一种地铁轨道几何病害识别方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及地铁轨道病害识别领域,特别是涉及一种地铁轨道几何病害识别方法及系统。
背景技术
地铁在现代大型城市交通中占有重要地位。轨道是地铁基础设施的重要组成部分,其良好的质量状态是列车安全运行、旅客舒适乘坐的保证。轨道几何状态是应用最广泛的用于表示轨道质量状态的指标和编制轨道维修计划的依据。轨道几何状态主要由以下轨道几何参数表示:高低(Longitudinal level,LL)、轨向(Alignment,AL)、水平(Cross-level,CL)、轨距(Gauge,GA)、三角坑(Twist,TW)等。世界各国都规定轨道几何参数的偏差的管理值,并根据管理需求对偏差程度进行分级。超过这些管理值的状态就是轨道几何病害。
当轨道上存在轨道几何病害时,将会降低旅客乘坐的舒适性,严重时会影响列车运行的安全性,甚至导致列车脱轨。地铁运营公司会根据实际的管理需求,对不同等级的病害采取不同的应对措施。随着乘客对地铁运行服务质量需求的提高,地铁基础设施管理行业正在逐渐走向精细化管理,基于状态预测的轨道几何预防性维修模式正在逐渐成为主流。而这种维修模式的基础,则是准确、及时地掌握轨道几何病害的信息。
对地铁轨道进行动态轨道几何病害检测最常见的方式是轨检车检测。然而,基于轨检车的轨道几何病害(track geometry defect,TGD)检测模式存在运用成本高,检测频率低的问题。例如在中国,地铁公司每两个月进行一次轨检车检测。因此,现有的轨检车检测方式难以满足地铁轨道基础设施管理部门的精细化管理需求。近年来地铁行业出现了在普通载客列车上安装传感器或使用便携式传感器设备采集轴箱、转向架和车体的加速度与角速度等列车运行振动数据,其中,使用便携式设备在车厢内采集车体振动数据更加方便灵活,不需要额外传感器维护,可以提高检测效率,降低检测成本。但是由于车体振动数据与TGD之间呈现复杂的非线性关系,这样的方法仍处于初步发展阶段,检测的准确率和适用的病害类型还需要进一步研究。
在运营列车上收集的振动数据包括轴箱、转向架和车体的加速度与角速度,对这些数据进行分析的方法可以分为传统方法和机器学习类方法。其中传统方法可以进一步细分为基于机理模型和基于信号分析两大类。
(1)传统列车振动数据分析方法:机理模型类研究中的一类研究以车辆动力学为基础进行。相较于转向架和车体,利用轴箱振动数据进行轨道几何估计会获得相对更好的结果,这是由于在轴箱、转向架和车体之间悬挂系统。悬挂系统会对轨道几何的原始波形起到滤波器的作用,提高了轨道几何-转向架振动和轨道几何-车体振动之间的非线性。但是安装在轴箱的传感器工作条件恶劣,又难以进行及时维修,因此研究人员更倾向于使用转向架和车体的振动数据进行研究。另一类研究基于车辆-轨道耦合系统的动力学仿真模型进行。然而由于轨道结构、轮轨接触状态、非线性悬挂等众多影响因素的存在,车辆-轨道间关系呈现复杂的非线性,因此机理模型类的方法通常难以全面考虑各种影响因素,而准确性又依赖于系统参数选取的真实性和可靠性。传统分析方法中另外一类是基于信号分析的研究。然而信号处理方法本质上是对振动数据进行线性处理,在处理时通常假设运行速度为常数。另外由于不同的病害经过车辆最终反应在振动信号中的特征是不同的,针对每种病害寻找最可行和有效的特征指标仍然很困难。
(2)机器学习类的列车振动数据分析方法:近年来,以神经网络(Neural network,NN)为代表的机器学习类模型在多个行业得到了广泛应用。仅利用车体振动来提取轨道几何病害是一件具有挑战性的研究。得益于机器学习类方法的发展,这一领域已经有了一些有价值的成果。这些基于机器学习(Machine Learning,ML)的方法依赖于实际数据的积累与验证,既有研究在这方面仍有欠缺。此外,仅将机器学习类模型作为分类器类的方法,本质上是对基于信号处理类方法的拓展,在建立特征指标时仍然面临相同的困难。而黑盒类研究虽然使用了具有较强的非线性表示能力的模型,但是这类模型的网络结构优化和超参数选择仍然需要进一步研究。既有的模型主要使用尝试法(Trail method),难以有效获取最佳的模型。
(3)机器学习类的网络结构搜索(NetworkArchitecture Search,NAS)领域相关研究:设计一个适用于具体应用场景的ML模型结构(Architecture)依赖专家经验、专业知识,并需要大量的时间进行尝试。ML模型的结构定义为组成模型的部件和他们的超参数。为了高效进行模型结构开发,研究人员提出了网络结构搜索(Network architecture search,NAS)理论方法。NAS的思路是在一个网络结构的搜索空间
其中,D
由上述内容可知,在利用便携式设备采集车体振动数据进行轨道几何病害识别的问题中,虽然机器学习类方法已经体现出了分析复杂非线性关系的潜力,并且使用仿真数据验证了初步可行性,但是仍然存在提高在实际数据上识别准确率的挑战。另一方面,此类模型进行结构超参数优化时,主要使用黑盒尝试法,优化的时间长,且性能较低,因此识别效率也有待提高。
发明内容
基于此,本发明实施例提供一种地铁轨道几何病害识别方法及系统,以提高地铁轨道几何病害识别的识别准确率和识别效率。
为实现上述目的,本发明提供了如下方案:
一种地铁轨道几何病害识别方法,包括:
获取目标地铁轨道的车体振动数据和车体信息;所述车体信息,包括:车体运行速度和车况信息;
对所述目标地铁轨道的车体振动数据进行分段,并基于均方根值的方法对各段数据进行转换,得到所述目标地铁轨道的多段等距离间隔数据;
根据所述目标地铁轨道的多段等距离间隔数据和所述目标地铁轨道的车体信息,得到所述目标地铁轨道的检测数据;
将所述目标地铁轨道的检测数据输入轨道几何病害识别模型中,确定所述目标地铁轨道是否存在轨道几何病害以及存在时的病害等级;
其中,所述轨道几何病害识别模型是采用训练数据,基于可微结构搜索的方法对二维卷积神经网络进行训练得到的;
所述训练数据,包括:地铁轨道样本的检测数据和对应的标签数据;所述标签数据,包括:所述地铁轨道样本是否存在轨道几何病害以及存在时的病害等级。
本发明还提供了一种地铁轨道几何病害识别系统,包括:
数据获取模块,用于获取目标地铁轨道的车体振动数据和车体信息;所述车体信息,包括:车体运行速度和车况信息;
数据划分模块,用于对所述目标地铁轨道的车体振动数据进行分段,并基于均方根值的方法对各段数据进行转换,得到所述目标地铁轨道的多段等距离间隔数据;
检测数据确定模块,用于根据所述目标地铁轨道的多段等距离间隔数据和所述目标地铁轨道的车体信息,得到所述目标地铁轨道的检测数据;
病害识别模块,用于将所述目标地铁轨道的检测数据输入轨道几何病害识别模型中,确定所述目标地铁轨道是否存在轨道几何病害以及存在时的病害等级;
其中,所述轨道几何病害识别模型是采用训练数据,基于可微结构搜索的方法对二维卷积神经网络进行训练得到的;
所述训练数据,包括:地铁轨道样本的检测数据和对应的标签数据;所述标签数据,包括:所述地铁轨道样本是否存在轨道几何病害以及存在时的病害等级。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明实施例提出了一种地铁轨道几何病害识别方法及系统,该方法,基于目标地铁轨道的车体振动数据和车体信息得到目标地铁轨道的检测数据,并将目标地铁轨道的检测数据输入轨道几何病害识别模型中,确定目标地铁轨道是否存在轨道几何病害以及存在时的病害等级;其中,轨道几何病害识别模型是采用训练数据,基于可微结构搜索的方法对二维卷积神经网络进行训练得到的。本发明基于可微结构搜索的方法实现轨道几何病害的识别,相较于传统黑盒尝试法,大大提高了识别模型优化的效率和效果,从而提高地铁轨道几何病害识别的识别准确率和识别效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的地铁轨道几何病害识别方法的流程图;
图2为本发明实施例提供的二维卷积神经网络的结构示意图;
图3为本发明实施例提供的堆叠结构中的一个单元的具体结构示意图;
图4为本发明实施例提供的二维深度可分离卷积块的结构示意图;
图5为本发明实施例提供的二维扩张可分离卷积块的结构示意图;
图6为本发明实施例提供的采用便携式检测仪采集数据的示意图;
图7为本发明实施例提供的技术框架示意图;
图8为本发明实施例提供的数据转换示意图;
图9为本发明实施例提供的数据集划分示意图;
图10为本发明实施例提供的堆叠结构中的单元结构示意图;
图11为本发明实施例提供的不同超参数设置的模型TGDF对比及模型训练时间对比图;
图12为本发明实施例提供的地铁轨道几何病害识别系统的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
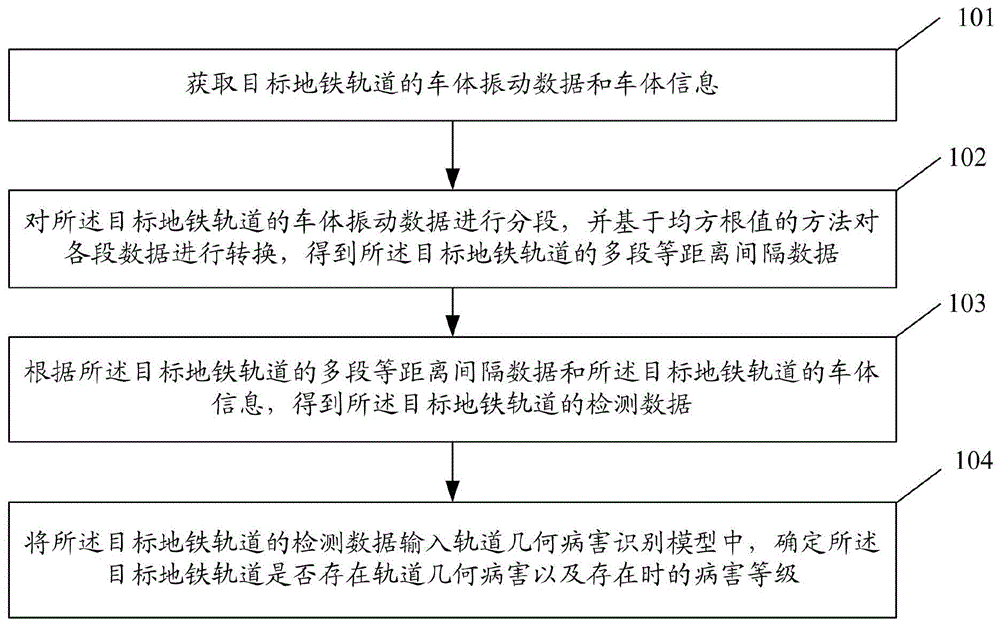
参见图1,本实施例的地铁轨道几何病害识别方法,包括:
步骤101:获取目标地铁轨道的车体振动数据和车体信息。
其中,所述车体振动数据,包括:横向加速度、垂向加速度和三轴角速度。所述车体信息,包括:车体运行速度和车况信息。
本实施例采用便携式检测仪采集车体振动数据。
步骤102:对所述目标地铁轨道的车体振动数据进行分段,并基于均方根值的方法对各段数据进行转换,得到所述目标地铁轨道的多段等距离间隔数据。
步骤103:根据所述目标地铁轨道的多段等距离间隔数据和所述目标地铁轨道的车体信息,得到所述目标地铁轨道的检测数据。
步骤104:将所述目标地铁轨道的检测数据输入轨道几何病害识别模型中,确定所述目标地铁轨道是否存在轨道几何病害以及存在时的病害等级。
其中,所述轨道几何病害识别模型是采用训练数据,基于可微结构搜索的方法对二维卷积神经网络进行训练得到的。所述训练数据,包括:地铁轨道样本的检测数据和对应的标签数据;所述标签数据,包括:所述地铁轨道样本是否存在轨道几何病害以及存在时的病害等级。
在一个实例中,步骤102,具体包括:
1)对所述目标地铁轨道的车体振动数据按照采样频率进行划分,得到多段等时间间隔数据;所述等时间间隔数据中包括多个数据点。
2)计算每段所述等时间间隔数据的均方根值,根据所述均方根确定多段等距离数据段。
3)对每段所述等距离数据段中的数据点按照里程由大道小进行组合,得到多段等距离间隔数据。
在一个实例中,步骤103,具体包括:
1)根据所述目标地铁轨道的车体信息中的车体运行速度,计算每段所述等距离间隔数据对应的平均速度。
2)根据所述目标地铁轨道的车体信息中的车况信息,确定每段所述等距离间隔数据对应的车底编号。
3)将所述等距离间隔数据、对应的平均速度和对应的车底编号确定为所述目标地铁轨道的检测数据。
在一个示例中,步骤104中的所述轨道几何病害识别模型的确定方法为:
1)获取训练数据。
2)构建二维卷积神经网络。
参见图2,所述二维卷积神经网络,包括:第一卷积层(Init Conv)、第二卷积层(Init Conv)和堆叠结构。所述第一卷积层和所述第二卷积层并联。所述堆叠结构,包括:n个单元(Cell),其中,n个单元中的第
所述有向无环图中的边,包括:依次连接的二维深度可分离卷积块(2-d DepthSeparable ConvolutionBlocks,2-d DSCB)、二维扩张可分离卷积块(2-d DilatedSepratable Convolution Blocks,2-d DiSCB)、二维最大池化运算模块(2-d MaxPooling,2-d MaxPool)和二维平均池化运算模块(2-dAverage Pooling,2-dAvgPool)。
参见图4,所述二维深度可分离卷积块(2-d DSCB),具体包括:依次连接的第一输入层、第一非线性整流单元(Rectified LinearUnit,ReLU)、第一深度卷积层(DepthwiseConv)、第一点卷积运算层(Pointwise Conv)、第一二维批标准化运算层(2-dimensionalBatchNormalization,2-dBN)、第二非线性整流单元(Rectified LinearUnit,ReLU)、第二深度卷积层(Depthwise Conv)、第二点卷积运算层(Pointwise Conv)、第二二维批标准化运算层(2-dimensionalBatchNormalization,2-dBN)和第一输出层。
参见图5,所述二维扩张可分离卷积块2-d DiSCB,具体包括:依次连接的第二输入层、第三非线性整流单元(Rectified LinearUnit,ReLU)、第三深度卷积层(DepthwiseConv)、第三点卷积运算层(Pointwise Conv)、第三二维批标准化运算层(2-dimensionalBatchNormalization,2-dBN)和第二输出层。
3)将所述训练数据输入所述二维卷积神经网络中,采用可微结构搜索的方法进行空间搜索,确定所述二维卷积神经网络中的结构参数值。具体的:
根据所述二维卷积神经网络中的结构参数构建双层优化模型;所述双层优化模型包括内层优化模型和外层优化模型。
将所述训练数据划分为训练集和验证集。
将所述训练集和所述验证集分别输入所述二维卷积神经网络中,采用可微结构搜索的方法对所述内层优化模型进行一代训练,采用可微结构搜索的方法将所述外层优化模型的搜索空间由离散转为连续,同时基于一代训练得到的最优权重,采用梯度下降法对所述外层优化模型进行求解,得到述二维卷积神经网络中的结构参数值。
4)将确定结构参数值后的二维卷积神经网络确定为轨道几何病害识别模型。
为了进一步说明上述实施例,下面给出了一个更为具体的实例,主要对数据采集、轨道几何病害识别模型所采用的训练数据、模型训练过程及模型的有效性等方面进行了详细描述。
本实例要解决的技术问题是基于便携式检测仪采集的车体振动数据进行地铁轨道几何病害识别(Car-body-vibration-data-basedmetro track geometry defectidentification problem,CVD-based MTGDIP)问题。该问题需要使用地铁列车车体振动数据(Car-body vibration data,CVD),判断地铁轨道上是否存在轨道几何病害(trackgeometry defect,TGD),并确定该病害的等级。
1、首先对便携式检测仪进行介绍。
(1)CVD由一种便携式检测仪在普通载客地铁列车上采集,数据信号包括车体纵向、横向和垂向的加速度及角速度,符合右手坐标系,车体振动数据坐标系如图6的(A)部分所示,同时,获得的还有速度和里程位置信息,为了尽量降低车况对振动数据造成额外影响,采集装置应当安装在走行部上方,车体振动数据采集位置如图6的(B)部分所示。本实例使用的便携式检测仪由北京交通大学轨道交通控制与安全国家重点实验室研发。检测仪主机的尺寸为270×170×91mm,便携式检测仪结构如图6的(C)部分所示,便携式检测仪,包括:控制器1、噪声传感器2、4G模块3、Wi-Fi模块4和惯性测量单元5,噪声传感器2、4G模块3、Wi-Fi模块4和惯性测量单元5均与控制器1连接。图6的(C)部分仅为了示出各个结构的位置关系。
(2)选取TGD的一种,记为C。根据地铁公司的管理规定将病害C的严重程度划分为若干等级,此外,本实例将不存在病害也作为病害C的一种状态。
2、对卷积神经网络CNN进行说明。
CNN具有与LSTM这类循环神经网络(Recurrentneuralnetwork,RNN)模型相当的时间序列信号处理能力,并且具有更快的训练速度,因此很多研究被用来处理振动信号数据。本发明实例提出的基于可微结构搜索(Differentiable architecture search,DARTS)方法进行结构优化的地铁轨道几何病害识别CNN模型(Metro track geometry defectsidentification CNN,MTGDI-CNN)来解决CVD-based MTGDIP问题。即基础问题转化为MTGDI-CNN的构建问题(MTGDI-CNN development problem,MTGDI-CNNDP)。本发明实例的技术框架如7所示,参见图7,基于在相同轨道区段采集的CVD、影响CVD的异质性因素和同时期轨检车的TGD报告等数据生成CVD-TGD数据集,之后利用DARTS方法使用该数据集对MTGDI-CNN进行模型结构优化和优化效果验证。
CNN模型的训练过程是如公式(3)、(4)所示的最优化问题。
s.t.(X,Y)∈D
其中,X∈R
MTGDI-CNNDP问题包含以下技术问题:
(1)研究将CVD-based MTGDIP问题中的原始数据与预测目标转化为适用于CNN模型的输入输出的方法。需要考虑:
1)如何将连续的CVD转化为适用于CNN输入的离散样本;
2)在生成样本时考虑CVD与TGD之间的哪些异质性影响因素。
(2)MTGDI-CNN结构设计,训练与评价。结构设计即根据转化后的样例数据集,设计CNN模型的结构。CVD和TGD具有复杂的函数关系,需要大量增加层数的神经网络才能得到较好的拟合效果。但是普通简单结构的CNN模型增加层数后将导致过拟合,反而降低了模型的识别性能。因此,MTGDI-CNN的NAS问题是本研究需要解决的一个关键问题。解决这个问题需要考虑:
1)降低公式(1)的搜索空间;
2)提高公式(2)的计算速度;
3)应对TGD数据集的类别不平衡问题的策略;
4)结合地铁轨道管理实际需求评价不同模型结构的综合性能。
3、对地铁轨道几何病害识别模型及优化方法进行介绍。
3.1样例数据集(训练数据)设计
样例数据集中的每个样例由样本和标记组成。在本实例中,样本以CVD为基础生成,标记以同时期的轨检车检测报告生成。轨检车检测报告包括检测时间、检测线路信息、病害记录等。其中病害记录的内容包括病害位置、病害长度、病害类型、病害等级等信息。
(1)样本生成规则
考虑到车体纵向加速度直接受到列车加减速的影响,因此在本实例中,不将其纳入样本,只考虑剩余的5种车体振动数据,即横向加速度
为了适应CNN模型的输入,需要对连续的I进行分段。每个数据段对应的实际地铁线路里程长度记为s,该段数据记为I
局部的等时间间隔数据,如图8的(C)部分所示,设I在最小距离间隔d内的包含n个点,则这n个点的第i种振动信号的RMS值计算公式如公式(5)。
其中,i=1,2,...,5表示不同的振动数据类型;j=1,2,...n表示距离间隔d内的第j个数据点;
其中,
(2)样本标记规则
本实例将不存在病害也作为病害C的一种状态。当依据地铁公司的管理规则将地铁轨道几何划分为n
/>
3.2基于DARTS的MTGDI-CNN模型(即上述的二维卷积神经网络)
(1)模型结构
车体振动数据是天然的多通道1维数据,各通道信号振幅以轨道里程为维度波动。然而同一种轨道几何病害通常会反应在多个通道的车体振动数据中,车体自身车况导致的振动也会反应在所有通道的车体振动数据中,并且这些振动的强度还会随运行速度变化。因此,轨道几何病害识别模型不仅需要具有分析各种振动数据的能力,还需要具有分析不同数据之间关系的能力。CNN模型中最常用的卷积方式是1维卷积或2维卷积。使用1维卷积构建模型来处理原始的振动数据进行轨道几何病害识别更加直接,而不需要引入其他的特征提取方法,在建筑管理和病害识别领域有很多相关研究。但是1维卷积假设不同种类的振动数据之间相对独立,处理不同振动数据之间关系的能力相对较弱,考虑到CVD数据的特点,使用1维卷积会降低导致识别性能。本实例采用2维卷积,通过将振动信号拼合为2维数据,提出一种基于可微结构搜索方法(DARTS)的轨道几何病害识别2-d CNN模型,实现利用便携式检测仪对轨道几何病害的识别。模型整体结构仍参见图2。
MTGDI-CNN模型(二维卷积神经网络)的主体以单元(Cell)堆叠组成,输入为由车体振动数据及速度、车况等异质性因素生成的样本X
(2)单元结构
由于直接对所有运算层之间连接组成的空间进行搜索非常困难,考虑到神经网络中有很多相同的结构,在网络结构搜索(NAS)的研究中,可以将整个网络视为若干个相同结构的单元(Cell)的堆叠,在结构优化时,只针对单元的结构进行,以降低NAS问题的难度。基于进化算法或强化学习的搜索方法,即使面对已经缩小了的搜索空间,仍然需要耗费巨大且难以承受的时间。本实例利用可微结构搜索方法(DARTS)对单元结构进行优化,解决基于车体振动数据的轨道几何病害识别CNN模型的结构优化问题。
轨道几何病害会反映为样本数据中振动数据的振幅变化。经过卷积等特征提取运算的处理,这些振幅变化转变为多组数值向量或矩阵,称为特征图(feature map),也是轨道几何病害的振动特征。如图2和图3所示,单元(Cell)是由若干特征图作为节点(node)和特征提取运算作为边(edge)组成的有向无环图(directed acyclic graph)。单元中有三个固定节点和若干个中间节点,固定节点中两个作为输入接收之前单元的输入,一个作为输出。每个中间节点都与其他两个中间节点或输入节点相连,所有中间节点通过级联(concatenation)与输出节点相连。单元分普通单元(Normal Cell)和缩减单元(ReductionCell)。普通单元输入和出处特征图的尺寸和通道数相同。而缩减单元提取特征的尺寸是输入的一半,通道数是输入的2倍。这样的单元结构既可以提取轨道几何病害具有的不同长度的特征,又可以处理不同特征之间的关系。
(3)运算块结构
本实例利用2维运算操作作为Cell的边来处理样本数据X
卷积运算的特征提取数量由卷积核的通道数决定。所以为了充分提取特征,模型中的卷积核通道数会逐层增大。传统的普通卷积运算(Conv)的卷积核与输入特征图的所有通道都要进行运算,如果用普通卷积处理车体振动,随着通道数量的递增,神经网络运算量将迅速增大,从而导致模型存在难以训练,并且性能低。
近来许多高效的神经网络引入了深度可分离卷积和扩张卷积等操作来应对这个问题。深度可分离卷积包括深度卷积(Depthwise Conv)和点卷积运算(Pointwise Conv)两个核心元素。其中深度卷积仍保持一定卷积核宽度,但每个卷积核仅处理输入特征图的一个通道;而点卷积运算宽度为1,同时处理输入特征图的全部通道。通过这样的分步卷积,可以实现在保持模型的特征提取能力的同时,降低运算量。扩张卷积(Dilated Conv)的卷积核不与输入数据的连续相邻元素进行卷积,而是以一定间隔进行运算。例如,卷积核宽度为3,扩张参数为1的扩张卷积进行运算时,第i次与卷积核进行运算的输入数据X的元素由[x
因此,为了在保证准确性的同时,大幅降低运算量,本实例在构建MTGDI-CNN的单元时,基于2维卷积运算构建2-d DSCB和2-d DiSCB来替代普通卷积运算。除深度卷积、点卷积运算和扩张卷积外,2-d DSCB和2-d DiSCB还包括2维批标准化运算(2-dBN)和非线性整流单元(ReLU)等运算以使每个运算块都具有独立的特征提取能力,可以在单元中替换任意的边。块中各种运算按Conv-BN-ReLU的次序排列,结构如图4和图5所示。2-d DSCB和2-dDiSCB中的卷积核尺寸可以设置不同的值以满足提取不同尺寸车体振动特征的需求。
(4)基于DARTS的单元结构搜索
通过上述设计,单元具有了高效提取振动特征的能力,但是单元中不同特征图的连接方式(即单元结构)需要根据CVD-based MTGDIP问题的特点进行优化。单元结构优化是如公式(1)(2)所示的双层优化问题。在CVD-based MTGDIP中,Cell需要多个中间节点和不同尺寸的卷积核来提取不同长度的轨道几何病害特征,和分析特征间的关系。因此公式(1)单元结构的搜索空间规模仍然是巨大的。另一方面,内层优化问题中将外层确定的模型结构训练至收敛的过程需要大量时间。因此,MTGDI-CNNDP的CAS问题仍然难以求解。
本实例使用可微结构搜索(Differentiable Architecture Search,DARTS)方法解决这个问题。为了在外层优化搜索空间高效搜索,DARTS将搜索空间由离散转为连续,同时利用梯度下降的方式进行求解,加快寻优速度;为了减少内层优化寻优的时间,DARTS利用模型的一代训练结果对最优权重进行二阶近似,取代了训练至收敛的过程。在单元中,中间节点j的特征图p
其中,i<j表示节点i为在j之前,向其输出的节点;o
其中,
若用α表示模型结构A(MTGDI-CNN模型)中的所有结构参数(即单元Cell中各节点Node之间各种连接方式的全部权重向量),则公式(1)(2)的双层优化模型可以表示为公式(11)和公式(12)。
其中,L
由于公式(9)将单元结构的搜索空间转变为了连续空间,因此可以通过求梯度的方法对α进行优化,即沿梯度
其中,ξ是一个小实数,也称为学习率。应用链式法则对梯度
上式即为将公式(13)代入
由于公式(14)的第二项仍然难以求解,所以在DARTS方法中,使用了有限差分逼近方法对其进行了再次近似,如公式(15)。即使用w的左极限w
其中,∈是一个足够小的实数,一般取
(5)数据集类别不平衡问题应对
由于地铁轨道几何病害是一种非正常现象,正常运营的地铁线路上具有轨道几何病害的处所很少,因此4.1节中生成的CVD-TGD样例数据集是一个类别不平衡(Class-imbalanced,CI)数据集。通常情况下,不存在病害的样例数量是存在II级病害样例数量的几十倍。直接将这样的数据集用于MTGDI-CNN模型的训练将会导致不利影响,模型难以学习数量较少样例类型的特征,从而降低该等级轨道几何病害的识别效果。ML-based method通常使用对模型的分类阈值进行加权或者对样例数据集重采样等方法解决这个问题。但是对模型分类阈值加权需要预先估计各个类别的比例,因此在CVD-based MTGDIP问题中并不适用。对样例数据集重采样的主要分为过采样(oversampling,OS)和欠采样(downsampling,DS)。过采样方法还可以分为随机过采样(Random OS,ROS)和合成少数过采样(Syntheticminority oversamplingtechnique,SMOTE),这是一种对类别较少的样例依据聚类进行合成的方法。使用DS方法会导致大量不存在病害的样例没有被模型学习,而SMOTE会使很多原本不存在的样例用于训练。考虑到CVD-based MTGDIP问题具有高类别不平衡比例和高非线性的特点,使用DS和SMOTE方法会降低模型的病害识别效果。因此,本实例提出在CVD-basedMTGDIP问题中使用ROS方法来处理类别不平衡数据集,即对少数类别的样例进行随机复制。值得注意的是,MTGDI-CNN模型的构建分为单元结构优化和最终模型验证两个阶段。为了保证模型具有充足的泛化能力,本实例提出了仅在FMV的训练阶段使用ROS的策略。考虑到单元结构优化阶段,模型会根据输入数据集的特征更改模型结构,因此在该阶段不使用ROS方法,以避免模型结构过于适应较少数量样例类型的特征。而在最终模型训练阶段,使用ROS方法处理用于模型训练的数据集,使模型达到更好的训练效果。
3、模型性能的评价指标
(1)模型性能评价指标的选取原则
选择模型的性能评价指标时,需要考虑具体的应用场景。在进行轨道几何病害检测时,地铁轨道管理部门最关心的是实际存在的病害没有被检测到的情况(漏检)和检测到的病害与实际等级不相符的情况(虚警)。由于对地铁运营安全的高要求,漏检比误报更需要被重视。
(2)轨道几何病害识别性能评价指标
在机器学习类分类任务中常用的评价指标是查准率(precision)和查全率(recall)。查准率越高,虚警情况越少;查全率越高,漏检情况越少。为了综合考虑查准率和查全率,通常需要使用二者的调和平均数F
本实例提出了轨道几何病害F指数(TrackgeometrydefectF-score,TGDF)用于在MTGDI-CNNDP问题中进行模型性能评价。考虑到轨道几何病害存在不同等级,TGDF是各等级TGDF
其中,i表示病害等级;TP
4、案例分析
4.1案例数据描述
本案例使用的实际现场数据集与Wang et al.(2022)相同,以便与其进行对比。该数据集是作者使用0节中描述的便携式检测仪于2020年12月在北京地铁1号线采集的。数据采集共进行了12次(其中11次为完整检测,1次检测缺少一个区间),6次为上行6次为下行。共乘坐6列运营列车,次序为0,0,0,1,2,2,3,4,4,5,6,2。数据的采样频率为250Hz,采集的数据包括CVD及列车运行的速度和数据对应的里程。轨道几何病害数据来自2020年12月15日的轨检车检测报告。本案例选择高低病害(即C=高低)验证所提出模型的有效性。轨道几何病害数据集中共有高低病害I级127处,II级34处,不存在III级和IV级病害。
本案例选用s=20m和d=0.25m生成样本,根据3.1中的规则生成样例数据集。样本的最终尺寸为1×80×7(1通道2维数据)。共生成样例16659组,其中无病害样例15740组,I级病害样例726组,II及病害样例193组。样例数据集中仅包含I级超限和II级超限的情况,即其中样例数据标记的取值范围为Y
4.2模型有效性验证
为了有效验证模型的泛化性能,本案例将原始数据集划分为4份,分别为类别不平衡的训练数据集
同时,为了保证案例分析的可复现性,本案例所有涉及到随机数生成的过程均预先指定随机数种子,且对不同模型进行训练与验证时,使用相同的划分后的数据集。
1)模型参数的设置
1)备选操作的设置。根据样本尺寸,卷积核尺寸2-d DSCB是3×3、5×5、7×7;2-dDiSCB是3×3、5×5;2-d MaxPool和2-dAvgPool是3×3。加上空操作,单元的备选操作集共8种元素。
2)CAS。本案例进行单元结构搜索时,选择的单元堆叠层数为8层,初始卷积的通道数为6,每批训练的样本数为128(训练集和测试集相同),共训练50代。其他参数遵循DARTS基本设置,单元的中间节点数为4,损失函数选用交叉熵函数(cross-entropyloss),用于内层优化的梯度迭代算法是随机梯度下降(SGD),学习率以无重启的余弦退火方法更新,初始值为0.025,动量为0.9,权重衰减系数为0.004;外层优化的梯度迭代算法是Adam
3)FMV。本案例设置了不同的堆叠层数和训练代数以分析部分超参数对模型性能的影响,将在下面详细叙述。初始卷积的通道数和每批训练的样例数相同,分别为6和512。其他参数遵循DARTS基本设置,损失函数选用交叉熵函数,用于模型训练的梯度迭代算法是SGD,参数设置与(2)相同。并且为了提高训练效率,使用了梯度裁剪(cutout)方法和概率为0.2的路径丢弃(path dropout)方法。
4)实现及计算。本案例的模型均由PyTorch机器学习框架实现,模型训练使用单张NVIDIAGeForce GTX 10808g显卡。
(2)模型结果
为了验证数据集类别不平衡问题应对策略的效果,本案例采用ROS方法分别对
表1不同策略的数据集处理方法设置
为了降低不同随机数因素带来的影响,本案例在CAS阶段使用了3种不同的随机数种子(Random seed=[0,2,4])分别进行,在FMV阶段使用了固定的随机种子。本案例首先进行了3种实验模式的CAS,每种模式使用3个随机数种子,得到了9种单元结构。M-1/2/3(BASE)的平均运算时间分别是0.9289,0.9363and 0.3474GPU days。可以看出,由于数据集数量的不同,不同实验设置的平均训练时间不同,并且在CAS阶段,训练数据集
接下来,本案例使用相同的随机数种子(Random seed=0)对每种单元结构组成的模型进行重新训练。4种实验设置与3个CAS阶段随机数种子组合共训练12次。为了同步验证TGDF的有效性,本案例基于
为了以较少的时间成本进行FMV,训练时单元堆叠层数为8层,训练代数为300,训练后各模型在不同随机数种子下的平均性能指标值如表2所示。可以看出,在FMV阶段的训练过程中使用ROS方法处理数据集之后进行训练的模式(M-3)比使用原始数据集进行训练的模式(BASE),可以使各种性能指标有明显的提升。另外,模型的平均训练时间与用于训练的样例数量正相关,因此M-1/2/3的平均训练时间基本相同,而BASE的平均训练时间较少。性能指标中,常用的通用指标ovoAUC和本实施例提出的TGDF指标都得到了提升,说明TGDF可以有效反应模型的综合性能。性能指标中Avg.TGDF、Avg.TGDF-1和Avg.TGDF-0.5分别提升8.0%,4.9%and 2.0%。这说明对
表2模型性能评价结果
(3)其他超参数影响分析
本案例在上面的M-3设置中,TGDF值最高的单元结构(为random seed=2得到的单元结构,如图10所示构建的模型,图10中(A)为普通单元(Normal Cell)具体的节点连接方式及其连接时使用的运算操作,(B)为缩减单元(ReductionCell)具体的节点连接方式及其连接时使用的运算操作。使用相同的随机数种子(Random seed=0),设置不同的堆叠层数(n=[8,16,24])和训练代数(epoch=[300,600,...,1500])进行了训练与测试。不同参数设置的模型最终验证综合性能指标TGDF和训练时间(traintime,GPU days)的对比如图11所示,为方便说明,用M
从图11的(A)部分中可以看出,M
表3 M
(4)与既有模型对比
本案例与Wang et al.(2022)中利用黑盒枚举法得到的模型(以下简称Wang-model)进行了对比。Wang-model搭建模型时,先按顺序将1个普通2维卷积(2-d Conv)运算,1个ReLU运算和1个2维最大池化(2-dMaxPool)运算固定组成功能层(functional layer,FL),之后将多个FL进行简单堆叠,并通过指定不同层的2-d Conv卷积核尺寸的方式构建模型。
Wang-model的模型结构可以通过给定FL层数、卷积核初始边长、特征图最小宽度和最小高度四种超参数确定。由于一些限制,该方法通过这4个参数可以确定360中不同结构的模型,因此Wang et al.(2022)使用了枚举的黑盒尝试法进行模型结构搜索。作为对比本案例中的搜索空间为8^14。本案例使用与之前相同的计算资源,使用3种不同的随机数种子对Wang et al.(2022)中的360种结构的模型进行了枚举训练及验证。每批样例数为512,每个模型的训练代数为100,3种随机数种子下,360个模型枚举验证过程平均耗时2.13GPU天,作为对比,本案例使用方法平均耗时为0.35GPU天,比其低83.6%。之后,本案例计算了360个模型在3个随机数种子下TGDF/TGDF-1/TGDF-0.5/ovoAUC性能指标的平均值,并挑选每种指标平均值的最大值与与MTGDI-CNN的平均性能指标的(表2中M-3的平均性能指标)进行了对比,如表4所示。可以看出,MTGDI-CNN的各类指标的性能均好于Wang-model,四种性能指标分别提高6.7%、2.7%、0.1%、1.8%。这说明,本案例提出的方法相比于枚举的黑盒尝试法可以极大提高模型结构搜索的效率,并且最终得到的MTGDI-CNN模型的综合性能更好。
表4模型评价结果
4.3与1维卷积搭建的模型对比
为了验证2-d卷积比1-d卷积更适用于CVD-basedMTGDIP问题的观点,本案例重新构建了一种地铁轨道几何病害识别1-d CNN模型(MTGDI-CNN-1-d),并使用与前节中相同划分的数据集对其首先验证。
(1)1维模型设置
MTGDI-CNN-1-d由MTGDI-CNN中的2-d操作被1-d替换而来。为了适配其输入,样本数据由1×80×7(1通道2维数据)重整为7×80(7通道1维数据)。模型中1-d DSCB的卷积核尺寸包括3、5、7、11、15;1-d DiSCB的卷积核尺寸包括3、5、7、11、15;1-dMaxPool和1-dAvgPool的卷积核尺寸为3。加上空操作,1-d单元的备选操作集共13种元素。其余模型设置均与前节相同。ROS设置如表5所示。
表5 MTGDI-CNN-1-d类别不平衡策略设置
(2)模型验证结果
本案例首先使用与前面相同的3个随机数种子,基于不同的实验设置处理数据,利用DARTS方法训练50代,得到了3种单元结构(M-3-1-d与BASE-1-d的CAS阶段设置相同,仅需进行3次实验),平均运算时间为0.9584GPU天。接下来,本案例使用与前节相同的随机数种子,对每种单元结构组成的模型进行重新训练。根据表5中的设置,2种实验设置与3个CAS阶段随机数种子组合共训练6次。基于测试数据集计算出的各项性能指标与0节中M-3模式的对比如表6所示。可以看出,在FVM阶段使用相同数量的进行训练的时间基本相当(M-3与M-3-1-d比较),说明1-d卷积和2-d卷积具有相当计算效率。而2-d卷积的M-3模式各项性能指标均最高,M-3相比M-3-1-d四种指标分别高33.3%,30.0%,26.8%and 8.1%,说明2-d卷积更加适用于CVD-Based MTGDIP问题。而比较M-3-1-d与BASE-1-d则再次验证了0节的结论,即仅对FVM阶段的训练数据集采用ROS方法的应对策略可以得到更好性能的模型。
表6模型评价结果
本发明具有如下优点:
(1)提出了基于DARTS方法的地铁轨道几何病害识别CNN模型(MTGDI-CNN),实现对地铁轨道病害及其严重程度的一体化识别。通过将DARTS引入本发明的问题场景,相较于传统黑盒尝试法,大大提高了结构优化的效率和效果(efficiency and effectiveness)。
(2)提出了MTGDI-CNN建模时应对数据集的数据类别不平衡问题的策略。该策略可以降低模型结构优化和训练时使用类别不平衡数据集所导致的模型不易训练的影响。
(3)提出了一种用于评价地铁轨道几何病害识别模型综合性能的指标。该指标设计过程考虑了地铁轨道基础设施管理的实际需求,用于评价模型性能时更有利于提高模型的实际应用价值。
本实施例还提供了一种地铁轨道几何病害识别系统,参见图12,所述系统,包括:
数据获取模块901,用于获取目标地铁轨道的车体振动数据和车体信息;所述车体信息,包括:车体运行速度和车况信息。
数据划分模块902,用于对所述目标地铁轨道的车体振动数据进行分段,并基于均方根值的方法对各段数据进行转换,得到所述目标地铁轨道的多段等距离间隔数据。
检测数据确定模块903,用于根据所述目标地铁轨道的多段等距离间隔数据和所述目标地铁轨道的车体信息,得到所述目标地铁轨道的检测数据。
病害识别模块904,用于将所述目标地铁轨道的检测数据输入轨道几何病害识别模型中,确定所述目标地铁轨道是否存在轨道几何病害以及存在时的病害等级。
其中,所述轨道几何病害识别模型是采用训练数据,基于可微结构搜索的方法对二维卷积神经网络进行训练得到的。所述训练数据,包括:地铁轨道样本的检测数据和对应的标签数据;所述标签数据,包括:所述地铁轨道样本是否存在轨道几何病害以及存在时的病害等级。
本实施例采用可微结构搜索方法(Differentiable architecture search,DARTS),利用松弛的方法,将搜索空间由离散转变为连续,并使用基于梯度下降的方法进行优化。并且不需要在模型优化结构的设计中引入如控制器或超网等额外部件,降低了建模难度,提高了搜索效率。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种轨道交通车轮身份和装车位置在线动态识别系统及识别方法
- 地铁施工临时轨道车脱轨预警机构以及地铁施工临时轨道车运输系统
- 一种地铁轨道几何形位参数动态检测系统及方法
- 一种地铁轨道几何检测数据矫正方法及系统