268。CPU管芯246包括提供那个管芯上的各种部件之间的连接性的互连248。ASIC管芯271包括提供那个管芯上的各种部件之间的连接性的互连272。
这个示例中每个部件的管芯位置的这种选择具有几个优势。CPU 217、闪存213、RAM 216和DMA控制器212,与诸如HV传感器225、HV致动器226、CAN/LIN 224、PMU 268和复杂通信/传感器/致动器210之类的一些其它部件难以在同一半导体工艺中实现或者实现起来昂贵。通过将系统分布在多个管芯上,每个管芯可以以适合位于该管芯上的部件的半导体工艺技术来实现。此外,位于CPU管芯246上的部件相对通用,而ASIC管芯271上的部件更特定于特定应用。通过使用这种布置,一个产品可以有可能使用与ASIC管芯271配对的CPU管芯246,而其它产品使用与不同ASIC管芯配对的相同CPU管芯246,该不同ASIC管芯具有针对不同应用选择的部件。
将这些部件中的一些放置在CPU管芯246上并且将其它部件放置在ASIC管芯271上提出了挑战,因为它们中的许多已经在单管芯微控制器200中经由互连220彼此连接。看似简单的解决方案将是为ASIC管芯271上的部件的互连220信号提供专用的管芯到管芯互连261,使得互连220与用于单管芯微控制器200的相同,但作为互连248、互连272和管芯间信号261的组合分布在两个管芯上。但是,经过检查,这种设计方法对典型系统提出了挑战,因为所需管芯间信号261的数量对于实现来说是不现实的并且无法扩展。这种方法的另一个缺点是管芯间信号261特定于位于ASIC管芯271上的特定部件,因此将CPU管芯246与包含不同/修改的部件的不同ASIC管芯配对要求针对每个新ASIC管芯271重新设计CPU管芯246。
在所公开的通信技术的一个实施例中,CPU管芯246与ASIC管芯271之间的连接性是用数量显著更少的管芯到管芯互连262来实现的。这些互连通过一对通信桥连接:位于CPU管芯上的主桥245和位于ASIC管芯上的从桥264。主桥245在其接口260上访问CPU管芯互连248。从桥264在其接口201上访问ASIC管芯互连272。接口260、主桥245、管芯到管芯互连262、从桥264和接口201的组合一起作用,使得CPU管芯246上的部件可以与ASIC管芯271上的部件以类似于如果实现更大数量的管芯间信号261将会发生的方式进行交互。此外,到CPU管芯互连248的CPU管芯部件接口可以与用于到单管芯互连220的那些部件接口相同。类似地,到ASIC管芯互连272的ASIC管芯部件接口可以与到单管芯互连220的那些部件接口相同。例如,CPU接口236和LV传感器接口238中的AHB信号可以与它们在单管芯200实施方式中的相同,即使它们位于不同的管芯上并且分别附接到不同的互连248和272。
在所公开的通信技术的一个实施例中,管芯到管芯互连262被用于事务和消息交换。这些事务和消息交换以类似于实现更大量简单管芯间信号261将发生的方式在CPU互连248与ASIC管芯互连272之间传播相关改变。例如,如果用于LV传感器222的接口238中的信号从数据零改变为数据一,那么这种改变可以传播到互连248中的等效信号。为了实现这一点,互连272可以将这个信号传播到接口201,在那里从桥264可以检测数据转变。从桥264然后可以调度消息或事务以将这个数据改变传送到主桥245。主桥245然后可以通过接口260调整这个信号的同步版本,使得其在互连248中可供CPU管芯246中的部件使用。类似地,主桥245可以观察互连248信号中的改变用于通过管芯到管芯互连262和从桥264的同步,并且经由接口201在ASIC管芯互连272上提供这样的信号的同步版本以供ASIC管芯271中的部件使用。
简单信号可以以这种方式通过数据改变传播来同步,在其它实施例中,互连248和272中的许多典型信号和信号组通过利用它们的系统意图和特性来同步。例如,与数据总线事务相关的信号组(诸如AHB)已经指示部件之间的事务。由这些信号组暗示的数据总线事务可以被检测到并在桥之间作为桥之间的特殊编码事务传播,以被重新主控为另一个管芯上的等效事务。通过完成握手实现顺序PMU状态改变的信号组可以类似地变换成桥之间适当的特殊编码事务。中断请求和DMA请求可以以对这些接口的信令意图更有效的方式被编码成事务或消息。
我们使用前面讨论的如在双管芯系统中实现的CPU 217与LV传感器222之间的AHB数据总线事务作为示例,其中两个部件分别位于CPU管芯246和ASIC管芯271上。如前所述,这个事务由CPU 217在接口236中的AHB主信号上发出用于AHB事务的AHB地址阶段来发起。存在于互连248中的块地址解码逻辑解码出在用于这个事务的地址阶段中指示的地址是在分配给ASIC管芯地址范围的地址块中。互连248然后将这个AHB地址阶段呈现给接口260中的AHB从信号。这由主桥245检测到,然后主桥245通过管芯到管芯互连262调度对应的特定于AHB的管芯间事务。从桥264检测并解码这个管芯间事务并且在接口201中的AHB主信号上发出等效AHB事务的其自己的AHB地址阶段。存在于互连272中的块地址解码逻辑解码出在用于这个事务的地址阶段中指示的地址是分配给LV传感器222的地址块。然后互连272将这个地址阶段呈现给接口238中的AHB从信号。这导致两个不完整的AHB事务,一个在CPU 217与主桥245之间,另一个在从桥264与LV传感器222之间。取决于实现,这些事务可以通过组合地跨桥转发检测到的事务而在同一时钟周期上发出,或者可以在接口231上呈现的地址阶段与接口201上呈现的相关联地址阶段之间有一个或多个时钟周期的传播和/或仲裁时延。
然后,两个AHB事务都必须完成其AHB数据阶段。由CPU 217在接口236上提供的任何写数据都由互连248路由到主桥245的接口260。这个数据通过到从桥264的管芯间互连262作为管芯间事务的数据阶段被传播到ASIC管芯271,然后从桥264在其接口201上提供该数据作为AHB数据阶段。互连272将这个数据路由到接口238以供LV传感器222使用。由LV传感器222在接口238上提供的任何读取或响应数据由互连272路由到从桥264的接口201。这个数据作为管芯间事务的数据阶段通过管芯间互连262传播到主桥245,然后主桥245在其接口260上提供该数据作为AHB数据阶段。
管芯间事务格式不需要是桥接的AHB事务的直接编码、处于相同的数据速率或者使用相同的本机总线宽度。仅需要管芯间事务格式能够中继地址和数据阶段使得接口260和201中的对应AHB事务以正确的结果完成即可。在一些实施方式中,可能期望减少互连262信号计数,使得信号可以在地址与数据阶段之间共享,或者可以序列化为多个更小的传送。出于AHB事务桥接的目的,用于管芯间事务的信号也不必专门用于此目的。在那些互连262信号不忙于中继AHB事务的时间期间,其它同步或通信需要可以通过不同编码的管芯间事务来使用那些相同的互连262信号。
需要注意的一件事是互连248和272中的块地址解码逻辑形成两级块地址查找。互连248中的块地址解码逻辑不需要知道事务地址映射到ASIC管芯271部件中的特定块,仅需要它映射到可以是其中之一的地址。一旦在接口201上重新主控AHB事务,互连272中的地址解码逻辑就可以重新检查地址并路由到ASIC管芯271上的正确部件。这可以允许CPU管芯246实现简单且通用的地址解码器,诸如通过将大块地址预先分配给ASIC管芯部件,使得互连248中的地址解码逻辑在与不同ASIC管芯配对时不需要改变。
管芯间同步的另一个示例是先前讨论的从HV致动器226到CPU 217中的中断控制器的中断请求。HV致动器226可以在其接口242中的一个或多个中断请求源信号上指示中断请求。这经由互连272传播到从桥264的接口201中的中断请求接收信号。从桥264然后可以在管芯到管芯互连262上调度消息或事务以将检测到的中断激活传播到主桥245,主桥245通过在其接口260中的一个或多个中断请求源信号上指示中断请求来响应。这个信号可以经由互连248提供给接口236中的中断请求接收信号。在一种实施方式中,从桥264可以在接口201中提供多个编号的中断请求接收信号,每个信号可以经由互连272路由到ASIC管芯271上的各种部件的接口中的中断源信号。主桥245然后可以在接口260中实现相同数量的中断源信号,可以经由互连248将其提供给CPU管芯部件。
从桥264可以通过经由管芯到管芯互连262提供枚举的事件消息来将各种编号的中断请求激活传送到主桥245。不必所有这样的枚举消息都与中断激活对应,使得其它枚举消息可以用于其它目的。此外,在某些情况下,有可能与用于其它目的的互连中的信号共享用于这个消息传递的管芯到管芯互连262中的信号,诸如当有管芯间事务发生时与管芯间事务响应信号共享。在期望较低时延的情况下,还有可能将管芯到管芯互连262信号的子集专用于这个事件消息传递功能。
如本公开中其它地方所讨论的,使用不同的机制来处置中断请求激活和停用可以是有利的。例如,在接口201处检测到的中断请求激活可以通过管芯到管芯互连262经由事件消息传播到CPU管芯246,而停用可以通过另一个机制(诸如管芯到管芯互连262上合适的管芯到管芯事务)来检测。
管芯间同步的另一个实施例是先前讨论的经由DMA控制器212从LV通信221和RAM216进行的DMA发起的数据传送。LV通信221可以指示需要使用接口237中的一个或多个DMA请求源信号来执行这个事务。互连272可以将这个信号路由到DMA请求并在接口201中接收信号。从桥264然后可以在管芯到管芯互连262上调度消息或事务以将检测到的DMA请求激活传播到主桥245,主桥245通过在其接口260中的一个或多个DMA请求源信号上指示DMA请求来响应。互连248可以将这个信号路由到接口230中的DMA请求接收信号,向DMA控制器212指示期望传送。在接收到DMA请求时,DMA控制器212然后可以采取响应性动作,诸如经由接口230中的AHB主信号与LV通信221和RAM 216进行AHB事务。由于RAM 216与DMA控制器212位于同一管芯上,因此它们之间的通信可以与单管芯实施方式200类似地通过互连248进行。与单管芯实施方式200中一样,DMA控制器212通过在其接口230上发起数据总线事务来发起它与LV通信221的通信,但是互连248中的块地址解码逻辑在接口260处选择主桥245作为目标从设备。然后,通过管芯到管芯互连262的数据总线事务可以以类似于先前描述的CPU217和LV传感器222数据总线事务的方式进行。DMA控制器212不必知道LV通信221位于不同的管芯上。
在一种实施方式中,从桥264可以在接口201中供给多个编号的DMA请求接收信号,每个信号可以经由互连272路由到ASIC管芯271上的各种部件的接口中的DMA请求源信号。主桥245然后可以在接口260中实现相同数量的DMA请求源信号,可以经由互连248将其提供给CPU管芯部件。
从桥264可以通过经由管芯到管芯互连262提供枚举的事件消息来将各种编号的DMA请求激活传送到主桥245。不必所有这样的枚举消息都与DMA激活对应,使得其它枚举消息可以用于其它目的,诸如前面提到的中断请求激活。还可以使用如针对中断信令所讨论的通过与其它功能共享消息信令来减少管芯到管芯互连计数的(一个或多个)类似机制。
以周期准确的方式更新到DMA控制器212的接口230的DMA请求指示可以是有用的,使得DMA控制器212可以对DMA请求的停用做出响应,诸如通过停止传送或在完成的操作之后不执行后续操作。为了实现这一点,用于主桥245和从桥264之间经由管芯到管芯互连262的管芯到管芯事务的响应信号可以指示对DMA请求信号的更新,作为数据阶段传送的一部分。例如,如果LV通信221在数据总线事务数据阶段期间在接口237上提供不活动的DMA请求源信号,那么从桥264可以在接口201处检测到这一点并提供变体事务响应以包括这个更新后的DMA请求信息,作为管芯间事务数据阶段的一部分。这可以由主桥245检测到,主桥245然后可以更新其在接口260上的DMA请求源信号,以便在与接口260上的数据总线事务的数据阶段完成的相同周期上提供这个更新。在一个实施例中,DMA控制器212可以在接口230上提供附加信号,作为数据总线地址阶段的一部分,以指示哪个DMA请求对于那个总线事务是感兴趣的。然后,这可以作为附加地址阶段信号经由互连248被路由到接口260,使得管芯到管芯互连262上的管芯间事务可以向从桥264提供这个信息,使得它知道对于那个数据总线事务要监视其接口201上的哪个DMA请求。
管芯间同步还可以被用于同步电力管理功能。由于PMU 268位于ASIC管芯271上,因此它不能直接访问位于CPU管芯246上的CPU PMU接口256。为了使得PMU状态改变和握手事务能够在CPU 217与PMU 268之间发生,这些状态改变和事务可以通过管芯到管芯互连262以及桥245和264被变换成管芯间事务和消息。这可以通过将PMU控制器逻辑244包括到ASIC管芯246中来实现,ASIC管芯246可以与CPU 217交互,就好像它是PMU 205一样,同时实际上形成同步桥的一端以与PMU 268交互。为了实现这一点,PMU控制器244使用接口258与主桥245通信,而PMU 268使用接口281与从桥264通信。然后,通过接口256交换的事务和消息沿着这条路径通过管芯到管芯互连262被变换成管芯间事务或事件。这可以允许CPU 217以与CPU 217与单管芯实施方式的PMU 205交互类似的方式与PMU 268交互,并且允许CPUPMU接口256在两种情况下相同。这些管芯间事务和事件不需要管芯到管芯互连262中的专用导路,因为它们可以与用于其它目的的导线共享,诸如通过提供用于PMU使用的管芯间事务编码或通过创建供PMU使用的枚举事件消息。
管芯间同步还可以辅助定位对ASIC管芯271的调试访问(例如,在安全性管理器267中)。这可以在几个方面对多管芯系统有益。由于PMU 268位于ASIC管芯271上,因此整个CPU管芯246在处于非常低功率状态时有可能无时钟和/或断电。如果调试访问位于ASIC管芯271上,那么外部调试器可以通过接口282与PMU 268交互以允许改变电力模式,使得它可以在调试会话期间通过覆盖无时钟或无电力模式来发起或维持与CPU管芯246的通信。即使当CPU管芯217无时钟或未通电时,外部调试器也可以与ASIC管芯271部件交互,诸如通过在互连272上主控数据总线事务,诸如通过使用接口280与从桥264通信以主控接口201上的AHB事务。当CPU管芯246损坏或不存在时,这还可以允许调试器支配ASIC管芯271部件,诸如用于在制造期间部分组装的产品的故障分析或测试。
在ASIC管芯上定位调试访问的另一个益处是允许用于这个端口的外部电压信令与CPU管芯246上使用的电压解耦。这可以通过减少信令电压的数量或范围来简化CPU管芯246的设计,并且还允许使用具有不同ASIC管芯的CPU管芯246的不同产品具有不同的信令电压。
为了使连接到调试访问的调试器能够与CPU 217交互,可以使用通过管芯到管芯互连262的管芯间同步。这可以通过在CPU管芯246上包括CPU调试逻辑299来实现。CPU调试逻辑299可以使用接口234以与在单管芯实施方式200中调试器逻辑218与CPU 217交互类似的方式与CPU 217交互。这可以通过经由管芯到管芯互连262以及桥245和264将调试操作变换成事务或事件来实现。CPU调试逻辑299可以使用接口234与CPU 217交互,就好像它是单管芯实施方式200中的调试器218一样,同时使用到主桥245的接口257将这些操作变换成跨管芯到管芯互连262的适当信令。ASIC管芯271上的从桥264然后可以使用接口280来与安全性管理器267中的调试访问逻辑交互以执行期望的调试器操作。用于这个目的的互连262信号可以与用于其它目的的信号共享,诸如通过提供供调试器使用的管芯间事务编码或通过创建供调试器使用的枚举事件消息。在一些实施例中,不同宽度的互连262可以与不同的ASIC管芯和所公开的能力发现一起使用。例如,低端产品可以使用速度较慢且引脚数较少的调试,而高端产品线可以允许更详细的跟踪和调试。
可以通过将安全性管理器267添加到ASIC管芯271来改进调试访问逻辑的安全性。这个安全性管理器可以被用于在允许附加的调试器被呈现给其它接口(诸如用于CPU 217调试器操作的接口280或用于PMU调试器操作的接口282)之前核实其具有适当的授权。这可以包括仅允许具有所需安全性凭证的调试器进行一个或多个调试器操作、仅当产品处于某一生命周期状态时允许一个或多个调试器操作,或者仅当产品处于所需操作模式时允许一个或多个调试器操作。
为了允许CPU管芯246部件影响和存储安全性策略,安全性管理器243可以被包括在CPU管芯246上。可以向安全性管理器243提供经由接口252对诸如闪存存储器213之类的非易失性存储器的访问,用于存储诸如产品生命周期状态、调试器授权凭证和其它安全性配置之类的安全性策略配置。安全性管理器267可以使用管芯间事务管理通过桥245和264通过管芯到管芯互连262同步到安全性管理器的安全性策略。用于这些管芯间事务的互连262中的信号可以与用于其它目的的信号共享。
在单管芯微控制器上已连接到调试器218的调试通信端口现在位于ASIC管芯271上并且连接到调试访问逻辑。
注意的是,对于为了不同的同步目的而共享互连262中的导线,可能需要在桥245和264的逻辑中的共享导线的各种用途之间包括仲裁和优先化。当多个竞争的服务需要同步时,这个仲裁逻辑可以在各种服务中选择服务次序,同时使其它服务等待时间分配。
在ASIC管芯271上,我们实现了振荡器265及其到桥264的接口279,因此时钟被扩展到桥并扩展到CPU管芯246。调试访问使用安全性管理器267通过接口280连接到桥主设备264,以通过互连262扩展调试访问。PMU 268可以在ASIC管芯271上提供电力管理特征,并且可选地还为CPU管芯246提供电力供应,并且可以使用安全性管理器267通过互连280与CPU管芯上的PMU控制器244同步。可以包括诸如AHB、IRQ信号、DRQ信号和外围PMU指示之类的总线接口的外设接口272可以通过互连262经由桥主设备245和264以及接口260和201与它们的类似对应物248同步。(注意的是,外设接口272可以耦合到外设221、222、223、224、225和226,这些外设可以具有与单管芯200上的对应外设相同的实施方式。)由于接口248、257和258中信号的数量可能太大而无法直接可行地互连,桥主设备245和264协调以提供完成此操作的逻辑效果261,使得诸如CPU 217、DMA控制器212以及外设221、222、223、224、225和226之类的部件可以以与单管芯微控制器200上的相同部件所实现的方式相同的方式分别实现其接口237、238、239、240、241和242。
注意的是,管芯到管芯互连262可以执行物理链路以启用用于各种互连220服务的逻辑链路262。管芯到管芯互连262接口在图4中详细描述。它连接在CPU管芯桥主设备245与ASIC管芯桥主设备264之间。这个互连262有效地启用并实现了相应桥主设备245和264内的两个管芯之间的接口261的集合的扩展。
可以容易地看出,单个微控制器的这种划分并不是微不足道的,当我们考虑到我们将显著减少连接导线的数量时,例如,单管芯微控制器的内部互连性在导线数减少的情况下被充分扩展,我们看到了解决这个问题的需求。
在所公开的通信技术中,我们引入微控制器架构和到桥245的接口260以包括整个总线加上中断加上DMA结构,使得其减少导线的数量并用通过较小信号集进行通信的逻辑结构来代替它们。此外,其它管芯间行为(诸如PMU状态)以及调试器端口控制/数据可以跨这个接口被同步。这些接口由其它控件捕获,诸如经由接口257的CPU调试299和经由接口258的PMU控制器244。(注意的是,PMU控制器244、接口258、主桥245、管芯到管芯互连262、从桥264、接口280、安全性管理器267、接口282和PMU 268执行与PMU接口256相同的功能。还要注意的是,图2A中未示出调试安全性的显式对应部分。)这种逻辑结构导致最小化通信互连,同时维持期望的逻辑行为,就好像这些消除的导线存在一样,并且处于微控制器固件的完全控制之下。这使得微控制器系统能够使用多个管芯和/或包装来实现,同时保持互连信号计数低,而不要求对外设或CPU逻辑或行为进行重大改变。
在图3中,我们使用图1中描述的主要接口将单管芯微控制器划分为两个管芯,CPU管芯246和ASIC管芯271。为了了解如何减少连接导线的数量,同时维持单管芯微控制器的全部功能,我们重点关注以下接口:总线接口AHB 330、事件335(其可以包括IRQ 160和DRQ130)、PMU同步340和DAP 345。(注意的是,总线接口AHB 330可以传送接口135的子集,对于该子集,外设已被放置在ASIC管芯271上。因为块寻址已经以分布式方式被处置,所以ASIC管芯271上可以存在没有限制数量的外设。而且,事件335可以传送DRQ 130和IRQ 160的子集,对于该子集,外设已被放置在ASIC管芯271上,或者对于通用CPU管芯,传送用于可以被放置在ASIC管芯271上的外设的分配。此外,PMU同步340可以传送不由PMU控制器244处置的接口135的子集。通常,时钟门控和/或本地功率门控可以由PMU控制器244处置,而其它PMU功能可以涉及与ASIC管芯271的交互。此外,DAP 345可以传送端口接口140的子集,其可以通过接口280和调试访问端口来处置。)在一个实施例中,时钟源315(或时钟源115)可以位于ASIC管芯271上以提供时钟317(其可以是从时钟源115提供到时钟乘法器和多路复用器110的未编号的时钟,并且其还可以提供给桥264或桥365),其可以被扩展到CPU管芯时钟乘法器和多路复用器310(如下面所讨论的,其可以将附加同步信号从多路复用器310传达给桥350以处置时钟倍增,但在其它方面具有与时钟乘法器和多路复用器110类似的功能,并且在一些实施例中,可以是时钟乘法器和多路复用器110)。在一个实施例中,桥/串行解串器(serdes)350和桥/串行解串器365分别使用重新定时和I/O接口355和360通过管芯间逻辑互连262连接。桥/串行解串器350可以附接到CPU管芯接口330、335、340和345并且被提供有CPU管芯接口时钟325。桥/串行解串器365可以附接到ASIC管芯接口370、375、380和385并且被提供有ASIC管芯接口时钟317。(注意的是,ASIC管芯接口370、375和380传送与ASIC功能390相关的信令,而接口385与DAP 395通信。这些接口是接口330、335、340和345的对应物。)两个桥350和365通过互连262通信以将CPU管芯接口扩展并同步到它们对应的ASIC管芯接口。
一般而言,挑战在于开发具有两个或更多个管芯的微控制器,其中用户和/或程序员可以将其编程为(并将其视为)单管芯微控制器。此外,所公开的通信技术使用桥的概念,桥允许将IP集成到微控制器中,同时放置在第二管芯上,而不改变如果它们在同一管芯上时将使用的通常微控制器接口。换句话说,桥350及其对应物365为双方(软件/CPU和硬件外设)创建了它们彼此直接连接的外观。此外,ASIC管芯271上的硬件接口有意地相同,就好像它已经在与CPU相同的管芯上实现一样。
在一个实施例中,AHB总线330具有至少115个信号,包括:
HCLK(时钟)
HRESETn(总线复位)
HREADY(指示数据阶段没有停顿,因此命令阶段应当注册)
HADDR[31:0](32位地址总线)
HPROT[3:0](总线访问上下文信息)
HTRANS[1:0](传送类型)
HSIZE[1:0](传送尺寸)
HWRITE(传送方向)
HBURST[2:0](突发类型)
HMASTLOCK(锁定的序列指示)
HNONSEC(安全访问与非安全访问)
HWDATA[31:0](写入数据,主设备到从设备)
HRDATA[31:0](读取数据,从设备到主设备)
HREADYOUT(从设备指示它准备好完成数据阶段)
HRESP(从设备指示数据阶段是否应当带错误完成)
(注意的是,每个从设备具有HREADYOUT的实例。因此,接口237、238、239等中的每一个都具有自己的实例。总线逻辑可以将这些信号多路复用为HREADY广播信号。而且,每个从设备可以提供HRESP和HRDATA的自己的版本。因此,接口237、238、239等中的每一个可以提供此类输出。总线逻辑可以将这些信号多路复用为解复用的信号的单个集合,这些信号被提供给总线主设备,例如,当CPU是总线主设备时,在接口236上。)
另外,典型的控制器将具有多个外设IRQ通道。例如,ARM Cortex M4可以提供240个外设IRQ通道。DMA控制器通常可以有8-32个DRQ通道。为了允许中断从睡眠唤醒,实施方式需要附加的信号集合,每个集合的宽度与PMU接口中的IRQ集合相同。为了支持顺序进入和退出睡眠模式,需要更多信号。安全性策略同步和调试端口通常将要求进一步的信号。因此,对于由于成本和/或制造问题而无法使用甚至100根导线的实施方式,用专用导线直接连接管芯之间的这些信号是不可行的。注意的是,这些信号可以存在于各个管芯上的互连248和272上,但是可以通过管芯到管芯互连262经由消息递送来传递。
在一个实施例中,完整的实施方式(例如,通常没有总线停顿,对于IRQ/DRQ和PMU支持几乎没有时延)可以用42根导线来实现一个或多个功能。可替代地,另一个实施例(可能稍微慢一些)可以使用18根导线。注意的是,DDR版本可以进一步将其减少为具有类似性能的10导线实施方式。
允许16个中断且无DMA或PMU支持的系统的其它实施例可以用3根导线来实现。虽然这种方法会慢,但许多微控制器应用可以适应外设访问的时延。
图4图示了具有最少或精简的导线集合的双管芯系统之间的接口的实施例的选择细节。CPU管芯246包含CPU管芯桥350并且ASIC管芯271包含ASIC管芯桥365。这些桥与互连262连接,互连262具有信号NCLK 420、NDIO 421、NPHASE 422、NRESP 423和NEVT 424。与互连相结合的桥可以被用于以透明的方式同步位于两个管芯上的部件之间的各种事务、事件和服务。信号NDIO 421、NRESP 423和NEVT 424在一些实施方式中可以是多位信号,但在其它实施方式中也可以是单位实施方式。
互连262被划分为三个信号组。第一组包括信号NCLK 420,其可以充当用于其余信号上的数据传送的同步时钟。NLCK 420可以由来自ASIC管芯271上的时钟源315的时钟459提供,并且可以与时钟458对应,然后与CPU管芯246上的时钟乘法器401、时钟FCLK 402对应。第二组(即,事务互连460)可以具有NDIO 421、NRESP423和NPHASE 422,并且被用于实现由CPU管芯246发起、同时由ASIC管芯271接收和/或响应的事务。这个互连的示例用途是用于将CPU管芯246上的存储器映射的总线事务330中继到ASIC管芯271上的重新主控的事务370,诸如在通过AHB接口437连接的AHB主设备405与AHB从设备之间。CPU出于其它目的可能需要发起的其它事务也在事务互连460上进行。第三组包括事件中继互连NEVT 424并且主要用于将事件消息375从ASIC管芯271传播到CPU管芯246上的事件335。其它服务可以利用事务互连460和NEVT信号组两者,诸如将CPU管芯246PMU状态和事件340与ASIC管芯271PMU状态和事件380同步,或者将CPU管芯调试接口配置和事件345与ASIC管芯调试接口配置和事件385同步。
虽然这个示例在CPU管芯246和ASIC管芯271上使用AHB格式总线,但是其它格式总线也可以用于桥350和桥365的总线接口。此外,所有或一些总线接口也有可能是彼此不同的格式。
管芯到管芯桥允许以对最终用户很大程度上透明的方式实现多管芯控制器。在这个上下文中,透明度应当被理解为特征透明度,而不是情境或系统时延。通过在两个管芯之间桥接多个标准微控制器接口,外设可以被实现为在很大程度上不知道它们是在两个管芯中的哪一个中实现的。这个系统以主/从关系桥接两个管芯。CPU管芯246预期包含至少一个微控制器核心(CPU)及其紧密耦合的存储器。它还可以包含一个或多个DMA控制器212。
CPU管芯246不需要与引线框架(或另一种类型的风格的包装)有任何直接连接。ASIC管芯271可以是CPU管芯246到外界的网关,并且可以包含存储器映射的外设以实现以对CPU透明的方式完成未在CPU管芯246上实现的产品特征所需的任何接口和逻辑。此外,在许多情况下,CPU管芯246不需要具有任何电力管理模拟内容,使得PMU电路系统和相关联的逻辑中的全部或一些可以在ASIC管芯271上实现。CPU管芯仍然应当像它是单管芯系统那样控制PMU内容,从而导致需要分布式PMU系统。
在管芯之间桥接的接口可以包括AHB总线、中断、DMA请求以及PMU请求和确认。此外,逻辑桥可以至少包括:AHB、IRQ、DMA、PMU和安全性。这些逻辑桥通过管芯间互连进行事务处理,其包括事务互连460和事件中继互连NEVT 424。事务互连460可以被用于将AHB事务330桥接到重新主控的AHB事务370,同时还提供非AHB控制命令,例如,将PMU状态340同步到PMU状态380。CPU管芯246能够处置用于多个AHB主设备405和406的AHB事务330以被重新主控为ASIC管芯271上的ASIC管芯AHB事务370,但是许多实施方式可能仅实现对单个AHB主设备405的服务。ASIC管芯271可以将AHB事务370重新主控到多个AHB主接口437和436上,但是许多实施方式可以仅实现一个主接口。
事务互连460为各种服务提供同步,诸如:AHB总线事务、PMU状态改变、DMA和IRQ重新轮询和/或安全性。这是通过实现包括PHY 415和PHY 426的物理层事务桥来实现的,PHY415和PHY 426通过I/O 355和I/O 360由事务互连460连接。这允许CPU管芯246接口之间的事务交换以与其AISC管芯271接口同步。例如,呈现给AHB从接口405和406的事务可以被重新主控为AHB主接口437和436上的适当的类似事务。类似地,呈现给PMU事务接口404的PMU操作可以被重新主控为PMU事务接口438上的等效事务。DRQ同步逻辑414可以类似地使用接口448来实现事务,以通过接口465与DRQ同步逻辑428通信。IRQ同步逻辑451可以使用接口449来实现到使用接口474的IRQ同步逻辑431的事务。由PHY 415编码和排序的事务互连460上的信令提供由PHY 426解码的信息以使其能够将事务路由到相关接口。在一个实施例中,这个信息被编码为命令阶段传送的一部分。事件中继互连NEVT 424可以被用于将枚举的ASIC管芯事件375传递到CPU管芯事件335。用途可以包括转发中断和DMA请求断言。PMU同步的另一个用途是传播PMU状态改变和事件或从ASIC管芯271强制CPU管芯246复位。
中断请求同步负责将ASIC管芯IRQ接口433上检测到的中断请求同步到CPU管芯IRQ接口475上的对应中断请求。对于使用基于事件的中断类型的中断,可以仅使用事件中继互连424通过将检测到的IRQ激活变换成枚举事件来完成这个同步。对于使用基于电平的中断类型的中断,这种同步可以要求访问事务互连460。如果中断控制器在IRQ互连475上提供配置信息或者作为配置SFR组417中的编程提供配置信息,那么每个中断线可以为每个中断提供正确的行为。
DMA请求同步负责将ASIC管芯DMA接口434上的ASIC管芯271的DMA请求映射到CPU管芯246的DMA接口407中的对应请求。因为DMA请求是基于电平的,所以一对状态机进行协调以确保CPU管芯246DMA请求线电平的知识适当地满足DMA控制器212的需要。它必须能够访问事务和事件通信链路来实现这个功能。
在一些实施例中,将可选的重定时逻辑添加到I/O 355和/或I/O360中可以是有利的,诸如用以处置时钟偏斜或时钟频率差异。
协议可以用多种互连宽度来实现;一种实现大量互连并且更适合倒装凸块(flip-bump)组件作为管芯到管芯通信的(一种或多种)机制,其它接口利用引脚的子集来减少实施方式的互连数量,诸如以实现更小的球栅阵列或用于键合线互连情况。示例性较大引脚列表包括:NCLK 420是用于事务互连460和事件中继互连424的单个信号和主接口时钟。它还可以被用作用于CPU管芯426内部逻辑或时钟发生器和接口信号的定时源。事务互连460可以包括:NPHASE 422、NDIO 421和NRESP 423。NPHASE 422例如是单个位并且可以提供NDIO 421命令/数据阶段控制。NDIO 421例如是32位并且是命令/数据内容。NRESP 423例如是3位并且可以提供来自从设备的事务响应以及流量控制。ASIC到CPU事件中继互连包括:NEVT 424。这个接口可以具有合适的宽度以在一个或多个传送周期中对期望数量的枚举事件进行编码。
这些信号可以通过接口时钟NCLK 420进行同步。在一个实施例中,时钟可以从ASIC管芯271提供给CPU管芯246,在其它实施例中,时钟可以由CPU管芯246提供给ASIC管芯271,或者两个管芯都可以由另一个源提供。在一个实施例中,接口时钟可以与CPU管芯246时钟FCLK 402(其是那个管芯的总线时钟的源,例如HCLK)同步,诸如通过具有相同频率时钟或通过使FCLK 402是NCLK 420的倍数。类似地,ASIC管芯271逻辑可以与NCLK 420同步。
通过使用用于那些互连信号的双数据速率(DDR)信令,诸如通过在NCLK的两个边沿上传送NDIO 421数据,有可能减少全部或部分互连的导线数。其它接口(诸如NRESP 423和NEVT 424)也可以使用DDR来减少互连计数。
如果CPU管芯246FCLK 402是NCLK 420的倍数,那么可以在CPU管芯246上使用时钟乘法器401以从NCLK 420生成FCLK 402。为了协调管芯间互连的定时,时钟乘法器401可以向CPU管芯桥350提供信号,该信号指示在FCLK 402的逐周期基础上NCLK 420和FCLK 402的相位关系。在一种实施方式中,时钟乘法器401可以提供与FCLK 402同步的逻辑信号RE_STRB 416,该信号指示下一个FCLK 402边沿也是NCLK 420的边沿。然后,定序器/PHY 415逻辑可以使用这个信号来协调在NCLK 420边沿上发生的到互连逻辑的更新/来自互连逻辑的更新,同时向CPU管芯246的非PHY部件发信号通知可以提供FCLK 402速率的行为。
事务互连460上的事务被实现为命令阶段和数据阶段(不具有数据阶段的命令跳过数据阶段)。NDIO 421通信接口由有状态双向驱动器组成,以允许减少导线。在命令阶段期间,方向是CPU管芯246到ASIC管芯271。命令阶段内容被编码为向PHY 426指示是否要求数据阶段,以及如果要求,那么数据方向应当是什么。命令指示期望哪种事务以及那个事务的相关细节,诸如AHB地址阶段信息或关于要实现的期望非AHB事务的信息。对于实现AHB总线事务的事务,这包括地址、读/写、要传送的字节数、传输的访问特权等。其它事务可以使用带有枚举字段的命令阶段编码来指示传送类型以及命令数据的其余部分根据该枚举的命令类型进行解码。数据阶段包含事务的有效负载(对于命令阶段内容指示应当执行数据阶段的命令)。
这些事务互连460事务可以用双向NDIO 421信号和ASIC到CPU NRESP 423信号来实现。NDIO 421传播命令和数据阶段内容,而NRESP 423主要提供数据阶段响应(诸如OK、ERROR)以及数据阶段流控制,但在命令阶段期间可以可选地用于提供从ASIC到CPU的其它信息。为了促进突发事务和同步,可以使用附加信号CPU到ASIC信号NPHASE 422。
可以调整分配给总线事务的互连的数量,以在成本与时延之间进行权衡。通过NDIO 421的命令和数据阶段传送的(示例性)未加工宽度是32位。在实现没有任何明显的(对于CPU)时延的32位AHB(或其它流水线)接口的一个实施例中,NDIO 421可以是32位宽。实现低时延是因为流水线CPU总线在为先前发出的命令阶段退出数据阶段的同时,为“下一个”数据阶段发出命令阶段事务。因此,用于外设访问的命令阶段和数据阶段发生在不同的总线时钟周期上,因此NDIO互连可以被用于一个NCLK周期上的命令运输和后续周期上的相关数据运输。由于编译代码的正常行为,CPU几乎不可能在两个连续周期上访问非存储器地址(因为CPU需要计算下一个访问地址)。在一个实施例中,在命令阶段期间,CPU管芯246可以在NDIO互连421上提供多达32位的命令阶段内容以指示ASIC管芯271。如果命令指示数据阶段,那么ASIC和CPU都调整后续数据阶段的数据方向,并且使用32个NDIO 421信号作为数据阶段来传送(多达32位)数据。
在一个实施例中,为了实现AHB总线操作,命令阶段内容可以被分配为:一位用于读/写数据方向;两位用于数据传送尺寸(8、16、32或特殊位数);20位访问地址(1MB)。这可以被视为与某些相互理解的ASIC管芯基地址的地址偏移量;和/或关于传送的多达9位附加信息。
为了扩展可用命令或地址空间,编码到第一命令总线周期中的信息可以指示需要第二总线周期。在这个实施例中,可以传输组合的64位扩展命令内容。例如,上例中的附加保留位之一可以被用于指示距基地址偏移超过1MB的地址。地址的20个LSB可能像往常一样在第一命令周期上传送,并且第二总线周期被用于传送其余的MSB。桥的CPU侧可以检查CPU的总线地址偏移量,并且如果可以用20位表达,那么可以发出更高效的单周期命令。否则,它可以指示需要第二周期并提供其余信息。通过ASIC管芯271中的地址空间的布置以将最常用的地址定位在较低的1MB中,大多数访问将能够使用较短的命令版本。类似地,可用于附加传送信息的位不足以对用于各种AHB地址阶段信号的一些可能性进行编码。通过对这些位进行编码,使得编码之一指示需要添加附加的命令阶段周期以提供附加的命令内容,其它单周期编码可以被用于表达这些AHB信号的最常用值,以便很少会要求第二命令阶段传送。
指示扩展和/或替代命令的另一种方法是利用正常命令信号中的一个或多个的未编码的值以指示替代命令格式。例如,在上面的示例中,有两个位用于表达传送尺寸的三种可能性。使用这个两位编码的第四个(否则非法)值可以发信号通知整个命令编码应当以替代方式被处理。这可以被用于提供关于总线传送的更多或不同的信息,而且还用于参与由CPU管芯246发起的、未从总线操作(CTRL命令)映射的事务。例如:PMU状态改变指示可以从CPU发信号通知给ASIC。这些CTRL事务可以具有编码,以便对于编码的某个子集,数据阶段被跳过。这可以允许频繁但简单的CTRL事务仅使用命令总线周期,从而减少在总线上花费的时间。其它CTRL编码可以指示数据阶段并执行数据传送以传送与该事务相关的数据。
命令阶段可以提供关于传送的特殊安全性或定序信息。某些总线事务只能被授权用于以某些执行特权和/或CPU管芯上的某些授权总线主设备运行的代码(例如,只能由CPU1实现,使得CPU2和DMA控制器212不被授权)。对于需要这些特殊授权的总线事务,桥的CPU侧可以观察CPU管芯246AHB从接口405上存在的这些条件,并利用扩展命令周期来传送这个附加事务信息以传播到ASIC管芯AHB主接口437。
一旦执行了命令阶段(并且如果命令编码指示数据阶段),就可以使用NDIO 421信号来传送数据。如果数据方向是ASIC到CPU(读取),那么两个管芯都在命令阶段完成之后改变NDIO 421上的数据方向。然后,数据传送可以使用一个或多个周期来传送相关联的数据。为了实现典型的32位单总线传送,32位NDIO 421总线可以在一个数据阶段周期内完成这个操作。为了传送更多数据,可以使用变体命令来指示更大尺寸的数据。然后,两个管芯将使用足够的总线周期来传送所指示数量的数据。这可以被用于具有大有效载荷的CTRL传送、总线突发传送以及用于大于32位字尺寸的传送(例如,64位原子传送)。
为了进一步减小互连宽度,可以将命令和数据阶段传送序列化为较小NDIO 421互连宽度的多次传送,以总线周期来换取互连计数。例如,8位NDIO 421可以被用于在4个周期内传送32位命令和在4个周期内传送32位数据。由于传送涉及多个NDIO 421周期,因此CPU必须等待序列化和/或NDIO 421数据速率必须高于CPU总线速率。双方可以使用相同(或相似)的命令和数据格式,从而允许具有不同互连计数的实施方式具有彼此相同的所提供的特征。除了事务上的附加时延之外,除了PHY 415和426、I/O 355和360NDIO互连421之外,任一管芯上的东西都不需要更改。
关于序列化的改进是利用编码到命令阶段中的数据尺寸信息来指示小于32位的传送尺寸。例如,如果指示8位或16位传送,那么对于8位NDIO 421互连宽度,数据阶段周期的数量可以分别是1或2。
在命令阶段中可以进行类似的改进。通过创建命令的不同长度变体,桥可以选择对期望事务进行编码的最短长度编码。例如,可以使用16位、24位和32位的命令。32位变体可能以类似于使用32个互连的方式对命令进行编码,而较短的变体只能对子集进行编码。然后可以将该命令序列化为传送那个命令宽度所需的周期数。例如,使用8位NDIO 421互连宽度,可以使用两个周期来传送16位命令。
为了向ASIC管芯271指示命令宽度,有可能在第一命令周期中投入一定数量的位来指示命令宽度。对于16/24/32宽度变体,这将在三种变体中使用用于这个信息的第一传送阶段的2个位,剩下14/22/30位的有用位用于命令内容。替代配置可以在第二周期中使用专用位来指示对第三周期的需要,并且在第三周期中使用类似的位来指示对第四周期的需要。这将允许15/22/30位的有用命令内容。第三配置可以使用专用信号CPU至ASIC信号NPHASE 422来指示连续命令阶段,使得不需要使用通常的NDIO 421信号来传送命令长度。在每个命令阶段周期结束时,ASIC管芯PHY 426可以检查NPHASE 422以确定是否需要进一步的命令阶段序列化。在NPHASE 422指示命令阶段不继续的第一命令阶段周期,ASIC管芯271可以知道命令宽度并移至数据阶段(假定命令指示数据阶段)。
NRESP 423是ASIC到CPU响应信令路径,其与NDIO 421命令/数据阶段同步。用于NRESP 423的典型宽度可以是3位。在序列化版本中,这可以减少到2(诸如当使用16条、8条NDIO导线时)或1(诸如当使用4条或更少NDIO导线时)。在数据阶段期间,NRESP 423被用于从ASIC向CPU提供指示,以提供总线数据以外的信息。例如,对于指示总线错误的ASIC外设,可以在与将数据传送时相同的总线周期上提供ERR响应。为了指示事务成功,可以在与数据相同的周期内提供OK响应。对于要求更多时间才能传送数据的从设备,可以提供STL响应,其然后将数据阶段延迟到下一个周期。还可以对应当作为数据阶段的一部分从ASIC递送到CPU的其它相关信息进行编码。
NRESP的3位(单周期)编码示例在下面表1中示出。
/>
表1
在命令阶段期间,NRESP 423可以被用于其它目的。由于桥的两侧都知道命令/数据阶段,因此可以使用相同的位模式在命令和数据阶段期间对不同的概念进行编码。用于此的一些用途可能是指示已发出非法命令、命令停顿(ASIC未准备好接收新命令)以及类似事件的指示,诸如特定种类的数据或操作已准备好。
对于NDIO 421信令被序列化为多个周期的情况,也可以序列化NRESP 423信令。例如,两个位可能被用于具有8个互连的NDIO 421。它们可能如下面表2中所示的那样被编码。
表2
在这个编码中,一个特殊响应STL只能在第一数据周期上用作特殊代码,以在下一个总线周期上重启数据,因为ASIC尚未准备好传送数据。其它两个响应完全指示了那个周期的响应代码。第四代码被用于指示需要附加的周期来消除各种其它响应可能性之间的歧义。然后,第二总线周期必须被用于数据阶段以递送这个响应(即使当数据阶段可能已在第一周期上完成时,诸如8位NDIO上的8位传送)。通过使用较长的序列化仅对罕见的响应进行编码,可以在很大程度上避免附加的数据阶段时延,同时节省在第一总线周期中发信号通知可能响应所需的互连。
在期望极低成本实施方式的情况下,还有可能以少至两条导线来实现事务互连NDIO 421和NRESP 423。在一种实施方式中,NDIO 421可以具有空闲状态,使得序列化的NDIO 421命令的开始可以由开始位指示。在传输该开始位之后,NDIO 421命令的其余部分可以序列化。在一种实施方式中,要序列化的命令位的数量可以是固定数量,使得ASIC管芯271可以通过对开始位之后接收到的命令位的数量进行计数来确定命令阶段的结束。改进可以使用可变长度命令阶段,其中命令阶段的较早位中的编码可以指示命令位的总数及其含义。在命令阶段之后,数据阶段可以使用每位一个时钟周期进行序列化。然后,数据阶段可以通过在由那个命令指示的数据方向上序列化由命令阶段命令指示的位数来继续。NRESP 423也可以通过单根导线被序列化。在命令阶段之后,读取事务数据阶段开始时的NRESP 423位可以指示是否停顿,诸如通过指示NRESP 423上的高电平为停顿。如果不要求停顿,那么NRESP 423的第一数据阶段周期可以指示非停顿电平并且数据阶段可以在那个周期开始序列化。如果要求停顿,那么ASIC管芯271通过以停顿电平驱动NRESP 423来停顿数据变得可用所需的周期数。然后可以通过驱动非停顿电平来去除停顿,从而可以开始数据序列化。在数据序列化期间,NRESP 423的各种不同编码可以通过后续位的不同序列来序列化。对于写事务,停顿机制可以代替地以类似的方式延长最后一个数据阶段序列化周期。
使用类似的机制,不少于二的任何数量的导线可以被用于事务互连,同时保留桥接特征,以便在桥接时延与互连计数之间进行权衡。
可以通过添加突发支持来改进事务互连桥接。包括AHB的许多总线协议提供对突发传送的支持,其中一系列相关地址按顺序进行事务处理。这常常由高速缓存控制器和DMA控制器212使用。在极少数情况下,CPU本身也有可能在连续时钟周期上针对顺序地址发起事务,无论是作为显式突发还是仅按照与突发相同的顺序。此外,一些总线从设备可以实现FIFO地址,每次对同一存储器地址的访问都由从设备转换成分别用于写入/读取访问的FIFO入队/出队。对于这种从设备,当期望将突发中的多个FIFO项入队/出队时,通常会对同一地址进行多次顺序访问。当由DMA控制器212实现时,具有非递增地址的这个突发将是DMA通道配置的一部分。如果直接由软件完成,那么只有在事后通过观察CPU发出的总线事务序列才能看出这一点。在这些情况下,期望提供(一种或多种)机制来使用NDIO 421互连以仅响应于单个命令传送而执行多个相关数据传送。否则,在每次数据传送之后,必须使用NDIO互连为突发中的下一个事务提供命令阶段,从而将突发的NDIO 421传送速率降低一半。
为了实现突发传送,可以引入附加的CPU到ASIC互连信号NPHASE 422。这个信号向从设备指示下一个互连时钟周期是否预计为数据阶段。ASIC管芯271接收这个信号,并且当在数据阶段期间被断言时,它理解下一个互连总线周期应当是当前数据阶段的突发延续。然后,它可以在其总线主接口436或437上发出新的命令阶段以继续突发,而无需NDIO 421上的附加命令阶段指示。为了允许适当地处置停顿,对于NRESP 423是STL的数据阶段,无论NRESP是否被断言,CPU管芯桥350和ASIC管芯桥365都继续数据阶段。这是因为无论突发是否继续,数据阶段都必须延长到超过这个从设备停顿。NDIO 421上的命令阶段可以提供关于如何将总线事务从一个突发事务调整为其延续的信息。由于递增事务更为常见,因此默认命令格式可以默认为这种行为。注意的是,递增通常意味着将地址添加适当的量,以超出先前的地址每次传送的尺寸。因此,例如,如果使用HSIZE在AHB总线上指示16位传送,那么从前一个地址的增量将是把它加2,因为AHB使用字节寻址。可以提供命令变体来指示其它类型的更新行为,诸如针对FIFO地址的非递增事务,或类似高速缓存的操作的包装事务。
CPU管芯桥350还可以被配置为提供对多个AHB主设备的访问,诸如通过在CPU管芯桥350上提供多个AHB从端口。示例实施方式为CPU经由AHB接口405主控的总线提供总线从接口,并且为由DMA控制器经由AHB接口406主控的总线从接口提供另一个总线从接口。
为了对由CPU在AHB接口405上发出的事务和AHB接口406上的附加总线主设备以及与存储器映射的事务不相关的特殊总线事务(诸如PMU接口404和DMA接口407)之间的事务互连进行仲裁,可以提供仲裁器418。由于这些服务中的各种服务请求访问用于事务的事务互连,因此在发生争用的情况下,仲裁器可以使一个源优先于其他源。它可以通过严格的优先化、通过循环服务、通过保证最大时延调度、通过这些技术的组合或通过其它合适的方法来做到这一点。然后可以允许所选择的服务使用接口457访问PHY 415。在一些实施方式中,CPU可以通过在其配置SFR(寄存器)组417中提供特殊功能寄存器来影响仲裁方法。当多个服务请求访问时,可以向被仲裁器418暂时拒绝访问的服务提供停顿指示以延迟所请求的服务的事务,直到提供服务为止。
对于CPU管芯桥350被配置为充当多个总线(诸如405和406)上的从设备的实施方式,ASIC管芯271上的慢外设可以有可能会不必要地停顿ASIC管芯271上的AHB总线437上的事务的完成。这将造成这样的情况:NRESP 423将指示STL多个周期,占用事务互连而不会在数据传送方面取得任何进展。为了改进此类情况下的性能,ASIC桥365可以实现附加总线主端口436来主控第二ASIC管芯AHB总线。如果AHB总线主设备437上的事务需要多个周期来完成,那么可以在那个事务的NDIO 421数据阶段期间指示SPLIT的NRESP 423指示。这个指示使得CPU管芯桥350结束互连总线事务而不解决它。ASIC管芯桥365继续在其AHB总线主接口上主控这个暂停的操作,使得操作可以在AHB总线437上继续,每当总线从设备完成事务时,就将AHB事务结果存储在其存储器中。同时,仲裁器418能够针对不相关的事务发出另一个NDIO 421命令阶段。如果这种事务发生并且这个事务以AHB总线从设备为目标,那么这个事务可以由ASIC管芯桥365作为总线操作通过其替代总线主接口436来发出。在某个合适的点,仲裁器418可以发出NDIO 421命令变体JOIN以重新开始先前暂停的事务的数据阶段。如果此时总线主设备437上的事务已成功完成,那么从存储在桥的存储器中的结果递送数据阶段响应。如果总线主设备437上的事务仍然未决,那么数据阶段类似于SPLIT从未发生时那样重新开始。
使用事务互连的事务为CPU管芯246提供了足够的机制来发起与ASIC管芯271的相关联的交互。在某些情况下,ASIC管芯271可以发起其自己的交互。由于这个原因,使用使用NEVT互连424的事件中继。NEVT 424由ASIC管芯271驱动,其可以用于将消息传输到CPU管芯246。这些消息通常采用从枚举的预定义集合中进行选择的形式。典型的消息可以指示ASIC管芯271上的中断活动、ASIC管芯271上的DMA请求活动、ASIC管芯271上的PMU状态改变等。对于ASIC管芯271应当进一步提供非枚举数据作为交互的一部分的情况,通过事务互连与事件的接收者的协调可以调度有效载荷递送。可替代地,有可能提供枚举的前导码,后跟通过NEVT 424传送的多个周期的任意数据。
由于潜在枚举事件的数量相对大,因此NEVT 424信令可以被实现为序列化的消息,以便保持NEVT 424互连的数量小。在示例实施方式中,NEVT 424可以用例如5根导线来实现,并且事件消息使用两个连续的传送时钟周期来序列化。例外是特殊编码(例如,全零),它是单周期伪事件IDLE,指示没有事件。在这个编码下,NEVT 424传送的第一个周期有31个可能的值,第二个周期有32个可能的值,总共有992个可能的事件。具有不同数量的导线和不同序列化长度的其它实施方式可以被用于优化导线数量、序列化的时延与可能事件数量之间的权衡。还有可能使用可变长度事件编码,以便可以用较短的序列化长度来指示更常用的事件和/或期望较低时延的事件,同时仍然允许较长的序列化长度以增加可能事件的数量,这会带来更长序列化的惩罚。另一种实施方式仅使用具有起始位和N位序列的一根导线来传送多达2
在一个实施例中,事件传送可以可选地被序列化以增加可能事件的数量。在一种实施方式中,5根导线可以通过使用其中一根导线作为第一/第二传送阶段指示并且使用另外4根导线作为数据的第一和第二半字节(nibble)来提供256个事件。在另一个实施例中,仅使用一根导线,用起始位和N位序列来传送多达2
在事件时延/带宽可以不如较低互连数量重要的情况下,有可能使用单个互连集合来执行NRESP 423和NEVT 424功能。这可以通过使共享NEVT 424/NRESP 423互连的目的成为事务互连460的事务状态的函数来完成。在要求NRESP 423指示来形成数据阶段响应时期间,两个桥可以使用共享的NEVT 424/NRESP 423互连来进行NRESP 423通信。如果发生这种情况时正在序列化NEVT 424事件,那么两个桥都可以理解在NRESP 423通信期间暂停NEVT 424序列化。一旦NRESP 423内容被传送,两个桥就可以重新开始使用共享互连以用于NEVT 424目的,并从与暂停发生时相同的位置继续序列化。
使用事务互连460和NEVT互连424的组合将IRQ指示从ASIC管芯271传播到CPU管芯246。ASIC IRQ上升沿(激活)由ASIC管芯271上的IRQ同步逻辑431检测,并且被转换成NEVT424互连电报、事件或消息以通知CPU管芯246。IRQ同步逻辑431可以通过在接口470上提供请求来请求这些NEVT通信。由于NEVT互连可能由于其它NEVT活动而不能立即用于传输这个电报,因此IRQ同步逻辑431可以实现用于该中断的寄存器以指示需要在后面的时间(诸如当NEVT仲裁器/多路复用器430授予这个访问权时)传输这个电报。使用指示信号447将这种电报的接收提供给CPU管芯246上的IRQ同步逻辑451。在接收到这种指示后,IRQ同步逻辑451可以在IRQ接口475上的其IRQ输出的适当索引上提供单时钟周期IRQ指示。这些IRQ输出可以被提供给CPU管芯246上的中断控制器,诸如包含在CPU 217中的NVIC。CPU管芯246中断控制器可以被配置为针对至其中断控制器的IRQ接口475信号,使用边沿检测或者电平检测。这允许CPU看到ASIC管芯IRQ接口433上的新事件,但是其本身不为被解除断言的IRQ接口433上的IRQ信号提供同步。如何处理解除断言取决于中断源是打算对其信号进行边沿检测还是电平检测。
如前所述,使用NEVT 424互连上的事件消息传递,从ASIC管芯271传播对基于边沿的ASIC管芯271源的中断服务请求。由于基于边沿的IRQ不会在解除断言边沿上传播任何信息,因此这是用于同步此类中断源的完整解决方案。
对基于电平的ASIC管芯271源的中断服务请求通过NEVT 424和事务互连460信令的组合从ASIC管芯271传播到CPU管芯246。类似于基于边沿的情况,ASIC管芯271上的中断服务请求的激活被传播到CPU管芯246。IRQ接口475上的IRQ指示将在单个周期内被断言,即使ASIC管芯IRQ接口433上的对应信号仍然可以被断言。这使得在中断控制器中设置用于这个中断线的PENDED寄存器。中断控制器不需要来自中断源的进一步信息,直到后面清除其PENDED寄存器,因为它不会对其自己的中断服务请求输入(如从IRQ接口475上的IRQ信号提供的)做出不同的反应。CPU管芯桥350因此可以为IRQ接口475上的该中断提供不活动信号,而不关心IRQ接口433上的信号中的ASIC管芯271中断服务请求是活动的还是不活动的。只有在PENDED寄存器被清除之后,中断控制器才重新检查其中断服务请求输入。当执行中断服务例程清除PENDED寄存器时,可以在一个时钟周期内断言中断控制器内该IRQ的PEND_CLR信号,并且可以在执行那个中断服务例程期间断言中断控制器内的ACTIVE信号。可以使用IRQ接口475上的IRQ钩子将这些信号从中断控制器提供给CPU管芯IRQ同步逻辑451。当是软件清除PENDED寄存器时,这会导致中断控制器内用于那个IRQ的PEND_CLR信号在一个时钟周期内被断言,而ACTIVE信号没有被断言。仅当未设置其PENDED寄存器并且ACTIVE信号也未断言时,中断控制器才会重新检查它的那个IRQ编号的中断服务请求输入。CPU管芯桥350的IRQ同步逻辑451因此可以诸如通过观察PEND_CLR的断言来注册PENDED信号的清除,并且等待ACTIVE信号不被断言作为需要在用于那个中断的IRQ接口433上重新轮询ASIC管芯271IRQ信号的指示,以重新确定ASIC管芯271上的中断源是否在断言其IRQ。IRQ同步可以通过在请求信号449上通过仲裁器418请求这个命令而使用事务互连460上的特殊命令来执行这个重新轮询操作。当ASIC管芯定序器/PHY 426接收到这个命令时,它可以通知IRQ排队/调度逻辑431重新检查IRQ接口433上的信号中的适当中断请求信号,并且如果被断言,那么调度通过NEVT 424互连指示这一点的电报。注意的是,这个电报可以具有与先前讨论的激活电报相同的编码,因为它在CPU管芯246上的处理可以是相同的。如果发生这种情况,那么将使用事件接收器412接收NEVT 424电报,将其提供给IRQ同步逻辑451,并且导致在IRQ接口475上的IRQ信号上的适当IRQ指示的单个时钟周期断言,从而使得中断在中断控制器中被重新挂起。如果此时没有断言中断,那么IRQ排队/调度逻辑431可以等待IRQ接口433上的IRQ信号中的中断信号的上升沿,以提供先前讨论的激活NEVT 424电报。
CPU管芯桥350可以被提供用于每个中断的信息,指示该中断是否旨在被视为边沿检测或电平检测。在一个实施例中,可以使用配置SFR组417来提供这个信息。在另一个实施例中,中断控制器可以提供这个信息作为其IRQ接口475上的中断钩子的一部分。CPU管芯桥350然后可以利用这个信息来选择用于同步每个中断源的IRQ状态的适当方法。
在一些CPU管芯实施方式中,可能无法访问中断控制器的内部信号PEND_CLR或ACTIVE。为了解决这种情况,可以通过特殊功能寄存器访问来提供基于电平的中断重新轮询的替代机制。可以在CPU管芯桥350的配置SRF组417中实现特殊功能寄存器,从而允许CPU直接请求针对IRQ的重新轮询。这可以通过从对配置SFR组417的适当访问向IRQ同步逻辑451提供重新轮询指示来实现,诸如检测配置SFR组417的适当地址中的写访问。然后,每当基于电平的中断需要重新轮询时,软件就可以通过向这个特殊功能寄存器写入适当的值来直接请求重新轮询。典型情况是在软件清除针对那个中断的PENDED位之后,或者在中断服务例程内的适当点处。
从ASIC 271管芯到CPU管芯246的DMA请求同步可以通过NEVT 424和事务互连460信令的组合来实现。ASIC管芯DRQ同步逻辑428和CPU管芯DRQ同步逻辑414通过这些互连进行通信,以将DRQ信号434上的DRQ指示的改变传播到CPU管芯DMA信号407上的对应改变,从而提供DMA使能的外设提供DRQ接口434上的DRQ信号通过接口407中的DRQ信号与DMA控制器212交互的能力。DRQ同步逻辑414和428可以以适合于作为DMA请求的信号意图的方式将接口434上的改变有状态地传播到接口407上的对应信号。
对于要同步到CPU管芯接口407的接口434中的每个DRQ信号,CPU管芯DRQ同步逻辑414可以具有状态UNKN、ARMD和TRIGD。ASIC管芯DRQ同步逻辑428可以具有状态UNKN、ARMD、PEND和TRIGD。注意的是,虽然这些状态中的一些具有相同的名称,但是状态编码不需要相同,并且将存在同步逻辑414和428在任何给定时间可能不处于相同命名状态的情况。
在启动时或每当相关联的DMA通道被禁用时,同步逻辑414和428都可以处于UNKN状态。当ASIC管芯DRQ同步逻辑428处于UNKN状态时,它预期CPU管芯对同步接口434中的相关联的DRQ信号不感兴趣。当CPU管芯DRQ同步逻辑处于UNKN状态时,它预期ASIC管芯不会通知它任何改变,并向接口407中相关联的DRQ信号提供不活动信号。每当CPU管芯同步逻辑414处于UNKN状态并且相关联的DRQ被启用用于服务时,同步逻辑414可以通过接口448和465经由事务互连460上的事务向ASIC管芯同步逻辑428指示这一点。在完成这个事务后,DRQ同步逻辑414和428都可以针对那个DRQ信号进入它们的ARMD状态。
在ARMD状态下,ASIC管芯同步逻辑428预期CPU管芯同步逻辑414也处于ARMD状态并且期望被通知在接口434中的相关联的DRQ信号上观察到的任何活动电平。当CPU管芯同步逻辑414处于ARMD状态时,其在接口407中的对应DRQ信号上提供不活动电平,同时预期ASIC管芯同步逻辑428也处于ARMD状态并将向其通知接口434中的对应DRQ信号的任何观察到的激活。
每当ASIC管芯同步逻辑428处于ARMD状态并且在接口434中的相关联的DRQ信号上检测到活动电平时,它就可以进入PEND状态。当处于这个状态时,ASIC管芯同步逻辑428可以尝试使用接口467经由NEVT仲裁器/多路复用器430在NEVT上调度DRQ激活电报。在完成这个电报后,ASIC管芯同步逻辑428和CPU管芯同步逻辑414都可以进入TRGD状态。ASIC管芯同步逻辑428可以检测接口467上的这个电报完成,而CPU管芯同步逻辑414可以检测接口454上来自NEVT接收器412的这个电报完成。
当处于TRGD状态时,CPU管芯同步逻辑414在接口407中的相关联的DRQ信号上提供活动电平,预期DMA控制器212可以通过采取适当的响应性动作来响应。当处于TRIGD状态时,ASIC管芯同步逻辑428预期CPU管芯同步逻辑414也处于TRIGD状态并且期望被通知接口434中的相关联的DRQ信号的任何停用。
DMA控制器可以要求对已发起其响应性总线事务的DMA请求线进行周期准确的更新。如果要从DMA从设备读取可变长度数据,那么这可以被用于在数据被递送之后终止传送。在其它情况下,这可以是因为DMA控制器正在响应于先前的DMA请求来完成所需的传送,并且从从设备的DMA请求解除断言相对于最后总线数据阶段的处理的传播延迟会导致错误地重新触发从设备实际未请求的DMA操作。对于每个DMA响应性AHB总线事务,因此期望接口407中的CPU管芯同步的DRQ信号以与CPU管芯AHB接口405或406上同步的响应信号相同的时延到达。以这种方式,DMA控制器212完成其数据阶段的CPU管芯周期上的组合接口405/406/407中的相关信号与用于ASIC管芯周期的接口437/436/434中的对应信号相同,其中对应AHB事务数据阶段的数据阶段针对ASIC管芯DMA使能的外设完成。为了允许DRQ解除断言与AHB数据阶段递送在周期上同步,在事务互连460上的事务期间,NRESP 423可以被用于指示解除断言作为数据阶段响应的一部分。DMA控制器212可以使用DMA钩子407来提供AHB接口405或406上的特定事务在其AHB地址阶段期间响应哪个DMA请求的指示,诸如通过提供二进制编码的DRQ号作为地址阶段的一部分。同步事务互连460上的相关联的AHB事务的NDIO421命令可以包括这个DRQ编号信息作为命令编码的一部分。这个信息可以经由接口465提供给ASIC管芯DRQ同步逻辑428,使得它可以在接口434中选择适当的DRQ信号以用于在接口437或436上的AHB事务数据阶段期间进行监视,从而使用接口465向PHY426提供指示。ASIC桥365的PHY 426然后可以为成功的数据阶段提供NRESP 423编码的两种变体,OK和OKDN。OK指示数据阶段成功完成并且相关联的命令阶段期间指示的DMA请求当前是活动的。OKDN指示数据阶段成功完成并且在相关联的命令阶段期间指示的DMA请求当前是不活动的。CPU管芯桥350的PHY 415可以在事务互连360数据阶段完成期间检测NRESP 423上的OKDN编码并使用接口455将这个信息提供给DRQ同步逻辑414,例如通过为每个DRQ源434提供一个信号,该信号指示标记为响应于那个DRQ的事务已指示OKDN NRESP。CPU管芯DRQ同步逻辑414可以通过在接口407中解除相关联的DRQ的断言并将它的用于那个DRQ的内部状态改变为ARMD来对这个OKDN接收做出反应。类似地,每当OKDN作为NRESP 423上的响应阶段被递送时,ASIC管芯DRQ同步逻辑就可以针对相关联的DRQ将其内部状态从TRGD改变为ARMD。
响应性AHB事务之外的ASIC管芯271DRQ指示停用的同步不要求这样的同步时延。ASIC管芯同步逻辑428可以检测接口434中具有TRGD状态的DRQ信号的停用,其与事务互连460上的任何当前正在进行的事务无关,并且可以尝试使用接口467经由NEVT仲裁器/多路复用器430在NEVT上调度DRQ停用电报。在完成这个电报时,ASIC管芯同步逻辑428和CPU管芯同步逻辑414都可以进入ARMD状态。ASIC管芯同步逻辑428可以检测接口467上的这个电报完成,而CPU管芯同步逻辑414可以检测接口454上来自NEVT接收器412的这个电报完成。
每当CPU管芯同步逻辑414对于DRQ不处于UNKN状态并且相关联的DRQ对于服务被禁用时,同步逻辑414可以通过接口448和465经由事务互连460上的事务向ASIC管芯同步逻辑428指示这一点。在完成这个事务后,DRQ同步逻辑414和428都可以进入其针对那个DRQ信号的UNKN状态,并且接口407中的相关联的DRQ可以被解除断言。
使用这些机制和电路技术,CPU管芯桥350和ASIC管芯桥365可以提供CPU管芯246(具有DRQ同步逻辑414)与ASIC管芯271(具有DRQ同步428)之间的DRQ同步,同步ASIC管芯DRQ信号434与CPU管芯DRQ信号407,使得CPU管芯246上的DMA控制器212可以响应于CPU管芯271上的DMA使能的外设,如DRQ信号434所指示的。这些状态机中的每一个可以跟踪每个同步的DRQ信号434的内部状态以辅助这种同步。
可以使用事务互连460和NEVT 424管芯间互连在两个管芯之间同步PMU状态转变和同步。值得注意的是,PMU接口432上的PMU事件信号可以由事件发送器429传送,该信号由事件接收器412接收并且作为PMU事件信号在PMU接口411上提供。PMU接口432上的这些PMU事件信号可以源自ASIC管芯PMU 268,并且PMU接口411信号然后可以被提供给CPU管芯PMU控制器244,从而允许ASIC管芯PMU 268向CPU管芯PMU控制器244提供更新。可以为此类更新保留任何数量的枚举事件,以便每个事件消息可以提供不同的信息。典型的此类事件包括复位传播、掉电警告、调节器就绪指示和时钟速度改变通知。为了允许较大数量的可扩展事件,还可以为要求事务互连上的后续事务消除歧义的事件保留枚举之一,以便不要求低时延的事件可以使用这个公共事件编码并且由此不消耗枚举的NEVT编码之一。
类似地,CPU管芯PMU控制器244可以通过事务互连460上的事务来与ASIC管芯PMU268通信,使用PMU事务接口404发起此类事务。仲裁器/多路复用器418然后可以调度这个事务的时间以由CPU管芯PHY 415提供服务。然后ASIC管芯PHY 426可以解码该事务并在PMU事务钩子接口438上提供指示,该指示然后可以被提供给ASIC管芯PMU 268。在一些情况下,这个事务可以被视为CPU管芯到ASIC管芯枚举事件,使得仅需要编码该枚举事件的命令阶段在互连460上进行事务处理。在这种情况下,解码的命令阶段检测可以被提供作为PMU事务接口438上的信息,并且PHY 415和PHY426都将跳过互连460数据阶段。其它PMU命令编码可以暗示数据阶段,使得附加数据可以使用接口404和438在PMU控制器244和PMU 268之间传送。
在许多情况下,ASIC管芯271可以包含向CPU管芯246、也在ASIC管芯271上的其它部件或者外部端口提供电力供应的电路。在这些情况下,涉及睡眠和唤醒的大部分PMU逻辑(包括WIC)也可以位于ASIC管芯271上。在大多数微控制器架构中,睡眠是由CPU发起的。
在睡眠序列期间,CPU在其PMU接口256上提供其睡眠意图的信令。在单管芯实施方式200上,该接口256可以直接与PMU 205通信。对于多管芯实现,CPU管芯PMU控制器逻辑246可以拦截这个信令。然后它可以参与事务互连460上的多个事务以与ASIC管芯PMU 268交互以执行睡眠。对于实现WIC的CPU,CPU可以使用其PMU接口256将其NVIC状态的相关部分转移到WIC状态,从而提供镜像NVIC中的类似中断掩蔽功能的中断/异常检测逻辑的配置。CPU管芯246PMU控制器244可以代替地接收这个信令并使用事务互连460将其变换成一个或多个事务,以代替地将状态转移到ASIC管芯PMU 268中实现的WIC。这可以允许PMU在睡眠期间禁用NCLK 420、CPU管芯246的电力供应或其它服务,同时仍然提供WIC控制器的标准唤醒机制。这个PMU同步逻辑可以使用事务互连460和NEVT 424上的其它通信来执行适当的管芯间排序,从而以标准方式通过CPU PMU接口256实现CPU 217与PMU 268之间的多步握手睡眠序列。在唤醒时,类似的事务互连460和NEVT 424事务可以通过CPU PMU接口256执行CPI 217与PMU 268之间的必要序列。如果唤醒是由ASIC管芯271上的WIC发起的,那么状态转移回到NVIC可以作为这个序列的一部分来完成,诸如通过事务互连460事务从ASIC管芯WIC读取这个状态作为该唤醒序列的一部分。可替代地,可以在唤醒序列期间或之后的合适时间使用NEVT 424上的枚举事件来实现唤醒时的这个WIC状态转移的全部或一些。例如,可以通过使用ASIC管芯IRQ同步逻辑431发送相同的NEVT 424枚举消息来警告CPU管芯NVIC哪一个中断或异常引起了唤醒,就像在睡眠状态之外发生该相同的中断或异常的情况一样。通过在相对于唤醒序列的适当时间传送这个事件,CPU管芯246上的逻辑可以确保这个中断或事件在CPU 217开始执行之前在CPU管芯NVIC中待决。
睡眠的另一方面是互连接口的正确管理,使得事务互连460和NEVT互连424都处于空闲状态,使得当睡眠发生时那些接口上的通信都没有仅部分序列化,可能导致格式错误的事务。如果发生这种情况,一个管芯可以理解数据传送已经完成或者事件或握手已经被传送,而另一个管芯则具有不同的理解。为了解决这个问题,可以在睡眠协商期间使用事务互连460上的事务在可能已经在进行中的任何NEVT 424序列化完成之后禁用进一步的新NEVT 424活动。这个命令可以作为睡眠序列的一部分由PMU控制器244在睡眠协商期间的适当时间自动发出,以保证当睡眠生效时NEVT 424消息已经被原子地递送并且进一步的NEVT424消息被暂停。可以通过在进入睡眠模式之前进行那个互连上的最后一个事务来避免事务互连460上的不完整事务—具有指示我们现在可以去睡眠的编码的“已完成事务”,这将完成睡眠协商序列。CPU管芯总线仲裁器/多路复用器418和ASIC管芯NEVT仲裁器/多路复用器430然后可以通过睡眠序列使任何请求的操作停顿,并且然后在随后的唤醒序列期间在合适的点处重新启用服务。
而且,ASIC管芯271可以包括配置寄存器组419。用于调试访问端口的安全性策略同步也可以使用事务互连和NEVT桥接进行同步。在一个实施例中,用于调试访问端口的通信接口可以位于ASIC管芯271上。附接的调试器可以根据经由安全性管理器267访问的策略与这个接口通信,安全性管理器267可以由CPU管芯246上的安全性管理器243设置。这个安全性策略可以包括是否允许附接的调试器访问与CPU管芯的通信、是否允许调试器直接访问ASIC管芯271上的资源、调试器是否可以发起功率状态转变(诸如在CPU管芯可能无法通电或计时的睡眠模式期间)、以及授权凭证(诸如用于授权某种类型的访问的质询/响应序列)。
在初始加电序列期间,可以通过使用由CPU管芯安全性管理器243发起的事务互连460上的事务,将安全性策略从CPU管芯安全性管理器243传送到位于ASIC管芯上的ASIC管芯安全性管理器267。为了避免在这个策略被传送之前调试端口上的未经授权的活动,ASIC管芯安全性管理器267可以禁止访问具有不明确安全策略的资源,直到相关策略被传送为止。可替代地,ASIC管芯安全性管理器267可以禁用调试器通信接口,直到提供策略为止。ASIC管芯安全性管理器267可以通过任何CPU管芯246睡眠周期维持该策略,使得其可以对调试器请求做出响应。对安全性策略的更新(诸如通过CPU 217软件调整安全性管理器243的配置)可以被传送到ASIC管芯以使用事务互连460事务来更新其策略。
一些调试器操作可以发起对期望CPU状态的改变,诸如强制电力状态和停止/取消停止CPU操作。ASIC管芯271上的调试端口可以使用NEVT 424消息来发起诸如这样的操作,这取决于一个或两个管芯上的安全性管理器的授权。
在制造和产品开发过程的某些阶段期间能够在没有任何连接的CPU芯片271的情况下将调试端口附接到ASIC芯片271可以是有用的。为了实现这一点,ASIC管芯安全性管理器267可以确定没有附接的CPU管芯246并且允许根据未附接零件安全性策略来访问全部或部分ASIC管芯271资源的默认策略。
它在分析故障或客户退回的零件时也可以是有用的,以使得在故障分析期间能够访问非安全资源。为了实现这一点,可以在ASIC管芯安全性管理器267中实现默认安全性策略,以解决安全性策略由于CPU管芯246的不当行为而失败的情况。
当CPU管芯安全性管理器243已启用生命周期管理时,可以实现产品生命周期进程。例如,零件的生命周期可以从正常操作模式改变为故障分析模式,以使得能够对产品退回进行调试。ASIC管芯安全性管理器267可以被实现为响应来自附接的调试器的生命周期状态改变指令。安全性管理器267和ASIC管芯271上的调试接口可以被实现为对这个通信做出响应,而不管由CPU管芯安全性管理器243提供的安全性策略如何。ASIC管芯安全性管理器267可以使用NEVT 424事件发起生命周期状态改变。这个事件可以被提供给CPU管芯安全性管理器243,该CPU管芯安全性管理器243然后可以参与总线事务以对调试器的凭证执行认证,诸如通过形成质询并验证响应。在成功认证后,CPU管芯安全性管理器243可以采取必要的步骤来执行生命周期改变,诸如通过擦除敏感的非易失性存储器并将生命周期状态进程写入存储这个状态的非易失性存储器。一旦完成,调试端口和安全性管理器243、267就可以使用与该新的生命周期状态一致的更新后的安全策略。
图5中示出了使用这种技术的总线事务的序列图示例。在这个示例中,示出了CPU管芯246上的信号、管芯间262信令以及ASIC管芯271上的信号。特别地,示出了从CPU管芯AHB 330地址阶段信号514和CPU管芯AHB 330数据阶段信号512选择的信号。类似地,示出了来自ASIC管芯AHB 370地址阶段信号508和ASIC管芯AHB 370数据阶段信号512的所选择的信号。在这个示例中,CPU和ASIC都在数据总线248和277中实现AHB(注意的是,桥与AHB交互的端口是405和437)。在这个示例中,CPU针对地址A0、A1、A2和A3发起四个总线事务。A0与ASIC管芯271上的外设(BLOCK1)216相关联,A1和A3与CPU管芯246上的SRAM块518相关联,并且A2与ASIC管芯271上的外设(BLOCK2)520相关联。在这种情况下,时钟以相同速率彼此同步。BLOCK1和/或BLOCK2是位于ASIC管芯上的任何从外设。
在周期1 522上开始,CPU在其地址阶段信号514上发出针对地址A0的32位写入的AHB事务。CPU管芯AHB块地址解码器确定这个地址在ASIC管芯271块地址空间中,并且因此在AHB地址阶段期间激活CPU管芯桥350的HSEL 532。CPU管芯桥350形成要在NDIO 421上发出的命令作为具有所需信息(例如,HADDR 570、HWRITE 566、HSIZE 568等的LSB)的互连460命令阶段。在这个示例中,我们假设命令阶段信号是根据CPU管芯AHB地址阶段信号组合生成的,但这也可以通过注册来完成。在已注册的情况下,该命令将在比CPU管芯的AHB地址阶段晚的时钟周期上在NDIO 421上发出。ASIC管芯桥365通过在其地址阶段信号508上发起对应的AHB总线事务来响应这个命令。ASIC管芯271上的AHB块地址解码器确定该地址与BLOCK1相关联并且因此为那个块发出HSEL 516作为那个ASIC管芯AHB地址阶段的一部分。
在周期2 534上,CPU在HWDATA 536上提供写有效载荷D0作为CPU管芯AHB数据阶段信号512的一部分,以用于在前一周期发起的针对A0的事务。CPU管芯桥350接收这个数据并使用NDIO 421互连信号作为互连460数据阶段将其传送到ASIC管芯271。ASIC管芯桥365将这个数据传播到其自己的HWDATA 538以供BLOCK1外设使用。在这种情况下,BLOCK1外设可以在该周期内完成操作,因此它断言其HREADYOUT 540允许ASIC管芯AHB数据阶段完成。ASIC管芯271AHB HREADYOUT多路复用器选择这个信号以提供给ASIC管芯桥365用于其HREADY 562。这个信息由ASIC管芯桥365通过在NRESP 423上指示OK而通过互连460传播。CPU管芯桥350然后进一步将其传播到其自己的HREADYOUT 544以允许CPU管芯246AHB数据阶段完成。
而且,在周期2 534上,CPU使用其地址阶段信号514发起针对地址A1的事务。CPU管芯246上的AHB块地址解码器确定这个地址与CPU管芯246上的SRAM 216相关联,并且因此在AHB地址阶段期间断言用于那个块的HSEL 518。由于在这个事务中不涉及CPU管芯桥350,因此它忽略这个事务并继续先前调度的数据阶段。如果数据阶段尚未调度,它将作为命令阶段将IDLE伪命令驱动到NDIO 421互连上。如果周期2 534上的CPU管芯AHB地址阶段通过断言其HSEL 532而被引导到CPU管芯桥,那么桥将注册CPU管芯AHB地址阶段信号514,以便在稍后在已经调度的NDIO数据阶段完成之后发出NDIO 421命令阶段。ASIC管芯桥365已经致力于数据阶段来传送D0,因此不将NDIO内容视为新的命令阶段。由于还没有被给予新的NDIO命令阶段,因此它在周期2 534期间不在其AHB地址阶段信号508上发起任何进一步的事务。SRAM事务在周期3 546上在CPU管芯246上完成。
在周期6 548上,CPU管芯246发起针对地址A2的16位读事务。CPU管芯AHB块地址解码器确定这个地址在ASIC管芯271块地址空间中,并且因此在其AHB地址阶段信号514上激活CPU管芯桥的HSEL 532。这被传播到NDIO 421上的命令阶段,其进一步以与周期1 522上发生的方式类似的方式被传播到ASIC管芯AHB 370地址阶段。在这种情况下,ASIC管芯AHB块地址解码器确定地址A2与BLOCK2外设相关联,因此它向这个块发出HSEL。
在周期7 550上,BLOCK2对其HREADYOUT 552解除断言以指示它未准备好完成ASIC管芯AHB数据阶段。ASIC管芯271AHB HREADYOUT多路复用器选择这个信号以提供给ASIC管芯桥365用于其HREADY 562。这由ASIC管芯桥365通过NRESP 423互连作为STL指示被传播。CPU管芯桥350接收这个STL指示并通过解除对其HREADYOUT数据阶段信号544的断言来响应以指示CPU管芯数据阶段未准备好完成。由于这是读取命令,因此两个桥都由于数据阶段是读取类型而反转了NDIO 421上的数据方向,使得ASIC管芯271在这个周期期间驱动互连。但由于从设备尚未提供由STL指示所指示的数据,因此NDIO 421上的数据在这个周期期间被CPU管芯桥忽略。
在周期8 554上,BLOCK2断言其HREADYOUT 552以指示它现在准备好完成数据阶段。它还在其HRDATA 556上进一步提供所请求的数据。ASIC管芯AHB数据阶段多路复用器由于先前注册的地址阶段而选择这些信号,并将它们提供给ASIC管芯桥365。ASIC管芯桥365通过在NRESP 423上指示OK并在NDIO 421上驱动HRDATA 556通过互连来将其传播。CPU管芯桥350然后通过断言其HREADYOUT 544并驱动其HRDATA 558上的数据D2来将其传播到CPUAHB总线。
在周期9 560上,CPU发出针对地址A3的读事务。AHB块地址解码器确定这与SRAM518相关联,因此向那个块发出HSEL。CPU以及ASIC桥350和365已经回复到用于事务互连460信令的命令阶段,将在NDIO 421互连上恢复原始的CPU到ASIC数据方向。由于到CPU管芯桥532的HSEL没有被断言,因此桥没有被提供任何事务来处理,因此它在NDIO上发出IDLE伪命令。ASIC管芯桥接收这个IDLE命令并将其解释为指示没有任何事务要处理,因此它在其AHB地址阶段信号508上不发出地址阶段。
在这个示例中,许多信号已被示为从其它信号组合地生成,使得当排序允许时,AHB信号514、512、508在同一周期上传播到互连262信号/从互连262信号传播。应当显而易见的是,这些信号传送中的一个或多个可以以寄存的方式完成,使得所生成的信号在比源信号更晚的周期上提供,诸如允许NCLK 420频率更高,同时仍然维持信号定时。
类似地,在这个示例中,互连262中的信号的数量足以在单个周期中传送所需量的命令和数据阶段内容。如果使用较少数量的互连,那么可以使用多个NCLK 420周期在多个序列化的周期中传送所需的内容。
贯穿这个序列的始终,CPU管芯246和在其上运行的软件不需要为BLOCK1和BLOCK2外设提供特殊处理。从CPU管芯246AHB总线的角度看,事务以通常的方式发出和响应。只需要分配BLOCK1和BLOCK2外设的总线地址,使得CPU管芯上的AHB块地址解码器将这些地址与CPU管芯桥350块地址空间相关联。在CPU管芯246的规范期间甚至不必了解在ASIC管芯271上实现的部件。由于ASIC管芯271实现其自己的AHB块地址解码器以向其各个AHB从设备提供HSEL信号,因此在CPU管芯的AHB块地址解码器中将大块地址分配给ASIC管芯271并让ASIC管芯271处置块地址解码的其余部分就足够了。这可以允许CPU管芯246是通用的,使得单个CPU管芯246实施方式可以能够与多个不同的ASIC管芯配合。
此外,ASIC管芯271上的外设也不需要因为它们是在ASIC管芯271上实现的而进行特殊处理。从ASIC管芯外设的角度看,它们连接到标准AHB总线370并且可以根据通常的AHB协议来操作。
为了处置软件针对ASIC管芯271中未实现的地址发起事务的情况,块地址解码器(或外设)可以在ASIC管芯数据阶段期间提供错误的HRESP指示。这可以作为ERR指示通过NRESP 423传播,CPU管芯桥350可以通过其自己的HRESP将该指示传播到CPU管芯AHB总线330。从CPU及其上运行的代码的角度看,该行为与就好象它自己的块地址解码器已确定该地址与任何已实现的AHB从设备都不匹配一样。此外,由于安全性授权不足,总线事务可能是非法的。在AHB系统中,这可以是对HPROT.PRIVILEGED 612解除断言的总线访问,这通常指示用户特权代码的访问,访问总线从设备中仅对通过内核特权代码的访问合法的地址。此外,HNONSEC被断言的访问尝试访问总线从设备中的地址(这仅对于HNONSEC未断言的访问合法)应当生成事务错误。在这些情况下,ASIC管芯271上的总线从设备可以由ASIC管芯桥365提供通常的AHB信号,然后它可以在其认为适当时对其做出响应,诸如通过使用HRESP423发出总线错误。
在图6中示出了使用这种技术的总线错误传播的序列图示例。在这个示例中,CPU发起三个事务,其中两个事务以错误响应完成。在周期1 622上,CPU发起对地址A0的写事务,地址A0被指派给ASIC管芯块地址空间,因此CPU桥的HSEL 532在周期1 622上的CPU AHB地址阶段期间被激活。CPU管芯桥350构成命令C0 618以呈现给NDIO 421互连。ASIC管芯桥365进一步将其传播到ASIC管芯AHB总线上的AHB事务地址阶段。ASIC管芯271中的块地址解码器未能将这个地址与任何实现的总线从设备相关联,因此AHB默认从设备的HSEL被激活。默认从设备通过激活其HRESP数据阶段指示并使用其HREADYOUT执行总线停顿来执行两周期错误响应,如AHB规范所要求的。使用通常的AHB数据阶段多路复用将HRESP和HREADY信号提供给ASIC管芯桥365。ASIC管芯桥365使用NRESP 423信令来指示ERR,以指示数据阶段带有错误地完成。然后,CPU管芯桥350使用其HRESP 574和HREADYOUT 544信号来执行其自己的两周期错误响应,以带错误完成这个CPU管芯AHB事务。
在周期4 610上,CPU发起另一个总线事务。在这种情况下,地址与ASIC管芯271上的总线从设备BLOCK1 516匹配,但是那个总线从设备被配置为不允许非特权访问。CPU在周期4 610上发起AHB事务地址阶段,指示这是使用HPROT 612的PRIVILEGED 612位的非特权访问。CPU管芯246上的块地址解码器检测到这个地址与CPU管芯桥350相关联,因此CPU管芯桥的HSEL 532被激活。CPU管芯桥350将其传播到NDIO 421命令阶段C1 620中。命令阶段内容包括未设置PRIVILEGED 612位的信息。ASIC管芯桥365将其传播到ASIC管芯AHB事务中,其中HPROT 614的PRIVILEGED位未被激活。当其块地址解码器将这个地址与BLOCK1相匹配时,它激活用于BLOCK1 516的HSEL。BLOCK1 516被配置为在非特权访问的情况下对错误做出响应,因此它在周期5 616和6 624期间在数据阶段中实现错误响应。这通过通常的AHB数据阶段多路复用被传播到ASIC管芯桥365。ASIC管芯桥365指示NRESP 423互连上的ERR,CPU管芯桥350检测并实现对CPU管芯AHB总线的数据阶段的两周期错误响应。
在周期7 626上,CPU向BLOCK1 516发出另一个事务,但是这次设置了特权位。通过NDIO 421C2中继的命令包括这个信息。ASIC管芯总线令其自己的HPROT PRIVILEGED 614位被设置来发起这个事务,因此BLOCK1从设备可以无错误地完成该事务。这使用OK NRESP423指示被指示回CPU管芯246,CPU管芯桥350通过无错误地完成CPU管芯AHB数据阶段来响应该OK NRESP 423指示。
图7描绘了具有各种突发的示例序列图。第一个突发是具有显式AHB突发指示的顺序事务。CPU管芯246上的AHB总线主设备使用从总线地址HADDR 570A0开始的INCR的HBURST710在周期1742上发出事务。地址A0被CPU管芯的块地址解码器确定为在ASIC管芯271块地址空间中,因此CPU桥的HSEL 532在AHB地址阶段期间被断言。CPU管芯桥350接收各种AHB地址阶段信号并形成NDIO 421命令阶段C0 740。当HBURST 710被指示为INCR时,命令C0 740被形成为向ASIC管芯桥365指示如果突发要发生,则每个传送的地址应当从前一个传送的地址递增。由于这是最常见的情况,因此可以构造命令编码,以便如果没有指示其它突发类型,那么可以将其假设为默认行为。如果HBURST 710是某种其它AHB突发类型,例如WRAP8,那么可以代替地对C0 740进行编码以提供这个指示。在周期2 744上,数据字D0被照常传送。而且,在周期2 744上,CPU管芯桥350接收与突发继续一致的另一个AHB命令,并且因此断言NPHASE 422以指示数据阶段的突发继续。一致性检查可以包括核实HADDR 570被正确递增,以及HWRITE 566和HSIZE 568与先前的传送匹配。ASIC管芯桥365检测到NPHASE被断言,并且因此在其AHB总线上形成流水线地址阶段以指示具有更新的HADDR 526和可选地更新的HTRANS(未编号)的突发继续。即使当NDIO互连正在传送数据D0时,它也会执行这个操作,因此不被用于在这个周期上提供另一个命令阶段。ASIC管芯上期望的AHB事务是从先前的C0 740命令和如由NPHASE指示的突发继续推断出来的。然后在周期3 746上,数据D1通过NDIO 421被传送以完成突发中的第二数据阶段。除了在周期5 750上AHB主设备不发出事务并且因此NPHASE 422在那个周期期间不被断言之外,这在周期4 748和5 750上类似地继续。由于NPHASE 422尚未在周期5 750上被断言并且周期5 750数据阶段NRESP 423不是STL,因此周期6 752中的NDIO421互连被两个桥理解为保留用于命令阶段。如果在周期6752期间发起了针对ASIC管芯271的另一个CPU AHB事务,或者在周期5期间发起了与正在进行的突发不相关的CPU AHB事务并且在CPU管芯桥365中为后面的事务排队,那么用于那个传送的命令可能已在周期6 752期间在NDIO 421上发出。在这个示例中,未指示此类事务,因此在NDIO 421互连上发出伪命令IDLE。
在周期7 754上,CPU管芯246上的AHB主设备用SINGLE HBURST 710向ASIC管芯从设备发起AHB事务,指示这个事务不可能是突发的一部分。ASIC管芯桥365形成命令C4以开始将那个事务桥接到ASIC管芯271。命令C4可以被编码为指示默认突发类型,即使总线主设备尚未明确指示任何突发类型。在周期8 756上的后续数据阶段期间,CPU管芯AHB发起另一个AHB事务,该事务恰好与已发出的命令C4的默认突发类型一致。在这种情况下,ASIC管芯桥365可以推断突发并且在周期8756上发出NPHASE 422以将各个事务变换成NDIO 421突发。
在周期11 722上,CPU管芯246上的DMA控制器212向同一地址A6发起一系列FIFO事务中的第一AHB事务。DMA控制器212可以向CPU管芯桥350提供额外信号NOINCR 724作为发出NDIO 421命令C6的提示,该NDIO 421命令C6指示突发继续应当针对每次传送使用相同的总线地址。在周期12 726上,DMA控制器212发出这个序列中的下一个事务。CPU管芯桥350可以核实这个新事务与当前命令C6的有效突发继续的一致性,并且断言NPHASE 422以继续非递增突发。ASIC管芯桥365将其形成在其AHB总线上的周期12 726地址阶段中,指示对与先前发出的地址相同的地址的事务。
在周期14 728上,CPU管芯总线主设备向相同地址A8发起一系列FIFO事务中的第一个事务。在这种情况下,它未能指示NOINCR 724,导致CPU管芯桥350形成具有与非递增不同的默认突发类型的NDIO 421命令阶段C8。在周期15 730上的数据阶段期间,CPU管芯总线主设备发起第二事务,CPU管芯桥350确定该第二事务与与其先前在命令阶段C8上所指示的不同的突发类型一致。在这种情况下,CPU管芯桥350检测到观察到的AHB序列与非递增突发一致。由于NDIO 421命令C8与推断的突发类型不一致,因此CPU管芯桥350在周期15 730上解除NPHASE 422的断言以将NDIO 421互连返回到用于即将到来的周期16 732的命令阶段。在周期16 732期间,它发出更新的NDIO 421命令C9以指示推断的非递增突发类型。在这个周期期间,CPU管芯桥350解除其HREADYOUT 544的断言以停顿CPU管芯AHB总线的数据阶段,同时在NDIO 421上发出新命令C9。然后,对于周期17 734到19 738,突发的其余部分可以不中断地继续,因为在CPU管芯AHB总线405上接收的每个命令与由C9指示的突发类型一致,并且因此NRESP可以被用于继续突发。
图8描绘了示出ASIC管芯271上的中断源与CPU管芯246上的中断控制器之间的中断桥接的序列图。在这个示例中,ASIC管芯271上的两个中断源在那个管芯上产生中断指示IRQ1 810和IRQ2812。IRQ1中断源使用基于边沿的指示,而IRQ2源使用基于电平的指示。CPU管芯246上的中断控制器被配置为从桥818接受指示IRQ1 814和IRQ2 816(其是CPU管芯桥350与CPU管芯246中的其它部件之间的一组接口信号)。由于CPU管芯桥350在这些中断请求线上仅提供单周期指示,因此CPU管芯中断控制器可以被配置为接受这些作为基于电平或基于边沿的指示。CPU管芯桥350被提供用于这两个中断源的TYPE指示,其可以是EVENT或LEVEL。EVENT指示ASIC管芯271中断源正在使用基于边沿的信令,因此将每个中断激活视为简单事件。LEVEL指示中断源正在使用基于电平的信令,指示响应于中断控制器中相关联的PENDED寄存器被清除而需要重新轮询ASIC管芯的中断请求。
在周期1 848上,ASIC管芯271ASIC管芯IRQ1 810线被中断源断言。ASIC管芯中断桥检测0到1序列并确定需要将中断上升沿传播到CPU管芯246。它请求NEVT 424发送器429将适当的枚举事件传播到CPU管芯246,同时还在其自己的用于该IRQ 822的QUEUED寄存器中注册传播这个事件的需要。当事件桥空闲时,它可以立即开始使用两个时钟序列E0.0和E0.1在NEVT 424上序列化这个事件,以形成序列化事件E0。此外,ASIC管芯NEVT 424串行器429指示E0到ASIC管芯IRQ桥826的完成的消息传递(其是从ASIC桥365到ASIC管芯271的信号的集合),因此当所需消息已发送时,它清除其用于IRQ1 822的QUEUED寄存器。在周期2850上,CPU管芯桥350检测到E0事件接收,它确定将其编码为用于IRQ1 814断言的事件。然后它驱动CPU管芯246IRQ1 814信号单个周期。中断控制器将这个指示注册到用于IRQ1待决寄存器(NVIC 868中的IRQ1.PENDED 828)中。取决于中断控制器的配置,这个PENDED配置可以导致中断服务例程的执行,或者仅可以供软件读取。无论哪种方式,一旦中断被处置得令CPU满意,就可以通过CPU断言IRQ1.PEND_CLR 830信号来清除PENDED指示。在中断控制器内部,这导致IRQ1.PENDED 828寄存器的清除。使这个PEND_CLR信号可用于CPU管芯桥350。桥注意到其IRQ1.TYPE 832是EVENT,因此忽略这个指示,因为无需进一步的动作。
在周期5 852上,ASIC管芯271IRQ2 812源激活其中断请求。ASIC管芯桥365的响应与其在周期1848上对IRQ1的响应类似,导致到CPU管芯246的序列化的NEVT 424消息E1。CPU管芯246与之前的E0消息类似地响应,最终导致通过CPU管芯上的IRQ2信号816的单周期激活来设置中断控制器中的IRQ2.PENDED 834寄存器。
当E1仍在序列化时,ASIC管芯271上的IRQ1 810源激活其中断请求。在这种情况下,NEVT 424互连正忙于序列化E1,因此ASIC管芯271上的IRQ桥826仅设置其IRQ1.QUEUED822寄存器以记住稍后对此进行序列化。在周期7 854上,NEVT 424互连变得可用,并且因此ASIC管芯271NEVT 424串行器开始序列化E2以在ASIC管芯271IRQ桥826的请求下指示这个IRQ1 810激活事件。注意的是,E2可以具有与E0相同的编码,因为它表示与E0相同的中断激活。在周期8 856上,这个事件序列化完成,导致中断控制器中的IRQ1.PENDED 828寄存器经由CPU管芯上的IRQ1信号814的单周期激活而被设置,并且还使得IRQ1.QUEUED 822寄存器由于NEVT 424串行器报告成功的事件传输而被清除。
在周期10 858上,CPU进入用于IRQ2 816的中断服务例程,使得IRQ2.PEND_CLR836和IRQ2.ACTIVE 838信号被断言。CPU管芯246IRQ桥818注意到PEND_CLR断言并且IRQ2.TYPE被设置为LEVEL并且因此设置其IRQ2.REPOLL 840寄存器。由于IRQ2.ACTIVE 838信号在中断控制器内部被设置,因此它还不应当执行重新轮询,因此在这个此周期不采取进一步动作。在周期11 860上,IRQ2.ACTIVE 838信号在中断控制器中被解除断言。由于CPU管芯246IRQ桥818现在具有已设置其IRQ 2.REPOLL 840寄存器,同时未设置IRQ2.ACTIVE838,因此它请求使用事务互连460来发送指示需要ASIC管芯271IRQ桥826重新检查其IRQ2812中断指示的特殊事务,并且如果那个信号当前为高的话则生成另一个NEVT 424事件。这个互连460事务C0 844在周期12 860上被执行。ASIC管芯271上的IRQ桥826通过重新检查其IRQ2 812输入指示来响应这个事务的接收。因为IRQ2 812被断言,所以它设置其IRQ2.QUEUED寄存器并请求事件E3的序列化以向CPU管芯246指示中断源当前是活动的。在该示例中,NEVT 424互连不忙,因此E3序列化可以在周期13 862上开始。注意的是,有可能使用相同的枚举对E1和E3进行编码,因为CPU桥350不需要对它们进行不同的处理。E3的接收导致IRQ2.PENDED 834寄存器经由IRQ2 816上的信令以与事件E1类似的方式被设置。
在周期17 864上,IRQ2.PENDED 834寄存器被软件清除。这使得IRQ2.PEND_CLR836信号被断言,而IRQ2.ACTIVE 838位信号未被断言。由于IRQ2.PEND_CLR 836是活动的并且IRQ2.TYPE 842是LEVEL,因此CPU管芯246IRQ桥818设置其IRQ2.REPOLL 840位。由于未设置IRQ2.ACTIVE 838,因此它可以立即请求事务互连460事务以重新轮询ASIC管芯271上的IRQ2 812中断源。这导致可以具有与C0 844相同编码的事务C1 846在周期19 866上进行事务处理。ASIC管芯271IRQ桥826通过检查其IRQ2 812中断请求输入来响应C1 846的接收,并且由于其未被断言而不采取进一步的动作。CPU管芯246没有接收任何中断激活消息并且因此IRQ2.PENDED 834寄存器保持未设置。在后面的某个时间,当ASIC管芯271IRQ2 812中断源再次激活时,ASIC管芯271可以以与在周期5 852上发生的E1 NEVT 424事务类似的方式向CPU管芯246指示这一点。
图9描绘了示出ASIC管芯271DMA使能的总线从设备与CPU管芯246的DMA控制器212内部包括的信号922之间的DMA请求同步的示例序列图。在这个示例中,具有DMA能力的AHB管芯外设提供DMA请求DRQ1 910,该请求DRQ1 910应当与CPU管芯DMA请求DRQ1 920同步,该请求DRQ1 920应当导致CPU管芯DMA控制器实现对ASIC管芯271上的FIFO地址的四周期突发写入。在序列开始时,DMA控制器212尚未针对那个通道被启用。CPU和ASIC管芯DRQ桥912和914各自针对每个DRQ通道独立地维持用于两个管芯之间的DRQ同步的状态916和918(DRQ同步状态机414和428内部也有信号)。在这个序列的开始,DRQ通道DRQ1 920的CPU管芯246状态是UNKN,指示其不了解ASIC管芯271上的DRQ1 910信号,并且在这种状态下,它向到DMA控制器212的DRQ1 920输入提供非活动电平。这个状态是复位后的初始状态,并且每当DMA控制器212使该DRQ通道被禁用于服务时就进入这个状态。DRQ1 910的ASIC管芯桥365初始状态是DISA,它向桥的该侧指示CPU管芯246对针对那个通道的DRQ同步不感兴趣。
在周期1 934上,在DMA控制器212中启用DRQ1 920的服务。CPU管芯DRQ桥912接收指示DMA通道被启用用于服务的信号DRQ1.ENA。由于其同步状态是UNKN,因此它在NDIO 421互连上请求特殊命令C0 930,该命令请求来自ASIC管芯271DRQ桥914的针对DRQ通道DRQ1910的同步。当事务C0 930成功完成时,CPU管芯246DRQ桥912进入那个DRQ通道的ARMD状态。当处于AMRD状态时,它向DMA控制器212提供DRQ1 920的不活动指示。在接收到命令C0 930时,ASIC管芯DRQ桥914进入其DRQ1910同步状态918的ARMD状态。
当ASIC管芯的DRQ桥914处于DRQ1 910通道的ARMD状态时,它检查DRQ1 910指示并且如果观察到信号是活动的则进入那个通道的PEND状态。这发生在周期4上。当处于PEND状态时,它请求NEVT 424桥将DRQ1激活的指示发送到CPU管芯246。在周期5 938上,NEVT 424桥不忙,因此它开始事件E0的两周期序列化以发送DRQ1激活指示。在完成这个事件传输后,ASIC管芯DRQ桥914进入TRGD状态。在周期6上接收NEVT 424事件E0的指示被提供给CPU管芯DRQ桥912。由于当接收到这个事件时DRQ桥912处于DRQ1通道的ARMD状态,因此它进入那个通道的TRGD状态。当CPU管芯DRQ桥912处于DRQ1通道的TRGD状态时,它向DMA控制器212提供活动DRQ指示DRQ1 920,除非它正在从事务互连接收总线事务正在NRESP 423上接收针对与那个DRQ通道相关的BUS事务的OKDN响应的指示。在这种情况下,它没有在接收这个指示,因此它向DMA控制器212断言DRQ1 920。
在周期9 940上,DMA控制器212响应于其DRQ1 920输入的断言而开始编程的AHB突发事务。它在AHB地址阶段期间向CPU管芯桥350提供附加地址阶段信息DRQN 924,该信息指示该事务是DRQ1 920响应序列的一部分。在这种情况下,所需事务是非递增突发,因此它还提供NOINCR 724地址阶段突发提示以指示NDIO 421命令阶段命令C1 932应当指示非递增突发类型。NDIO 421命令C1932由CPU管芯桥350发出以发起桥接的AHB事务。ASIC管芯桥365接收这个命令并将应当被监视的DRQ通道号注册为DRQ1 910。在那个事务的一个或多个数据阶段中的每一个期间,每当该事务应当指示数据阶段成功完成时,如果ASIC管芯271上针对命令阶段中所指示的DRQ通道的DRQ请求在那个数据阶段期间为高,那么NRESP 423指示将为OK。代替地,如果ASIC管芯271的DRQ请求在数据阶段期间为低,那么NRESP 423指示为OKDN。对于每个数据阶段,CPU管芯AHB桥926接受OK或OKDN作为指示数据阶段成功完成。对于OKDN的每个CPU管芯246的接收,它进一步向DRQ桥912提供该接收的指示。DRQ桥912通过针对那个通道解除其自己的到DMA控制器212的DRQ指示的断言并且还将其针对那个通道的DRQ同步状态转变到ARMD来对此做出响应。对于OKDN的每个ASIC管芯271传输,那个通道的ASIC管芯271DRQ同步状态将被改变为ARMD。在这个示例序列中,这首先发生在周期12 942上,其以周期准确的方式同步两个管芯上的DRQ1 920和910的停用。
在一个实施例中,CPU管芯和/或ASIC管芯以多个NDIO 421宽度配置实现,其可以在运行时改变以使得能够与另一个管芯的多个不同配置耦合。这是期望的,因为它允许单个设计与具有不同互连宽度的多个其它设计耦合的灵活性。在一些实施例中,NEVT和NRESP也可以被重新分区。
图10A图示了实现初始降低速率数据发现过程的一个实施例,诸如在加电或复位1010时,两个管芯可以彼此协商它们的能力以确定相互支持的互连宽度。在一个实施例中,在起动时或响应于复位1010,一些或所有互连宽度的两个管芯都运行限于透视管芯的内部初始化过程1020,并且两者都可以通过假设普遍支持的小互连宽度来开始并使用它来连接1030可能交换多个连接消息。然后,两个管芯可以使用这个最小格式来交换能力1040数据,然后就它们都支持的较好执行格式达成一致1050。例如,它们可能通过独立评估或者通过CPU管芯246选择其优选格式并使用CTRL事务106将模式改变传送到ASIC管芯或者两者来做到这一点,例如,两个管芯识别最佳能力集并且CPU管芯使用事务互连460事务1060将其选择的集合发送到ASIC管芯。另外,可能期望维持最小能力以在正常操作期间保存电力或者在操作期间重新协商能力,诸如以优化接口功耗。在这种情况下,两个管芯可以以较低的能力集开始,并且CPU管芯可以总是基于后面选择的初始能力交换1040来使用CRTL消息1060来改变协议,而不需要复位。
图10B是替代发现过程的实施例,其中CPU管芯246能够具有一些或所有互连宽度,但允许ASIC管芯仅实现有限数量的优选宽度,诸如一些或全部宽度选项所需的一组非可选信号以及多个可选信号。仅ASIC管芯提供的互连连接到CPU管芯246,而其它CPU管芯246可选互连端口保持未连接。在复位或加电1010以及两个管芯的初始化1020之后,ASIC管芯可以在发现期间通过在其一些或全部可选互连上施加电阻拉动1070来指示其连接性。CPU管芯246可以通过感测其可选互连端口中的哪些可以检测该电阻拉动的存在来进行端口检测1080。以这种方式,CPU管芯可以确定ASIC管芯互连宽度。另外,使用这个信息,CPU管芯246将设置其内部能力1090以匹配ASIC管芯,而不要求任何进一步的消息交换。一旦检测到互连宽度,ASIC管芯就可以去除拉动,诸如通过检测NDIO上的适当命令。在一个实施例中,ASIC管芯可以应用上拉,并且编码为全零的NDIO上的IDLE命令可以指示上拉去除。其它ASIC管芯指示(诸如弱电流源)也可以被用作电阻拉动的替代方案。
在图10A和/或10B中的过程的一些实施例中,可以存在附加或更少的操作。而且,可以改变操作的次序,和/或可以将两个或更多个操作组合成单个操作。
在一个实施例中,所公开的通信技术提供了一种总是以主/从关系桥接两个管芯的系统。CPU管芯预期包含至少一个微控制器核心(CPU)及其紧密耦合的存储器。CPU管芯不限于单个CPU核心,并且同样支持多核。CPU管芯还可以包含一个或多个DMA控制器和存储器。CPU管芯预期不要求与引线框架进行任何直接连接。ASIC管芯可以作为CPU管芯与外界的网关。它包含存储器映射的外设,用于实现补充CPU管芯特征以用于特定应用所需的任何接口和逻辑。该接口以对CPU透明的方式在ASIC管芯外设与CPU管芯之间桥接总线事务、中断事件和DMA请求,从而扩展CPU功能性。从外部看,对于用户来说,这两个管芯看起来和行为上就像单个CPU。从CPU块的角度看,该单元“认为”它与这些外设有直接的有线连接,而事实上,它们是第二个管芯的一部分。(参见图2和图3了解更多细节。)为了实现这种效果(例如,应用开发多管芯透明性),本说明书包括多个实施例。
在描述中做出的某些选择仅仅是为了方便准备文本和附图,并且除非有相反的指示,否则这些选择本身不应被解释为传达关于所描述的实施例的结构或操作的附加信息。选择的示例包括:用于图形编号的名称的特定组织或指派,以及用于识别和引用实施例的特征和元素的元素标识符(例如,标注或数字指示符)的特定组织或分配。
词语“包括”和“包含”的各种形式具体地旨在被解释为描述开放式范围的逻辑集的抽象,并且并不意味着传达物理包含,除非明确地描述(诸如后跟词语“内(within)”)。
虽然出于描述和理解清楚的目的已经相当详细地描述了前述实施例,但是所公开的通信技术不限于所提供的细节。所公开的通信技术有许多实施例。所公开的实施例是示例性而非限制性的。
应该理解的是,结构、布置和使用的许多变化可能与本描述一致,并且在所颁发专利的权利要求的范围内。例如,互连和功能单元位宽、时钟速度以及所使用的技术的类型根据每个部件块中的各种实施例是可变的。给予互连和逻辑的名称仅仅是示例性的,并且不应当被解释为限制所描述的概念。流程图和流图过程、动作和功能元素的次序和布置根据各种实施例是可变的。而且,除非明确相反地说明,否则指定的值范围、使用的最大和最小值或其它特定规范(诸如文件类型;以及寄存器和缓冲器中的条目或级的数量)仅仅是所描述的实施例的那些,预期将跟踪实施技术的改进和变化,并且不应被视为限制。
可采用本领域中已知的功能上等同的技术来代替所描述的那些技术来实现各种部件、子系统、操作、功能、例程、子例程、内联例程、过程、宏或其部分。还应该理解的是,实施例的许多功能方面可根据依赖于实施例的设计约束以及更快处理(促进将以前在硬件中的功能迁移到软件中)和更高集成密度(有利于将以前在软件中的功能迁移到硬件中)的技术趋势来选择性地在或者硬件(例如,一般而言专用电路系统)或者软件(例如,经由某种方式的编程控制器或处理器)中实现。各个实施例中的具体变化包括但不限于:划分上的差异;不同的形状因子和配置;不同操作系统和其它系统软件的使用;不同接口标准、网络协议或通信链路的使用;以及当根据特定应用的独特工程和业务约束实现本文描述的概念时预期的其它变化。
已经用远远超出所描述的实施例的许多方面的最小实施方式所需的细节和环境上下文描述了实施例。本领域普通技术人员将认识到的是,一些实施例省略了所公开的部件或特征,而不更改其余元件之间的基本协作。因此应该理解的是,所公开的许多细节并不是实现所描述的实施例的各个方面所必需的。就其余元素与现有方法可区分的程度而言,被省略的部件和特征不限制本文描述的概念。
所有此类设计变化都是对所描述的实施例所传达的教导的非实质性改变。还应该理解的是,本文描述的实施例对其它计算和网络应用具有广泛的适用性,并且不限于所描述的实施例的特定应用或行业。因此,所公开的通信技术应被解释为包括涵盖在所颁发专利的权利要求的范围内的多种可能的修改和变化。
所公开的实施例可以是任何电子设备(或可以包括在其中)。例如,电子设备可以包括:蜂窝电话或智能电话、平板计算机、膝上型计算机、笔记本计算机、个人或台式计算机、上网本、媒体播放器设备、电子图书设备、
虽然使用特定部件来描述实施例,但是在替代实施例中,可以存在不同的部件和/或子系统。因此,系统和/或集成电路的实施例可以包括更少的部件、附加的部件、不同的部件、两个或更多个部件可以被组合成单个部件、单个部件可以被分离成两个或更多个部件,和/或可以改变一个或多个部件的一个或多个位置。
而且,系统和/或集成电路的实施例中的电路和部件可以使用模拟和/或数字电路系统的任何组合来实现,包括:双极、PMOS和/或NMOS门或晶体管。此外,这些实施例中的信号可以包括具有连续值的大致离散值和/或模拟信号的数字信号。此外,部件和电路可能是单端或差异的,并且电源可以是单极或双极的。注意的是,前面实施例中的电耦合或连接可以是直接的或间接的。在前面的实施例中,与路由对应的单线可能指示一条或多条单线或路由。
集成电路可以实现通信技术的功能中的一些或全部。这个集成电路可以包括用于实现与通信技术相关联的功能的硬件和/或软件机制。
在一些实施例中,用于设计集成电路或集成电路的一部分(包括本文描述的电路中的一个或多个)的过程的输出可以是计算机可读介质,诸如例如磁带或光盘或磁盘。可以用数据结构或其它描述电路系统的信息对计算机可读介质进行编码,这些信息可以在物理上被实例化为集成电路或集成电路的部分。虽然可以使用各种格式进行此类编码,但这些数据结构通常以以下格式编写:Caltech中间格式(CIF)、Calma GDS II流格式(GDSII)、电子设计互换格式(EDIF)、OpenAccess(OA)或Open Artwork系统互换标准(OASIS)。集成电路设计领域的技术人员可以从上面详述的类型的示意图以及对应的描述中开发出此类数据结构,并在计算机可读介质上编码数据结构。集成电路设计领域的技术人员可以使用此类编码的数据来制造包括本文所述的电路中的一个或多个的集成电路。
虽然前面的实施例中的操作中的一些是在硬件或软件中实现的,但通常可以用各种配置和架构实现前面的实施例中的操作。因此,可以在硬件、软件或两者中执行上述实施例中的操作中的一些或全部。例如,可以使用由处理器或集成电路中的固件执行的程序指令来实现通信技术中的操作中的至少一些。
而且,虽然在前述讨论中提供了数值的示例,但在其它实施例中使用不同的数值值。因此,所提供的数值并不是要限制。
在前述描述中,我们参考“一些实施例”。注意的是,“一些实施例”描述所有可能的实施例的子集,但并不总是指定相同的实施例。
前述描述旨在使本领域任何技术人员都能够做出并使用本公开,并且是在特定应用及其要求的上下文中提供的。而且,仅出于说明和描述的目的呈现了本公开的实施例的前述描述。它们不是详尽的或将目前的公开限制到所公开的形式。因而,对于本领域技术人员来说,在不偏离本公开的精神和范围的情况下,许多修改和变化将是显而易见的,并且本文定义的一般原则可以应用于其它实施例和应用。此外,对前面的实施例的讨论并非旨在限制本公开。因此,本公开并不限于所示的实施例,而是应当符合与本文公开的原理和特征一致的最宽广范围。
- 线夹机构和引线键合机
- 线尾自动处理装置和引线键合机
- 全自动引线键合机金线断线检测装置